









文章目录
Python并发编程2
1. 僵尸进程与孤儿进程
僵尸进程
指进程代码运行结束之后并没有直接结束而是需要等待回收子进程资源才能结束
孤儿进程
即主进程已经死亡(非正常)但是子进程还在运行,操作系统中通常都有会回收孤儿进程的机制
2. 守护进程
- 守护进程即守护着某个进程,一旦这个进程结束那么也随之结束。设置守护进程一定要在进程启动之前对其进行设置。
from multiprocessing import Process
import time
def test(name):
print('总管:%s is running' % name)
time.sleep(3)
print('总管:%s is over' % name)
if __name__ == '__main__':
p = Process(target=test, args=('tom',))
p.daemon = True # 将字进程设置为守护进程(一定要放在start语句上方)
p.start()
print("tom寿终正寝")
time.sleep(0.1)
# tom寿终正寝
# 总管:tom is running
3. 互斥锁
-
多个进程操作同一份数据的时候,会出现数据错乱的问题。针对该问题,解决方式就是加锁处理:将并发变为串行,牺牲效率但是保证了数据的安全
-
锁就可以实现将并发变成串行的效果
行锁、表锁 -
使用锁的注意事项
在主进程中产生 交由子进程使用
1.一定要在需要的地方加锁 千万不要随意加
2.不要轻易的使用锁(死锁现象)
import json
from multiprocessing import Process, Lock
import time
import random
# 查票
def search(name):
with open(r'data.txt', 'r', encoding='utf8') as f:
data_dict = json.load(f)
ticket_num = data_dict.get('ticket_num')
print('%s查询余票:%s' % (name, ticket_num))
# 买票
def buy(name):
# 先查票
with open(r'data.txt', 'r', encoding='utf8') as f:
data_dict = json.load(f)
ticket_num = data_dict.get('ticket_num')
# 模拟一个延迟
time.sleep(random.random())
# 判断是否有票
if ticket_num > 0:
# 将余票减一
data_dict['ticket_num'] -= 1
# 重新写入数据库
with open(r'data.txt', 'w', encoding='utf8') as f:
json.dump(data_dict, f)
print('%s: 购买成功' % name)
else:
print('不好意思 没有票了!!!')
def run(name,mutex):
search(name)
mutex.acquire() # 抢锁
buy(name)
mutex.release() # 释放锁
if __name__ == '__main__':
mutex = Lock()
for i in range(1, 11):
p = Process(target=run, args=('用户%s' % i,mutex))
p.start()
运行结果:
用户1查询余票:1
用户2查询余票:1
用户3查询余票:1
用户4查询余票:1
用户5查询余票:1
用户1: 购买成功
不好意思 没有票了!!!
不好意思 没有票了!!!
不好意思 没有票了!!!
不好意思 没有票了!!!
在上述实验中如果不加入互斥锁时,程序运行速度很快并且用户1-用户5都能购买到票,而票总共只有一张,这显然不合理。在加入互斥锁后程序运行效率大幅降低,但只有一个用户可以买到票,这就是我们牺牲了程序的效率而保证了数据的安全性

4. 进程通信IPC机制
我们知道进程与进程之间的数据是相互隔离的无法互相调用,但实际生产环境中我们却常需要在进程见进行相互通信,这里我们引入IPC机制(Intent Process Communication),意识就是进程间通信。注意IPC机制并不是只在编程语言中存在,它在操作系统中同样存在。而在python中我们可以通过管道与队列两种方式来实现进程间的通信,实现原理为在进程间建立一个中转的空间,让进程与进程之间通过队列或管道进行数据的交互。
4.1 管道
管道:subprocess模块
stdin stdout stderr
# 一般不用
4.2 队列
"""
队列是在管道的基础上增加了锁等一系列的功能,所以我们在进程间的通信常用队列
队列:先进先出
堆栈:先进后出
"""
from multiprocessing import Queue
q = Queue(5) # 括号内可以填写最大等待数
# 存放数据
q.put(111)
q.put(222)
# print(q.full()) # False 判断队列中数据是否满了
q.put(333)
q.put(444)
q.put(555)
# print(q.full())
# q.put(666) # 超出范围原地等待 直到有空缺位置
# 提取数据
print(q.get())
print(q.get())
print(q.get())
print(q.empty()) # 判断队列是否为空
print(q.get())
print(q.get())
# print(q.get()) # 没有数据之后原地等待直到有数据为止
print(q.get_nowait()) # 没有数据立刻报错
"""
full和get_nowait和empty能否用于多进程情况下的精确使用
不能!!!
队列的使用就可以打破进程间默认无法通信的情况
"""

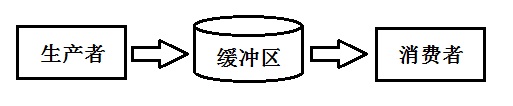
5. 生产者消费者模型
生产者消费者模式并不是GOF提出的众多模式之一,但它依然是开发编程过程中最常用的一种模式
生产者模块儿负责产生数据,放入缓冲区,这些数据由另一个消费者模块儿来从缓冲区取出并进行消费者相应的处理。该模式的优点在于:
- 解耦:缓冲区的存在可以让生产者和消费者降低互相之间的依赖性,一个模块儿代码变化,不会直接影响另一个模块儿
- 并发:由于缓冲区,生产者和消费者不是直接调用,而是两个独立的并发主体,生产者产生数据之后把它放入缓冲区,就继续生产数据,不依赖消费者的处理速度
from multiprocessing import Queue, Process, JoinableQueue
import time
import random
def producer(name, food, q):
for i in range(10):
print('%s 生产了 %s' % (name, food))
q.put(food)
time.sleep(random.random())
def consumer(name, q):
while True:
data = q.get()
print('%s 吃了 %s' % (name, data))
q.task_done()
if __name__ == '__main__':
# q = Queue()
q = JoinableQueue() # 在Queue中添加了join函数,阻塞函数,会阻塞直到等待队列中所有数据都被处理完毕。
p1 = Process(target=producer, args=('大厨tom', '玛莎拉', q))
p2 = Process(target=producer, args=('印度阿三', '飞饼', q))
p3 = Process(target=producer, args=('泰国阿人', '榴莲', q))
c1 = Process(target=consumer, args=('班长阿飞', q))
p1.start()
p2.start()
p3.start()
c1.daemon = True # 开启守护进程
c1.start()
p1.join()
p2.join()
p3.join()
q.join() # 等待队列中所有的数据被取干净
print('主进程')
6. 线程理论
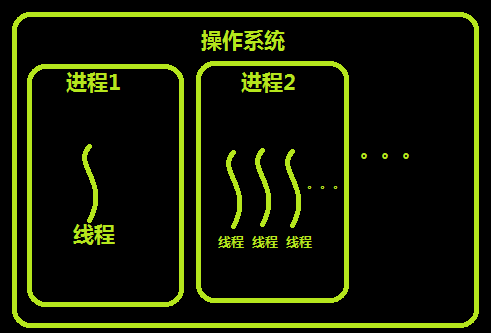
什么是线程?
进程其实是一个资源单位 真正被CPU执行的其实是进程里面的线程
"""
进程类似于是工厂 线程类似于是工厂里面的一条条流水线
所有的进程肯定含有最少一个线程
"""
进程间数据默认是隔离的 但是同一个进程内的多个线程数据是共享的

7. 开设线程的两种方式
"""
开设进程需要做哪些操作
1.重新申请一块内存空间
2.将所需的资源全部导入
开设线程需要做哪些操作
上述两个步骤都不需要 所以开设线程消耗的资源远比开设进程的少!!!
"""
方案一:
from threading import Thread
import time
def test(name):
print('%s is running' % name)
time.sleep(3)
print('%s is over' % name)
t = Thread(target=test, args=('jason',))
t.start()
print('线程')
方案二:
class MyClass(Thread):
def __init__(self,name):
super().__init__()
self.name = name
def run(self):
print('%s is running' % self.name)
time.sleep(3)
print('%s is over' % self.name)
obj = MyClass('jason')
obj.start()
print('线程')
8. 线程对象的其他方法
1.join方法 # 子线程等待其他线程结束
2.os.getpid获取进程号(验证同一个进程内可以开设多个线程)
3.active_count 统计当前正在活跃的线程数
4.current_thread().name # 获取当前线程的名字

9. 守护线程
"""
主线程的结束意味着整个进程的结束
所以主线程需要等待里面所有非守护线程的结束才能结束
"""
from threading import Thread
from multiprocessing import Process
import time
def foo():
print(123)
time.sleep(3)
print("end123")
def bar():
print(456)
time.sleep(1)
print("end456")
if __name__ == '__main__':
t1=Thread(target=foo)
t2=Thread(target=bar)
t1.daemon=True
t1.start()
t2.start()
print("main-------")
- join方法与守护线程总结
(主进程).join方法是主进程(线程)等待子进程(线程)运行完后才运行,守护进程(线程)是子进程(线程) 当主进程(线程) 运行完毕后立马结束运行
10. 线程互斥锁
from threading import Thread, Lock
from multiprocessing import Lock
import time
num = 100
def test(mutex):
global num
mutex.acquire()
# 先获取num的数值
tmp = num
# 模拟延迟效果
time.sleep(0.1)
# 修改数值
tmp -= 1
num = tmp
mutex.release()
t_list = []
mutex = Lock()
for i in range(100):
t = Thread(target=test, args=(mutex,))
t.start()
t_list.append(t)
# 确保所有的子线程全部结束
for t in t_list:
t.join()
print(num)

11. 局域网内文件上传下载多线程版本
局域网内实现文件上传下载
Server 端
import os
import json
import socket
from socket import SOL_SOCKET, SO_REUSEADDR
import common
from threading import Thread
server = socket.socket()
server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
server.bind(('192.168.11.43', 8080))
server.listen(5)
data_path = r'./服务端视频'
if not os.path.exists(data_path):
os.mkdir('./服务端视频')
# 获取文件名列表
file_name_list = os.listdir(data_path)
def run(sock):
while True:
data = sock.recv(4)
if not data: break
# 判断是否从服务器下载资源
if data == bytes(1):
# 序列化文件列表
list_json = json.dumps(file_name_list)
# 传输文建列表
common.info_into(sock, '文件列表', len(list_json))
sock.send(list_json.encode('utf8'))
# 获取用户选择文件信息
choice_data = sock.recv(4)
if not choice_data: break
choice = int(choice_data.decode('utf8'))
file_name = file_name_list[choice - 1]
# 拼接路径,获取文件大小
res = common.read_file(data_path, file_name, sock)
if res:
break
elif data == bytes(2):
real_dict2 = common.parse_dict(sock)
common.witer_file(file_name_list, real_dict2, data_path, sock)
while True:
sock, address = server.accept()
print(address)
t = Thread(target=run, args=(sock,))
t.start()
















 1421
1421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











