







爬取东方财富网的基金行情
网站链接:http://quote.eastmoney.com/
进入到网站之后点击基金
再点击排行
下面这张图就是我们想要获取的内容了

1.分析所有页的请求url
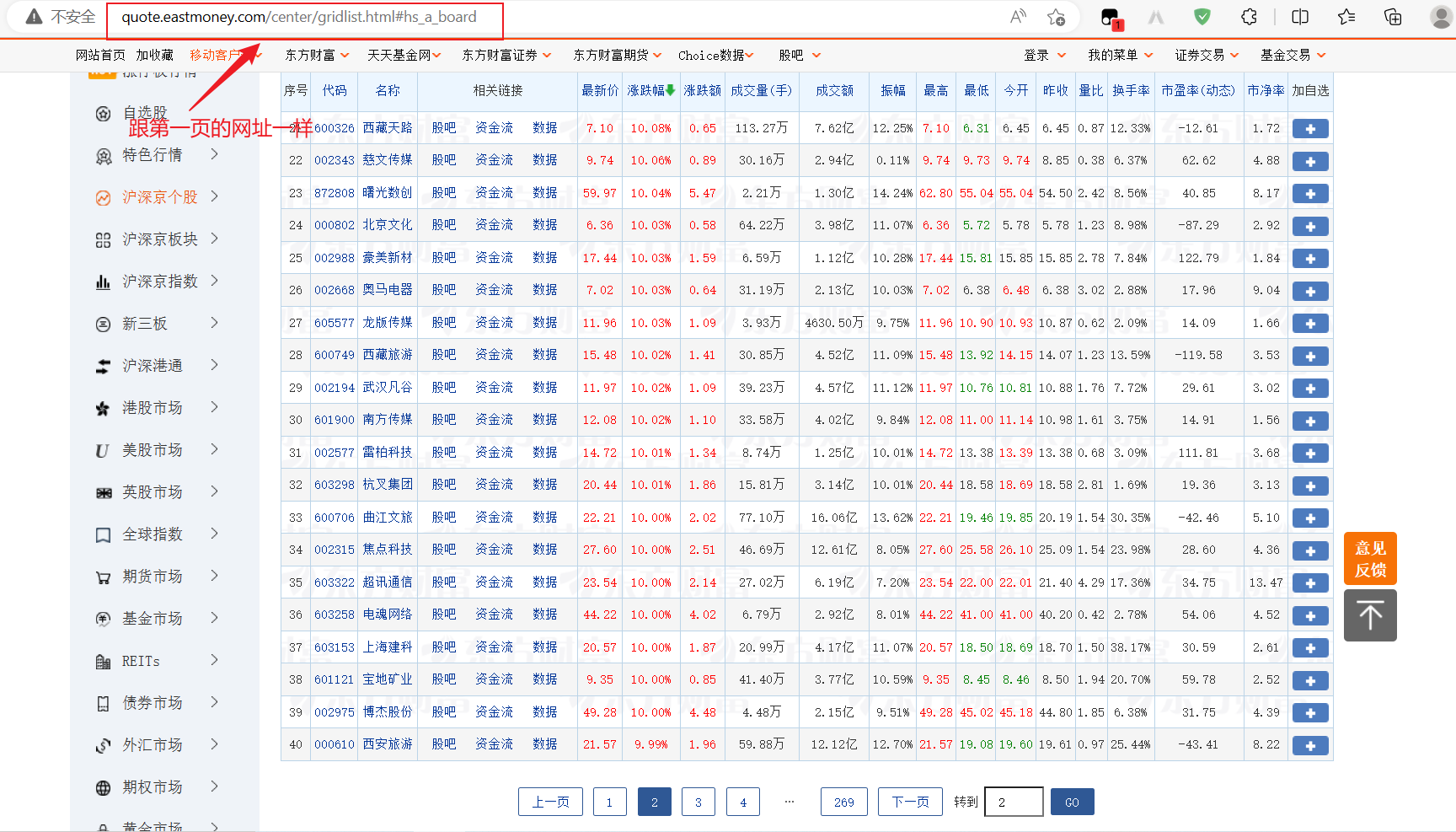
爬虫的第一步就是要获取网站的请求url,在这里我们是在第一页,然后点击下一页跳转到第二页之后发现,网页左上角的网址是没有变的。因为这是动态网页是通过Ajax动态加载的,无论你点击到哪一页,左上角的网址都是不会变的。
既然这是个动态网页那我们想要的数据肯定不是在网页源代码里的了,所以我们直接右击检查打开开发者工具,然后点击网络,选择Fetch/XHR,刷新网页,查看左边的网页
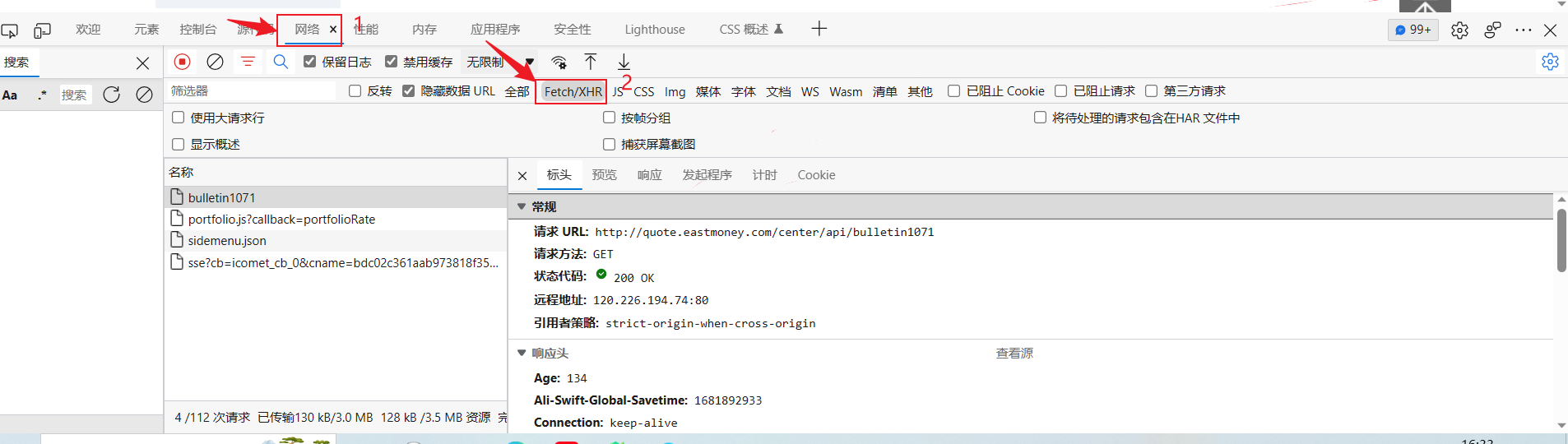
查看完之后发现我们想要的数据都不在里面,那么我们在JS里看看,点击JS,再选择清除,然后点击第二页刷新一下数据,然后查找
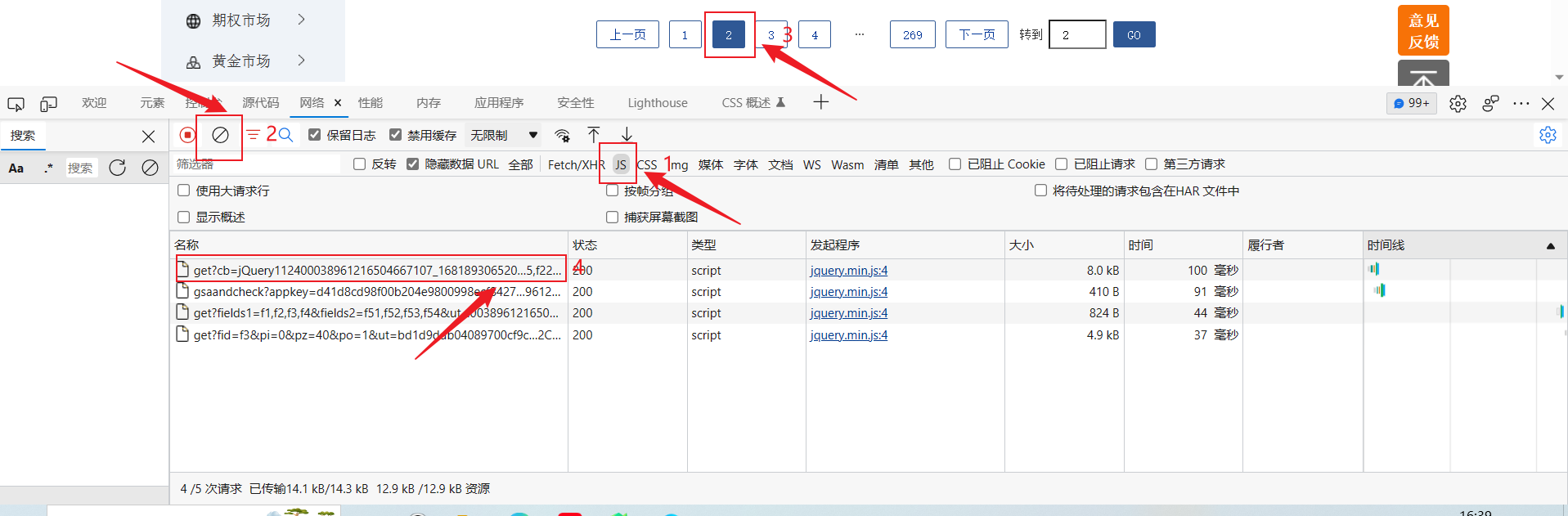
在我们点进第二页后发现已经刷新出了一些新的数据,我们依次点击,然后查看预览发现第一个就是我们想要的数据,而且很明显可以看出我们想要的数据是json数据。
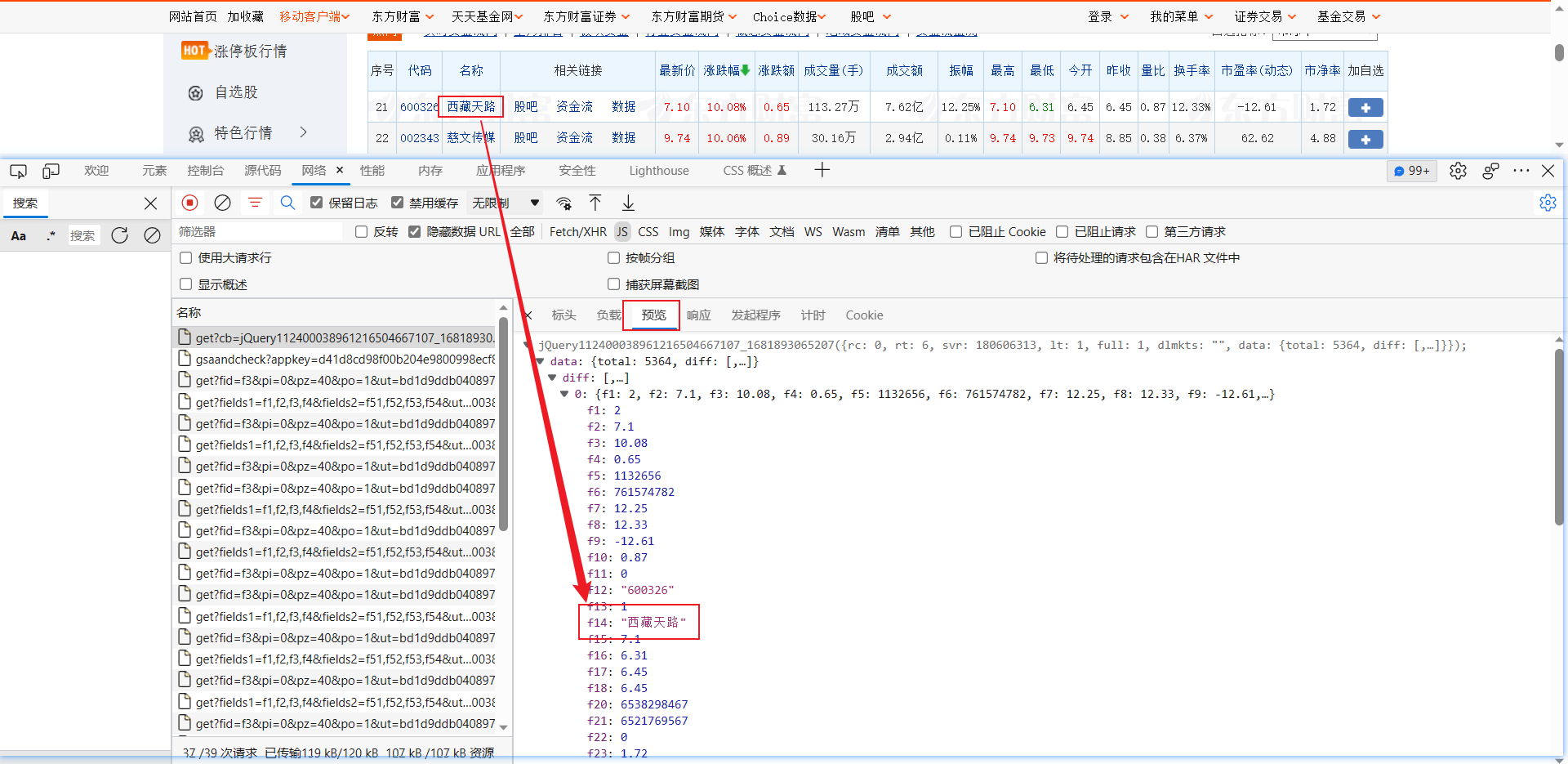
再查看一下这一页的请求url情况,点击标头
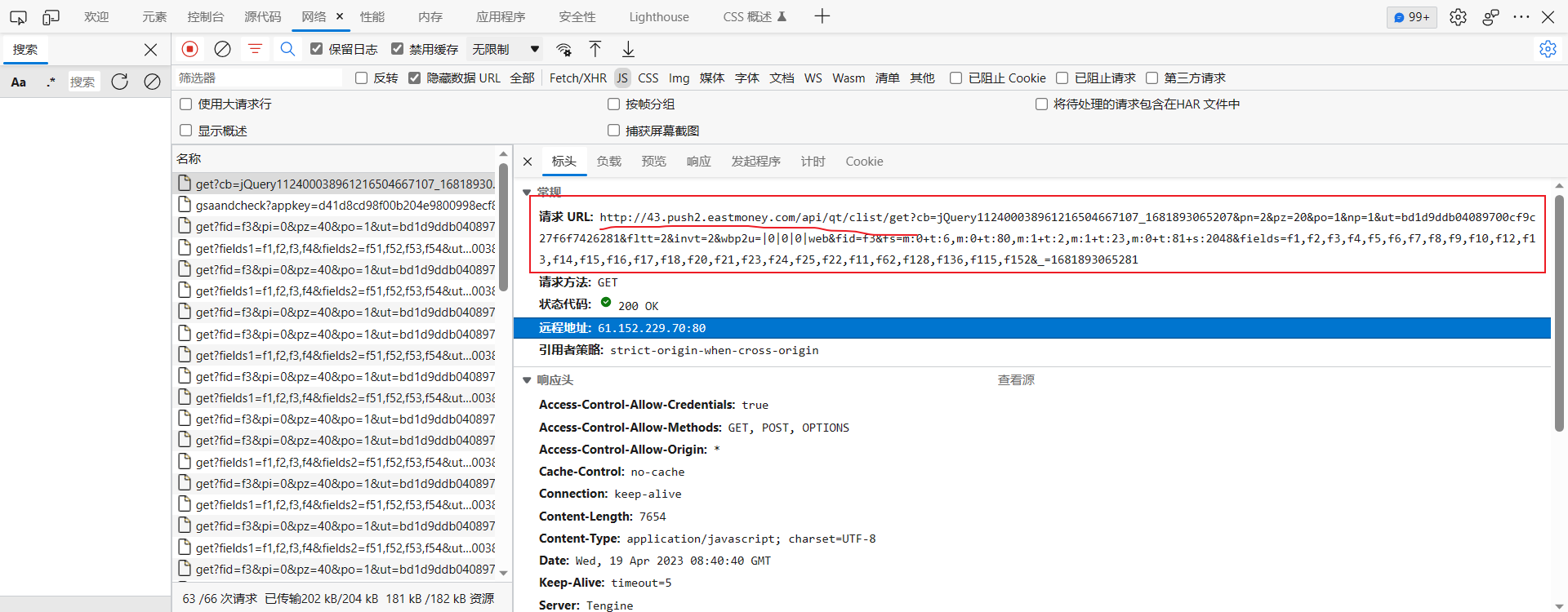
可以发现这页的请求url后面一大串,但其实疑问号"?"后面的都是参数,接下来我们看一下参数情况,点击负载
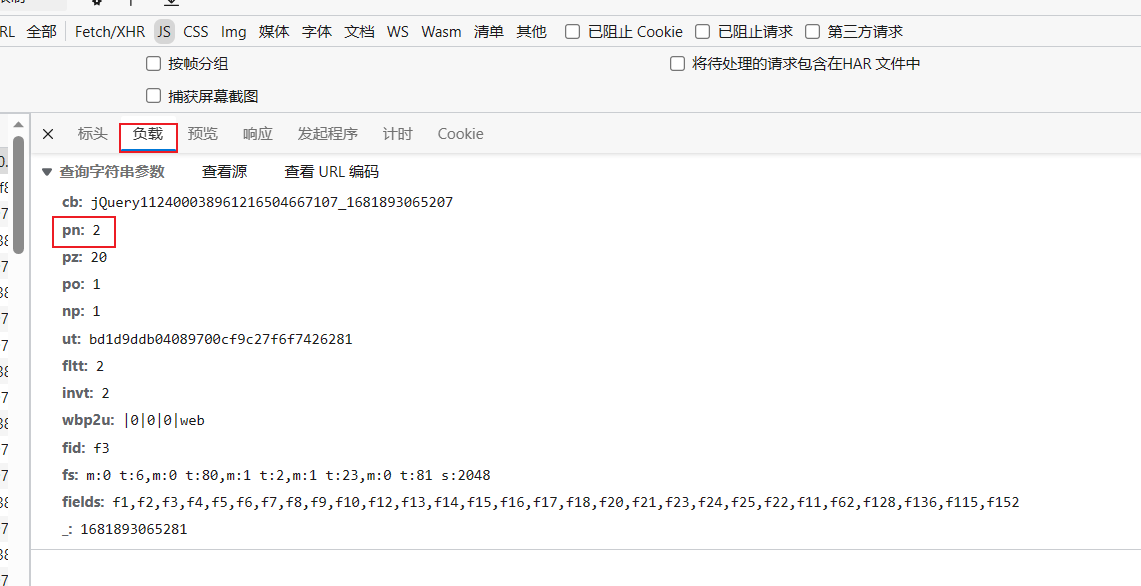
在负载里我们看到每一个参数,其中pn=2就是最关键的了,这其实就是代表着当前的页数。为了确保我们没有弄错,我们点击清除,再选择回到我们的第一页查看第一页的参数后发现,第一页的pn=1那就说明我们没有弄错
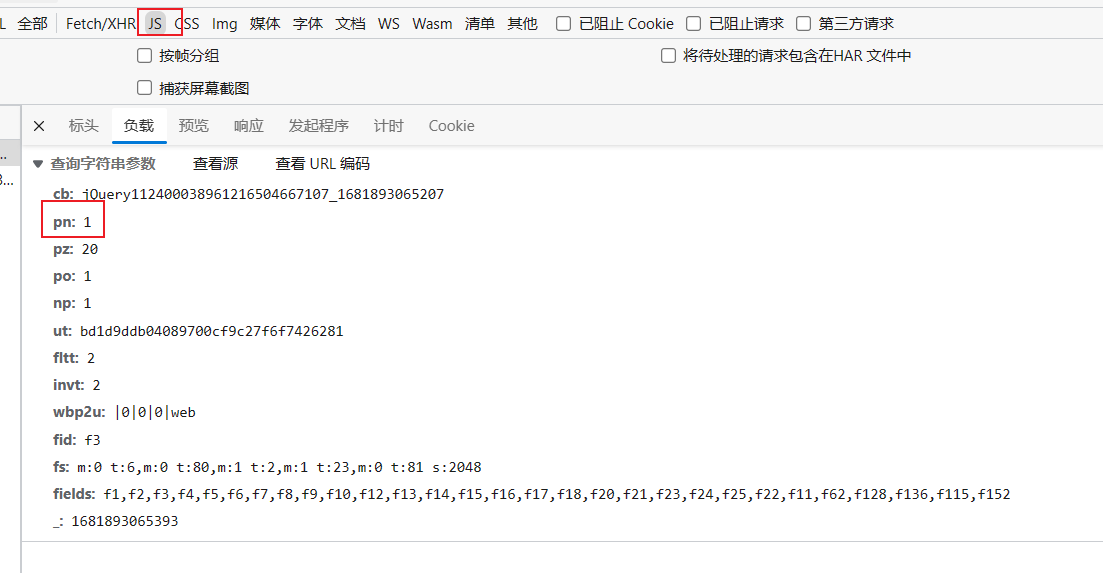
既然pn=1是第一页,pn=2是第二页那么每一页都有对应一个pn值,也就是说我们想要获取哪页的请求url就把其中pn的值替换成相应的值就行了,这样我们就可以获取所有页的请求url。
2.导入相应的库
在这里我测试了一下创建一个线程与不创建线程的运行时间,所以导入了Thread和time。
import csv
import time
import json
import requests
from threading import Thread
from urllib.parse import urlencode3.创建相应的表格表头
# 创建表格
f=open('股票行情2.csv','a+',encoding='utf-8')
a=csv.writer(f)
# 创建表头
a.writerow(('代码','名称','最新价','涨跌幅','涨跌额','成交量','成交额','振幅','最高','最低','今开','昨收','量比','换手率','市盈率','市净率'))
4.数据清洗
因为通过requests得到的数据是这样的,是一个字符串类型。

而我们想要的是里面的json数据,所以在这我取巧了,直接用字符串的切片把里面的json数据给拿出来了然后再用loads()方法转化为python字典对象。
def get_info(url):
response=requests.get(url,headers=head)
response=response.text[42:-2] # 取出json数据
data=json.loads(response) # 转化为python对象
datas=data['data']['diff']
for i in datas:
d={
'代码':i['f12'],'名称':i['f14'],'最新价':i['f2'],'涨跌幅':i['f3'],'涨跌额':i['f4'],'成交量':i['f5'],'成交额':i['f6'],'振幅':i['f7'],
'最高':i['f15'],'最低':i['f16'],'今开':i['f17'],'昨收':i['f18'],'量比':i['f10'],'换手率':i['f8'],'市盈率':i['f9'],'市净率':i['f23']
}
#添加进表格
a.writerow((d['代码'],d['名称'],d['最新价'],d['涨跌幅'],d['涨跌额'],d['成交量'],d['成交额'],d['振幅'],d['最高'],d['最低'],d['今开'],d['昨收'],d['量比'],d['换手率'],d['市盈率'],d['市净率']))
完整代码
import csv
import time
import json
import requests
from threading import Thread
from urllib.parse import urlencode
def get_info(url):
response=requests.get(url,headers=head)
response=response.text[42:-2]
data=json.loads(response)
datas=data['data']['diff']
for i in datas:
d={
'代码':i['f12'],'名称':i['f14'],'最新价':i['f2'],'涨跌幅':i['f3'],'涨跌额':i['f4'],'成交量':i['f5'],'成交额':i['f6'],'振幅':i['f7'],
'最高':i['f15'],'最低':i['f16'],'今开':i['f17'],'昨收':i['f18'],'量比':i['f10'],'换手率':i['f8'],'市盈率':i['f9'],'市净率':i['f23']
}
a.writerow((d['代码'],d['名称'],d['最新价'],d['涨跌幅'],d['涨跌额'],d['成交量'],d['成交额'],d['振幅'],d['最高'],d['最低'],d['今开'],d['昨收'],d['量比'],d['换手率'],d['市盈率'],d['市净率']))
if __name__ == '__main__':
start=time.time()
# 创建表格
f=open('股票行情.csv','a+',encoding='utf-8')
a=csv.writer(f)
# 创建表头
a.writerow(('代码','名称','最新价','涨跌幅','涨跌额','成交量','成交额','振幅','最高','最低','今开','昨收','量比','换手率','市盈率','市净率'))
head = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.34'}
url=' http://98.push2.eastmoney.com/api/qt/clist/get?'
for i in range(1,270):
parmas={
"cb": "jQuery112406972859260835329_1681831227889",
"pn": f"{i}",
"pz": "20",
"po": "1",
"np": "1",
"ut": "bd1d9ddb04089700cf9c27f6f7426281",
"fltt": "2",
"invt": "2",
"wbp2u": "|0|0|0|web",
"fid": "f3",
"fs": "m:0 t:6,m:0 t:80,m:1 t:2,m:1 t:23,m:0 t:81 s:2048",
"fields": "f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152",
"_": "1681831228407"
}
new_url=url+urlencode(parmas)
# 创建线程
t1 = Thread(target=get_info, args=(new_url,))
t1.start()
print(f'第{i}页爬取完毕!!!')
end=time.time()
print(f'总共用时{end-start}秒')
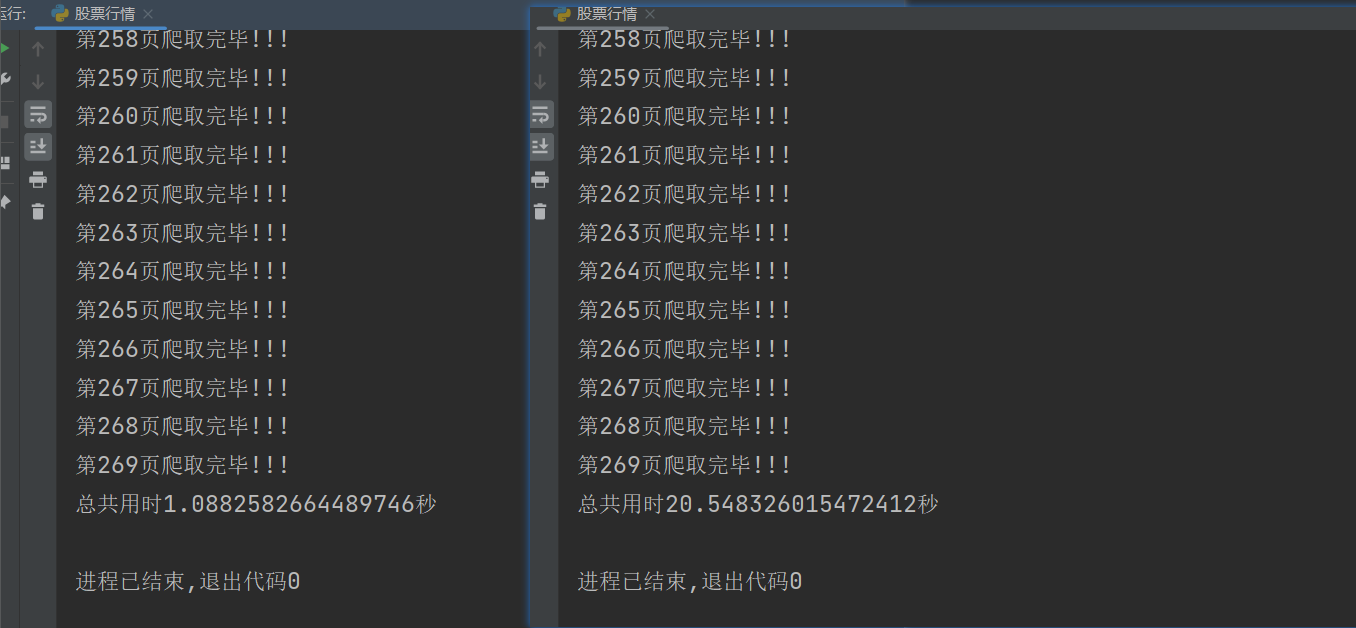
下面左图是创建了线程运行的,右图是正常运行的,可以发现使用多线程爬虫确实快得多。
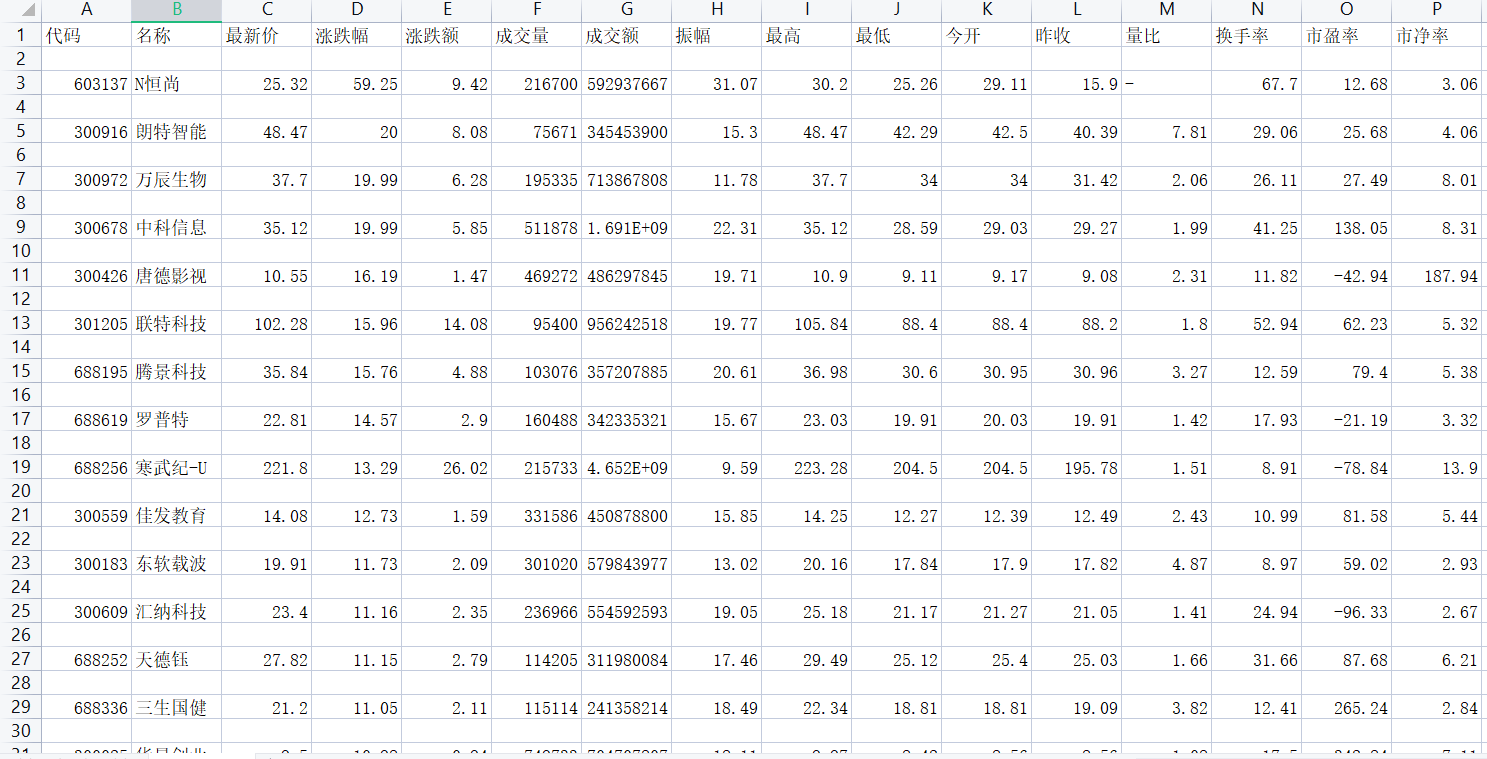
部分结果如下图
本人初学爬虫,如有误,希望大家多指正!!!














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









