







声明:文章参考数学建模清风的网课编写。
因子分析简介
因子分析由斯皮尔曼在1904年提出,其在某种程度上可以被看成主成分分析的推广和扩展。
因子分析通过研究变量间的相关系数矩阵,把这些变量间错综复杂的关系归结成少数几个综合因子,由于归结出的因子个数少于原始变量的个数,但它们又几乎包含原始变量的全部信息,所以也是对原有数据的降维。
由于因子往往比主成分更易得到解释,故因子分析比主成分分析更容易成功。
因子分析一般模型
假设有n个样本,p个指标,构成大小为n*p的样本矩阵x:
x
=
[
x
11
x
12
.
.
.
x
1
p
x
21
x
22
.
.
.
x
2
p
⋮
⋮
⋱
⋮
x
n
1
x
n
2
.
.
.
x
n
p
]
=
[
x
1
,
x
2
,
…
,
x
p
]
x = \begin{bmatrix} x_{11}& x_{12}& ...& x_{1p}\\ x_{21}& x_{22}& ...& x_{2p}\\ \vdots & \vdots & \ddots & \vdots \\ x_{n1}& x_{n2}& ...& x_{np} \end{bmatrix}=\begin{bmatrix} x_{1},x_{2} ,\dots ,x_{p} \end{bmatrix}
x=⎣
⎡x11x21⋮xn1x12x22⋮xn2......⋱...x1px2p⋮xnp⎦
⎤=[x1,x2,…,xp]
因子分析:
x
1
,
x
2
,
.
.
.
,
x
p
⇒
f
1
,
f
2
,
.
.
.
,
f
m
(
m
≤
p
)
,
x_{1},x_{2},...,x_{p}\Rightarrow f_{1},f_{2},...,f_{m}(m\le p),
x1,x2,...,xp⇒f1,f2,...,fm(m≤p), 且它们满足:
{
x
1
=
u
1
+
a
11
f
1
+
a
12
f
2
+
.
.
.
+
a
1
m
f
m
+
ε
1
x
2
=
u
2
+
a
21
f
1
+
a
22
f
2
+
.
.
.
+
a
2
m
f
m
+
ε
2
⋮
x
p
=
u
p
+
a
p
1
f
1
+
a
p
2
f
2
+
.
.
.
+
a
p
m
f
m
+
ε
p
\left\{\begin{matrix} x_{1} = u_{1} + a_{11}f_{1} + a_{12}f_{2} + ...+a_{1m}f_{m} + \varepsilon _{1}\\ x_{2} = u_{2} + a_{21}f_{1} + a_{22}f_{2} + ...+a_{2m}f_{m} + \varepsilon _{2}\\ \vdots \\ x_{p} = u_{p} + a_{p1}f_{1} + a_{p2}f_{2} + ...+a_{pm}f_{m} + \varepsilon _{p } \end{matrix}\right.
⎩
⎨
⎧x1=u1+a11f1+a12f2+...+a1mfm+ε1x2=u2+a21f1+a22f2+...+a2mfm+ε2⋮xp=up+ap1f1+ap2f2+...+apmfm+εp
其中
u
i
u_{i}
ui是
x
i
x_{i}
xi的均值,
a
i
j
a_{ij}
aij是
x
i
x_{i}
xi在因子
f
j
f_{j}
fj上的载荷,
f
1
,
f
2
,
.
.
.
,
f
m
f_{1},f_{2},...,f_{m}
f1,f2,...,fm被称为公共因子,
ε
i
\varepsilon _{i}
εi被称为特殊因子,各因子的线性组合构成了原始的指标。注意:表示式中的每一个
x
i
和
f
i
x_{i}和f_{i}
xi和fi都是一个包含n个元素的列向量。
上述式子可以简记为:
x
=
u
+
A
f
+
ε
x = u + Af + \varepsilon
x=u+Af+ε
其中:
A
p
×
m
=
a
i
j
,
u
=
[
u
1
u
2
⋮
u
p
]
,
f
=
[
f
1
f
2
⋮
f
m
]
,
ε
=
[
ε
1
ε
2
⋮
ε
p
]
A_{p\times m} = a_{ij}, \ \ \ u = \begin{bmatrix} u_{1}\\ u_{2}\\ \vdots \\ u_{p} \end{bmatrix}, \ \ \ f = \begin{bmatrix} f_{1}\\ f_{2}\\ \vdots \\ f_{m} \end{bmatrix}, \ \ \ \varepsilon = \begin{bmatrix} \varepsilon_{1}\\ \varepsilon_{2}\\ \vdots \\ \varepsilon_{p} \end{bmatrix}
Ap×m=aij, u=⎣
⎡u1u2⋮up⎦
⎤, f=⎣
⎡f1f2⋮fm⎦
⎤, ε=⎣
⎡ε1ε2⋮εp⎦
⎤
并假设公共因子彼此步相关,且具有单位方差;特殊因子彼此不相关且与公共因子不相关。
因子分析有几个比较重要的数据需要重点说明一下:
- A A A被称为因子载荷矩阵;
- A A A的行元素平方和 h i 2 = ∑ j = 1 m a i j 2 h_{i}^{2} = \sum_{j=1}^{m}a_{ij}^{2} hi2=∑j=1maij2表示原始变量 x i x_{i} xi对公共因子的依赖程度,被称为共性方差;
- A A A的列元素平方和 g i 2 = ∑ i = 1 p a i j 2 g_{i}^{2} = \sum_{i=1}^{p}a_{ij}^{2} gi2=∑i=1paij2表示公因子 f j f_{j} fj对x的贡献;
因子分析步骤
-
将数据导入SPSS后点击分析->降维->因子:
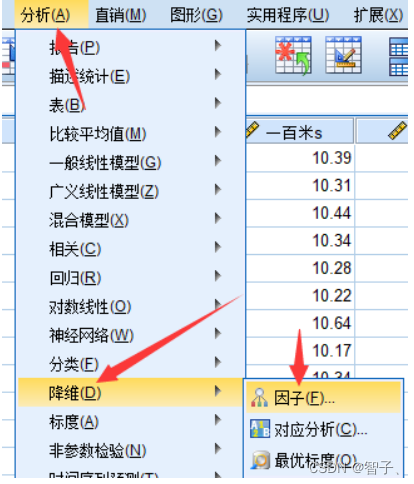
-
选择要分析的变量:
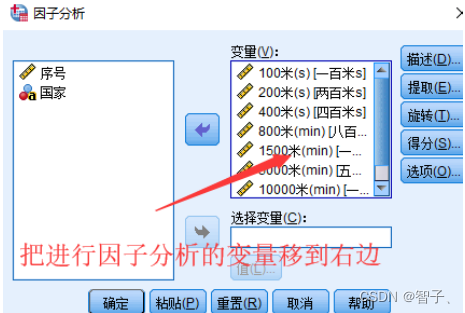
-
在第2步页面,单击右侧描述并按图进行勾选:
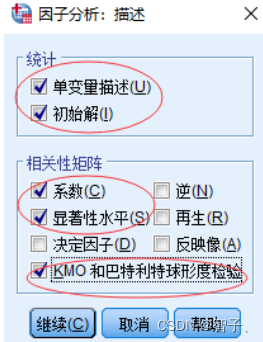
单变量描述:输出参与分析的每个原始变量的均值、标准差和有效取值个数。
初始解:输出未经过旋转直接计算得到的初始公因子、初始特征值和初始方差贡献率等信息。
系数:输出初始分析变量间的相关系数矩阵。
显著性水平:输出每个相关系数对于单侧假设检验的显著性水平。
KMO检验和巴特利特球形检验:进行因子分析前要对数据进行KMO检验和巴特利特球形检验。简单来说KMO检验标准:KMO>0.9,非常适合;0.8<KMO<0.9,适合;0.7<KMO<0.8, 一般;0.6<KMO<0.7,不太适合;KMO<0.5,不适合。巴特利特球形检验显著值小于0.05。 -
在第2步页面,单击右侧提取并按图依次选择。注意此步中没有选择要提取因子数,需要经过一次分析观察碎石图选择合适的因子数。
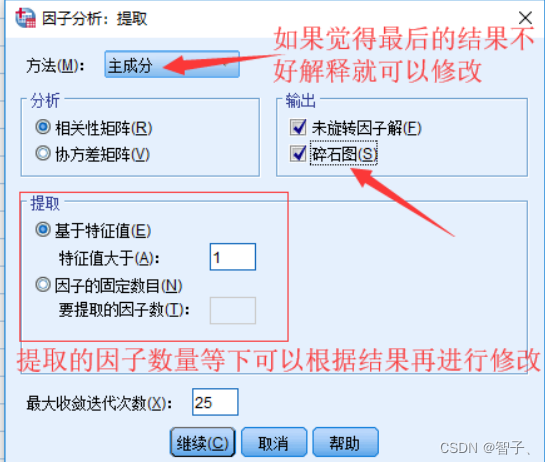
-
在第2步页面,单击右侧旋转并按图依次选择:
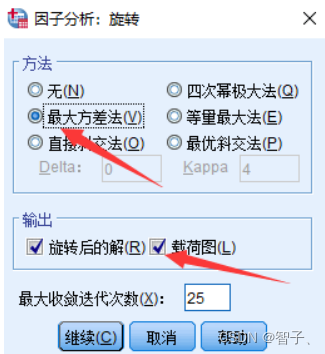
-
在第2步页面,单击右侧得分并按图依次选择:

-
确定因子数目:
碎石检验(scree test)是根据碎石图来决定因素数的方法。Kaiser提出,可通过直接观察特征值的变化来决定因素数。当某个特征值较前一特征值的值出现较大的下降,而这个特征值较小,其后面的特征值变化不大,说明添加相应于该特征值的因素只能增加很少的信息,所以前几个特征值就是应抽取的公共因子数。从碎石图可以看出,前两个因子对应的特征值的变化较为陡峭,从第三个因子开始,特征值的变化较为平坦,因此我们应选择两个因子进行分析。(SPSS中文版翻译成了组件,实际应翻译为因子)。
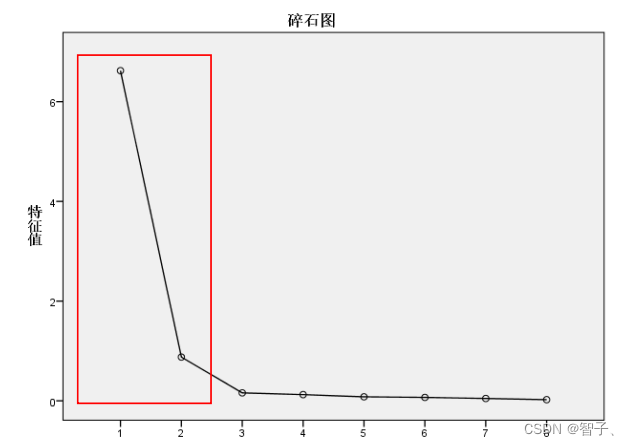
-
根据第7步确定好的因子数重新进行因子分析得出最终结果。
因子分析结果解释
-
数据是否适合因子分析(如图KMO>0.9,并且巴特利球形检验显著性<0.05。非常适合。):

-
公因子方差,即共性方差。载荷矩阵 A A A的行元素平方和 h i 2 = ∑ j = 1 m a i j 2 h_{i}^{2} = \sum_{j=1}^{m}a_{ij}^{2} hi2=∑j=1maij2表示原始变量 x i x_{i} xi对公共因子的依赖程度。
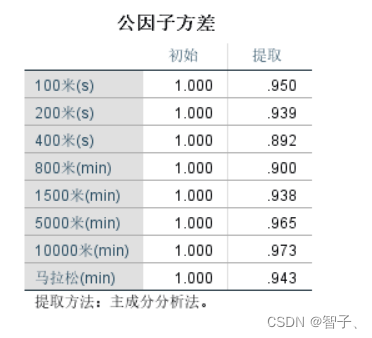
100米(s)这个变量的公因子方差为0.95,这可以解释为我们提取的两个公共因子对100米(s)这个变量的方差贡献率为95%,即这两个公共因子能够反映出(或者说保留)100米(s)这个变量95%的信息。 -
总方差解释。
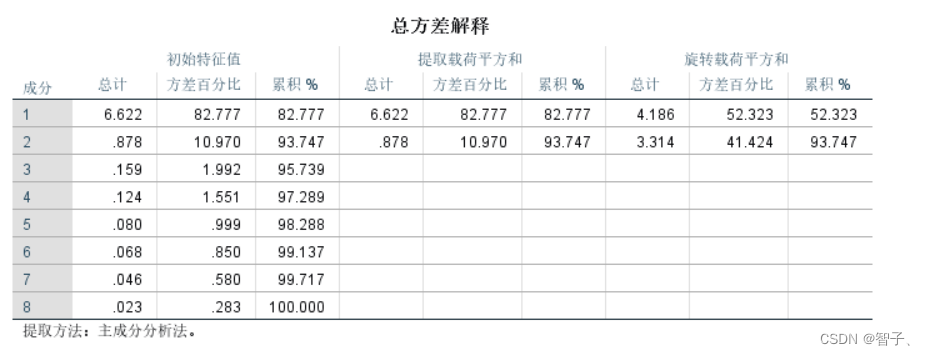 从“初始特征值”一栏中可以看出,前2个公共因子解释的累计方差达93.747%,而后面的公共因子的特征值较小,对解释原有变量的贡献越来越小,因此提取两个公共因子是合适的。
从“初始特征值”一栏中可以看出,前2个公共因子解释的累计方差达93.747%,而后面的公共因子的特征值较小,对解释原有变量的贡献越来越小,因此提取两个公共因子是合适的。
“提取载荷平方和” 一栏是在未旋转时被提取的2个公共因子的方差贡献信息,其与“初始特征值”栏的前两行取值一样。
“旋转载荷平方和”是旋转后得到的新公共因子的方差贡献信息,和未旋转的贡献信息相比,每个公共因子的方差贡献率有变化,但最终的累计方差贡献率不变 -
成分矩阵,即载荷矩阵 A A A。
注意:只解释旋转后的成分矩阵。因为旋转的作用使得旋转后的矩阵更容易解释。
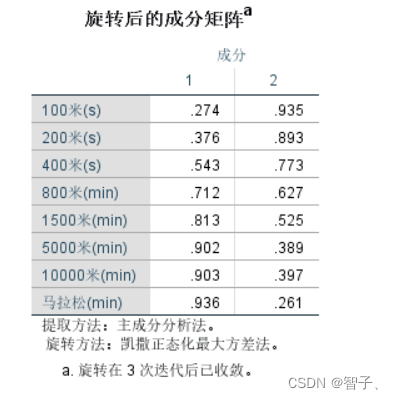
因子1(SPSS翻译为成分)在后5个变量的绝对值取值较大;因子2在前三个变量的绝对值取值较大。因此因子1可以解释为耐力因子,因子2可以解释为爆发力因子。 -
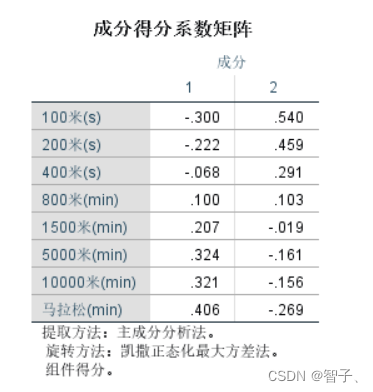
成分得分系数矩阵。
先来解释一下得分:
因子分析是将变量表示为公共因子和特殊因子的线性组合;此外,我们可以反过来将公共因子表示为原变量的线性组合,即可得到因子得分。
{ x 1 = u 1 + a 11 f 1 + a 12 f 2 + . . . + a 1 m f m + ε 1 x 2 = u 2 + a 21 f 1 + a 22 f 2 + . . . + a 2 m f m + ε 2 ⋮ x p = u p + a p 1 f 1 + a p 2 f 2 + . . . + a p m f m + ε p \left\{\begin{matrix} x_{1} = u_{1} + a_{11}f_{1} + a_{12}f_{2} + ...+a_{1m}f_{m} + \varepsilon _{1}\\ x_{2} = u_{2} + a_{21}f_{1} + a_{22}f_{2} + ...+a_{2m}f_{m} + \varepsilon _{2}\\ \vdots \\ x_{p} = u_{p} + a_{p1}f_{1} + a_{p2}f_{2} + ...+a_{pm}f_{m} + \varepsilon _{p } \end{matrix}\right. ⎩ ⎨ ⎧x1=u1+a11f1+a12f2+...+a1mfm+ε1x2=u2+a21f1+a22f2+...+a2mfm+ε2⋮xp=up+ap1f1+ap2f2+...+apmfm+εp ⇓ \Downarrow ⇓ { f 1 = b 11 x 1 + b 12 x 2 + . . . + b 1 p x p f 2 = b 21 x 1 + b 22 x 2 + . . . + b 2 p x p ⋮ f m = b m 1 x 1 + b m 2 x 2 + . . . + b m p x p \left\{\begin{matrix} f_{1} = b_{11}x_{1}+b_{12}x_{2}+...+b_{1p}x_{p}\\ f_{2} = b_{21}x_{1}+b_{22}x_{2}+...+b_{2p}x_{p}\\ \vdots \\ f_{m} = b_{m1}x_{1}+b_{m2}x_{2}+...+b_{mp}x_{p} \end{matrix}\right. ⎩ ⎨ ⎧f1=b11x1+b12x2+...+b1pxpf2=b21x1+b22x2+...+b2pxp⋮fm=bm1x1+bm2x2+...+bmpxp
b i j b_{ij} bij就是第i个因子 f i f_{i} fi对应于第j个变量 x j x_{j} xj的系数。因子分析的结果就是由 b i j b_{ij} bij构成的 B m × p B_{m \times p} Bm×p系数矩阵。
使用因子分析结果,可以计算因子。(图中的因子是SPSS计算好的)
















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











