






第一节课(2022.10.29)
线性回归
(1)线性
(2)残差是否符合正态(均值=0)
违反独立性原则:两个变量存在相关性。。以及伪重复实验,大多时候也是违反了独立性原则
方差不齐——本来显著的关系,做出来结果显示不显著
残差分布不正态,增大犯一类错误的可能性:本来无统计格局,统计显示出了显著性格局
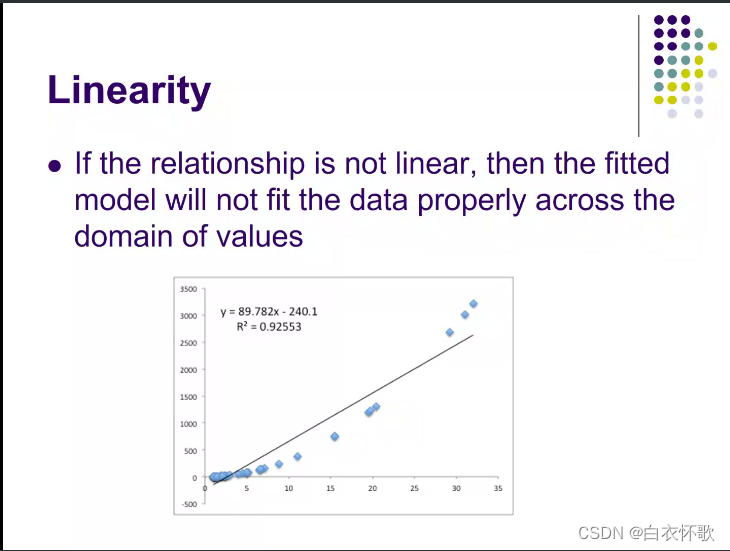
拟合曲线是否具有趋势
检验残差——QQnorm残差图
方差齐性的重要性

数据分布呈喇叭形:左侧-20到20,右侧-50到50,典型的方差不齐,不能贸然使用参数检验
很多时候数据方差不齐是内在属性导致的
画个直方图检验数据正态性,方差齐性——想办法转换,或者使用广义线性回归


残差正态不好时转换
残差正态性不好,log/开根号/标准化等来解决
先做一个概率分布直方图,预想转换后可能的数据分布,考虑使用的转换方式

左侧典型的泊松分布,除了使用ln转换,也可以套用广义线性模型里面的泊松分布
(1)lg转换适用于生态学的生物量等——即本身数据横跨多个数量级(0.01g和10g),降量纲和维度
(2)开根号,左侧点比较多,右侧点少
(3)平方转换
转换之后相应的解释也发生变化

标准化转换scale,均值为0,方差为1,不可以转换得到原方程。其余的lg、ln、次方、根号可以得到方程
两个变量之间存在交互效应
x1和x2对y交互产生显著影响,就必须把x1、x2单独对y主效应必须放在一个最佳模型里面,更好地解释交互效应
两个变量的贡献性,自相关关系
皮尔逊相关系数、斯皮尔曼相关系数,相关性本身也是样本量n的相关系数,样本量越多越不容易得到一个相关(人为定的P=0.7,r2=0.49)
奥德姆剃须刀原则(最吝啬法则):如无必要,勿增实体(引入变量越少越好)
好多种可选路径,默认最简单最高效的方式——简化模型,R2虽然有所损失,但可以把无关变量删除,得出一个简洁的拟合公式。
目录
为什么筛选简化模型
(1)容易过度拟合overfit,形成不符合认知的结论(两个变量高度自相关)
(2)提供无效的重复信息
→获得性价比更高的模型,花最少的自变量,获得更大的R2,更好的拟合优度。


最大模型:考虑所有的变量,拟合的R2比较高 (预测随机数,随机森林,进行迭代拟合)
e.g. 蚂蚁的草食性研究,全球数据所有变量(土壤、气候、水肥气热)全部拟合,就可以预测哪些地方食草性高
最少模型:R2略低于最大模型,拟合优度略微降低,但其参数个数往往大幅少于最大模型。即性价比比较高
零模型:评判全面最佳模型拟合出来的结果是否有用。零模型AIC值小于最佳模型,还没有无变量的影响显著,最佳模型无意义。(多自变量数据,使用AIC进行多模型推断)

n是样本量,SSerror是误差平方和,P是参数个数
固定样本量n,AIC随着误差平方和与自变量变化,AIC越小越好。两个模型之间差异不超过2,不能评价两个的好坏
step()傻瓜式路径依赖
广义的正态分布就是高斯分布
狭义的标准的正态分布:均值为0,方差为1(特指)
逻辑斯蒂模型(a/b出现在指数项上)
 狗的年龄和死亡
狗的年龄和死亡

logistic转换 存活的比例数据会较为完美地贴合这条曲线。
广义线性回归

与线性回归区别:
(1)函数名称lmer、glmer
(2)不同误差分布族
不要误差分布族,拟合model,比较不同的AIC
(3)线性公式变化
把中间部分转换(log等),再代入到线性公式
所谓的广义线性回归就是能够转化为线性回归的非线性回归

在R里面有根据右侧进行公式转换
混合效应模型
多水平模型/多层次模型/混合效应模型

最大似然法:赋予不同的权重
神枪手爷爷带孙子去森林,枪响鸟落,0.03的概率是孙子打的(随机因素)
处理一些日常不独立、不好处理的数据
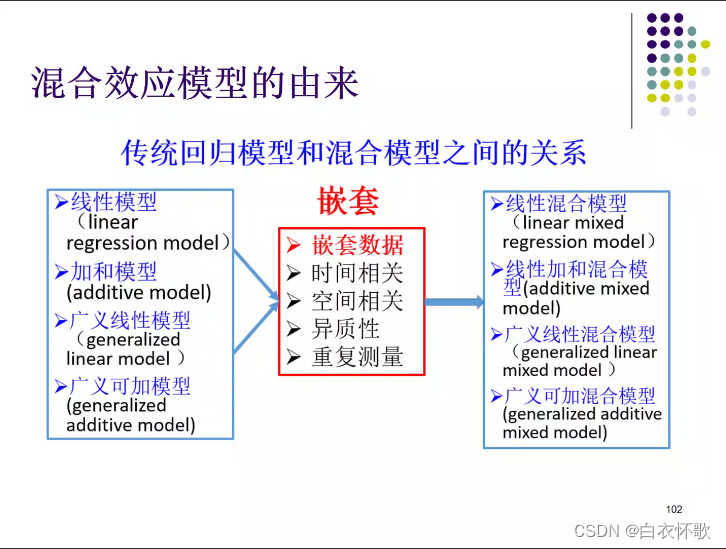
混合,包括固定效应和随机效应 (随机效应解决自相关问题)
嵌套、假重复
时间自相关(重复测量):施肥,不同月份测株高;不同批次
空间自相关:某一地区很多样点
e.g. 降水对生物量 距离越接近,植被物种越接近,甘南这一块不仅降水丰富,物种也丰富,出现正相关。——并不是降水导致了生物量增加,而是空间自相关导致两者之间出现相关
应该——改变降水(降水梯度),比较生物量的相关关系
又如,村庄里面的牛数量和村庄新生小孩数量——暗含村庄规模,规模越大,牛越多,孩子新生也多。相关不代表二者之间存在因果关系。

系统发育自相关:e.g. 增温是否会对不同草的株高产生影响——内蒙显著影响,西藏高原不显著
可能原因,内蒙的禾草居多响应增温
系统发育矩阵,来降低系统发育相近物种的比重(三个禾本科、一个菊科、一个豆科)
第二节课(2022.11.5)

固定效应
(1)我们感兴趣的
(2)这个如何影响因变量y,我们感兴趣
(3)科学问题感兴趣
(4)可以量化,这个效应值

随机效应
(1)标签具有可交换性(A,B,C,D) 字符型而不是数字型 1,2,3数字型导入时必须as.factor转换为A,B,C
(2)不感兴趣效应值,影响方向,但不得不考虑 对因变量y产生影响,须扣除


探究相对海拔高度(NAP)【自变量】与物种丰富度(Richness)【因变量】之间的关系
随机效应【9个site,每个地点5个样点】的Beach
常规解法
(1)complete pooling全部放一起进行线性回归——拟合出来斜率为负(下图)

问题:较多离群点,方差不齐 不能说出9个沙滩的情况
(2)No pooling9个地方各自线性回归
问题:每个沙滩的R2比较高,效果比较好,但是拟合出来的线差异较大(斜率、截距)

利用混合效应模型解决:

同一个site的5个点
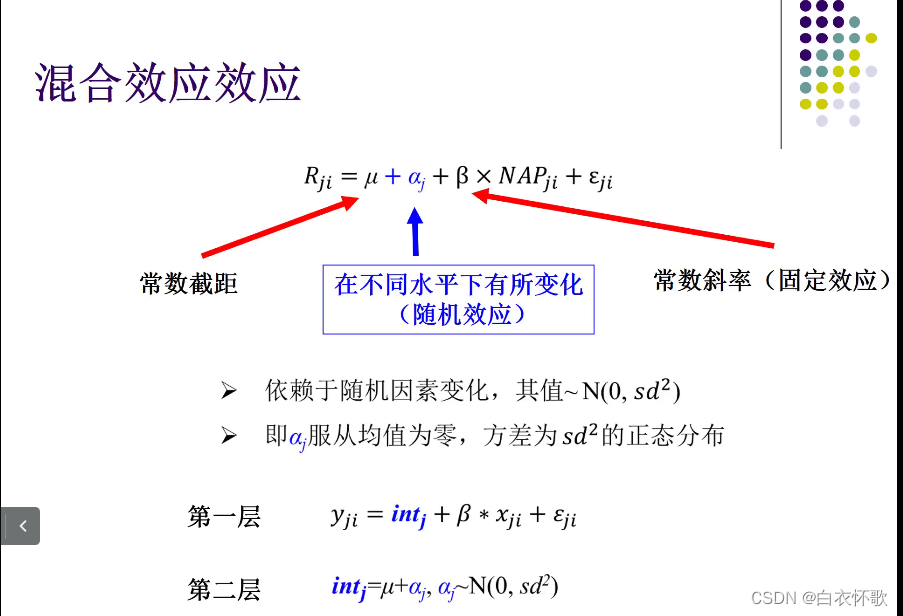
设置随机截距,公式如上,αj为调整项
第一层,传统线性回归格式
第二层,对于截距来说,总体截距μ,再给予一个校正值αj,每个沙滩各有一个,每个沙滩都形成一个不同的截距
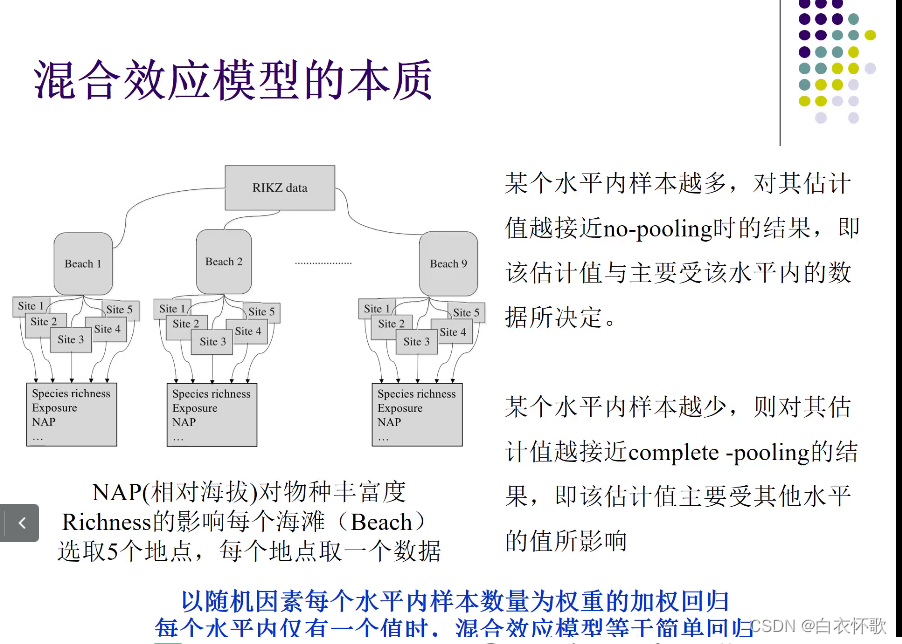
每个沙滩组内,样本量越多,估计的斜率截距值就越接近自身结果
截距介于No-pooling(样本点较多)和complete pooling(样本点较少)之间
常用随机截距模型


小的嵌套于大的https://mp.weixin.qq.com/s/2D1PAx9C9ctKk0hJ1Nlm7w
m2<lmer(Richness~1|fBeach),data=RIKZ)

限制性似然最大标准值(REML criterion at convergence) 239.5
ε残差(Scaled residuals)分布特征 点到拟合出来的颜色相同的线的垂线段最大,最小,方差
(Fixed efffects)固定效应
截距/斜率估计值分别为 6.5819和-2.5684 与0是否有显著差异
海拔0,随海拔生物量变化是否显著
自由度是小数,,限制性最大似然法本来得出的自由度就是小数

μ总体截距6.48
β总体斜率-2.56
αj,每个沙滩相对于整体的调整值,9个沙滩出现9个调整值
求出9个准确的各自沙滩的截距值
误差ε,不关注,但可以得到参数值,符合均值为0,有确定方差的正态分布

随机截距,拟合出来就是9条平行线——斜率固定为总体斜率,但截距存在调整
黑线即为拟合出来的总体的线,共享斜率 -2.568
左列各自截距,右侧各自斜率

随机斜率模型——物种丰富度不同,各自沙滩丰富度随海拔也在变化
两者之间存在交互效应,就需要随机斜率——随着海拔增加,物种丰富度变化,而这种变化依赖于沙滩
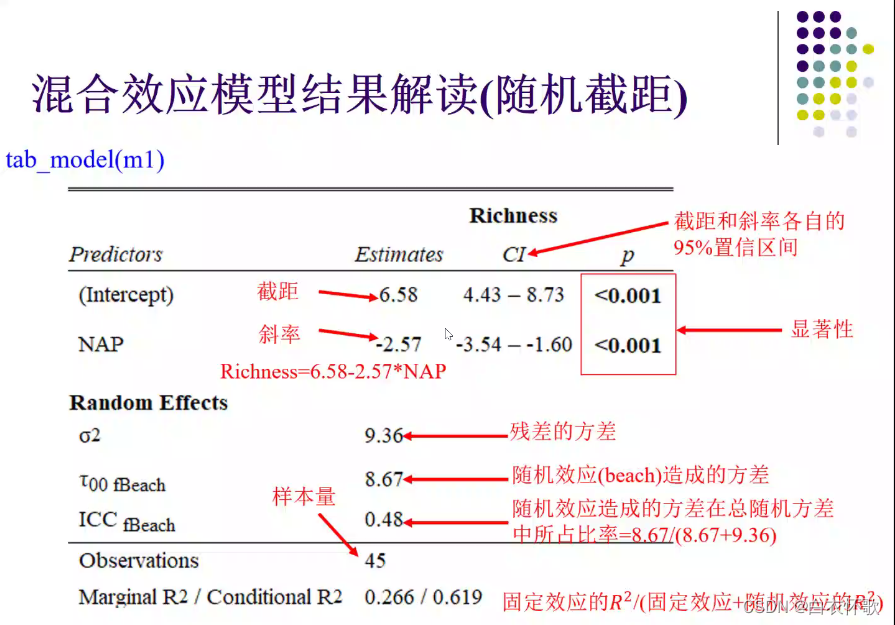
tab_model得出拟合的表格
95%置信区间和0没有交点,结果显著性好

13年日本人Nakagawa给出求解R2的方式
使用函数MuMIn,得出比较关注的固定效应的R2m
R2c肯定大于R2m,因为它是两部分的加和(固定+随机)

下侧
model1 考虑两个随机 species和plot
model0 只考虑plot
anova分析,AIC差异显著则需要考虑species,增加拟合优度

!只有装了lmerTest函数才会对固定效应给予方差分析,得出P值

随机斜率和截距模型
随机效应(不同组)和固定效应(NAP)影响y的时候存在交互
m2<lmer(Richness~NAP|fBeach),data=RIKZ)


截距大的,斜率越负,向左侧汇聚

R2m=0.295,R2c=0.728 70%可以解释这个变化,已经可以了。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









