







目录
介绍:
广告点击量的好处:
(1)获得高点击率后就可以收取一部分广告收入,当然你的内容粘性越大,广告收入越高;
(2)商业网站更重要的是能够获得信息资产;
(3)获取无形资产:网站知名度,客户资料,客户数据。
注:可以获得客户资料和数据,分析客户的需求,进行定制性服务,让客户更满意;
通过分析,平台可以增加内容与服务,更改结构和工作流程。
数据准备
数据格式:
2022-5-3-22:19:30 浙江 城市6 大笨蛋 广告1
时间、省份、城市、用户、广告 中间字段使用空格分隔。
模拟数据生成
代码如下:
import java.io.{File, PrintWriter}
object DataGet {
def main(args: Array[String]): Unit = {
Data(6000)
}
def Data(n:Int):Unit ={
var sb:StringBuilder = new StringBuilder
for (i <- 1 to n){
sb.append(time + "-" + timeStamp())
sb.append(" ")
sb.append(province())
sb.append(" ")
sb.append(city())
sb.append(" ")
sb.append(user())
sb.append(" ")
sb.append(ADV())
if (i <= n - 1) {
sb.append("\n")
}
}
writeToFile(sb.toString())
}
def province(): String = {
val name = Array(
"北京","上海","贵州","河南","湖北","河北","云南","四川","浙江","江苏"
)
val s = (Math.random() * (9) + 0).toInt
name(s)
}
def city(): String = {
val cityname = Array(
"城市1","城市2","城市3","城市4","城市5","城市6","城市7"
)
val s = (Math.random() * (6) + 0).toInt
cityname(s)
}
def ADV(): String = {
val ADVname = Array(
"广告1","广告2","广告3","广告4","广告5","广告6","广告7","广告8"
)
val s = (Math.random() * (7) + 0).toInt
ADVname(s)
}
def user(): String = {
val name = Array(
"张三","李四","王二","麻子","大笨蛋","小调皮","小乖乖","小机灵"
)
val s = (Math.random() * (8) + 0).toInt
name(s)
}
def time(): String = {
var year: Int = (2022).toInt
var month: Int = (Math.random() * (12 - 1 + 1) + 1).toInt
var day: Int = (Math.random() * (31 - 1 + 1) + 1).toInt
year + "-" + month + "-" + day
}
def timeStamp(): String = {
var hour = (Math.random() * (24 - 1 + 1) + 1).toInt
var m = (Math.random() * (60 - 1 + 1) + 1).toInt
var second = (Math.random() * (60 - 1 + 1) + 1).toInt
hour + ":" + m + ":" + second
}
def writeToFile(str: String): Unit = {
val printWriter = new PrintWriter(new File("E:\\AllProject\\sparklearn\\datas\\testlog.log"))
printWriter.write(str)
printWriter.flush()
printWriter.close()
}
}需求描述&流程
统计每个省份每个广告被点击数排行的Top5。
如下图,作者懒,不想做文字解释。
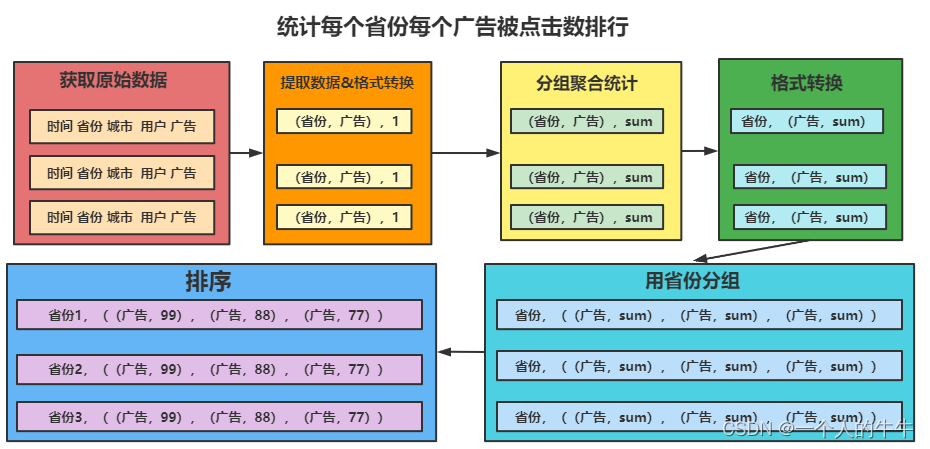
功能实现
代码如下:
import org.apache.spark.{SparkConf, SparkContext}
object case1 {
def main(args: Array[String]): Unit = {
//TODO 创建环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
//TODO 案例分析 统计出每个省份每个广告被点击数量排行的Top5
//1.获取原始数据:时间、省份、城市、用户、广告
val rdd = sc.textFile("datas/testlog.log")
//2.提取需要的数据,进行格式转换
val mapRDD = rdd.map(
line => {
val datas = line.split(" ")
((datas(1), datas(4)), 1)
}
)
//3.分组聚合
val reduceRDD = mapRDD.reduceByKey(_ + _)
//4.结果的格式转换
val newRDD = reduceRDD.map {
case (
(province, adv), sum) => {
(province, (adv, sum))
}
}
//5.用省份分组
val groupRDD = newRDD.groupByKey()
//6.排序
val resultRDD = groupRDD.mapValues(
iter => {
iter.toList.sortBy(_._2)(Ordering.Int.reverse).take(5)
}
)
//7.打印
resultRDD.collect().foreach(println)
//TODO 关闭环境
sc.stop()
}
}结果如下:
















 1899
1899











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









