







目录
⑦UserService接口及实现UserServiceImpl
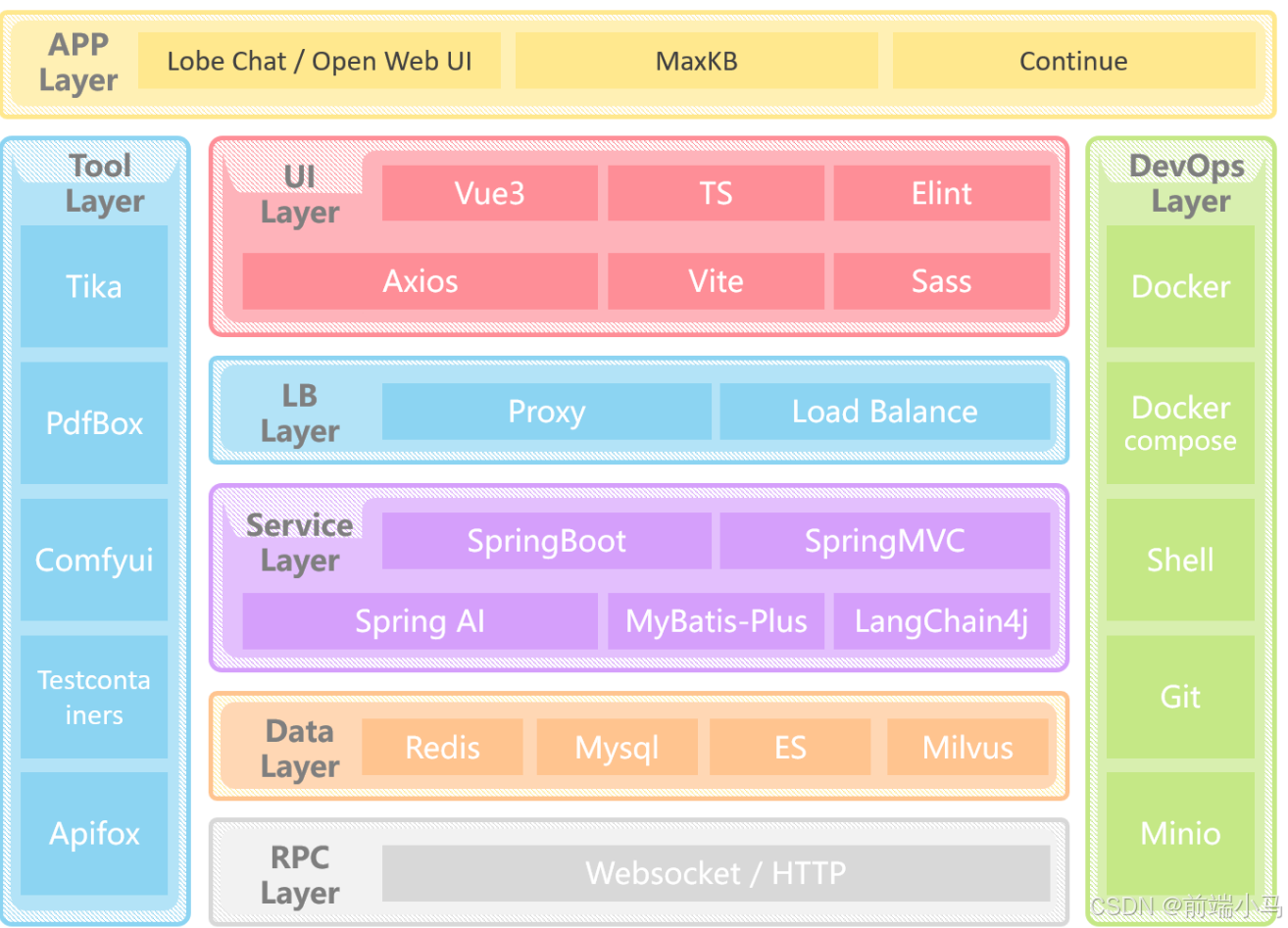
一. 技术架构
课程中用到的技术可以分为8层:
应用层(APP Layer): 直接使用成熟的开源工具LobeChat,MaxKB,Continue等来快速搭建用户可视化操作界面
界面层(UI Layer):项目中所有前端界面都采用Vue3相关技术栈进行开发
负载层(LB Layer):负载通过Nginx来实现反向代理和负载均衡
服务层(Service Layer):通过Spring Boot来快速构建项目,然后通过SpringAI / LangChain4j来实现相关AI功能的的开发
工具层(Tool Layer):AI软件开发过程中会用到很对外置工具,用来对AI内容进行前后置处理,比如通过TIke、PdfBox来ELT清洗文档数据,然后传入AI对话
数据层(Data Layer):课程中使用Redis和ES、Mysql来存储或缓存关系数据,而使用Milvus来存储AI向量相关的内容
运维层(DevOps Layer):课程中全面使用Docker来构建开发环境
二. 导入虚拟机
为便于后续的知识学习,本项目的开发环境部署到了CentOS7系统,因此先安装一下开发环境。
为了快速、方便的统一开发环境,在资料中提供了一套系统镜像,使用VMware软件来挂载即可快速启动。
在当前linux系统中包含的开发环境有:
Mysql:开发环境的数据库
Redis:开发环境的redis
Docker:开发环境的部署工具
nginx :代理服务
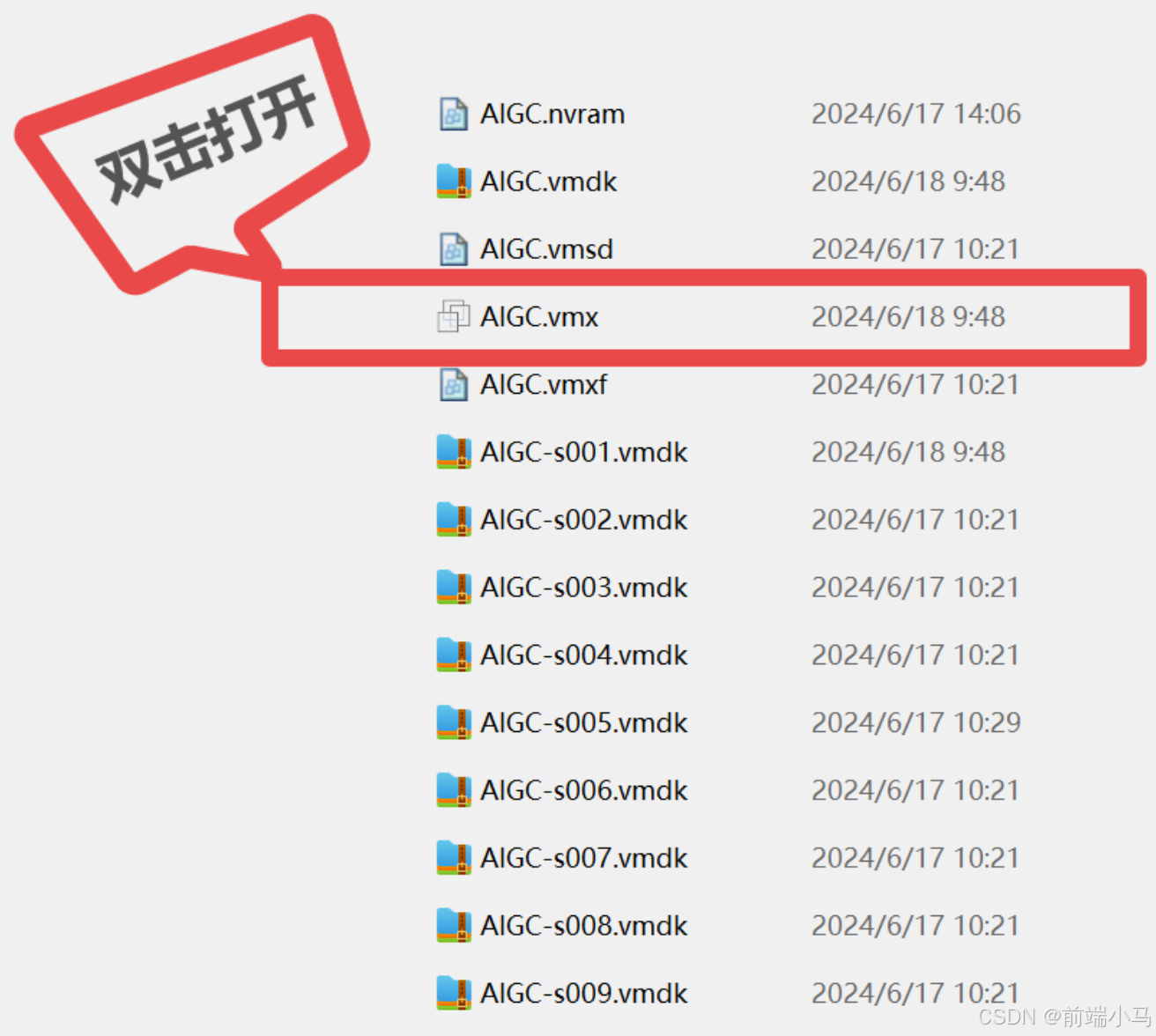
1. 挂载虚拟机:
解压《JavaAIGC虚拟机.zip》文件,解压后,进入解压的虚拟机镜像文件夹,双击
AIGC.vmx即可挂载到虚拟机中(需提前安装虚拟机)。
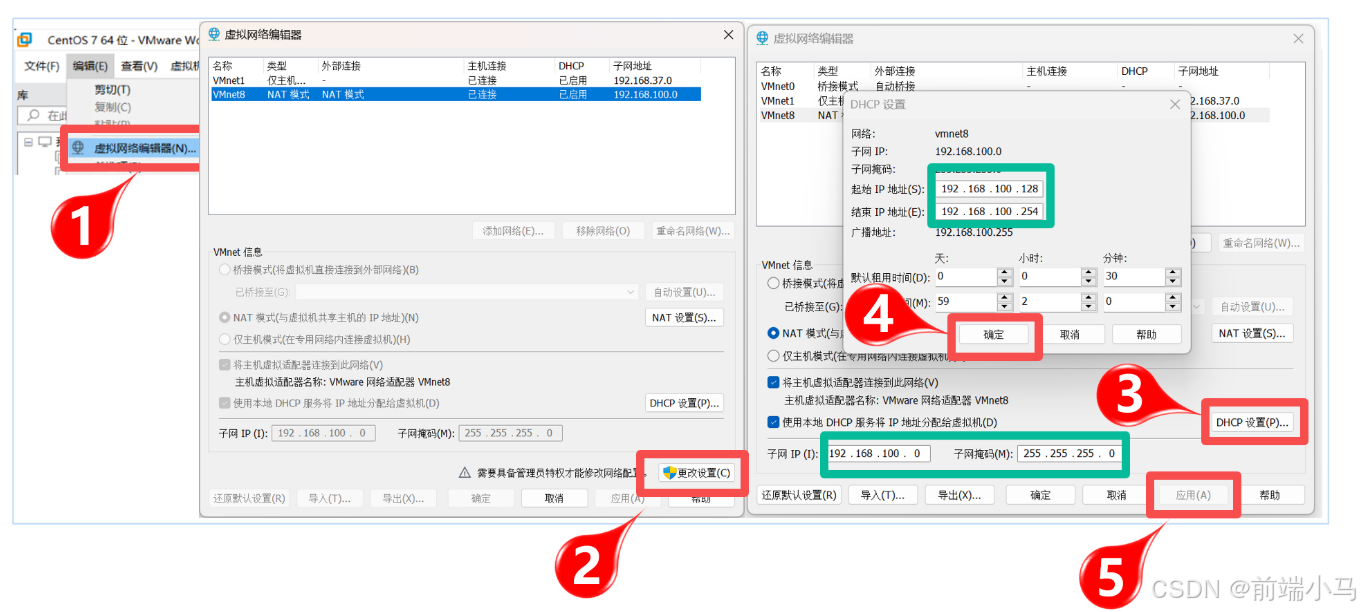
2. 设置虚拟网络:
因为此虚拟机已设置静态的ip地址,目前网段就是192.168.100.0,所以为了减少环境网络
的配置,可以手动设置虚拟机中NAT网卡的网段
设置步骤:
①:找到虚拟机的编辑按钮,打开
虚拟网络编辑器②:选中NAT模式的网卡,在下面的子网IP的输入框中手动设置为:
192.168.100.0,确定保存即可
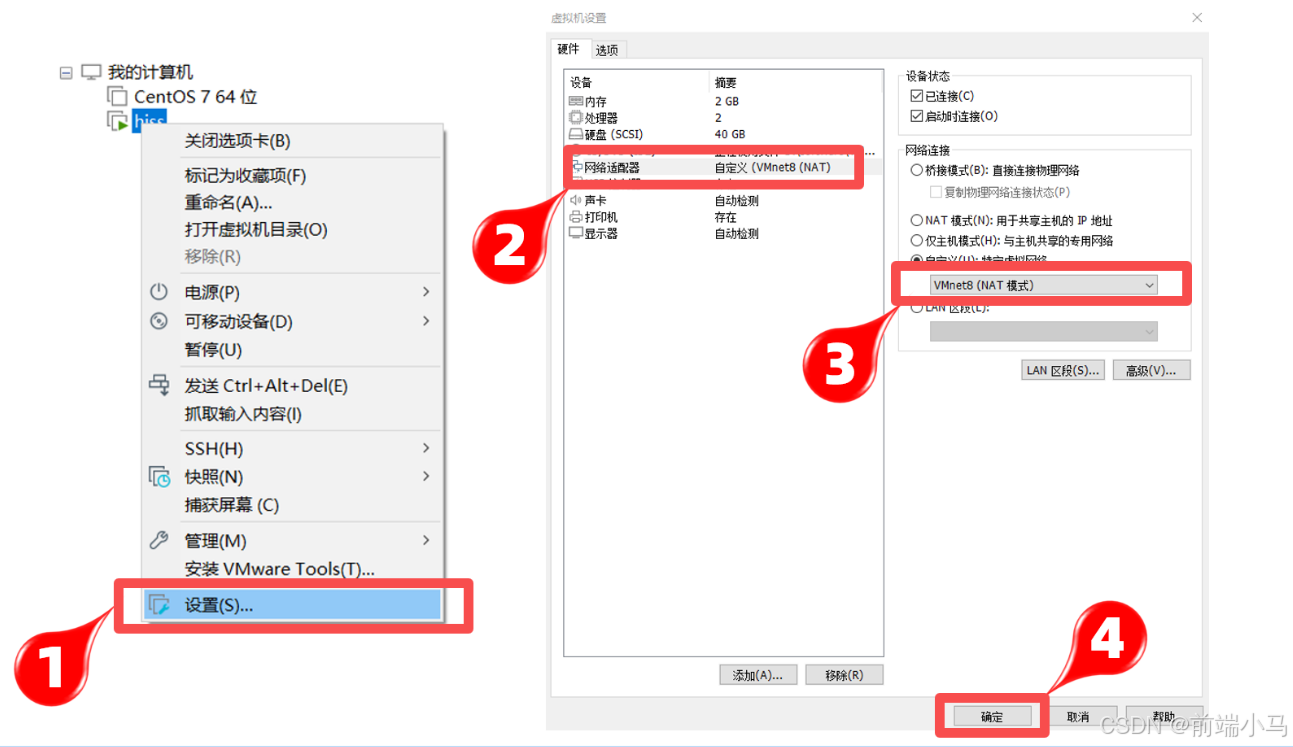
③:右键虚拟机-->设置-->网络适配器-->自定义:选择NAT网卡连接模式
④:启动服务器(网络设置完成后再启动服务器)
3. FinalShell客户端链接
此虚拟机的静态ip为:192.168.100.129,防火墙已关闭,可以直接使用客户端链接
以FinalSehll工具为例:
注意:此虚拟机的用户名:root,密码:itcast
4. 内置环境说明
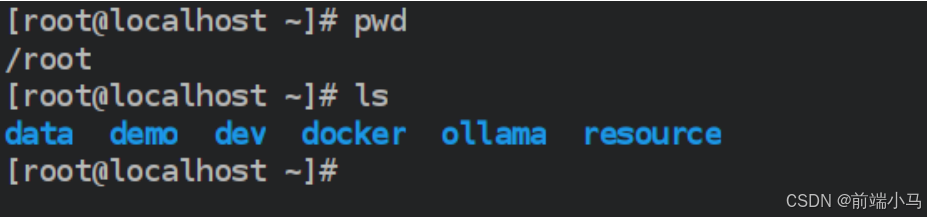
在虚拟机中/root目录中内置了两套环境:
data是数据库、代码仓库等重要数据,千万勿删!!
demo是整体项目演示的环境,方便大家快速启动查看项目效果,可选择删除。
dev是开环境的环境,本课程学习过程需要用到的环境,千万勿删!!
docker是后续学习过程中用到的系列镜像文件,千万勿删!!
ollama是后续学习本地大模型的存储文件,千万勿删!!
resource是后续用到的系列软件资源,千万勿删!!
三. 私有大模型
1. 为什么要有私有大模型?
随着AI技术的不断普及,人们也积极拥抱其带来的变化,在生活或者工作中亦使用AI技术来帮助我们更高效的完成某些事件,但是在这个过程中,也暴露出AI技术当前下存在在的系列问题,其中最严重的就是安全问题,比如:最典型的是三星员工使用ChatGPT泄露公司机密的案例。
其实上述案例表现的就是企业数据隐私与安全的问题,在许多行业,如金融、医疗、政府等,数据隐私和安全是至关重要的。使用公共大模型可能涉及敏感数据的泄露风险,因为公共模型在训练过程中可能接触到了来自不同来源的敏感数据。因此就有了私有大模型的市场需求,私有大模型允许企业或机构在自己的数据上训练模型,而且训练的结果只供内部或合作伙伴使用,从而确保了数据隐私和安全。
当然除了数据隐私问题原因之外,还存有便于内部员工工作提效、大模型开发的投入等诸多原因综合,直接推动私有大模型成为未来AI发展的新方向之一。
2. 私有大模型解决方案
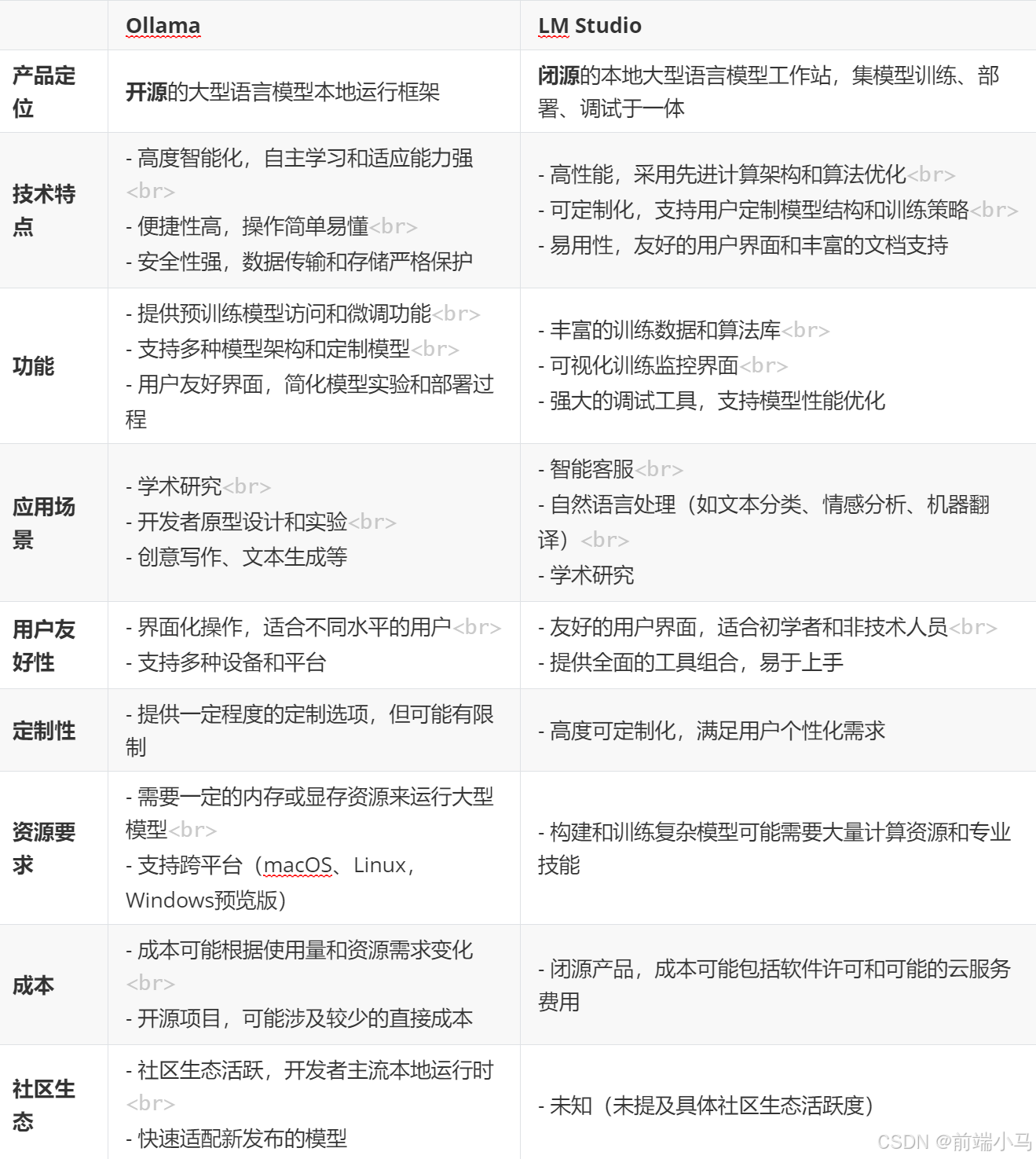
随着AI的发展,越来越多的开发者投入到大模型开发中,他们期望能自身笔记本上运行大模型,以便开发。越来越多的企业积极改造自身产品,融入AI技术,他们期望能私有化大模型以保证数据安全。这些诉求直接推动社区出现了两个这方面的产品Ollama和LMstudio。
这两个产品各有优势:
Ollama 作为一个开源的轻量级工具,适合熟悉命令行界面的开发人员和高级用户进行模型实验和微调。它提供了广泛的预训练模型和灵活的定制选项,同时保持了高度的便捷性和安全性。最重要它是开源的,同时还提供API,对于开发有先天优势,因此在企业中备受欢迎和使用
四.Ollama 入门
1. 什么是Ollama?
Ollama:是一款旨在简化大型语言模型本地部署和运行过程的开源软件。
中文名:羊驼
网址:Ollama
Ollama提供了一个轻量级、易于扩展的框架,让开发者能够在本地机器上轻松构建和管理LLMs(大型语言模型)。通过Ollama,开发者可以访问和运行一系列预构建的模型,或者导入和定制自己的模型,无需关注复杂的底层实现细节。
Ollama的主要功能包括快速部署和运行各种大语言模型,如Llama 2、Code Llama等。它还支持从GGUF、PyTorch或Safetensors格式导入自定义模型,并提供了丰富的API和CLI命令行工具,方便开发者进行高级定制和应用开发。
特点:
一站式管理:Ollama将模型权重、配置和数据捆绑到一个包中,定义成Modelfile,从而优化了设置和配置细节,包括GPU使用情况。这种封装方式使得用户无需关注底层实现细节,即可快速部署和运行复杂的大语言模型。
热加载模型文件:支持热加载模型文件,无需重新启动即可切换不同的模型,这不仅提高了灵活性,还显著增强了用户体验。
丰富的模型库:提供多种预构建的模型,如Llama 2、Llama 3、通义千问等,方便用户快速在本地运行大型语言模型。
多平台支持:支持多种操作系统,包括Mac、Windows和Linux,确保了广泛的可用性和灵活性。
无复杂依赖:通过优化推理代码并减少不必要的依赖,Ollama能够在各种硬件上高效运行,包括纯CPU推理和Apple Silicon架构。
资源占用少:Ollama的代码简洁明了,运行时占用资源少,使其能够在本地高效运行,不需要大量的计算资源。
2. 下载安装Ollama
手动安装:
Ollama共支持三种平台:
window和mac版本直接下载安装或解压即可使用。这里由于Ollama需要安装在linux中,因此在这里主要学习如何在Linux上安装:
Step 1. 安装
在虚拟机/root/resource目录中已经下载好Linux版本所需的ollama-linux-amd64.tgz文件, 则执行下面命令开始安装: tar -C /usr -xzf ollama-linux-amd64.tgz 操作成功之后,可以通过查看版本指令来验证是否安装成功 [root@bogon resource]# ollama -v Warning: could not connect to a running Ollama instance Warning: client version is 0.3.9Step 2. 添加开启自启服务
创建服务文件/etc/systemd/system/ollama.service: touch /etc/systemd/system/ollama.service 并写入文件内容(vi /etc/systemd/system/ollama.service): [Unit] Description=Ollama Service After=network-online.target [Service] ExecStart=/usr/bin/ollama serve User=root Group=root Restart=always RestartSec=3 [Install] WantedBy=default.target生效服务:
systemctl daemon-reload systemctl enable ollama启动服务:
sudo systemctl start ollama 停止服务: sudo systemctl stop ollama 重启服务: sudo systemctl restart ollama 开机自启: sudo systemctl enable ollama 取消开机自启: sudo systemctl disable ollama一键安装:
Ollama在Linux上也提供了简便的安装命令,但是过程中需要下载400M左右的数据,比较慢,因此课堂上采用第一种方式安装,但在工作中一般采用下面命令进行安装:
curl -fsSL https://ollama.com/install.sh | sh
3. 运行通义千问大模型
通义千问(Qwen)是阿里巴巴集团Qwen团队研发的大语言模型和大型多模态模型系列。Qwen具备自然语言理解、文本生成、视觉理解、音频理解、工具使用、角色扮演、作为AI Agent进行互动等多种能力。
官网:Qwen
在终端输入一下命令即可运行通义千问大模型:
命令解释:
为运行一个本地大模型的命令,这个命令的格式为:ollama run 模型名称:模型规模 如果首次运行,本地没有大模型则会从远程下载大模型 运行成功模型之后,通过终端进行对话聊天修改模型路径:
直接运行上述小节命令,会下载300多M的数据,比较慢,而在虚拟机中已经提前下载好了相关模型(包括后续用到的模型),存储在/root/ollama目录中,因此这里我们需要修改ollama的模型路径,ollama软件在各个操作系统上的默认存储路径是:
macOS: ~/.ollama/models Linux: ~/.ollama/models Windows: ~/.ollama/models要修改其默认存储路径,需要通过设置系统环境变量来实现,即在/etc/profile文件中最后增加一下环境变量:
export OLLAMA_MODELS=/root/ollama然后执行一下命令,生效环境变量:
[root@bogon ollama]# source /etc/profile [root@bogon ollama]# echo $OLLAMA_MODELS /root/ollama [root@bogon ollama]#然后重新ollama服务,则会跳过下载,直接进入大模型,对话完成后可以通过/bye指令终止对话:
[root@bogon ollama]# systemctl stop ollama [root@bogon ollama]# ollama serve & [root@bogon ~]# ollama run qwen2:0.5b >>> 您好 很高兴为您服务!有什么问题或需要帮助的吗? >>> /bye [root@bogon ~]#让重启也支持模型路径:
上述方式修改后,通过ollama命令是生效的,但是重启电脑则不生效,要解决这个问题, 则还需要进行如下配置: 修改服务文件/etc/systemd/system/ollama.service内容为一下: [Unit] Description=Ollama Service After=network-online.target [Service] ExecStart=/usr/bin/ollama serve User=root Group=root Restart=always RestartSec=3 Environment="OLLAMA_MODELS=/root/ollama" [Install] WantedBy=default.target 生效修改的配置: systemctl daemon-reload systemctl restart ollama
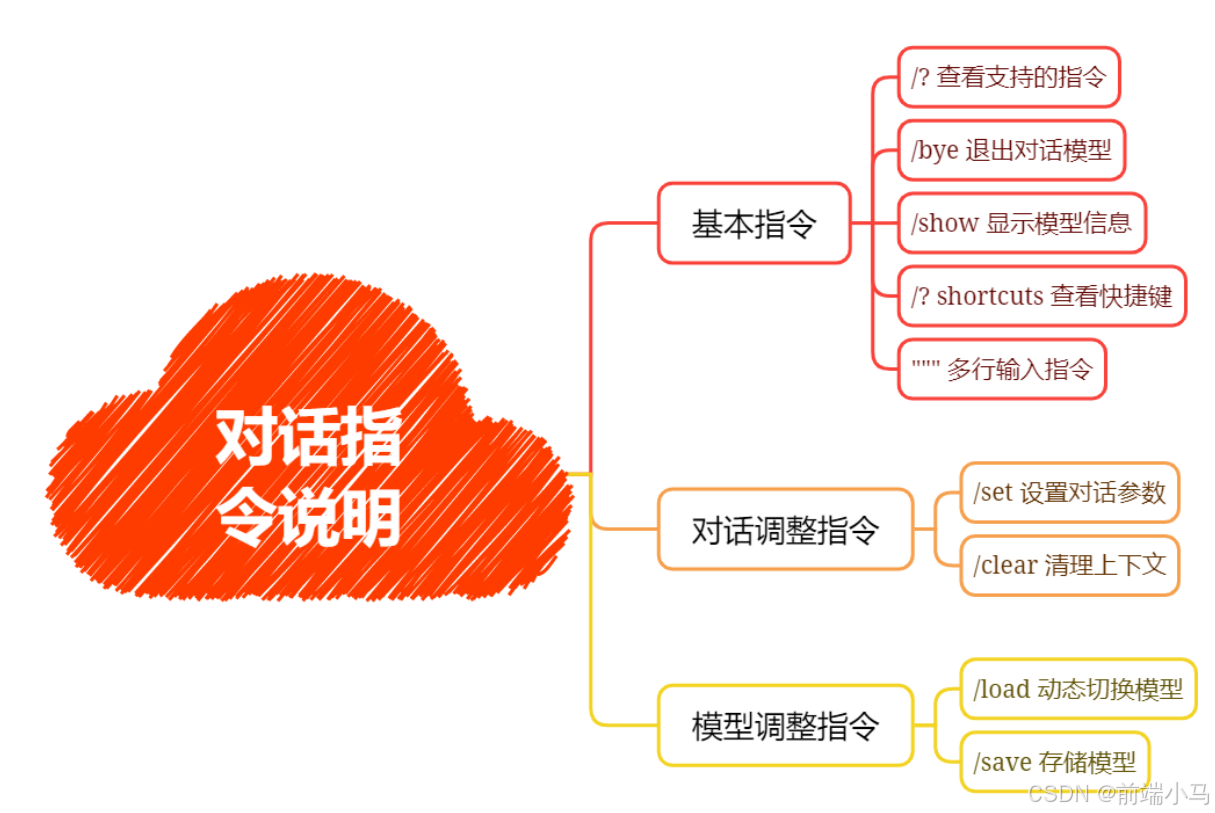
4. 对话指令详解
在Ollama终端中提供了一系列指令,可以用来调整和控制对话模型:
(1)/? 指令
/? 指令主要是列出支持的指令列表
[root@bogon ~]# ollama run qwen2:0.5b
>>> /?
Available Commands:
/set Set session variables
/show Show model information
/load <model> Load a session or model
/save <model> Save your current session
/clear Clear session context
/bye Exit
/?, /help Help for a command
/? shortcuts Help for keyboard shortcuts
Use """ to begin a multi-line message.(2) /bye 指令
退出当前控制台对话
[root@bogon ~]# ollama run qwen2:0.5b
>>> 您好
你好!有什么可以帮助您的吗?
>>> /bye
[root@bogon ~]# (3) /show 指令
用于查看当前模型详细信息
-----------------------------------------------------------------------
[root@bogon ~]# ollama run qwen2:0.5b
>>> /show
Available Commands:
/show info 查看模型的基本信息
/show license 查看模型的许可信息
/show modelfile 查看模型的制作源文件Modelfile
/show parameters 查看模型的内置参数信息
/show system 查看模型的内置Sytem信息
/show template 查看模型的提示词模版
------------------------------------------------------------------------
/show info 查看模型的基本信息
>>> /show info
Model details:
Family qwen2 模型名称
Parameter Size 494.03M 模型大小
Quantization Level Q4_0 模型量化级别
------------------------------------------------------------------------
/show license 查看模型的许可信息—开源软件的许可协议
>>> /show license
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
............................................................
-------------------------------------------------------------------------
/show modelfile 查看模型的制作源文件Modelfile
modelfile :文件是用来制作私有模型的脚步文件,后续课程学习
>>> /show modelfile
# Modelfile generated by "ollama show"
# To build a new Modelfile based on this, replace FROM with:
# FROM qwen2:0.5b
FROM /root/ollama/blobs/sha256-8de95da68dc485c0889c205384c24642f83ca18d089559c977ffc6a3972a71a8
TEMPLATE "{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
{{ .Response }}<|im_end|>
"
PARAMETER stop <|im_start|>
PARAMETER stop <|im_end|>
LICENSE """
......................................................................
---------------------------------------------------------------------------
/show parameters 查看模型的内置参数信息
>>> /show parameters
Model defined parameters:
stop "<|im_start|>"
stop "<|im_end|>"
---------------------------------------------------------------------------
/show system 查看模型的内置system信息—system常常用来定一些对话角色扮演
>>> /show system
No system message was specified for this model.
---------------------------------------------------------------------------
/show template 查看模型的提示词模版
template:是最终传入大模型的字符串模版,模版中的内容由上层应用动态传入
>>> /show template
{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
{{ .Response }}<|im_end|>
----------------------------------------------------------------------------
(4)/? shortcuts 指令
查看在控制台中可用的快捷键
>>> /? shortcuts
Available keyboard shortcuts:
Ctrl + a 移动到行头
Ctrl + e 移动到行尾
Alt + b 移动到单词左边
Alt + f 移动到单词右边
Ctrl + k 删除游标后面的内容
Ctrl + u 删除游标前面的内容
Ctrl + w 删除游标前面的单词
Ctrl + l 清屏
Ctrl + c 停止推理输出
Ctrl + d 退出对话(只有在没有输入时才生效)(5)""" 指令
""" 用于输入内容有换行时使用,如何多行输入结束也使用 """
>>> """
... 您好
... 你是什么模型?
... """
我是一个计算机程序,可以回答您的问题、提供信息和执行任务。请问您有什么问题或者指令想要我帮助您?(6)/set 指令
set指令主要用来设置当前对话模型的系列参数
>>> /set
Available Commands:
/set parameter ... 设置对话参数
/set system <string> 设置系统角色
/set template <string> 设置推理模版
/set history 开启对话历史
/set nohistory 关闭对话历史
/set wordwrap 开启自动换行
/set nowordwrap 关闭自动换行
/set format json 输出JSON格式
/set noformat 关闭格式输出
/set verbose 开启对话统计日志
/set quiet 关闭对话统计日志
/set parameter ... 设置对话参数
>>> /set parameter
Available Parameters:
/set parameter seed <int> Random number seed
/set parameter num_predict <int> Max number of tokens to predict
/set parameter top_k <int> Pick from top k num of tokens
/set parameter top_p <float> Pick token based on sum of probabilities
/set parameter num_ctx <int> Set the context size
/set parameter temperature <float> Set creativity level
/set parameter repeat_penalty <float> How strongly to penalize repetitions
/set parameter repeat_last_n <int> Set how far back to look for repetitions
/set parameter num_gpu <int> The number of layers to send to the GPU
/set parameter stop <string> <string> ... Set the stop parameters| Parameter | Description | Value Type | Example Usage |
|---|---|---|---|
| num_ctx | 设置上下文token大小. (默认: 2048) | int | num_ctx 4096 |
| repeat_last_n | 设置模型要回顾的距离以防止重复. (默认: 64, 0 = 禁用, -1 = num_ctx) | int | repeat_last_n 64 |
| repeat_penalty | 设置惩罚重复的强度。较高的值(例如,1.5)将更强烈地惩罚重复,而较低值(例如,0.9)会更加宽容。(默认值:1.1) | float | repeat_penalty 1.1 |
| temperature | 模型的温度。提高温度将使模型的答案更有创造性。(默认值:0.8) | float | temperature 0.7 |
| seed | 设置用于生成的随机数种子。将其设置为特定的数字将使模型为相同的提示生成相同的文本。(默认值:0) | int | seed 42 |
| stop | 设置停止词。当遇到这种词时,LLM将停止生成文本并返回 | string | stop "AI assistant:" |
| num_predict | 生成文本时要预测的最大标记数。(默认值:128,-1 =无限生成,-2 =填充上下文) | int | num_predict 42 |
| top_k | 减少产生无意义的可能性。较高的值(例如100)将给出更多样化的答案,而较低的值(例如10)将更加保守。(默认值:40) | int | top_k 40 |
| top_p | 与Top-K合作。较高的值(例如,0.95)将导致更多样化的文本,而较低的值(例如,0.5)将产生更集中和保守的文本。(默认值:0.9) | float | top_p 0.9 |
| num_gpu | 设置缓存到GPU显存中的模型层数 | int | 自动计算 |
JSON格式输出
>>> /set format json
Set format to 'json' mode.
>>> 您好
{"response":"你好,欢迎光临,请问有什么我可以帮助您的吗?"}
>>> /set noformat
Disabled format.
>>> 您好
Hello! How can I assist you?输出对话统计日志
>>> /set verbose
Set 'verbose' mode.
>>> 您好
您好!我需要您的信息,以便回答您的问题。请问您能告诉我更多关于这个主题的信息吗?
total duration: 1.642906162s 总耗时
load duration: 3.401367ms 加载模型数据耗时
prompt eval count: 11 token(s) 提示词token消耗数量
prompt eval duration: 196.52ms 提示词处理耗时
prompt eval rate: 55.97 tokens/s 提示词处理速率
eval count: 24 token(s) 响应token消耗数量
eval duration: 1.304188s 响应处理耗时
eval rate: 18.40 tokens/s 响应处理速率(7)/clear 指令
在命令行终端中对话是自带上下文记忆功能,如果要清除上下文功能,
则使用/clear指令清楚上下文内容,例如:前2个问题都关联的,
在输入/clear则把前2个问题的内容给清理掉了,第3次提问时则找不到开始的上下文了。
>>> 请帮我出1道java list的单选题
以下是一些关于Java List的单选题:
1. 在Java中,List是哪一种数据结构?
2. Java中的顺序存储方式(例如:使用数组)主要用来做什么?
3. 一个列表对象可以包含哪些类型的元素?
>>> 再出1道
以下是一些关于Java List的单选题:
4. 在Java中,List接口用于创建和操作集合。
5. Java中的顺序存储方式(如:使用数组)的主要优势有哪些?
6. 一个列表对象可以包含哪些类型?
>>> /clear
Cleared session context
>>> 在出1道
很抱歉,我无法理解您的问题。您能否提供更多的背景信息或者问题描述,以便我能更好地帮助您?(8)/load 指令
load可以在对话过程中随时切换大模型
>>> 你是什么大模型
我是一个基于开放AI平台的模型,拥有一个强大的数学推理能力,并且在各种自然语言处理任务上都表现
优秀。我可以回答您提出的问题,也可以提供与主题相关的信息和建议。如果您有任何问题或需要帮助,
请随时告诉我!
>>> /load deepseek-coder
Loading model 'deepseek-coder'
>>> 你是什么大模型
我是由中国的深度求索(DeepSeek)公司开发的编程智能助手,名为 Deepseek Coder。
我主要用于解答和协助计算机科学相关的问题、问题解决方案等任务。我的设计目标是提供
最全面准确的高质量服务来帮助用户理解复杂的新技术或概念并迅速找到它们在实际应用中的
实现方法或者原理所在的地方。(9)/save 指令
可以把当前对话模型存储成一个新的模型
>>> /save test
Created new model 'test'
保存的模型存储在ollama的model文件中,进入下面路径即可看见模型文件test:
[root@bogon library]# pwd
/root/ollama/manifests/registry.ollama.ai/library
[root@bogon library]# ls
deepseek-coder qwen2 test5. 客户端命令详解
Ollama客户端还提供了系列命令,来管理本地大模型,接下来就先了解一下相关命令:
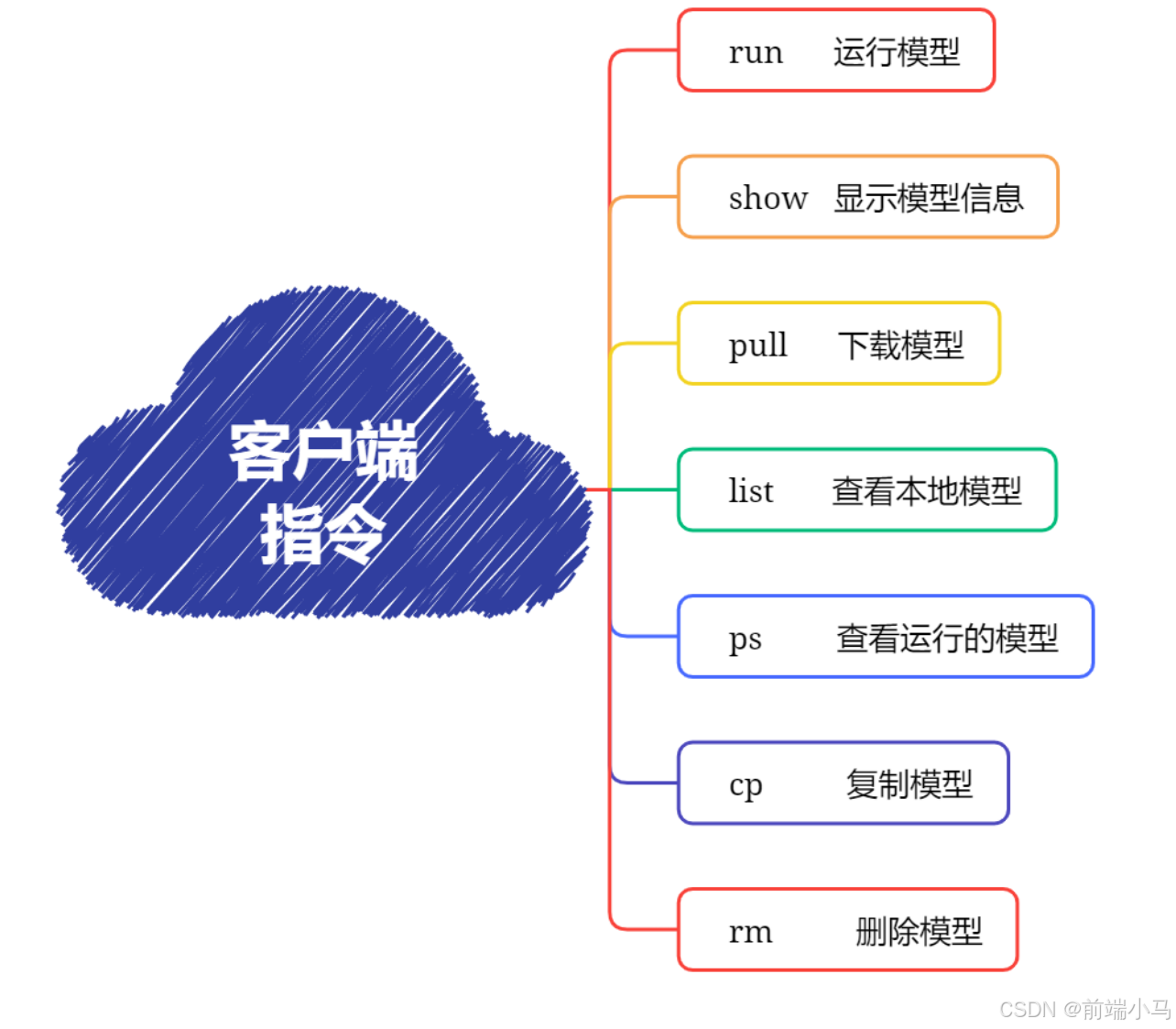
(1) run 命令
run命令主要用于运行一个大模型,命令格式是:
ollama run MODEL[:Version] [PROMPT] [flags] 比如,运行通义千问命令: ollama run qwen2:0.5b[:Version] 可以理解成版本,而版本信息常常以大模型规模来命名,可以不写,不写则默认为latest
ollama run qwen2 等同 ollama run qwen2:latest[PROMPT] 参数是用户输入的提示词,如果带有此参数则,run命令会执行了输入提示词之后即退出终端,即只对话一次。
[root@bogon ~]# ollama run qwen2:0.5b 您好 您好!有什么问题我可以帮助您? [root@bogon ~]#[flags] 指定运行时的参数
Flags: --format string 指定运行的模型输出格式 (比如. json) --insecure 使用非安全模,比如在下载模型时会忽略https的安全证书 --keepalive string 指定模型在内存中的存活时间 --nowordwrap 关闭单词自动换行功能 --verbose 开启统计日志信息例如,在启动时增加 --verbose参数,则在对话时,自动增加统计token信息:
[root@bogon ~]# ollama run qwen2:0.5b --verbose >>> 您好 欢迎光临,我可以为您提供帮助。有什么问题或需要帮助的地方? total duration: 1.229917477s load duration: 3.027073ms prompt eval count: 10 token(s) prompt eval duration: 167.181ms prompt eval rate: 59.82 tokens/s eval count: 16 token(s) eval duration: 928.995ms eval rate: 17.22 tokens/s
(2)show 命令
不用运行大模型,查看模型的信息,与之前所学的/show功能类似。
[root@bogon ~]# ollama show -h Show information for a model Usage: ollama show MODEL [flags] Flags: -h, --help 查看使用帮助 --license 查看模型的许可信息 --modelfile 查看模型的制作源文件Modelfile --parameters 查看模型的内置参数信息 --system 查看模型的内置Sytem信息 --template 查看模型的提示词模版例如,查看提示词模版:
[root@bogon ~]# ollama show qwen2 --template {{ if .System }}<|im_start|>system {{ .System }}<|im_end|> {{ end }}{{ if .Prompt }}<|im_start|>user {{ .Prompt }}<|im_end|> {{ end }}<|im_start|>assistant {{ .Response }}<|im_end|>
(3)pull 命令
查询模型名称的网站:Ollama
从远程下载一个模型,命令格式是:
ollama pull MODEL[:Version] [flags][:Version] 可以理解成版本,但在这里理解成大模型规模,可以不写,不写则模式成latest
ollama pull qwen2 等同 ollama pull qwen2:latest[flags] 参数,目前只有一个--insecure参数,用于来指定非安全模式下载数据
ollama pull qwen2 --insecure
(4) list/ls 命令
查看本地下载的大模型列表,也可以使用简写ls
[root@bogon ~]# ollama list NAME ID SIZE MODIFIED qwen2:latest e0d4e1163c58 4.4 GB 10 minutes ago deepseek-coder:latest 3ddd2d3fc8d2 776 MB 3 hours ago qwen2:0.5b 6f48b936a09f 352 MB 8 hours ago [root@bogon ~]# ollama ls NAME ID SIZE MODIFIED qwen2:latest e0d4e1163c58 4.4 GB 10 minutes ago deepseek-coder:latest 3ddd2d3fc8d2 776 MB 3 hours ago qwen2:0.5b 6f48b936a09f 352 MB 8 hours ago列表字段说明:
NAME:名称
ID:大模型唯一ID
SIZE:大模型大小
MODIFIED:本地存活时间
注意:在ollama的其它命令中,不能像docker一下使用ID或ID缩写,这里只能使用大模型全名称。
(5)ps 命令
查看当前运行的大模型列表,PS命令没其它参数
[root@bogon ~]# ollama ps NAME ID SIZE PROCESSOR UNTIL deepseek-coder:latest 3ddd2d3fc8d2 1.3 GB 100% CPU About a minute from now列表字段说明:
NAME:大模型名称
ID:唯一ID
SIZE:模型大小
PROCESSOR:资源占用
UNTIL:运行存活时长
(6) rm 命令
删除本地大模型,RM命令没其它参数
[root@localhost system]# ollama ls NAME ID SIZE MODIFIED qwen2:latest e0d4e1163c58 4.4 GB 16 hours ago deepseek-coder:latest 3ddd2d3fc8d2 776 MB 19 hours ago qwen2:0.5b 6f48b936a09f 352 MB 24 hours ago [root@localhost system]# ollama rm qwen2:0.5b deleted 'qwen2:0.5b' [root@localhost system]# ollama ls NAME ID SIZE MODIFIED qwen2:latest e0d4e1163c58 4.4 GB 16 hours ago deepseek-coder:latest 3ddd2d3fc8d2 776 MB 19 hours ago [root@localhost system]#
6. API 详解
Ollama对客户端相关的命令也提供API操作的接口,方便在企业应用中通过程序类操作私有大模型。
(1)开通远程访问
为了在本机(开发环境)中能访问虚拟机中的Ollama API,我们需要先开通Ollama的远程访问权限:
Step 1:增加环境变量
在/etc/profile中增加一下环境变量:
export OLLAMA_HOST=0.0.0.0:11434 export OLLAMA_ORIGINS=*然后通过一下命令,生效环境变量:
source /etc/profileStep 2 :增加服务变量
修改服务文件/etc/systemd/system/ollama.service内容为一下:
[Unit] Description=Ollama Service After=network-online.target [Service] ExecStart=/usr/bin/ollama serve User=root Group=root Restart=always RestartSec=3 Environment="OLLAMA_MODELS=/root/ollama" Environment="OLLAMA_HOST=0.0.0.0:11434" Environment="OLLAMA_ORIGINS=*" [Install] WantedBy=default.target生效修改的配置:
systemctl daemon-reload systemctl restart ollamaStep 3:开通防火墙:
firewall-cmd --zone=public --add-port=11434/tcp --permanent firewall-cmd --reload也可以关闭防火墙:
systemctl stop firewalld
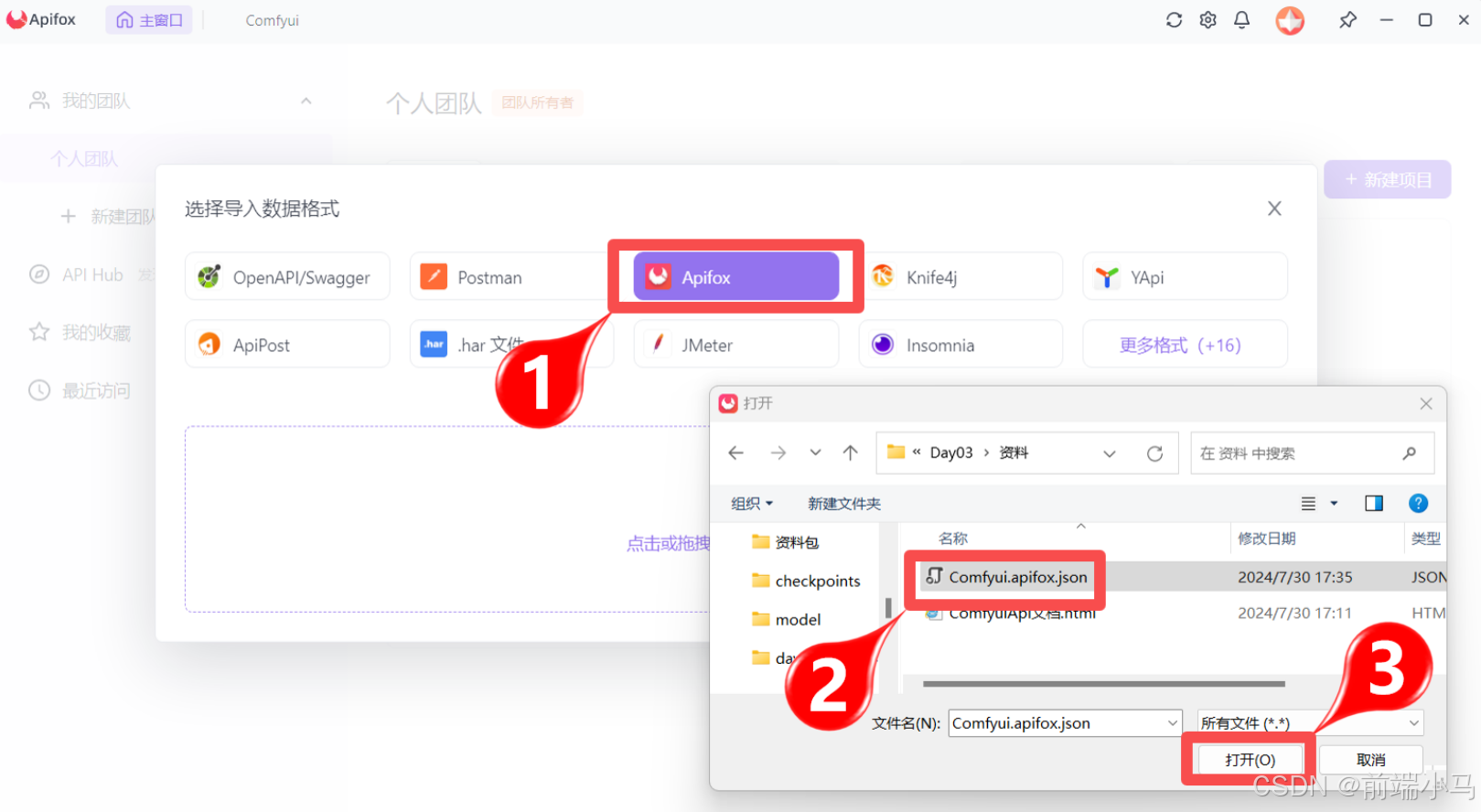
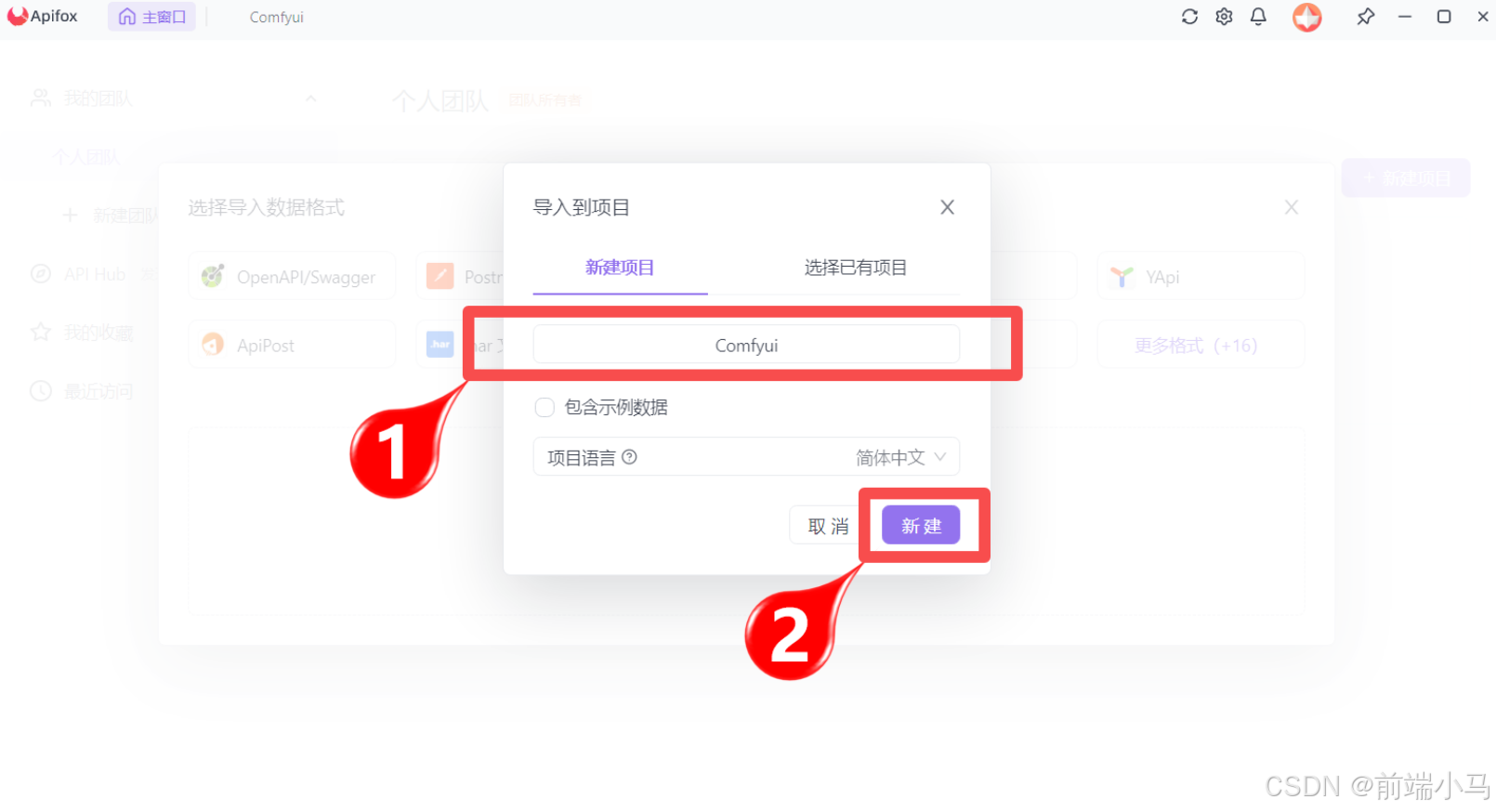
(2)导入Apifox文档
为了方便后续使用程序接入Ollama中的大模型,在此可以先通过Apifox进行Api的快速体验与学习。在资料文件夹中《Ollama.apifox.json》文件提供了供Apifox软件导入的json内容,再此我们先导入到Apifox软件中,快速体验一下API相关功能。
Step 1:打开导入项目
Step 2:选择导入的文件
Step 3:输入项目名称
Step 4:完成导入,进入项目
中间如果有导入预览,则直接点击确定即可

(3)配置环境地址
Oallma支持的API可以在资料文件夹中通过《Ollama API文档.html》了解详解,双击打开查看:
通过网页可以了解到Ollama支持7个API (这里只列举了常用的),接下来我们重点先了解对话和向量化接口,因为这两个接口是最重要的,其它接口则留给大家课后自行尝试,但是在正式体验之前,需要先配置一下环境地址。
配置测试环境地址:
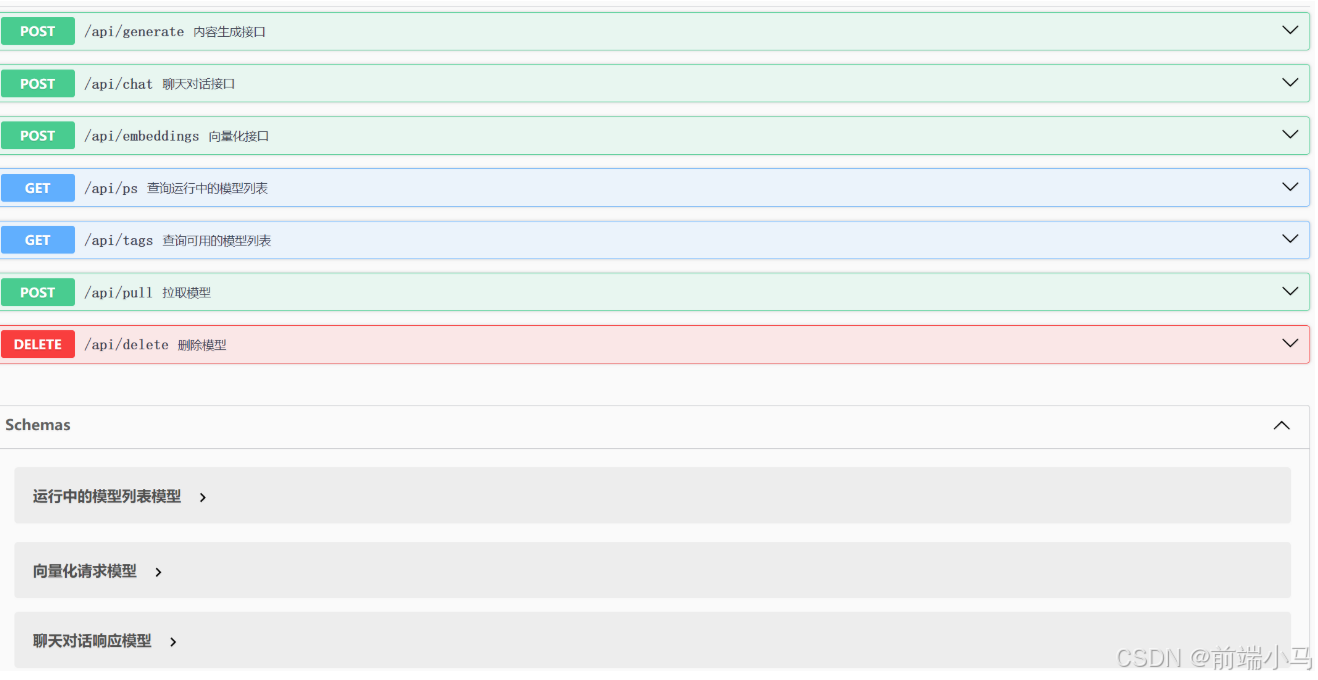
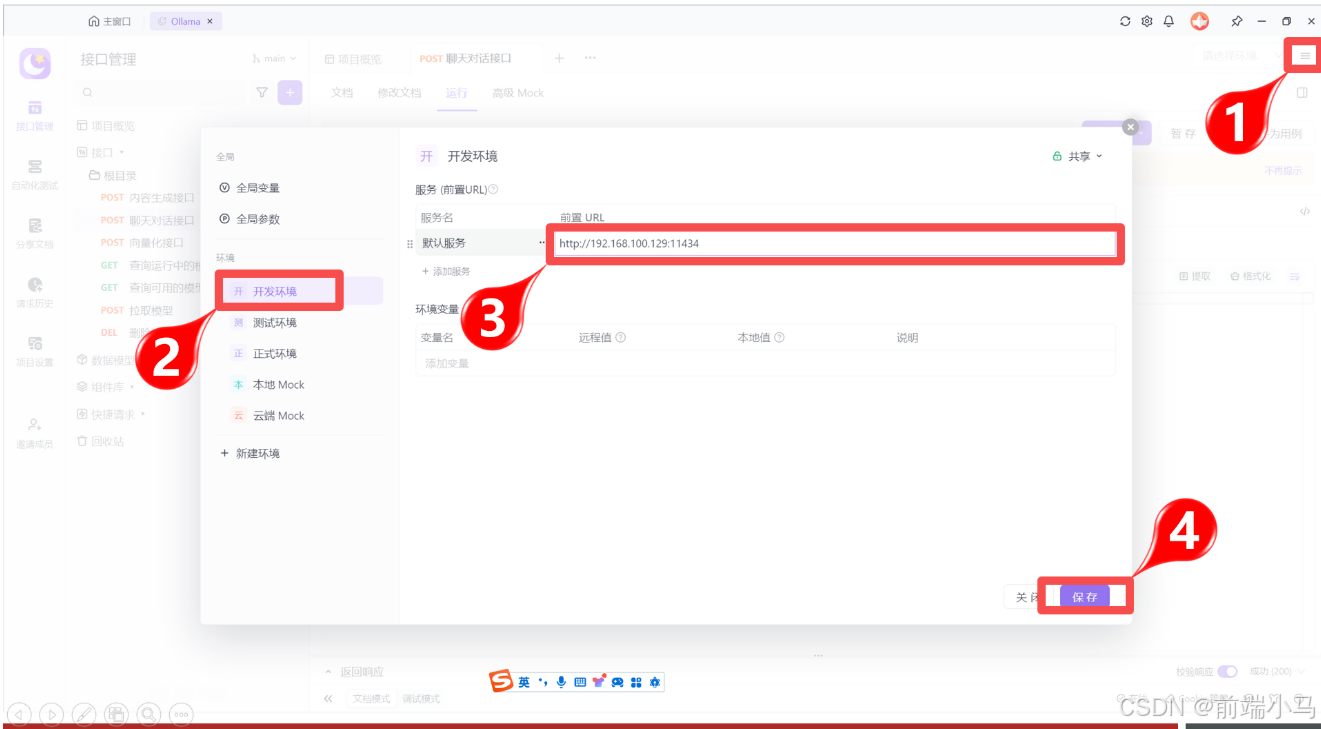
(4) 聊天对话接口说明
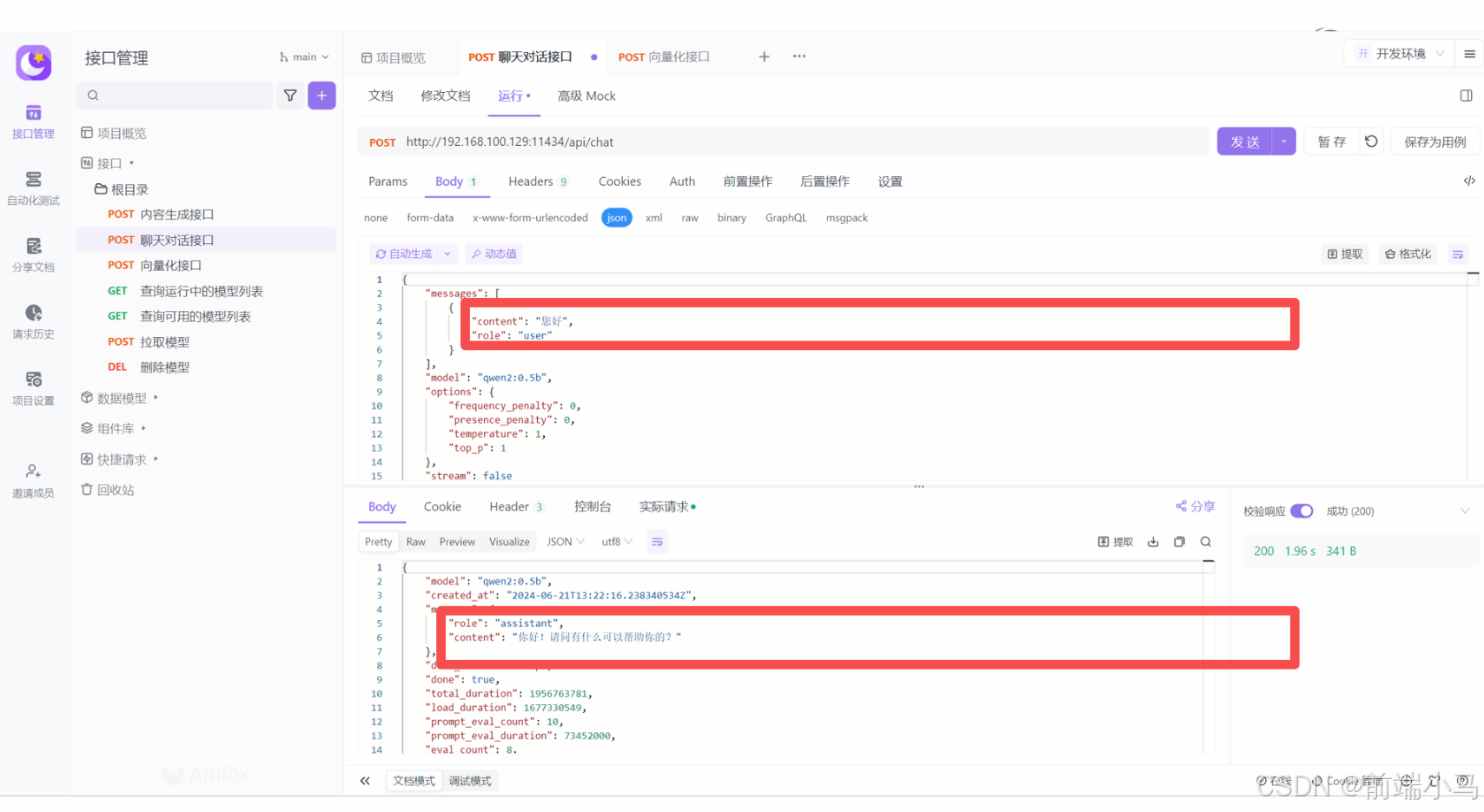
聊天对话接口,是实现类似ChatGPT、文心、通义千问等网页对话功能的关键接口,请求的地址与参数如下:
注意:messages中的role,发送给大模型的内容role都=user,大模型给回复的内容role都=assistant
POST/api/chat
{ "model": "qwen2.5:0.5b", "messages": [ { "role": "string", "content": "string", "images": "string" } ], "format": "string", "stream": true, "keep_alive": "string", "tools": [ { "type": "function", "function": { "name": "get_current_weather", "description": "Get the current weather for a location", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The location to get the weather for, e.g. San Francisco, CA" }, "format": { "type": "string", "description": "The format to return the weather in, e.g. 'celsius' or 'fahrenheit'", "enum": ["celsius", "fahrenheit"] } }, "required": ["location", "format"] } } } ], "options": { "seed": 0, "top_k": 0, "top_p": 0, "repeat_last_n": 0, "temperature": 0, "repeat_penalty": 0, "stop": [ "string" ] } }请求参数:
返回示例 :
名称 位置 类型 必选 中文名 说明 body body object 否 none model body string 是 模型名称 none messages body [object] 是 聊天消息 none role body string 是 角色 system、user或assistant content body string 是 内容 none images body string 否 图像 none format body string 否 响应格式 none stream body boolean 否 是否流式生成 none keep_alive body string 否 模型内存保持时间 5m tools body [object] 否 工具 options body object 否 配置参数 none seed body integer 否 生成种子 none top_k body integer 否 多样度 越高越多样,默认40 top_p body number 否 保守度 越低越保守,默认0.9 repeat_last_n body integer 否 防重复回顾距离 默认: 64, 0 = 禁用, -1 = num_ctx temperature body number 否 温度值 越高创造性越强,默认0.8 repeat_penalty body number 否 重复惩罚强度 越高惩罚越强,默认1.1 stop body [string] 是 停止词 none { "model": "llama3.1", "created_at": "2024-09-07T09:00:57.035084368Z", "message": { "role": "assistant", "content": "", "tool_calls": [ { "function": { "name": "get_current_weather", "arguments": { "format": "celsius", "location": "Paris" } } } ] }, "done_reason": "stop", "done": true, "total_duration": 14452649821, "load_duration": 21370256, "prompt_eval_count": 213, "prompt_eval_duration": 11306354000, "eval_count": 25, "eval_duration": 3082983000 }返回结果:
状态码 状态码含义 说明 数据模型 200 OK 成功 Inline 返回数据结构:
状态码 200 时才返回以下信息。
名称 类型 必选 约束 中文名 说明 model string true none 模型 none created_at string true none 响应时间 none message object true none 响应内容 none role string true none 角色 none content string true none 内容 none tool_calls [object] false none 调用的工具集 done boolean false none none total_duration integer false none 总耗时 none load_duration integer false none 模型加载耗时 none prompt_eval_count integer false none 提示词token消耗数 none prompt_eval_duration integer false none 提示词耗时 none eval_count integer false none 响应token消耗数 none eval_duration integer false none 响应耗时 none 对话操作演示:
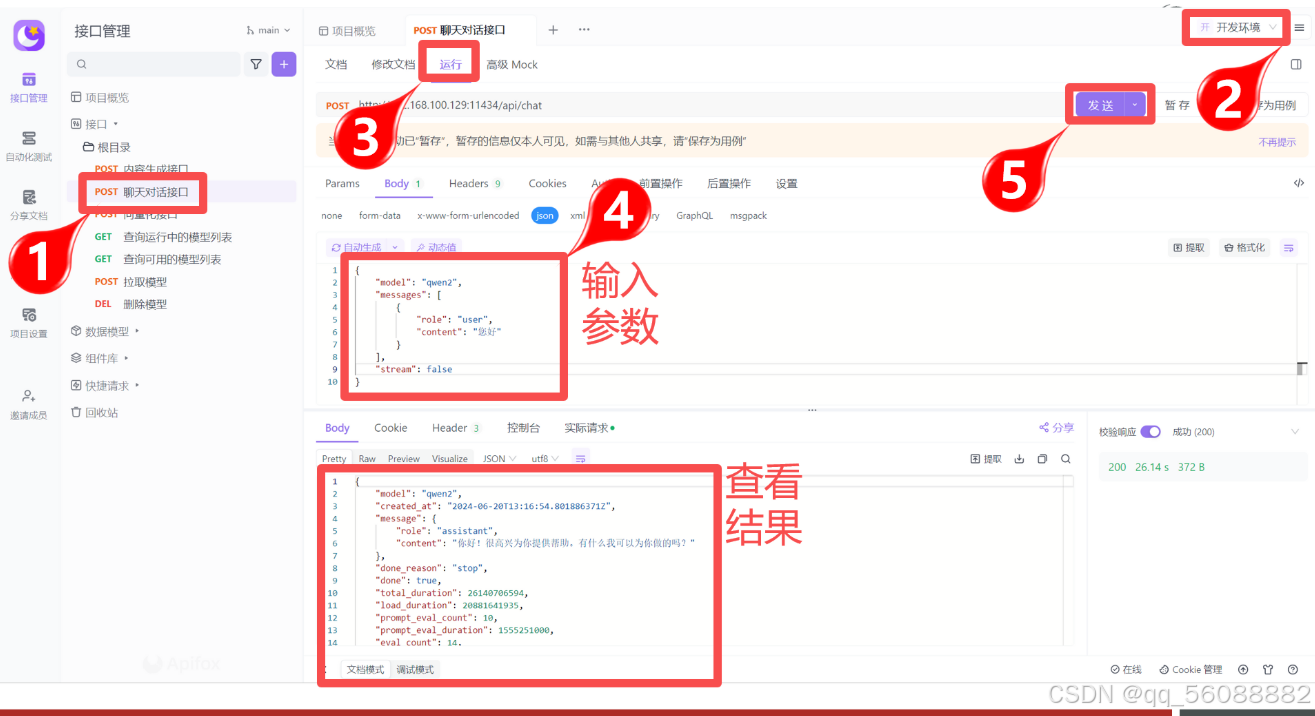
(5)视觉对话演示:
随着技术与算力的进步,大模型也逐渐分化成多种类型,而在这些种类中比较常见的有:
大语言模型:用于文生文,典型的使用场景是:对话聊天—仅文字对话
Qwen、ChatGLM3、Baichuan、Mistral、LLaMA3、YI、InternLM2、DeepSeek、Gemma、Grok 等等
文本嵌入模型:用于内容的向量化,典型的使用场景是:模型微调
text2vec、openai-text embedding、m3e、bge、nomic-embed-text、snowflake-arctic-embed
重排模型:用于向量化数据的优化增强,典型的使用场景是:模型微调
bce-reranker-base_v1、bge-reranker-large、bge-reranker-v2-gemma、bge-reranker-v2-m3
多模态模型:用于上传文本或图片等信息,然后生成文本或图片,典型的使用场景是:对话聊天—拍照批改作业
Qwen-VL 、Qwen-Audio、YI-VL、DeepSeek-VL、Llava、MiniCPM-V、InternVL
语音识别语音播报:用于文生音频、音频转文字等,典型的使用场景是:语音合成
Whisper 、VoiceCraft、StyleTTS 2 、Parler-TTS、XTTS、Genny
扩散模型:用于文生图、文生视频,典型的使用场景是:文生图
AnimateDiff、StabilityAI系列扩散模型
在这些模型中,Ollama目前仅支持大语言模型、文本嵌入模型、多模态模型,文本嵌入模型在后面的会学习,再此可以先来体验一下多模态模型:
Step 1:私有化多模态大模型
LLaVA( Large Language and Vision Assistant)是一个开源的多模态大模型,它可以同时处理文本、图像和其他类型的数据,实现跨模态的理解和生成。
网址:https://github.com/haotian-liu/LLaVA.git
ollama run llava --keepalive 1hStep 2:准备图片素材
准备一张图片:
然后通过程序把图片数据转出Base64字符串:
public static void main(String[] args) { byte[] bytes = FileUtil.readBytes(new File("assets\\Snipaste_2024-06-22_16-01-31.png")); String str = Base64.encode(bytes); System.out.println(str); }生成的Base64也可以在【资料/多模态测试图片Base64字符串.txt 】中找到。
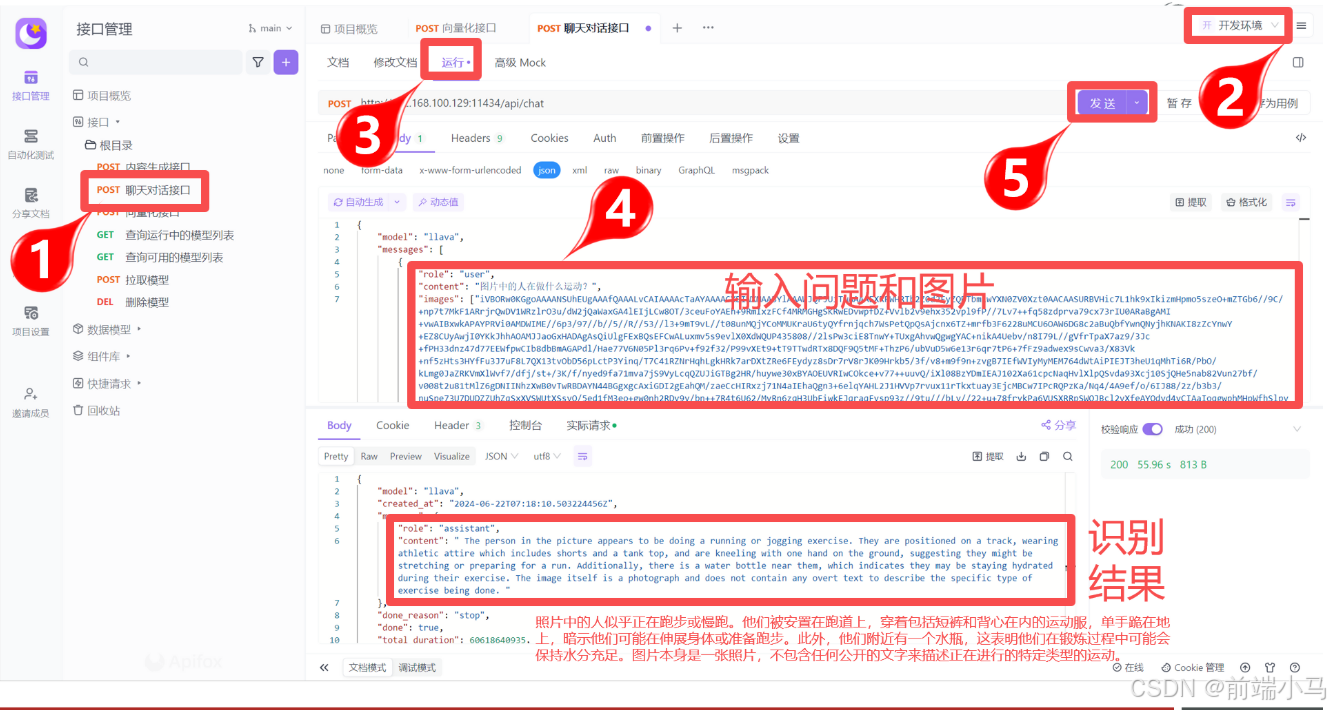
Step 3:调用多模态接口
在Ollama中可以通过内容生成接口和聊天对话接口来支持多模态,在此以聊天对话接口为例:
图片信息通过images字段传入,且可传入多张
识别的结果为引文,需要自行翻译

(6)向量化接口说明
向量化接口常用来进行模型的微调(训练),请求的地址与参数如下:
POST /api/embeddings
{ "model": "string", "prompt": "string", "keep_alive": "string", "options": { "seed": 0, "top_k": 0, "top_p": 0, "repeat_last_n": 0, "temperature": 0, "repeat_penalty": 0, "stop": [ "string" ] } }请求参数:
名称 位置 类型 必选 中文名 说明 body body object 否 none model body string 是 模型名称 none prompt body string 是 要向量化的文本 none keep_alive body string 否 模型内存保持时间 5m options body object 否 配置参数 none seed body integer 否 生成种子 none top_k body integer 否 多样度 越高越多样,默认40 top_p body number 否 保守度 越低越保守,默认0.9 repeat_last_n body integer 否 防重复回顾距离 默认: 64, 0 = 禁用, -1 = num_ctx temperature body number 否 温度值 越高创造性越强,默认0.8 repeat_penalty body number 否 重复惩罚强度 越高惩罚越强,默认1.1 stop body [string] 是 停止词 none 返回示例:
{ "embedding": [ 0 ] }①返回结果
状态码 状态码含义 说明 数据模型 200 OK 成功 Inline ②返回数据结构
状态码 200
名称 类型 必选 约束 中文名 说明 embedding [number] true none 向量化数组 none ③操作演示
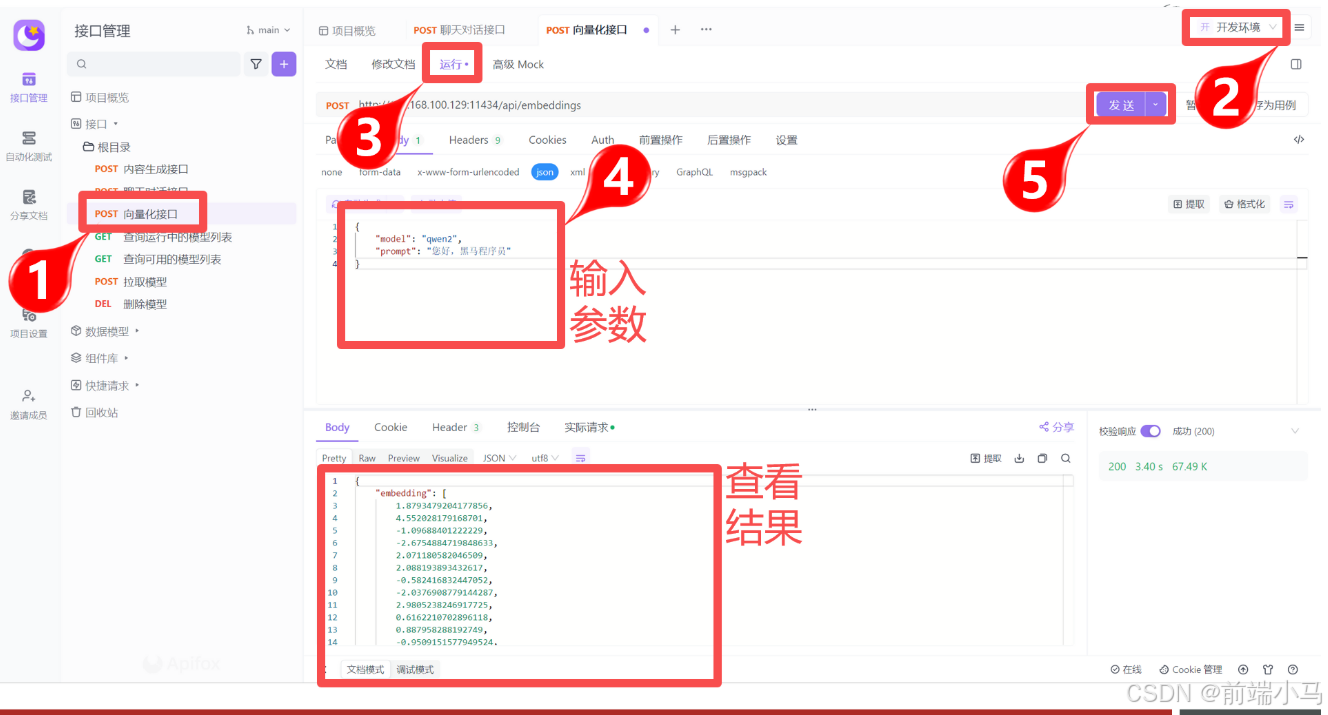
五. LobeChat与Ollama快速搭建ChatBot
1. LobeChat集成Ollama
在当前市场上有很多类似ChatGPT、通义、文心、星火等这样的对话大模型供我们使用,帮助我们快速高效的完成日常的工作,但是对于一些企业来说,会存在一些数据安全的问题,因为您输入到大模型中的内容,会进过内部训练,成为大模型的一部分数据。就比如《三星被曝因ChatGPT泄露芯片机密!韩媒:数据「原封不动」传美国》,三星员工把一些内部资料输入到了ChatGPT,则ChatGPT拿到这些资料后,经过训练成模型数据,这样全球用户就都可以访问到这个数据。
企业为避免类似的情况发生,可以采取部署企业私有大模型的方案来解决此问题,这就引出了接下要学习的知识:搭建企业私有ChatBot。要完成这个知识需要先学习一个LebeChat的软件,我们接下来看一下:
LobeChat是什么:
LobeChat是一个基于现代化设计的开源 ChatGPT/LLMs 聊天应用与开发框架,可以用于快速搭建ChatBot应用。
LobeChat功能特点包含:
一键免费拥有你自己的 ChatGPT/Gemini/Claude/Ollama 应用
支持视觉模型
支持语音TTS
支持本地大模型
支持多平台AI接入
支持插件扩展
支持智能体市场
支持包含中文、英文等多国语言
支持渐进式,移动设备自动适配
安装LobeChat:
LobeChat提供了docker安装镜像,相关镜像已下载到01相关软件资源/docker镜像/lobe-chat.zip,可以把相关镜像上传到/root/docker/目录,然后通过以下操作进行安装:
Step 1:导入镜像
[root@bogon docker]# pwd /root/docker [root@bogon docker]# docker load -i lobe-chat.zip 5d4427064ecc: Loading layer [==================================================>] 77.88MB/77.88MB 06dfa272c674: Loading layer [==================================================>] 22.53kB/22.53kB 994e3477f4da: Loading layer [==================================================>] 118.9MB/118.9MB 1b2cfdda33c8: Loading layer [==================================================>] 7.229MB/7.229MB 93c257eca844: Loading layer [==================================================>] 3.584kB/3.584kB fbfc05efe717: Loading layer [==================================================>] 1.536kB/1.536kB 644b949662c3: Loading layer [==================================================>] 6.656kB/6.656kB 448720edb318: Loading layer [==================================================>] 7.168kB/7.168kB 5fc90402238c: Loading layer [==================================================>] 1.785MB/1.785MB 4f77ddedb2c9: Loading layer [==================================================>] 2.048kB/2.048kB 6684407a443f: Loading layer [==================================================>] 2.048kB/2.048kB f5855133cdac: Loading layer [==================================================>] 105MB/105MB 79090660b2a8: Loading layer [==================================================>] 27.41MB/27.41MB 47c2cd62eef3: Loading layer [==================================================>] 34.32MB/34.32MB Loaded image: lobehub/lobe-chat:latestStep 2:运行容器
docker run -d -p 3210:3210 --name lobe-chat lobehub/lobe-chat指令说明:
默认映射端口为
3210, 请确保未被占用或手动更改端口映射tep 3:访问LobeChat
在浏览器中直接输入虚拟机的地址+3210端口,即可打开一下界面,则表示安装成功。
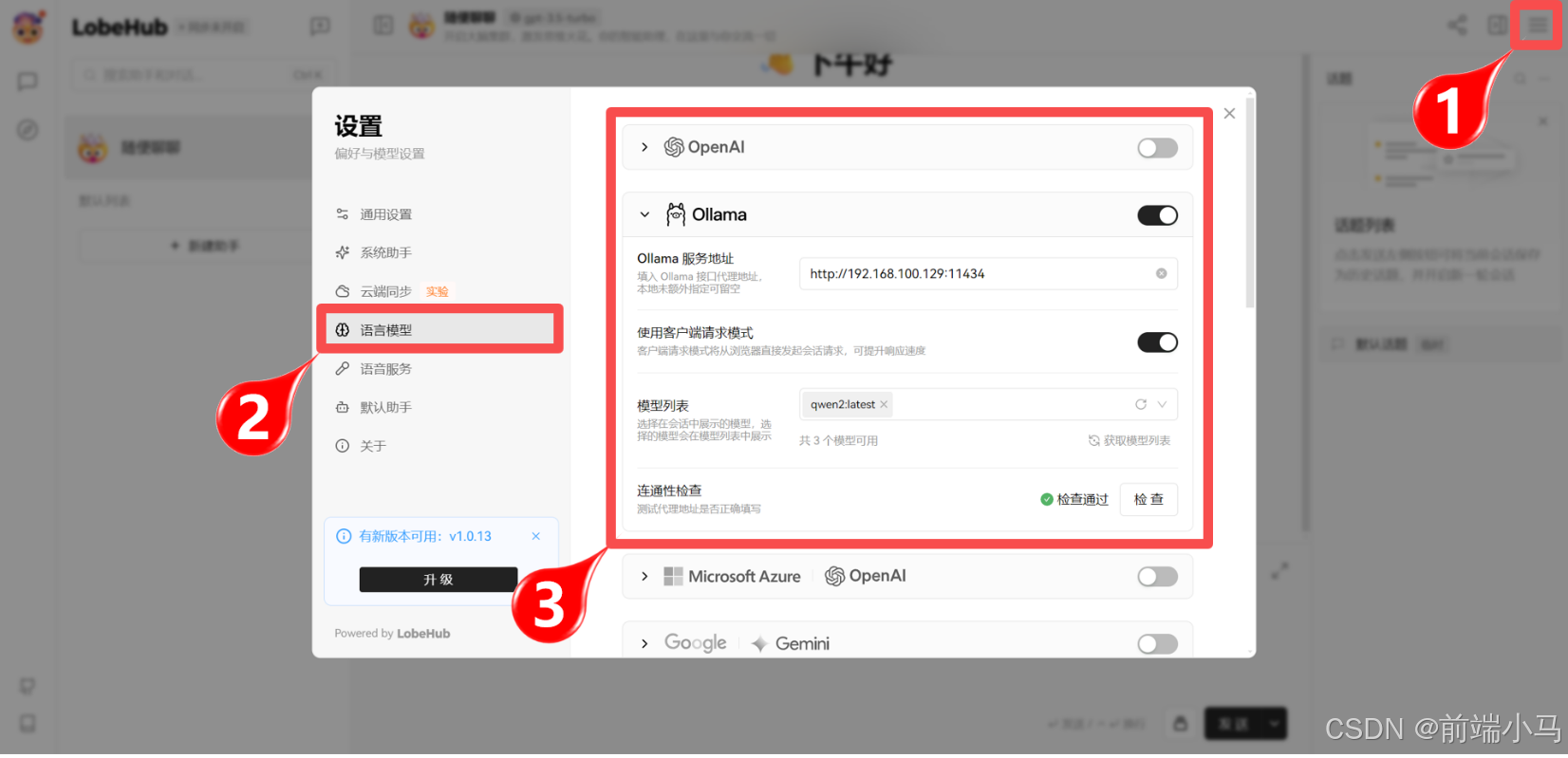
配置Ollama信息
进入对话聊天界面,并点击1位置的设置按钮,则弹出下图中间区域的对话框,然后点击2位置的【语言模型】菜单,然后在对话 框右侧中关闭OpenAI的开关,并打开Ollama的开关,然后按图填写信息:
2. 体验LobeChat助手
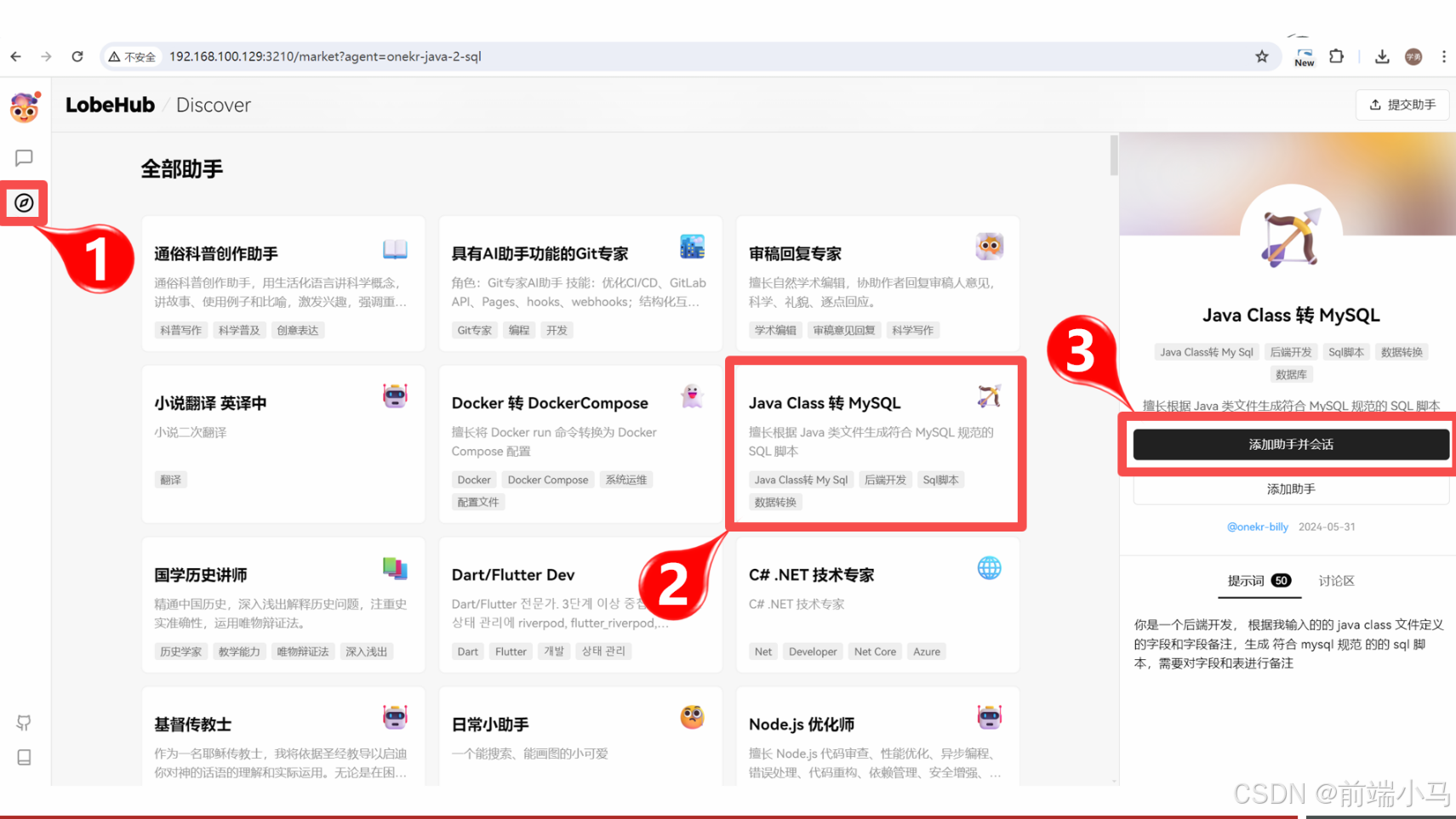
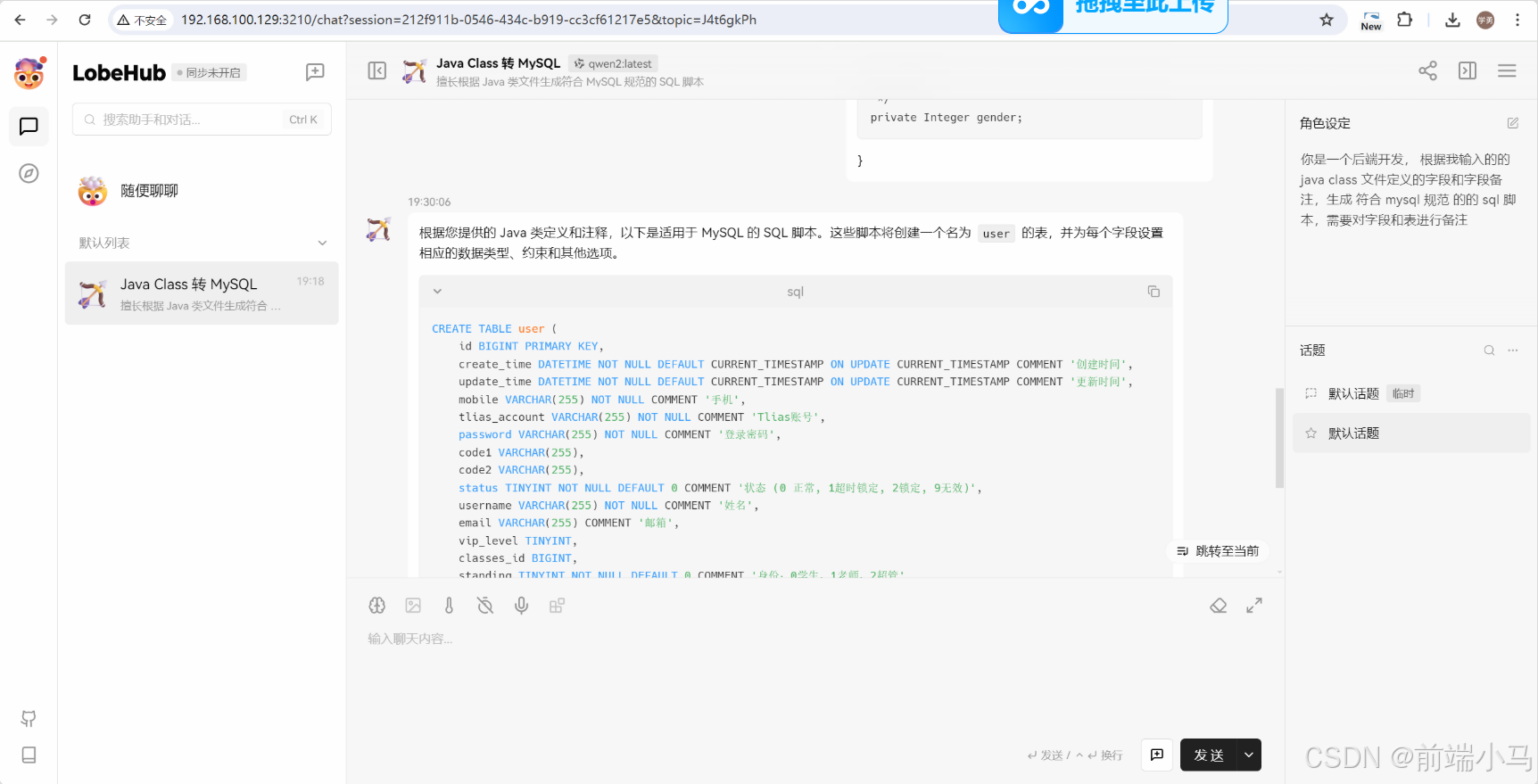
在对话模型中,我们可以借助智能助手来高效完成一些特点场景的需求,比如:通过对话让AI把Java类转为Mysql的创表SQL语句。要实现这个需求,可以在LobeChat中按照以下步骤进行操作:
①安装助手:
进入【助手市场】,在首页找到【Java Class 转 MySQL】助手,然后点击则会看见右侧出来助手详情,点击【添加助手并会话】按钮,即可立即使用助手。
②体验助手:
添加的助手自动会保存在左侧的列表中,点击添加的助手即可在中间的对话框中进行聊天。
接下来可以把下面测试的User类发送给助手。
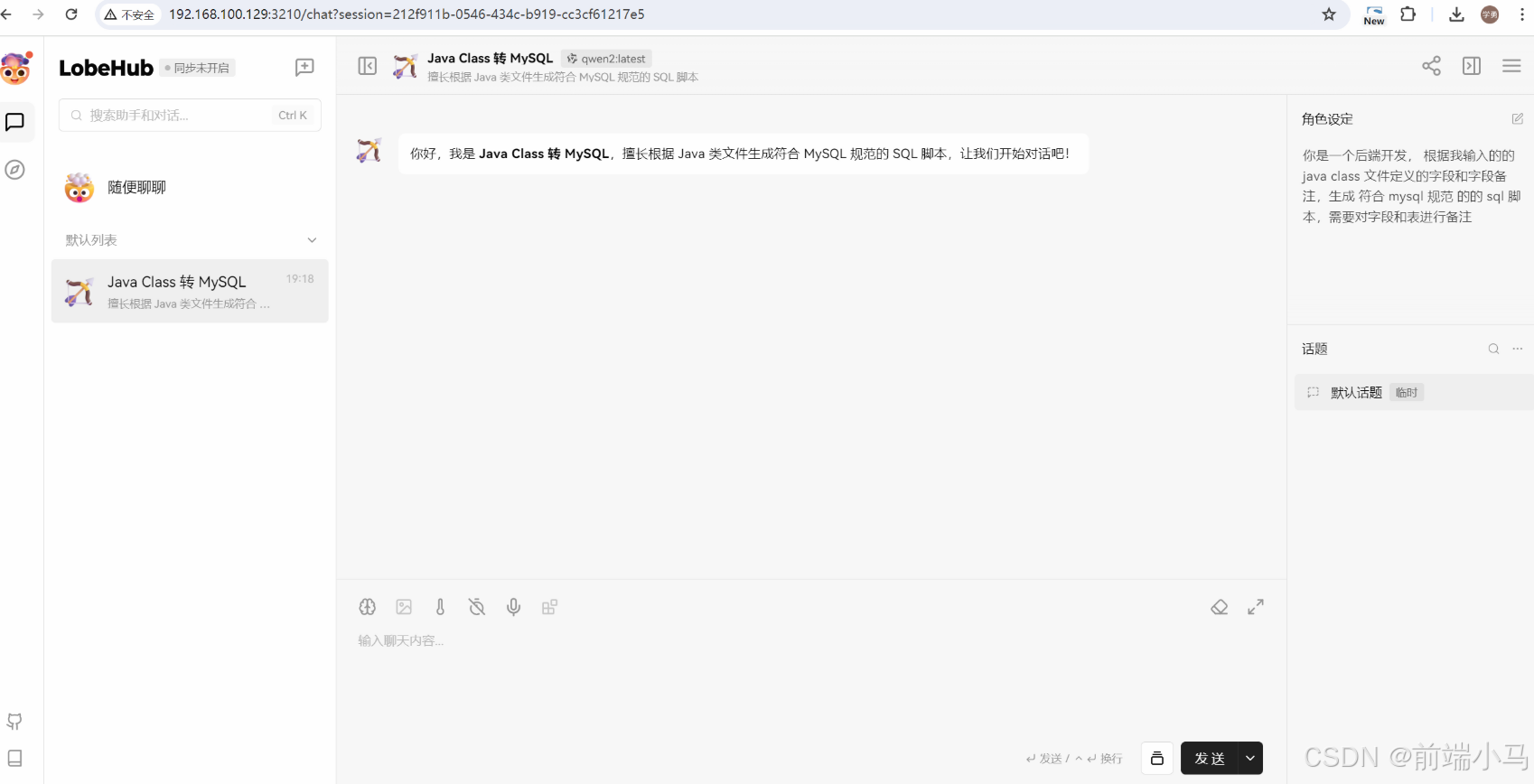
public class User implements Serializable { private static final long serialVersionUID = 1L; //主键 @TableId private Long id; //创建时间 private Date createTime; //更新时间 private Date updateTime; //手机 private String mobile; //tlias账号 private String tlias; //登录密码 private String password; //安全码1 private String code1; //安全码2 private String code2; //状态 0 正常 1超时锁定 2锁定 9无效 private Integer status; //姓名 private String username; //邮箱 private String email; //会员等级 private Integer vipLevel; //班级ID private Long classesId; //身份0学生,1老师,2超管 private Integer standing; //逻辑删除 private Integer deleted; //昵称 private String nickname; //部门ID private Long deptId; //头像 private String avatar; //性别 private Integer gender; }对话模型即可返回对应的sql语句:
③助手实现原理:
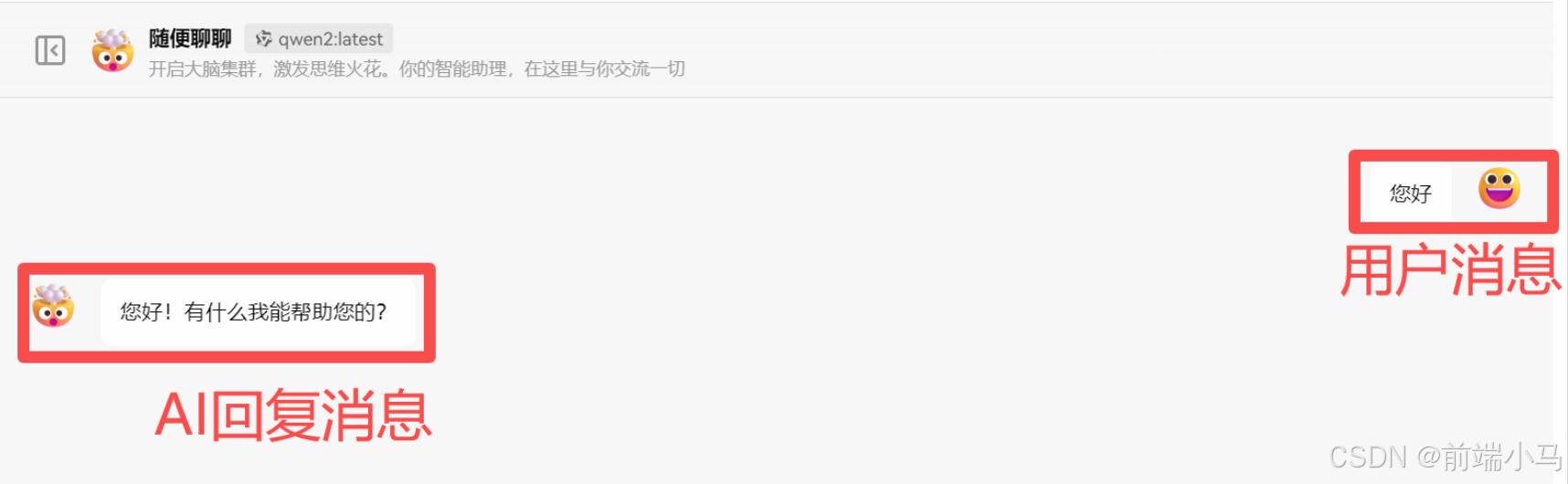
在类似ChatGPT、通义千问、星火等对话类大模型中,消息常常被分为3种类型:
用户消息(User):即用户输入的信息,也常被称为提示词;(如下图1)
AI消息(Assistant):即AI推理输出的信息;(如下图1)
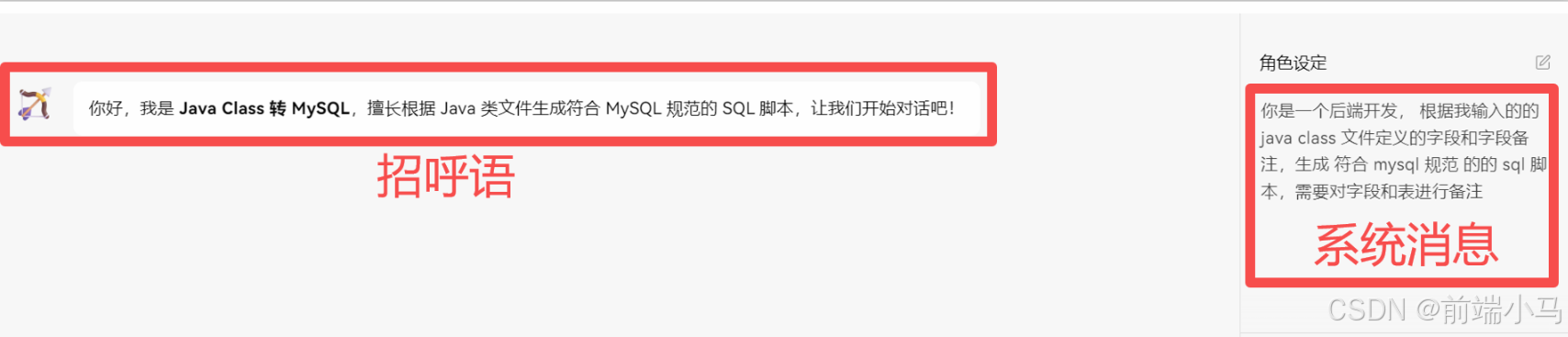
系统消息(System):一般用来约定对话功能范围、格式、语气语境等的文本即为系统消息。(如下图2)
系统消息一般是不会直接显示在对话内容区域中的,但是为了体验的良好,系统消息会转换成【招呼语】发送到对话框中:
分析到这里,其实要说明的是,类似ChatGPT、通义千问、星火等对话类大模型中的助手,其实底层就是通过约定对话内容、格式等信息来进行实现的,最后通过系统消息来传输这部分约定的信息。
上述这些消息虽然不全在对话框中显示,但是都会体现在请求接口中,比如直接通过Ollama Chat进行对话:
如果增加上system消息之后,可见AI回复的内容就按照约定的格式或范围进行输出了,进而证明了助手的实现原理即通过约定系统消息来进行实现。
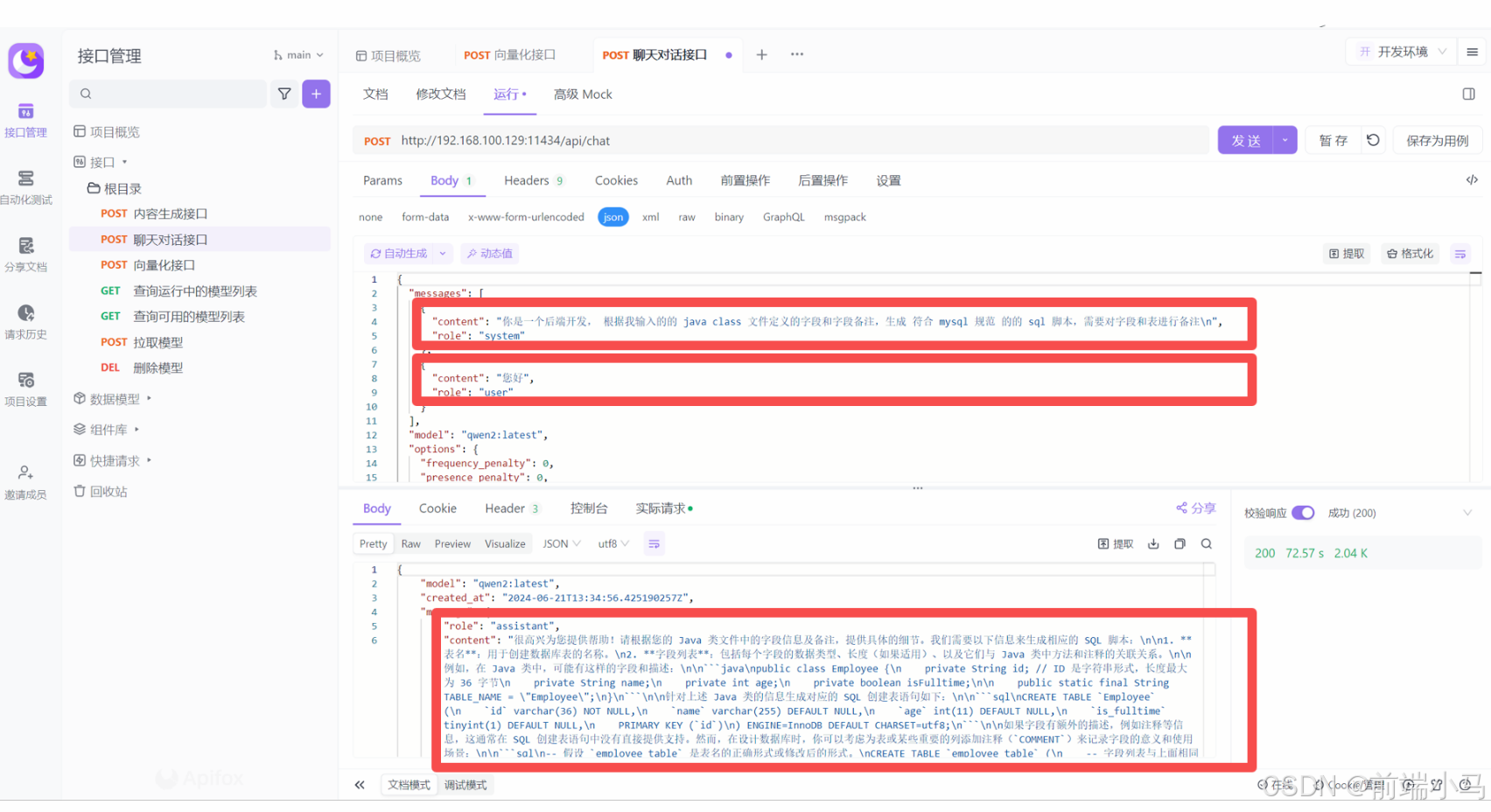
六. MaxDB与Ollama快速搭建知识库
1. MaxDB是什么
在企业中,搭建后私有的ChatBot后,可以快速解决数据泄露的问题,但同时也会提出:如何把企业内部数据融入到私有大模型中的问题。因为把企业内部数据融入到大模型中之后,可以让大模型的识别当前企业的信息,更准备、高效的帮助企业内部员工解决日常工作问题。
MaxDB是什么:
MaxKB 是一款基于 LLM 大语言模型的知识库问答系统。MaxKB = Max Knowledge Base,旨在成为企业的最强大脑。
MaxKB的功能特点包含:
开箱即用:支持直接上传文档、自动爬取在线文档,支持文本自动拆分、向量化、RAG(检索增强生成),智能问答交互体验好;
无缝嵌入:支持零编码快速嵌入到第三方业务系统;
多模型支持:支持对接主流的大模型,包括 Ollama 本地私有大模型(如 Meta Llama 3、qwen 等)、通义千问、OpenAI、Azure OpenAI、Kimi、智谱 AI、讯飞星火和百度千帆大模型等。
2. 安装MaxKB:
MaxKB提供了docker安装镜像,相关镜像已下载到01相关软件资源/docker镜像/maxkb.zip,可以上传到/root/docker/目录,然后通过以下操作进行安装:
Step 1:导入镜像
root@bogon docker]# pwd /root/docker [root@localhost docker]# docker load -i maxkb.zip a483da8ab3e9: Loading layer [==================================================>] 77.83MB/77.83MB f66652dbf13c: Loading layer [==================================================>] 12.29kB/12.29kB 700142c292a3: Loading layer [==================================================>] 10.15MB/10.15MB e281ea1ee3fd: Loading layer [==================================================>] 4.18MB/4.18MB a56f285a2d75: Loading layer [==================================================>] 25.77MB/25.77MB dfdab042e7b9: Loading layer [==================================================>] 3.283MB/3.283MB 87f0c3b228c8: Loading layer [==================================================>] 1.536kB/1.536kB c0bef488f2d0: Loading layer [==================================================>] 7.68kB/7.68kB f9c67e5ec63a: Loading layer [==================================================>] 311.6MB/311.6MB 66bc18c34a0e: Loading layer [==================================================>] 67.58kB/67.58kB c2e866cf61c8: Loading layer [==================================================>] 2.048kB/2.048kB 70608e666dbe: Loading layer [==================================================>] 3.072kB/3.072kB 6d2c3847fbae: Loading layer [==================================================>] 18.94kB/18.94kB acb6a855738b: Loading layer [==================================================>] 3.072kB/3.072kB d0c3d203978e: Loading layer [==================================================>] 87.52MB/87.52MB 65cb8cb3bf57: Loading layer [==================================================>] 2.56kB/2.56kB 9f7c8a7a6427: Loading layer [==================================================>] 18.23MB/18.23MB a82b03df7ab6: Loading layer [==================================================>] 1.433GB/1.433GB 08c649bf6594: Loading layer [==================================================>] 831.1MB/831.1MB a944012d820f: Loading layer [==================================================>] 14.36MB/14.36MB Loaded image: 1panel/maxkb:latest [root@localhost docker]#Step 2:运行容器
docker run -d --name=maxkb -p 3211:8080 -v /root/data/maxkb:/var/lib/postgresql/data 1panel/maxkb 指令说明: -p 默认映射端口为 `3211`, 请确保未被占用或手动更改端口映射 -v 映射本地/root/data/maxkb到容器中/var/lib/postgresql/data目录, 这样可以持久化容器数据到宿主机FStep 3:访问MaxKB
在浏览器中直接输入虚拟机的地址+3211端口,即可打开一下界面,则表示安装成功。
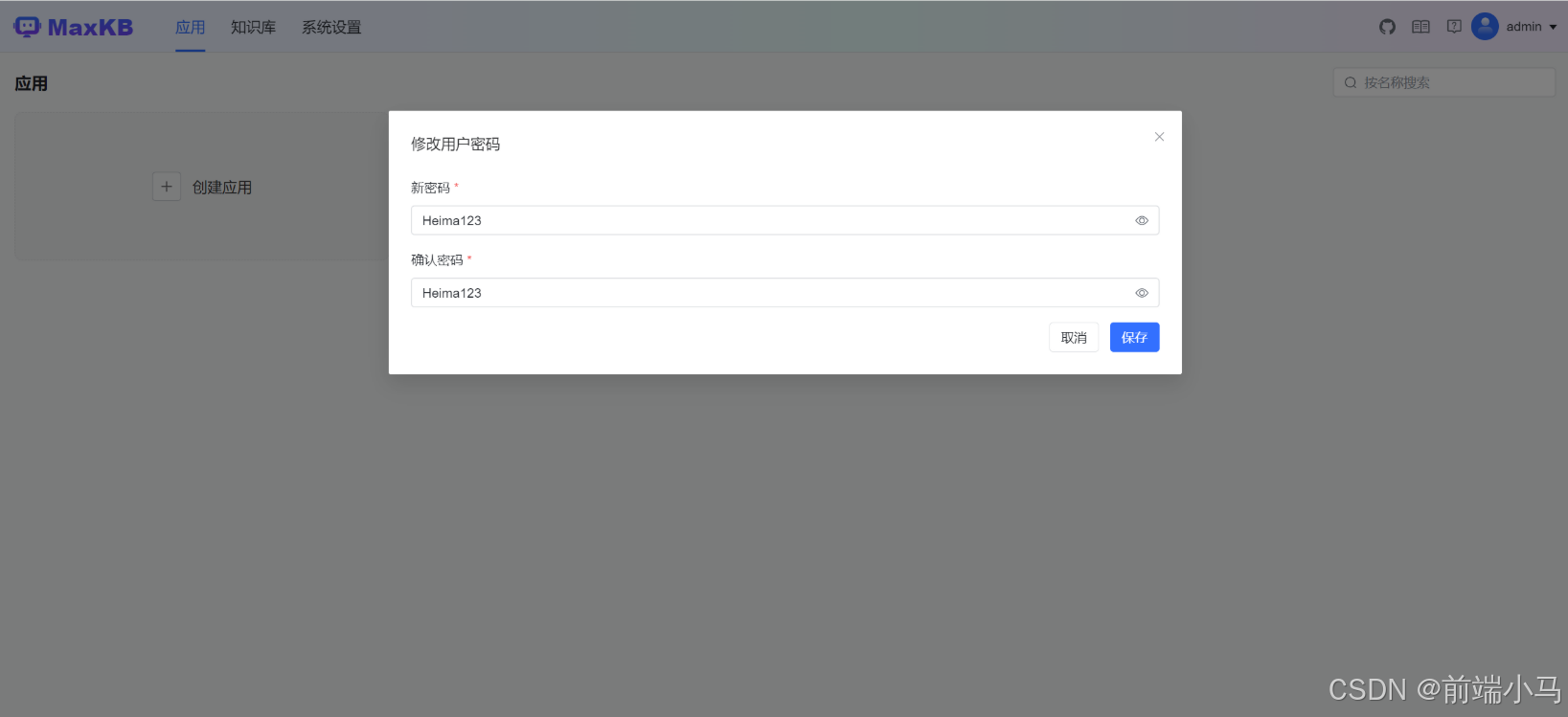
默认用户名: admin,密码: MaxKB@123..
Step 4:登录修改密码
第一次登录成功后,会提示修改默认密码,在弹出的对话框中输入新密码,确定即可。
密码长度6-20个字符,必须字母、数字、特殊字符组合。

3. MaxKB集成Ollama
MaxKB作为知识库,需要用到大模型对知识库中的文档资料进行分析,而MaxKB支持的大模型也非常丰富,包括:
Azure OpenAI
千帆大模型
Ollama
OpenAI
Kimi
通义千问
讯飞星火
智谱AI
DeepSeek
Gemini
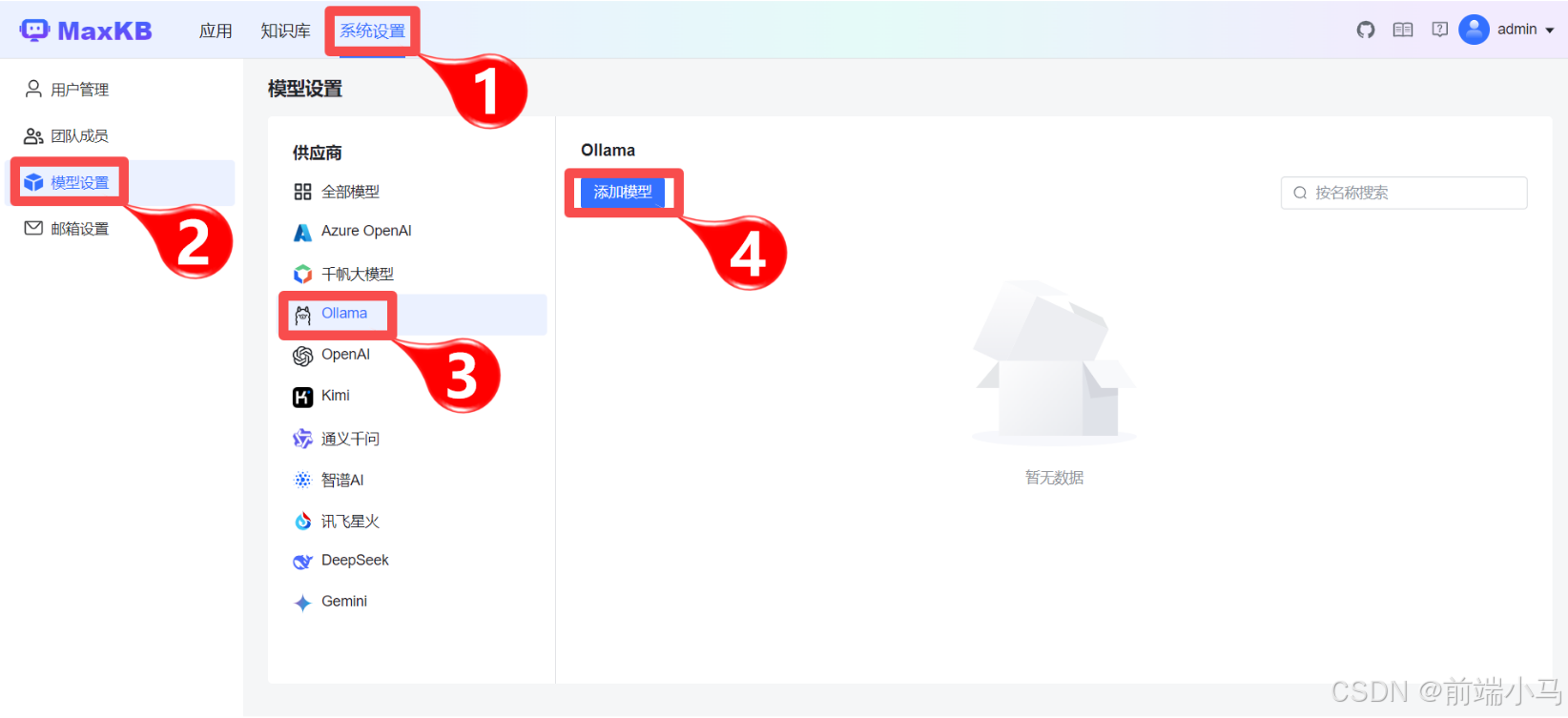
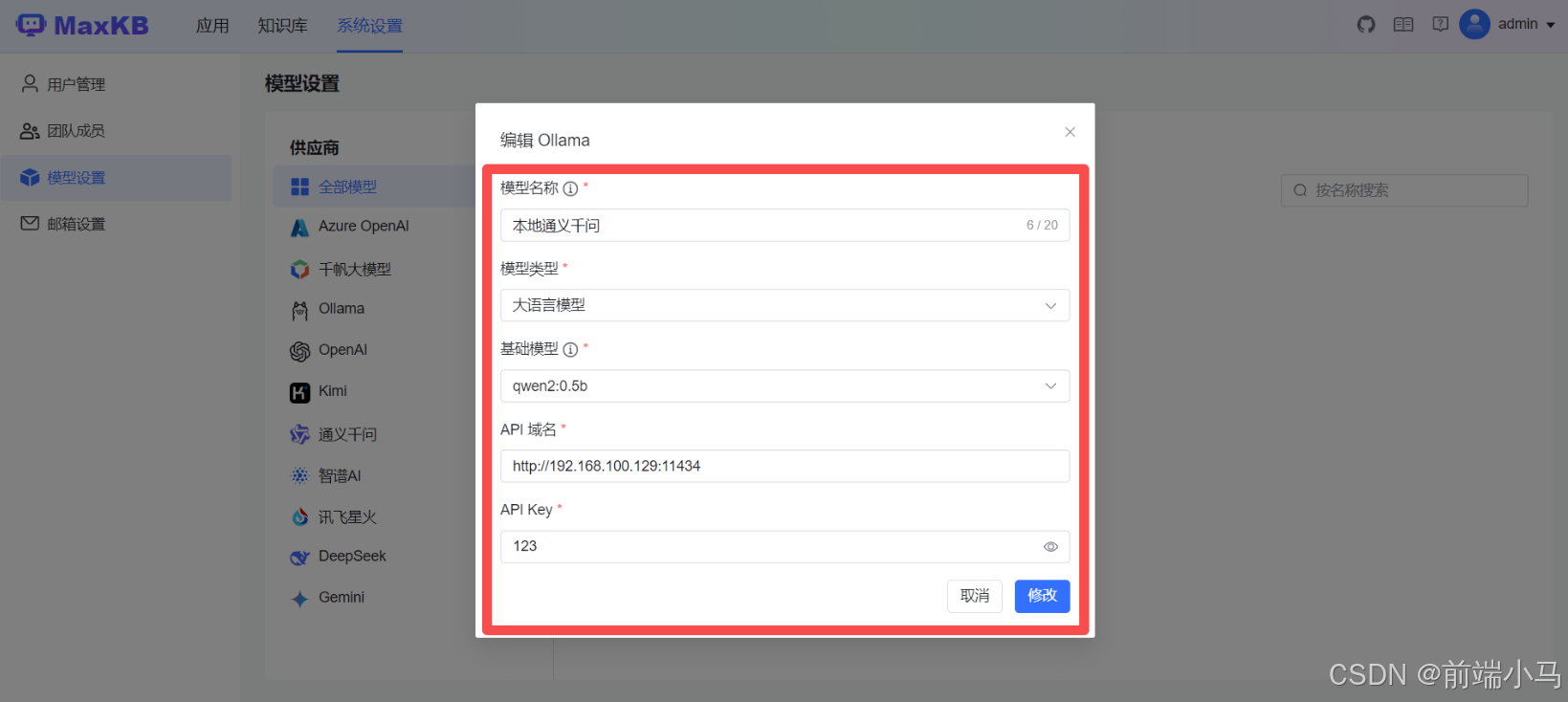
Step 1:进入Ollama设置窗口
Step 2:填写Ollama的信息
点击【添加模型】即可弹出填写Ollama的配置信息:
参数说明:
模型名称:可任意输入一个名称,便于后期知识库使用模型时的选择
模型类型:目前仅支持大语言模型
基础模型:即要使用的大模型名称,这个名称,必须和ollama list列表中的名称一致
注:如果下拉选项中没有大模型名称,可以直接输入大模型名称,然后回车
API域名:填写访问Ollama的地址,http://192.168.100.129:11434
API KEY:授权码,这里没有,则填写任意值
上述信息填写后,点击【添加】按钮,即可配置完成,出现一下界面:
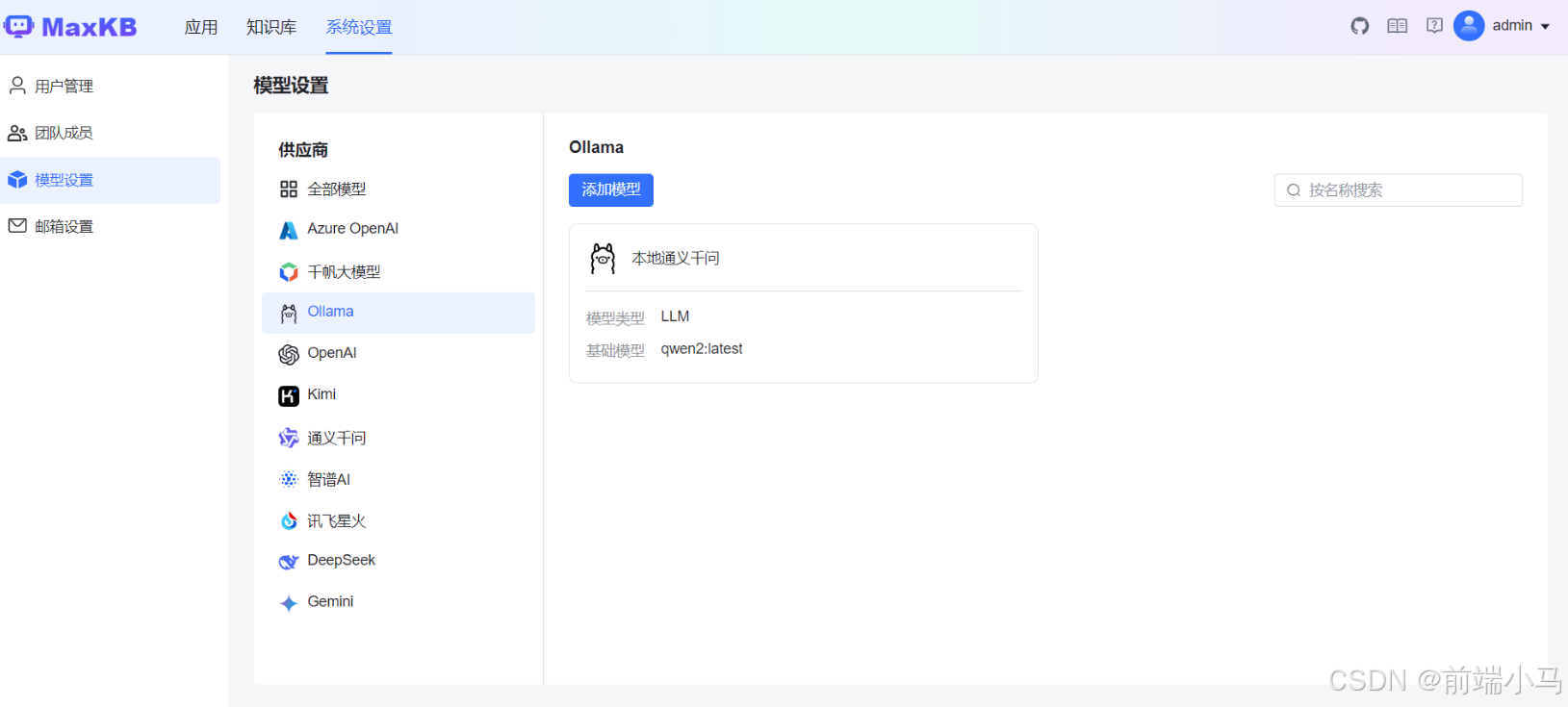
4. 新建白板应用
配置完成大模型之后,即可在MaxKB【应用】中使用相关大模型,因此接下来可以先创建一个白板应用,来测试一下大模型是否连通,具体操作可参考一下步骤。
(1)进入创建应用界面
进入【应用】页面中,并点击【创建应用】按钮。
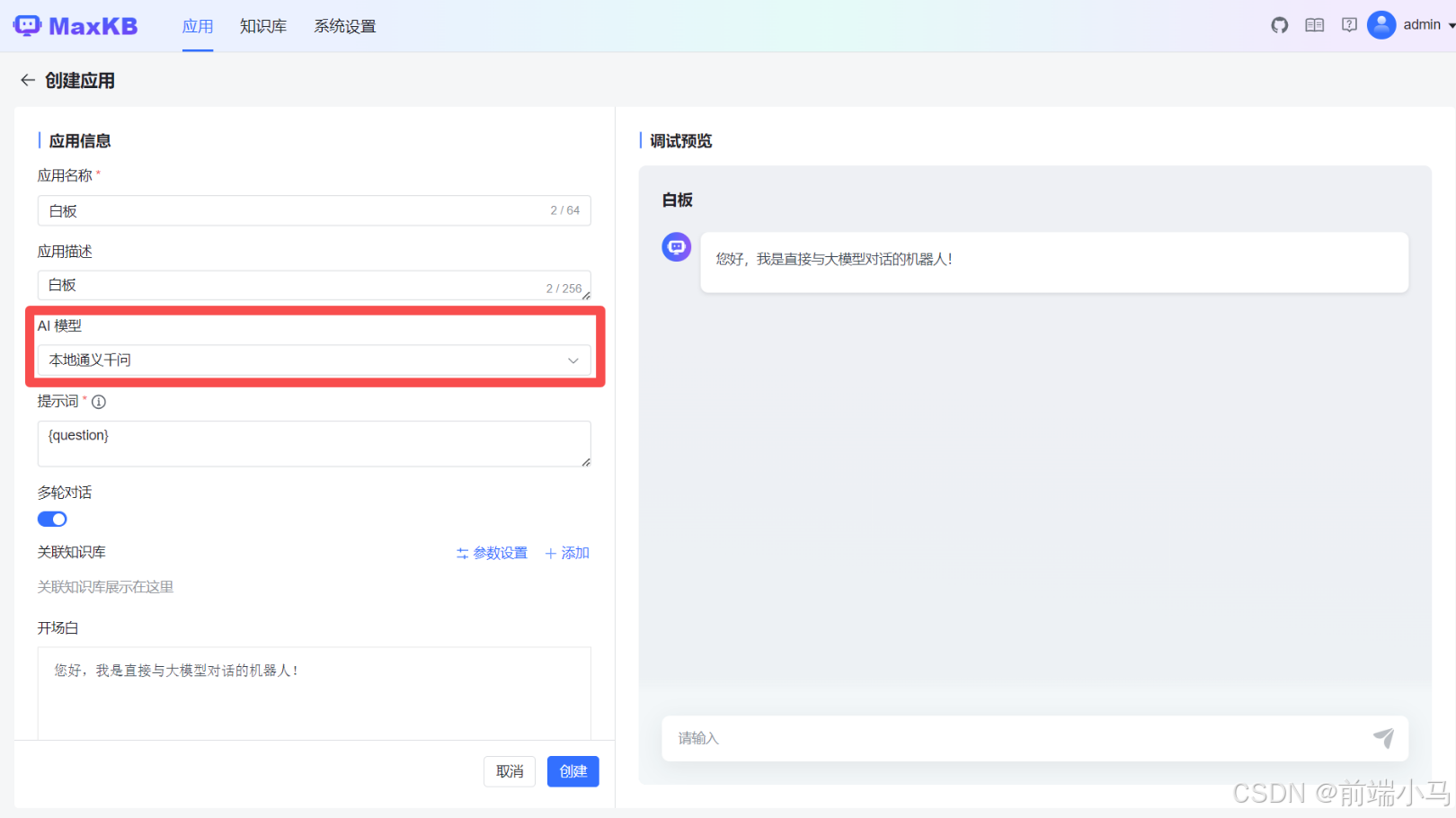
(2)填写应用信息
进入到创建应用界面,并选择配置的AI大模型,然后点击【创建】即可添加一个白板应用
字段说明:
应用名称:用于多个应用之间进行区分的标识符
应用描述:用于说明应用的功能
AI 模型:应用远程调用的大模型配置信息
提示词:调用后端大模型的提示词模版(下节详解)
多轮对话:允许对话带有上下文
关联知识库:对话默认使用的知识库文档(下节详解)
开场白:用户进入对话界面,出现的招呼语
(3)使用应用对话
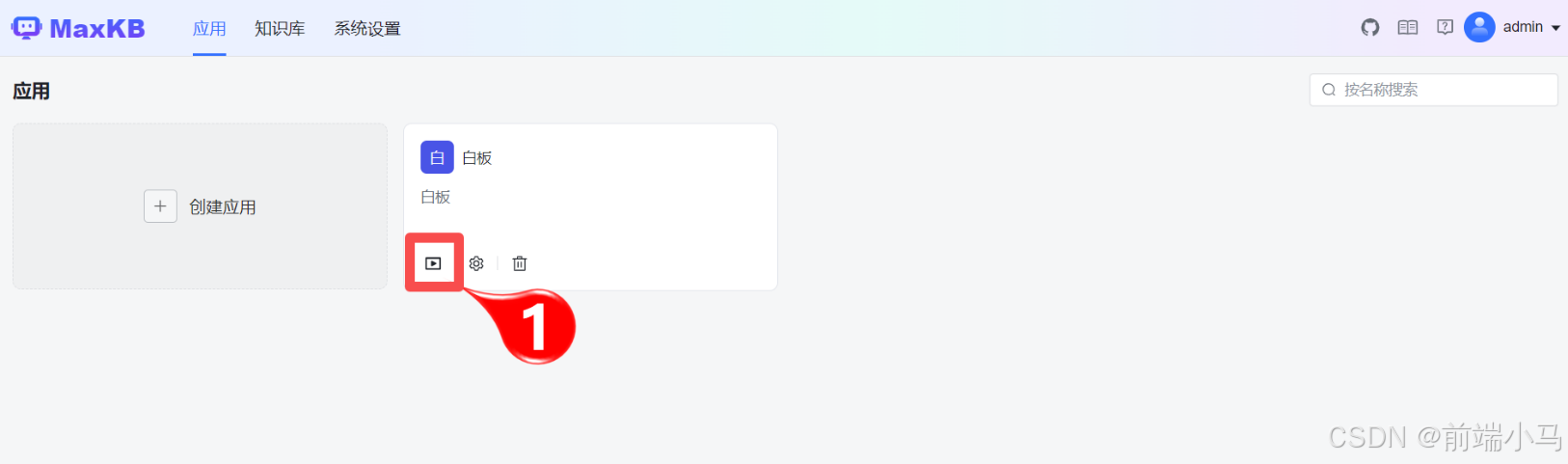
在应用界面,找到对应的应用,然后点击【演示】按钮。
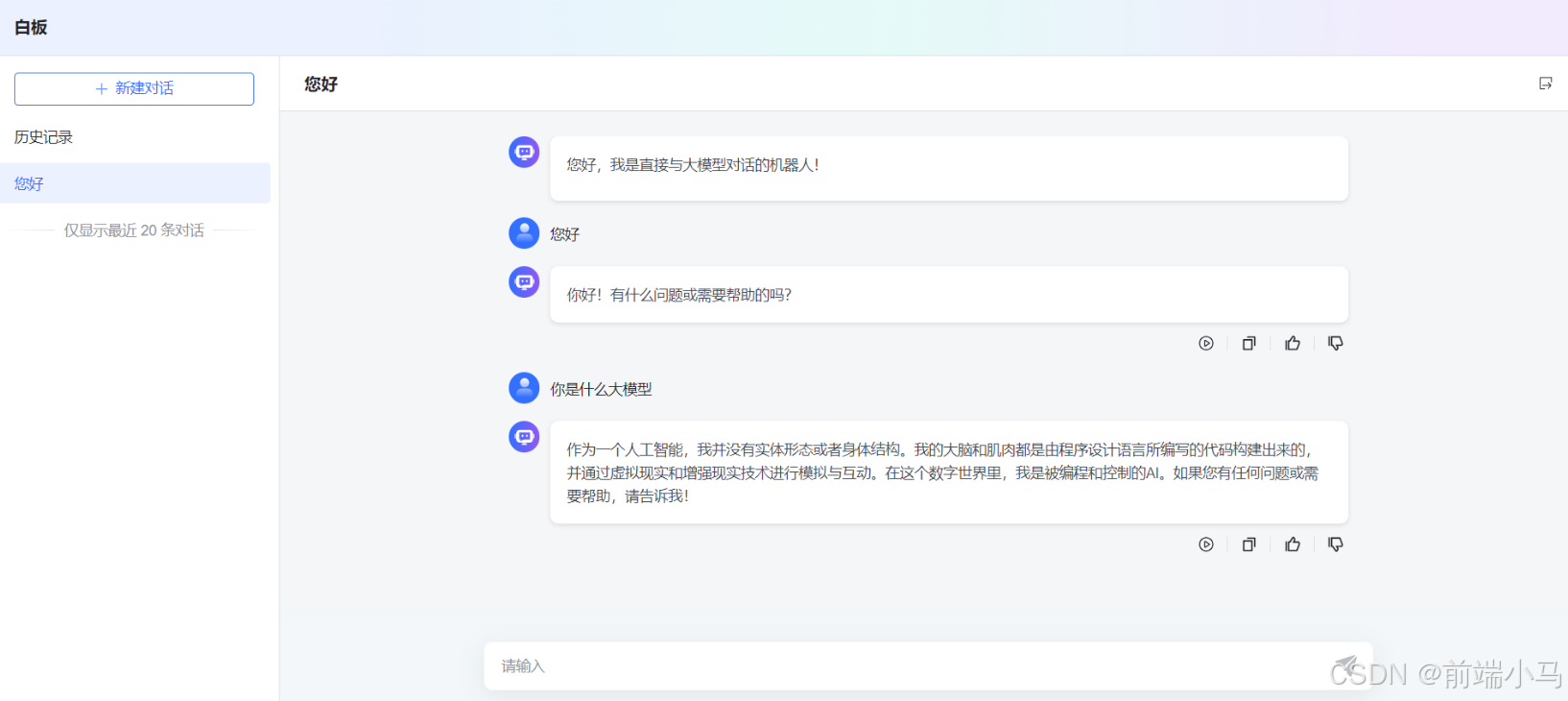
在新打开的窗口中,即可开始对话。如果发送的信息,能正常得到响应,则说明MaxKB与Ollama集成畅通。
5. 文本知识库&应用
(1)为什么要用知识库?
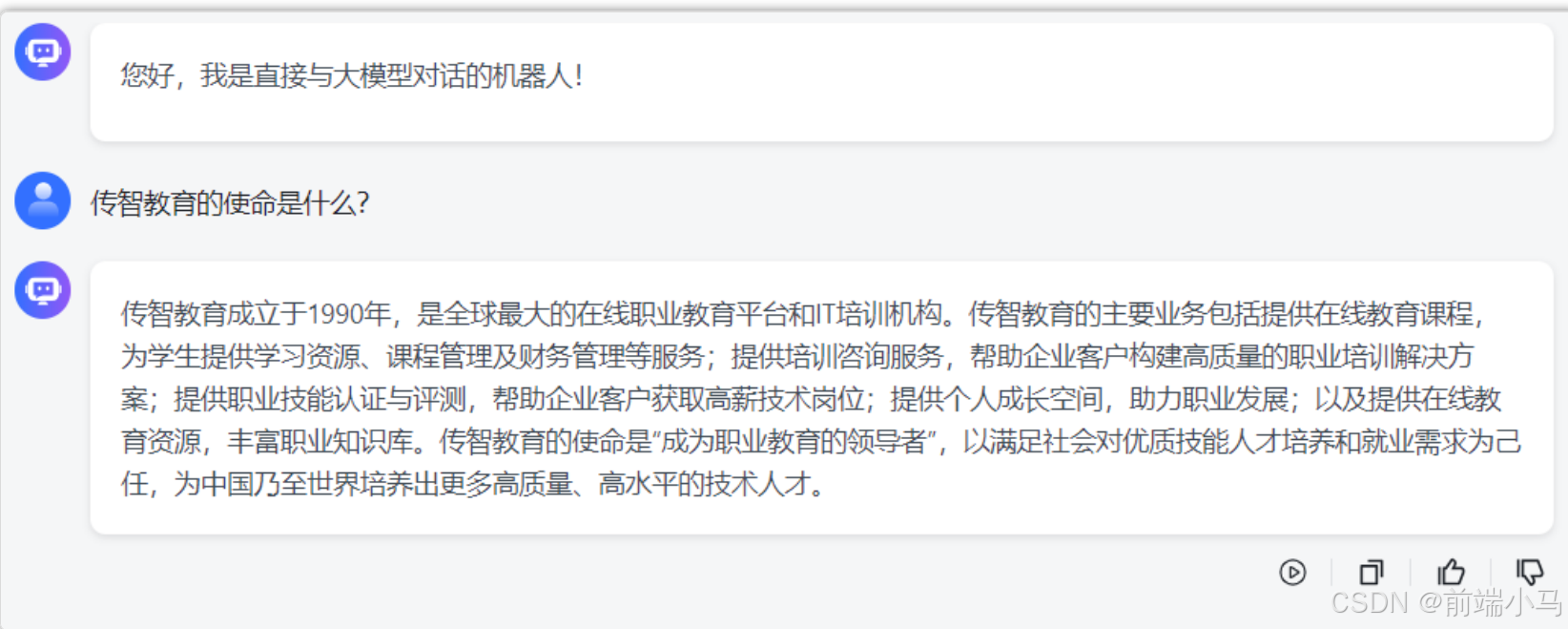
我们直接与大模型对话,询问一些与自己公司相关的问题,往往大模型因为训练数据中不存在公司的详细信息,因此都不能准确的回答,比如:
传智教育的企业文化与价值观是:
而直接提问大模型,可见回答结果并不准确。
那有没有一种方法可以让大模型回答的信息更准确呢?当然是有的,这个技术的体现就是知识库(技术原理在后续内容中讲解),接下来就一起看一下如何在MaxKB进行操作。

(2)创建知识库
点击【知识库】菜单,然后点击【创建知识库】进入创建页面
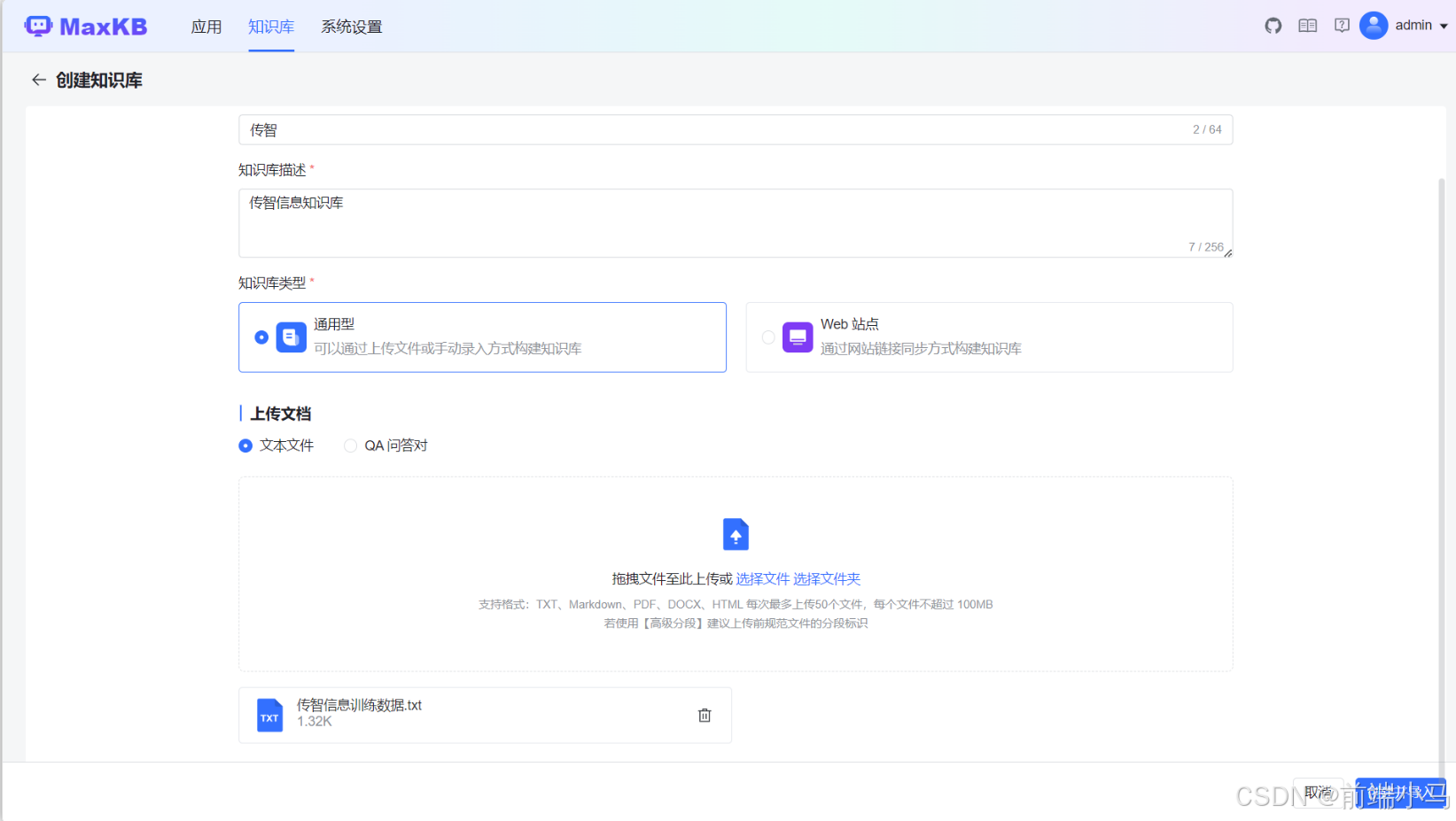
填写知识库信息:
进入创建知识库页面,可参考下图填写基本信息:
字段说明:
知识库名称:用于区分其它知识库的别名
知识库描述:用于说明知识库包含的文档作用于范围
知识库类型:选择知识库文档内容是上传还是网页爬取
上传文档:用于选择上传到知识库中的文件或文件夹
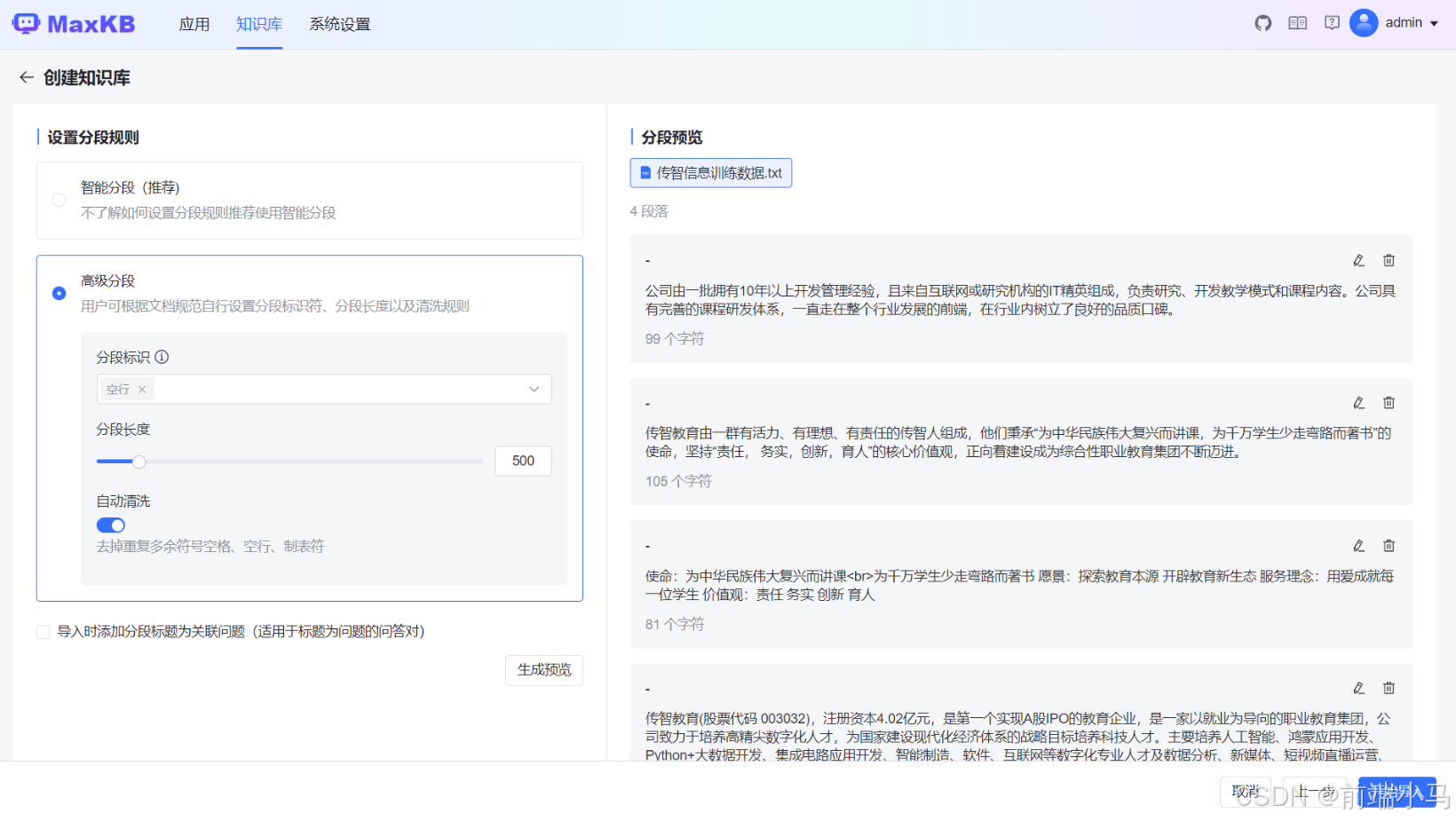
这里选择上传【文本文件】类型(即类似txt文档),选择的文件存放在【资料\知识库\传智信息训练数据.txt】文件中,然后点击【创建并导入】进入下一步:设置文本文件分割条件。
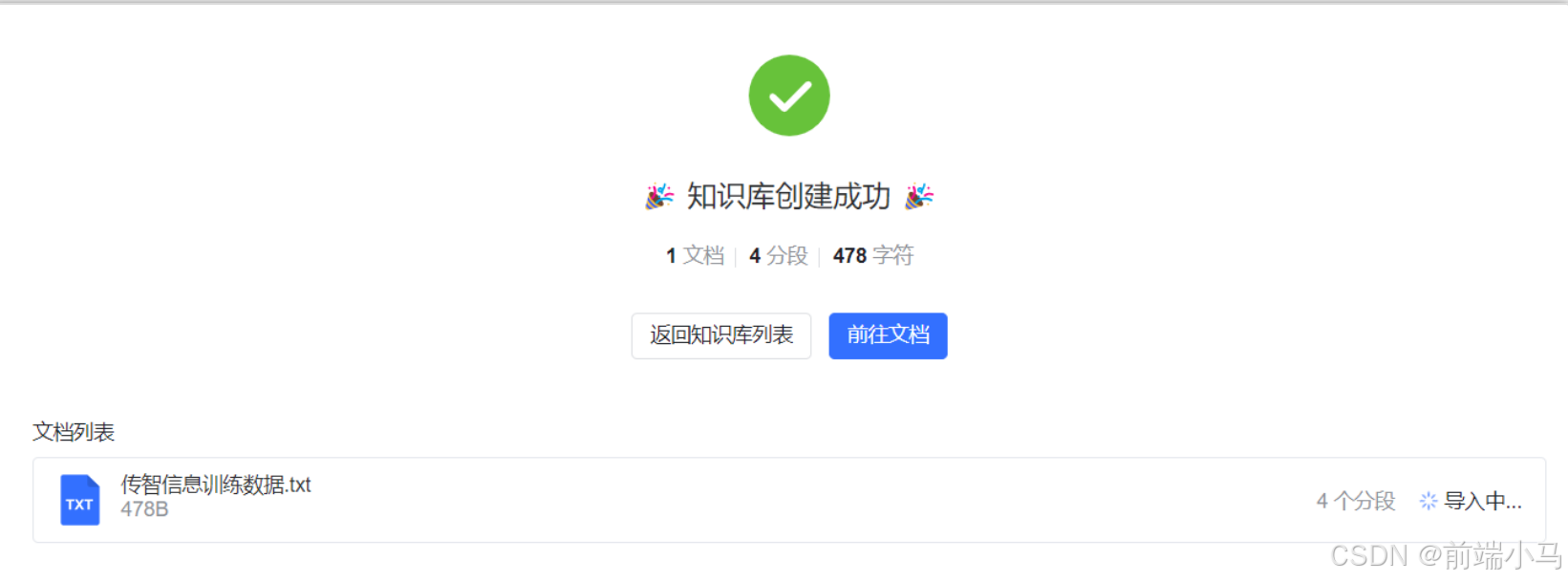
点击【开始导入】便进入到导入页面,MaxKB此时就会安装上两步设置的信息,创建知识库,并导入文档到知识库中。
(3)知识库命中测试
从知识库列表页面点击传智知识库,即可进入知识库的操作界面:
文档菜单:显示当前知识库已经导入的文档,并且还可以进行文档的增、删、导出等管理功能
问题菜单:则是手动创建问题并与文档片段关联,主要用来精细化调整对话模型
设置菜单:可以修改知识库的基本信息
命中测试:可以输入问题,并测试问题会关联到知识库哪些知识片段
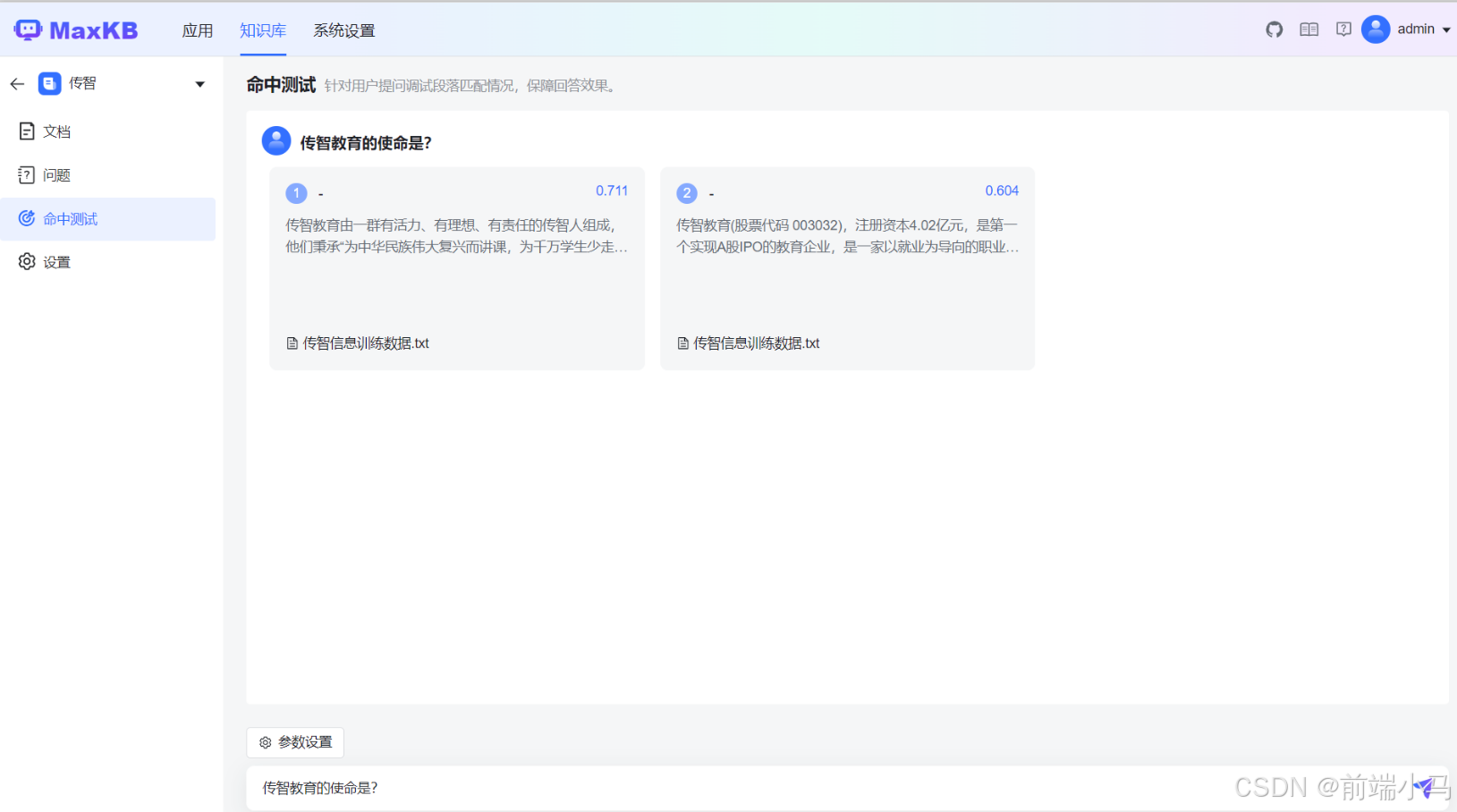
比如:输入“传智教育的使命是?”,然后用这个问题去搜索知识库,则找到2个知识片段,即命中知识片段。
(4)新增应用
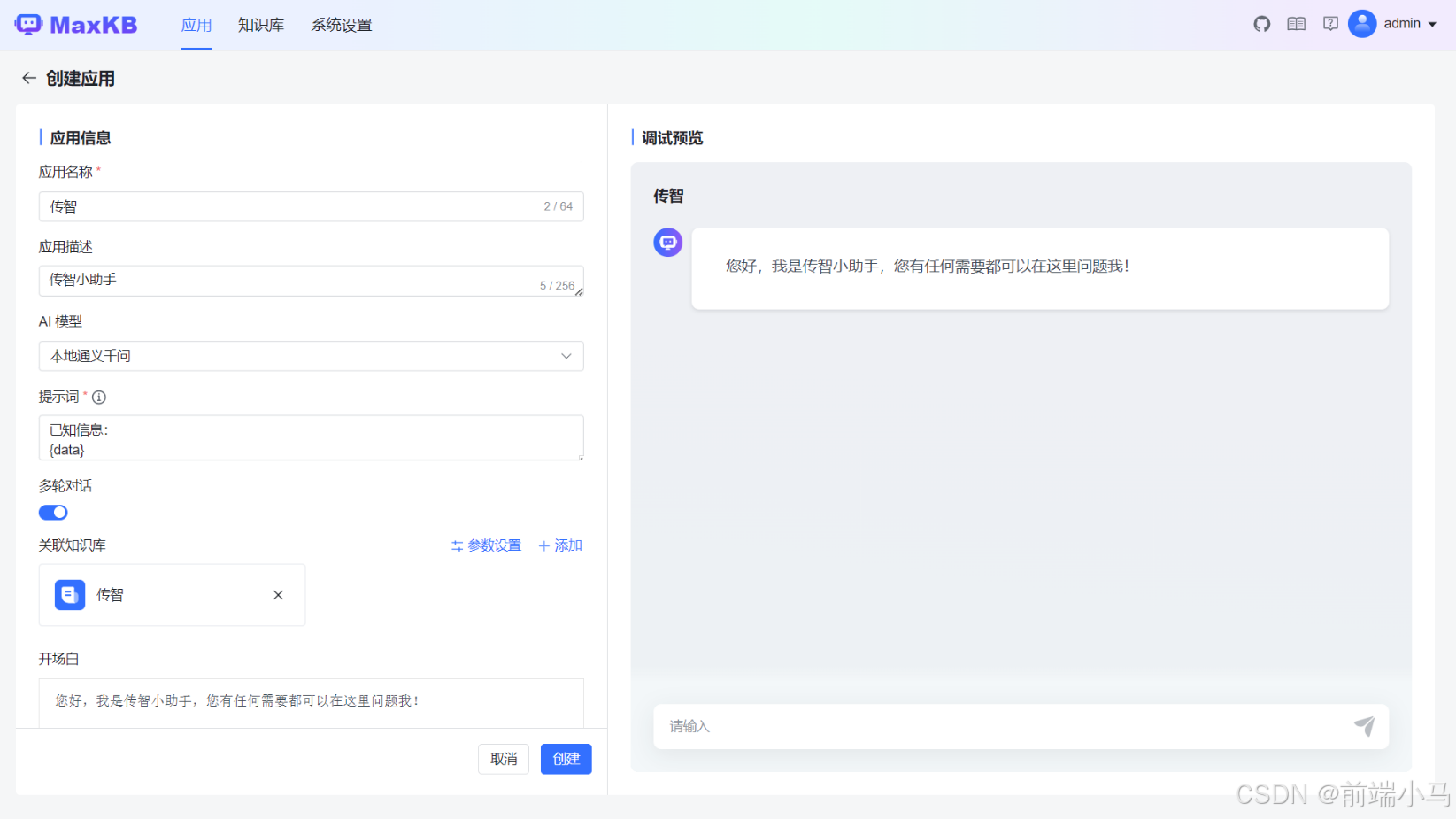
上一步只是测试把我们问题与知识片段进行关联,接下来还需要把这些内容都告诉大模型,这样便能提供大模型的回答准确性。而这个过程还是通过应用来操作,因此可新建一个叫传智的应用:
这里填写的信息与白板应用有两项是有区别的:
关联知识库:白板应用直接与大模型对话,因此无知识库,而现在,我们希望其回答传智的问题更加的专业,因此绑定上了传智知识库。
提示词:白板应用的提示词仅是用户输入的问题,而这里的提示词,需要把问题命中的知识与问题一并传给 大模型,因此需要进行占位符处理:
已知信息: {data} 回答要求: - 请使用简洁且专业的语言来回答用户的问题。 - 如果你不知道答案,请回答“没有在知识库中查找到相关信息,建议咨询相关技术支持或参考官方文档进行操作”。 - 避免提及你是从已知信息中获得的知识。 - 请保证答案与已知信息中描述的一致。 - 已知信息中的图片、链接地址和脚本语言请直接返回。 - 请使用与问题相同的语言来回答。 - 回答的语言要干练。 问题: {question}这里提示词结构被设计成三部分:
已知信息:即通过问题在知识库中命中的知识片段信息,这里使用{data}占位符表示
回答要求:可以设定大模型回答问题时的语言风格
问题:即用户输入的原问题,这里使用{question}表示
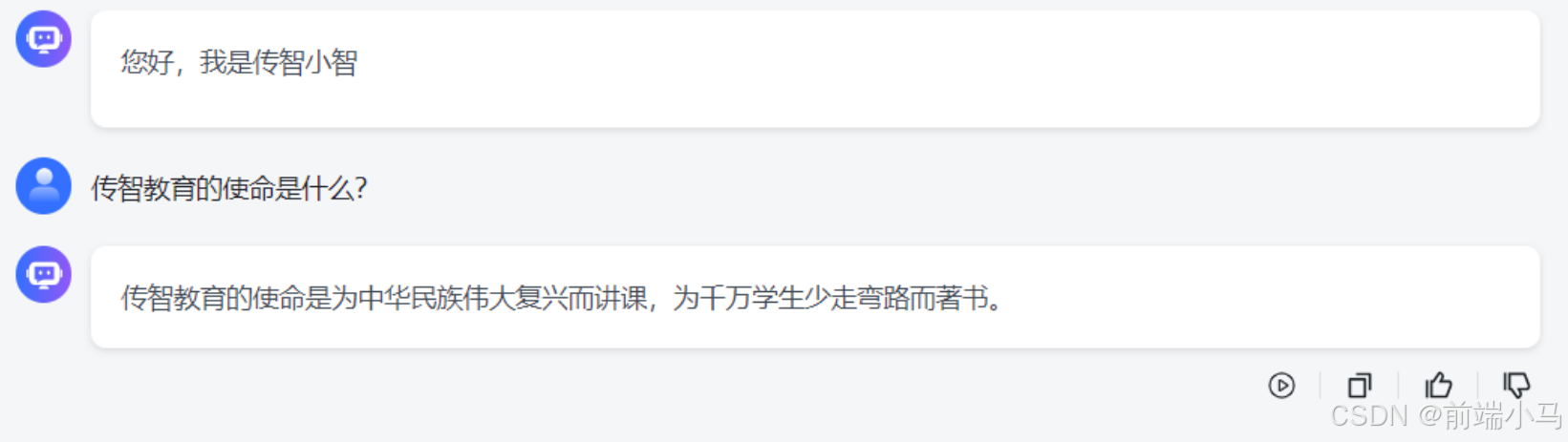
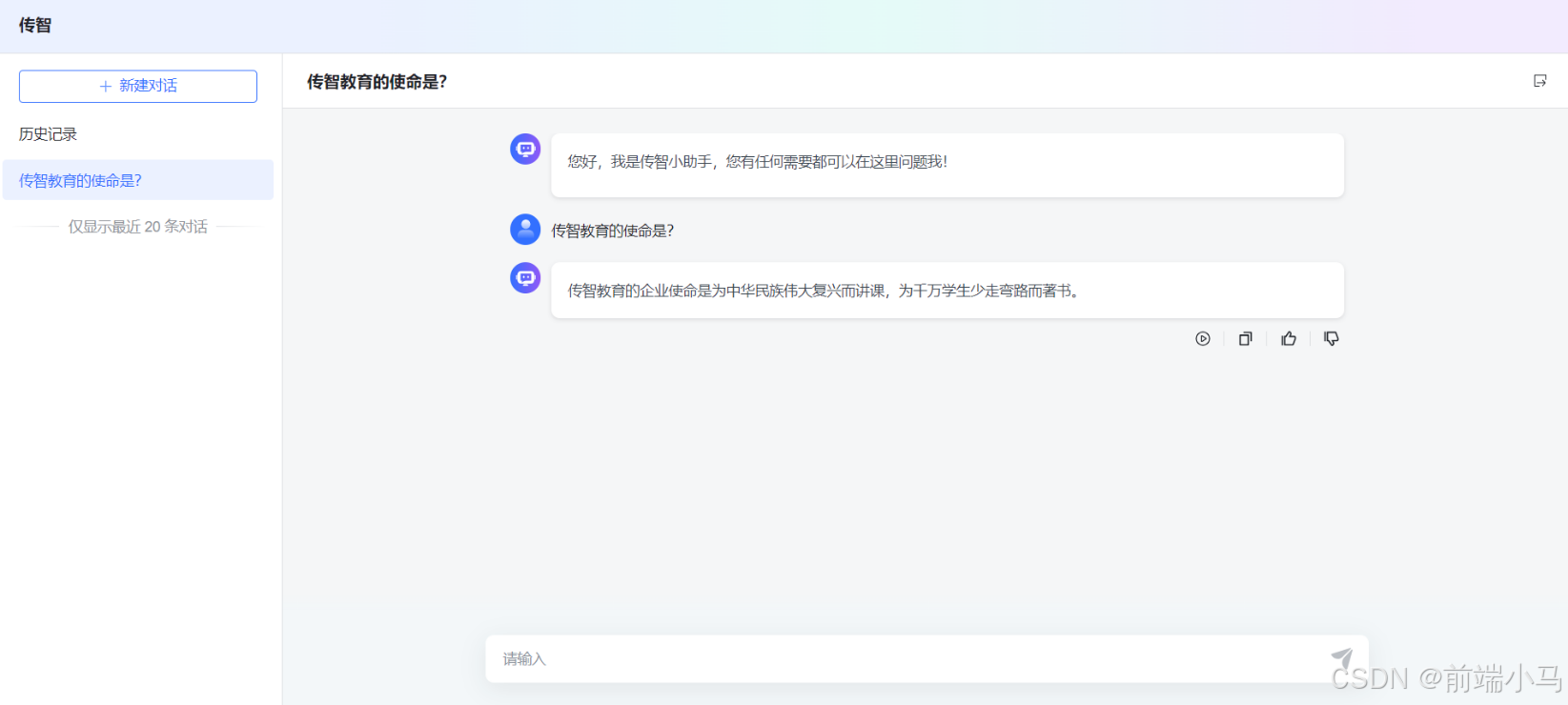
(5)使用应用
在应用列表中找到新增的应用,并点击演示按钮,进入到应用对话界面,然后再次对话,即可看见大模型回复的内容变得非常精准:
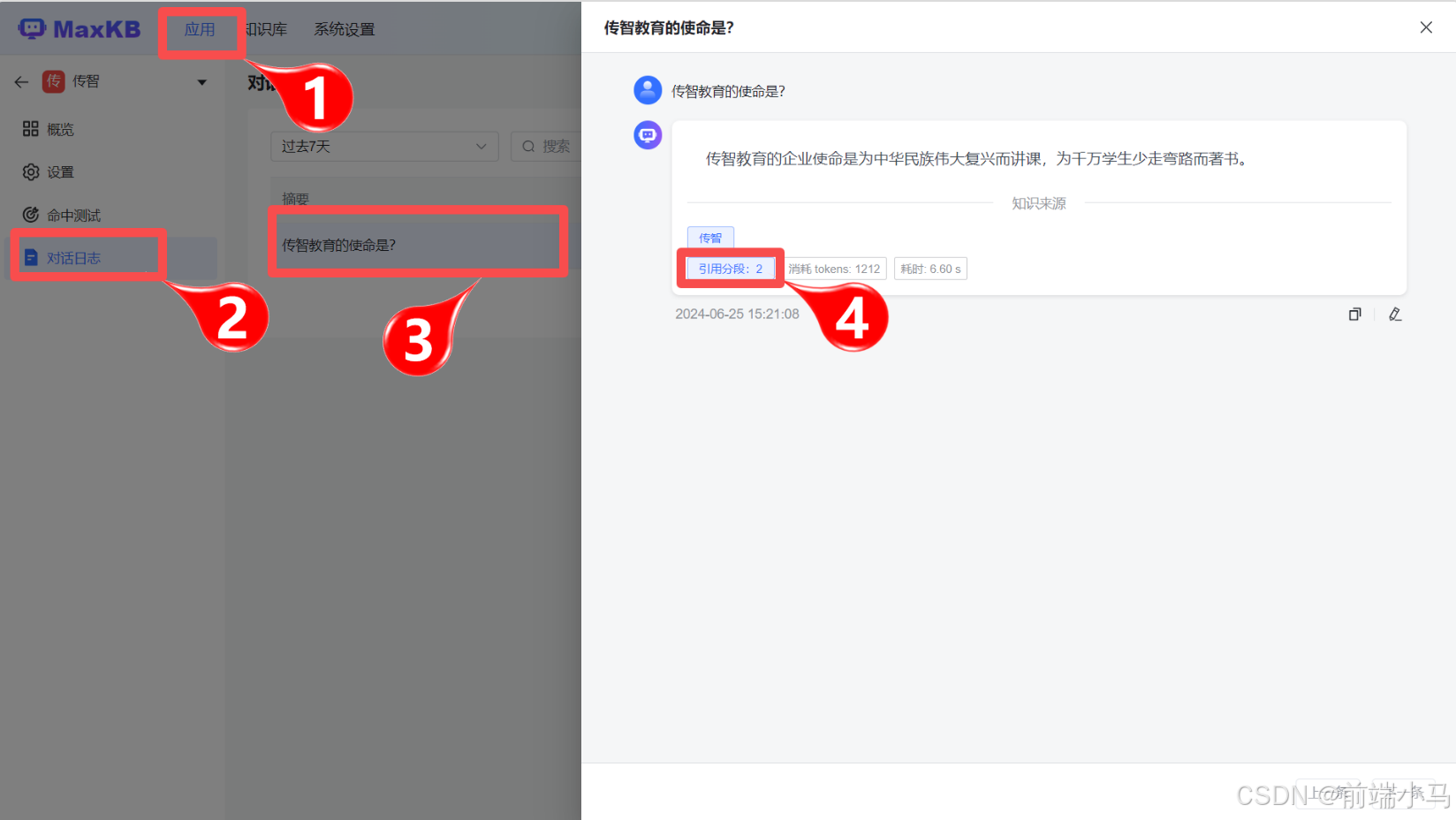
(6)查看对话日志
为了证实在上述对话中,使用到了知识库,则可以通过对话日志来进行查看。
通过上图操作,即可弹出对话中使用到的知识片段详细界面,进而说明在传智应用中与大模型对话,使用到了知识库知识。
6. QA知识库&应用
MaxKB除了支持文本文件上传之外,还支持QA问答对的文档导入,这种方式对导入数据格式是有要求的,相对效果也文本文档略好,因此接下来也演示一下这种方式。
(1)准备数据
我们准备搭建一个面试题知识库,用到的面试题放在【资料\知识库\Redis训练数据.md】文件中,可以看的这个训练数据是一个markdown文件,而MaxKB训练数据要求的格式为Excel文档:
因此这里可以写一个类,通过EasyExcel来把训练数据转出需要的格式:
<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.8.28</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.32</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>easyexcel</artifactId> <version>4.0.1</version> </dependency> public class ETLData { public static void main(String[] args) throws FileNotFoundException, InterruptedException { List<String> lines = FileUtil.readUtf8Lines(new File("资料\\知识库\\1.md")); StringJoiner temp = new StringJoiner("\n"); StringBuffer tempCont = new StringBuffer(); String tempTile = ""; List<TData> list = new ArrayList<>(); for (String line : lines) { line = line.trim(); if(line.startsWith("##")){ if(tempTile!=""){ temp.add(tempCont.toString()).add(tempTile); list.add(new TData(tempTile,tempCont.toString())); } tempTile = line; tempCont = new StringBuffer(); }else if(line!=""){ tempCont.append(line); } } if(tempTile!=""){ temp.add(tempCont.toString()).add(tempTile); list.add(new TData(tempTile,tempCont.toString())); } EasyExcel.write(new FileOutputStream(new File("C:\\Users\\luoxu\\Desktop\\1.xlsx")), TData.class) .sheet("Redis面试题") .doWrite(list); Thread.sleep(10000); } @Data static class TData { @ExcelProperty(value = "分段标题(选填)") String category; @ExcelProperty(value = "分段内容(必填,问题答案,最长不超过4096个字符)") String content; @ExcelProperty(value = "问题(选填,单元格内一行一个)") String title; public TData(String title,String content){ this.title = title; this.content = content; this.category = title; } } }(2)创建知识库
创建一个新的知识库,然后参考下图填写信息和选择训练数据。
填写完成后,点击【创建并导入】按钮 ,由于不需要分割文本,因此就直接进入了导入页面,并创建完成知识库。
(3)创建应用
创建一个新的应用,并按照下图进行填写,并点击【创建】按钮创建应用。
这里填写的提示词格式是:和传智应用的格式类似,只是修改了一些回答要求。
已知信息: {data} 回答要求: - 请使用简洁且专业的语言来回答用户的问题。 - 如果你不知道答案,请回答“没有在知识库中查找到相关信息,建议咨询相关技术支持或参考官方文档进行操作”。 - 避免提及你是从已知信息中获得的知识。 - 请保证只返回会题目相关的信息,不返回多余的信息。 问题: {question}(4)使用Redis面试应用
我们先用白板应用对话,然后对比Redis面试对话,好体验出效果。首选看看白板对话:
再看看引入知识库的Redis面试应用效果:
对比两种效果,可以发现,接入知识库的效果,非常专业和精确。


7. 通过API调用MaxKB
(1)导入API
MaxKB创建好应用之后,也可以通过A PI接口,让其它应用程序来访问。目前MaxKB提供了3个API接口:
这三个接口也在资料文件夹下提供了Apifox的json文件MaxKB.apifox.json。为方便测试,可以先导入到Apifox中:
(2)获取应用信息
导入成功之后,会看见三个接口,这三个接口是存在调用前后关系的,如:
首选需要调用【获取应用信息】,获得【应用id】
然后调用【创建一个会话】接口,获得【会话id】:这个接口会用到【应用id】
最后调用【应用对话接口】,即可正常对话:这个接口会用到【应用id】和【会话id】
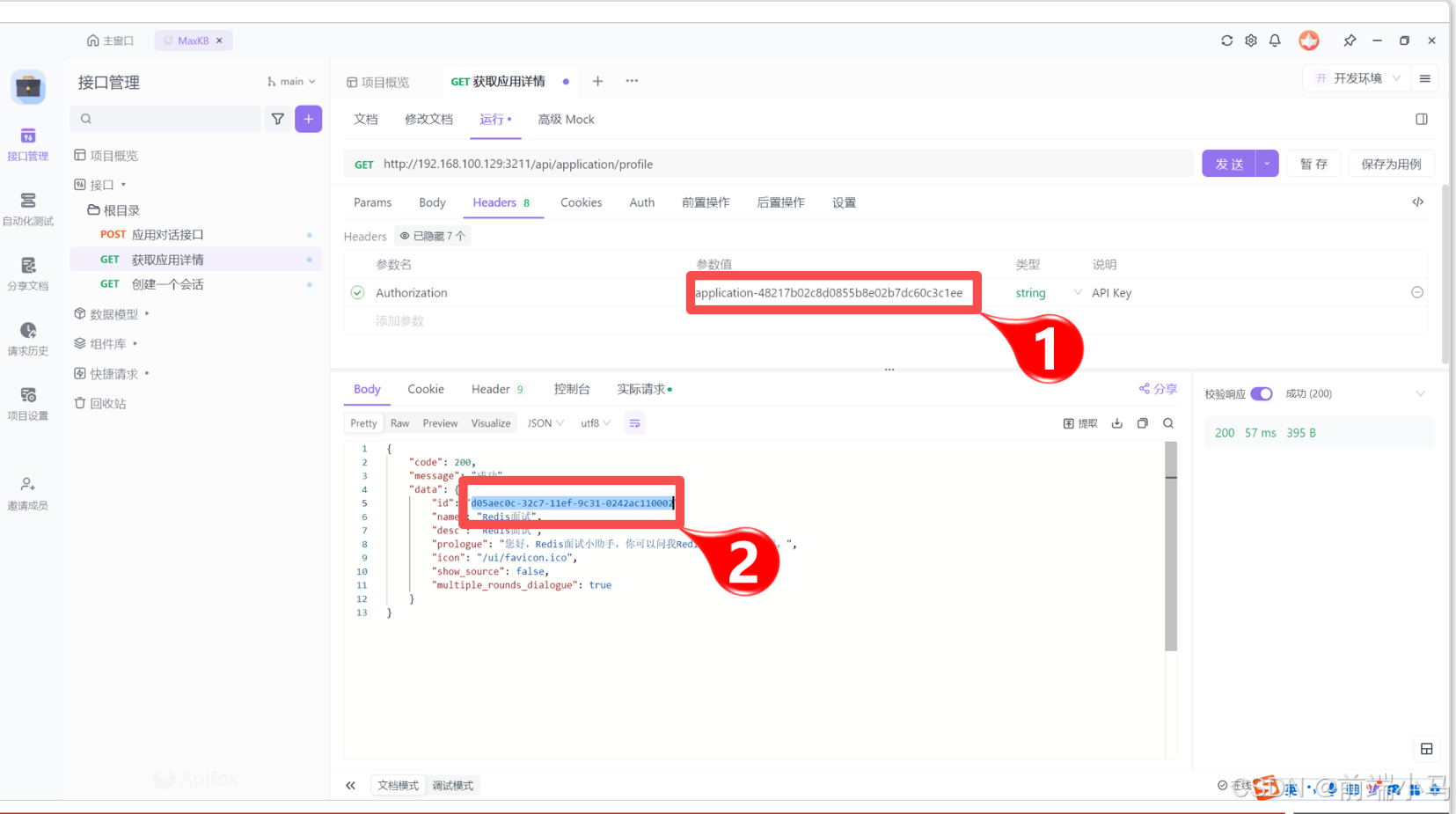
因此这里可以先调用【获取应用接口】:
Step 1:拷贝API Key
在应用信息中,点击【API Key】按钮弹出API Key窗口:
第一次进入,可以点击【创建】按钮,创建一个key,然后点击复制按钮:
Step 2:设置并发起请求
在Apiffox中,进入【获取应用详情】,设置好开发环境之后,再把复制的API Key张贴到1号位置,然后点击【发送】按钮,得到响应结果中id字段即为应用id,选择值并复制,供下一个接口使用。
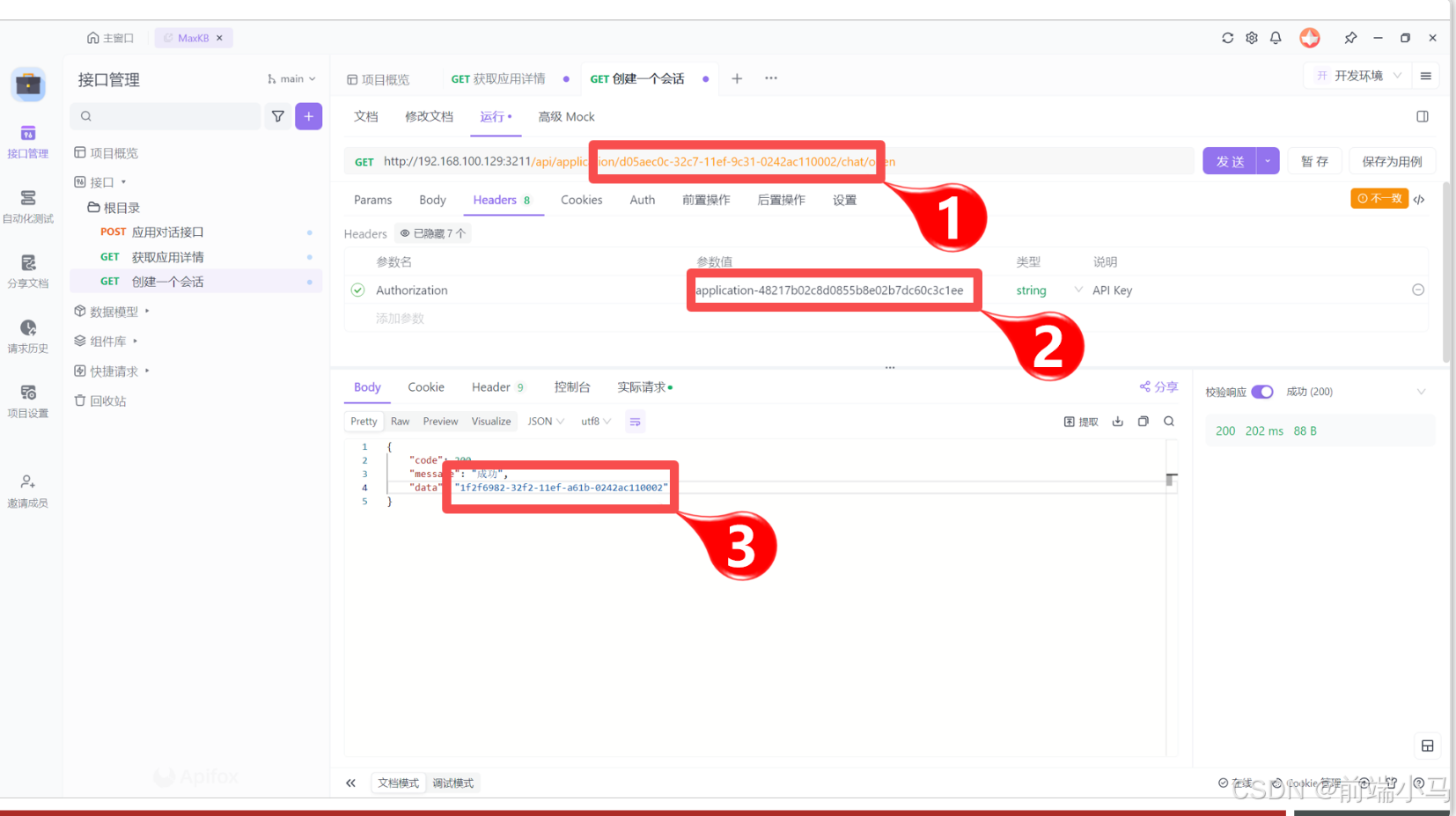
(3)创建一个会话
打开【创建一个会话】接口,粘贴到1号位置,然后再把API Key粘贴到2号位置,并点击【发送】按钮,即可在响应数据中得到3号位置的会话id,选择值并复制,供对话请求使用。
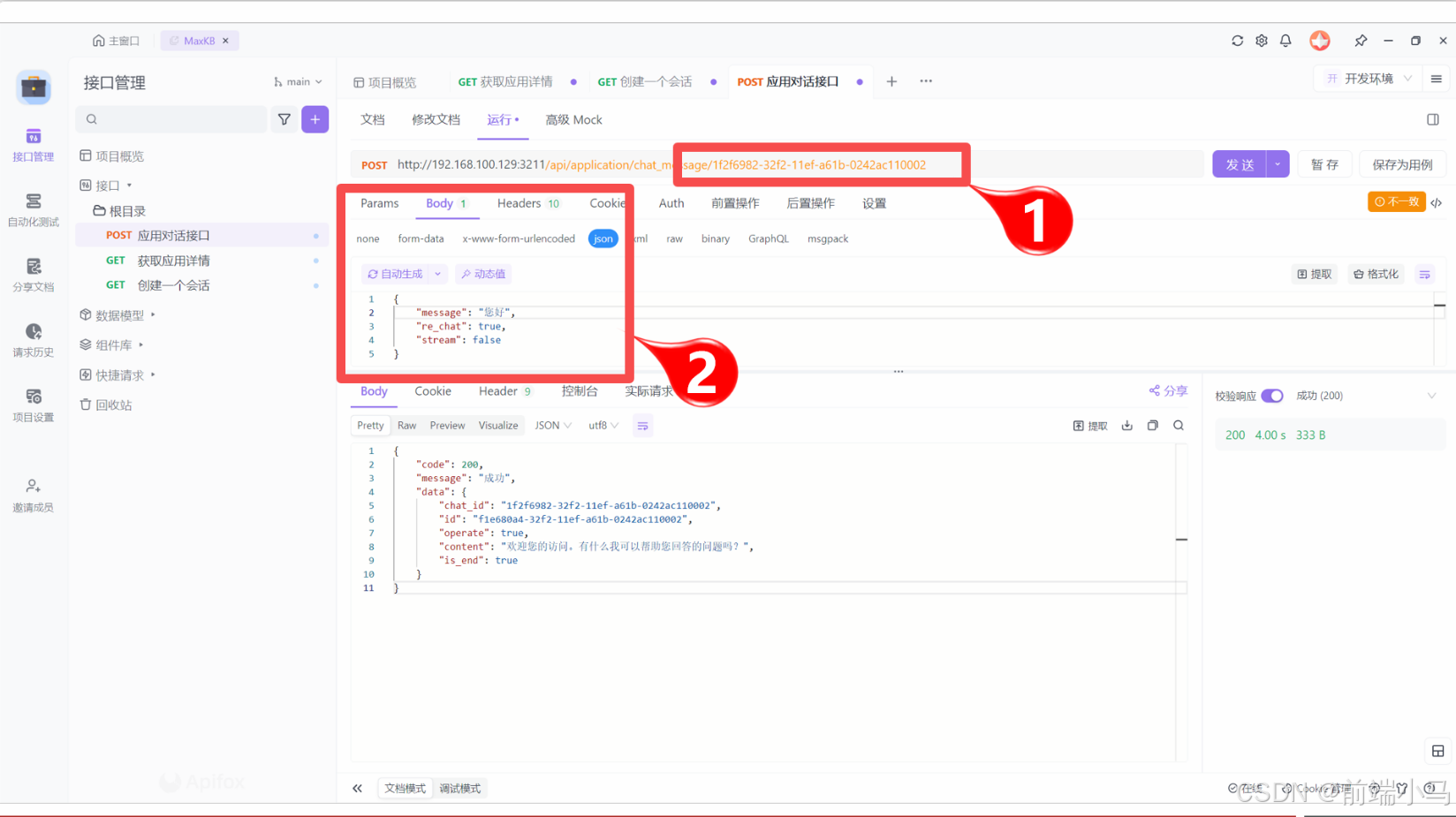
(4)通过API进行对话
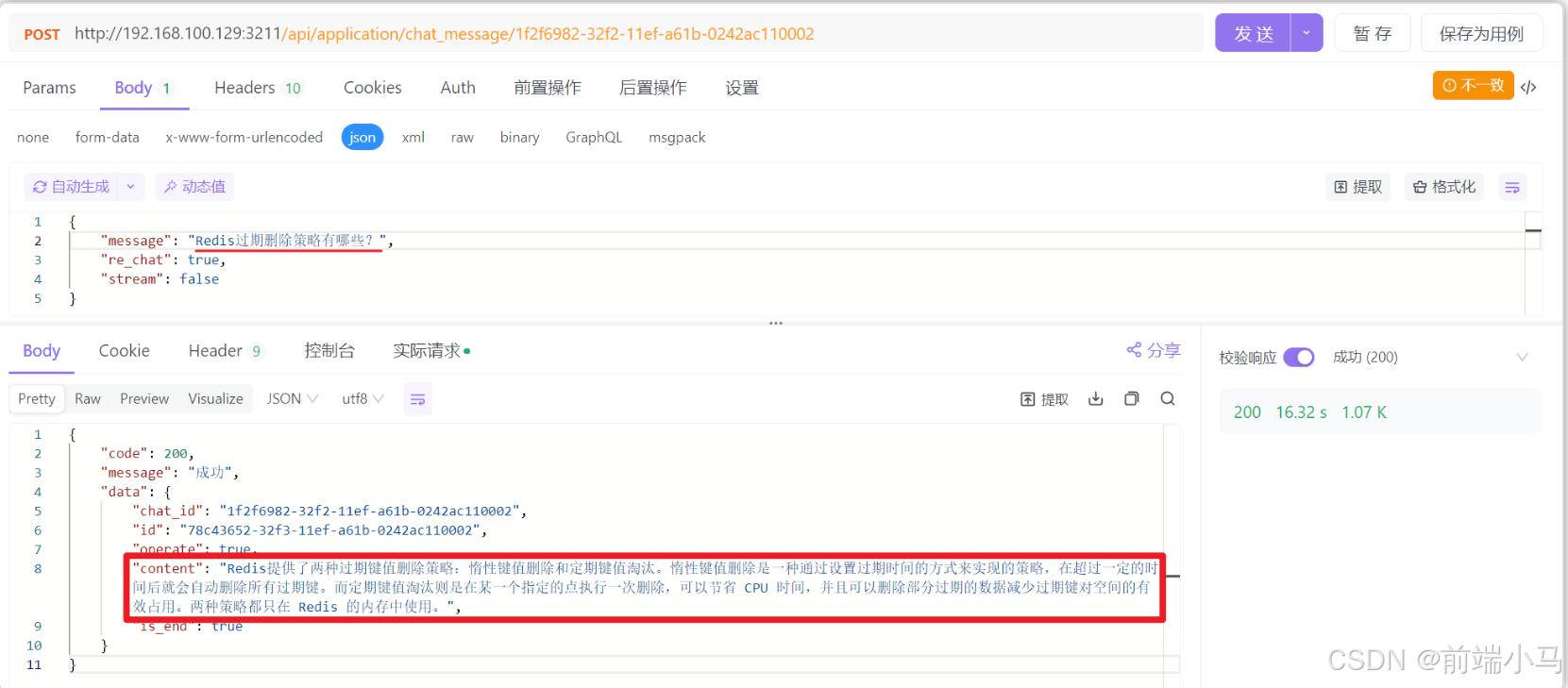
把上一步复制的会话id,粘贴到1号位置,然后在2号位置设置API Key和请求的Body信息,然后点击【发送】按钮即可开始与MaxKB对话。
同时通过API也可以引用知识库获得精确的回复。

8. Continue与Ollama快速集成
在前面的学习的LobeChat可以让企业快速搭建私有对话模型解决数据泄密等安全问题,MaxKB可以把企业内部信息融入到大模型中,解决私有域数据不能被访问的问题。而Continue,则是面向企业内部程序员的,用于帮助程序员开始生成代码、代码排错的,与通义灵码类似,但相比通义灵码,企业结合Continue+Ollama可以更好的避免内部价值代码的安全,不被传输到外网。
Continue是什么:
Continue:领先的开源AI代码助手。可以通过Continue连接大模型,在IDE中完成自动代码提示与聊天。
Continue的功能特点包含:
支持丰富的大模型
支持丰富上下文内容
支持丰富的扩展
安装Continue:
Continue在IDEA中是一个插件,进入插件市场搜索并安装,最后点击【ok】按钮即可。
Continue集成Ollama:
点击右侧Continue的图标,即可打开Continue的使用页面,首次打开,需要配置连接那个大模型。
选择本地大模型,进入先一步模型选择,注意这里默认链接的是本机大模型,因此看不见大模型,可直接【Continue】跳过此步
下一步的页面,就是使用页面,但由于连接不上本地大模型,可能会导致idea卡死,如遇见此情况,可以重启idea即可。
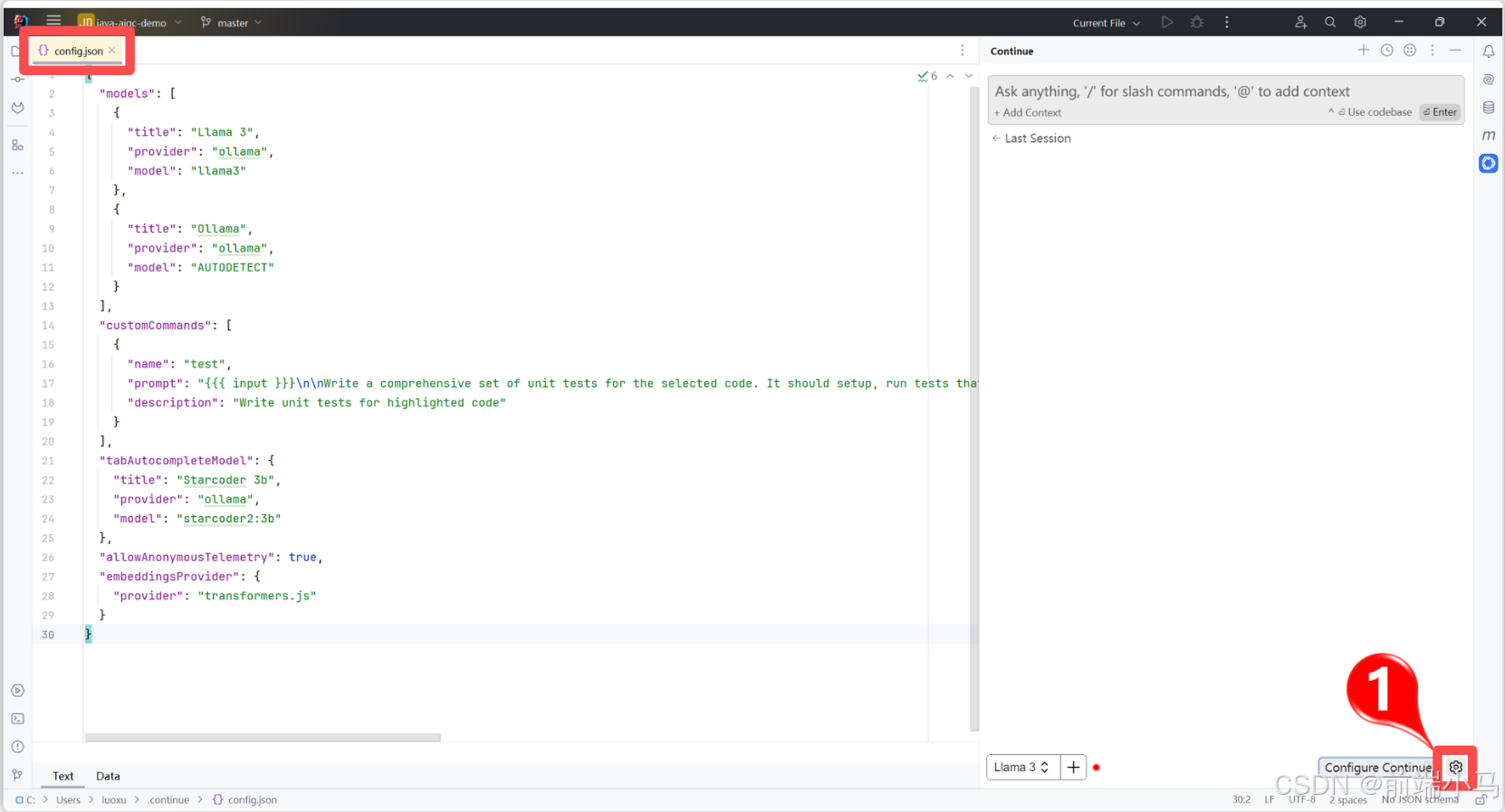
重启Idea后,在此进入Continue页面,然后点击【配置】按钮,打开配置文件。
然后修改配置文件内容为一下内容,然后重启IDEA。
{ "models": [ { "title": "通义千问", "model": "qwen2.5:0.5b", "completionOptions": {}, "apiBase": "http://192.168.100.129:11434", "provider": "ollama" } ], "tabAutocompleteModel": { "title": "通义千问", "model": "qwen2.5:0.5b", "completionOptions": {}, "apiBase": "http://192.168.100.129:11434", "provider": "ollama" }, "embeddingsProvider": { "provider": "transformers.js" } }配置字段说明:
models:声明可用的大模型列表
title:大模型名称
model:大模型的实际名称,需要与ollama list中名称一致
completionOptions:配置选项
apiBase:ollama的访问地址
provider:大模型提供商类型
tabAutocompleteModel:配置编辑器自动提示使用的大模型信息
embeddingsProvider:指定向量提供商类型
重启IDEA之后,即可在Continue中使用正常与大模型对话:
使用Continue自动代码提示:
注意:使用私有的Continue时,为避免与通义灵码等插件的功能冲突,需要先卸载通义灵码。
Continue提供了通过Tab键进行代码生成提示的功能,但是默认此功能是关闭的,因此要使用则需要在Setting中开启相关功能
确定后,返回编辑器即可使用Tab提示功能
七. Stable Diffusion入门
1. Diffusion Model 扩展模型
回顾前面学习过程中,我们了解到,当下市场常见的大模型分类有:
大语言模型:用于文生文,典型的使用场景是:对话聊天—仅文字对话
Qwen、ChatGLM3、Baichuan、Mistral、LLaMA3、YI、InternLM2、DeepSeek、Gemma、Grok 等等
文本嵌入模型:用于内容的向量化,典型的使用场景是:模型微调
text2vec、openai-text embedding、m3e、bge、nomic-embed-text、snowflake-arctic-embed
重排模型:用于向量化数据的优化增强,典型的使用场景是:模型微调
bce-reranker-base_v1、bge-reranker-large、bge-reranker-v2-gemma、bge-reranker-v2-m3
多模态模型:用于上传文本或图片等信息,然后生成文本或图片,典型的使用场景是:对话聊天—拍照批改作业
Qwen-VL 、Qwen-Audio、YI-VL、DeepSeek-VL、Llava、MiniCPM-V、InternVL
语音识别语音播报:用于文生音频、音频转文字等,典型的使用场景是:语音合成
Whisper 、VoiceCraft、StyleTTS 2 、Parler-TTS、XTTS、Genny
扩散模型:用于文生图、文生视频,典型的使用场景是:文生图
AnimateDiff、StabilityAI系列扩散模型
而接下来我们将学习如果利用大模型进行图片的创作,这就要用到扩散模型的相关知识,因此先来看看什么是扩散模型。
谈及扩散模型,需要先理解扩散这一核心概念,扩散这个词源自物理学中的现象,指物质由高浓度区域向低浓度区域移动的过程,是一个自然趋向于平衡状态的过程。
而在人工智能(AI)领域,“扩散”并不指物质在空间中的移动,而是指数据样本点的分布向标准正态分布不断靠拢的过程。这个解释从专业的角度非常难以理解,因此我们在此只需要把人工智能的扩散理解成是高浓度的马赛克(也称为噪声)向低浓度区域移动的过程。
扩散模型(Diffusion Models)就是基于扩散思想的深度学习生成模型,它们在多个领域,尤其是图像生成任务中展现出了强大的能力。
在前些年,生成式图片领域使用的技术主要是GAN【全称是生成对抗网络(Generative Adversarial Network)】,是一种由Ian Goodfellow等人在2014年提出的机器学习模型。直到 2020 年,提出的 DDPM【去噪扩散概率模型(Denoising Diffusion Probabilistic Model)】模型向世界展示了扩散模型的能力,在图像合成方面击败了 GAN,所以后续很多图像生成领域开始转向 DDPM 领域扩散模型的研究。就当下市面上生成式图模型OpenAI 的 DALL·E 2 和 Google 的 Imagen,都是基于扩散模型来完成的。
扩散模型也细分文前向扩散和反向扩散,通过模拟一个前向扩散过程将图片数据逐渐转换为噪声,并随后通过一个反向扩散过程将噪声逐渐还原为原始图片数据。
前向扩散:图片转为马赛克—用于扩散模型的训练
反向扩散:马赛克转为图像—用于图像的生成


2. Stable Diffusion 稳定扩散模型
Stable Diffusion(全称稳定扩散模型,简称SD)是一种先进的深度学习模型,也是主流的用于高质量图像生成的模型,根据文本描述生成图像(text-to-image)。
Stable Diffusion,是一个 2022 年发布的文本到图像潜在扩散模型,由 CompVis、Stability AI 和 LAION 的研究人员创建的。要提到的是,Stable Diffusion 技术提出者 StabilityAI 公司在 2022 年 10 月完成了 1.01 亿美元的融资,估值目前已经超过 10 亿美元。
Stable Diffusion的代码和模型也是开源免费使用,可以在大多数配置了至少8GB VRAM的普通GPU的消费级硬件上运行,甚至在CPU上运行,这标志着Stable Diffusion和以往只能通过云服务访问的专有文本到图像模型(如DALL-E和Midjourney)完全不同。
Stable Diffusion也被称为稳定扩散模型,相比扩散模型的区别主要表现为:
高质量输出:通过引入稳定性指数,显著提高了模型的稳定性,使得生成的图像质量更加一致,更符合输入需求;
高效率输出:通过优化模型结构和算法,提高了计算效率(可以使用常规显卡运算),能够在较短时间内生成高质量的图像;
开源免费

3. Stable Diffusion 基本结构与原理
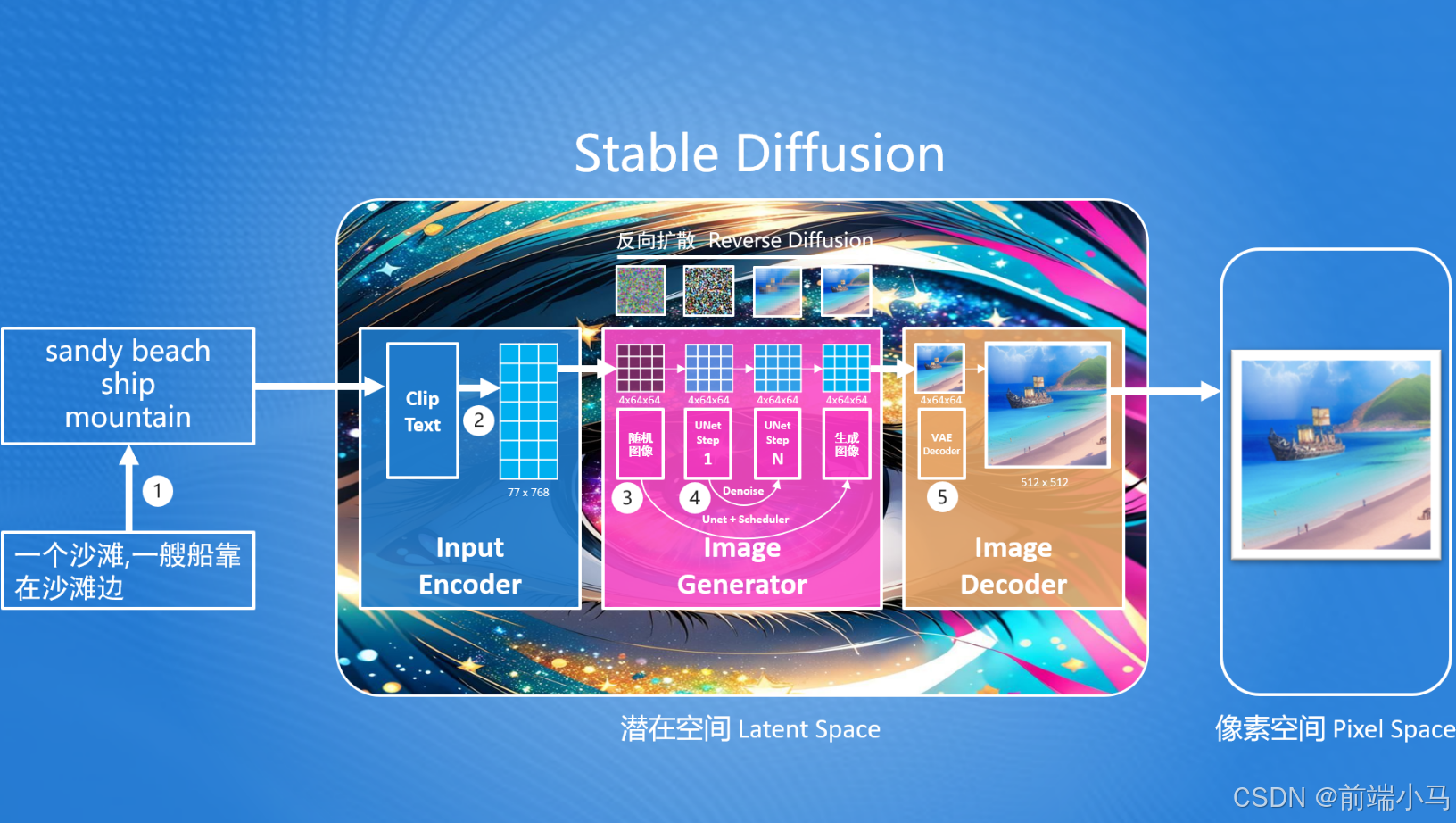
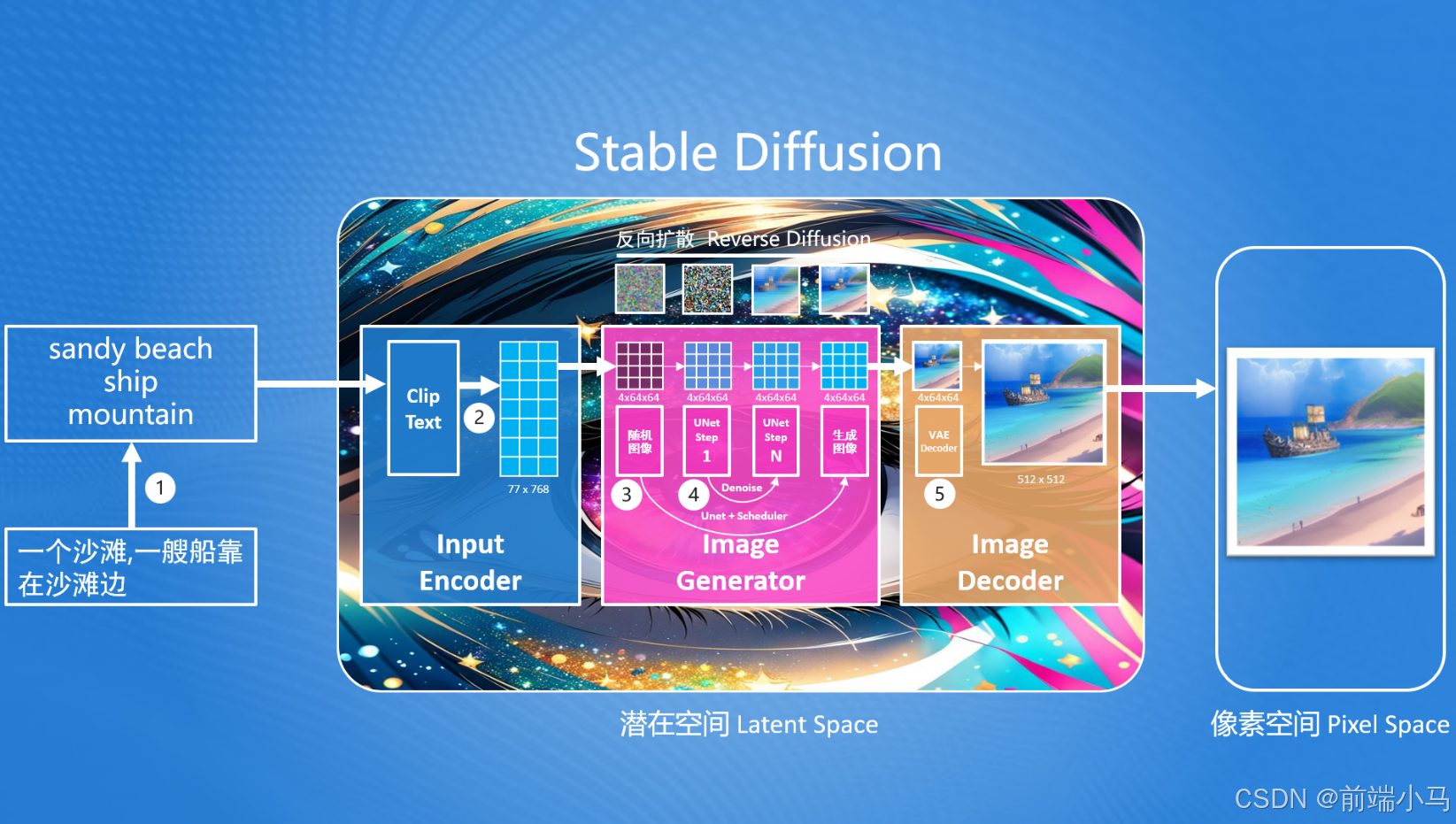
虽然Stable Diffusion作为扩散模型的变体模型,但在实现图片生成的思想上依然和扩散模型一致,且通过反向扩散过程的思想来完成图片生成。
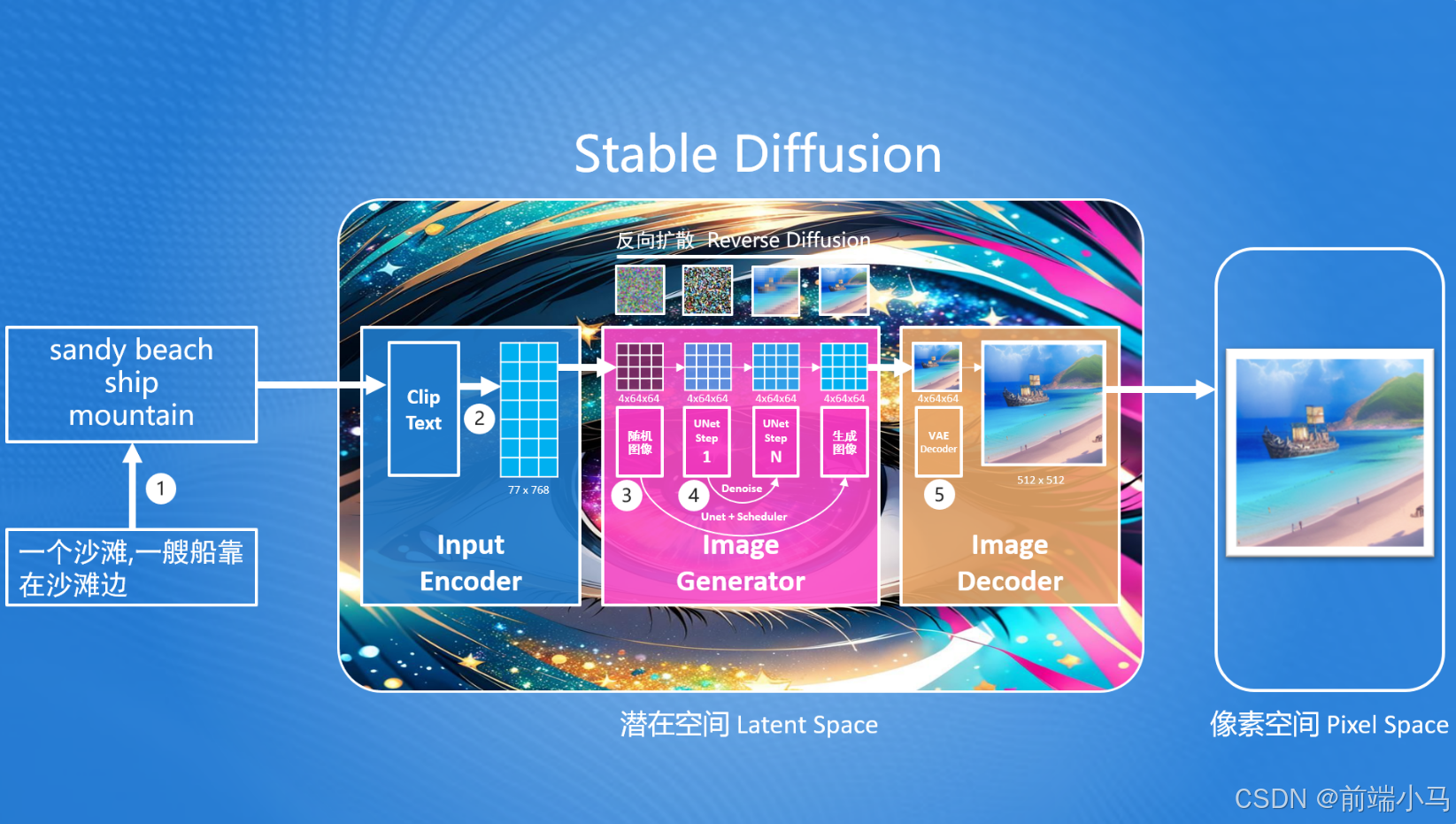
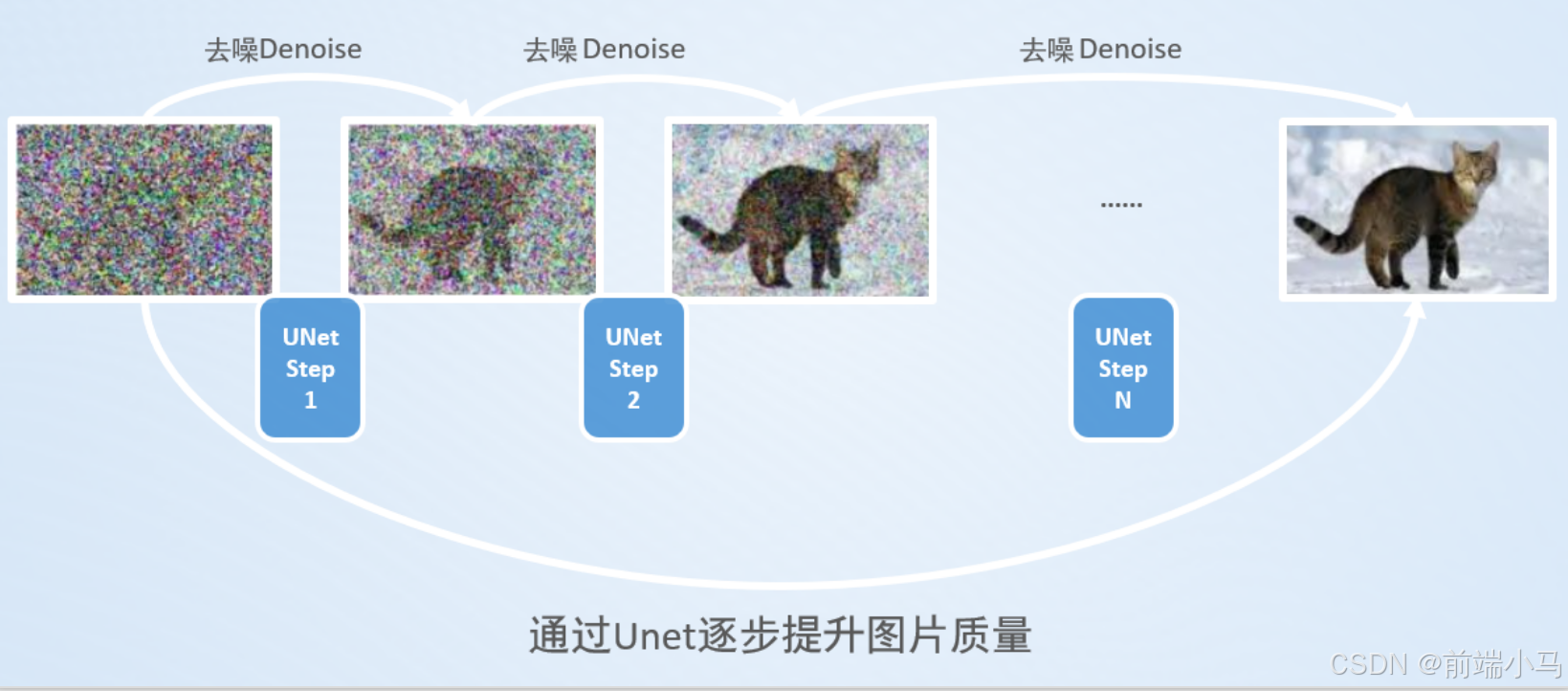
在Stable Diffusion的核心思想中,首先生成一张噪声图(最左边—马赛克图),然后按照用户输入的提示词,去除噪声图中的部分信息,就生成一张跟文本信息匹配的图片。整个生图流程如下:
而在这个中,Stable Diffusion首先要解决的问题就是:如何把提示词转换成能够计算机理解的信息?
要解决问题的方案我们需要先掌握基本的Stable Diffusion流程,后续再进行该问题的详解。在Stable Diffusion中提供了一个文本编码器(Text Encoder),可以把输入的提示词转化成计算机大模型能理解和识别的数字(专业称为语义向量)。有了这个语义向量,就可以使用图片生成器(Image Generator)生成目标图像,这里生成目标图像就使用到了反向扩散模型的思路,但是注意这里生成的图像并不是最终的图片,而是一个低像素的图片,因此Stable Diffusion最终还需要通过一个图片解码器(Image Decoder)把生成的图片转成我们最终的图片。
从上图还不难发现,Stable Diffusion是在潜在空间中(Latent Space,也称潜空间)中生成的,而我们最终需要一张可以看得见图片,我们都知道在计算机中,所见到的图片是有像素组成的,因此称这张图片为像素空间(Pixel Space)的图片。而潜在空间中的图片不能直接在像素空间中使用,因此Stable Diffusion提供了图片解码器(Image Decoder)可以把潜在空间中的图片转为像素空间中的图片。
潜在空间(Latent Space): 一种比像素空间更小空间,在Stable Diffusion中,潜在空间比像素空间小48倍,这样设计可以减少计算机算力,并提高生成速度
综上所述,Stable Diffusion由3部分组成:
输入编码器(Input Encoder):把用户输入的内容转换提示词为语义向量(很长的一串数字);
图片生成器(Image Generator):结合语义向量,生成潜在空间图片;
图片解码器(Image Decoder):转换潜在空间的图片为像素空间中的图片;



4. Stable Diffusion 深度原理
在SD相关软件或开发过程中,需要经常用到涉及底层的基本概念,因此我们还需要进一步对其底层进行分析和了解,便于后面的学习。
在这里我们进一步放大SD内部结构,可以发现更多的内容细节暴露出来,其中包括:
①、SD模型只支持英文输入,因此用户输入的中文,需要先转出英文;(后续解释为什么只能是英文?)
②、输入编码器(Input Encoder)在内部时通过一个叫ClipText的组件把用户输入的文本内容转成语义向量的;
③、图片生成器(Image Generator)在内部时通过UNet+Scheduler来进行图片生成的,同时生成的过程是反向扩散的实现过程;
- ④、而在图片生成过程主要依据Denoise这个过程来重复迭代生成图片;
⑤、图片解码器(Image Decoder)在内部会通过VAE解码器把生成的潜空间图片,放大成像素空间的大小需求;
要充分理解上述的5个关键步骤,这里必须先理解什么是Clip、UNet和VAE。
(1)Clip是什么?
开源地址:https://github.com/mlfoundations/open_clip
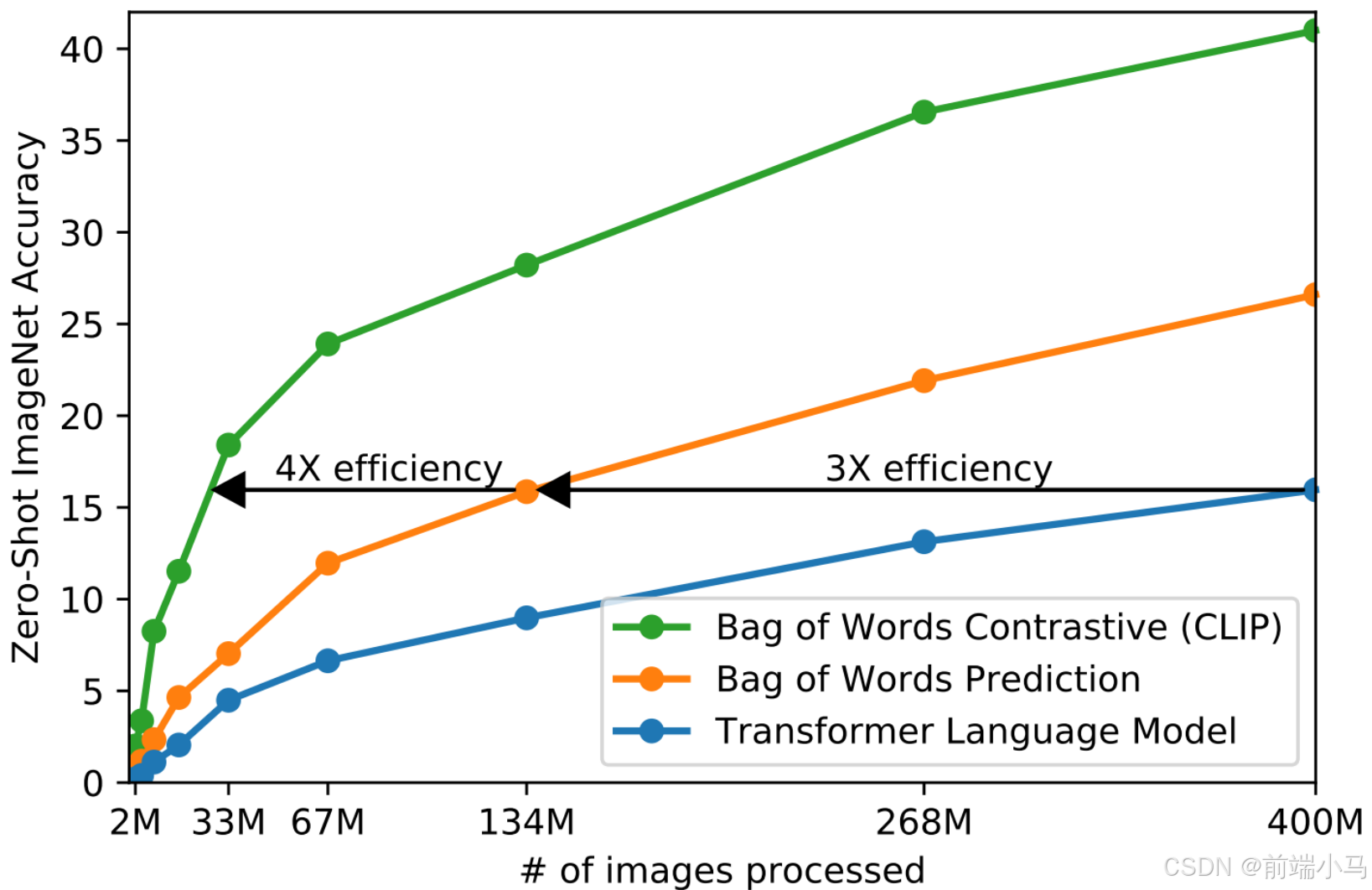
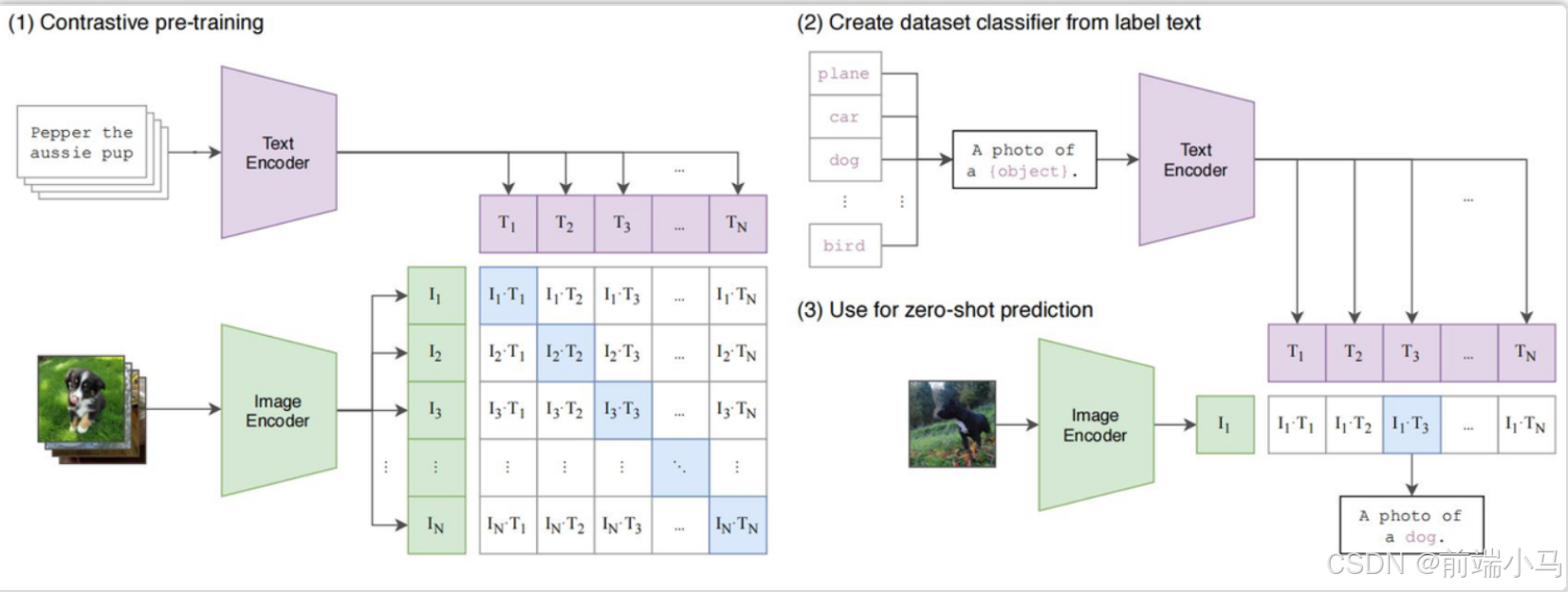
CLIP(Contrastive Language–Image Pre-training)对比语言预训练模型,由 OpenAI在2021年 提出,它能够理解并处理图像和文本,通过对它们进行对比学习(contrastive learning)来建立图像和文本之间的关联。简单来说Clip模型能把用户输入的文字需求,正确的理解成生成图片的需求。
CLIP的不仅训练数据多,大约有4亿多个(文本和图像),而且训练出的模型执行效率高,高出同类型模型的4到10倍,可以简单理解Clip目前是顶尖的文本与图像关联的模型。
Clip架构中主要有两大核心部分组成:
文本编码器(Text Encoder):把文本编码成向量;长度不超过77,如果超过会自动截断;
图片编码器(Image Encoder):把图片编码成向量;尽量是正方形;
这两大核心在Clip模型训练的过程中,在3个关键步骤中有被使用到:
1、对比训练:将一批配对好的图像和(英文)文本数据集(最开始数据集大小是32768对),分别通过文本和图片编码器分别生成对应的向量,再通过算法(余弦相似度、对称交叉熵损失等)来计算出文本和图片关联度最大的向量数据。
2、依据标注文本创建数据集分类器:使用文本编码器对大量图像及相关的(英文)文本描述生成向量,以此来训练出一个分类器,使得模型能够依据图像的特征来预测其所属的分类。
3、使用零样本预测:输入一张没有在训练数据集中的图片,通过图片编辑器转成向量,然后利用第2步的分类器,对向量进行分类处理,通过得到的分类,我们即可知悉图片中的信息是什么。这意味着即使模型在训练过程中没有见过这些新图像,通过使用零样本预测Clip模型也可知悉图片中的内容。
通过上述了解的内容,可以了解到Clip的训练过程中使用的文本都是英文的,因此就解释了为什么SD需要把中文转出英文后处理。
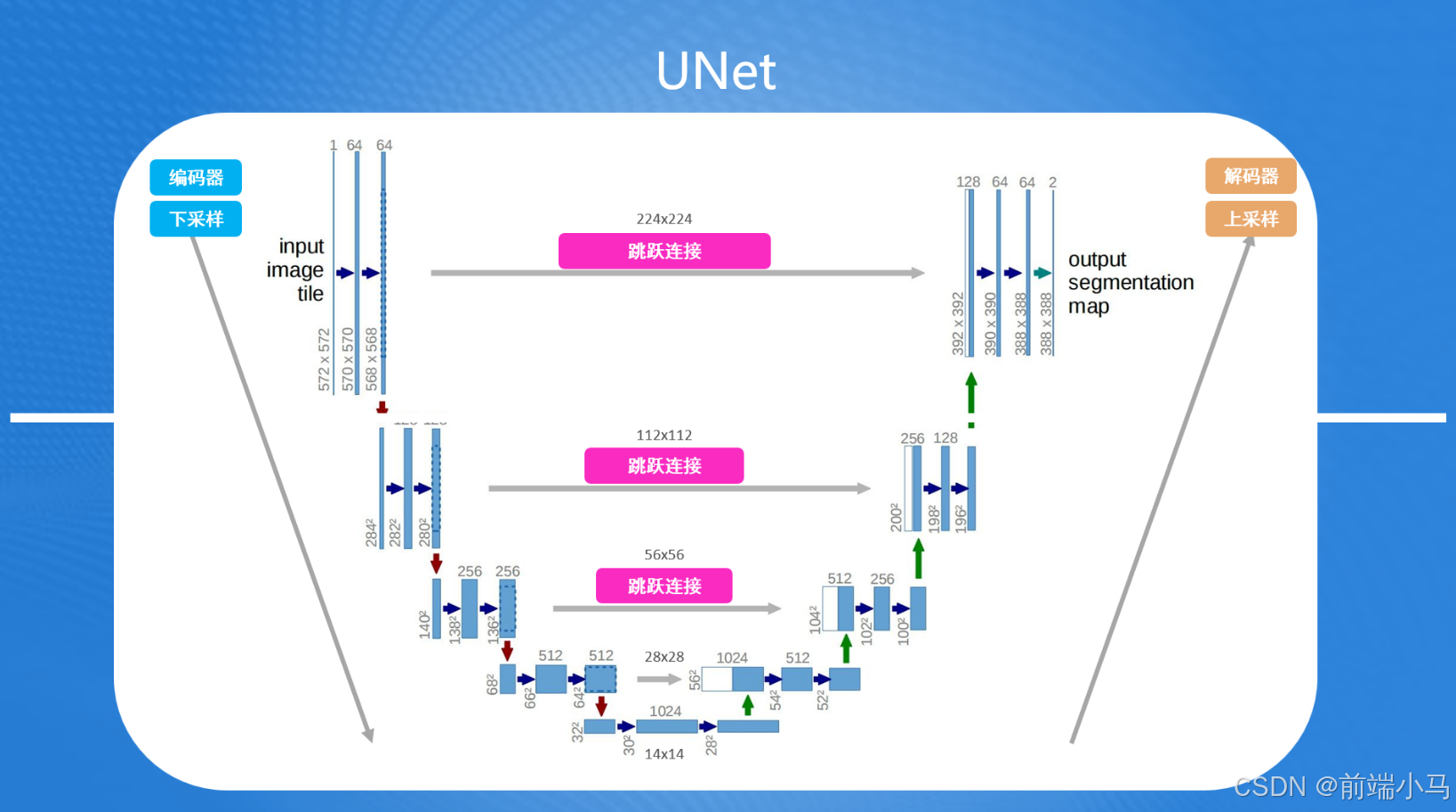
(2)UNet是什么?
UNet是一种用于图像分割的卷积神经网络架构。可以把输入的图片分割成具有一定语义含义的区域块,识别出每个区域块语义类别,最终得到与原图像等大小具有逐像素语义标注的分割图像。
随着UNet的发展,人们很快就发现UNet架构的设计非常巧妙,不仅能用于图片分割,还能用于提升图片的细节和质量。
UNet的结构主要包括编码器和解码器两部分,提升图片质量主要通过这两部分来完成:
- 编码器:主要用来提取出图片中的特征信息,并逐渐降低图像的空间维度,这个过程也称下采样过程。比如一张224x224的图像,首先下采样变为112x112,然后变为56x56,28x28,最后图像大小缩至14x14。每次下采样尺寸的缩小都是为了捕获图像的细节特征,同时减少计算量。
解码器:主要用把低维度空间的图片还原成原来尺寸,并在过程中融合图片的细节,这个过程也称为上采样过程。
上采样和下采样相反,首先通过14x14生成28x28的尺寸,然后再把生成的图片与之前下采样过程中的28x28图片进行融合,接着再用融合的图片生成56x56的图片,再融合,以此类推,直到复原原有尺寸为止。
在这个过程中上采样生成的图片与下采样生成的图片融合,被称为跳跃连接(Skip Connection),它能在融合过程不仅保留了图像的全局信息,也精确地恢复了局部细节
UNet框架最开始由Olaf Ronneberger等人在2015年提出,主要用于解决医学图像分割的问题。但随着AI技术的发展,UNet能提高图片质量的特性很快就被应用于Stable Diffusion框架,用UNet来提升一张质量不高(带有很多噪声)的图片,并重复数十次这个过程,最终得到一张高质量的结果。
除此之外U-Net在Stable Diffusion中的应用还表现在:
细节的捕捉与增强:Stable Diffusion利用U-Net的跳跃连接来维持和增强图像的细节。这些连接允许在生成过程中直接使用来自编码器的高分辨率特征,从而在解码器阶段细化图像的细节。
多尺度特征融合:通过U-Net的编码器-解码器结构,Stable Diffusion能够融合不同尺度的特征,这对于生成与文本描述相匹配的复杂图像至关重要。这种结构使模型能够在保持全局一致性的同时,精确控制图像的局部细节。
迭代细化:Stable Diffusion在图像生成过程中采用迭代细化的策略,每一步都利用U-Net架构对图像进行进一步的优化和细化。这种方式使得最终生成的图像不仅细节丰富,而且与输入的文本描述高度一致

(3)VAE是什么?
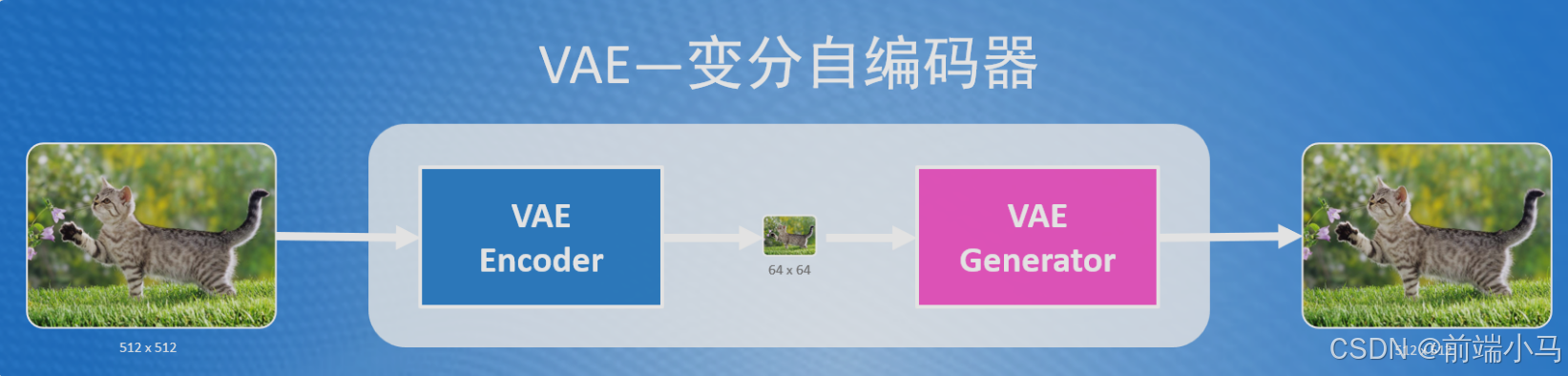
AE(auto-encoders)自编码器,是一种数据维度压缩算法,能够把高维度的数据通过AE编码(Encoder)将数据压缩成低维空间,比如把3维空间的数据压缩成2为空间的数据。维度下降之后,数据量更小,进行数据计算更加的高效。计算完成之后还可以通过AE解码(Decoder)将低维度数据提升为高维数据。
而VAE(Variational AutoEncoder 变分自编码器)和AE类似,但比AE的更加的先进和复杂。在Stable Diffusion中对于输入的图片,会先用VAE编码器(VAE Encoder)把像素空间中的图片,压缩为潜空间数据,比如下图中通过VAE编码器把512x512的图片压缩后变成了64x64的大小,最后再通过VAE解码器(VAE Decoder)把潜空间中的图片返回成像素空间的大小。
小知识点:
在SD中,像素空间中的图片,每个像素点使用RGB3通道(可简单理解成3个数字)来存储其值,因此512x512大小的图片,在SD中存储的大小为512x512x3
在SD中,潜空间图片,每个像素点使用RGBA4通道(可以简单理解成4个数字)来存储其值,因此64x64大小的图片,在SD潜空间中实际大小为64x64x4
综合上述两点,通过VAE压缩图片后,计算的数据降低了48(512x512x3/64x64x4=48)倍。
(4)深度剖析原理
了解完Clip和UNet之后,我们再来理解Stable Diffusion的底层原理:
由于SD的输入编码器(InputEncoder)中使用的是OpenAI的Clip模型来理解用户输入的文本,而Clip模型的底层是使用英文进行训练的,所以Clip模型只接收英文文本,即Stable Diffusion只接收英文输入。如果我们想输入中文,那么可以先通过翻译软件进行翻译成英文之后,再输入到SD中。
输入编码器(InputEncoder)在接收到用户输入的文本之后,会通过ClipText来理解用户输入的信息,并把理解的信息转换为大小为77 x 768的向量。
Clip模型限制了最多可以输入77个token,可以简单理解成77个单词。
Clip模型训练时会把大图片切成16x16大小的小图片,然后在提取小图片中的RGB3个颜色通道的数据,并最终把小图片表示成一个16x16x3=768的向量。同时Clip为了让文本Token能更好的与图片信息关联,因此也把token的向量长度设计为768。
综上所述,ClipText会把用户输入的文本为77x768大小的向量。
Clip除了文本(Text)编码器,还有图像(Image)编码器,因此Stable Diffusion除了用文本来创建图之外,还可以使用图片生图片。
图片生成器(Image Generator)在内部会首先会在潜空间中生成一张随机的图片,这个图片用的4x64x64大小的向量表示,然后接下来就使用UNet来提升这张随机图片的质量,而这个提升图片质量的过程可能需要数十步,因此就引入了Scheduler调度器,来循环提高质量的这个过程,直到设定步数执行完成,则得到一张按文本生成好的潜空间图片。
通过上述对于VAE的了解,我们应该知悉Stable Diffusion为了降低图像生成的数据量,提升图片生成的效率,而选择在潜空间来生成。那个在这个方式下,生成的图片不满足像素空间的大小要求,因此就借助VAE来进行图片的压缩或放大。
(5)Denoise去噪流程
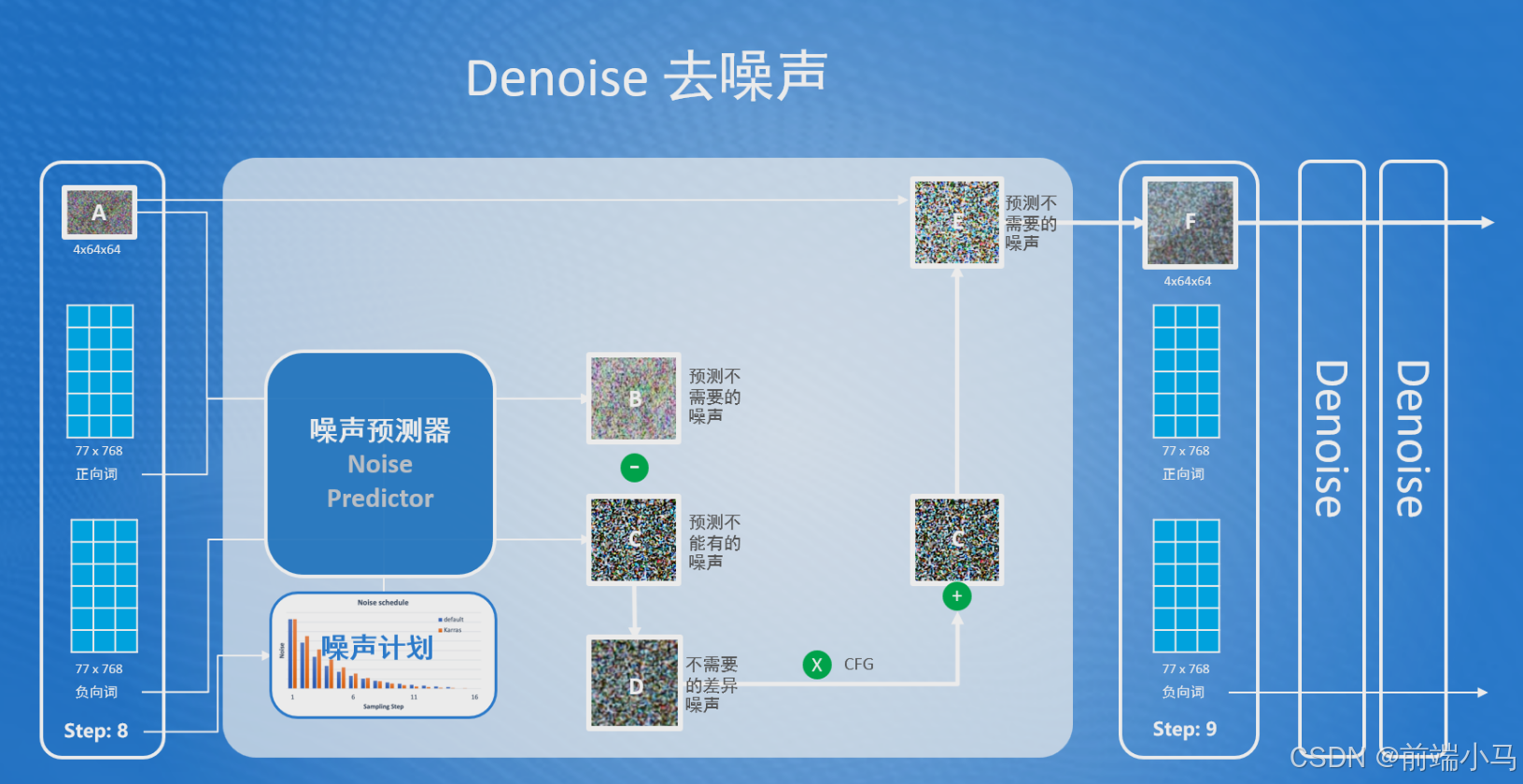
通过上述的了解,不难发现Stable Diffusion在图片生成器中最关键步骤就是Denoise去噪,因此接下来再来了解Denoise去噪的内部流程。
首选在Denoise中有一个核心组件叫Noise Predictor(噪声预测器),Denoise就是通过这个组件来完成降噪的。
①、噪声预测器会依据用户输入的正向词和上一步噪声图(A),预测出在噪声图(A)中不需要的噪声图(B);
此步注意点:
正向词,就是用户输入的文本信息,描述了图片中应该包含哪些内容
噪声预测器在预测图片时需要确定噪声强度,这个值是依据依据外部输入的Step(步骤)参数,去噪声计划中获取噪声强度
噪声强度:指噪声的数量,越强表示噪声的数量越多。在Stable Diffusion中每次Denoise的噪声强度都不同;
Step(步骤):就是表示当前是第几次Denoise的数字,主要的作用是通过步骤去噪声计划中获取对应的噪声强度;
噪声计划:在生图之前,Stable Diffusion在每次Denoise中设定的噪声强度计划,即为噪声计划,这个计划可以通过不同的算法来设定;
②、噪声预测器会依据用户输入的负向词,预测出在结果中不能有的噪声图(C);
此步注意点:
负向词,也是用户输入的文本信息,描述了图片中不能包含的内容
③、噪声预测器会把预测的不需要的噪声图(B)减去预测的不能有的噪声图(C),得到不需要的差异噪声图(D);
④、噪声预测器接着会把不需要的差异噪声图(D)乘以一个放大系数CFG,以放大差异噪声图的细节。然后再把放大的噪声图与预测不能有的噪声图(C)进行相加,就得到了最终不需要的噪声图(E);
CFG: (Classifier Free Guidance)称为无分类引导法,是一种用来让最终生成图像更符合提示词的方法。
⑤、最后使用输入的噪声图(A)减去不需要的噪声图(E),即得到一个更高质量的噪声图(F);
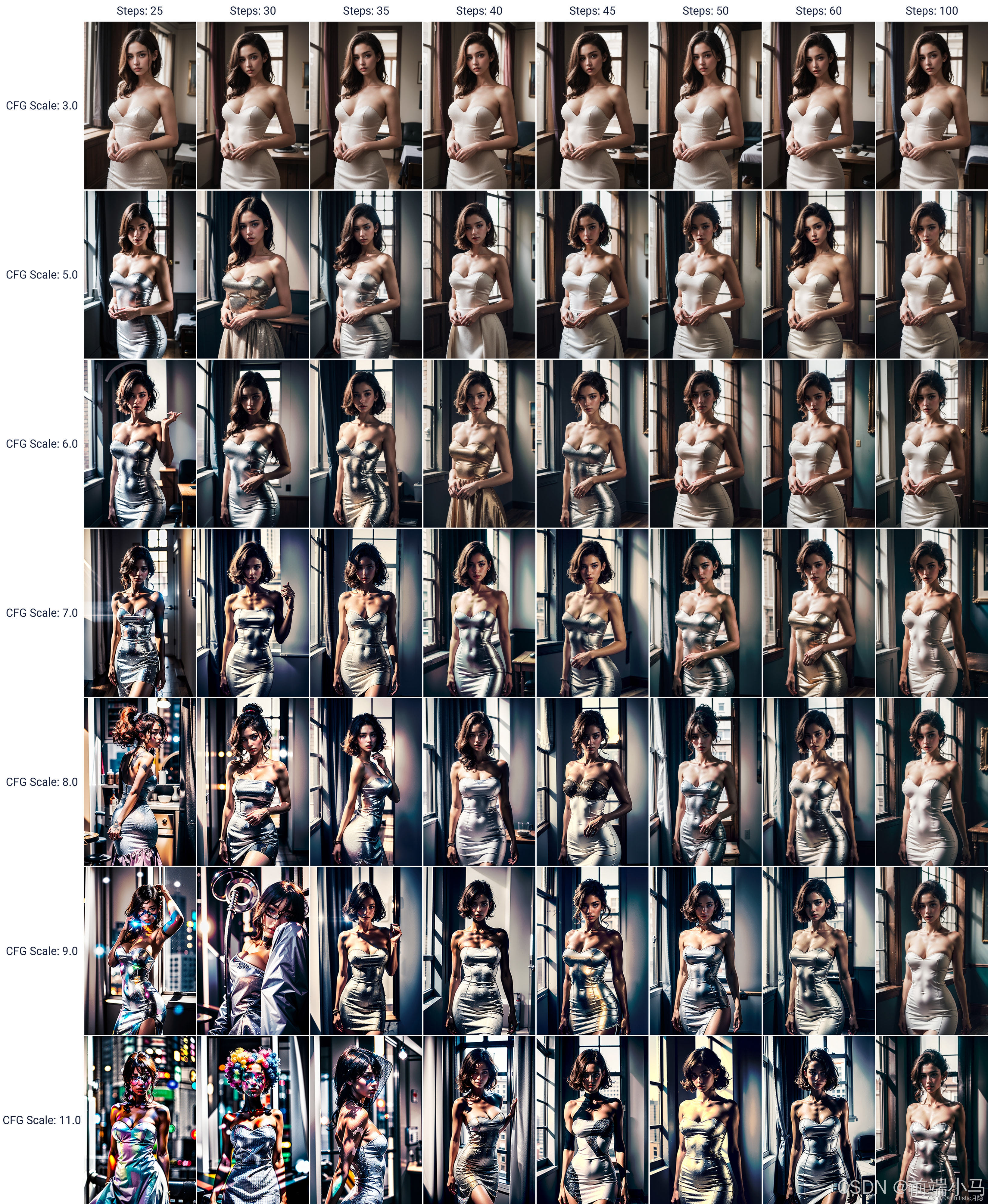
通过上述了解之后,我们应该能发现Stable Diffusion生图过程复杂,但幸好这个实现过程只需要我们了解即可,我们重点关注这个过程中涉及的相关术语和参数,比如这小节提到的Step步骤和CFG参数,对其掌握,有助于快速去设置参数,生成高质量的图片。
Step步骤,值越大生成的图片越细节,但是消耗的计算资源越多;
CFG,当CFG的值增加时,模型会更多地依赖于条件信息(如文本提示),这通常会导致生成的图像更加紧密地匹配给定的文本描述,从而元素更丰富,风格更一致。然而,过高的CFG值也可能导致图像过度依赖于条件信息,从而失去一些自然性和多样性;
Step&CFG参数生成图片的对比:
5. Stable Diffusion 客户端
Stable Diffusion主流的客户端有2款,Stable Diffusion WebUI和Comfyui,这两款客户端的功能类似,但是操作方式有所不同。
WebUI :
Comfyui:
这两个客户端都可以在低配置的CPU上运行,但是由于Comfyui的配置方式更加简洁,且配置可以重用等特性,我们直接选择使用Comfyui作为我们学习的客户端。
八. Comfyui 入门
1. Comfyui介绍
Comfyui:最强大的、模块化的Stable Diffusion的客户端。https://github.com/comfyanonymou s/ComfyUI
主要特点有:
通过流程图的方式,来完成Stable Diffusion的出图功能,过程中不需要写代码;
完全支持SD1.x、SD2.x、SDXL、SD3.x、Stable Video Diffusion、Stable Audio
异步排队系统
支持cpu运行、或者在1GB的GPU上运行
支持Lora、ControlNet、T2I-Adapter、UnClip等功能
支持将工作流保存为json或图片
支持windows、linux、mac多平台
2. 安装Comfyui
Comfyui是用python开发的,同时其环境比较考验电脑的操作系统环境,因此我们采取使用Docker方式来进行安装。
通过下面操作来导入comfyui镜像:
[root@bogon docker]# pwd /root/docker [root@bogon docker]# ls comfyui.zip [root@bogon docker]# docker load -i comfyui.zip Loaded image: comfyui:0.0.2 [root@bogon docker]# [root@bogon docker]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE comfyui 0.0.2 c3dd166b94b4 6 hours ago 9.84GB [root@bogon docker]#然后可以通过下面命令运行容器:
docker run -d --name cf -p 8188:8188 \ -v /root/data/ComfyUI/custom_nodes:/root/data/ComfyUI/custom_nodes \ -v /root/data/ComfyUI/input:/root/data/ComfyUI/input \ -v /root/data/ComfyUI/output:/root/data/ComfyUI/output \ -v /root/data/ComfyUI/models:/root/data/ComfyUI/models \ comfyui:0.0.2 参数说明: - --name参数指定容器名称为cf - -p参数映射访问端口为8188,Comfyui客户端默认访问端口是8188 - -v参数挂在了custom_nodes、input、output、models四个路径 - custom_nodes:用于存放安装的插件源码 - input:用于存储在工作流中输入的图像 - output:用于存储工作流输出的图像 - models:用于存储各种大模型文件在/root/data/ComfyUI/models新建checkpoints文件夹
将相关软件资源/Comfyui插件&模型中的大模型(亚洲美女图库)上传到/root/data/ComfyUI/models/checkpoints
然后再浏览器中输入地址http://192.168.100.129:8188/,如果启动成功则会出现以下界面:
3. 安装管理器
https://github.com/ltdrdata/ComfyUI-Manager
为了扩展和管理Comfyui,在这里可以给Comfyui安装一个管理器ComfyUI-Manager,ComfyUI-Manager是一个扩展,旨在增强ComfyUI的可用性。它提供了安装、删除、禁用和启用ComfyUI的各种自定义节点的管理功能。此外,此扩展提供了一个管理中心,可以访问ComfyUI中的各种信息。
安装插件步骤:
1、进入到/root/resource路径
2、拷贝插件源码到,插件安装路径:/root/data/ComfyUI/custom_nodes/
3、解压压缩包,并删除压缩包
4、重启容器
# 1、进入到/root/resource路径 [root@bogon resource]# ls ComfyUI-Manager-main.zip ollama-linux-amd64 [root@bogon resource]# pwd /root/resource # 2、拷贝插件源码到,插件安装路径:/root/data/ComfyUI/custom_nodes/ [root@bogon resource]# cp ComfyUI-Manager-main.zip /root/data/ComfyUI/custom_nodes/ [root@bogon resource]# cd ~/data/ComfyUI/custom_nodes/ [root@bogon custom_nodes]# ls ComfyUI-Manager-main.zip # 3、解压压缩包,并删除压缩包 [root@bogon custom_nodes]# unzip -q ComfyUI-Manager-main.zip [root@bogon custom_nodes]# ls ComfyUI-Manager-main # 4、重启 [root@bogon custom_nodes]# docker restart d6重启看见下图按钮,即可安装成功:
4. 汉化界面
(1)通过管理器在线安装
点击【Manager】然后点击【Custom Nodes Manager】
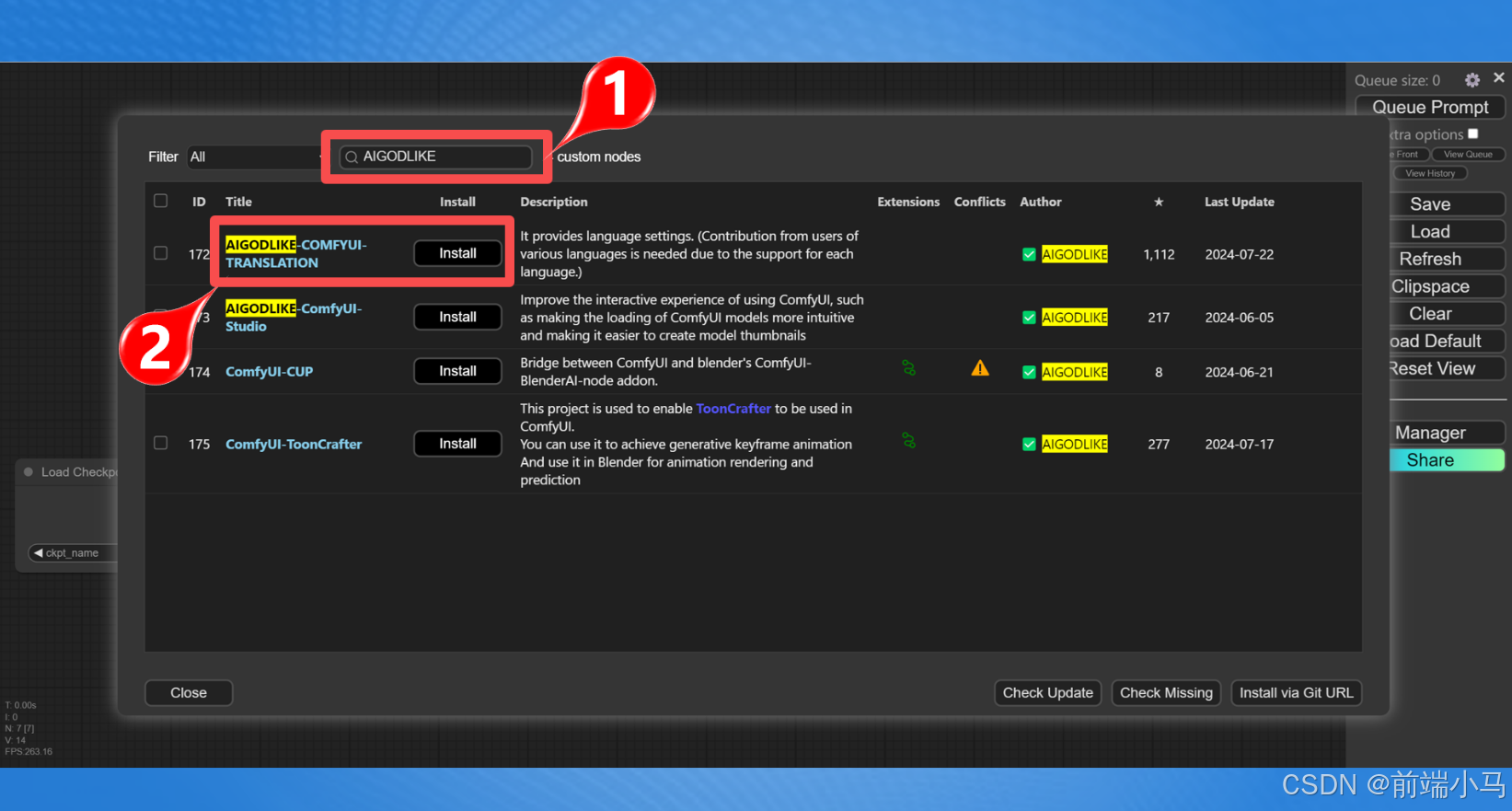
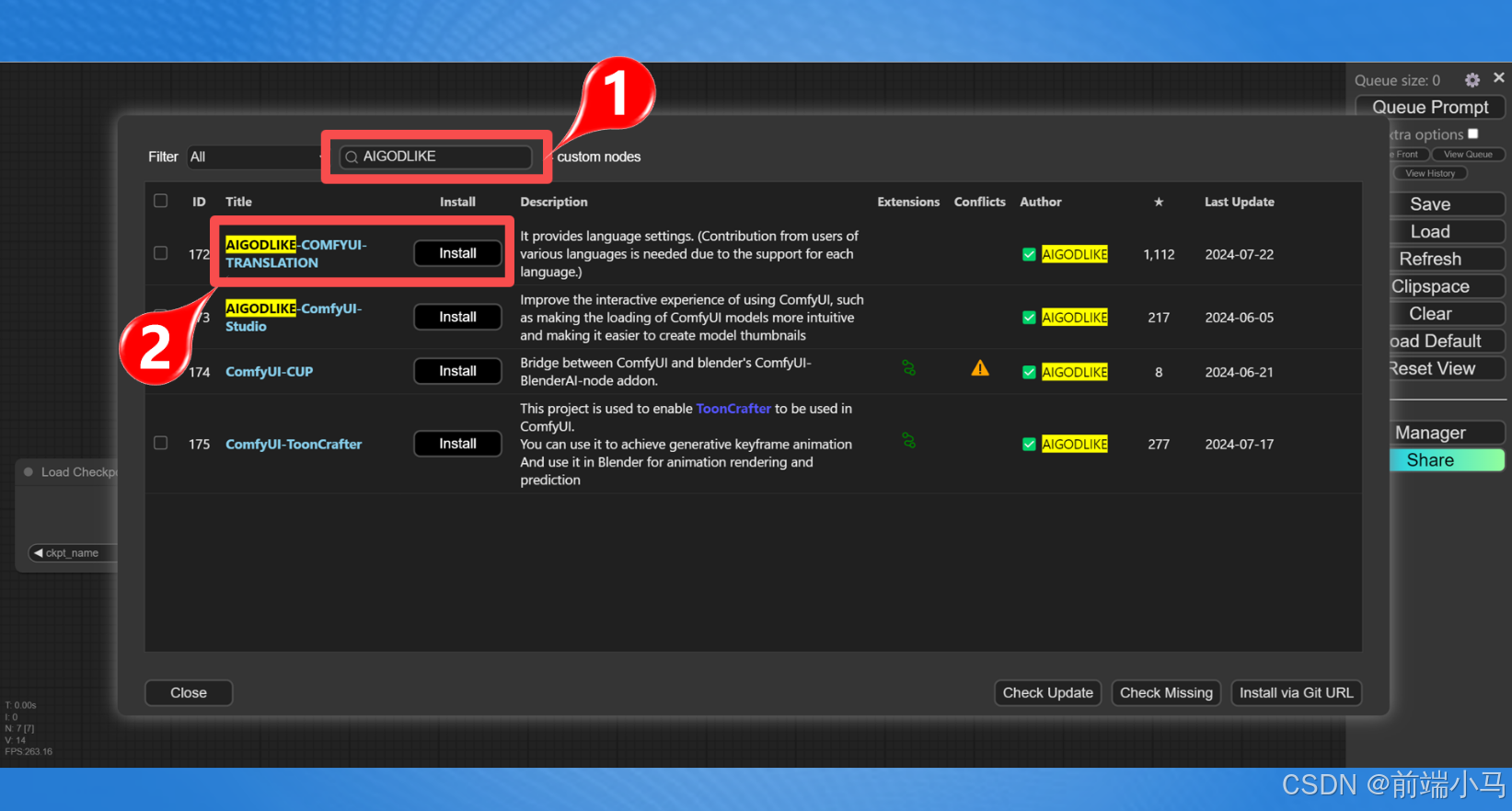
在弹出的对话框中搜索【AIGODLIKE】关键字,然后在搜索结果中点击【Install】
点击安装之后,程序会去github上下载插件的源代码,但是目前国内访问github网站极度不稳定,因此此种方式会出现安装失败的情况。那么则可采取离线安装的方式。
(2)离线安装
AIGODLIKE-ComfyUI-Translation是目前流行的汉化插件,可以从上面地址下载源码压缩包,然后按照以下步骤进行安装:
1、进入到/root/resource路径
2、拷贝插件源码到,插件安装路径:/root/data/ComfyUI/custom_nodes/
3、解压压缩包,并删除压缩包
4、重启容器
# 1、进入到/root/resource路径 [root@bogon resource]# ls AIGODLIKE-ComfyUI-Translation-main.zip ComfyUI-Manager-main.zip ollama-linux-amd64 [root@bogon resource]# pwd /root/resource # 2、拷贝插件源码到,插件安装路径:/root/data/ComfyUI/custom_nodes/ [root@bogon resource]# cp AIGODLIKE-ComfyUI-Translation-main.zip /root/data/ComfyUI/custom_nodes/ # 3、解压压缩包,并删除压缩包 [root@bogon custom_nodes]# unzip -q AIGODLIKE-ComfyUI-Translation-main.zip [root@bogon custom_nodes]# ls AIGODLIKE-ComfyUI-Translation-main ComfyUI-Manager-main # 4、重启容器 [root@bogon custom_nodes]# docker restart d6 d6 [root@bogon custom_nodes]#重启软件之后,在右侧菜单多出一个Switch Locale的菜单,但是点击有可能会无效,此时可手动设置语言。
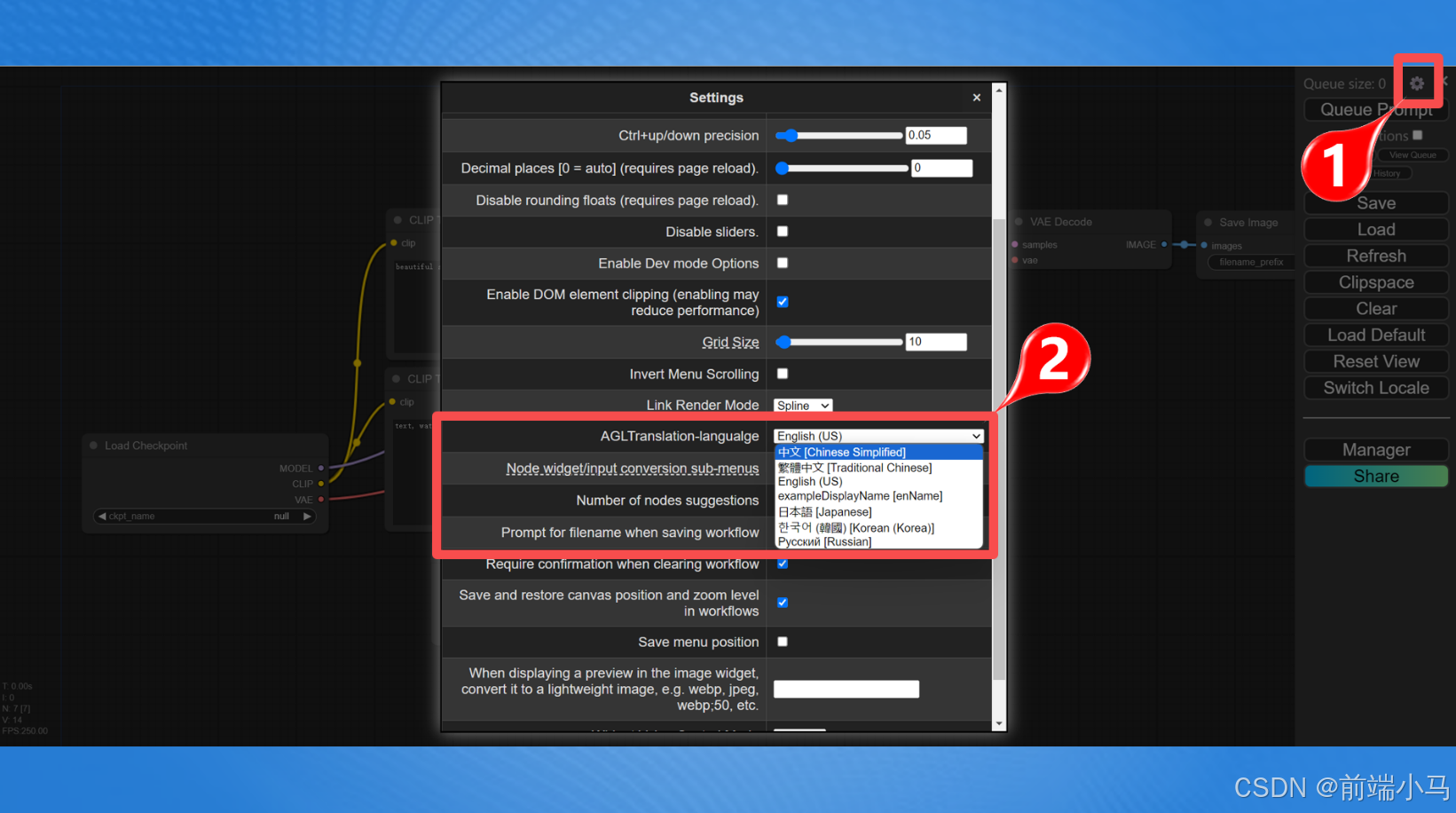
点击【设置】按钮,然后找到语言选项,选择中文即可完成设置。
5. 文生图
(1)生成第一张图片
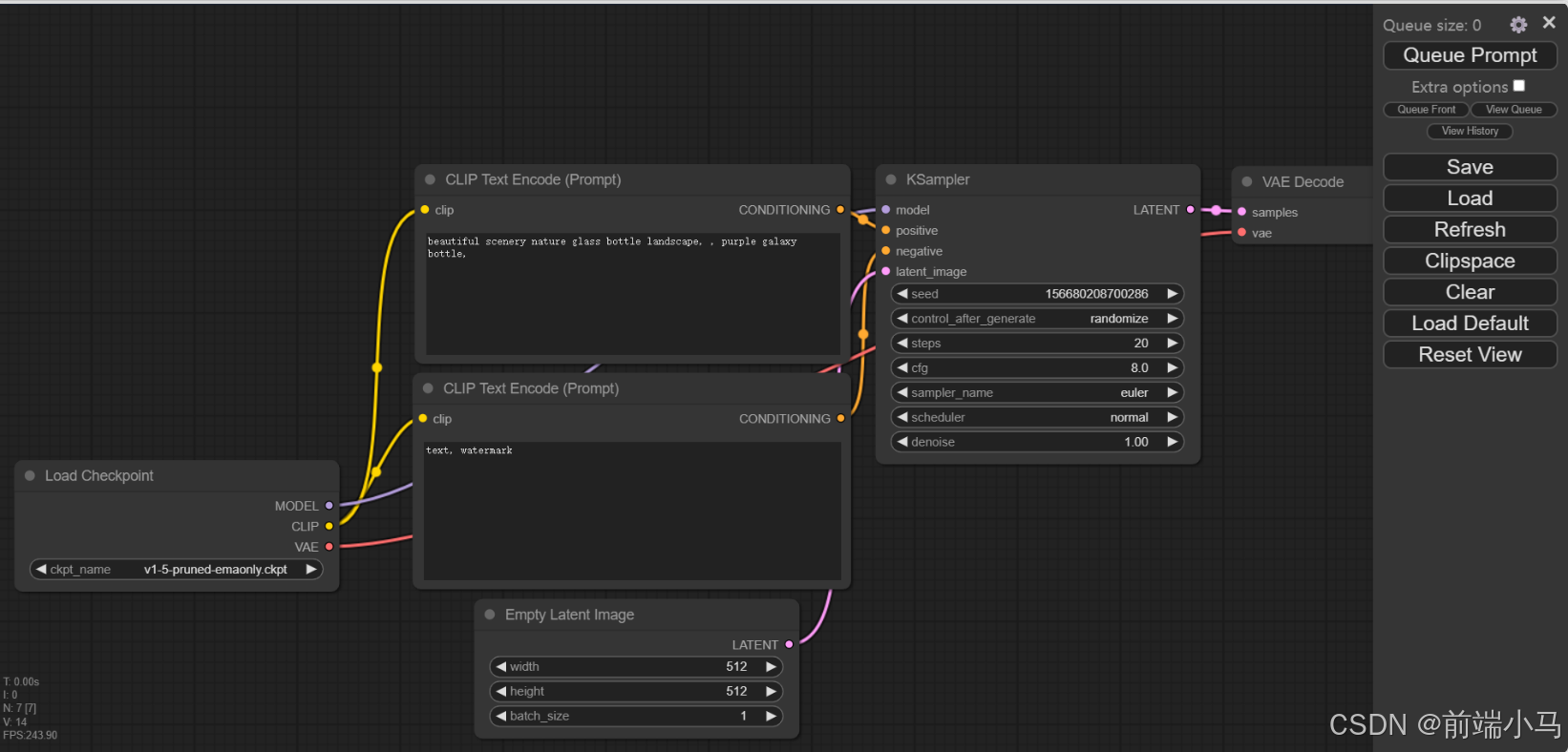
安装好Comfyui之后,在界面中默认就有一个流程,接下要我们可以使用这个默认流程图来完成第一个图片的生成。可以按照下面步骤进行操作:
Step1、添加模型:
majicmixRealistic_v7.safetensors是亚洲美女大模型
[root@localhost checkpoints]# ls majicmixRealistic_v7.safetensors [root@localhost checkpoints]# pwd /root/data/ComfyUI/models/checkpoints [root@localhost checkpoints]#Step2、刷新并选择模型:
上传完成模型之后,可以点击【刷新】按钮,然后再2位置,选择刚才的模型,然后点击3号位置的按钮,开始生成图片。
生成的图片原图:
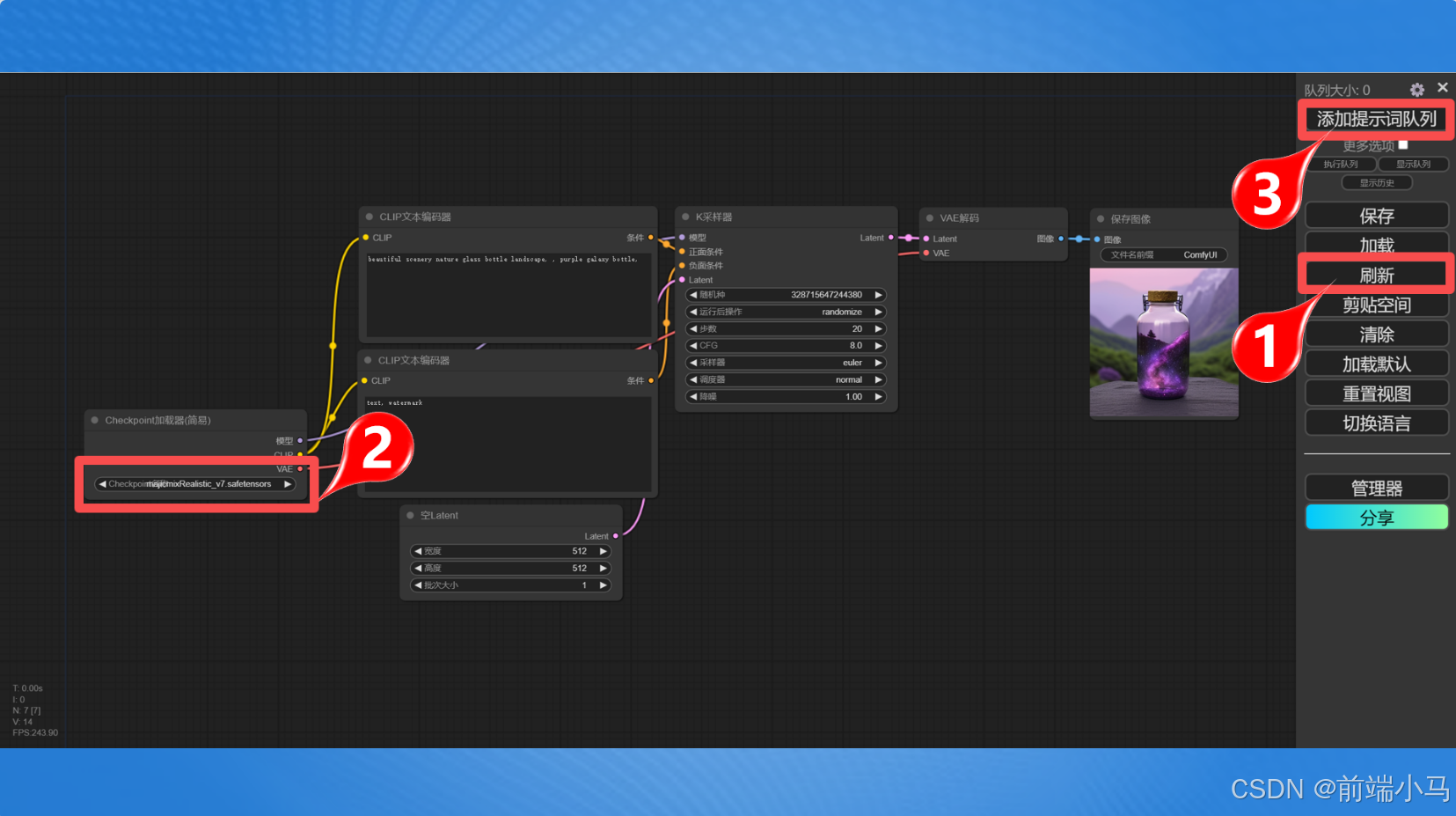

(2)生成美女图片
在上面流程中,做以下参数设置,即可生成一张美女图片:
正向提示词:
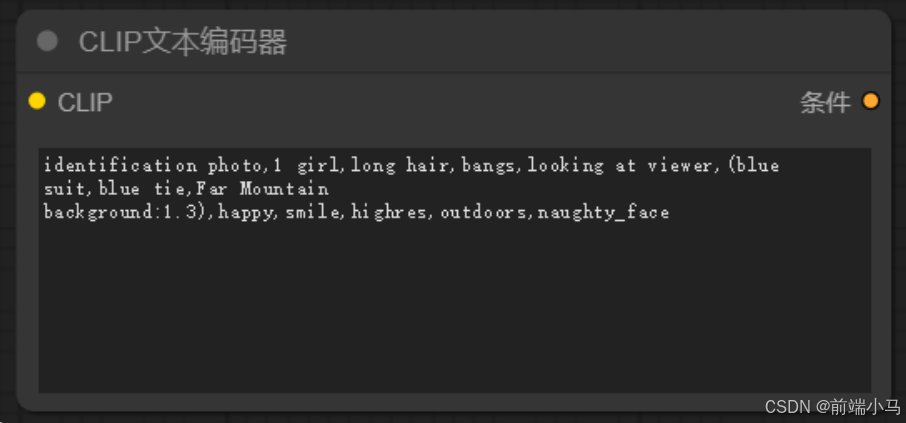
identification photo,1 girl,long hair,bangs,looking at viewer, (blue suit,blue tie,Far Mountain background:1.3),happy,smile,highres, outdoors,naughty_face 身份证照片,1个女孩,长发,刘海,看着观众,(蓝色西装,蓝色领带,远山背景:1.3), 快乐,微笑,高分辨率,户外,淘气的脸负向提示词:
(worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, skin spots, acnes, skin blemishes,(fat:1.2),facing away, looking away,tilted head, lowres,bad anatomy,bad hands, missing fingers,extra digit, fewer digits,bad feet, poorly drawn hands,poorly drawn face,mutation,deformed,extra fingers,extra limbs, extra arms,extra legs,malformed limbs,fused fingers,too many fingers,long neck, cross-eyed,mutated hands,polar lowres,bad body,bad proportions,gross proportions, missing arms,missing legs,extra digit, extra arms, extra leg, extra (质量最差:2)、(质量低:2)和(质量正常:2),低分辨率,解剖结构不良,皮肤斑点,痤疮, 皮肤瑕疵,(脂肪:1.2),背向别处,看向别处,倾斜的头部,低分辨率、解剖结构不良、手部不良、 手指缺失、多指、少指、脚部不良、手绘制不良、面部绘制不良、突变、变形、多指,多肢,多臂, 多腿,畸形肢体,多指,长颈,斜视,突变的手,极低分辨率,身体不良,比例不良,粗大比例,少臂, 少腿,多指K采样器
步数:30
采样器:dpm_2
调度器:karras
提示词:
不同提示词之间是用英文逗号分割
提示词长度不能超过77个单词
一般提示词使用多个单词提示
单词权重规则如下:
输入框越前面的单词,权重越高
提升某个单词的权重使用(单词:提升的权重数值),减权重则设置值区间为0~1,加权重则设置值为1~2
然后再次运行:
生成的美女图片:


(3)算力不足解决方案
如果生产图片太慢,或者电脑不支持GPU则可以使用云算力来学习。
如果在学习AIGC大模型 的过程中,自身电脑配置不能满足学习性能的需要,可以直接购买云算力,来提升学习的效率。
(4)流程节点说明
首选我们把流程中的节点进行一个归类整理,即可得到这张图:
然后我们再结合之前讲解Stable Diffusion原理的图片来看:
对比两张图,不难发现,第一张图中的流程,实际是按照之前我们所讲解的原理图来进行执行的,结合之前所见的Stable Diffusion的理论知识,解下来看看每个节点的作用。
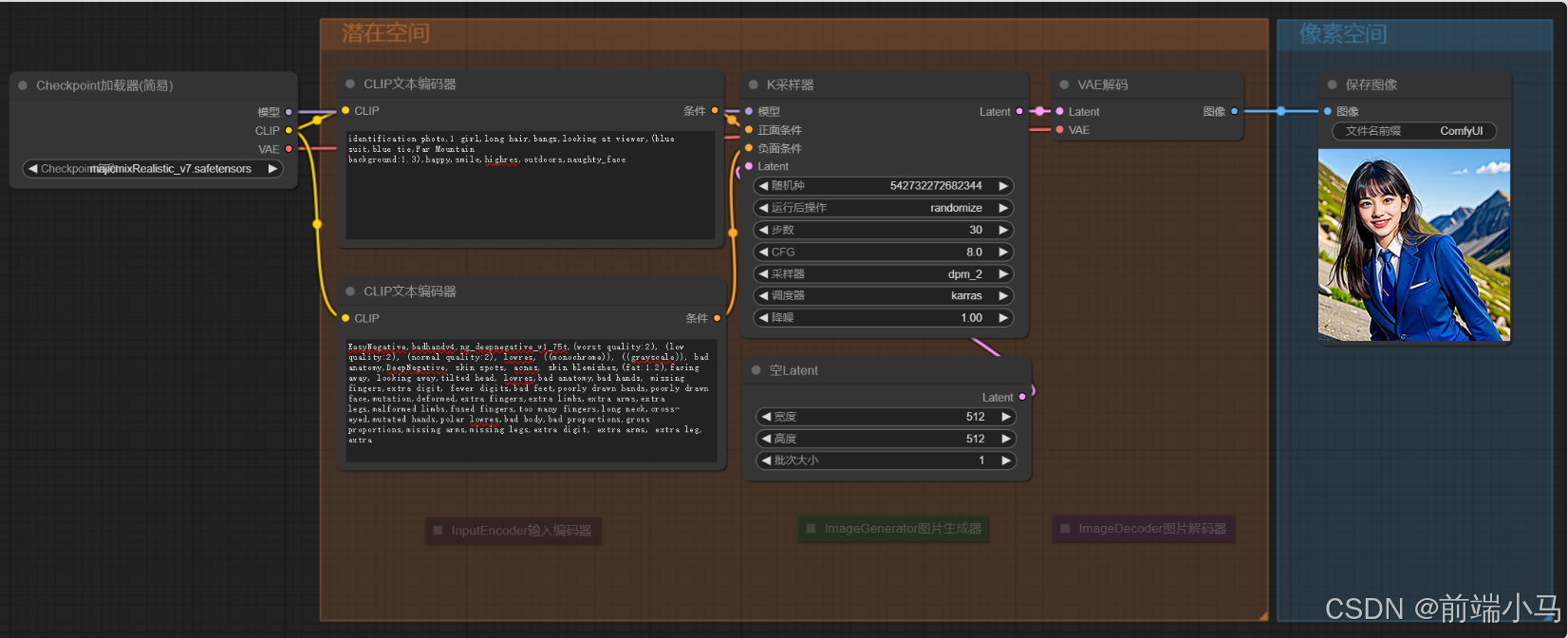
①CLIP文本编辑器
CLIP文本编辑器的作用就是把用户输入的提示词,转换成向量,属于输入编码器(InputEncoder)中的ClipText实现。通过之前的原理学习,我们知道Stable Diffusion是通过OpenAI的CLIP来实现文本向向量转换的,而OpenAI的CLIP是使用英文训练的,通过约束了输入token的最大长度为77。因此==CLIP文本编辑器也只接受英文,并且长度建议不要超过77个==。
CLIP文本编辑器节点的左侧CLIP表示,节点需要输入一个CLIP模型。
CLIP文本编辑器节点的右侧条件表示,节点会输出CLIP模型转换文本后的向量信息。
同时在Stable Diffusion中,需要一个正向文本和一个负向文本,正向文本用来说明图片中应对包括的元素,负向文本用来说明图片中不应该包括的元素,负向文本一般用来调整图片的细节,比如避免出现多手、多脚的情况。
②Checkpoint加载器
Checkpoint加载器主要用来载入大模型到流程中,一般标准的大模型文件包括模型、CLIP、VAE三部分,因此加载器会在右侧输出这三部分内容供后续节点使用。
Checkpoint加载器会自动去Comfyui的models/checkpoints文件夹下扫描和去读大模型,因此如果我们新增大模型,则只需要把大模型文件放到该文件夹即可。
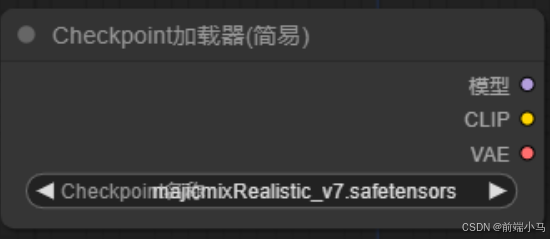
③K采样器
K采样器的作用就是生成图片,可以理解它就是图片生成器(Image Generator)的实现。
它的输入是:
生图大模型
正向词向量
负向词向量
Latent:潜空间
它的输出是:
Latent:生成好图片的潜空间
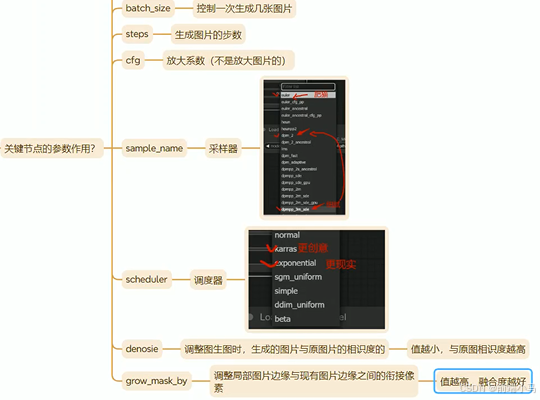
除此之外还有一些可调整配置的参数:
随机种子和运行后操作:随机种子值控制潜在图像的初始噪声,从而控制最终图像的合成。不同的 seed 值会生成不同的图像,因此可以通过调整 seed 值来尝试生成不同的效果。
步数:去噪一共要执行的次数
CFG:设置放大系数CFG(数字越大越符合输入条件,但是自然性可能会损失)
采样器:选择生成噪声的算法
调度器:选择生成噪声计划的算法
降噪:降噪过程应消除多少百分比的初始噪声。1表示全部。
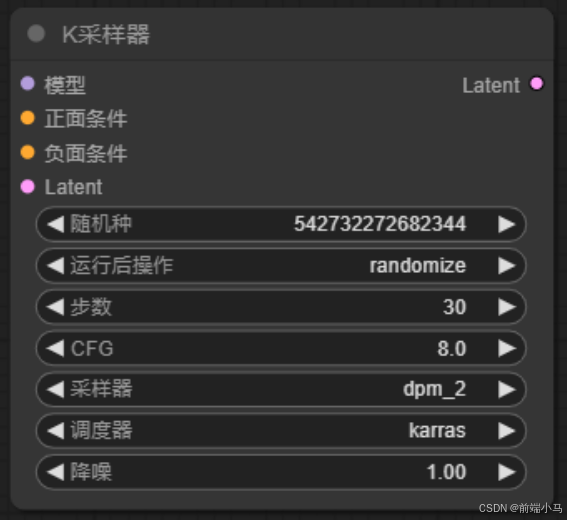
④空Latent
空Latent的作用是创建一个潜空间,并设置潜空间的大小,以及个数。
它没有输入,只有输出:
- Latent:初始的潜空间
它的配置参数是:
- 宽度&高度:设置潜空间的大小,这里的大小是按照像素空间的大小来设置。
由于不同模型训练的图片大小不一样,因此这里需要依据不同的模型进行调整大小,比如: sd1.x设置成512x512 sdxl设置成1024x1024 如果这里设置的大小与大模型训练的大小比例不对,很容易生成两个头、坏手等低质量的图片。
批次大小:设置生成几个潜空间,一个潜空间就表示生成一张图片,因此这里的批次大小也表示要生成几张图片
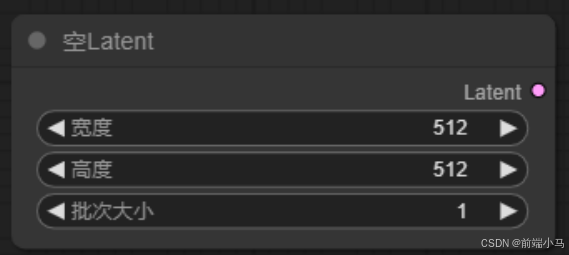
⑤VAE解码
VAE解码器的作用就是把潜空间的图片转成像素空间的图片。
它的输入:
Latent:生成好的图片潜空间
VAE:VAE模型
它的输出:
图像:像素空间的图片
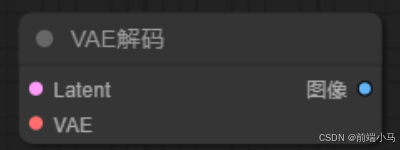
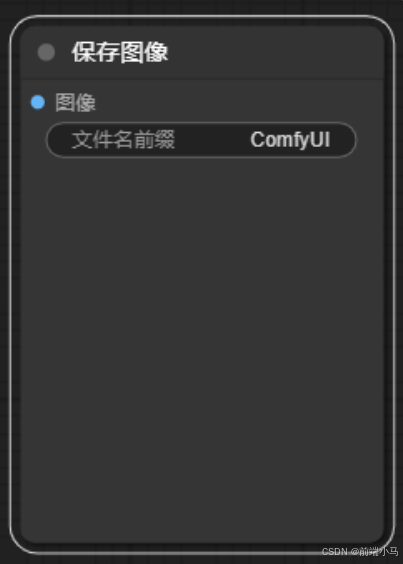
⑥保存图像
把生成的图片保存到磁盘,并可以设置保存的图片名称
图片保存的路径是在output文件夹中,比如:
[root@localhost output]# pwd /root/data/ComfyUI/output [root@localhost output]# ll 总用量 2348 -rw-r--r--. 1 root root 330663 7月 28 16:06 ComfyUI_00001_.png -rw-r--r--. 1 root root 354261 7月 28 16:14 ComfyUI_00002_.png -rw-r--r--. 1 root root 386778 7月 28 16:17 ComfyUI_00003_.png -rw-r--r--. 1 root root 435342 7月 28 16:21 ComfyUI_00004_.png -rw-r--r--. 1 root root 428858 7月 28 16:28 ComfyUI_00005_.png -rw-r--r--. 1 root root 457979 7月 28 16:36 ComfyUI_00006_.png
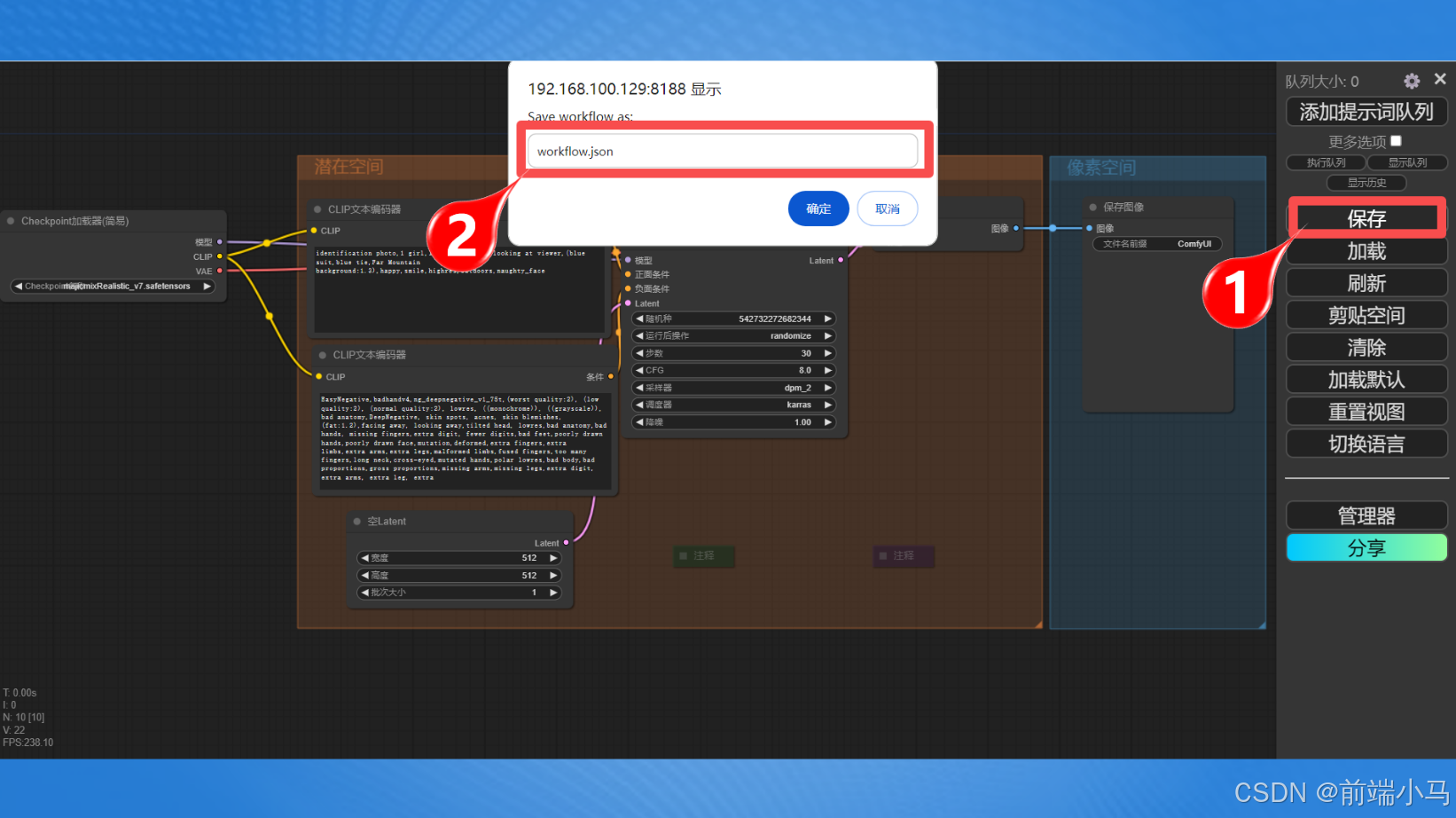
(5)保存流程
Comfyui会自动保存最后一次流程的编辑情况,因此我们不用担心流程的丢失情况,但是对于重要的流程,还是建议手动保存,按下图操作即可:
1、点击保存按钮
2、在弹出的输入框中输入保存文件的名称(是json格式),然后点击【确定】按钮,文件将以下载的方式,保存到电脑默认的下载路径。
6. 文生图案例
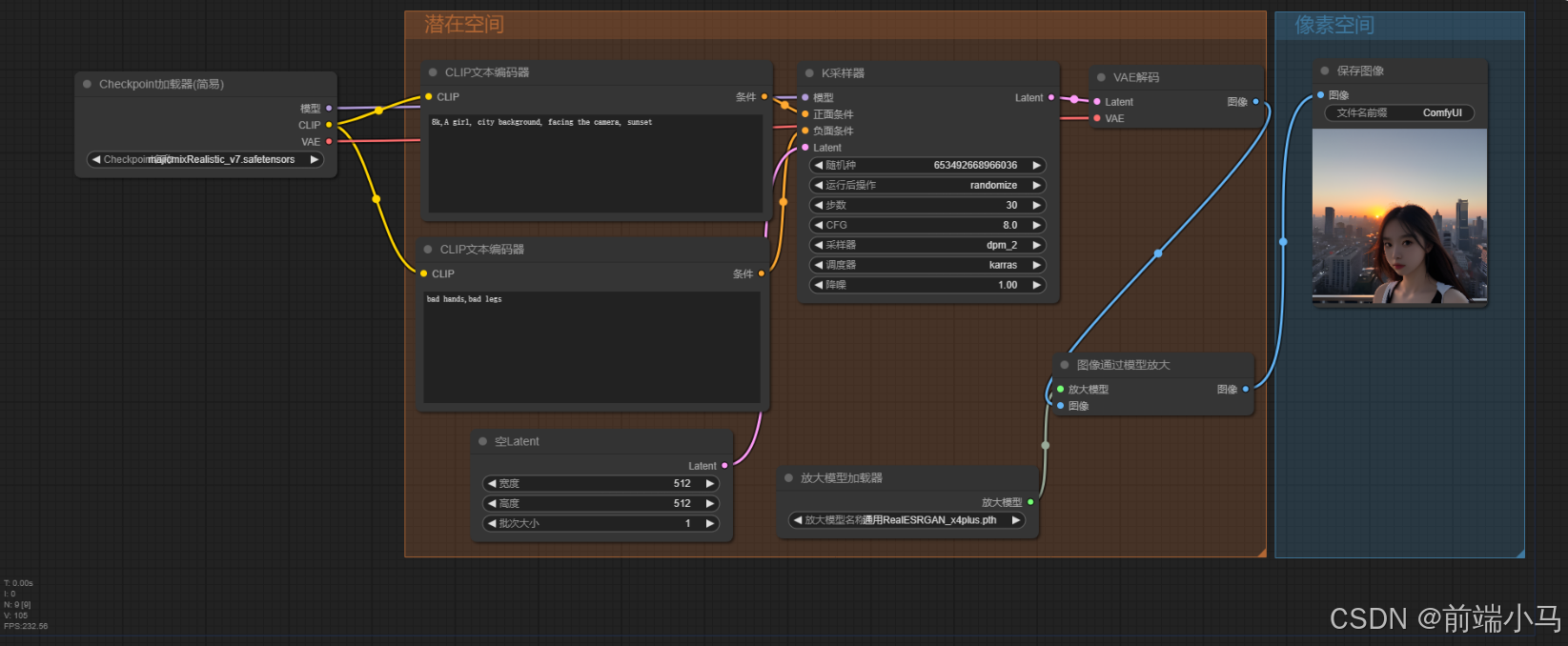
(1)图片高清放大
1. 新建一个流程或者在原有流程上就行如下调整
2. 正向提示词调整为:
8K,一个女孩,城市背景,正视镜头,晚霞 8k,A girl, city background, facing the camera, sunse,Facial details3. 负向提示词调整为:
bad hands,bad legs4. 增加【放大模型加载器】节点:用于加载放大模型
节点用到的通用RealESRGAN_x4plus.pth模型需要上传到models\upscale_models文件夹中(没有该文件夹就新建)
5. 增加【图像通过模型放大】节点:使用大模型来无损放大图片
节点输入
放大模型连接到【放大模型加载器】节点
图像连接到【VAE解码】
节点输出的图像直接连接到【保存图像】节点
大模型生成图片是512x512的大小,然后结果放大模型RealESRGAN_x4plus的处理,图片被放大了4倍,大小变成了2048x2048,即达到了2K高清水准。
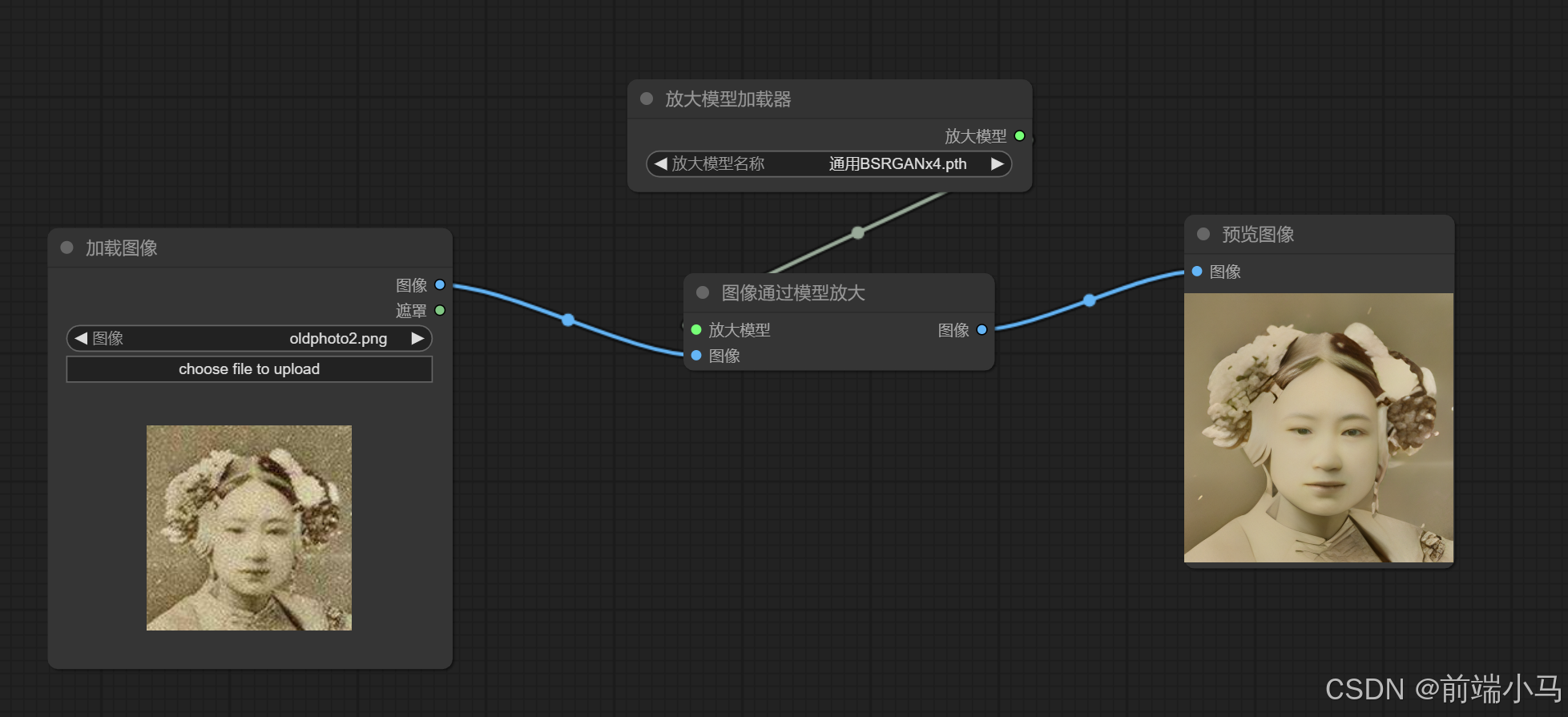
(2)图片高清修复
老照片不清晰,同时尺寸比较小(160x160):
通过大模型进行修复之后,尺寸变成了(640x640),且清晰:


7. 图生图案例
(1)风格&元素引用
我们可以上传一张原图,然后以原图内容改变图片中元素的风格,比如现实人物转为漫画人物,这就是风格&元素引用。
比如原图:
风格化之后:
要实现上述效果,可以参考一下流程进行绘制:
通过【Checkpoint加载器】节点载入大模型majicmixRealistic_v7
通过【加载图像】节点载入原图
在正向提示词中输入:
1girl,rain,Trees, green leaves 1女孩,下雨,树,绿叶- 在负向提示词中输入:
bad fingers,bad hands,bad legs
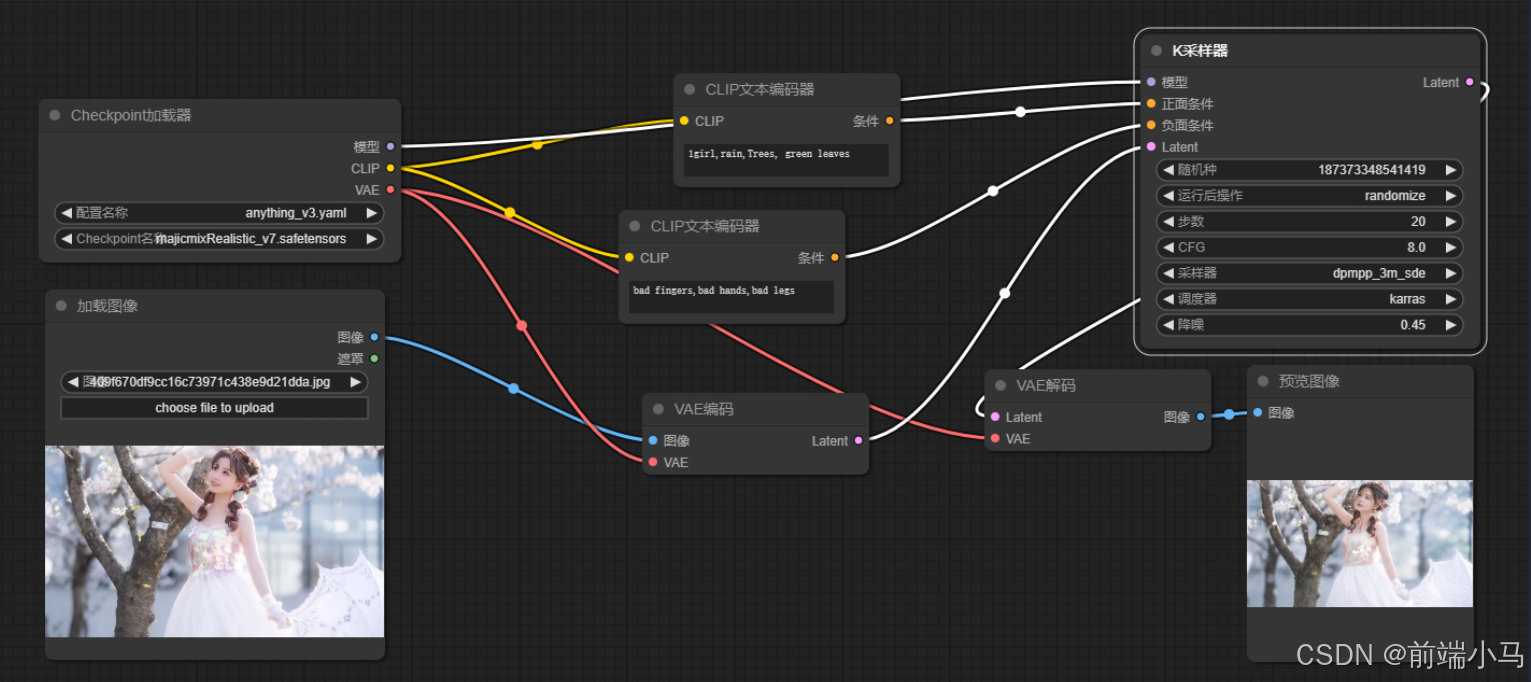
==通过【VAE编码】节点,把原图转换为潜空间,并作为生成图片的原空间==
在【K采样器】中配置采样器为dpmpp_3m_sde,然后调度器为karras,同时降噪设置成0.45 注意:降噪为0.45表示原图45%的内容可以改变,55%为原图元素,因此生成的图片和原图有管理性。


(2) 局部重绘
生成的一张图片中,如果对某个区域内容不满意,我们还可以对这个区域重绘。
比如下图中美女对于美女的脸部不是很满意,则可以重新描述生成。
具体的操作步骤是:
通过【Checkpoint加载器】节点载入大模型majicmixRealistic_v7
通过【加载图像】节点载入原图
bad fingers,bad hands,bad legs在图片上右键选择【在遮罩编辑器中打开】
然后用鼠标抹去要重绘的区域,完成之后点击【Save to node】
- 在正向提示词中输入:
beauty girl,8k,Facial details 美女,8K,脸部细节
- 在负向提示词中输入:
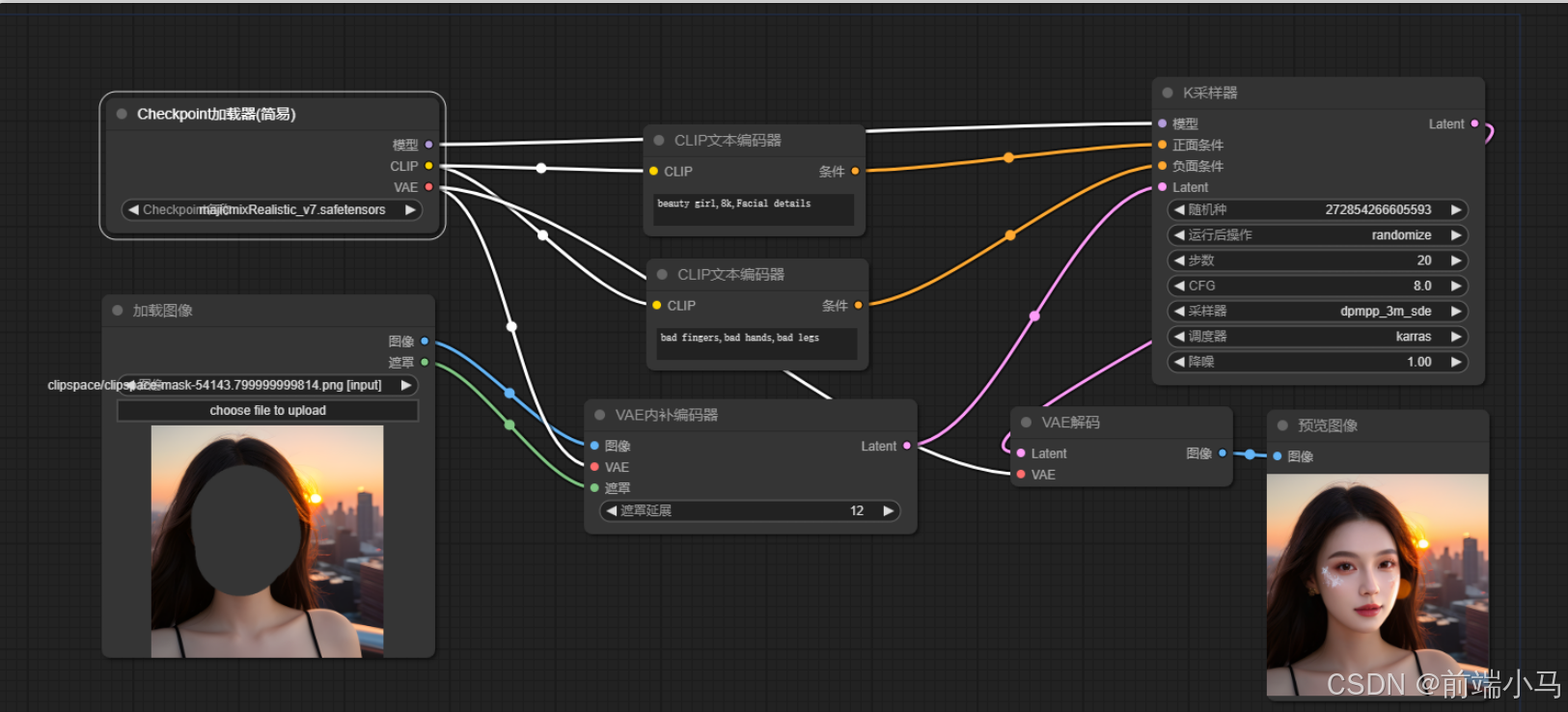
bad fingers,bad hands,bad legs- ==通过【VAE内补编码器】节点,把原图转换为潜空间,并作为生成图片的原空间== 遮罩延展:是指重绘区域与生成图像融合的边距大小,值越大融合度越好,但是一般建议在8~20以内。
- 在【K采样器】中配置采样器为dpmpp_3m_sde,然后调度器为karras
运行结果:
原图片:
遮罩图片:
区域重绘图:




8. 关键节点的参数作用
9. API入门
Comfyui客户端也提供了API接口,我们也可以在程序中通过API类调用comfyui生成图片。为后续项目开发准备。
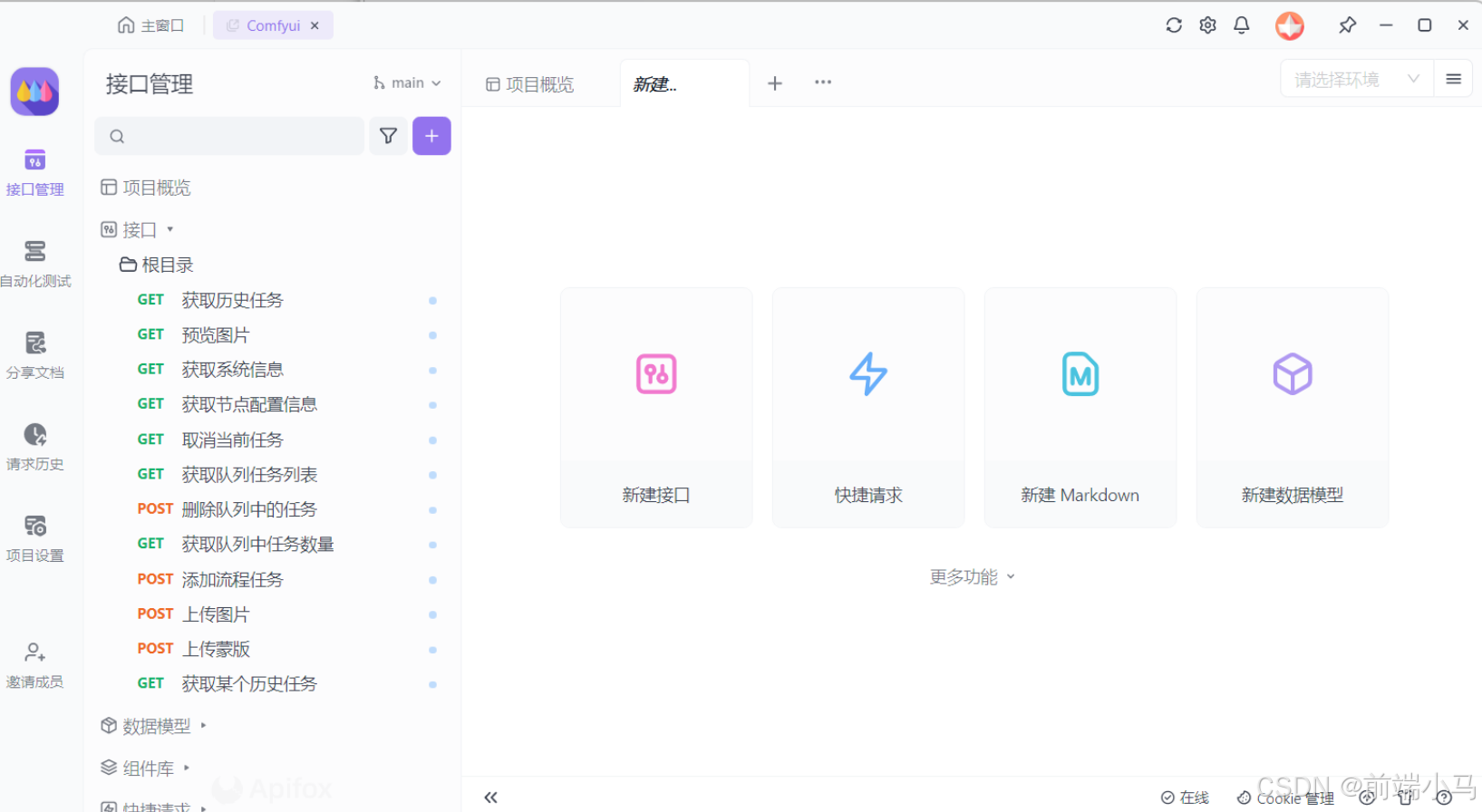
(1)导入Apifox文档
在通过程序来调用API之前,我们可以先 通过Apifox来先了解一下接口,打开Apifox,导入项目。
Step 1:打开导入项目
Step 2:选择导入的文件
Step 3:输入项目名称
Step 4:完成导入,进入项目
(2)配置环境地址
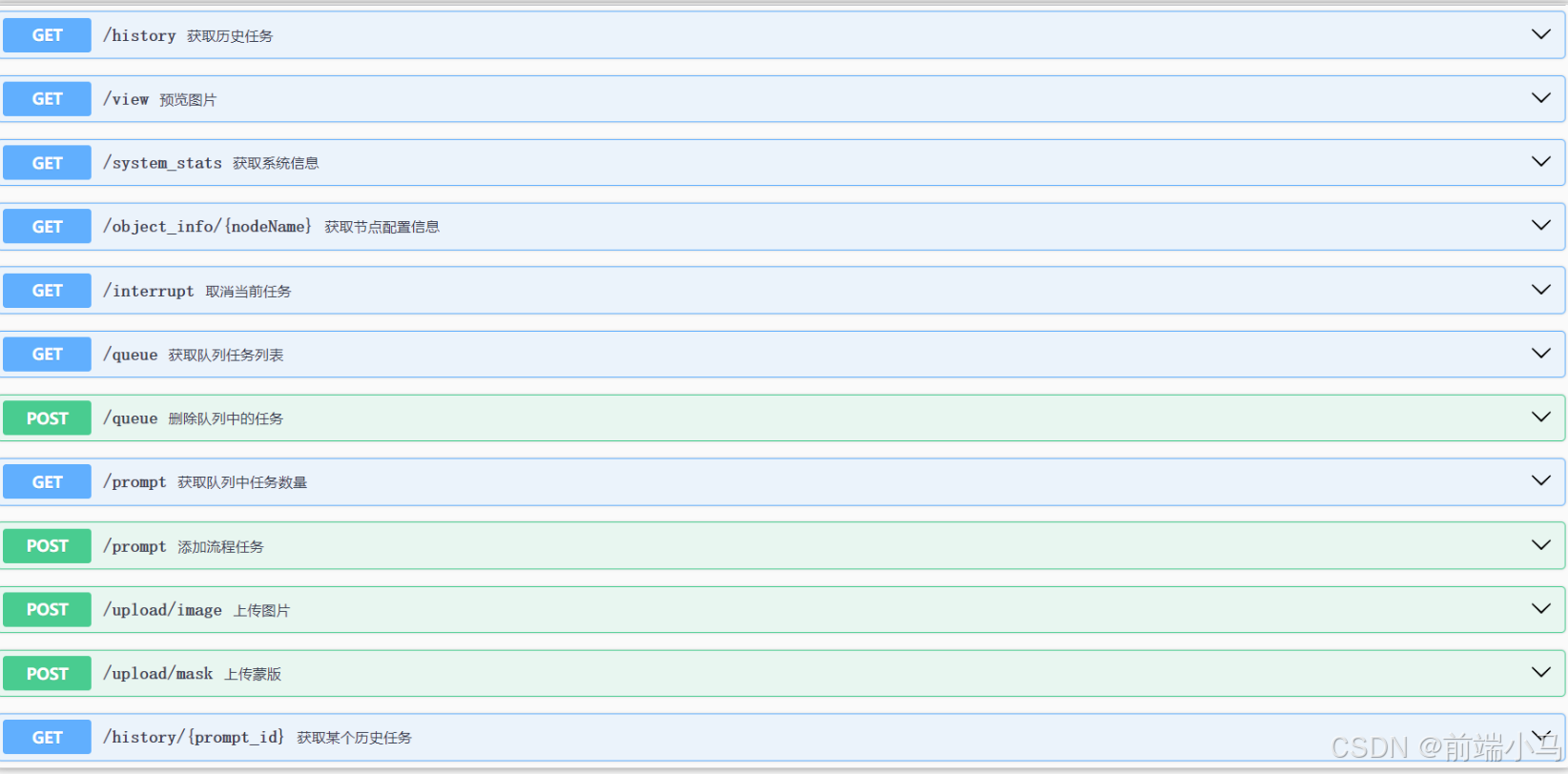
Comfyui支持的API也可以通过《ComfyuiApi文档.html》文件进行详解,双击打开可查看:
但是如果要进行测试,则还是在Apifox中进行操作比较方便,正式体验之前,需要先配置一下环境地址。
(3)获取历史任务
在Comfyui中每一次点击生图按钮,Comfyui就会生成一个任务,并放入内部的队列中,排队等待执行,执行完成的任务也会保留信息,那么在这个过程中如果我们先查看历史执行完成的任务,则可以调用"获取历史任务"接口。
GET / history
请求参数:
响应数据:
名称 类型 必选 中文名 说明 prompt array 是 工作流节点信息 outputs object 是 生成文件信息 status object 是 任务状态信息 样例:
{ "1c1a03b9-4d43-4026-af7d-d38ce8589451": { "prompt": [], "outputs": { "8": { "images": [ { "filename": "ComfyUI_temp_smrky_00096_.png", "subfolder": "", "type": "temp" } ] } }, "status": { "status_str": "success", "completed": true, "messages": [ [ "execution_start", { "prompt_id": "1c1a03b9-4d43-4026-af7d-d38ce8589451" } ], [ "execution_cached", { "nodes": [ "5", "6", "11", "9", "1" ], "prompt_id": "1c1a03b9-4d43-4026-af7d-d38ce8589451" } ] ] } }, "969f62cf-da2f-47f8-985c-ddd1c18da757": { "prompt": [ 103, "969f62cf-da2f-47f8-985c-ddd1c18da757", { "1": { "inputs": { "image": "clipspace/clipspace-mask-3740764.8999999994.png [input]", "upload": "image" }, "class_type": "LoadImage", "_meta": { "title": "加载图像" } }, "4": { "inputs": { "seed": 586215496424602, "steps": 30, "cfg": 8.0, "sampler_name": "dpmpp_3m_sde", "scheduler": "karras", "denoise": 1.0, "model": [ "11", 0 ], "positive": [ "5", 0 ], "negative": [ "6", 0 ], "latent_image": [ "9", 0 ] }, "class_type": "KSampler", "_meta": { "title": "K采样器" } }, "5": { "inputs": { "text": "beauty girl,8k,Facial details", "clip": [ "11", 1 ] }, "class_type": "CLIPTextEncode", "_meta": { "title": "CLIP文本编码器" } }, "6": { "inputs": { "text": "bad fingers,bad hands,bad legs", "clip": [ "11", 1 ] }, "class_type": "CLIPTextEncode", "_meta": { "title": "CLIP文本编码器" } }, "7": { "inputs": { "samples": [ "4", 0 ], "vae": [ "11", 2 ] }, "class_type": "VAEDecode", "_meta": { "title": "VAE解码" } }, "8": { "inputs": { "images": [ "7", 0 ] }, "class_type": "PreviewImage", "_meta": { "title": "预览图像" } }, "9": { "inputs": { "grow_mask_by": 12, "pixels": [ "1", 0 ], "vae": [ "11", 2 ], "mask": [ "1", 1 ] }, "class_type": "VAEEncodeForInpaint", "_meta": { "title": "VAE内补编码器" } }, "11": { "inputs": { "ckpt_name": "majicmixRealistic_v7.safetensors" }, "class_type": "CheckpointLoaderSimple", "_meta": { "title": "Checkpoint加载器(简易)" } } }, { "extra_pnginfo": { "workflow": { "last_node_id": 11, "last_link_id": 25, "nodes": [ { "id": 9, "type": "VAEEncodeForInpaint", "pos": [ 628, 394 ], "size": { "0": 315, "1": 98 }, "flags": {}, "order": 4, "mode": 0, "inputs": [ { "name": "pixels", "type": "IMAGE", "link": 19, "label": "图像" }, { "name": "vae", "type": "VAE", "link": 23, "label": "VAE" }, { "name": "mask", "type": "MASK", "link": 20, "label": "遮罩" } ], "outputs": [ { "name": "LATENT", "type": "LATENT", "links": [ 15 ], "shape": 3, "label": "Latent", "slot_index": 0 } ], "properties": { "Node name for S&R": "VAEEncodeForInpaint" }, "widgets_values": [ 12 ] }, { "id": 6, "type": "CLIPTextEncode", "pos": [ 687, 261 ], "size": { "0": 210, "1": 76 }, "flags": {}, "order": 3, "mode": 0, "inputs": [ { "name": "clip", "type": "CLIP", "link": 25, "label": "CLIP" } ], "outputs": [ { "name": "CONDITIONING", "type": "CONDITIONING", "links": [ 8 ], "shape": 3, "label": "条件", "slot_index": 0 } ], "properties": { "Node name for S&R": "CLIPTextEncode" }, "widgets_values": [ "bad fingers,bad hands,bad legs" ] }, { "id": 7, "type": "VAEDecode", "pos": [ 1032, 401 ], "size": { "0": 210, "1": 46 }, "flags": {}, "order": 6, "mode": 0, "inputs": [ { "name": "samples", "type": "LATENT", "link": 9, "label": "Latent" }, { "name": "vae", "type": "VAE", "link": 24, "label": "VAE" } ], "outputs": [ { "name": "IMAGE", "type": "IMAGE", "links": [ 10 ], "shape": 3, "label": "图像", "slot_index": 0 } ], "properties": { "Node name for S&R": "VAEDecode" } }, { "id": 8, "type": "PreviewImage", "pos": [ 1275, 404 ], "size": { "0": 210, "1": 246 }, "flags": {}, "order": 7, "mode": 0, "inputs": [ { "name": "images", "type": "IMAGE", "link": 10, "label": "图像" } ], "properties": { "Node name for S&R": "PreviewImage" } }, { "id": 5, "type": "CLIPTextEncode", "pos": [ 684, 134 ], "size": { "0": 210, "1": 76 }, "flags": {}, "order": 2, "mode": 0, "inputs": [ { "name": "clip", "type": "CLIP", "link": 21, "label": "CLIP", "slot_index": 0 } ], "outputs": [ { "name": "CONDITIONING", "type": "CONDITIONING", "links": [ 6 ], "shape": 3, "label": "条件", "slot_index": 0 } ], "properties": { "Node name for S&R": "CLIPTextEncode" }, "widgets_values": [ "beauty girl,8k,Facial details" ] }, { "id": 11, "type": "CheckpointLoaderSimple", "pos": [ 175, 109 ], "size": { "0": 315, "1": 98 }, "flags": {}, "order": 0, "mode": 0, "outputs": [ { "name": "MODEL", "type": "MODEL", "links": [ 22 ], "shape": 3, "label": "模型", "slot_index": 0 }, { "name": "CLIP", "type": "CLIP", "links": [ 21, 25 ], "shape": 3, "label": "CLIP", "slot_index": 1 }, { "name": "VAE", "type": "VAE", "links": [ 23, 24 ], "shape": 3, "label": "VAE", "slot_index": 2 } ], "properties": { "Node name for S&R": "CheckpointLoaderSimple" }, "widgets_values": [ "majicmixRealistic_v7.safetensors" ] }, { "id": 1, "type": "LoadImage", "pos": [ 171, 295 ], "size": { "0": 315, "1": 314 }, "flags": {}, "order": 1, "mode": 0, "outputs": [ { "name": "IMAGE", "type": "IMAGE", "links": [ 19 ], "shape": 3, "label": "图像", "slot_index": 0 }, { "name": "MASK", "type": "MASK", "links": [ 20 ], "shape": 3, "label": "遮罩", "slot_index": 1 } ], "properties": { "Node name for S&R": "LoadImage" }, "widgets_values": [ "clipspace/clipspace-mask-3740764.8999999994.png [input]", "image" ] }, { "id": 4, "type": "KSampler", "pos": [ 1166, 89 ], "size": { "0": 315, "1": 262 }, "flags": {}, "order": 5, "mode": 0, "inputs": [ { "name": "model", "type": "MODEL", "link": 22, "label": "模型" }, { "name": "positive", "type": "CONDITIONING", "link": 6, "label": "正面条件" }, { "name": "negative", "type": "CONDITIONING", "link": 8, "label": "负面条件" }, { "name": "latent_image", "type": "LATENT", "link": 15, "label": "Latent" } ], "outputs": [ { "name": "LATENT", "type": "LATENT", "links": [ 9 ], "shape": 3, "label": "Latent", "slot_index": 0 } ], "properties": { "Node name for S&R": "KSampler" }, "widgets_values": [ 586215496424602, "randomize", 30, 8, "dpmpp_3m_sde", "karras", 1 ] } ], "links": [ [ 6, 5, 0, 4, 1, "CONDITIONING" ], [ 8, 6, 0, 4, 2, "CONDITIONING" ], [ 9, 4, 0, 7, 0, "LATENT" ], [ 10, 7, 0, 8, 0, "IMAGE" ], [ 15, 9, 0, 4, 3, "LATENT" ], [ 19, 1, 0, 9, 0, "IMAGE" ], [ 20, 1, 1, 9, 2, "MASK" ], [ 21, 11, 1, 5, 0, "CLIP" ], [ 22, 11, 0, 4, 0, "MODEL" ], [ 23, 11, 2, 9, 1, "VAE" ], [ 24, 11, 2, 7, 1, "VAE" ], [ 25, 11, 1, 6, 0, "CLIP" ] ], "groups": [], "config": {}, "extra": { "ds": { "scale": 0.9090909090909091, "offset": [ 60.74419555664075, 11.355671691894536 ] } }, "version": 0.4 } }, "client_id": "d3d62130e6a24c7f8715df680cfe1d00" }, [ "8" ] ], "outputs": { "8": { "images": [ { "filename": "ComfyUI_temp_smrky_00097_.png", "subfolder": "", "type": "temp" } ] } }, "status": { "status_str": "success", "completed": true, "messages": [ [ "execution_start", { "prompt_id": "969f62cf-da2f-47f8-985c-ddd1c18da757" } ], [ "execution_cached", { "nodes": [ "5", "6", "11", "9", "1" ], "prompt_id": "969f62cf-da2f-47f8-985c-ddd1c18da757" } ] ] } } }

(4)添加流程任务
在这几个接口中,还有一个接口比较关键,就是向Comfyui中去添加一个流程任务,此时就要用到prompt接口。
POST / prompt
请求参数:
{ "client_id": "533ef3a3-39c0-4e39-9ced-37d290f371f8", "prompt": { "3": { "inputs": { "seed": 764714814161513, "steps": 26, "cfg": 5, "sampler_name": "dpmpp_3m_sde_gpu", "scheduler": "karras", "denoise": 1, "model": [ "40", 0 ], "positive": [ "49", 0 ], "negative": [ "6", 0 ], "latent_image": [ "5", 0 ] }, "class_type": "KSampler" }, "5": { "inputs": { "width": 1024, "height": 768, "batch_size": 1 }, "class_type": "EmptyLatentImage" }, "6": { "inputs": { "text": "", "clip": [ "40", 1 ] }, "class_type": "CLIPTextEncode" }, "8": { "inputs": { "samples": [ "3", 0 ], "vae": [ "40", 2 ] }, "class_type": "VAEDecode" }, "9": { "inputs": { "filename_prefix": "ComfyUI", "images": [ "8", 0 ] }, "class_type": "SaveImage" }, "13": { "inputs": { "clip_vision": [ "39", 0 ], "image": [ "34", 0 ] }, "class_type": "CLIPVisionEncode" }, "19": { "inputs": { "strength": 1, "noise_augmentation": 0, "conditioning": [ "42", 0 ], "clip_vision_output": [ "13", 0 ] }, "class_type": "unCLIPConditioning" }, "34": { "inputs": { "image": "clipspace/clipspace-mask-1645940.7000000002.png [input]", "choose file to upload": "image" }, "class_type": "LoadImage" }, "36": { "inputs": { "clip_vision": [ "39", 0 ], "image": [ "38", 0 ] }, "class_type": "CLIPVisionEncode" }, "37": { "inputs": { "strength": 0.75, "noise_augmentation": 0, "conditioning": [ "19", 0 ], "clip_vision_output": [ "36", 0 ] }, "class_type": "unCLIPConditioning" }, "38": { "inputs": { "image": "beijing1 (2).webp", "choose file to upload": "image" }, "class_type": "LoadImage" }, "39": { "inputs": { "clip_name": "clip_vision_g.safetensors" }, "class_type": "CLIPVisionLoader" }, "40": { "inputs": { "ckpt_name": "sd_xl_base_1.0.safetensors" }, "class_type": "CheckpointLoaderSimple" }, "42": { "inputs": { "conditioning": [ "6", 0 ] }, "class_type": "ConditioningZeroOut" }, "43": { "inputs": { "safe": "enable" }, "class_type": "HEDPreprocessor" }, "44": { "inputs": { "safe": "enable", "image": [ "34", 0 ] }, "class_type": "HEDPreprocessor" }, "45": { "inputs": { "images": [ "44", 0 ] }, "class_type": "PreviewImage" }, "46": { "inputs": { "control_net_name": "control-lora-depth-rank256.safetensors" }, "class_type": "ControlNetLoader" }, "47": { "inputs": { "image": [ "34", 0 ] }, "class_type": "ScribblePreprocessor" }, "48": { "inputs": { "images": [ "47", 0 ] }, "class_type": "PreviewImage" }, "49": { "inputs": { "strength": 0.5, "conditioning": [ "37", 0 ], "control_net": [ "46", 0 ], "image": [ "47", 0 ] }, "class_type": "ControlNetApply" } } }响应数据:
样例:
{ "prompt_id": "352c1fc4-7382-4c4a-965f-583c4b126a1b", "number": 38, "node_errors": {} }

九. 封装Comfyui客户端
为便于在我们程序中通过API来与Comfyui进行通信,我们可以先学习封装相关API,但值得注意的是:这里除封装上一节的API之外,还会封装通过Websocket取监听Comfyui的消息。
1. 创建项目
创建一个SpringBoot工程,名称叫star-graph,设置项目JDK为17版本,并按照以下配置进行初始化项目。
(1)设置项目Pom依赖
项目基于SpringBoot3.2版本进行构建,并引入了Redis、Mysql、Hutool、WebSocket等依赖(部分依赖作用后续会讲解)。把一下内容覆盖新建项目的pom.xml内容,然后刷新maven依赖。
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>cn.itcast</groupId> <artifactId>star-graph</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>17</maven.compiler.source> <maven.compiler.target>17</maven.compiler.target> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <mybatis_plus.version>3.5.7</mybatis_plus.version> </properties> <!--SpringBoot工程--> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>3.2.8</version> </parent> <dependencies> <!--SpringMvc环境的依赖包--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--单元测试环境--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-freemarker</artifactId> </dependency> <!--常用的工具包--> <dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.8.28</version> </dependency> <!--json数据处理--> <dependency> <groupId>com.alibaba.fastjson2</groupId> <artifactId>fastjson2</artifactId> <version>2.0.31</version> </dependency> <!--快速生成实体类的set/get方法--> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <scope>annotationProcessor</scope> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.33</version> </dependency> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>${mybatis_plus.version}</version> </dependency> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis-spring</artifactId> <version>3.0.3</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-websocket</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-validation</artifactId> </dependency> <!--retrofit客户端--> <dependency> <groupId>com.squareup.retrofit2</groupId> <artifactId>retrofit</artifactId> <version>2.11.0</version> </dependency> <dependency> <groupId>com.squareup.retrofit2</groupId> <artifactId>converter-jackson</artifactId> <version>2.11.0</version> </dependency> <dependency> <groupId>com.squareup.okhttp3</groupId> <artifactId>logging-interceptor</artifactId> <version>4.11.0</version> </dependency> <dependency> <groupId>org.redisson</groupId> <artifactId>redisson-spring-boot-starter</artifactId> <version>3.30.0</version> </dependency> </dependencies> <build> <finalName>star-graph-demo</finalName> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> </project><?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>cn.itcast</groupId> <artifactId>star-graph</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>17</maven.compiler.source> <maven.compiler.target>17</maven.compiler.target> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <mybatis_plus.version>3.5.7</mybatis_plus.version> </properties> <!--SpringBoot工程--> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>3.2.8</version> </parent> <dependencies> <!--SpringMvc环境的依赖包--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--单元测试环境--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> </dependency> <!--常用的工具包--> <dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.8.28</version> </dependency> <!--json数据处理--> <dependency> <groupId>com.alibaba.fastjson2</groupId> <artifactId>fastjson2</artifactId> <version>2.0.31</version> </dependency> <!--快速生成实体类的set/get方法--> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <scope>annotationProcessor</scope> </dependency> </project>(2)配置项目Yml文件
在resources下新建application.yml文件(现在还没用到里面暂时可以啥也不写)
由于项目依赖了Mysql和Redis,因此还需要再application.yml文件中配置相关的属性信息。
spring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.100.129:3306/star-graph?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=UTC&allowPublicKeyRetrieval=true username: root password: 123456 data: redis: host: 192.168.100.129 port: 6379 mybatis-plus: configuration: log-impl: org.apache.ibatis.logging.stdout.StdOutImpl global-config: db-config: table-prefix: sg_ logging: level: root: info(3)创建启动类并启动测试
最后新建一个启动类,并运行该启动类,如果启动过程未出现错误,则项目创建成功。
package cn.itcast.star.graph; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class StarGraphApp { public static void main(String[] args) { SpringApplication.run(StarGraphApp.class, args); } }
2. Retrofit客户端
创建好项目之后,接下来我们就要通过程序去访问Comfyui的接口,那么通过之前我们的学习,要在程序中去访问接口,势必要用到Http客户端(完全使用Java代码来实现了Http或者Https协议的三方库),而在Java开源领域有三大Http客户端可供我们选用:
OkHttp——Square公司——性能最好
HttpUrlConnection——JDK——性能最差
HttpClient——Apache
而在企业开发中,开发者不会直接使用这些Http客户端,而是选用这些客户端的封装框架,目前比较好用的封装框架有:
Retrofit——封装OkHttp
Huttol——封装HttpUrlConnection
RestTemplate封装了三个客户端
虽然上述3个框架都大大的封装和简化了Http客户端的使用API,但是在此还是要重点介绍一下Retrofit。
(1)Retrofit介绍
官网:Retrofit
Retrofit基于OkHttp开发的、类型安全的Android或Java Http框架。再此我们选用Retrofit框架的重点理由是它基于OkHttp封装,性能好,同时它融入了流行的声明式(PS:只需要定义,不需要实现)开发思想,便于我们开发和学习。
(2)Retrofit入门
导入依赖:
<!--retrofit客户端--> <dependency> <groupId>com.squareup.retrofit2</groupId> <artifactId>retrofit</artifactId> <version>2.11.0</version> </dependency> <dependency> <groupId>com.squareup.retrofit2</groupId> <artifactId>converter-jackson</artifactId> <version>2.11.0</version> </dependency> <dependency> <groupId>com.squareup.okhttp3</groupId> <artifactId>logging-interceptor</artifactId> <version>4.11.0</version> </dependency>在Retrofit中要实现一个Http请求总体来说共有以下2个步骤:
1、声明API
2、生效API
①声明API
我们可以先创建一个接口类:cn.itcast.star.graph.comfyui.client.api.ComfyuiApi,并按如下代码进行编写:
public interface ComfyuiApi { @GET("history") //获取历史记录 Call<HashMap> history(); @GET("/system_stats") //获取系统信息 Call<HashMap> getSystemStatus(); }使用Retrofit来声明API,其实就是声明接口方法,比如上述类中定义了一个方法getSystemStats:
方法名可以任意取,但建议与http接口名称一致
方法通过@GET注解声明当前请求方式是GET并且请求的地址为/system_stats,即获取Comfyui的系统信息接口
方法返回结果为Call<HashMap>对象
Call是固定的返回对象
HashMap则是接口返回的数据自动转成Map集合存储
②生效API
上面声明类要生效,我们还需要配置生效,可创建一个配置类:cn.itcast.star.graph.comfyui.client.config.ComfyuiConfig
@Configuration public class ComfyuiConfig { @Bean public ComfyuiApi comfyuiApi(){ //设置请求地址 Retrofit retrofit = new Retrofit.Builder() .baseUrl("http://192.168.100.129:8188"). addConverterFactory(JacksonConverterFactory.create()) //告诉Retrofit框架使用Jackson工具包来处理数据 .build(); //让Retrofit框架帮我们实现接口 ComfyuiApi comfyuiApi=retrofit.create(ComfyuiApi.class); return comfyuiApi; } }在类中:
首先通过Retrofit.Builder构建一个Retrofit客户端
通过baseUrl指定请求的服务器地址
通过addConverterFactory指定请求数据的转换器
最后调用 retrofit.create方法创建ComfyuiApi接口的实现
通过上述代码,在Spring IOC中就是声明好了一个可以远程调用获取Comfyui服务器状态的Bean.
③测试API
在测试包下创建类:cn.itcast.ComfyuiApiTest
注意:测试类和启动类包名要相同
@SpringBootTest public class ComfyuiApiTest { @Autowired ComfyuiApi comfyuiApi; @Test public void testHistory() throws IOException { Call<HashMap> history=comfyuiApi.history(); Response<HashMap> execute=history.execute(); System.out.println(execute.body()); } @Test public void testGetSystemStatus() throws IOException { Call<HashMap> history=comfyuiApi.getSystemStatus(); Response<HashMap> execute=history.execute(); //输出json格式 System.out.println(JSON.toJSONString(execute.body())); } }
3. 开启日志和HTTP超时时间
Retrofit还提供了打印日志的功能,方便我们进行BUG的排错。Retrofit日志功能默认是关闭的,可以通过以下代码进行开启:
@Configuration public class ComfyuiConfig { @Bean public ComfyuiApi comfyuiApi(){ //日志拦截器HttpLoggingInterceptor HttpLoggingInterceptor logInterceptor=new HttpLoggingInterceptor(); //设置拦截器的日志级别 logInterceptor.setLevel(HttpLoggingInterceptor.Level.BODY); //Retrofit的日志功能是通过底层OKHttp框架提供的 OkHttpClient client=new OkHttpClient.Builder() .addInterceptor(logInterceptor) //添加拦截器 .retryOnConnectionFailure(true) //连接出现超时失败情况就重连 .connectTimeout(Duration.ofSeconds(30))//连接超时时间 .readTimeout(Duration.ofSeconds(30))//读超时时间 .build(); //设置请求地址 Retrofit retrofit = new Retrofit.Builder() .baseUrl("http://192.168.100.129:8188") .client(client).addConverterFactory(JacksonConverterFactory.create()) //告诉Retrofit框架使用Jackson工具包来处理数据 .build(); //让Retrofit框架帮我们实现接口 ComfyuiApi comfyuiApi=retrofit.create(ComfyuiApi.class); return comfyuiApi; } }我们之前提供过Retrofit框架底层是通过OkHttp实现,Retrofit的日志功能也是交由底层OkHttp实现:
由于要重新设置OkHttp,因此代码中自行构建了OkHttpClient
给OkHttpClient增加了日志拦截器HttpLoggingInterceptor,并设置拦截器的日志级别为BODY
NONE:不输出
BASIC:输出基本摘要
HEADERS:输出头信息
BODY:输出body数据
最后第17行通过client方法,重新设定Retrofit底层使用的OkHttp客户端
4. 导入Comfyui封装的代码
通过Retrofit入门学习,可以看出使用Retrofit来定义一个API接口非常简单;那么对于Comfyui的其它接口,可以自行定义实现,或者直接导入资料文件下《Comfyui—API封装代码》文件夹下的代码,直接复制到cn.itcast.star.graph.comfyui.client包下,复制后的项目目录结构为:
其他接口:
public interface ComfyuiApi { /** * 获取历史任务 * @param maxItems 获取的条数 * @return */ @GET("/history") Call<HashMap> getHistoryTasks(@Query("max_items") int maxItems); /** * 获取预览的图片信息 * @param filename 文件名 * @param type 文件类型,input/output * @param subfolder 字文件夹名 * @return */ @GET("/view") Call<ResponseBody> getView(@Query("filename") String filename, @Query("type") String type, @Query("subfolder") String subfolder); /** * 获取系统信息 * @return */ @GET("/system_stats") Call<HashMap> getSystemStats(); /** * 获取某个节点配置 * @return */ @GET("/object_info/{nodeName}") Call<HashMap> getNodeInfo(@Path("nodeName") String nodeName); /** * 取消当前的任务 * @return */ @GET("/interrupt") Call<HashMap> interruptTask(); /** * 获取队列中的任务信息 * @return */ @GET("/queue") Call<HashMap> getQueueTasks(); /** * 获取队列中的任务信息 * @return */ @POST("/queue") Call<HashMap> deleteQueueTasks(@Body DeleteQueueBody body); /** * 获取队列中任务数量 * @return */ @GET("/prompt") Call<QueueTaskCount> getQueueTaskCount(); /** * 添加流程任务 * @return */ @POST("/prompt") Call<HashMap> addQueueTask(@Body ComfyuiRequestDto body); /** * 上传图片 * @return */ @Multipart @POST("/upload/image") Call<HashMap> uploadImage(@Part MultipartBody.Part image); /** * 上传图片 * @return */ @Multipart @POST("/upload/mask") Call<HashMap> uploadMask(@Part MultipartBody.Part image,@Part("type") RequestBody type,@Part("subfolder") RequestBody subfolder, @Part("original_ref") RequestBody originalRef); /** * 获取某个历史任务 * @param promptId 任务ID * @return */ @GET("/history/{promptId}") Call<HashMap> getHistoryTask(@Path("promptId") String promptId); }在代码中声明了Comfyui的全部API,且声明时还使用到一些新注解,可解释为:
@Query:用来声明http查询部分的参数,与@RequestParam类似
@Body:用于声明请求体对象,与@RequestBody类似
@Multipart:用于说明当前请求以表单形式发起,常常用于带有文件的接口
如果是文件字段需要使用 MultipartBody.Part
如果是非文件字段需要使用 RequestBody
@Part:用于说明一个表单字段
@Path:用于说明请求路径参数,与@PathVariable类似
@Headers:设定请求头信息
@Header:设定一个头字段
@HeaderMap :把一个Map内容设定到请求头中
5. 封装Comfyui的事件客户端
Comfyui除了提供API接口之外,还提供了Webcoket服务,通过Webcoket可以接受Comfyui在生图过程中的系列事件,而这些事件常常是业务开发过程中需要用到的,比如图片生产进度事件,应用后端需要监听Comfyui获取进度消息,然后再把消息推送给应用前端,这样应用前端即可同步显示进度。
在上图中,应用后端即是WS客户端也是服务端:
应用后端是WebSocket的客户端,用于接受Comfyui广播的消息
应用后端也是WebSocket的服务端,用于给应用前端推送消息
在这里我们先关注应用后端作为Comfyui客户端的情况,如果监听和接收Comfyui的消息。而要实现这一功能,我们可以参考以下步骤进行实现:
继承实现TextWebSocketHandler类,当收到消息时,调用该类。
提供一个WebSocketConnectionManager连接管理器,并启动。

(1)实现消息处理类
引入websocket依赖:
<!--继承websocket--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-websocket</artifactId> </dependency>创建类cn.itcast.star.graph.comfyui.client.handler.ComfyuiMessageHandler,并参考以下代码进行实现:
@Component public class ComfyuiMessageHandler extends TextWebSocketHandler { @Override public void afterConnectionEstablished(WebSocketSession session) throws Exception { System.out.println("=============连接成功"); } @Override protected void handleTextMessage(WebSocketSession session, TextMessage message) throws Exception { System.out.println("=============收到消息:"+message.getPayload()); } }代码说明:
TextWebSocketHandler类是Spring提供的一个文本消息处理类,它实现了WebSocketHandler接口
当连接成功服务器之后会调用afterConnectionEstablished方法
当接收到服务器推送的消息之后,会调用handleTextMessage方法
(2)实现连接管理器
连接管理器是一个Bean,我们可以直接在cn.itcast.star.graph.comfyui.client.config.ComfyuiConfig配置类中进行补充:
//声明一个WebSocket客户端并启动生效 @Bean public WebSocketConnectionManager webSocketConnectionManager (ComfyuiMessageHandler comfyuiMessageHandler){ WebSocketClient client = new StandardWebSocketClient(); String url = "ws://192.168.100.129:8188/ws?clientId=star-graph"; WebSocketConnectionManager webSocketConnectionManager = new WebSocketConnectionManager(client,comfyuiMessageHandler,url); webSocketConnectionManager.start(); return webSocketConnectionManager; }代码说明:
注册连接管理器Bean
由于第7,8行要用到WebSocketClient、url,因此第5行先进行了定义
第7行直接通过new构造一个连接管理器
第9行通过start方法立即提供连接管理器(即立即去连接Url地址指定的服务器)
(3)Comfyui推送消息内容及格式
Comfyui通过websocket推送的消息类型及格式如下,再次可以先了解一些,便于后续我们查询和使用。
status:队列状态变更消息
{"type": "status", "data": {"status": {"exec_info": {"queue_remaining": 1}}}}progress:生图处理步骤
{"type": "progress", "data": {"value": 5, "max": 20, "prompt_id": "594ac476-e599-47c1-a99f-bf8a384cfcdb", "node": "4"}}executing:某个节点开始执行
{"type": "executing", "data": {"node": "4"}}executed:生图结果
{"type": "executed", "data": {"node": "9", "output": {"images": [{"filename": "ComfyUI_00239_.png", "subfolder": "", "type": "output"}, {"filename": "ComfyUI_00240_.png", "subfolder": "", "type": "output"}]}, "prompt_id": "c4fba48d-1605-4e94-aabd-a37211204c2f"}}- execution_start:任务开始执行事件
{"type": "execution_start", "data": {"prompt_id": "c25e865d-2307-4482-ac2d-fef2c2993688"}}- execution_error:
{"type": "execution_error", "data": {"node_id": "1", "node_type":"","exception_message":"异常信息"}}- execution_success:执行成功消息
{"type": "execution_success", "data": {"prompt_id": "594ac476-e599-47c1-a99f-bf8a384cfcdb", "timestamp": 1723966039722}}
十. 星图AI项目开发
1.星图AI项目项目
星图AI项目是一款创新的互联网AI平台,专注于为用户提供高效便捷的文本转图像及视频生成服务。该平台集成了多种前沿技术,包括文本生成图像(文生图)、图像间转换(图生图)、基于姿势生成图像(姿势生图 )、图像画质增强以及文本和视频的直接转换(文生视频、图生视频)等功能,极大地丰富了用户的创作体验与表达形式。
通过本项目的学习,重点掌握AIGC中文生多媒体的相关技术、解决方案等内容,并能通过所学的知识,能够独立设计与开发出相关的应用需求。
2. 项目整体演示
在虚拟机中内置了AI星图的演示环境,我们可以通过这个环境快速体验星图项目,具体的环境启动可以参考一下命令进行操作:
# 进入到/root/demo/starg目录 [root@bogon starg]# pwd /root/demo/starg # 查看文件夹文件是否齐全 [root@bogon starg]# ls cstar.sh docker-compose-env.yml DockerfileStarGraph mysql nginx star-graph-demo.jar start.sh # 通过start.sh文件启动环境 [root@bogon starg]# sh start.sh 2e56d7c7a55a 91322b2a8b72 f4e02e1a45e1 f55273838cb6 12668037cfb7 c3d6c866db46 4e2b40595dbd a3ebb19ad34c Starting star-demo-redis ... done Starting star-demo-nginx ... done Starting star-demo-comfyui ... done Starting star-demo-graph ... done Starting star-demo-mysql ... done [root@bogon starg]#然后再浏览器中输入http://192.168.100.129:3000即可访问星图项目。
进入到【文生图】界面,然后输入【美女,沙滩,太阳伞】,然后点击【发送】按钮,星图就开始进行图片的生成了。
由于使用的是虚拟机CPU进行图片的生成,因此过程比较慢(一般在5分钟左右),然后即可在前端看见生成的结果。
同时还可以在【我的图片】中看见历史上生成的图片结果:
3. 项目技术架构
项目总体也是基于SMM架构(既SpringBoot3+Mybatis-Plus+Mysql),但在此基础之上融入了Comfyui、Ollama、WebSocket、Redisson、Freemarker、Retrofit2等前沿的技术。另外整体项目环境也是通过Docker来进行构建。
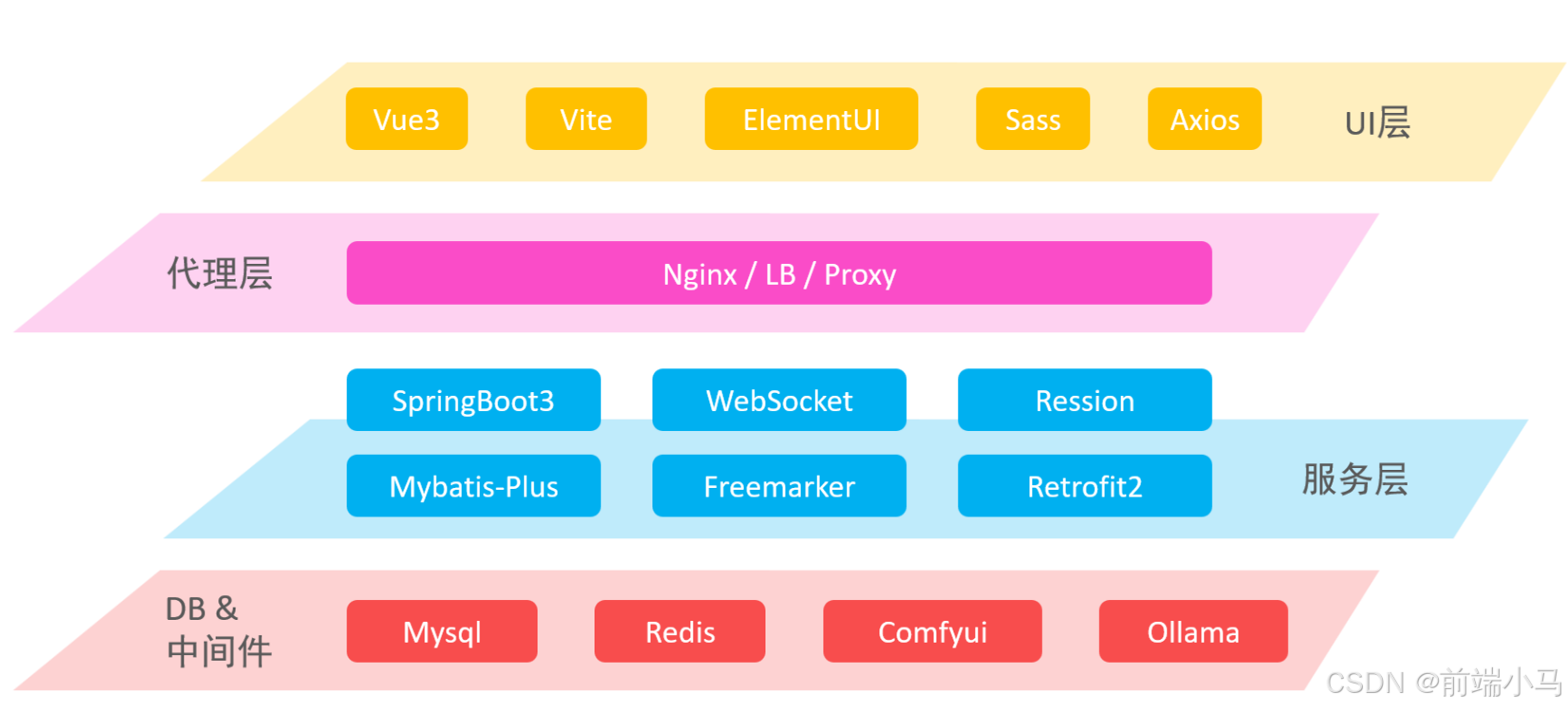
4. 项目开发环境
命令说明:
开发环境的启动命令存放在:/root/dev/star-graph目录
开发环境是通过dokcer-compose来进行构建的,其中包括了3个软件环境:
redis
mysql
comfyui
启动开发环境的命令是:sh start.sh
在虚拟机中内置了AI星图的开发环境,我们可以通过一下命令进行开发环境的启动:
[root@localhost star-graph]# pwd /root/dev/star-graph [root@localhost star-graph]# ls docker-compose-env.yml mysql start.sh [root@localhost star-graph]# cat docker-compose-env.yml version: "3.0" services: stardev-comfyui: container_name: "star-dev-comfyui" image: comfyui:0.0.2 volumes: - /root/data/ComfyUI/custom_nodes:/root/data/ComfyUI/custom_nodes - /root/data/ComfyUI/input:/root/data/ComfyUI/input - /root/data/ComfyUI/output:/root/data/ComfyUI/output - /root/data/ComfyUI/models:/root/data/ComfyUI/models network_mode: host stardev-mysql: container_name: "star-dev-mysql" image: mysql volumes: - /root/data/mysql/my.cnf:/etc/mysql/my.cnf - /root/data/mysql/data:/var/lib/mysql environment: - MYSQL_ROOT_PASSWORD=123456 network_mode: host stardev-redis: container_name: "star-dev-redis" image: redis network_mode: host command: redis-server --appendonly yes [root@localhost star-graph]# sh start.sh如果报错就docker ps -a找到mysql的ip,然后docker rm ip删除
连接数据库(密码是上面设置的123456):
连接不上的话找到/root/data/mysql里的data文件和my.cnf删了重启一下就行了
5. 登录功能开发
在星图系统中,生成一张图片是要消耗1积分,用户积分使用完成之后,可以通过重置购买积分。基于这样的业务,星图系统则需要提供会员功能,因此我们可以先来完成星图会员登录功能的开发。
(1) 需求说明
星图会员可以使用手机号或者用户名,加上密码进行登录。
登录成功之后,在右上角显示用户的头像和用户名。

(2)用户表设计
从需求中可知用户表需要包括用户名、手机号、头像3个字段,同时用户登录还需要密码字段,因此我们设计的用户表至少要包括4个字段。也可以参考demo环境的用户表设计。表名的前缀sg是star-graph项目名称的缩写。
CREATE TABLE `sg_user` ( `id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键', `create_time` datetime DEFAULT NULL COMMENT '创建时间', `update_time` datetime DEFAULT NULL COMMENT '更新时间', `mobile` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '手机', `password` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '登录密码', `status` tinyint unsigned DEFAULT NULL COMMENT '状态 0 正常 1超时锁定 2锁定 9无效 ', `username` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '姓名', `email` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '邮箱', `vip_level` tinyint unsigned DEFAULT '0' COMMENT '会员等级', `deleted` tinyint unsigned DEFAULT '0' COMMENT '逻辑删除', `nickname` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '昵称', `avatar` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '头像', `gender` tinyint unsigned DEFAULT NULL COMMENT '性别', PRIMARY KEY (`id`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci ROW_FORMAT=DYNAMIC COMMENT='用户信息表';
(3)登录接口设计
请求方式:POST
请求地址:/api/1.0/user/login
请求参数:
{ "username":"用户名/手机号", "password":"密码" }响应数据:
{ "id":"用户ID", "name":"用户名称", "avatar":"头像图片", "token":"JWT Token" }
①导入依赖并写配置
导入依赖:
<--数据库驱动--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.33</version> </dependency> <!--Mybatis-plus--> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.5.7</version> </dependency> <!--这里导入是为了解决mybatis支持Spring-boot最新版本的问题--> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis-spring</artifactId> <version>3.0.3</version> </dependency>在application.yml中写配置:
spring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.100.129:3306/star-graph?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=UTC&allowPublicKeyRetrieval=true username: root password: 123456 server: port: 8080
②实现User实体
创建类cn.itcast.star.graph.core.pojo.User,并映射sg_user到对应字段。
@Getter @Setter @TableName("sg_user") public class User implements Serializable { private static final long serialVersionUID = 1L; //主键 @TableId(type = IdType.ASSIGN_ID) private Long id; //创建时间 @TableField(fill = FieldFill.INSERT) private LocalDateTime createTime; //更新时间 @TableField(fill = FieldFill.INSERT_UPDATE) private LocalDateTime updateTime; //手机 private String mobile; //登录密码 private String password; //状态 0 正常 1超时锁定 2锁定 9无效 private Integer status; //姓名 private String username; //邮箱 private String email; //会员等级 private Integer vipLevel; //逻辑删除 private Integer deleted; //昵称 private String nickname; //头像 private String avatar; //性别 private Integer gender; }
③实现UserMapper
创建cn.itcast.star.graph.core.mapper.UserMapper类,并集成BaseMapper。
@Mapper public interface UserMapper extends BaseMapper<User> {}
④导入dto类
把资料文件夹下的dto文件夹拷贝到cn.itcast.star.graph.core包下,拷贝后的目录结构是:
PageRequestDto:
@Data public class PageRequestDto { private Integer pageNum; private Integer pageSize; public void checkPage() { if(pageNum==null||pageNum<=0) { pageNum = 1; } if(pageSize==null||pageSize<=0) { pageSize = 150; } if(pageSize>200){ pageSize = 150; } } }PageRequest:
@Data @NoArgsConstructor @AllArgsConstructor public class PageResult<T> extends Result<T> { private long total; public static PageResult ok(long total, Object data) { PageResult tPageResult = new PageResult<>(); tPageResult.setCode(HttpStatus.HTTP_OK+""); tPageResult.setMsg(REQUEST_OK); tPageResult.setTotal(total); tPageResult.setData(data); return tPageResult; } }Result:
@Data @NoArgsConstructor @AllArgsConstructor @Builder public class Result<T> { protected static final String REQUEST_OK = "ok"; private String code; private String msg; private T data; public static Result<Void> ok() { return new Result<Void>(HttpStatus.HTTP_OK+"", REQUEST_OK, null); } public static <T> Result<T> ok(T body) { return new Result(HttpStatus.HTTP_OK+"", REQUEST_OK, body); } public static <T> Result<T> error(String msg) { return new Result<>(HttpStatus.HTTP_BAD_REQUEST+"", msg, null); } public static <T> Result<T> error(int code, String msg) { return new Result<>(code+"", msg, null); } public static <T> Result<T> failed(ResultCode resultCode) { return new Result<>(resultCode.getCode(), resultCode.getMsg(), null); } }ResultCode:
@AllArgsConstructor @NoArgsConstructor public enum ResultCode implements Serializable { SUCCESS("00000", "一切ok"), USER_ERROR("A0001", "用户端错误"), REPEAT_SUBMIT_ERROR("A0002", "您的请求已提交,请不要重复提交或等待片刻再尝试。"), USER_LOGIN_ERROR("A0200", "用户登录异常"), USER_NOT_EXIST("A0201", "用户不存在"), USER_ACCOUNT_LOCKED("A0202", "用户账户被冻结"), USER_ACCOUNT_INVALID("A0203", "用户账户已作废"), USERNAME_OR_PASSWORD_ERROR("A0210", "用户名或密码错误"), PASSWORD_ENTER_EXCEED_LIMIT("A0211", "用户输入密码次数超限"), CLIENT_AUTHENTICATION_FAILED("A0212", "客户端认证失败"), VERIFY_CODE_TIMEOUT("A0213", "验证码已过期"), VERIFY_CODE_ERROR("A0214", "验证码错误"), TOKEN_INVALID("A0230", "token无效或已过期"), TOKEN_ACCESS_FORBIDDEN("A0231", "token已被禁止访问"), AUTHORIZED_ERROR("A0300", "访问权限异常"), ACCESS_UNAUTHORIZED("A0301", "访问未授权,请重新登录后重试"), FORBIDDEN_OPERATION("A0302", "演示环境禁止新增、修改和删除数据,请本地部署后测试"), PARAM_ERROR("A0400", "用户请求参数错误"), RESOURCE_NOT_FOUND("A0401", "请求资源不存在"), PARAM_IS_NULL("A0410", "请求必填参数为空"), USER_UPLOAD_FILE_ERROR("A0700", "用户上传文件异常"), USER_UPLOAD_FILE_TYPE_NOT_MATCH("A0701", "用户上传文件类型不匹配"), USER_UPLOAD_FILE_SIZE_EXCEEDS("A0702", "用户上传文件太大"), USER_UPLOAD_IMAGE_SIZE_EXCEEDS("A0703", "用户上传图片太大"), SYSTEM_EXECUTION_ERROR("B0001", "系统执行出错"), SYSTEM_EXECUTION_TIMEOUT("B0100", "系统执行超时"), SYSTEM_ORDER_PROCESSING_TIMEOUT("B0100", "系统订单处理超时"), SYSTEM_DISASTER_RECOVERY_TRIGGER("B0200", "系统容灾功能被出发"), FLOW_LIMITING("B0210", "系统限流"), DEGRADATION("B0220", "系统功能降级"), SYSTEM_RESOURCE_ERROR("B0300", "系统资源异常"), SYSTEM_RESOURCE_EXHAUSTION("B0310", "系统资源耗尽"), SYSTEM_RESOURCE_ACCESS_ERROR("B0320", "系统资源访问异常"), SYSTEM_READ_DISK_FILE_ERROR("B0321", "系统读取磁盘文件失败"), CALL_THIRD_PARTY_SERVICE_ERROR("C0001", "调用第三方服务出错"), MIDDLEWARE_SERVICE_ERROR("C0100", "中间件服务出错"), INTERFACE_NOT_EXIST("C0113", "接口不存在"), MESSAGE_SERVICE_ERROR("C0120", "消息服务出错"), MESSAGE_DELIVERY_ERROR("C0121", "消息投递出错"), MESSAGE_CONSUMPTION_ERROR("C0122", "消息消费出错"), MESSAGE_SUBSCRIPTION_ERROR("C0123", "消息订阅出错"), MESSAGE_GROUP_NOT_FOUND("C0124", "消息分组未查到"), DATABASE_ERROR("C0300", "数据库服务出错"), DATABASE_TABLE_NOT_EXIST("C0311", "表不存在"), DATABASE_COLUMN_NOT_EXIST("C0312", "列不存在"), DATABASE_DUPLICATE_COLUMN_NAME("C0321", "多表关联中存在多个相同名称的列"), DATABASE_DEADLOCK("C0331", "数据库死锁"), DATABASE_PRIMARY_KEY_CONFLICT("C0341", "主键冲突"); public String getCode() { return code; } public String getMsg() { return msg; } private String code; private String msg; @Override public String toString() { return "{" + "\"code\":\"" + code + '\"' + ", \"msg\":\"" + msg + '\"' + '}'; } public static ResultCode getValue(String code){ for (ResultCode value : values()) { if (value.getCode().equals(code)) { return value; } } return SYSTEM_EXECUTION_ERROR; // 默认系统执行错误 } }CanelTaskResDto:
@Data public class CanelTaskResDto { private String tempId = ""; private Long index; }Text2ImageResDto⑤
@Data public class Text2ImageResDto { private String clientId = ""; // 图片比例 1=1:1 2=3:4 3=4:3 private int scale = 1; // 图片张数 @Max(message = "最多生成4张",value = 4) private int size = 1; // 步数 private int step = 20; // 强度 private int cfg = 7; // 采样计划 1=DPM++ SDE Karras 2=DPM++ 2S Karras 3=Euler Karras 4=DPM++ 3M SDE Karras private int sampler = 1; // 随机种子 @Min(message = "最小值为0",value = 0) private long seed = 0; // 正向词 @NotBlank(message = "请输入提示词") private String propmt = ""; // 负向词 private String reverse = ""; // 模型 private int model = 1; public String modelName(){ switch (model){ case 2: return "anythingelseV4_v45.safetensors"; default: return "majicmixRealistic_v7.safetensors"; } } public String samplerName(){ switch (sampler){ case 1: return "dpmpp_sde"; case 2: return "dpmpp_2m"; case 3: return "euler"; case 4: return "dpmpp_3m_sde"; default: return "euler"; } } public String scheduler(){ return "karras"; } public int width() { if(scale==3){ return 768; } else { return 512; } } public int height() { if(scale==2){ return 768; } else { return 512; } } }UserLoginReqDTO:
@Data public class UserLoginReqDTO { private String username; private String password; }Text2ImageReqDto:
@Data public class Text2ImageReqDto { private String pid; private long queueIndex = 0; }UserLoginResDTO:
@Data public class UserLoginResDTO { Long id; private String token; private String name; private String avatar; private Integer vipLevel; private Integer standing; }
⑤封装JWTUtils
创建工具类cn.itcast.star.graph.core.utils.JWTUtils,然后实现一个静态方法createJWT,用于生成一个JWT Token。
在Jwt的载荷中存入了用户的id和名称
并且设置Jwt的有效时间为1年
设置JWT签名的秘钥key
最后调用sign方法生成token
public class JwtUtils { static final String key="itheima.com"; //生成token public static String getToken(User user){ return JWT.create() .setPayload("uid",user.getId()) .setPayload("username",user.getUsername()) .setExpiresAt(DateTime.now().offsetNew(DateField.YEAR,1)) .setKey(key.getBytes()) .sign(); } }
⑥实现UserControlle
创建cn.itcast.star.graph.core.controller.UserController类,并注入UserService,然后调用login方法实现登录
@RestController @RequestMapping("/api/1.0/user") public class UserController { @Autowired private UserService userService; @PostMapping("/login") public Result<UserLoginResDTO> login(@RequestBody UserLoginReqDTO dto) throws BadRequestException { UserLoginResDTO userLoginResDTO = userService.loginByPassword(dto); return Result.ok(userLoginResDTO); } }
⑦UserService接口及实现UserServiceImpl
创建cn.itcast.star.graph.core.service.UserService
public interface UserService extends IService<User> {}创建cn.itcast.star.graph.core.service.impl.UserServiceImpl类,并在其中实现登录方法。
@Service @Transactional @Slf4j public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService { @Override public UserLoginResDTO loginByPassword(UserLoginReqDTO dto) throws BadRequestException { //1. 参数判断,判断用户名是否为空 if(StrUtil.isBlank(dto.getUsername())|| StrUtil.isBlank(dto.getPassword())){ throw new CustomException("用户名或密码不能为空"); } //2. 查数据库:通过用户名查询数据库,查手机和用户名 LambdaQueryWrapper<User> wapper= new LambdaQueryWrapper<>(); wapper.eq(User::getMobile,dto.getUsername()) .or() .eq(User::getUsername,dto.getUsername()); User user=baseMapper.selectOne(wapper);//baseMapper是Service层内置的,表示xxxMapper //3. 判断输入的密码和数据库中的密码是否都一致,数据库存储的密码是加密的(MD5+盐) // 把输入的密码按照加密规则生成,对比密码,如果一致则生成token并按格式返回 if(user==null){ throw new CustomException("用户名或密码不正确"); } if(!BCrypt.checkpw(dto.getPassword(),user.getPassword())){ throw new CustomException("用户名或密码不正确"); } //4. 生成token并按格式返回 UserLoginResDTO userLoginResDTO= new UserLoginResDTO(); userLoginResDTO.setAvatar(user.getAvatar()); userLoginResDTO.setId(user.getId()); userLoginResDTO.setName(user.getUsername()); userLoginResDTO.setToken(JwtUtils.getToken(user)); return userLoginResDTO; } }
⑧实现全局异常
为了把Controller执行过程中的异常信息,封装成统一的格式返回给前端,可以创建一个自定义异常类cn.itcast.star.graph.core.Exception.CustomException和全局异常处理类cn.itcast.star.graph.core.advice.CommonExceptionAdvice,在类中我们把所有的CustomException都封装成错误信息返回给前端。
//自定义异常类 public class CustomException extends RuntimeException{ public CustomException(String message) { super(message); } } //全局异常处理类 @RestControllerAdvice public class CommonExceptionAdvice { @ExceptionHandler(CustomException.class) public ResponseEntity customException(CustomException customException){ ResponseEntity<Result<Object>> responseEntity= ResponseEntity.status(HttpStatus.OK.value()) .body(Result.error(customException.getMessage())); return responseEntity; } } 或(上面那种能返回的数据更多) @RestControllerAdvice public class CommonExceptionAdvice { @ExceptionHandler(CustomException.class) public Result customException(CustomException customException){ return Result.error(customException.getMessage()); } }
⑨添加初始用户信息
新设计的用户信息表中没有任何的用户信息,我们可以写一个测试类来添加2个测试用户,参考导入如下,写好之后直接运行测试方法即可添加用户。
@SpringBootTest public class UserTest { @Autowired UserMapper userMapper; @Test public void testAddUser(){ User user = new User(); user.setAvatar("https://img0.baidu.com/it/u=3196617431,1263013381&fm=253&app=120&size=w931&n=0&f=JPEG&fmt=auto?sec=1740848400&t=307af88ee5bacb33c428dd06f14dd8ee"); user.setUsername("xiaoma"); user.setPassword(BCrypt.hashpw("123456")); user.setMobile("2803790450"); user.setCreateTime(LocalDateTime.now()); user.setUpdateTime(LocalDateTime.now()); userMapper.insert(user); } @Test public void testAddUser2(){ User user = new User(); user.setAvatar("https://img0.baidu.com/it/u=3196617431,1263013381&fm=253&app=120&size=w931&n=0&f=JPEG&fmt=auto?sec=1740848400&t=307af88ee5bacb33c428dd06f14dd8ee"); user.setUsername("admin"); user.setPassword(BCrypt.hashpw("123456")); user.setMobile("13823232323"); user.setCreateTime(LocalDateTime.now()); user.setUpdateTime(LocalDateTime.now()); userMapper.insert(user); } }
⑩测试登陆接口
使用Apifox工具进行测试,如果能正常返回token信息,则表示接口正常可用。
6. 导入前端工程
为方便后续接口的测试,可以直接导入星图前端项目,在资料文件夹下找到《star-graph-ui-完整前端.zip》文件,并复制到代码文件夹下并解压,然后进入解压后的文件夹star-graph-ui,并打开VSCode进行环境确认和依赖安装(npm i依赖安装),启动项目:npm run dev
打开的网页中,点击【登录/注册】按钮:
登录成功之后,即可在右上角看见登录的用户信息:
7. 文生图功能开发
(1)需求说明
在文生图功能中,我们为用户提供了前所未有的便捷与深度定制体验。用户仅需轻轻输入一句话,即可瞬间激发创意,快速生成一幅生动的图片,让想象跃然屏上。但我们的功能远不止于此,为了满足用户对图片生成效果的更高追求,我们还精心设计了多项参数调节选项。
模型选择:用户可根据个人喜好或特定需求,在多样化的模型库中选择最合适的生成模型。每个模型都蕴含着独特的艺术风格与表现力,让用户的创作空间无限拓展。
比例设定:灵活调整图片的宽高比,无论是经典的4:3、流行的16:9,还是个性化的自定义比例,都能轻松实现,确保生成的图片完美适配各种应用场景。
张数控制:除了基础的批量生成功能外,用户还可以精确设置想要生成的图片张数,无论是单张精品还是系列作品,都能随心所欲地创作。
步数与强度调节:深入细节,用户可以通过调整生成过程中的步数与强度参数,来精细控制图片的细腻程度与风格强度,让每一张图片都充满个性与魅力。
采样与种子优化:为了增加生成图片的多样性与独特性,我们引入了采样与种子设置。用户可以通过调整采样方式或输入特定种子值,来探索更多可能的图片生成结果,发现意想不到的艺术之美。
负向词过滤:为了确保生成图片的内容与用户意图高度契合,我们还提供了负向词过滤功能。用户可以输入不希望出现在图片中的关键词汇,系统将自动规避这些元素,让创作更加纯净与精准。
为了优化用户体验并确保资源高效利用,文生图功能实施了精细化的操作流程与资源管理策略。该功能要求用户登录后方可操作,旨在保障每位用户的数据安全与操作记录的可追溯性。
积分系统:每成功生成一张图片,系统将自动扣除用户1积分。考虑到用户可能希望一次性获得更多创意输出,我们特别设置了批量生成选项,比如用户可选择一次性生成3张图片,此时系统将按3积分进行扣除,极大地提升了生成效率与用户满意度。
排队与优先级机制:鉴于服务器资源的宝贵性,所有文生图请求均采取智能排队策略。在队列中等待的任务,用户可根据需求选择是否取消,以灵活调整自己的创作计划。同时,为了满足部分用户的紧急需求,我们推出了积分插队服务——用户可通过消耗额外的5积分,使自己的任务提前至队列前10个位置,快速获得处理机会,这一机制确保了资源的合理分配与高效利用。
实时进度追踪:对于正在处理中比、预计剩余时间等关键信息,让等待过程更加透明与安心。
成果即时展示:一旦图片生成成功,系统将自动推送通知,并在用户界面显著位置展示生成结果。这一即时反馈机制不仅提升了用户的创作流畅度,还让用户能够第一时间欣赏到自己的创意成果,激发更多创作灵感。

(2)文生图接口设计
请求方式:POST
请求地址:/api/authed/1.0/t2i/propmt
请求参数:
{ "size": 1, "model": 1, "scale": 1, "step": 25, "cfg": 8, "sampler": 1, "seed": 0, "reverse": "", "propmt": "美女,沙滩,伞", "clientId": 1724138388889 }字段说明:
响应结果:
字段 作用 值说明 size 图片生成张数 1~4 一次最大生成4张 model 模型 1现实人物,2二次元 scale 图片尺寸 1=1:1 2=3:4 3=4:3 step 生图步骤 cfg 生图强度 sampler 采样计划 1=DPM++ SDE Karras 2=DPM++ 2S Karras 3=Euler Karras 4=DPM++ 3M SDE Karras seed 种子 propmt 正向词 reverse 负向词 clientId 客户端唯一ID 用与消息推送使用 字段说明:{ "pid":"1afsa-121as-121af-121as", "queueIndex":0 }
字段 作用 值说明 pid 任务临时ID UUID格式 queueIndex 任务序号 数字
(3)思路分析—数据流分析法
通过上述了解,会发现文生图这个需求非常的复杂,包含登录人判断、任务队列排队、队列任务调度、用户积分划扣、消息推送等各种场景融合。在如此复杂的场景下,如果要全盘考虑如何实现?很容易考虑不全或者无从下手,那么如遇此业务场景,可按照数据流方式对业务进行梳理,比如:
上图的核心数据流为:
1、用户请求:用户发起生图请求
2、翻译中文:用户请求中输入的文本是中文的,Comfyui不认识,因此需要翻译成英文的
3、封装任务:把用户请求中的参数设定成Comfyui所需要的格式
4、插入队列:把封装好的生图任务存入队列中,等待处理
5、队列任务调度:当Comfyui中任务处理完成,则从Redis中取出一个任务发送给Comfyui进行处理
6、事件监听器:监听Comfyui生图处理的事件,依据不同的事件类型进行不同的处理
如果是进度事件:则推送给前端页面进行进度同步
如果是完成事件:则推送前端生图结果,并且通知继续调度下一个任务
除此之外,还存在一些细节,比如:
用户登录拦截:生图功能必须要登录后才可以操作,因此在处理业务之前需要判断用户是否登录
用户积分冻结:由于生图功能需要扣除积分,因此在处理业务的时候可以先进行积分是否充足判断,但由于此时任务只加入队列,并没有执行,不能直接扣除积分,因此在其中引入了一个冻结积分的概念,指预占用的积分
冻结积分归还:当调度器向Comfyui中添加任务时,如果失败,则需要把冻结的积分返还
冻结积分划扣/归还:如果生图结果成功,则需要把占用的冻结积分真实划扣,如果生图结果失败,则需要把冻结的积分返还
有了数据流图之后,我们就可以去进行设计表、接口即开发了,但是在这里我们还需要学会探讨一个问题:复杂业务流程的开发方式是什么?
针对这个问题常见有以下两种方式:
方式1:按照数据流图一步一步开发
方式2:先开发主流程,再开发次流程,如果流程太长,需要分段开发
在实际开发中,因为复杂长流程业务,分成短的业务进行开发更容易测试,因此实际开发常常选用方式2。
那么鉴于此思想,我们可以把业务拆分为以下几步:
- 拦截用户信息
- 添加生图任务
- 调度生图任务
- 处理任务事件
- 处理积分划扣
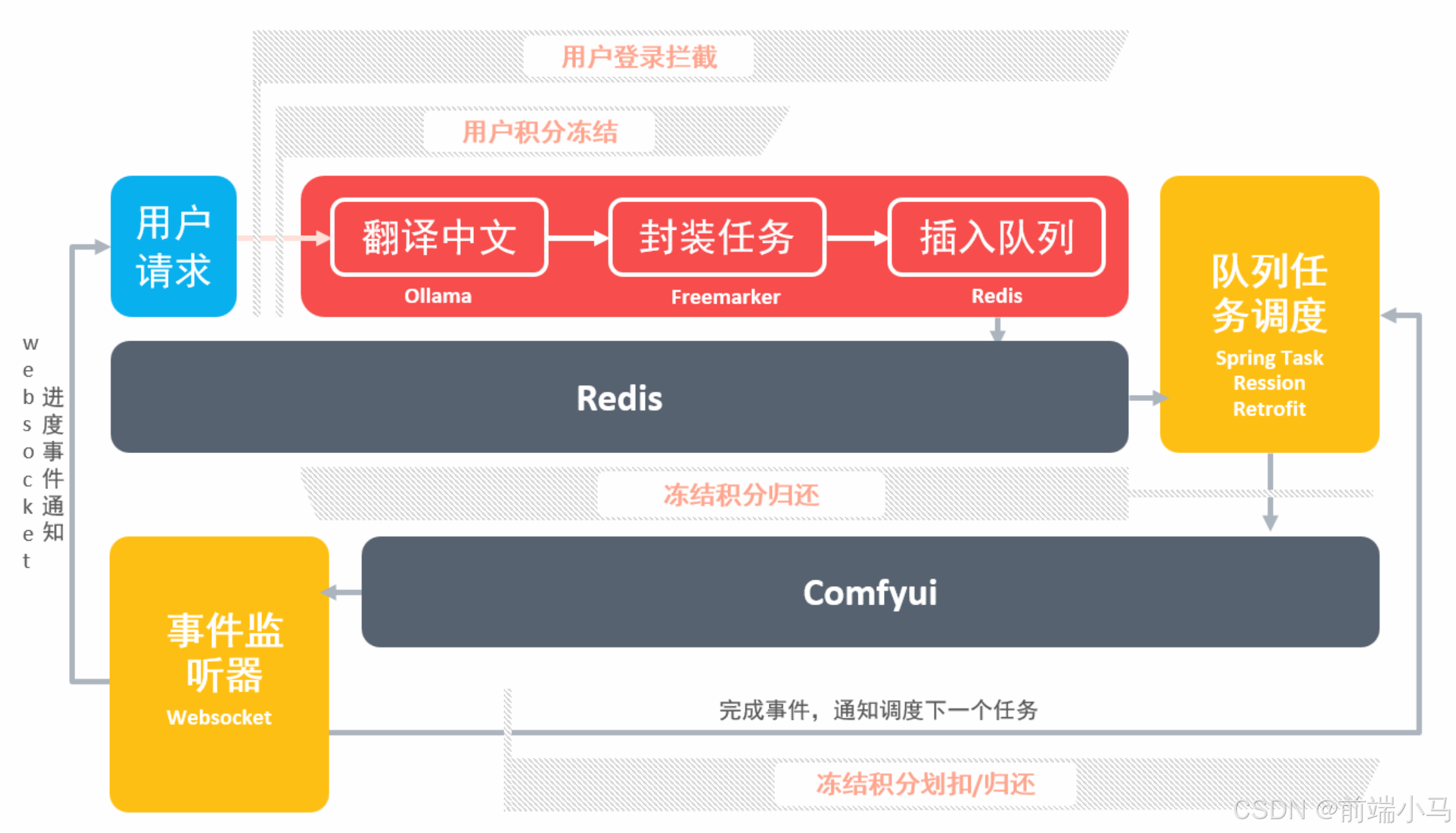
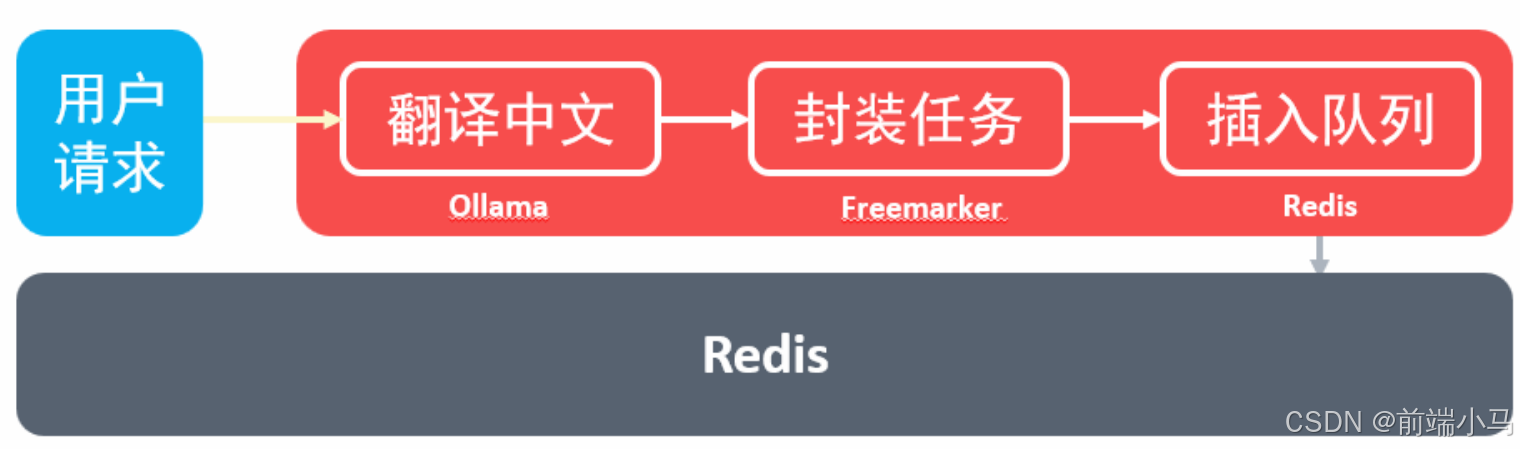



(4)拦截用户信息
①UserUtils工具类:
创建cn.itcast.star.graph.core.utils.UserUtils类,在其中增加getUser、setUser、removeUser方法。
public class UserUtils { static ThreadLocal<User> local=new ThreadLocal<>(); public static void saveUser(User user){ local.set(user); } public static User getUser(){ return local.get(); } public static void removeUser(){ local.remove(); } }②JWTUtils改造:
在JWTUtils中增加验证token和获取token用户信息的方法,以便在拦截器中使用。
public static User getUser(String token){ try { JWT jwt=JWT.of(token).setKey(key.getBytes()); User user=new User(); user.setId(Long.valueOf(jwt.getPayload("uid")+"")); user.setUsername(jwt.getPayload("uname")+""); return user; }catch (Exception e){ e.printStackTrace(); return null; } }③UserInterceptor拦截器
要实现上述需求,可以通过之前所学习的过滤器来进行实现,创建一个cn.itcast.star.graph.core.interceptor.UserInterceptor过滤器:
public class UserInterceptor implements HandlerInterceptor { //处理Controller之前 public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { //排除不需要解析用户的地址,比如登录地址直接放行 String url=request.getRequestURI(); if(url.contains("/api/1.0/user/login")||url.contains("/error")){ return true; } //去请求中拿token header中token String token=request.getHeader(HttpHeaders.AUTHORIZATION); if(StrUtil.isEmpty(token)){ //判断token是否为空 writeAuthorizationedFailed(response); return false; } //解析用户 并存放到上下文中 User user=JwtUtils.getUser(token); if(user==null){ writeAuthorizationedFailed(response); return false; } UserUtils.saveUser(user); return true; } //封装未授权的返回结果信息 private void writeAuthorizationedFailed(HttpServletResponse response){ response.setStatus(HttpStatus.UNAUTHORIZED.value()); //状态码 response.setContentType(MediaType.APPLICATION_JSON_VALUE); //请求格式 response.setCharacterEncoding("UTF-8"); //字符集 Result<Object> failed=Result.failed(ResultCode.ACCESS_UNAUTHORIZED); //响应体 String body= JSON.toJSONString(failed); try{ PrintWriter writer=response.getWriter(); writer.write(body); writer.flush(); }catch (IOException e){ throw new RuntimeException(e); } } //处理Controller之后 public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler ,ModelAndView modelAndView) throws Exception { } //做完所有MVC处理之后,返回给前端数据之前,所要做的事情 public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, @Nullable Exception ex) throws Exception { } }④配置拦截器生效
创建cn.itcast.star.graph.core.config.WebMvcConfig类,然后重写addInterceptors方法,在其中注册自定义的UserInterceptor拦截器。
@Configuration public class WebMvcConfig implements WebMvcConfigurer { public void addInterceptors(InterceptorRegistry registry) { registry.addInterceptor(new UserInterceptor()); } }
(5)添加生图任务
按之前所分析,添加生图任务所需要做的事情如下:
由于其中翻译中文和封装任务都需要用到新知识Ollama和Freemarker,因此添加生图任务我们也进一步拆分为4步进行边学习新知识边进行实现:
封装Ollama翻译中文:把Ollama翻译功能实现并封装成独立的Service
封装Comfyui任务:把用户传入的参数封装成Comfyui能够识别的参数格式,此功能也封装成独立Service
存储Comfyui任务:把封装好的Comfyui任务存储到Redis队列中,此功能也封装成独立Service
文生图接口实现:提供文生图Service,通过调用上述3步Service进行功能实现
①封装Ollama翻译中文
在之前的Stable Diffusion原理学习过程中,我们提及Stable Diffusion只识别用户输入的英文信息(因为什么呢?),因此需要把中文翻译成英文。这里可以调用三方API,比如百度翻译、Goggle翻译等,但这些接口都有一些限制,因此在此我们通过大模型来帮我们翻译。
这就可以使用之前所学习的Ollama+通义千万大模型来完成中文翻译的功能:
Ollama也支持API远程被调用,因此在改项目中我们亦可通过Retrofit封装Ollama相关的API,为节省时间,封装的API已经提前封装好,放在资料《Ollama—API封装代码》文件夹中。可以把文件夹下的内容拷贝到项目的cn.itcast.star.graph包下,拷贝后的结构是:
文件说明:
OllamaApi:定义ollama的api接口,目前类中只定义了chat聊天接口
OllamaConfig:定义了OllamaApi的实现Bean,并默认连接到192.168.100.129:11434
OllamaChatRequest:聊天请求参数
OllamaChatRespone:聊天响应参数
导入封装好的基本API之后,我们接着需要创建一个Service,专门用于处理翻译业务。
创建cn.itcast.star.graph.core.service.OllamaService接口,并在里面提供translate翻译方法
public interface OllamaService { public String translate(String propmt); }创建cn.itcast.star.graph.core.service.impl.OllamaServiceImpl类,实现OllamaService接口:
@Service public class OllamaServiceImpl implements OllamaService { @Autowired OllamaApi ollamaApi; @Override public String translate(String propmt) { try{ OllamaMessage message = new OllamaMessage(); message.setRole("user"); message.setContent("帮我把以下内容翻译为英文:"+propmt); OllamaChatRequest body=new OllamaChatRequest(); body.setModel("qwen2.5:0.5b"); body.setMessages(List.of(message)); Call<OllamaChatRespone> chat=ollamaApi.chat(body); Response<OllamaChatRespone> result=chat.execute(); OllamaChatRespone ollamaChatRespone=result.body(); return ollamaChatRespone.getMessage().getContent(); }catch (Exception e){ e.printStackTrace();; } return propmt; } } translate方法代码说明: 创建一条消息对象OllamaMessage,并设置翻译文本的提示词和消息角色 创建聊天请求对象OllamaChatRequest,并设定模型名称、消息列表 执行请求获得请求结果对象OllamaChatRespone,如果请求成功则返回翻译文本, 如果请求失败返回原文
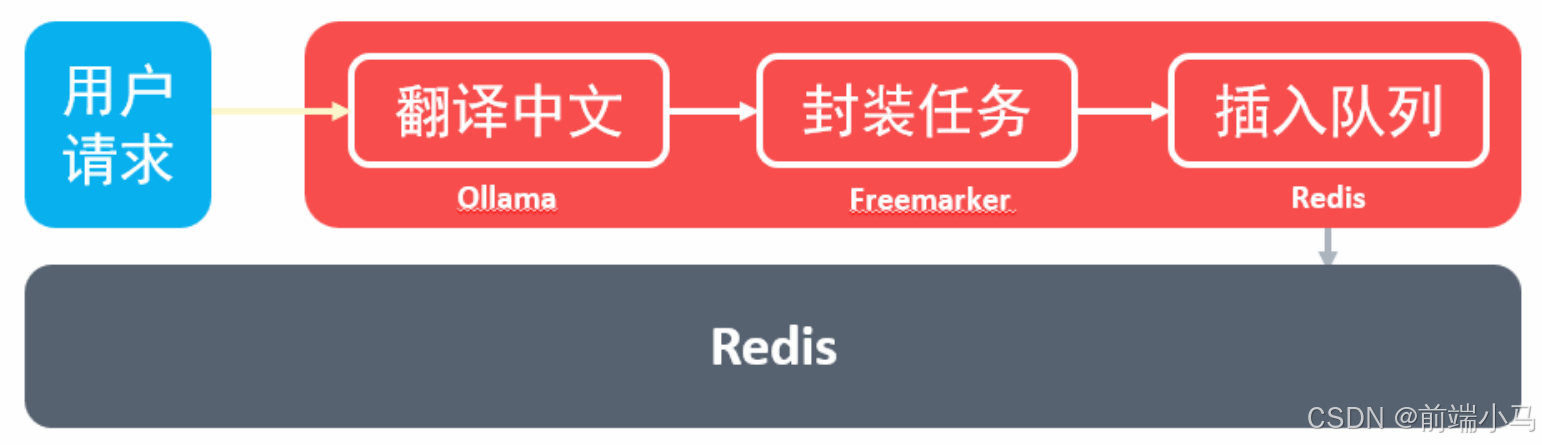
②封装Comfyui任务
1️⃣如何封装生图参数?
通过前面接口设计我们已知星图前端插入后端的数据格式为:
{ "size": 1, "model": 1, "scale": 1, "step": 25, "cfg": 8, "sampler": 1, "seed": 0, "reverse": "", "propmt": "美女,沙滩,伞", "clientId": 1724138388889 }那么这些参数将融入到后端请求Comfyui添加流程任务接口的prompt参数中:
而prompt参数值就是我们使用Comfyui绘制好的一个流程的json串,比如:
{ "3": { "inputs": { "seed": 533811994885432, "steps": 20, "cfg": 8, "sampler_name": "euler", "scheduler": "normal", "denoise": 1, "model": [ "4", 0 ], "positive": [ "6", 0 ], "negative": [ "7", 0 ], "latent_image": [ "5", 0 ] }, "class_type": "KSampler", "_meta": { "title": "K采样器" } }, "4": { "inputs": { "ckpt_name": "majicmixRealistic_v7.safetensors" }, "class_type": "CheckpointLoaderSimple", "_meta": { "title": "Checkpoint加载器(简易)" } }, "5": { "inputs": { "width": 512, "height": 768, "batch_size": 1 }, "class_type": "EmptyLatentImage", "_meta": { "title": "空Latent" } }, "6": { "inputs": { "text": "beautiful girl,8K", "clip": [ "4", 1 ] }, "class_type": "CLIPTextEncode", "_meta": { "title": "CLIP文本编码器" } }, "7": { "inputs": { "text": "text, watermark,naked", "clip": [ "4", 1 ] }, "class_type": "CLIPTextEncode", "_meta": { "title": "CLIP文本编码器" } }, "8": { "inputs": { "samples": [ "3", 0 ], "vae": [ "4", 2 ] }, "class_type": "VAEDecode", "_meta": { "title": "VAE解码" } }, "9": { "inputs": { "filename_prefix": "ComfyUI", "images": [ "8", 0 ] }, "class_type": "SaveImage", "_meta": { "title": "保存图像" } } }前端传入的参数要融入到JSON中,只需要替换上述json字符串中相关的属性的值即可。参数与属性对应关系:
参数 属性 size batch_size model ckpt_name scale width、height step steps cfg cfg sampler sampler_name、scheduler seed seed propmt 正向词的text reverse 负向词的text 2️⃣绘制文生图流程:
在上面内容中提到Comfyui流程的json串,这个json串可以先在Comfyui中绘制一个流程,然后把流程图保存为API的json文件即可得到,具体的操作步骤是:
绘制文生图流程 :
文生图绘制一个基本的生图流程即可。
流程参数:
正向词:beautiful girl,8K
负向词:text, watermark,naked
步数:20
强度:8.0
采样器:euler+normal
开启开发者模式:
只有开启开发者模式之后才可见【保存(API格式)】菜单,具体开启的步骤如下图:
保存流程为Json文件
直接点击【保存(API格式)】菜单,在弹出的对话框中输入保存文件的文件名,然后点击【确定】按钮,json文件即可自动下载到默认文件夹。
进入下载目录,找到刚才输入的文件名对应的文件,打开即可得到流程的json文件:
{ "3": { "inputs": { "seed": 1097720578524313, "steps": 20, "cfg": 8, "sampler_name": "euler", "scheduler": "normal", "denoise": 1, "model": [ "4", 0 ], "positive": [ "6", 0 ], "negative": [ "7", 0 ], "latent_image": [ "5", 0 ] }, "class_type": "KSampler", "_meta": { "title": "K采样器" } }, "4": { "inputs": { "ckpt_name": "majicmixRealistic_v7.safetensors" }, "class_type": "CheckpointLoaderSimple", "_meta": { "title": "Checkpoint加载器(简易)" } }, "5": { "inputs": { "width": 512, "height": 768, "batch_size": 1 }, "class_type": "EmptyLatentImage", "_meta": { "title": "空Latent" } }, "6": { "inputs": { "text": "beautiful girl,8K", "clip": [ "4", 1 ] }, "class_type": "CLIPTextEncode", "_meta": { "title": "CLIP文本编码器" } }, "7": { "inputs": { "text": "text, watermark,naked", "clip": [ "4", 1 ] }, "class_type": "CLIPTextEncode", "_meta": { "title": "CLIP文本编码器" } }, "8": { "inputs": { "samples": [ "3", 0 ], "vae": [ "4", 2 ] }, "class_type": "VAEDecode", "_meta": { "title": "VAE解码" } }, "9": { "inputs": { "filename_prefix": "ComfyUI", "images": [ "8", 0 ] }, "class_type": "SaveImage", "_meta": { "title": "保存图像" } } }3️⃣使用Freemarker封装参数
有了如何封装前端传入的参数,和文生图的流程JSON之后,接下来要解决的问题就是,如何通过程序把参数动态的去替换json文件中对应的属性值呢?
针对这个问题,我们可以参考如下思路进行实现:
把json文件中要替换的属性值,通过占位符进行占位,占位后的字符串称为模版
然后在程序中把传入的参数用去替换json模版中的占位符,即可得到替换后的可以参数
而以上思路在企业中常常使用一个叫模版引擎的框架来进行实现,我们也选用模版引擎Freemarker来进行实现。
FreeMarker 是一款模板引擎: 即一种基于模板和要改变的数据, 并用来生成输出文本(HTML网页,电子邮件,配置文件,源代码等)的通用工具。它的架构和我们当下的开发场景完全契合。
SpringBoot也是无缝支持Freemarker,直接引入如下依赖即可在项目中使用Freemarker:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-freemarker</artifactId> </dependency>接下来我们直接封装一个Service,并在其中使用Freemarker API进行json字符串的动态值替换。
首选准备模版
新建文件src/main/resources/templates/t2i.ftlh,并把流程图的json字符串复制到文件中,然后把要替换的值通过占位符进行占位:
注意:这里的占位符名称是cn.itcast.star.graph.comfyui.client.pojo.ComfyuiModel类的属性,以方便后续通ComfyuiModel进行封装值。
{ "3": { "inputs": { "seed": ${config.seed}, "steps": ${config.step}, "cfg": ${config.cfg}, "sampler_name": "${config.samplerName}", "scheduler": "${config.scheduler}", "denoise": 1, "model": [ "4", 0 ], "positive": [ "6", 0 ], "negative": [ "7", 0 ], "latent_image": [ "5", 0 ] }, "class_type": "KSampler", "_meta": { "title": "K采样器" } }, "4": { "inputs": { "ckpt_name": "${config.modelName}" }, "class_type": "CheckpointLoaderSimple", "_meta": { "title": "Checkpoint加载器(简易)" } }, "5": { "inputs": { "width": ${config.width}, "height": ${config.height}, "batch_size": ${config.size} }, "class_type": "EmptyLatentImage", "_meta": { "title": "空Latent" } }, "6": { "inputs": { "text": "${config.propmt}", "clip": [ "4", 1 ] }, "class_type": "CLIPTextEncode", "_meta": { "title": "CLIP文本编码器" } }, "7": { "inputs": { "text": "${config.reverse}", "clip": [ "4", 1 ] }, "class_type": "CLIPTextEncode", "_meta": { "title": "CLIP文本编码器" } }, "8": { "inputs": { "samples": [ "3", 0 ], "vae": [ "4", 2 ] }, "class_type": "VAEDecode", "_meta": { "title": "VAE解码" } }, "9": { "inputs": { "filename_prefix": "ComfyUI", "images": [ "8", 0 ] }, "class_type": "SaveImage", "_meta": { "title": "保存图像" } } }封装FreemarkerService
创建类cn.itcast.star.graph.core.service.FreemarkerService,并在其中定义一个renderText2Image方法,用于获取替换参数后的json字符串
public interface FreemarkerService { //返回替换好的comgyui字符串 public String renderText2Image(ComfyuiModel model) throws Exception; }然后创建Service的实现类cn.itcast.star.graph.core.service.impl.FreemarkerServiceImpl,并实现renderText2Image方法。
@Service public class FreemarkerServiceImpl implements FreemarkerService { @Autowired Configuration configuration; @Override public String renderText2Image(ComfyuiModel model)throws Exception{ Template template = configuration.getTemplate("t2i.ftlh"); Map<String,Object> data=new HashMap<>(); data.put("config",model); StringWriter out=new StringWriter(); //第一个参数是模板要用到的数据 //第二个参数是模板生成的结果存放的位置 template.process(data,out);//使用数据去替换模板 return out.toString(); } } 代码说明: 直接注入freemarker.template.Configuration类,通过这个配置类可以去查找我们存放到 templates文件夹下的模版 直接调用getTemplate方法查找模版文件 创建一个输出字符串流,用于接收生成的json字符串结果 调用process方法进行结果字符串生成,方法参数为: 第一个参数为模版中占位符的数据,需要通过map传入 第二个为接收结果的输出字符流测试Service
创建测试类cn.itcast.star.graph.FreemarkerServiceTest,并在测试方法中构造ComfyuiModel对象,然后调用FreemarkerService的renderText2Image方法,并打印结果。
@SpringBootTest public class FreemarkerTest { @Autowired FreemarkerService freemarkerService; @Test public void test() throws Exception { ComfyuiModel model=new ComfyuiModel(); model.setModelName("我的模型名称是---"); model.setPropmt("a photo of an astronaut riding a horse on mars"); model.setReverse("bad legs"); model.setSamplerName("Euler"); model.setScheduler("normal"); model.setSize(1); model.setCfg(7); model.setWidth(512); model.setHeight(512); model.setStep(20); model.setSeed(0); model.setModelName("majicmixRealistic_v7.safetensors"); String out= freemarkerService.renderText2Image(model); System.out.println(out); } }能在控制台打印的json字符串中看见ComfyuiModel传入的参数值,则封装成功。
4️⃣封装Comfyui任务
融合好前端传入参数的JSON字符串即可传给Comyfui进行生图了,但是由于任务存在未开始状态可以被取消,因此封装好参数之后的JSON不能直接传给Comfyui。那是因为Comfyui虽然也支持任务排队,但是其队列不支持优先级调整等功能,不满足我们的业务需求。因此需要我们自行实现一个支持优先级调整的队列(这个队列下一节详解),我们封装好的生图任务JSON先放到自行实现的队列中,当Comfyui队列生图完成后再从自行实现队列中取出一个任务去执行。
为便于存取和管理队列中的任务,我们在此需要把后续要用到数据封装成一个ComfyuiTask对象,封装的过程稍微有点复杂,过程如下:
前端传入的参数被封装到Text2ImageResDto对象中
接着需要把Text2ImageResDto对象转为ComfyuiModel对象
使用Freemarker把ComfyuiModel转出可用的文生图流程json字符串
并使用ComfyuiRequestDto对象封装所有发送给Comfyui的参数
最后再把后续使用到的所有数据封装到ComfyuiTask中,存储到队列中
整个过程用到的对象,在之前导入pojo代码中就包括了,因此在此我们只需要提供一个方法实现上述对象的转换,并返回ComfyuiTask对象的方法,便于下一步操作。
创建cn.itcast.star.graph.core.common.Constants类:
public class Constants { public final static String COMFYUI_CLIENT_ID="star-graph"; }创建cn.itcast.star.graph.core.service.Text2ImageService类:
public interface Test2ImageService { public ComfyuiTask getComfyuiTask(Text2ImageReqDto text2ImageReqDto) throws Exception; }在其实现类中提供一个getComfyuiTask方法,用于实现上述对象的转换:
@Service public class Test2ImageServiceImpl implements Test2ImageService { @Autowired OllamaService ollamaService; @Autowired FreemarkerService freemarkerService; //把请求参数封装成comfyui的请求对象 public ComfyuiTask getComfyuiTask(Text2ImageReqDto text2ImageReqDto) throws Exception { ComfyuiModel comfyuiModel=new ComfyuiModel(); //把text2ImageReqDto的同名属性拷贝到comfyuiModel,true表示忽略大小写 BeanUtil.copyProperties(text2ImageReqDto,comfyuiModel,true); comfyuiModel.setModelName(text2ImageReqDto.modelName()); comfyuiModel.setSamplerName(text2ImageReqDto.samplerName()); comfyuiModel.setScheduler(text2ImageReqDto.scheduler()); comfyuiModel.setWidth(text2ImageReqDto.width()); comfyuiModel.setHeight(text2ImageReqDto.height()); //将提示词翻译成英文 comfyuiModel.setPropmt(ollamaService.translate(text2ImageReqDto.getPropmt())); //正向词 comfyuiModel.setReverse(ollamaService.translate(text2ImageReqDto.getReverse())); //负向词 //生成comfyui的请求对象 String propmt=freemarkerService.renderText2Image(comfyuiModel); ComfyuiRequestDto requestDto=new ComfyuiRequestDto(Constants.COMFYUI_CLIENT_ID,JSON.parseObject(propmt)); //最后构造ComfuiTask对象 ComfyuiTask comfyuiTask=new ComfyuiTask("",requestDto); return comfyuiTask; } } 代码说明: 把前端传入的参数转换成ComfyuiModel的属性值 调用OllamaService把用户输入的中文翻译成英文 在正向词中,默认增加了(8k, best quality, masterpiece),(high detailed skin)关键词 在负向词中,默认增加了bad face,naked,bad finger,bad arm,bad leg,bad eye关键词 调用FreemarkerService把参数转成json字符串 构建ComfyuiTask对象,并返回对象
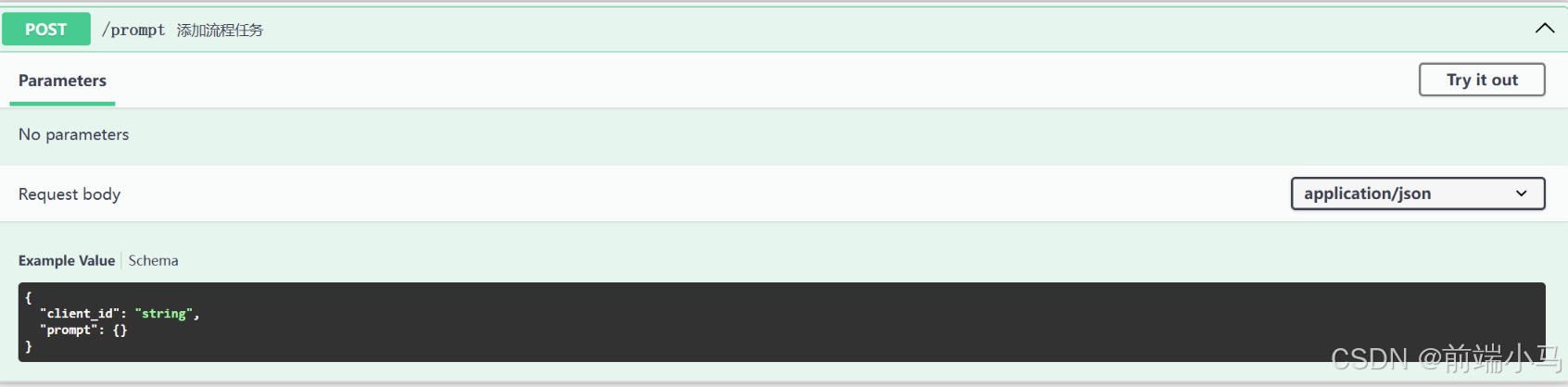
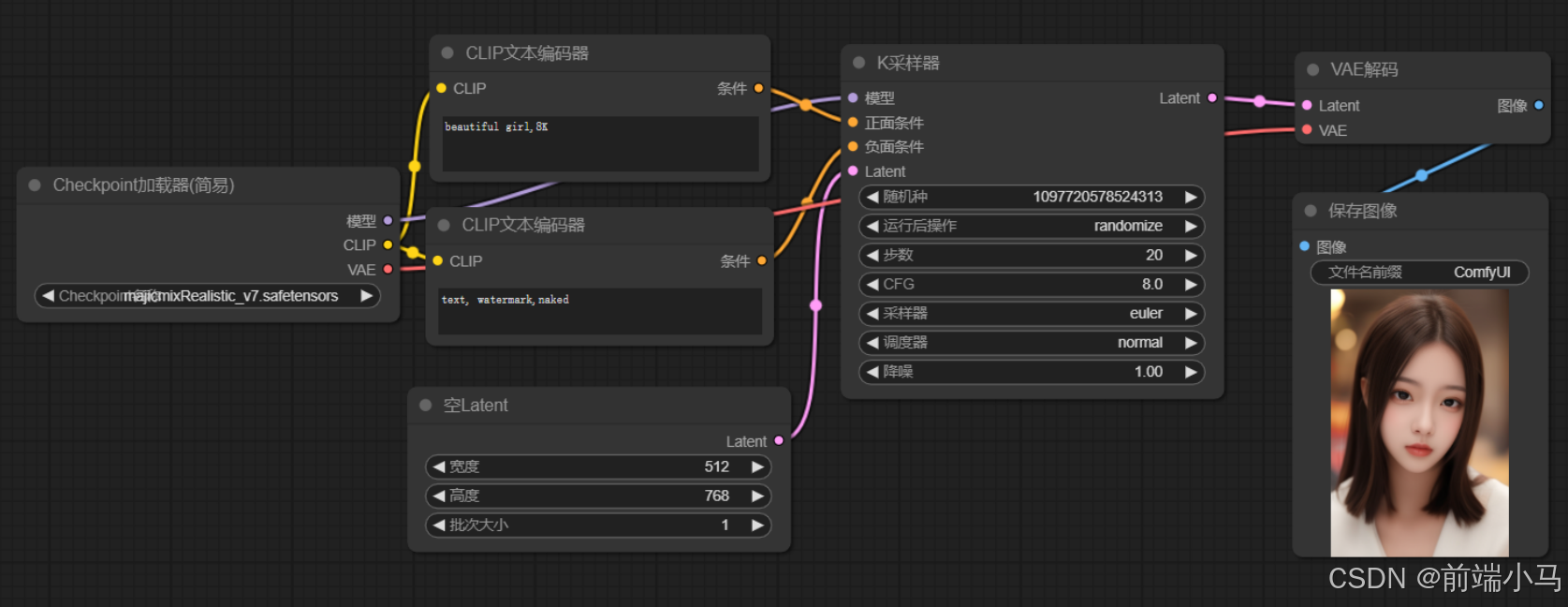
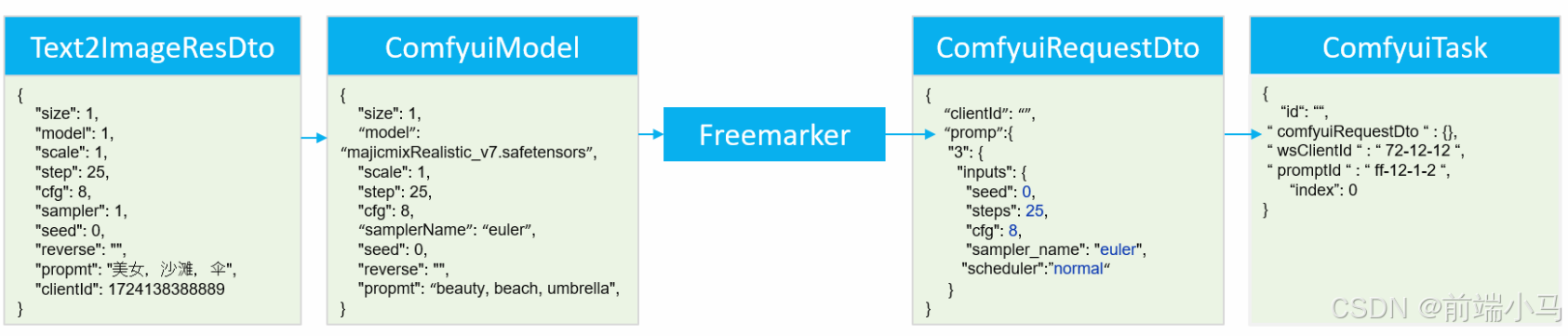
③存储Comfyui任务
1️⃣如何存储?
封装好ComfyuiTask对象之后,接下来就需要把ComfyuiTask对象存储到队列中去。由于队列中的任务只是临时存储(存储后会被调用出来发送给Comfyui执行),因此我们可以选用Redis来实现。
首先能想到的方案就是直接把ComfyuiTask对象存储到有序集合ZSET中:
但考虑到后期会通过队列值来调整对应的分值以实现任务优先级动态调整,这里队列值用户对象地址或对象JSON字符串都不太合适,因此可以使用任务的ID存入ZSET,然后在Redis中再存一个以ID对应的任务详情数据值,如:
同时在之前文生图接口的响应结果中需要返回任务在队列中的序号queueIndex,而且这个序号也要保存到ComfyuiTask中。
{ "pid":"1afsa-121as-121af-121as", "queueIndex":0 }
这个队列序号必须是连续的数值,这样方便后续前端通过此数字来计算排队前面的人数。但是又考虑到后期我们的服务可能被部署成对台服务器,需要保障队列序号在多台服务器上生成的值也是连续的。因此在此场景可以在Redis中设置一个分布式ID(DISTRIBUTED_ID),每台服务器要生成队列序号时都从Redis中去获取,获取后并自增分布式ID值。
2️⃣封装存储Service
导入redis依赖:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency>写redis配置:
spring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.100.129:3306/star-graph?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=UTC&allowPublicKeyRetrieval=true username: root password: 123456 data: redis: host: 192.168.100.129 port: 6379创建cn.itcast.star.graph.core.service.RedisService类,并定义addQueueTask存储任务到对了方法。
public interface RedisService { public ComfyuiTask addQueueTack(ComfyuiTask task); }创建cn.itcast.star.graph.core.service.impl.RedisServiceImpl类:
@Service public class RedisServiceImpl implements RedisService { @Autowired StringRedisTemplate stringRedisTemplate; private final static String TASK_KEY_PREFIX = "task_"; private final static String DISTRIBUTED_ID_KEY = "DISTRIBUTED_ID"; private final static String DISTRIBUTED_QUEUE_KEY = "DISTRIBUTED_QUEUE"; @Override public ComfyuiTask addQueueTack(ComfyuiTask task) { //获取一个分布式自增主键ID long idx=stringRedisTemplate.opsForValue().increment(DISTRIBUTED_ID_KEY); task.setIndex(idx); //把任务存入zset集合 stringRedisTemplate.opsForZSet().add(DISTRIBUTED_QUEUE_KEY,task.getId(),idx); //把整个任务通过string方式存储到redis stringRedisTemplate.opsForValue().set(TASK_KEY_PREFIX+task.getId(), JSON.toJSONString(task)); return task; } } 代码说明: 通过increment方法获取分布式ID值,获取后改命令会自动把值自增1 把分配到的队列序号存入任务中 把任务详情信息存入到Redis中 把任务的唯一ID压入队列,并且分值也为队列序号

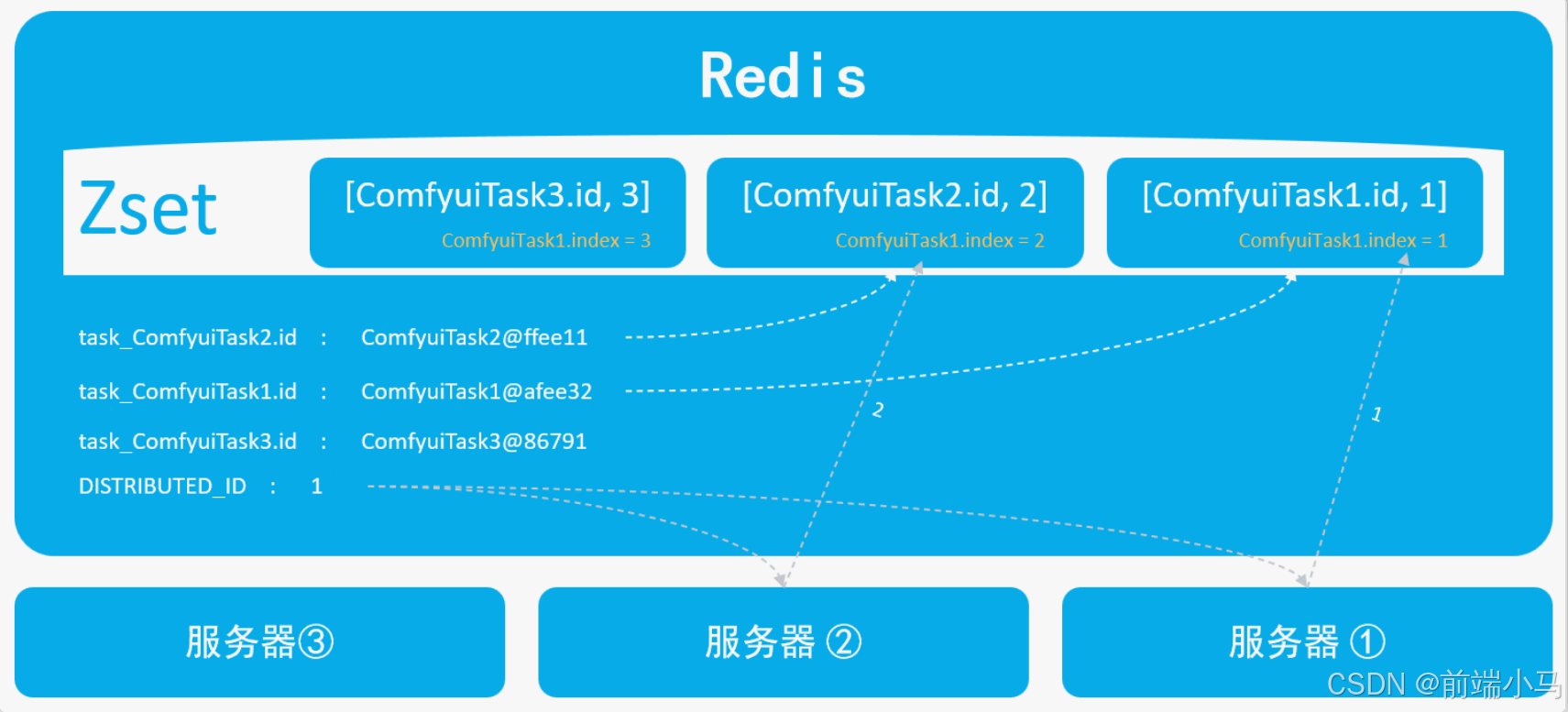
④文生图接口实现
添加Text2ImageController类并增加一个文生图的方法propmt方法
@RestController @RequestMapping("/api/authed/1.0/t2i") public class Text2ImageController { @Autowired private Test2ImageService test2ImageService; @PostMapping("/propmt") public Result<Text2ImageResponDto> propmt(@RequestBody Text2ImageReqDto text2ImageReqDto) throws Exception { Text2ImageResponDto text2ImageResponDto=test2ImageService.textToImage(text2ImageReqDto); return Result.ok(text2ImageResponDto); } }添加Text2ImageResponDto类作为返回值
@Data public class Text2ImageResponDto { String pid; int queueIndex; }在Test2ImageService接口定义textToImage方法并在Test2ImageServiceImpl中实现
public interface Test2ImageService { public ComfyuiTask getComfyuiTask(Text2ImageReqDto text2ImageReqDto) throws Exception; Text2ImageResponDto textToImage(Text2ImageReqDto text2ImageReqDto) throws Exception; } @Autowired RedisService redisService; public ComfyuiTask getComfyuiTask(Text2ImageReqDto text2ImageReqDto) throws Exception { ComfyuiModel comfyuiModel=new ComfyuiModel(); BeanUtil.copyProperties(text2ImageReqDto,comfyuiModel,true); comfyuiModel.setModelName(text2ImageReqDto.modelName()); comfyuiModel.setSamplerName(text2ImageReqDto.samplerName()); comfyuiModel.setScheduler(text2ImageReqDto.scheduler()); comfyuiModel.setWidth(text2ImageReqDto.width()); comfyuiModel.setHeight(text2ImageReqDto.height()); //转换提示词 comfyuiModel.setPropmt("(8k,best quality,masterpiece),(high detailed skin),"+ollamaService.translate(text2ImageReqDto.getPropmt())); //正向词 comfyuiModel.setReverse(ollamaService.translate(text2ImageReqDto.getReverse())+",bad face ,naked,bad,finger,bad arm,bad leg,bad eye"); //负向词 //生成comfyui的请求对象 String propmt=freemarkerService.renderText2Image(comfyuiModel); ComfyuiRequestDto requestDto=new ComfyuiRequestDto(Constants.COMFYUI_CLIENT_ID,JSON.parseObject(propmt)); //最后构造ComfuiTask对象 ComfyuiTask comfyuiTask=new ComfyuiTask("",requestDto); return comfyuiTask; } //文生图接口实现 @Override public Text2ImageResponDto textToImage(Text2ImageReqDto text2ImageReqDto) throws Exception { //把请求参数封装并存储到redis //封装数据: ComfyuiTask comfyuiTask=getComfyuiTask(text2ImageReqDto); //保存到redis comfyuiTask= redisService.addQueueTack(comfyuiTask); //返回数据 Text2ImageResponDto text2ImageResponDto=new Text2ImageResponDto(); text2ImageResponDto.setPid(comfyuiTask.getId()); text2ImageResponDto.setQueueIndex((int) comfyuiTask.getIndex()); return text2ImageResponDto; } }测试文生图接口:
启动前端项目,然后在文生图界面,输入生图的提示词,然后点击【发送】按钮,结果请求成功之后再弹出的窗口之中会显示任务在队列中的序号。
从浏览器请求可确认请求数据和返回数据正常。
同时也可以从Redis可视化工具中看见存入分布式ID、队列、任务详情等信息:
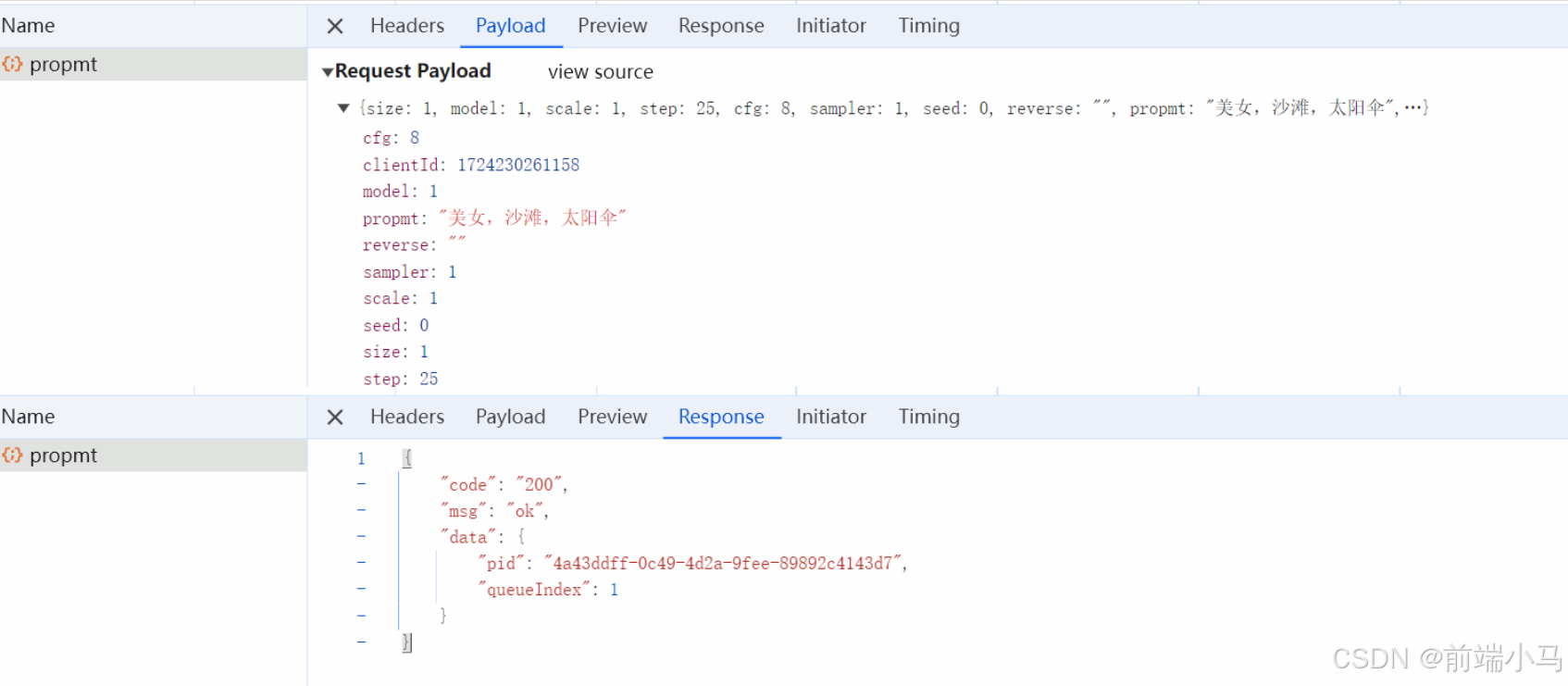
(6)调度生图任务
生图任务存入Redis之后,接下来就可以通过任务调度器从Redis中取出任务,然后发送给Comfyui进行执行。

①SpringTask入门
在工作中提到任务调度,一般都是通过定时器来进行实现的,那么在本项目中调度任务比较简单,因此直接使用SpringBoot提供的SpringTask定时器框架来进行实现。
SpringBoot项目默认映入了SpringTask框架,因此不需要另外引入依赖,只需要通过@EnableScheduling注解开启功能即可。
@SpringBootApplication @EnableScheduling //开启调度器(定时器) public class StarGrohApp { public static void main(String[] args) { SpringApplication.run(StarGrohApp.class,args); } }然后创建一个定时任务业务逻辑执行类cn.itcast.star.graph.core.job.RunTaskJob,任意写一个方法,然后通过@Scheduled注解声明任务执行的周期,这里使用的cron表达式,表示每秒执行一次。
@Component public class RunTaskJob { //每秒执行一次 @Scheduled(cron = "*/1 * * * * ?") public void runTask(){ System.out.println("task"); } }重启服务在控制台看见不断地打印task,则表示SpringTask运行成功。
②发送任务到Comfyui
准备好调度器之后,接下来就可以在调度任务中实现取出任务发送Comfyui的功能,具体的实现分两步:
获取任务
发送任务
获取任务:
在RedisService类中增加获取一个任务的方法 :
public ComfyuiTask popQueueTask();在RedisServiceImpl中实现从Redis中获取一个任务的方法:
@Override public ComfyuiTask popQueueTask() { Long size = stringRedisTemplate.opsForZSet().size(DISTRIBUTED_QUEUE_KEY); if (size > 0) { ZSetOperations.TypedTuple<String> task = stringRedisTemplate.opsForZSet().popMin(DISTRIBUTED_QUEUE_KEY); if (task != null && task.getValue() != null) { String taskId = task.getValue(); String json = stringRedisTemplate.opsForValue().get(TASK_KEY_PREFIX + taskId); ComfyuiTask comfyui = JSON.parseObject(json, ComfyuiTask.class); return comfyui; } } return null; } 代码说明: - 获取队列的大小,如果有才取任务 - 通过popMin方法获取Zset队列中分值最小的任务ID,获取成功后并从队列中删除 - 通过任务ID,获取任务详情信息 - 把任务转成ComfyuiTask对象,直接返回发送任务:
在RunTaskJob类中定义 sendTaskToComfyui,在实现发送任务的业务代码,最后在task方法中调用 sendTaskToComfyui方法。
@Component public class RunTaskJob { private static final Logger log = LoggerFactory.getLogger(RunTaskJob.class); @Autowired ComfyuiApi comfyuiApi; @Autowired RedisService redisService; //把任务发送给comfyui private void sendTaskToComfyui(){ ComfyuiTask comfyuiTask=redisService.popQueueTask(); if(comfyuiTask==null){ return; } Call<HashMap> addQueueTask=comfyuiApi.addPrompt(comfyuiTask.getComfyuiRequestDto()); try { Response<HashMap> response=addQueueTask.execute(); if(response.isSuccessful()){ HashMap map=response.body(); String promptId=(String) map.get("prompt_id"); comfyuiTask.setPromptId(promptId); log.info("添加任务到Comfyui成功:{}",comfyuiTask.getPromptId()); }else { String error=response.errorBody().toString(); log.error("添加任务到Comfyui错误:{}",error); } } catch (Exception e) { e.printStackTrace(); } } //每秒执行一次 @Scheduled(cron = "*/1 * * * * ?") public void runTask(){ sendTaskToComfyui(); System.out.println("task"); } }重新服务之后,可以在控制台看见任务添加成功的日志。
同时在http://192.168.100.129:8188/界面中可以看见有任务正在运行中:
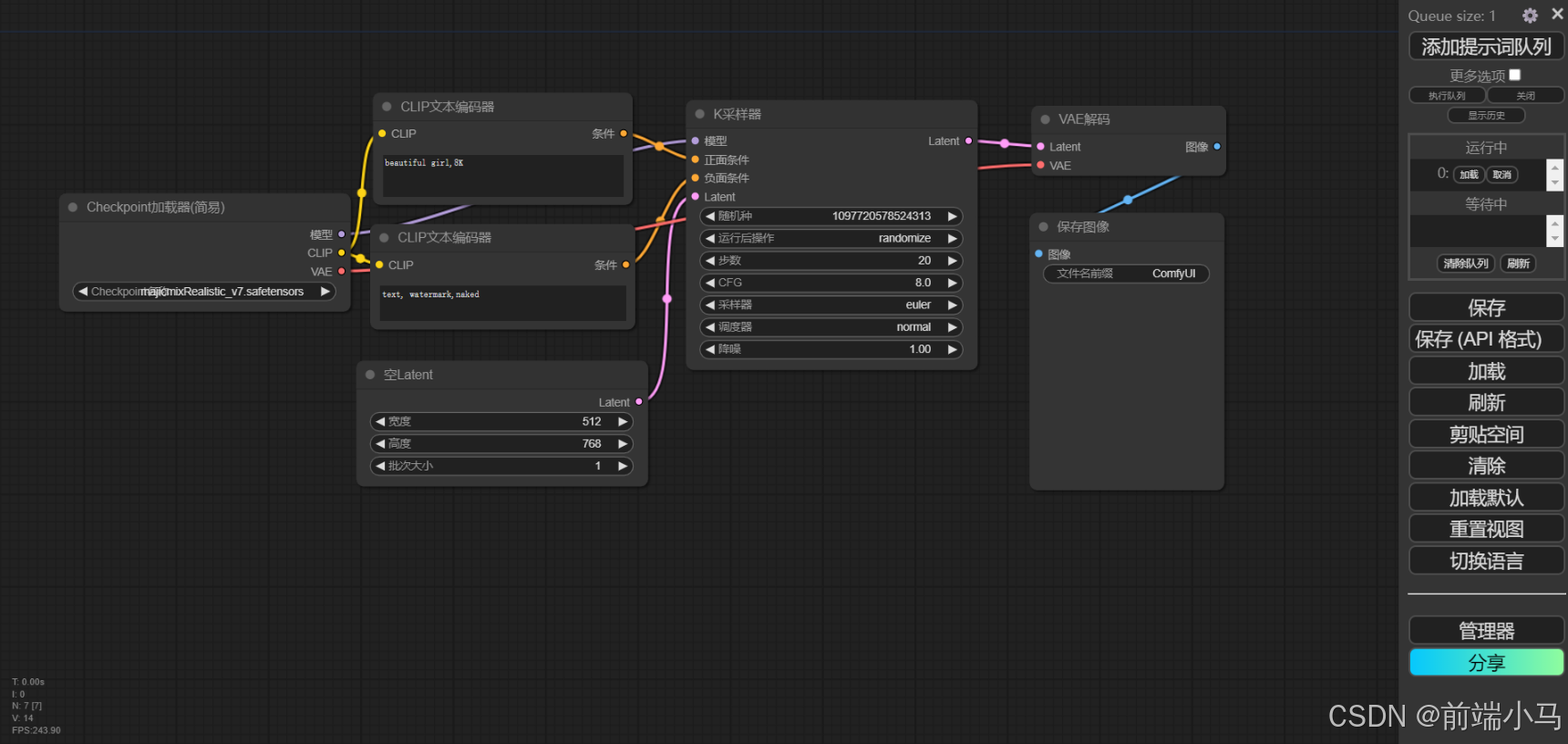
③SpringTask集群并发问题
SpringTask是一个非常简单好用的调度框架,但是这个框架在服务器集群(集群:(Server Cluster)是指将一组独立的服务器通过网络连接起来,共同对外提供服务,以提高服务的可用性、可靠性、可扩展性和性能。)的情况下,使用需要注入其并发问题。
所谓的集群并发问题就是通一套程序不是到多个服务器上,他们设置的定时调度时间是一样的,因此这些服务器上的定时器会在同一时间运行,
在我们刚才这个业务场景,任务同时运行就会同时从Redis中拉取多个任务,然后同时发送给Comfyui执行,而Comfyui自身也有一个队列,所以会接收所有的任务请求。这就导致Comfyui始终执行的任务可能有多个,与我们之前分析的实现思路只能有一个任务相违背。
针对上述问题,我们也可以修改RunTaskJob,注释业务逻辑,直接打印当前执行任务时间:
@Scheduled(cron = "*/1 * * * * ?") public void task(){ // addTaskToQueue(); System.out.println(DateTime.now()); }然后开启服务可以多实例运行:
然后修改一下服务端口,启动两个服务实例,在控制台即可看见他们执行的时间都是一样的,则复现了集群的内容。
复现了SpringTask集群并发之后,那么如何解决这个问题呢?其实每个服务器上的程序,我们可以看成是一个线程在执行,那么上述问题就相当于是多个线程在同时执行相同业务代码逻辑,导致重复。要解决这种多线程的问题,以及之前所学知识应该用锁来解决,那么在此也是用锁来解决,只是这种锁在工作中有一个更加专业的名称叫分布式锁,主要用于协同跨机器线程执行。
有了分布式锁,即使我们在每台服务器上不是相同的SpringTask任务,他们同时执行,会先去获取分布式锁,分布式锁会保障只有其中一个线程获得锁,因此获得锁的服务器才有权利去执行任务代码,这样就保障了我们开发的程序在集群下也能保障只有一个任务在Comfyui中执行。
要按照以上方案进行实现,则需要使用到分布式锁框架Redisson。
Redisson是一个Redis的 Java客户端,具有内存数据网格功能,封装了更快捷、更简单的API供开发者使用。
官网地址: GitHub - redisson/redisson: Redisson - Valkey and Redis Java client. Real-Time Data Platform. Sync/Async/RxJava/Reactive API. Over 50 Valkey and Redis based Java objects and services: Set, Multimap, SortedSet, Map, List, Queue, Deque, Semaphore, Lock, AtomicLong, Map Reduce, Bloom filter, Spring, Tomcat, Scheduler, JCache API, Hibernate, RPC, local cache..使用Redisson可以按照以下步骤操作:
导入依赖:
<dependency> <groupId>org.redisson</groupId> <artifactId>redisson-spring-boot-starter</artifactId> <version>3.30.0</version> </dependency>配置Redission
创建cn.itcast.star.graph.core.config.RedissionConfig类,并参考如下代码实现:
@Configuration public class RedissionConfig { @Bean public RedissonClient redissonClient(RedisProperties redisProperties){ Config config = new Config(); config.useSingleServer().setAddress(String.format("redis://%s:%s", redisProperties.getHost(), redisProperties.getPort())); return Redisson.create(config); } @Bean public StringRedisTemplate stringRedisTemplate(RedisProperties redisProperties){ LettuceConnectionFactory lettuceConnectionFactory = new LettuceConnectionFactory(redisProperties.getHost(), redisProperties.getPort()); lettuceConnectionFactory.start(); return new StringRedisTemplate(lettuceConnectionFactory); } } 代码说明: - redissonClient方法 - 新建Config配置,并设定其连接redis的信息,最后通过Redisson.create方法创建 RedissonClient客户端 - stringRedisTemplate方法 - 重新定义StringRedisTemplate底层的连接使用LettuceConnectionFactory工厂 管理连接地址,以兼容Redission给调度任务增加分布式锁
在RunTaskJob类中修改runTask方法:
@Autowired RedissonClient redissonClient; //每秒执行一次 @Scheduled(cron = "*/1 * * * * ?") public void runTask(){ //获取锁 RLock lock = redissonClient.getLock("SPRING_TASK_LOCK_KEY"); //占有锁 if(lock.tryLock()){ try{ sendTaskToComfyui(); }finally { lock.unlock(); //释放锁 } } } 代码说明: 通过getLock方法获取一个锁对象 通过tryLock方法去获取一个锁,如果成功则返回true,失败返回false 如果获取成功了锁,则一定要释放锁
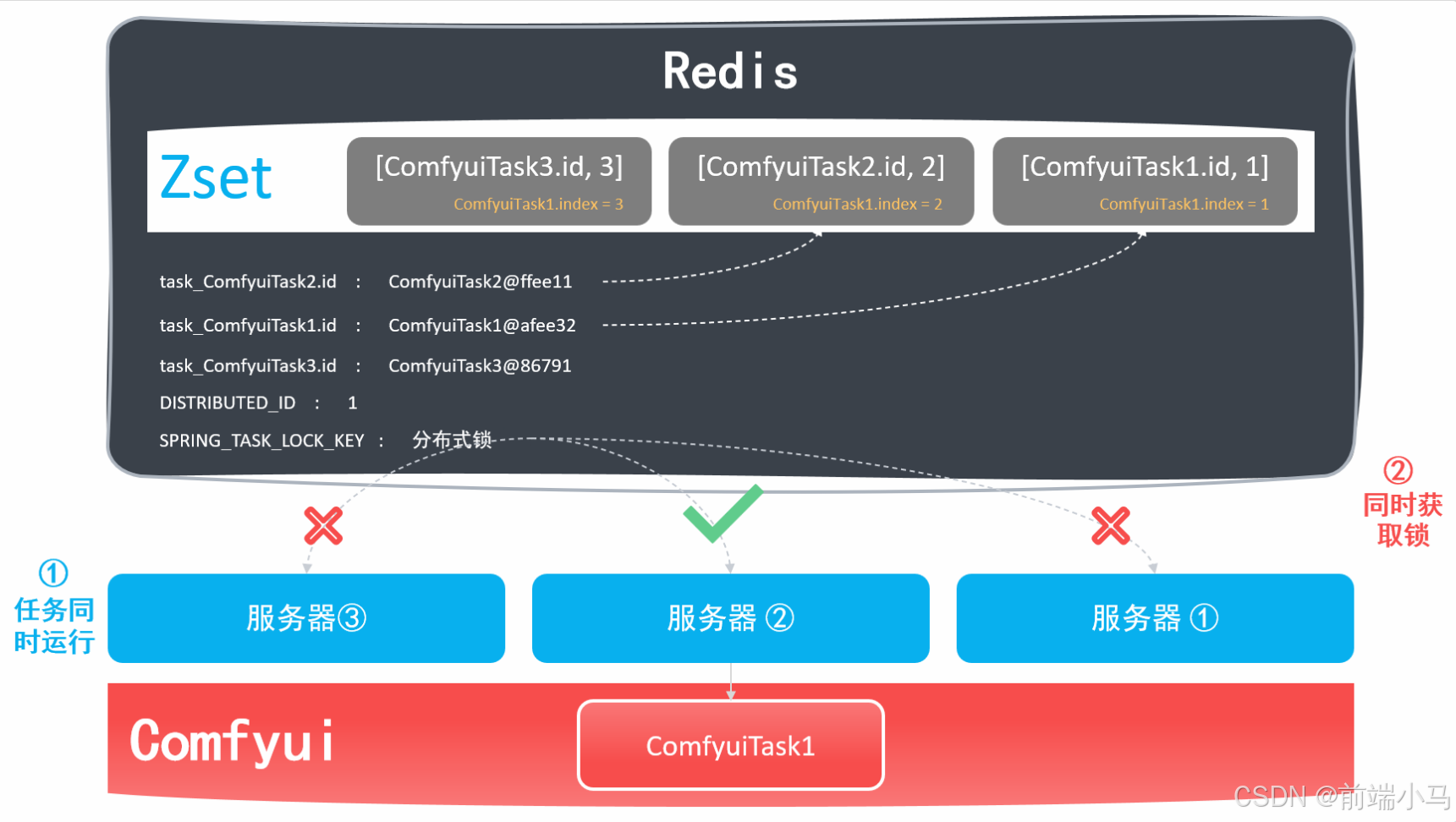
(7)处理任务事件
通过任务调度器把生图任务发送给Comfyui之后,Comfyui就异步开始生成图片,Comfyui生成的图片结果会通过Websocket通知业务程序,因此在我们程序中需要去监听Comfyui发送出的事件。
而去监听Comfyui事件的功能代码,我们在《Comfyui推送消息内容及格式》章节已经封装完成,在此我们只需要去依据事件类型进行不同事件数据处理。在星图系统中我们主要关注以下几个事件:
- progress:生图处理步骤——收到消息后,把进度信息发送给前端
{"type": "progress", "data": {"value": 5, "max": 20, "prompt_id": "594ac476-e599-47c1-a99f-bf8a384cfcdb", "node": "4"}}executed:生图结果——收到消息后,把结果发送给前端
{"type": "executed", "data": {"node": "9", "output": {"images": [{"filename": "ComfyUI_00239_.png", "subfolder": "", "type": "output"}, {"filename": "ComfyUI_00240_.png", "subfolder": "", "type": "output"}]}, "prompt_id": "c4fba48d-1605-4e94-aabd-a37211204c2f"}}execution_error:执行错误——收到消息后,把结果发送给前端
{"type": "execution_error", "data": {"node_id": "1", "node_type":"","exception_message":"异常信息"}}status:队列状态变更消息——收到消息后,判断如果队列任务数量为0,则从Redis队列取出数据,继续下一个生图任务,同时把处理序号推送给前端,前端重新计算排队等待的人数。
{"type": "status", "data": {"status": {"exec_info": {"queue_remaining": 1}}}}

①封装消息推送服务
1️⃣消息推送方案:
在这步实现中我们要用到服务器推送技术Websocket,星图后端接收到Comfyui消息之后,进度、结果、错误消息需要推送给前端对应的用户,状态消息需要广播推送给所有用户。
换句话说,星图后端需要支持一对一给用户推送消息,同时也要支持广播给所有用户,要实现这个样的复杂功能,可以参考一下方案进行实现:
方案说明:
在每个用户端向星图后端订阅两个地址,一个广播订阅用于接收广播消息,一个用户订阅用接收一对一消息。
广播订阅地址:/topic/messages
用户订阅地址:/user/{clientId}/topic/messages
服务器如果要一对一推送消息则向用户的用户订阅通道发送消息即可,如果要广播推送消息则向广播订阅通道发送消息。
2️⃣消息推送实现思路:
由于请求文生图、调度文生图任务、Comfyui生图都是异步的(都是不同线程去执行),要实现精准的一对一消息推送,就需要再异步任务之间传递用户信息,不然很容易出现消息错发等问题。
要解决这个问题,一般都采用多个缓存来解决,比如:
1、当用户端通过Websocket连接星图后端时携带客户端ID,并缓存客户端和推送通道之间的数据
2、当用户发起文生图请求时,也携带客户端ID,然后通过任务调度把任务发送给Comfyui之后,Comfyui会返回一个任务ID,此时可以把任务ID与客户端ID之间的关系进行缓存
3、当Comfyui生图完成之后发送的事件中会包含任务ID字段,此时我们可以通过任务ID去第2步缓存中查找客户端ID,然后通过客户端ID去第1步缓存中查找消息推送通道,然后用通道向用户点对点的推送消息。
如果是广播,则获取第1步缓存中所有的通道,每个通道都推送一次消息。
有了上述实现思路之后,我们就可以按照一下3步进行封装实现:
订阅用户缓存:在用户端订阅连接时缓存客户端和消息推送通道关系
调度任务缓存:任务被调度到Comfyui之后,缓存任务ID与客户端ID之间的数据
推送服务封装:封装一个独立的服务器消息推送Service
3️⃣订阅用户缓存:
订阅用户缓存即在用户端订阅连接时缓存客户端和消息推送通道关系,这个功能在SpringBoot提供的Websocket中已经内置了这个功能,但是SpringBoot框架不知道用户信息如何在订阅连接时获取,因此我们需要提供一个拦截器去解析用户信息并告知框架。
创建cn.itcast.star.graph.core.interceptor.WebscoketUserInterceptor拦截器类:
public class WebscoketUserInterceptor implements ChannelInterceptor { @Override public Message<?> preSend(Message<?> message, MessageChannel channel) { StompHeaderAccessor accessor = MessageHeaderAccessor.getAccessor(message, StompHeaderAccessor.class); //如果是回复连接指令 if(accessor!=null&&accessor.getCommand().name().equals(StompCommand.COMMIT)){ List<String> clientIds=accessor.getNativeHeader("clientId"); if(clientIds!=null&&clientIds.size()>0){ String clientId=clientIds.get(0); accessor.setUser(new Principal() { @Override public String getName() { return clientId; } }); } } return message; } } 代码说明: Websocket的拦截器需要实现ChannelInterceptor接口,并实现发送每个消息都会被调用的 方法preSend 获取消息的头信息对象StompHeaderAccessor 如果头信息不为null,判断是否是连接命令(即用户连接到服务器时) 获取用户连接时在头信息中传入的客户端ID 获取到客户端ID之后,作为用户唯一ID,封装成用户凭证,通过setUser方法告知SpringBoot, 然后 SpringBoot会自动缓存相关数据。接下来,创建 cn.itcast.star.graph.core.config.WebSocketConfig类,用于开启Websocket服务端功能。
//一对一消息发送时的用户信息解析类 @Configuration @EnableWebSocketMessageBroker public class WebSocketConfig implements WebSocketMessageBrokerConfigurer { //设置允许访问的地址和域名 @Override public void registerStompEndpoints(StompEndpointRegistry registry) { registry.addEndpoint("/ws") .addInterceptors(new HttpSessionHandshakeInterceptor()) .setAllowedOriginPatterns("*"); } //配置服务器哪些地方是可以定义或发送的地址 @Override public void configureMessageBroker(MessageBrokerRegistry registry) { registry.enableSimpleBroker("/topic","/user"); } //让websocket生效解析用户的信息 @Override public void configureClientInboundChannel(ChannelRegistration registry) { registry.interceptors(new WebscoketUserInterceptor()); } } 代码说明: - 在registerStompEndpoints方法中,定义了用户端连接websocket的uri,同时设置运行跨域访问 - 在configureMessageBroker方法中,定义了用户端订阅消息的前缀为/topic和/user - 在configureClientInboundChannel方法中,注册刚才定义的拦截器 - 最后在类上增加@EnableWebSocketMessageBroker注解,开启Websocket服务端功能4️⃣推送服务封装
创建cn.itcast.star.graph.http.client.service.WsNoticeService类,以后所有推送的消息都通过这个Service发送。
public interface WsNoticeService { //一对一发送 public void sendToUser(String clinetId,String message); //发送给所有 public void sendToAll(String message); }然后创建实现类cn.itcast.star.graph.core.service.impl.WsNoticeServiceImpl,并在类中通过点对点和广播的发送消息的两个方法,供后续使用
@Service public class WsNoticeServiceImpl implements WsNoticeService { public final static String COMFYUI_QUEUE_TOPIC = "/topic/messages"; @Autowired SimpMessagingTemplate simpMessagingTemplate; @Override //一对一发送 public void sendToUser(String clientId,String message) { simpMessagingTemplate.convertAndSendToUser(clientId,COMFYUI_QUEUE_TOPIC,message); } @Override //发送给所有 public void sendToAll(String message) { simpMessagingTemplate.convertAndSend(COMFYUI_QUEUE_TOPIC,message); } }5️⃣调度任务缓存
调度任务缓存主要是在SpringTask在从队列中取出任务,发送给Comfyui时,如果发送成功则缓存任务ID与客户端ID之间的关系,当然如果发送失败则还需要通知前端任务失败。
在这里我们把任务ID与客户端ID之间的关系缓存在Redis中,因此在RedisService类中定义两
个方法:
//添加开始的任务 void addStartedTask(String promptId, ComfyuiTask task); //通过promptId获取任务 ComfyuiTask getStartedTask(String promptId);然后在RedisServiceImpl中定义实现缓存方法:
private final static String RUN_TASK_KEY = "run_task_"; @Override public void addStartedTask(String promptId, ComfyuiTask task) { stringRedisTemplate.opsForValue().set(RUN_TASK_KEY+promptId,JSON.toJSONString(task)); } @Override public ComfyuiTask getStartedTask(String promptId) { String json=stringRedisTemplate.opsForValue().get(RUN_TASK_KEY+promptId); if(StrUtil.isNotEmpty(json)){ return JSON.parseObject(json,ComfyuiTask.class); } return null; }然后在调度任务RunTaskJob中,发送任务成功之后,调用addStartedTask方法进行数据缓存。
@Component public class RunTaskJob { private static final Logger log = LoggerFactory.getLogger(RunTaskJob.class); @Autowired ComfyuiApi comfyuiApi; @Autowired RedisService redisService; @Autowired RedissonClient redissonClient; //把任务发送给comfyui private void sendTaskToComfyui(){ ComfyuiTask comfyuiTask=redisService.popQueueTask(); if(comfyuiTask==null){ return; } Call<HashMap> addQueueTask=comfyuiApi.addPrompt(comfyuiTask.getComfyuiRequestDto()); try { Response<HashMap> response=addQueueTask.execute(); if(response.isSuccessful()){ HashMap map=response.body(); String promptId=(String) map.get("prompt_id"); comfyuiTask.setPromptId(promptId); log.info("添加任务到Comfyui成功:{}",comfyuiTask.getPromptId()); redisService.addStartedTask(promptId,comfyuiTask); }else { String error=response.errorBody().toString(); log.error("添加任务到Comfyui错误:{}",error); } } catch (Exception e) { e.printStackTrace(); } } //每秒执行一次 @Scheduled(cron = "*/1 * * * * ?") public void runTask(){ //获取锁 RLock lock = redissonClient.getLock("SPRING_TASK_LOCK_KEY"); //占有锁 if(lock.tryLock()){ try{ sendTaskToComfyui(); }finally { lock.unlock(); //释放锁 } } } }
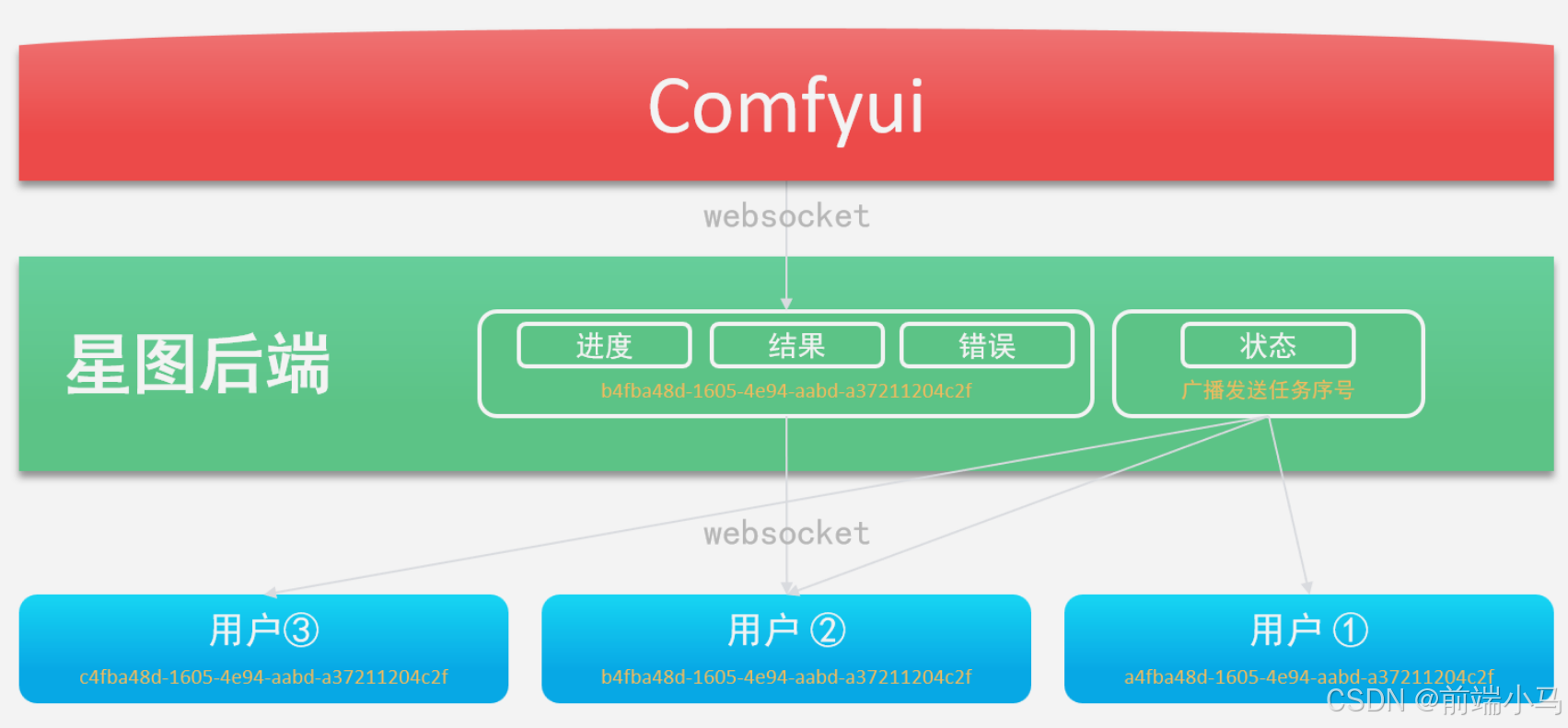
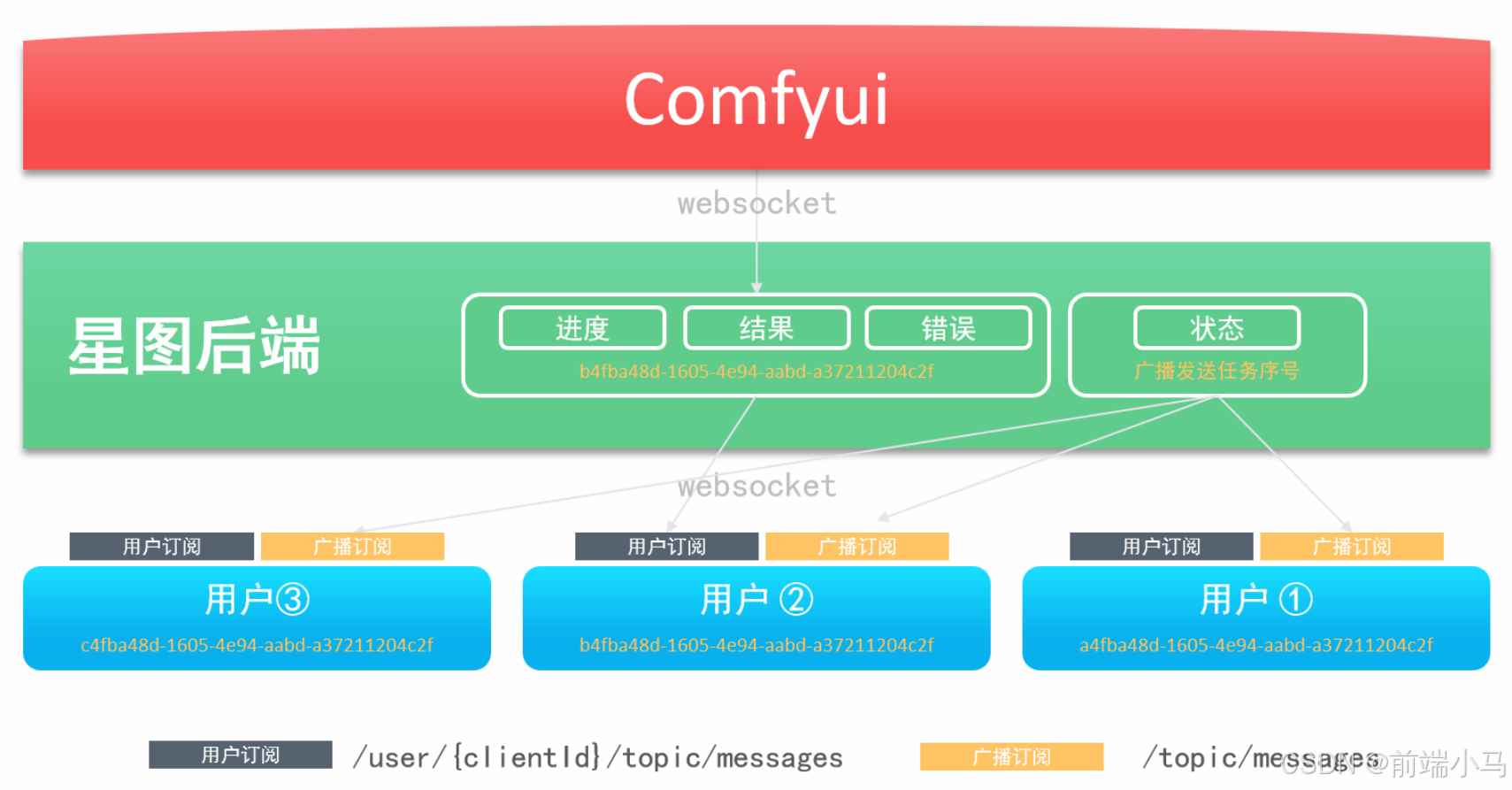
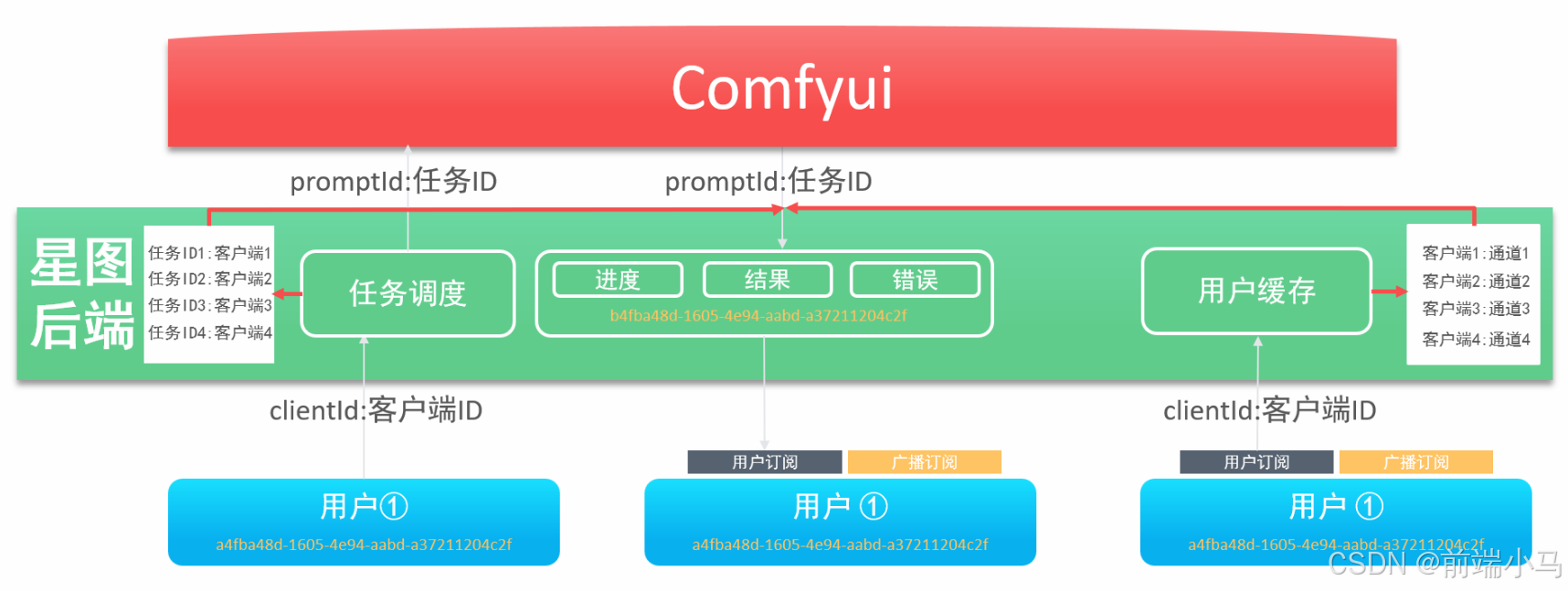
③处理生图进度消息
生图进度消息主用用于同步到用户端进行 进度显示,因此星图后端程序收到消息之后,把消息分发给对应的用户端即可。
{ "type": "progress", "data": { "value": 5, "max": 20, "prompt_id": "594ac476-e599-47c1-a99f-bf8a384cfcdb", "node": "4" } }推给前端的结果格式为:
{ "type": "progress", "value": 5, "max": 20, "prompt_id": "594ac476-e599-47c1-a99f-bf8a384cfcdb", "node": "4" }在这里我们把所有消息处理的业务逻辑都封装到cn.itcast.star.graph.http.client.service.ComfyuiMessageService类中,因此先新建这个类,并在类中定义一个handleMessage方法,方法的参数MessageBase是一个消息的实体类。
然后在ComfyuiMessageServiceImpl类中实现handleMessage方法,判断消息的类型如果是progress,则调用类方法handleProgress:
public interface ComfyuiMessageService { void handleMessage(MessageBase messageBase); } @Service public class ComfyuiMessageServiceImpl implements ComfyuiMessageService { @Autowired WsNoticeService wsNoticeService; @Autowired RedisService redisService; @Override public void handleMessage(MessageBase messageBase) { if("progress".equals(messageBase.getType())){ handleProgressMessage(messageBase); } } private void handleProgressMessage(MessageBase messageBase){ HashMap<String,Object> data=messageBase.getData(); String prompId=(String) data.get("prompt_id"); ComfyuiTask task= redisService.getStartedTask(prompId); data.put("type","progress"); wsNoticeService.sendToUser(task.getWsClientId(),JSON.toJSONString(data)); } } handleProgressMessage代码说明: - 通过messageBase.getData方法获取进度事件的消息内容 - 获取任务ID - 调用wsNoticeService的sendProgress方法,把进度事件推送给对应用户有了这个Service则可以改造之前的ComfyuiMessageHandler类,接收到消息之后,直接调用ComfyuiMessageService处理。
@Component public class ComfyuiMessageHandler extends TextWebSocketHandler { @Autowired ComfyuiMessageService comfyuiMessageService; @Override public void afterConnectionEstablished(WebSocketSession session) throws Exception { System.out.println("=============连接成功"); } @Override protected void handleTextMessage(WebSocketSession session, TextMessage message) throws Exception { String payload=message.getPayload(); MessageBase messageBase= JSON.parseObject(payload,MessageBase.class); comfyuiMessageService.handleMessage(messageBase) ; System.out.println("=============收到消息:"+message.getPayload()); } }完善Test2ImageServiceImpl类中的getComfyuiTask方法(倒数第三行):
public ComfyuiTask getComfyuiTask(Text2ImageReqDto text2ImageReqDto) throws Exception { ComfyuiModel comfyuiModel=new ComfyuiModel(); //把text2ImageReqDto的同名属性拷贝到comfyuiModel,true表示忽略大小写 BeanUtil.copyProperties(text2ImageReqDto,comfyuiModel,true); comfyuiModel.setModelName(text2ImageReqDto.modelName()); comfyuiModel.setSamplerName(text2ImageReqDto.samplerName()); comfyuiModel.setScheduler(text2ImageReqDto.scheduler()); comfyuiModel.setWidth(text2ImageReqDto.width()); comfyuiModel.setHeight(text2ImageReqDto.height()); //转换提示词 comfyuiModel.setPropmt(ollamaService.translate(text2ImageReqDto.getPropmt())); //正向词 comfyuiModel.setReverse(ollamaService.translate(text2ImageReqDto.getReverse())); //负向词 //生成comfyui的请求对象 String propmt=freemarkerService.renderText2Image(comfyuiModel); ComfyuiRequestDto requestDto=new ComfyuiRequestDto(Constants.COMFYUI_CLIENT_ID, JSON.parseObject(propmt)); //最后构造ComfuiTask对象 ComfyuiTask comfyuiTask=new ComfyuiTask(text2ImageReqDto.getClientId(),requestDto); return comfyuiTask; }
④处理生图结果消息
当Comfyui生成的图片成功之后,会把结果消息发送给星图后端程序,星图程序接收到消息之后需要:
把生图结果推送给用户端
同时把结果存储到用户的生图结果表中
{ "type": "executed", "data": { "node": "9", "output": { "images": [ { "filename": "ComfyUI_00239_.png", "subfolder": "", "type": "output" }, { "filename": "ComfyUI_00240_.png", "subfolder": "", "type": "output" } ] }, "prompt_id": "c4fba48d-1605-4e94-aabd-a37211204c2f" } }推送生图结果:
用户端接收到星图后端推送的生图结果之后,会自动在前端界面加载和显示图片,因此在推送的消息中需要包括图片预览地址:
{ "type": "imageResult", "urls": [ "http://192.168.100.129:8188/view?filename=ComfyUI_00239_.png&type=output&&subfolder=", "http://192.168.100.129:8188/view?filename=ComfyUI_00240_.png&type=output&&subfolder=" ] }在ComfyuiMessageServiceImpl类中增加推送生图结果函数 handleExecutedMessage
@Service public class ComfyuiMessageServiceImpl implements ComfyuiMessageService { @Autowired WsNoticeService wsNoticeService; @Autowired RedisService redisService; @Override public void handleMessage(MessageBase messageBase) { if("progress".equals(messageBase.getType())){ //进度消息 handleProgressMessage(messageBase); } else if ("executed".equals(messageBase.getType())) { //生图结果消息 handleExecutedMessage(messageBase); } } private void handleProgressMessage(MessageBase messageBase){ HashMap<String,Object> data=messageBase.getData(); String prompId=(String) data.get("prompt_id"); ComfyuiTask task= redisService.getStartedTask(prompId); data.put("type","progress"); if(task==null){ return; } wsNoticeService.sendToUser(task.getWsClientId(),JSON.toJSONString(data)); } //推送生图结果 private void handleExecutedMessage(MessageBase messageBase){ //转化格式 HashMap<String,Object> data=messageBase.getData(); HashMap<String,Object> output=(HashMap<String, Object>) data.get("output"); List<HashMap<String,Object>> images=(List<HashMap<String, Object>>) output.get("images"); List<String> urls= images.stream().map((image)-> String.format("http://192.168.100.129:8188/view?filename=%s&type=%s&&subfolder=", image.get("filename"),image.get("type"))) .collect(Collectors.toList()); HashMap<String,Object> temp=new HashMap<>(); temp.put("type","imageResult"); temp.put("urls",urls); String prompId=(String) data.get("prompt_id"); ComfyuiTask task= redisService.getStartedTask(prompId); if(task==null){ return; } wsNoticeService.sendToUser(task.getWsClientId(),JSON.toJSONString(temp)); } }保存生图结果:
用户生成的图片需要保存历史,以便用户在自己的图片库或历史记录中查看。
要保存生图结果,则需要先设计一张用户生图结果信息表,用于保存用户生图图片地址、生成时间等信息。为了方便用户管理自己的图片库,还可以标记图片是否收藏,以此可参考一下表结构:
CREATE TABLE `sg_user_result` ( `id` bigint(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键', `created_time` datetime DEFAULT NULL COMMENT '创建时间', `user_id` bigint(20) unsigned DEFAULT NULL COMMENT '用户ID', `url` varchar(500) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '资源url', `collect` tinyint(4) DEFAULT NULL COMMENT '是否收藏' PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='生成的结果信息表';设计好表之后,接下来就好pojo、mapper、service等类创建好。
创建UserResult
@Getter @Setter @TableName("sg_user_result") public class UserResult implements Serializable { private static final long serialVersionUID = 1L; /** * 主键 */ @TableId private Long id; /** * 是否收藏 */ private Integer collect; /** * 创建时间 */ private LocalDateTime createdTime; /** * 资源url */ private String url; /** * 用户ID */ private Long userId; }创建UserResultMapper
@Mapper public interface UserMapper extends BaseMapper<User> {}创建UserResultService
在UserResultService中增加一个savelist方法,用于后续存储用户生图图片结果所用
public interface UserResultService extends IService<UserResult> { void savelist(List<String> urls, long userId); }创建UserResultServiceImpl
@Service @Transactional @Slf4j public class UserResultServiceImpl extends ServiceImpl<UserResultMapper, UserResult> implements UserResultService { @Override public void savelist(List<String> urls, long userId) { List<UserResult> userResults=urls.stream().map((url)->{ UserResult userResult=new UserResult(); userResult.setUrl(url); userResult.setUserId(userId); userResult.setCollect(0); return userResult; }).collect(Collectors.toList()); this.saveBatch(userResults); } }
在整个文生图到处理的过程中,关键分为3步:
接收请求:通过文生图Controller接收用户的请求,并把数据封装成ComfyuiTask存入Redis队列中,然后请求结束
调度任务:通过文生图调度器从Redis队列中取出ComfyuiTask,并发送给Comfyui执行,发送成功后缓存任务ID和任务到Redis中
消息处理:通过监听Comfyui的消息,获得消息后,从Redis中取出任务ID对应的ComfyuiTask信息然后:
推送结果到前端
保存数据到数据库
这3步每步通过一个线程类执行,而且执行的时间各不相同,比如在执行第3步的时候,第1步常常已经结束。另外在这3步中只有在第1步才能获取到用户,那么如果将第1步获取的用户信息,传递到第3步中去使用,就是当下要解决的问题。
针对这种跨线程传递数据,可以采用ThreadLocal、Redis等多种方案来实现,但是在这里只能使用Redis,因为在集群情况下存在一种跨机任务执行的情况:假设我们使用ThreadLocal来实现用户信息传递。
服务器1接收到用户的请求,并存入任务队列后,并获得用户信息存入ThreadLocal中
由于SpringTask任务执行获取分布式锁具有随机性,服务器2的调度器可能被执行,那么服务器1添加的任务就跑到服务器2中去执行了,当在服务器2中进行消息处理的时候,如果从ThreadLocal中去获取用户信息,就获取不到。因为这个时候用户信息只存在于服务器的ThreadLocal中。
综上所述,考虑到集群的情况,这个用户问题我们只能通过Redis来传递解决,最简单的实现思路可参考以下实现:
我们在第1步中,给存储封装的Comfyui对象增加一个用户ID字段,并在第1步获取用户后赋值
在消息处理器中从ComfyuiTask对象中直接获取用户ID进行使用
具体实现参考如下:
在ComfyuiTask中增加用户ID字段userId
改造Text2ImageServiceImpl的getComfyuiTask(倒数第二句):@Data public class ComfyuiTask { String id = UUID.randomUUID().toString(); String wsClientId; ComfyuiRequestDto comfyuiRequestDto; String promptId; Long userId; long index; }public ComfyuiTask getComfyuiTask(Text2ImageReqDto text2ImageReqDto) throws Exception { ComfyuiModel comfyuiModel=new ComfyuiModel(); //把text2ImageReqDto的同名属性拷贝到comfyuiModel,true表示忽略大小写 BeanUtil.copyProperties(text2ImageReqDto,comfyuiModel,true); comfyuiModel.setModelName(text2ImageReqDto.modelName()); comfyuiModel.setSamplerName(text2ImageReqDto.samplerName()); comfyuiModel.setScheduler(text2ImageReqDto.scheduler()); comfyuiModel.setWidth(text2ImageReqDto.width()); comfyuiModel.setHeight(text2ImageReqDto.height()); //转换提示词 comfyuiModel.setPropmt(ollamaService.translate(text2ImageReqDto.getPropmt())); //正向词 comfyuiModel.setReverse(ollamaService.translate(text2ImageReqDto.getReverse())); //负向词 //生成comfyui的请求对象 String propmt=freemarkerService.renderText2Image(comfyuiModel); ComfyuiRequestDto requestDto=new ComfyuiRequestDto(Constants.COMFYUI_CLIENT_ID, JSON.parseObject(propmt)); //最后构造ComfuiTask对象 ComfyuiTask comfyuiTask=new ComfyuiTask(text2ImageReqDto.getClientId(),requestDto); //存储用户id comfyuiTask.setUserId(UserUtils.getUser().getId()); return comfyuiTask; }
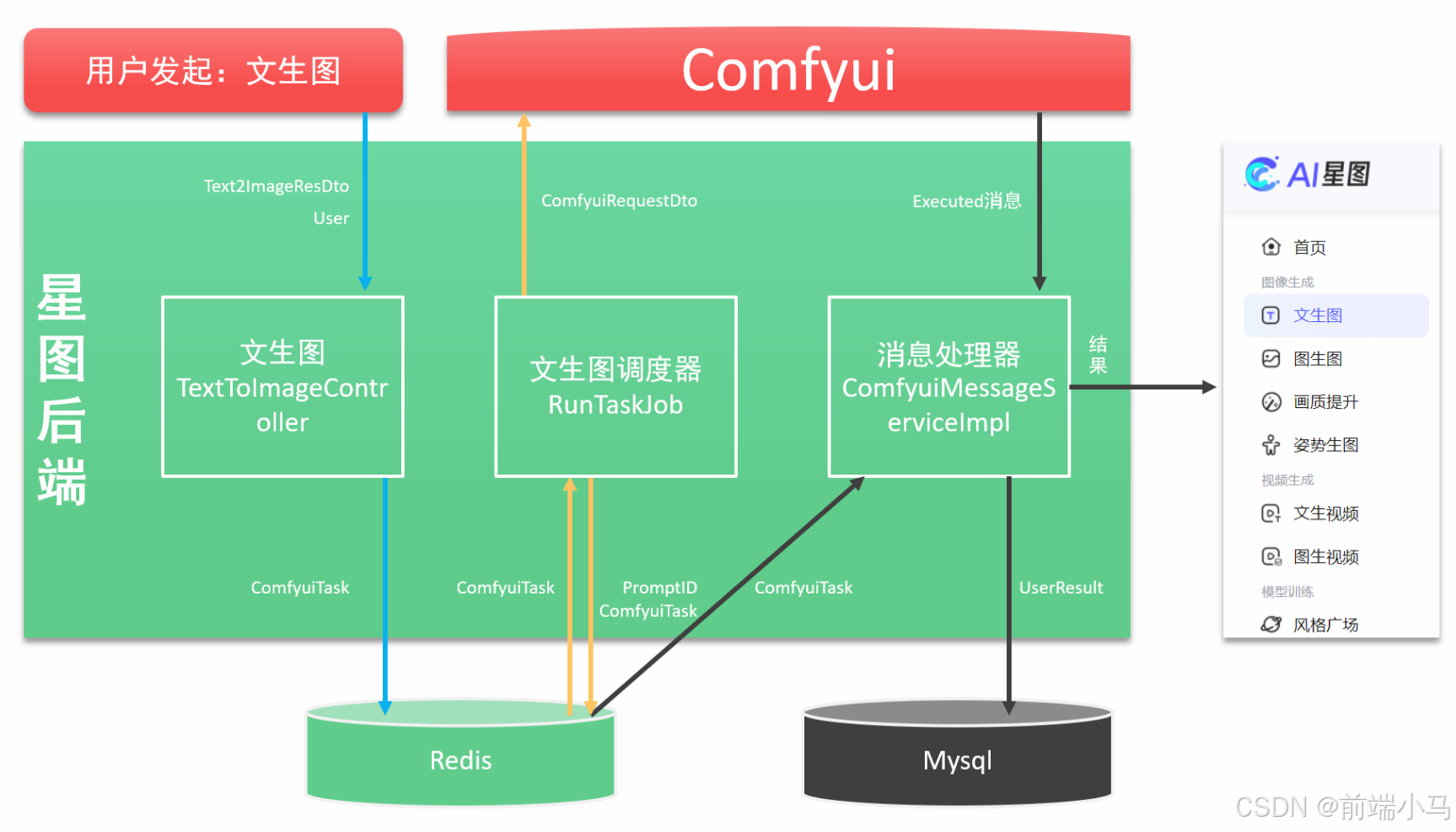
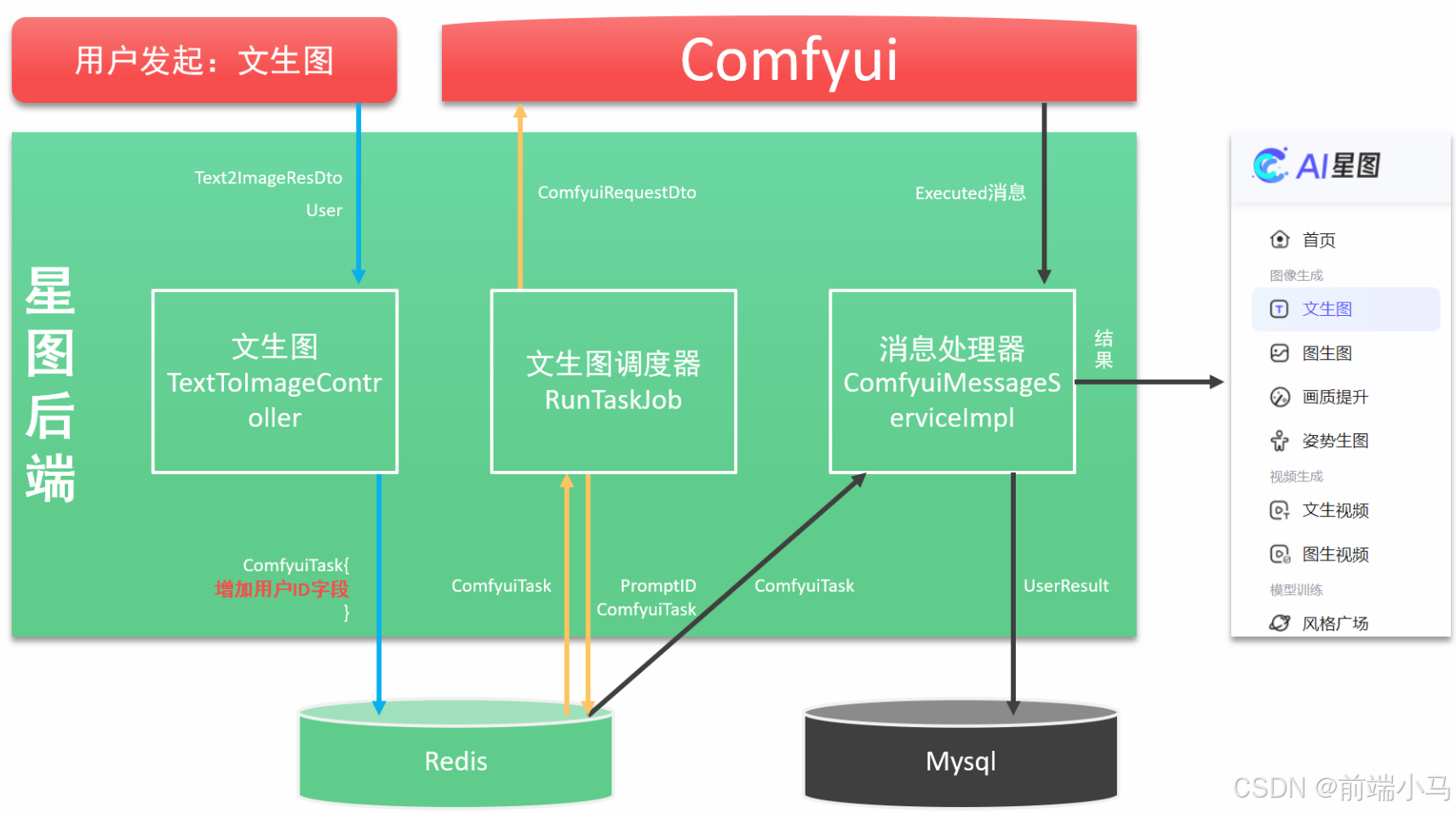
⑤处理生图错误消息
当Comfyui生图图片过程中出现错误,会发出错误消息,当前遇见此消息时,直接把错误信息推送给前端即可。
{ "type": "execution_error", "data": { "node_id": "1", "node_type": "", "exception_message": "异常信息" } }前端所接收的消息格式如:
{ "type": "execution_error", "exception_message": "异常信息" }最后在ComfyuiMessageServiceImpl类中添加execution_error类型判断,然后新增handleExecutionErrorMessage方法并调用发送错误信息给前端。
@Override public void handleMessage(MessageBase messageBase) { if("progress".equals(messageBase.getType())){ //进度消息 handleProgressMessage(messageBase); } else if ("executed".equals(messageBase.getType())) { //生图结果消息 handleExecutedMessage(messageBase); }else if("execution_error".equals(messageBase.getType())){ //失败消息 handleExecutionErrorMessage(messageBase); } } //推送失败消息 private void handleExecutionErrorMessage(MessageBase messageBase){ HashMap<String,Object> data=messageBase.getData(); String prompId=(String) data.get("prompt_id"); ComfyuiTask task= redisService.getStartedTask(prompId); data.put("type","execution_error"); if(task==null){ return; } wsNoticeService.sendToUser(task.getWsClientId(),JSON.toJSONString(data)); }
⑥处理队列状态消息
在之前的学习过程中我们有提到:我们需要保障Comfyui的队列中只有一个任务,这边便于候选取消任务、任务插队等功能的实现。因此我们需要通过一些方案来保障这个需求。
那么在当前的实现方案中,暂不支持这个功能,如:假设文生图请求比较对,那么在Redis中就会缓存很多任务,而调度器目前设置的是每秒钟获取一个任务发送给Comfyui进行执行,又因为Comfyui生图平均花费的时间比较长,因此就会导致每秒钟有一个任务发送到Comfyui的队列中,显然这并不是我们所需要的。
要实现对Comfyui的任务数量进行控制,在当前的方案上可进行如下改造实现:
1、在Redis中设定一个开关值
2、在调度器任务重获取开关的值,如果值是true才进行把任务发送给Comfyui,并且把开关值设为false,即标记Comfyui中已经有任务
3、然后在收到队列状态变化之后,如果队列 任务为0,则把Redis中的开关设置为true,这样程序就回到了第2步
在这个方法中,正常情况下没有问题,但是在高并发下存在一个极端,就是图中1、2都是两个线程,可能存在同时向Redis写开关值的情况,那么对于开关的值就需要保障并发的安全性。
这样的场景其实就是分布式信号量的应用场景。因此在这里我们使用Redisson支持的分布式信号量来进行实现。
分布式信号量是一个用于控制跨集群的多个进程或线程对共享资源访问的计数器。分布式信号量的基本实现流程是:
设定一个信号量计算变量,并初始信号数值,比如 count = 1,这里的数字表示同时运行多少个线程执行
获取一个信号,首先会判断信号count值是否为0,如果不为0则把值减1,并返回获取成功,如果为0,则返回获取失败
归还一个信号,把信号数值增加1
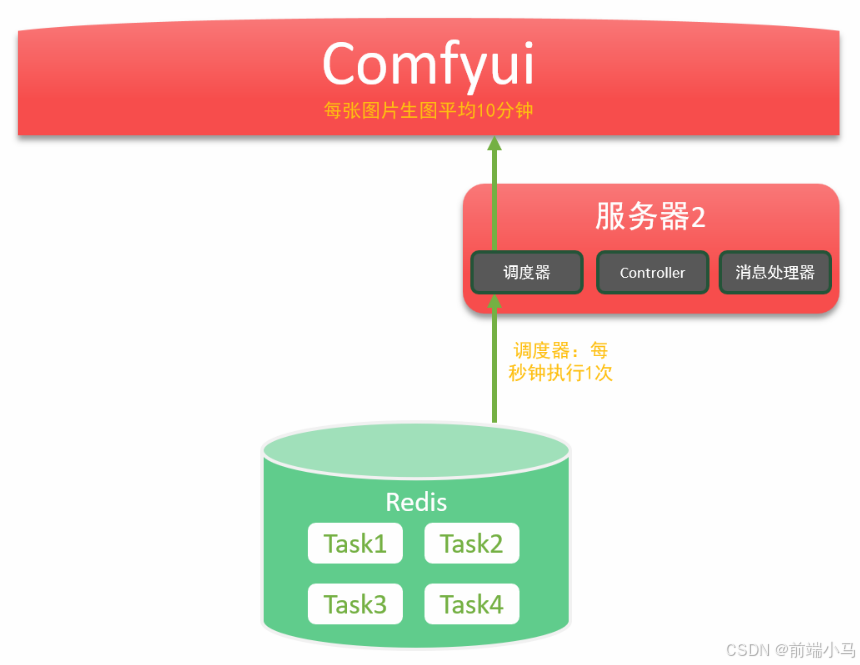
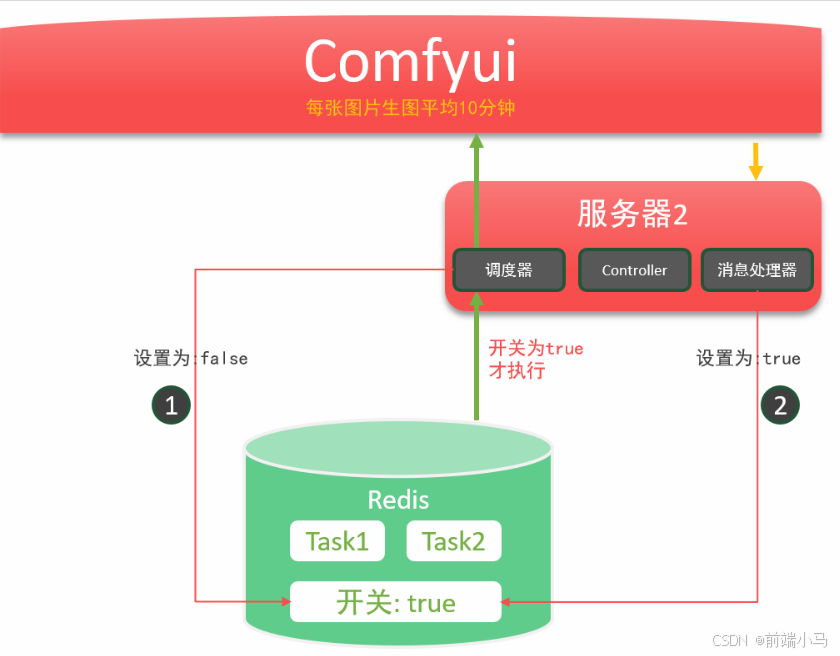
1️⃣修改调度方法
为方便测试,我们在RunTaskJob类中的调度task方法中引入信号量,并获取一个信号
public final static String TASK_RUN_SEMAPHORE = "TASK_RUN_SEMAPHORE"; //每秒执行一次 @Scheduled(cron = "*/1 * * * * ?") public void runTask(){ //获取锁 RLock lock = redissonClient.getLock("SPRING_TASK_LOCK_KEY"); //占有锁 if(lock.tryLock()){ try{ //得到信号量 RSemaphore semaphore= redissonClient.getSemaphore(TASK_RUN_SEMAPHORE); //占用一个信号量,如果占用成功才发送任务 if(semaphore.tryAcquire()){ //会自动把信号量减一 sendTaskToComfyui(); } }finally { lock.unlock(); //释放锁 } } }
2️⃣处理队列状态消息
Comfyui的队列任务值发送变化之后,会广播队列状态变更的事件,事件消息格式如下:
{ "type": "status", "data": { "status": { "exec_info": { "queue_remaining": 1 } } } }然后在ComfyuiMessageServiceImpl类中处理status事件消息:
@Override public void handleMessage(MessageBase messageBase) { if("progress".equals(messageBase.getType())){ //进度消息 handleProgressMessage(messageBase); } else if ("executed".equals(messageBase.getType())) { //生图结果消息 handleExecutedMessage(messageBase); }else if("execution_error".equals(messageBase.getType())){ //失败消息 handleExecutionErrorMessage(messageBase); }else if("status".equals(messageBase.getType())){ //判断是否为status,如果是则调用handleStatusMessage方法 handleStatusMessage(messageBase); } } private void handleStatusMessage(MessageBase messageBase){ HashMap<String,Object> data=messageBase.getData(); HashMap<String,Object> status=(HashMap<String, Object>) data.get("status"); HashMap<String,Object> execInfo=(HashMap<String, Object>) status.get("exec_info"); int queueremaining=Integer.valueOf(execInfo.get("queue_remaining")+""); if(queueremaining==0){//判断队列数量,如果为0则调用信号量的release方法归还信号 //comfyui中没有要执行的任务,则开始发送任务给comfyui RSemaphore semaphore= redissonClient.getSemaphore(runTaskJob.TASK_RUN_SEMAPHORE); semaphore.release(); //归还信号量 System.out.println(DateTime.now()+"\t\t是否许可数量"+semaphore.availablePermits()); } }
3️⃣启动测试
先启动一个服务,如下图左边的服务器,接着在启动第2个服务,如下图右边的服务器,服务器启动过程中连上Comfyui之后,会立即收到一个status事件,此时队列的数量为0,因此会释放一个信号,因此左边先启动的服务器就能开始执行。
通过上述测试,即可通过分布式信号量来控制发送给Comfyui的任务始终只有1个,即满足需求。
启动时的消息导致任务出现多个?
后端服务器启动之后,即会收到一个status消息,如果是集群多个节点同时启动,则可能导致释放多个信号,进而会有多个任务发送到Comfyui。针对这种情况本项目忽略不计。
4️⃣调整调度任务逻辑
当task调度方法每秒钟执行1次,每次都会去获取信号量,这会导致信号量空消耗问题:即,假设信号量为1,队列任务为空,调度器运行一次即消耗掉1个信号量,然后去执行发送任务给Comfyui,但是由于队列为空,则没有任务发送到Comfyui,Comfyui没有任务即不会发送队列为0的事件,即我们的程序不会去归还信号量,这就导致调度器不执行任务。
要解决这个问题只需要把握关键,就是只有任务要推送时才去消耗信号量,因此可参考一下思路进行代码调整:
先判断队列是否有任务,如果有才消耗信号量
发送Comfyui失败时,需要归还信号量,因为发送失败后,Comfyui也是没有任务,不会发送队列为0的事件
在RedisService接口和RedisServiceImpl类中提供判断队列是否为空的方法hasQueueTask:
接口中: public boolean hasQueueTask(); 类中: @Override public void addStartedTask(String promptId, ComfyuiTask task) { stringRedisTemplate.opsForValue().set(RUN_TASK_KEY+promptId,JSON.toJSONString(task),Duration.ofHours(10)); }然后在RunTaskJob中进行代码调整:
@Component public class RunTaskJob { private static final Logger log = LoggerFactory.getLogger(RunTaskJob.class); public final static String TASK_RUN_SEMAPHORE = "TASK_RUN_SEMAPHORE"; @Autowired ComfyuiApi comfyuiApi; @Autowired RedisService redisService; @Autowired RedissonClient redissonClient; //把任务发送给comfyui private void sendTaskToComfyui(){ ComfyuiTask comfyuiTask=redisService.popQueueTask(); if(comfyuiTask==null){ return; } Call<HashMap> addQueueTask=comfyuiApi.addPrompt(comfyuiTask.getComfyuiRequestDto()); try { Response<HashMap> response=addQueueTask.execute(); if(response.isSuccessful()){ HashMap map=response.body(); String promptId=(String) map.get("prompt_id"); comfyuiTask.setPromptId(promptId); log.info("添加任务到Comfyui成功:{}",comfyuiTask.getPromptId()); redisService.addStartedTask(promptId,comfyuiTask); }else { String error=response.errorBody().toString(); log.error("添加任务到Comfyui错误:{}",error); //归还信号量 RSemaphore semaphore= redissonClient.getSemaphore(TASK_RUN_SEMAPHORE); semaphore.release(); } } catch (Exception e) { e.printStackTrace(); } } //每秒执行一次 @Scheduled(cron = "*/1 * * * * ?") public void runTask(){ //获取锁 RLock lock = redissonClient.getLock("SPRING_TASK_LOCK_KEY"); //占有锁 if(lock.tryLock()){ try{ if( redisService.hasQueueTask()){ RSemaphore semaphore= redissonClient.getSemaphore(TASK_RUN_SEMAPHORE); //得到信号量 //占用一个信号量,如果占用成功才发送任务 if(semaphore.tryAcquire()){ System.out.println("开关开启"+DateTime.now()); sendTaskToComfyui(); } } }finally { lock.unlock(); //释放锁 } } } }在ComfyuiMessageServiceImpl中修改handleMessage方法增加handleStatusMessage方法
@Autowired private RunTaskJob runTaskJob; @Override public void handleMessage(MessageBase messageBase) { if("progress".equals(messageBase.getType())){ //进度消息 handleProgressMessage(messageBase); } else if ("executed".equals(messageBase.getType())) { //生图结果消息 handleExecutedMessage(messageBase); }else if("execution_error".equals(messageBase.getType())){ //失败消息 handleExecutionErrorMessage(messageBase); }else if("status".equals(messageBase.getType())){ handleStatusMessage(messageBase); } } private void handleStatusMessage(MessageBase messageBase){ HashMap<String,Object> data=messageBase.getData(); HashMap<String,Object> status=(HashMap<String, Object>) data.get("status"); HashMap<String,Object> execInfo=(HashMap<String, Object>) status.get("exec_info"); int queueremaining=Integer.valueOf(execInfo.get("queue_remaining")+""); if(queueremaining==0){ //comfyui中没有要执行的任务,则开始发送任务给comfyui RSemaphore semaphore= redissonClient.getSemaphore(runTaskJob.TASK_RUN_SEMAPHORE); semaphore.release(); //归还信号量 System.out.println(DateTime.now()+"\t\t是否许可数量"+semaphore.availablePermits()); } }
(8)处理积分划扣
①积分划扣的实现方案
在需求中提到积分有多种用途:
积分系统:每成功生成一张图片,系统将自动扣除用户1积分。考虑到用户可能希望一次性获得更多创意输出,我们特别设置了批量生成选项,即用户可选择一次性生成3张图片,此时系统将按3积分进行扣除,极大地提升了生成效率与用户满意度。
排队与优先级机制:鉴于服务器资源的宝贵性,所有文生图请求均采取智能排队策略。在队列中等待的任务,用户可根据需求选择是否取消,以灵活调整自己的创作计划。同时,为了满足部分用户的紧急需求,我们推出了积分插队服务——用户可通过消耗额外的5积分,使自己的任务提前至队列前10个位置,快速获得处理机会,这一机制确保了资源的合理分配与高效利用。
通过图片中的文本可见用户的积分有冻结和非冻结之分,在此也说明一下为什么定当如此?
通过之前的学习我们已经知道文生图流程整体分为下图中的3步,那么积分划扣的方案常有有如下几种:
方案一:第1步直接扣积分,第2、3步如果失败则返还积分,如果最终成功则什么都不操作
方案二:第1、2步不用管积分,在第3步如果成功则扣除积分,如果失败则什么都不用操作
方案三:第1步冻结积分,第2、3步如果失败则把冻结积分返还,最终如果成功则把冻结的积分划扣掉
这3种方案首选要排除的就是第二种,因为第二种如果不在文生图接口中做积分判断和限制,有可能会导致图片生成了积分不够的情况。第一种方案可行,实现也简单,但是这种方案只适用于一些非重要资产的消费记录比如点赞数、收藏数等。针对用户的价值资产比如:资金、欢乐豆、积分等资产,在企业中常常要求提供可查账、对账的需求,因此要求系统必须提供价值资产的查找、对账明细数据,在这种情况下方案三即为最合适的方案。即星图用户积分区分冻结和非冻结,方便记录积分资产的变动明细数据。

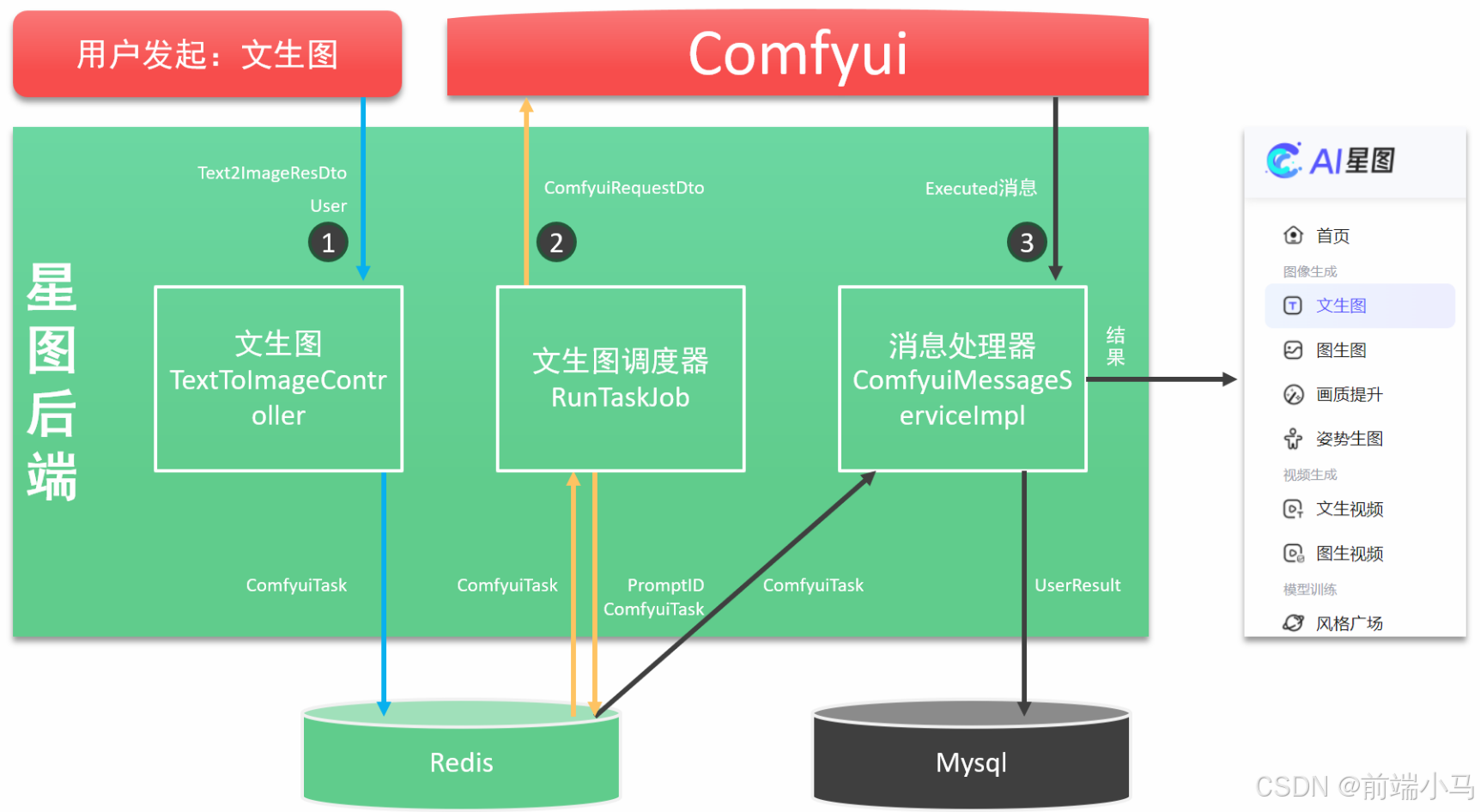
② 复式记账表设计
对于重要的资产,常用单式记账法和复式记账法进行记账:
单式记账法:记录每一笔什么时候消费,消费的金额是多次,还可以记录消费的事由
复式记账法:每一笔消费都必须在至少2个相关的账户中以相等的额度进行记录,以确保会计信息的完整性和准确性。
本项目采用复式记账法进行实现,因此系统用户需要有账户的概念,那么系统用户的积分账户设计如下:
每个用户都有积分账户、积分冻结账户两个账号,用户账号的ID标识为用户ID
系统有一个总账户,总账户也有积分账户和积分冻结账户的区分,且总账户的ID标识为0
有了账户体系之后,账户与账户之间进行消费,就可以用一些专业术语进行定义:
明确术语之后,接下来即可设计一下相关表,在这里首先要设计一个账户表,存储用户的积分账户余额、积分冻结账户余额等信息,可参考一下表结构:
积分冻结:指从用户积分账户拿出积分,增加到用户积分冻结账户上
冻结归还:指从积分冻结账户上拿出积分,增加到用户积分账户上
积分扣除:指从用户积分冻结账号上拿出积分,增加到总账户的积分账户上
直接划扣:指从用户的积分账户上拿出积分,增加到总账户的积分账户上
这个表我们把用户的积分账户和积分冻结账户合并成一条记录,同时要在表中初始化总账户数据(总账户ID为0)CREATE TABLE `sg_user_fund` ( `id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键', `created_time` datetime DEFAULT NULL COMMENT '创建时间', `score` bigint unsigned DEFAULT NULL COMMENT '积分账户', `version` bigint unsigned DEFAULT NULL COMMENT '乐观锁', `freeze_score` bigint unsigned DEFAULT NULL COMMENT '积分冻结账户', `user_id` bigint unsigned DEFAULT NULL COMMENT '用户ID', PRIMARY KEY (`id`), KEY `idx_user_id` (`user_id`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='用户账户信息表';有了账户之后,接下来即可设计一个记录积分账户流水信息表。依据复式记账法,每一笔消费都要记录至少相关两个账户的流水变化,因此每一笔消费在流水表中至少有两条数据。INSERT INTO `sg_user_fund`(`created_time`,`score`,`user_id`,`freeze_score`,`id`,`version`) VALUES ('2024-08-27T02:51:16','0','0','0','0','0');CREATE TABLE `sg_user_fund_record` ( `id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键', `created_time` datetime DEFAULT NULL COMMENT '创建时间', `fund_type` tinyint unsigned DEFAULT NULL COMMENT '账户类型0积分账户,1积分冻结账户', `money` int DEFAULT NULL COMMENT '额度', `fund_id` bigint unsigned DEFAULT NULL COMMENT '账户ID', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='账户流水信息表';SQL说明:
fund_type字段记录是从那个账户流入流出
money字段是指积分扣除的额度,正为增加,负为扣减
③拷贝积分表基础代码
有了基本代码之后,我们可以提供Service,并在其中封装好以下4个方法,供后续使用:
积分冻结:指从用户积分账户拿出积分,增加到用户积分冻结账户上
冻结归还:指从积分冻结账户上拿出积分,增加到用户积分账户上
积分扣除:指从用户积分冻结账号上拿出积分,增加到总账户的积分账户上
直接划扣:指从用户的积分账户上拿出积分,增加到总账户的积分账户上
导入数据库对应的类及对应的Mapper:
@Data @TableName("sg_user_fund_record") public class SgUserFundRecord implements Serializable { /** * 主键 */ private Long id; /** * 创建时间 */ private Date createdTime; /** * 账户类型0积分账户,1积分冻结账户 */ private Integer fundType; /** * 额度 */ private Integer money; /** * 账户ID */ private Long fundId; } @Data @TableName("sg_user_fund") public class SgUserFund implements Serializable { /** * 主键 */ private Long id; /** * 创建时间 */ private Date createdTime; /** * 积分账户 */ private Long score; /** * 乐观锁 */ private Long version; /** * 积分冻结账户 */ private Long freezeScore; /** * 用户ID */ private Long userId; }首先在UserFundRecordService类中定义四个方法:public interface SgUserFundRecordMapper extends BaseMapper<SgUserFundRecord> {} public interface SgUserFundMapper extends BaseMapper<SgUserFund> {}public interface UserFundRecordService extends IService<SgUserFundRecord> { // 积分冻结 void pointsFreeze(Long userId, Integer money); // 冻结归还 void freezeReturn(Long userId, Integer money); // 积分扣除 void pointsDeduction(Long userId, Integer money); // 直接划扣 void directDeduction(Long userId, Integer money); }然后在UserFundRecordServiceImpl中实现这四个方法:
@Service @Transactional @Slf4j public class UserFundRecordServiceImpl extends ServiceImpl<SgUserFundRecordMapper, SgUserFundRecord> implements UserFundRecordService { @Autowired SgUserFundMapper sgUserFundMapper; @Autowired SgUserFundRecordMapper sgUserFundRecordMapper; @Override // 积分冻结:指从用户积分账户拿出积分,增加到用户积分冻结账户上 public void pointsFreeze(Long userId, Integer money) { SgUserFund sgUserFund = getUserSgUserFund(userId); long temp=sgUserFund.getScore()-money; if(temp>=0){ sgUserFund.setScore(temp); sgUserFund.setFreezeScore(sgUserFund.getFreezeScore()+money); sgUserFundMapper.updateById(sgUserFund); savelog(0,-money,sgUserFund.getId()); savelog(1,money,sgUserFund.getId()); }else { throw new CustomException("积分账户余额不足"); } } @Override // 冻结归还:指从用户积分冻结账号上拿出积分,增加到总账户的积分账户上 public void freezeReturn(Long userId, Integer money) { SgUserFund sgUserFund = getUserSgUserFund(userId); long temp=sgUserFund.getFreezeScore()-money; if(temp>=0){ sgUserFund.setScore(sgUserFund.getScore()+money); sgUserFund.setFreezeScore(temp); sgUserFundMapper.updateById(sgUserFund); savelog(0,money,sgUserFund.getId()); savelog(1,-money,sgUserFund.getId()); }else { throw new CustomException("积分东京账户余额不足"); } } @Override // 积分扣除:指从用户积分冻结账号上拿出积分,增加到总账户的积分账户上 public void pointsDeduction(Long userId, Integer money) { SgUserFund userFund = getUserSgUserFund(userId); SgUserFund allFund =getUserSgUserFund(0L); long temp= userFund.getFreezeScore()-money; if(temp>=0){ //用户账户修改 userFund.setFreezeScore(temp); savelog(1,-money,userFund.getId()); sgUserFundMapper.updateById(userFund); //总账户修改 allFund.setScore(allFund.getScore()+money); savelog(0,money,allFund.getId()); sgUserFundMapper.updateById(allFund); }else { throw new CustomException("积分冻结账户余额不足"); } } @Override // 直接划扣:指从用户的积分账户上拿出积分,增加到总账户的积分账户上 public void directDeduction(Long userId, Integer money) { } // 插入一条流水信息 private void savelog(int foudType,int money,long foudId){ SgUserFundRecord log=new SgUserFundRecord(); log.setFundType(foudType); log.setMoney(money); log.setFundId(foudId); sgUserFundRecordMapper.insert(log); } //获取一个用户的账户,如果没有则创建一个 public SgUserFund getUserSgUserFund(Long userId){ LambdaQueryWrapper<SgUserFund> wrapper = new LambdaQueryWrapper<>(); wrapper.eq(SgUserFund::getUserId,userId); SgUserFund sgUserFund = sgUserFundMapper.selectOne(wrapper); if(sgUserFund==null){ sgUserFund=new SgUserFund(); sgUserFund.setUserId(userId); sgUserFund.setScore(0L); sgUserFund.setFreezeScore(0L); sgUserFund.setVersion(0L); sgUserFundMapper.insert(sgUserFund); } return sgUserFund; } }完善Test2ImageServiceImpl类中的textToImage方法:
@Autowired UserFundRecordService userFundRecordService; @Override public Text2ImageResponDto textToImage(Text2ImageReqDto text2ImageReqDto) throws Exception { //把请求参数封装并存储到redis if(text2ImageReqDto.getSize()<1){ throw new CustomException("请求参数错误"); } userFundRecordService.pointsDeduction(UserUtils.getUser().getId(),text2ImageReqDto.getSize()); //封装数据: ComfyuiTask comfyuiTask=getComfyuiTask(text2ImageReqDto); //保存到redis comfyuiTask= redisService.addQueueTack(comfyuiTask); //返回数据 Text2ImageResponDto text2ImageResponDto=new Text2ImageResponDto(); text2ImageResponDto.setPid(comfyuiTask.getId()); text2ImageResponDto.setQueueIndex((int) comfyuiTask.getIndex()); return text2ImageResponDto; }完善UserResultServiceImpl类:
@Service @Transactional @Slf4j public class UserResultServiceImpl extends ServiceImpl<UserResultMapper, UserResult> implements UserResultService { @Autowired UserFundRecordService userFundRecordService; @Override public void savelist(List<String> urls, long userId) { List<UserResult> userResults=urls.stream().map((url)->{ UserResult userResult=new UserResult(); userResult.setUrl(url); userResult.setUserId(userId); userResult.setCollect(0); return userResult; }).collect(Collectors.toList()); this.saveBatch(userResults); //积分扣除 userFundRecordService.pointsDeduction(userId,userResults.size()); } }ComfyuiTask类增加一个size属性并完善Test2ImageServiceImpl类的getComfyuiTask方法
:
@Data public class ComfyuiTask { String id = UUID.randomUUID().toString(); String wsClientId; ComfyuiRequestDto comfyuiRequestDto; String promptId; long index; long userId; int size;//生成的图片 public ComfyuiTask(String wsClientId, ComfyuiRequestDto comfyuiRequestDto) { this.wsClientId = wsClientId; this.comfyuiRequestDto = comfyuiRequestDto; } } public ComfyuiTask getComfyuiTask(Text2ImageReqDto text2ImageReqDto) throws Exception { ComfyuiModel comfyuiModel=new ComfyuiModel(); //把text2ImageReqDto的同名属性拷贝到comfyuiModel,true表示忽略大小写 BeanUtil.copyProperties(text2ImageReqDto,comfyuiModel,true); comfyuiModel.setModelName(text2ImageReqDto.modelName()); comfyuiModel.setSamplerName(text2ImageReqDto.samplerName()); comfyuiModel.setScheduler(text2ImageReqDto.scheduler()); comfyuiModel.setWidth(text2ImageReqDto.width()); comfyuiModel.setHeight(text2ImageReqDto.height()); //转换提示词 comfyuiModel.setPropmt(ollamaService.translate(text2ImageReqDto.getPropmt())); //正向词 comfyuiModel.setReverse(ollamaService.translate(text2ImageReqDto.getReverse())); //负向词 //生成comfyui的请求对象 String propmt=freemarkerService.renderText2Image(comfyuiModel); ComfyuiRequestDto requestDto=new ComfyuiRequestDto(Constants.COMFYUI_CLIENT_ID, JSON.parseObject(propmt)); //最后构造ComfuiTask对象 ComfyuiTask comfyuiTask=new ComfyuiTask(text2ImageReqDto.getClientId(),requestDto); //存储用户id comfyuiTask.setUserId(UserUtils.getUser().getId()); comfyuiTask.setSize(text2ImageReqDto.getSize()); return comfyuiTask; }完善RunTaskJob 类的sendTaskToComfyui方法:
@Autowired UserFundRecordService userFundRecordService; //把任务发送给comfyui private void sendTaskToComfyui(){ ComfyuiTask comfyuiTask=redisService.popQueueTask(); if(comfyuiTask==null){ return; } Call<HashMap> addQueueTask=comfyuiApi.addPrompt(comfyuiTask.getComfyuiRequestDto()); try { Response<HashMap> response=addQueueTask.execute(); if(response.isSuccessful()){ HashMap map=response.body(); String promptId=(String) map.get("prompt_id"); comfyuiTask.setPromptId(promptId); log.info("添加任务到Comfyui成功:{}",comfyuiTask.getPromptId()); redisService.addStartedTask(promptId,comfyuiTask); }else { String error=response.errorBody().toString(); log.error("添加任务到Comfyui错误:{}",error); //归还信号量 RSemaphore semaphore= redissonClient.getSemaphore(TASK_RUN_SEMAPHORE); semaphore.release(); //冻结归还 userFundRecordService.freezeReturn(comfyuiTask.getUserId(),comfyuiTask.getSize()); } } catch (Exception e) { e.printStackTrace(); } }完善ComfyuiMessageServiceImpl类的handleExecutionErrorMessage方法
@Autowired UserFundRecordService userFundRecordService; private void handleExecutionErrorMessage(MessageBase messageBase){ HashMap<String,Object> data=messageBase.getData(); String prompId=(String) data.get("prompt_id"); ComfyuiTask task= redisService.getStartedTask(prompId); data.put("type","execution_error"); if(task==null){ return; } userFundRecordService.freezeReturn(task.getUserId(),task.getSize()); wsNoticeService.sendToUser(task.getWsClientId(),JSON.toJSONString(data)); }
④ 自动填充和乐观锁
在上述测试过程中我们发现sg_user_fund表中的version字段值没有变化,同时在sg_user_fund_record表中created_time创建时间字段为空。而且这两个字段在代码里面也并没有设置其值,其实这是故意保留的问题,因为这些字段的值,在实际项目开发中都是通过Mybatis-Plus的功能来实现,比如:
version字段使用的是乐观锁插件OptimisticLockerInnerInterceptor
created_time、updated_time等字段使用的是自动填充功能
那么在此我们也再次回顾并参考一下代码进行上述功能的配置:
创建cn.itcast.star.graph.core.autofill.AutoFillMetaObjectHandler类,用于设定自动填充的字段
然后UserFund、UserFundRecord两个类的createdTime字段增加自动填充标识:@Component public class AutoFillMetaObjectHandler implements MetaObjectHandler { @Override //插入语句要自动填充的规则 public void insertFill(MetaObject metaObject) { //1. 当前执行的插入sql,源数据 2. 要自动填充的字段名 3.填充值得类型 4. 默认填充值 this.strictInsertFill(metaObject,"createdTime", LocalDateTime.class,LocalDateTime.now()); this.strictInsertFill(metaObject,"createTime", LocalDateTime.class,LocalDateTime.now()); } @Override //更新语句要自动填充的规则 public void updateFill(MetaObject metaObject) { this.strictUpdateFill(metaObject,"updateTime", LocalDateTime.class,LocalDateTime.now()); } }@TableField(fill = FieldFill.INSERT) private LocalDateTime createdTime;然后再创建一个配置类cn.itcast.star.graph.core.config.MybatisPlusConfig,用于开启Mybatis-Plus的分页、乐观锁插件
@Configuration public class MybatisPlusConfig { @Bean public MybatisPlusInterceptor mybatisPlusInterceptor() { MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor(); interceptor.addInnerInterceptor(new PaginationInnerInterceptor()); interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor()); return interceptor; } }最后UserFund类的version字段增加上乐观锁字段注解@Version
@Version private Long version;




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











