






摘要:多模态奖励模型(MRMs)在增强多模态大语言模型(MLLMs)的性能方面发挥着至关重要的作用。 虽然最近的进展主要集中在改进MRM的模型结构和训练数据上,但对奖励建模的长期推理能力的有效性以及如何在MRM中激活这些能力的探索有限。在本文中,我们探讨了如何使用强化学习(RL)来改进奖励建模。 具体而言,我们将奖励建模问题重新表述为基于规则的强化学习任务。 然而,我们观察到,直接应用现有的强化学习算法(如强化学习++)来奖励建模,由于这些算法的固有局限性,往往会导致训练不稳定甚至崩溃。 为了解决这个问题,我们提出了StableReinforce算法,该算法改进了现有强化学习方法的训练损失、优势估计策略和奖励设计。 这些改进带来了更稳定的训练动态和更优的性能。 为了促进MRM培训,我们从不同的数据集中收集了200K的偏好数据。 我们的奖励模型R1-Reward使用StableReinforce算法在该数据集上进行训练,显著提高了多模态奖励建模基准的性能。 与之前的SOTA模型相比,R1-Reward在VL Reward-Bench上实现了8.4%的改进,在Multimodal Reward Bench上实现了14.3%的改进。 此外,随着推理计算能力的增强,R1-Reward的性能得到了进一步提升,突出了强化学习算法在优化MRM方面的潜力。Huggingface链接:Paper page,论文链接:2505.02835
研究背景和目的
研究背景
随着人工智能技术的快速发展,多模态大语言模型(Multimodal Large Language Models, MLLMs)在处理复杂任务、理解多模态数据方面展现出了强大的能力。这些模型结合了自然语言处理和计算机视觉技术,能够同时处理文本、图像等多种信息,极大地扩展了语言模型的应用范围。然而,MLLMs的性能高度依赖于其训练过程中所使用的奖励信号,这些信号通常由多模态奖励模型(Multimodal Reward Models, MRMs)提供。
MRMs在MLLMs的训练、推理和评估阶段均发挥着关键作用。在训练阶段,MRMs为强化学习(Reinforcement Learning, RL)算法提供奖励信号,直接影响训练的稳定性和最终模型的性能。在推理阶段,MRMs有助于筛选高质量的数据,提升模型的泛化能力。在评估阶段,MRMs可作为评估器,简化评估过程,特别是在开放式生成任务中。
尽管MRMs在MLLMs中扮演着如此重要的角色,但现有的MRMs在奖励建模的长期推理能力方面仍存在不足。传统的MRMs主要关注于提升模型的分类准确率和数据效率,而对于如何激活和利用模型的长期推理能力关注较少。此外,直接应用现有的RL算法(如Reinforce++)进行奖励建模时,往往面临训练不稳定甚至崩溃的问题,这限制了MRMs性能的进一步提升。
研究目的
本文的研究目的在于探索如何通过稳定的强化学习算法来训练多模态奖励模型(MRMs),以提升其长期推理能力和整体性能。具体而言,本文旨在:
-
提出一种稳定的强化学习算法:针对现有RL算法在奖励建模任务中存在的训练不稳定问题,提出一种名为StableReinforce的新算法。该算法通过改进训练损失、优势估计策略和奖励设计,实现更稳定的训练动态和更优的性能。
-
构建和训练MRMs:收集200K偏好数据,利用StableReinforce算法训练MRMs,特别是本文提出的R1-Reward模型。通过对比实验,验证R1-Reward在多模态奖励建模基准上的性能提升。
-
探索RL在MRMs中的潜力:通过实验验证,展示RL算法在优化MRMs方面的潜力,特别是在提升模型的长期推理能力和数据效率方面。
研究方法
数据收集与预处理
为了训练MRMs,本文从多个公开数据集中收集了200K偏好数据。这些数据涵盖了文本、图像等多种模态的信息,为MRMs的训练提供了丰富的样本。在数据预处理阶段,对原始数据进行了清洗、标注和格式化处理,以确保数据的质量和一致性。
StableReinforce算法设计
StableReinforce算法是在现有RL算法(如PPO和Reinforce++)的基础上进行改进得到的。具体改进包括:
-
预剪裁(Pre-CLIP):在计算指数函数之前,对概率比进行剪裁,以防止数值不稳定。这一操作通过限制概率比的范围,避免了因概率差异过大而导致的梯度爆炸问题。
-
优势过滤(Advantage Filter):应用3-sigma规则,仅保留标准化优势值在[-3, 3]范围内的样本。这一操作有效去除了异常值对训练过程的影响,提升了训练的稳定性。
-
一致性奖励(Consistency Reward):引入一个额外的MLLM作为裁判,评估模型的推理过程与最终结果的一致性。这一奖励机制鼓励模型在推理过程中保持逻辑一致性,从而提升最终输出的准确性。
模型训练与评估
利用收集到的偏好数据和StableReinforce算法,对R1-Reward模型进行训练。训练过程中,采用监督微调(SFT)和强化学习(RL)两个阶段。在SFT阶段,使用GPT-4o生成的思考过程作为冷启动数据,对模型进行初步训练。在RL阶段,选取具有挑战性的样本进行训练,以提升模型的推理能力和鲁棒性。
评估阶段,在多个多模态奖励建模基准上对R1-Reward模型进行测试,包括VL Reward-Bench、Multimodal Reward Bench和MM-RLHF Reward Bench等。通过对比实验,验证R1-Reward在性能上的提升。
研究结果
性能提升
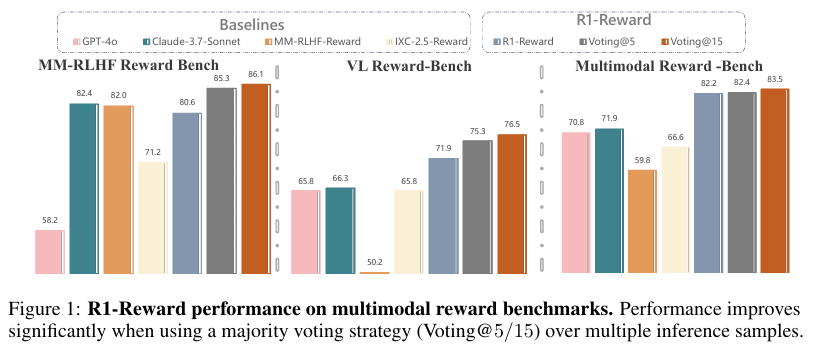
实验结果表明,与之前的SOTA模型相比,R1-Reward在多个多模态奖励建模基准上均取得了显著的性能提升。具体而言,在VL Reward-Bench上,R1-Reward实现了8.4%的性能提升;在Multimodal Reward Bench上,性能提升了14.3%。此外,在MM-RLHF Reward Bench上,R1-Reward也展现出了优越的性能。
数据效率提升
值得注意的是,R1-Reward在仅使用200K偏好数据的情况下,就取得了与使用超过100万样本训练的IXC-2.5-Reward模型相当甚至更优的性能。这一结果表明,StableReinforce算法显著提升了模型的数据效率,使得在有限数据下也能训练出高性能的MRMs。
推理能力增强
通过引入一致性奖励机制,R1-Reward在推理过程中展现出了更强的逻辑一致性。实验结果显示,在处理复杂多模态任务时,R1-Reward能够更准确地理解问题背景、分析选项差异,并给出更合理的判断。这一改进不仅提升了模型的性能,还增强了其在实际应用中的可靠性和可用性。
测试时扩展能力
本文还探索了R1-Reward在测试时的扩展能力。通过增加推理时的采样次数,并采用多数投票策略,R1-Reward的性能得到了进一步提升。这一结果表明,R1-Reward具有优秀的测试时扩展能力,能够根据实际需求灵活调整推理策略,以获得更优的性能。
研究局限
尽管本文在多模态奖励建模方面取得了显著进展,但仍存在一些局限性:
-
数据多样性:尽管本文从多个公开数据集中收集了偏好数据,但数据的多样性仍可能有限。未来研究可以考虑引入更多类型的数据源,以进一步提升模型的泛化能力。
-
模型复杂度:R1-Reward模型虽然取得了显著的性能提升,但其复杂度也相对较高。在实际应用中,需要考虑模型的计算资源和时间成本。未来研究可以探索如何在保持性能的同时降低模型的复杂度。
-
长期推理能力:尽管本文通过一致性奖励机制增强了模型的长期推理能力,但在处理极其复杂的多模态任务时,模型的推理能力仍可能受限。未来研究可以进一步探索如何利用更先进的RL算法和技术来提升模型的长期推理能力。
-
评估指标:本文在评估模型性能时主要采用了准确率等指标。然而,在实际应用中,模型的性能可能受到多种因素的影响。未来研究可以考虑引入更多维度的评估指标,以更全面地评估模型的性能。
未来研究方向
基于本文的研究结果和局限性分析,未来研究可以从以下几个方面展开:
-
数据增强与多样性提升:探索更多类型的数据源和数据增强技术,以提升训练数据的多样性和质量。例如,可以引入合成数据、迁移学习等技术来扩充数据集。
-
模型优化与复杂度降低:在保持模型性能的同时,探索降低模型复杂度的方法。例如,可以采用模型剪枝、量化等技术来减少模型的参数数量和计算量。
-
长期推理能力提升:进一步探索如何利用更先进的RL算法和技术来提升模型的长期推理能力。例如,可以研究如何结合层次化强化学习、元学习等技术来增强模型的推理能力。
-
多维度评估指标:引入更多维度的评估指标来全面评估模型的性能。例如,可以考虑模型的鲁棒性、可解释性、实时性等方面的指标。
-
实际应用探索:将R1-Reward模型应用于更多实际场景中,探索其在不同领域的应用潜力和价值。例如,可以将其应用于智能客服、自动驾驶、医疗诊断等领域,以验证其在实际应用中的有效性和可靠性。
-
跨模态融合与交互:研究如何更好地实现不同模态之间的融合与交互,以提升模型在处理多模态任务时的性能。例如,可以探索如何利用注意力机制、图神经网络等技术来增强模态之间的信息交互和融合。
综上所述,本文通过提出StableReinforce算法并训练R1-Reward模型,在多模态奖励建模方面取得了显著进展。然而,仍存在一些局限性和挑战需要未来研究进一步探索和解决。通过不断的研究和创新,相信未来能够开发出更加高效、可靠和智能的多模态奖励模型,为人工智能技术的发展和应用做出更大贡献。

















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









