







##
单链表是一种基本且常用的数据结构,
它通过指针将一系列节点(元素)串联起来。
每个节点包含两个主要部分:数据域和指针域。
##
1. 结构定义
在C语言中,单链表的节点通常可以这样定义:
typedef struct LNode {
int data; // 数据域,存储具体的数据内容
struct LNode *next; // 指针域,指向下一个节点的地址
} LNode, *LinkList;
这里的LNode是单个节点的结构体类型,而LinkList是指向LNode类型的指针,常用于表示整个链表的头指针。
在JAVA语言中,单链表的节点通常可以这样定义:
public static class list_node{
public int val;
public list_node next;//类似于指针指向下一个元素节点的地址
public list_node(int val){
this.val=val;//外部需要传递的元素值
}
}
public list_node head;//指定头部
这里的的head是指向头部/首节点,常用于表示整个链表的头指针。
2. 链表特性
- 动态性:链表的长度可以在程序运行过程中任意改变,可以根据需要添加或删除节点。
- 非连续存储:链表中的各个节点在内存中不必是连续存放的,相邻节点之间通过指针相连。
- 顺序访问:只能从一个节点通过其
next指针找到下一个节点,不能随机访问。
3. 常见操作
- 创建链表:初始化头结点,然后逐步添加新节点
- `public void create_list(){
list_node node1=new list_node(11);
list_node node2=new list_node(13);
list_node node3=new list_node(11);
list_node node4=new list_node(12);
list_node node5=new list_node(20);
node1.next=node2;
node2.next=node3;
node3.next=node4;
node4.next=node5;
this.head=node1;//指定头部在第一个位置
}`
- 插入节点:
- 头插法:在链表头部插入新的节点。
- 中间插入:在指定位置后插入新节点。
- 尾插法:在链表尾部插入新的节点。
- 删除节点:根据给定值或节点位置删除相应节点。
- 遍历链表:通过指针逐个访问每个节点。
- 查找节点:按照给定条件搜索链表中的节点是否存在。
- 反转链表:修改节点间的连接方向以实现链表反转。
- 接口实现:
public interface Ilist_single {
//定义接口
public void addFirst(int data);
public void addLast(int data);
public void addIndex(int index, int data);
public boolean contains(int key);
public void remove(int key);
public void removeAllKey(int key);
public int size();
public void clear();
public void display();
}
`
4. 核心代码实现
package override_single_linked_list;
import link_list.my_link_list;
import link_list.yi_chang;
public class single_linked_list implements Ilist_single {
public static class list_node{
public int val;
public list_node next;//类似于指针指向下一个元素节点
public list_node(int val){
this.val=val;//外部需要传递的元素值
}
}
public list_node head;//指定头部
public void create_list(){
list_node node1=new list_node(11);
list_node node2=new list_node(13);
list_node node3=new list_node(11);
list_node node4=new list_node(12);
list_node node5=new list_node(20);
//指向关系 一个节点指向下一个节点
node1.next=node2;
node2.next=node3;
node3.next=node4;
node4.next=node5;
this.head=node1;//指定头部在第一个位置
}
@Override
public void addFirst(int data) {
//头插法
list_node new_elments=new list_node(data);//定义一个将要插入的新元素
if(head==null){
new_elments.next=head;
}
else{
new_elments.next=head;
this.head=new_elments;
}
}
@Override
public void addLast(int data) {
//尾插法
list_node new_elments=new list_node(data);
list_node cur=this.head;
if(cur==null){
cur=new_elments;//new_elments:是节点的地址
}
else{
while(cur.next!=null){
cur=cur.next;//一直往下遍历
}
cur.next=new_elments;
}
}
@Override
public void addIndex(int index, int data) {
//根据索引位置插入
//首先要检查index是否越界的问题
if(index<0||index>size()){
throw new yi_chang_("这是越界的异常");
}
if(index==0){
addFirst(data);
}
if(index==size()){
addLast(data);
}
//这些情况都不是的话进行按索引位置插入
//需要找到前一个位置
//不能去找后一个位置
// 因为一旦后一个位置确定那么前一个位置无法定位
// 因为单链表顺序而下 不能回退
list_node prev=search_node(index);
list_node new_lements=new list_node(data);
new_lements.next=prev.next;
prev.next=new_lements;
}
private list_node search_node(int index) {
//找到index的前一个位置
list_node cur = this.head;
int count = 0;
while (count != index - 1) {
cur = cur.next;
count++;
}
return cur;
//两种方式
// list_node cur=this.head;
// while(index-1!=0){
// cur=cur.next;
// index--;
// }
// return cur;
// }
}
@Override
public boolean contains(int key) {
//查找是否包含关键字key key是否在链表中
list_node cur=this.head;
while(cur!=null){
if(cur.val==key){
return true;
}
cur=cur.next;
}
return false;
}
@Override
public void remove(int key) {
//删除第一次出现key的节点
if(this.head==null){
return;
}
if(head.val==key){
head=head.next;
return ;
}
//需要找到前一个的index
list_node index_prev=search_node_index(key);
if(index_prev==null){
return;
}
//定义一个要删除的元素
list_node del = new list_node(key);
index_prev.next=del.next;
}
private list_node search_node_index(int key) {
list_node cur=this.head;
while(cur.next!=null){
if(cur.val==key){
return cur;
}
cur=cur.next;
}
return null;
}
@Override
public void removeAllKey(int key) {
//移除所有的包含key的节点
if(this.head==null){
return;
}
list_node prev=this.head;
list_node cur=this.head;
while(cur!=null){
if(cur.val==key){
prev.next=cur.next;
cur=cur.next;
}else{
prev=cur;
cur=cur.next;
}
}
if(head.val==key){
head=head.next;
}
}
@Override
public int size() {
int count=0;
list_node cur=this.head;
while(cur!=null){
cur=cur.next;
count++;
}
return count;
}
@Override
public void clear() {
//清盘
list_node cur=this.head;
while(cur!=null){
cur.next=null;
cur=cur.next;
}
this.head=null;
}
@Override
public void display() {
list_node cur=this.head;
while(cur!=null){
System.out.println(cur.val);
cur=cur.next;
}
}
}
以上就是单链表的基本概念及其一些典型操作的简要说明。
**总的来说:
单链表的难点在于在特定位置进行插入:( public void addIndex(int index, int data) ;)
以及
移除全部包含特定值的节点:( public void removeAllKey(int key) ;),**
5.原理剖析
在单链表中,插入一个节点到特定位置的本质是通过遍历链表找到该位置,并修改相应节点的指针来实现新节点与原链表的有效连接。以下是一个图例解析:
假设我们有一个单链表如下所示,其中每个节点包含数据部分和指向下一个节点的指针(next):
1 -> 2 -> 3 -> 4 -> 5
^
|
head
现在我们要在第1个位置(从0开始计数,即在数值为1的节点之前)插入一个新的节点值为node。
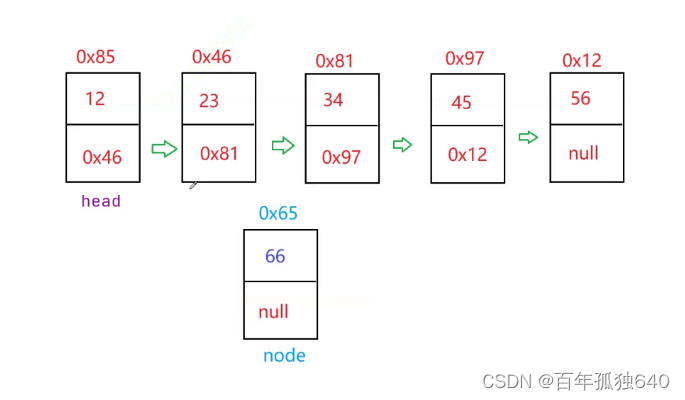
本质上就是交换地址:
- 新的元素node的next==null的改为23的地址0x81(node.next=23.next)
2.将元素23所在的地址0x81改为node的地址0x65
(23.next=node)
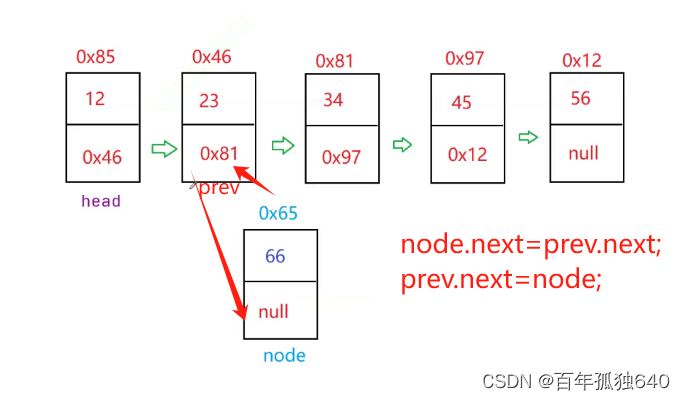
相当于执行以下代码操作:
newNode.next = current.next;
current.next = newNode;
这样,在单链表中的指定位置成功地插入了一个新节点X。
6.单链表的复杂度以及优缺点
单链表的数据结构具有以下的时间复杂度和空间复杂度,以及优缺点:
时间复杂度:
- 查找:在单链表中查找特定元素(线性查找)的时间复杂度是O(n),因为必须从头节点开始逐个遍历直到找到目标或者遍历完所有节点。
- 插入:在已知位置插入一个节点(比如在某个节点之后插入)的时间复杂度是O(1)(找到该位置的时间复杂度为O(n),但修改指针指向的操作是常数时间);而在有序链表中插入并保持有序,需要O(n)的时间复杂度(可能需要移动到正确的位置)。
- 删除:在已知位置删除一个节点的时间复杂度也是O(1)(找到节点后直接修改前后节点的指针),如果只知道待删除元素的值,则查找加删除操作总的时间复杂度是O(n)。
空间复杂度:
- 单链表的空间复杂度是O(n),其中n表示链表中的节点数量。每个节点都包含数据和指向下一个节点的指针。
优点:
- 动态性:可以方便地进行动态内存分配,不需要预先知道数据的大小,适合于频繁进行插入和删除操作的情况。
- 插入和删除效率高:对于非首尾节点,在不考虑查找的情况下,插入和删除操作仅需修改相邻节点的指针即可完成,时间复杂度较低。
- 空间利用率:由于链表节点可以存储在内存中任何地方,不需要连续空间,因此当内存碎片较大时,链表能更有效地利用内存资源。
缺点:
- 查找效率低:链表不适合需要快速随机访问的场景,无法像数组或顺序表那样通过下标直接访问。
- 需要额外存储空间:除了数据本身外,还需要额外存储指针信息,导致整体空间开销大于相同数据量的静态数组。
- 无序链表插入与删除虽快,但维持有序状态时,插入与删除的成本会显著增加。
- 不支持高效的随机访问和范围查询,对缓存不友好,连续内存访问性能差。
应用场景:
单链表常用于实现各种高级数据结构(如循环链表、双向链表、LRU缓存等)以及解决实际问题,如文件系统目录结构、数据库索引结构等。














 1198
1198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









