








目录
🌟我的其他文章也讲解的比较有趣😁,如果喜欢博主的讲解方式,可以多多支持一下,感谢🤗!
其他优质专栏: 【🎇SpringBoot】【🎉多线程】【🎨Redis】【✨设计模式专栏(已完结)】…等
如果喜欢作者的讲解方式,可以点赞收藏加关注,你的支持就是我的动力
✨更多文章请看个人主页: 码熔burning
前言
各位在代码江湖行走的侠客们,大家好!我是你们的老朋友,人称“数据库段子手”的BUG终结者。今天,咱们不聊风花雪月,也不谈代码鄙视链,咱们来盘一盘数据库里那个最重要、最核心,也时常让人头大的概念——事务(Transaction) 以及它那如雷贯耳的 ACID 四大护法!
你可能听说过它,可能在面试时背过它,甚至可能在不经意间用过它。但你真的“吃透”它了吗?知道它为什么这么设计吗?知道它背后有多少“爱恨情仇”和“江湖规矩”吗?
别急,今天这篇文章,我就用咱最熟悉的大白话,配上一点点“神经质”的幽默感,带你从一个全新的角度,把“事务”这哥们儿从里到外扒个精光!准备好了吗?发车啦!呜呜呜~ 🚂
序章:当数据库开始“分身乏术”——并发的烦恼 🤔
想象一下,你开了一家生意火爆的网店,卖的是宇宙限量版“程序员生发秘籍”。在某个夜黑风高的晚上,秒杀活动开始!
-
场景一:库存惊魂
- 小明同学和小红同学同时看中了最后一件“生发秘籍”。
- 系统A检查库存:还有1件!小明下单,系统A扣减库存,变成0。
- 几乎在同一瞬间,系统B(可能是另一个服务器节点)也检查库存:糟糕,网络延迟了一下,它读到的还是1件!小红也下单,系统B也想扣减库存。
- 问题:如果处理不好,是不是就可能卖超了?或者小明付了钱,结果没货了?小红也可能遇到同样的问题。这不就乱套了嘛!
-
场景二:转账疑云
- 你,作为网店老板,赚了钱要给供应商“码农快乐水”公司转账1000大洋。
- 你的操作:
- 从你的账户扣除1000。
- 给“码农快乐水”公司账户增加1000。
- 意外:如果在第一步成功后,服务器突然断电了、重启了、被外星人劫持了……总之,第二步没完成。
- 结果:你的钱少了,供应商的钱没多。这1000大洋人间蒸发了?你不得被供应商追杀到天涯海角?😱
这些场景,就是数据库世界里天天都在发生的“并发操作”和“意外情况”。我们的数据库,就像一个无比繁忙的银行柜台,同时有N多个客户(应用程序的请求)在办理业务(增删改查数据)。如果管理不善,就会出现数据错乱、账目不清等各种“灵异事件”。
为了解决这些问题,让我们的数据在并发操作和意外故障面前依然保持“从容淡定”、“井井有条”,数据库的大神们就引入了“事务”这个超级英雄!
第一章:事务四兄弟的“成团之路”——揭秘ACID 🦸♂️🦸♀️🦸♂️🦸♀️
事务,简单粗暴地说,就是一组数据库操作,这些操作要么全部成功执行,要么全部失败回滚,是一个不可分割的工作单元。 它的目标非常单纯:保证数据的最终一致性!
为了让事务这位超级英雄能够顺利完成使命,它配备了四大“贴身保镖”,也就是传说中的 ACID 属性。这四个字母可不是随便凑的,它们是数据库世界里的“四项基本原则”!
A - 原子性 (Atomicity): “要么团灭,要么一起飞!” 🚀
-
官方解释:事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用。
-
段子手解读:想象一个特种小队执行任务,要么所有队员都成功渗透并完成爆破,凯旋而归;要么行动失败,所有队员安全撤回,就当没去过。绝不能出现“一部分队员成功了,一部分队员牺牲了,任务搞砸了还留下一堆烂摊子”的情况。
-
对应场景:就是上面那个转账的例子。从你账户扣钱和给供应商账户加钱,这两个动作必须捆绑在一起。成功,都成功;失败,都回到最初的状态,你的钱一分不少,供应商的钱也一分没多。
-
幕后英雄:MySQL 主要通过 Undo Log(撤销日志) 来实现原子性。Undo Log 记录了数据修改前的“老样子”。如果事务执行过程中发生错误,或者你手动
ROLLBACK,MySQL 就会利用 Undo Log 把数据恢复到事务开始前的状态,就像用“Ctrl+Z”撤销操作一样神奇。START TRANSACTION; -- 开启一个神秘的仪式,接下来的操作将受到“原子性”的祝福 -- 假设账户表 accounts (user_id, balance) -- 李雷给韩梅梅转账100元 UPDATE accounts SET balance = balance - 100 WHERE user_id = 'LiLei'; -- 李雷账户减钱 -- 앗! Σ( ° △ °|||)︴突然数据库连接断了!或者发生了其他错误! -- 如果上面一步执行了,但下面这步没机会执行或者执行失败: -- UPDATE accounts SET balance = balance + 100 WHERE user_id = 'HanMeimei'; -- 怎么办?原子性大神出场! -- 由于事务没有正常完成 (COMMIT),MySQL 会借助 Undo Log 进行回滚 -- 结果:李雷的钱会退回到他账上,仿佛什么都没发生过。 COMMIT; -- 只有当所有操作都无误,并且执行了 COMMIT,更改才会被永久保存。 -- 或者 ROLLBACK; -- 如果中间想反悔,或者出了岔子,执行 ROLLBACK,一切回到原点。
C - 一致性 (Consistency): “账本必须平!” ⚖️
-
官方解释:事务执行前后,数据库都必须处于一致的状态。所有事务对一个数据的读取结果都是相同的 (当然,这是在特定隔离级别下的理想情况,后面会细说)。
-
段子手解读:这哥们是ACID的最终目标,也是最核心的追求。它更像是一个“业务规则”的总和。比如银行转账,无论怎么转,整个银行系统的总金额不能变(除非有人存钱或取钱)。一个账户的钱少了,另一个账户的钱必然要增加同样多。不能平白无故多出一笔钱,也不能莫名其妙少一笔钱。
-
对应场景:
- 转账后,A账户减少的金额 = B账户增加的金额。
- 数据库的约束(如主键唯一、外键约束、数据类型约束、NOT NULL约束)在事务结束后必须依然满足。
- 你定义的业务规则(比如“商品库存不能为负数”,“用户等级必须在1-10之间”)在事务完成后也必须得到遵守。
-
幕后英雄:一致性不是由单一技术实现的,它是原子性、隔离性、持久性三大特性共同保障的结果,再加上应用程序层面业务逻辑的正确性。 如果你的业务代码本身就有Bug(比如转账只扣钱不加钱的逻辑),那神仙也救不了一致性!所以,程序员的严谨也是一致性的重要一环。
小剧场:一致性的呐喊
一致性 © 对着 原子性 (A)、隔离性 (I)、持久性 (D) 咆哮:“你们仨都给我打起精神来!我能不能C位出道,全靠你们了!还有那个写代码的程序员,你可别给我整幺蛾子!”
A, I, D 瑟瑟发抖:“明白,C哥!”
程序员挠头:“我尽力…尽力…”
I - 隔离性 (Isolation): “我的地盘我做主,闲人免入!” 🚧
-
官方解释:并发执行的各个事务之间不能互相干扰。当多个事务并发访问数据时,一个事务不应该看到其他事务的中间状态(未提交的数据)。
-
段子手解读:想象一下,你在一个没有隔间的公共厕所里…呃,这个比喻不太好。换一个!你在自己的办公室里专心致志地写一份绝密报告,期间不希望任何人闯进来偷看你的草稿,或者在你写到一半的时候就拿去汇报。每个事务都应该感觉自己是“包场”在操作数据库,看不到其他事务“捣乱”的中间过程。
-
对应场景:
- 事务A正在修改用户X的余额,但还没提交。事务B此时去读取用户X的余额,它不应该读到事务A修改了一半的那个“脏”数据。
- 事务A在统计用户总数,统计过程中,事务B又插入了几个新用户并提交了。事务A的两次统计结果可能会不一样(这涉及到隔离级别,后面详谈)。
-
幕后英雄:隔离性的实现是最复杂的,也是数据库厂商们大展拳脚的地方。MySQL 主要通过以下机制来实现隔离性:
- 锁机制 (Locking):就像给数据行、数据表加上“请勿打扰”的牌子。想操作?先看牌子,按规矩来。分为共享锁(大家都能读)、排他锁(我用的时候谁也别碰)等。
- MVCC (Multi-Version Concurrency Control - 多版本并发控制):这是个超级酷的技术!简单说,就是给每一行数据都保留了多个“版本”。当一个事务要读取数据时,数据库会根据事务的启动时间和隔离级别,巧妙地给它看一个“合适的历史版本”,这样就能避免直接看到其他未提交事务修改的数据,也减少了锁的争用。InnoDB引擎的REPEATABLE READ(可重复读)隔离级别就高度依赖MVCC。
隔离性是并发事务问题的“重灾区”,也是我们接下来要重点讨论的内容。
D - 持久性 (Durability): “刻在石头上的誓言!” 😉
-
官方解释:一旦事务成功提交,它对数据库的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
-
段子手解读:你跟女神表白,女神点头同意并和你拉了勾。这个“约定”(事务提交)一旦达成,就不能反悔了!哪怕天打雷劈(服务器宕机),火山爆发(硬盘损坏,但有备份和恢复机制),等一切恢复正常后,你和女神的关系依然是“情侣”(数据依然是你提交后的状态)。
-
对应场景:
- 你成功支付了一笔订单,
COMMIT了。那么这笔支付记录就板上钉钉了,即使数据库服务器下一秒就断电重启,重启后这笔支付记录依然存在,商家依然能看到你付了钱。
- 你成功支付了一笔订单,
-
幕后英雄:MySQL 主要通过 Redo Log(重做日志) 来实现持久性。Redo Log 记录了数据修改后的“新样子”。当事务提交时,MySQL 会先把 Redo Log 写入磁盘(这个过程很快,因为是顺序写),并标记事务已提交。然后才会在后台慢慢地把实际的数据页(Data Page)也刷到磁盘上。
- WAL (Write-Ahead Logging):先写日志,再写数据。这就是大名鼎鼎的预写式日志。
- 好处:如果系统在数据页完全刷盘前崩溃了,没关系!重启后,MySQL 会检查 Redo Log,把那些已经提交了但数据还没完全落盘的事务重新做一遍(Re-do),确保数据恢复到最后一次成功提交的状态。
Undo Log vs Redo Log 小科普
- Undo Log(撤销日志):用于回滚事务(实现原子性),也用于MVCC(提供旧版本数据)。记录的是“如何撤销回原来的样子”。
- Redo Log(重做日志):用于在系统崩溃后恢复数据(实现持久性)。记录的是“如何前进到新的样子”。
它俩就像一对好基友,共同守护着MySQL数据的安全可靠。
好了,ACID四兄弟的“光辉事迹”我们先介绍到这里。是不是感觉它们各怀绝技,又配合默契?正是有了它们,我们的数据库才能在纷繁复杂的世界里,保持那份难得的“确定性”。
第二章:并发事务的“灵异事件簿”——脏写、脏读、不可重复读、幻读 👻
虽然我们有了事务和ACID,但江湖依然险恶。当多个事务“同时”对数据库进行操作时,如果隔离措施不到位,就会引发一系列“灵异事件”。这些事件的名字听起来就神神秘秘的:脏写、脏读、不可重复读、幻读。
这些问题的本质,都是数据库在多事务并发运行时,对数据读一致性的破坏。 让我们一个个来解剖这些“小妖怪”。
为了方便演示,我们先准备一张简单的 account 表,并插入一些初始数据:
CREATE TABLE `account` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`balance` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `account` (`name`, `balance`) VALUES ('lilei', 450);
INSERT INTO `account` (`name`, `balance`) VALUES ('hanmei', 16000);
INSERT INTO `account` (`name`, `balance`) VALUES ('lucy', 2400);
1. 更新丢失 (Lost Update) 或 脏写 (Dirty Write) 😱
- 案情描述:当两个或多个事务选择同一行数据进行修改,后提交(或后写入)的事务覆盖了先提交(或先写入但未提交)的事务的更新,导致前一个事务的修改如同泥牛入海,消失不见了。这就像你辛辛苦辛写了半天代码,结果被同事没拉最新代码直接
git push -f强制覆盖了,那叫一个惨! - 发生条件:通常在非常低的隔离级别下,或者某些数据库实现允许未提交的事务写入覆盖。幸运的是,所有标准的事务隔离级别都解决了“脏写”问题。 因为对数据的修改通常会上排他锁,一个事务没释放锁(没提交或回滚),另一个事务是改不了的。
- 举个栗子(纯理论,现代数据库一般不会这么“脏”):
- 事务A:读取lilei的余额是450。想给lilei充值100,计算后余额应为550。
- 事务B:也读取lilei的余额是450。想扣款50,计算后余额应为400。
- 事务A:将lilei的余额更新为550。(但还未提交)
- 事务B:在事务A提交前,强行将lilei的余额更新为400,并提交了。
- 事务A:随后也提交了。
- 结果:lilei的余额最终是400。事务A那100块的充值操作就丢失了!
- 段子手吐槽:“我明明改了!我的修改呢?被数据库吃了吗?还是被外星人劫走了?!” 👽
- 如何避免:现代数据库通过锁机制(写操作需要排他锁,事务未结束锁不释放)来避免脏写。一个事务在修改数据时会持有该数据的排他锁,直到事务提交或回滚,其他想修改该数据的事务必须等待。
2. 脏读 (Dirty Reads) 🙈
- 案情描述:事务A读取到了事务B已经修改但尚未提交的数据。如果事务B最终回滚了,那么事务A读取到的数据就是“脏”的、临时的、无效的、根本没真正存在过的数据。
- 发生条件:通常发生在“读未提交”(Read Uncommitted)这种最低的隔离级别下。
- 举个栗子:
-
时间点1 (客户端A - 事务A):设置隔离级别为
READ UNCOMMITTED。查询lilei余额。-- 客户端A SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; START TRANSACTION; SELECT * FROM account WHERE name = 'lilei'; -- 得到 balance = 450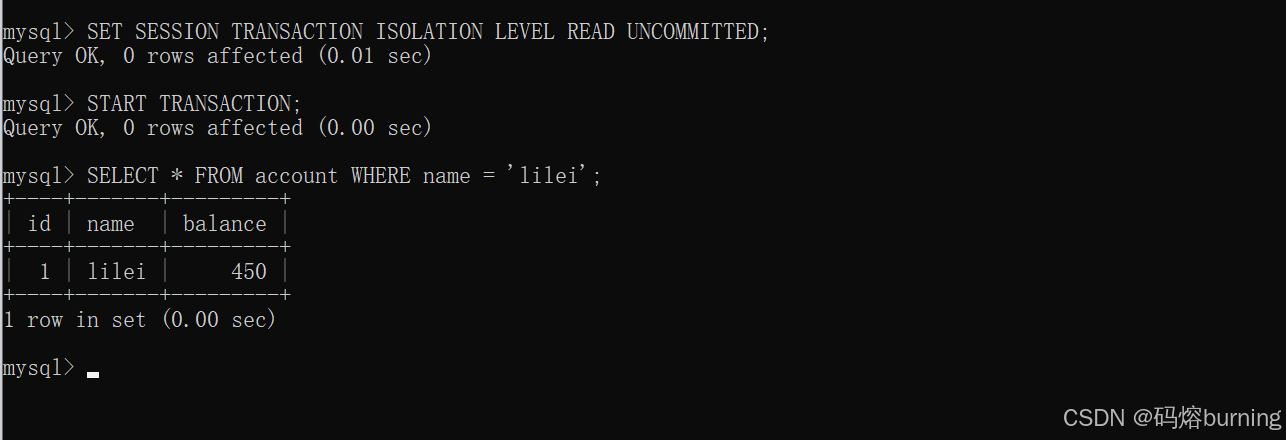
-
时间点2 (客户端B - 事务B):开启事务,修改lilei余额为100(比如老板发错工资了,先扣掉),但先不提交。
-- 客户端B START TRANSACTION; UPDATE account SET balance = 100 WHERE name = 'lilei'; -- lilei余额变为100,但事务B未提交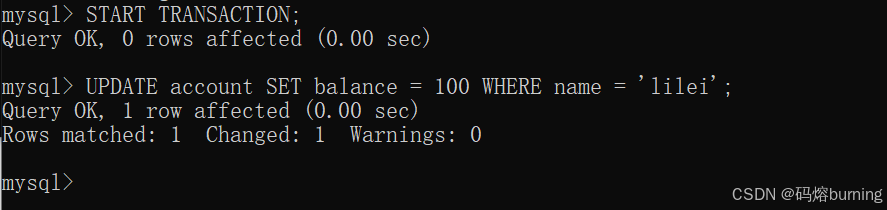
-
时间点3 (客户端A - 事务A):再次查询lilei余额。
-- 客户端A SELECT * FROM account WHERE name = 'lilei'; -- 哇!查到了 balance = 100!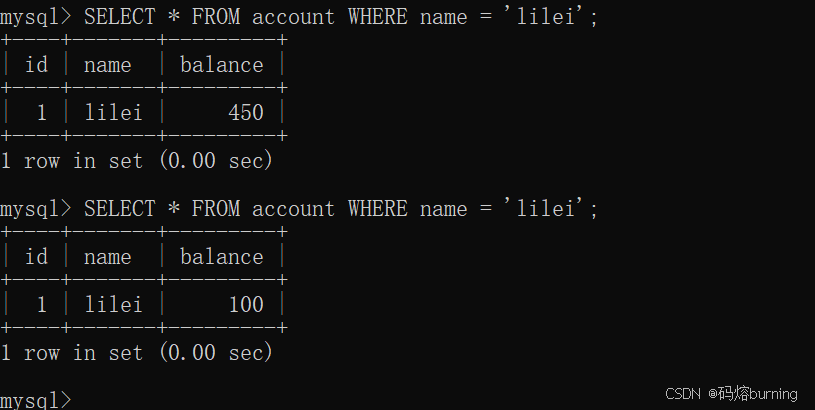
事务A此时以为lilei的余额真的变成100了,可能基于这个数据做了某些决策(比如发短信通知lilei:“您的余额已不足,请及时充值!”)。
-
时间点4 (客户端B - 事务B):老板发现搞错了,赶紧回滚事务B。
-- 客户端B ROLLBACK; -- lilei的余额恢复为450 -
结果:事务A在时间点3读取到的100就是个“脏数据”。lilei收到短信可能一脸懵逼:“我钱呢?!” 实际余额还是450。
-
- 段子手吐槽:“我靠!我刚看到那小子有钱了,想跟他借点,结果他说那是幻觉?逗我玩呢!” 😠
- 如何避免:提高隔离级别,至少到“读已提交”(Read Committed)。
3. 不可重复读 (Non-Repeatable Reads) 🔁❓
- 案情描述:事务A在同一个事务内部,对同一行数据执行了多次相同的查询,但在这期间,事务B修改了这行数据并已提交,导致事务A前后两次读到的数据不一致。
- 发生条件:通常发生在“读已提交”(Read Committed)隔离级别下。
- 核心:强调的是同一行数据的内容发生了变化。
- 举个栗子:
-
时间点1 (客户端A - 事务A):设置隔离级别为
READ COMMITTED。查询lilei余额。-- 客户端A SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; START TRANSACTION; SELECT balance FROM account WHERE name = 'lilei'; -- 第一次读,balance = 450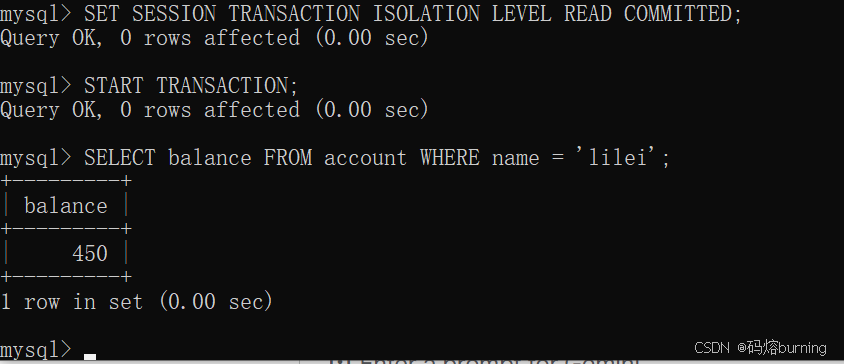
-
时间点2 (客户端B - 事务B):开启事务,修改lilei余额为800(比如发奖金了),并提交事务。
-- 客户端B START TRANSACTION; UPDATE account SET balance = 800 WHERE name = 'lilei'; COMMIT; -- 事务B提交,lilei余额正式变为800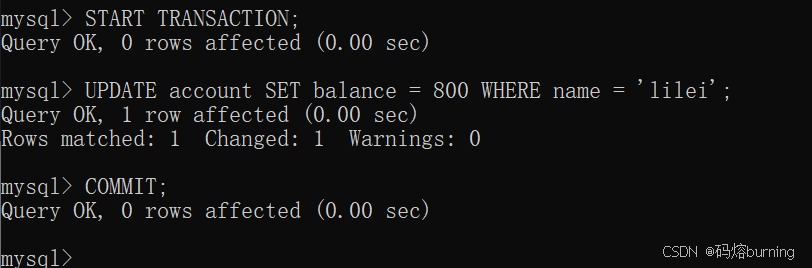
-
时间点3 (客户端A - 事务A):事务A还没结束,它又执行了和时间点1完全相同的查询。
-- 客户端A SELECT balance FROM account WHERE name = 'lilei'; -- 第二次读,balance = 800!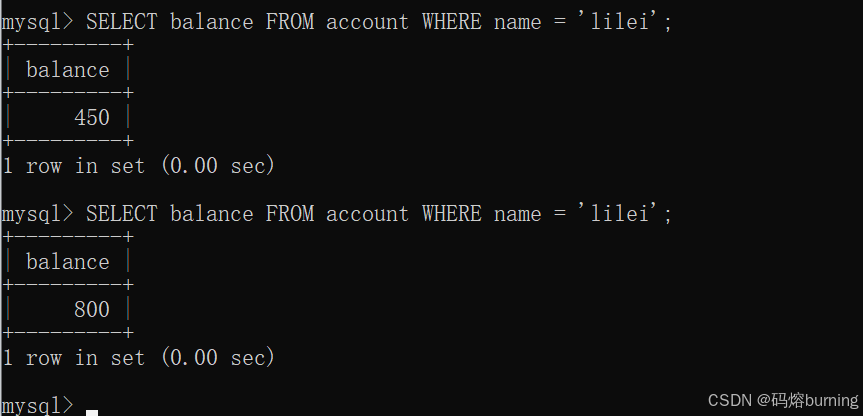
-
结果:事务A凌乱了。同一个事务里,同一个查询,第一次是450,第二次是800。这就像你反复问一个人“你吃饭了吗?”,他第一次说“没吃”,过了一会儿你再问,他说“吃了”。你可能会想:“我穿越了?还是他精神分裂了?”
-
- 段子手吐槽:“这数据怎么跟变色龙似的,一会儿一个样?还能不能愉快地玩耍了!” 🦎
- 如何避免:提高隔离级别到“可重复读”(Repeatable Read)。
4. 幻读 (Phantom Reads) 🕴️
- 案情描述:事务A按照某个条件范围查询数据,事务B在这个范围内插入或删除了新的数据行并已提交。当事务A再次以相同条件查询时,发现多了一些“幽灵般”的行,或者少了一些原本存在的行,就像产生了幻觉。
- 发生条件:通常发生在“可重复读”(Repeatable Read)隔离级别下(特指标准的RR,MySQL的RR通过MVCC和间隙锁在一定程度上解决了幻读,但特定情况下仍可能出现,后面细聊)。
- 核心:强调的是符合某个范围条件的数据行数量发生了变化,看到了“多出来的行”或“消失的行”。
- 举个栗子:
-
时间点1 (客户端A - 事务A):设置隔离级别为
REPEATABLE READ(我们先假设这是标准的RR,不考虑MySQL的额外优化)。查询所有余额大于500的账户数量。-- 客户端A SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ; START TRANSACTION; SELECT COUNT(*) FROM account WHERE balance > 500; -- 查到3条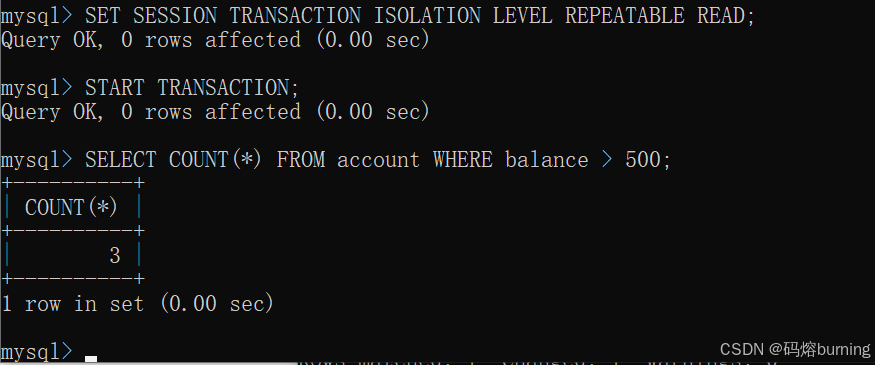
-
时间点2 (客户端B - 事务B):开启事务,插入一个新账户 “boss”,余额为100000,并提交事务。
-- 客户端B START TRANSACTION; INSERT INTO account (name, balance) VALUES ('boss', 100000); COMMIT; -- 事务B提交,新大款boss出现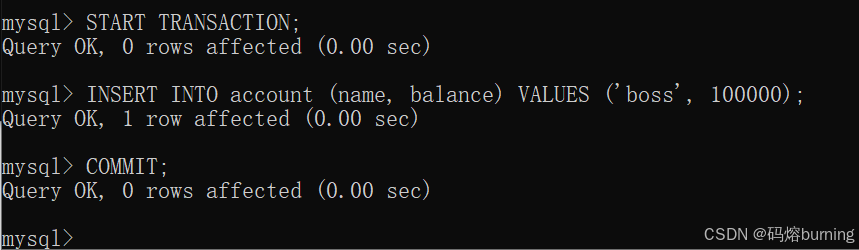
-
时间点3 (客户端A - 事务A):事务A还没结束,它又执行了和时间点1完全相同的查询。
-- 客户端A SELECT COUNT(*) FROM account WHERE balance > 500; -- 在标准的REPEATABLE READ下,这里可能就会查到4条! -- 咦,我第一次不是查到3条吗?怎么多了一条“幽灵”boss? -
再来个“幻影消失”的例子:
- 事务A第一次
SELECT * FROM account WHERE balance > 2000;查到了hanmei(16000)和lucy(2400)。 - 事务B把lucy的余额改成1000并提交了。
- 事务A第二次
SELECT * FROM account WHERE balance > 2000;可能就只查到hanmei了,lucy“消失”了。
- 事务A第一次
-
- 段子手吐槽:“我勒个去!刚才花名册上明明没这个人,怎么一转眼就冒出来了?难道我眼花了?还是公司闹鬼了?” 👻
- 不可重复读 vs 幻读:兄弟俩的辨析
- 不可重复读:重点在于“修改”。你反复读同一条数据,它的内容变了。像是一个人的衣服换了颜色。
- 幻读:重点在于“新增”或“删除”。你按条件查询一个范围,结果发现这个范围里的“人数”变了。像是一个房间里的人数变了。
- 更简单粗暴地区分:不可重复读是update操作干扰,幻读主要是insert或delete操作干扰。
- 如何避免:
- 提高隔离级别到“可串行化”(Serializable)。
- 在MySQL的Repeatable Read级别下,InnoDB引擎使用MVCC和一种叫做Next-Key Locks(临键锁,是行锁和间隙锁的组合) 的机制来防止“快照读”情况下的幻读,但在某些“当前读”(如
SELECT ... FOR UPDATE,UPDATE,DELETE)的场景下,如果处理不当,幻读仍有可能发生。我们稍后在隔离级别案例中会看到MySQL是如何处理的。
这些“灵异事件”是不是让你头皮发麻?别怕,数据库大神们早就为我们准备了“照妖镜”和“降妖伏魔杵”——那就是事务隔离级别!
第三章:数据库的“社交距离”——事务隔离级别详解 😷
为了解决上面提到的各种“并发灵异事件”,数据库标准定义了四种事务隔离级别。这些级别就像是给事务设定的不同“社交距离”,级别越高,隔离性越强,数据一致性越好,但并发性能可能会有所牺牲(因为限制更多了)。
| 隔离级别 | 脏读 (Dirty Read) | 不可重复读 (NonRepeatable Read) | 幻读 (Phantom Read) | 并发性能 |
|---|---|---|---|---|
| 读未提交 (Read Uncommitted) | 可能 | 可能 | 可能 | 最高 |
| 读已提交 (Read Committed) | 不可能 | 可能 | 可能 | 较高 |
| 可重复读 (Repeatable Read) | 不可能 | 不可能 | 可能 (理论上) | 中等 |
| 可串行化 (Serializable) | 不可能 | 不可能 | 不可能 | 最低 |
- 并发副作用越小,付出的代价越大:因为事务隔离的本质,就是在一定程度上让事务“串行化”执行,这显然和“并发”是矛盾的。
- 按需选择:不同的应用对一致性和并发性的要求不同。比如,某些应用可能对“不可重复读”和“幻读”不那么敏感,更关心并发访问能力。
在MySQL中:
-
查看当前事务隔离级别:
SHOW VARIABLES LIKE 'transaction_isolation'; -- 或者 (老版本 MySQL) -- SHOW VARIABLES LIKE 'tx_isolation';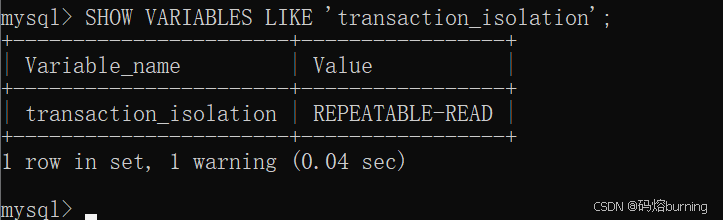
-
设置事务隔离级别:
SET GLOBAL TRANSACTION ISOLATION LEVEL REPEATABLE READ; -- 设置全局默认 SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE; -- 设置当前会话的隔离级别 -- SET TRANSACTION ISOLATION LEVEL READ COMMITTED; -- 设置下一个未开始事务的隔离级别注意:
tx_isolation在MySQL 8.0中已被transaction_isolation取代。 -
MySQL InnoDB 引擎的默认隔离级别是:可重复读 (Repeatable Read)。
-
Spring框架与隔离级别:如果你在用Spring开发程序,当你不显式设置事务的隔离级别时,Spring会默认使用数据库本身设置的隔离级别(比如MySQL的RR)。如果你在Spring的
@Transactional注解中指定了隔离级别,则会覆盖数据库的默认设置。
接下来,让我们戴上“显微镜”,逐个解剖这四种隔离级别,看看它们是如何工作的,以及它们各自的“脾气秉性”。
1. 读未提交 (Read Uncommitted): “八卦传播中心” 📢
-
隔离效果:最低的隔离级别。一个事务可以读取到其他事务尚未提交的修改。
-
优点:并发性能极高,因为读取基本不加锁(或者是非常宽松的锁)。
-
缺点:脏读、不可重复读、幻读都可能发生。数据一致性最差。
-
幽默比喻:就像一个毫无保密意识的办公室,张三正在写一份草稿(未提交的事务),李四路过就能直接拿来看(脏读)。张三改了N遍,李四每次看都不一样(不可重复读)。办公室里突然来了个新人王五,李四马上也知道了(幻读)。
-
使用场景:对数据一致性要求极低,但对并发性要求极高的场景。比如,某些实时统计在线人数(允许有少量误差)的功能。但说实话,在严肃的生产环境中,这个级别用得非常非常少。
-
案例分析
(1)客户端A设置隔离级别为
READ UNCOMMITTED,开启事务,查询lilei初始余额。-- 客户端A SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; START TRANSACTION; SELECT * FROM account WHERE name = 'lilei'; -- 初始 balance = 450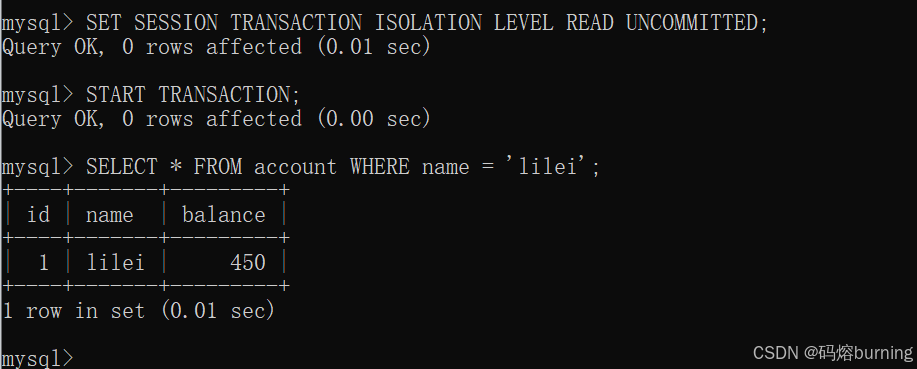
(2)客户端B开启事务,将lilei余额改为400(原为450,这里lilei余额400,然后B将其改为350。为保持一致,假设lilei初始为400,B将其改为350。但前面我们插入的是450。这里我们继续按逻辑走,假设lilei当前是400,事务B将其改为350。)我们还是按我们插入的初始数据450来,事务B将其改为350。
-- 客户端B START TRANSACTION; UPDATE account SET balance = 350 WHERE name = 'lilei'; -- lilei余额改为350,未提交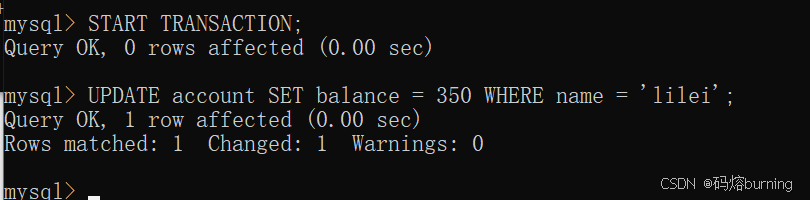
(3)客户端A再次查询lilei余额。由于是“读未提交”,A能看到B未提交的修改。
-- 客户端A SELECT * FROM account WHERE name = 'lilei'; -- 查到 balance = 350 (脏读发生)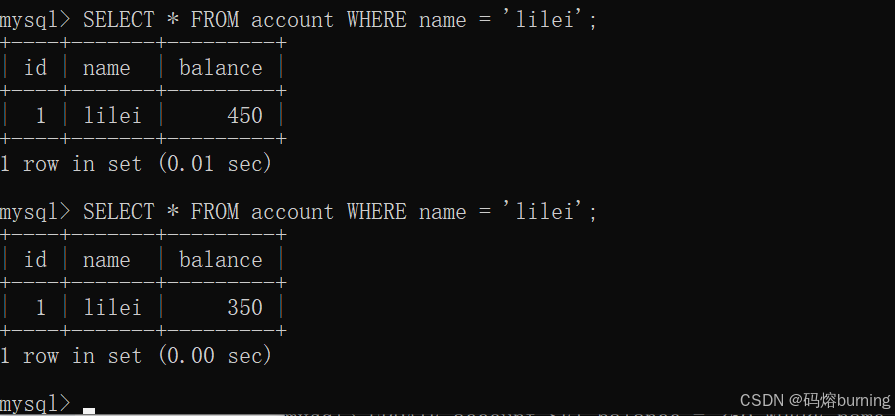
(4)客户端B由于某种原因,回滚了事务。
-- 客户端B ROLLBACK; -- lilei余额恢复为450(5)客户端A此时如果基于之前读到的350去做操作,比如
UPDATE account SET balance = balance - 50 WHERE id = 1(假设lilei的id是1)。
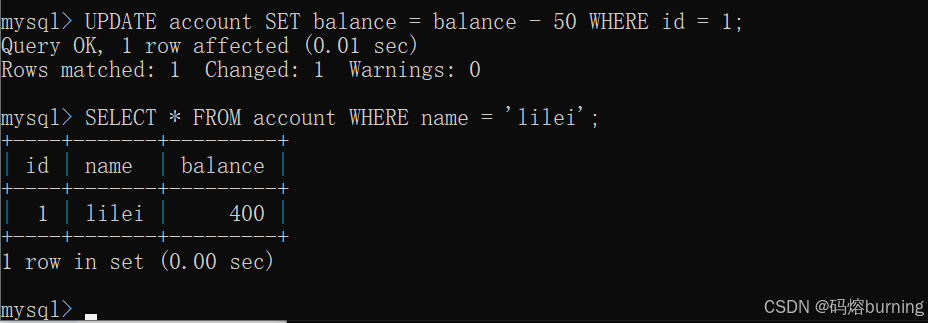
lilei的balance没有变成350,居然是400,是不是很奇怪,数据不一致啊,如果你这么想就太天真了,在应用程序中,我们会用400-50=350,并不知道其他会话回滚了…
这里有点绕,我们捋一下:- A在(3)读到的是350(脏数据)。
- B在(4)回滚,lilei实际余额变回450。
- A在(5)执行
balance = balance - 50。此时A事务内的balance是基于它自己最后一次有效读取(或者说,如果它在更新前再select一次,是基于select的结果)。- 如果A的更新是基于它在(3)读到的脏数据350来计算的(即程序逻辑是
new_balance = 350 - 50 = 300)然后去UPDATE ... SET balance = 300,那么结果就是300。 - 如果A的更新是
UPDATE account SET balance = balance - 50 WHERE id = 1这种相对更新,MySQL会读取当前数据库中lilei的真实余额(在B回滚后是450),然后执行450 - 50 = 400。所以结果是400。
这确实暴露了数据不一致的问题:事务A基于一个它认为是350(但实际已变回450)的认知去操作,如果应用程序在更新前没有重新读取最新值,而是依赖了之前脏读到的值进行计算再更新,那就会产生错误。
- 如果A的更新是基于它在(3)读到的脏数据350来计算的(即程序逻辑是
2. 读已提交 (Read Committed): “官方消息发布渠道” 📰
-
隔离效果:一个事务只能读取到其他事务已经提交的数据。这就避免了“脏读”。
-
优点:相比“读未提交”,数据一致性大大提高。是很多主流数据库(如Oracle, SQL Server, PostgreSQL)的默认隔离级别。
-
缺点:仍然可能发生不可重复读和幻读。
-
幽默比喻:还是那个办公室。张三在写稿,只有等他把稿子正式打印出来、盖章、分发(事务提交)之后,李四才能看到这份稿子的内容。这就避免了李四看到半成品草稿。但是,如果张三一天之内发布了三个不同版本的公告,李四每次去看,看到的版本都可能不一样(不可重复读)。
-
实现机制:通常通过MVCC实现。在每次SELECT时,会生成一个新的ReadView(可以理解为一个数据可见性快照),所以能读到其他已提交事务的最新修改。
-
案例分析
(1)客户端A设置隔离级别为
READ COMMITTED,开启事务,查询所有记录。-- 客户端A SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; START TRANSACTION; SELECT * FROM account; -- 初始数据 lilei:450, hanmei:16000, lucy:2400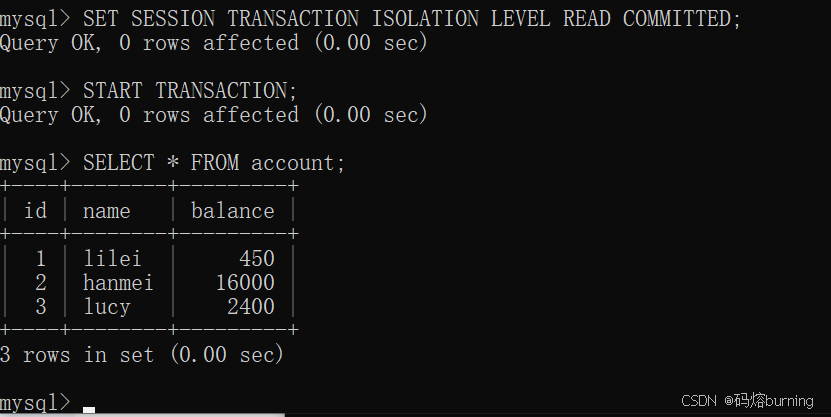
(2)客户端B开启事务,修改lilei余额为350,但不提交。
-- 客户端B START TRANSACTION; UPDATE account SET balance = 350 WHERE name = 'lilei';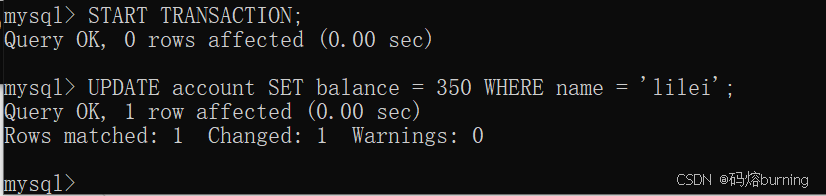
(3)客户端A再次查询,由于B未提交,A读不到B的修改,避免了脏读。
-- 客户端A SELECT * FROM account WHERE name = 'lilei'; -- 仍然是 balance = 450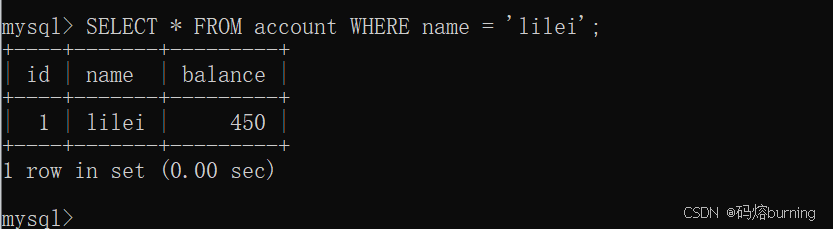
(4)客户端B提交事务。
-- 客户端B COMMIT; -- lilei余额正式变为350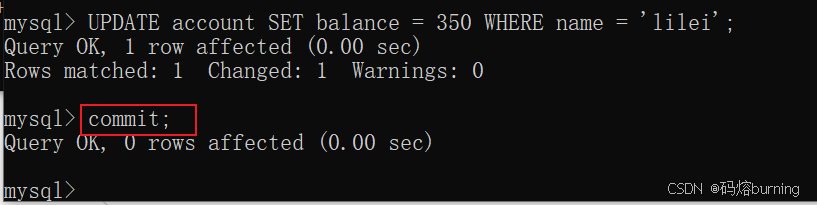
(5)客户端A在同一个事务内再次查询lilei余额。此时B的修改已提交,A能读到最新值。
-- 客户端A SELECT * FROM account WHERE name = 'lilei'; -- 查到 balance = 350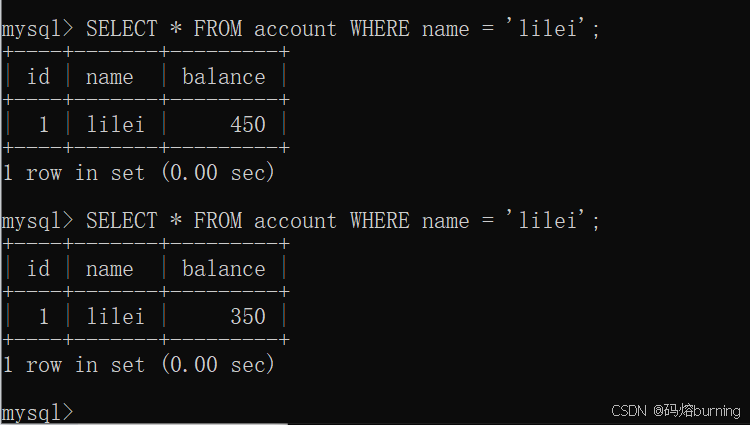
结果:客户端A在事务(1)的第一次查询(假设只查lilei)是450,在事务(5)的第二次查询是350。同一个事务内,两次对同一数据的读取结果不同,不可重复读发生了。
3. 可重复读 (Repeatable Read): “我的世界我做主(第一次查询时定格)” 📸
-
隔离效果:这是MySQL InnoDB引擎的默认隔离级别。它保证在同一个事务中,多次读取同样记录的结果是一致的(即“可重复读”)。能避免脏读和不可重复读。
-
优点:相比“读已提交”,数据一致性更好。
-
缺点:理论上标准的“可重复读”级别仍然可能发生幻读。但MySQL的InnoDB引擎通过MVCC和Next-Key Locks机制,在很大程度上解决了幻读问题(尤其是在快照读时)。
-
幽默比喻:你进办公室写报告,在开始工作前(事务开始后第一次SELECT),你给整个办公室拍了张快照。之后无论外面发生什么(其他事务提交了修改或新增),你查阅资料都只看你手里的这张“快照”。这样,你每次看张三的工位,他的状态都是一样的(可重复读)。
-
实现机制 (InnoDB):
- 快照读 (Snapshot Read):普通的
SELECT语句就是快照读。在事务开始后的第一次执行SELECT时,会创建一个ReadView(快照)。之后该事务内所有的快照读都会沿用这个ReadView,读取的是符合这个ReadView版本的数据,不受其他已提交事务的影响。 - 当前读 (Current Read):特殊的读操作,如
SELECT ... LOCK IN SHARE MODE(共享锁),SELECT ... FOR UPDATE(排他锁), 以及INSERT,UPDATE,DELETE操作。这些操作读取的是数据库中最新的、已提交的版本,并且会对读取的记录加锁。当前读就需要结合锁机制(包括Next-Key Locks)来避免一些并发问题。
- 快照读 (Snapshot Read):普通的
-
核心描述:可重复读隔离级别在事务开启的时候,第一次查询是查的数据库里已提交的最新数据,这时候全数据库会有一个快照(当然数据库并不是真正的生成了一个快照,这个快照机制怎么实现的后面课程会详细讲),在这个事务之后执行的查询操作都是查快照里的数据,别的事务不管怎么修改数据对当前这个事务的查询都没有影响,但是当前事务如果修改了某条数据,那当前事务之后查这条修改的数据就是被修改之后的值,但是查其它数据依然是从快照里查,不受影响。
-
案例分析
(1)客户端A设置隔离级别为
REPEATABLE READ,开启事务,查询所有记录。-- 客户端A SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ; START TRANSACTION; SELECT * FROM account; -- 初始数据 lilei:450, hanmei:16000, lucy:2400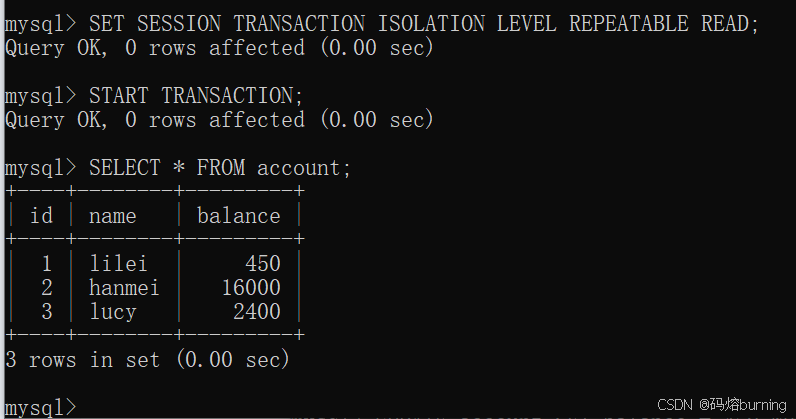
此时,事务A为后续的快照读生成了一个ReadView。
(2)客户端B开启事务,将lilei余额改为350,并提交。
-- 客户端B START TRANSACTION; UPDATE account SET balance = 350 WHERE name = 'lilei'; COMMIT; -- lilei余额正式变为350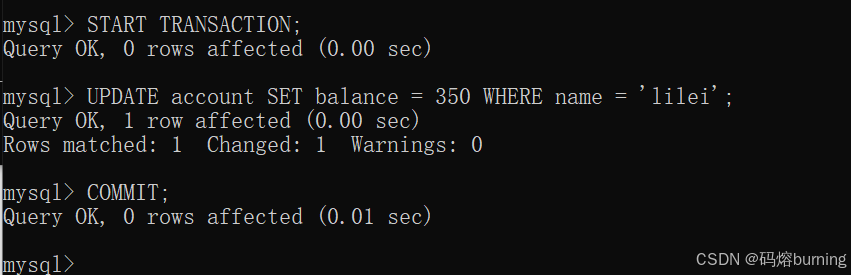
(3)客户端A再次查询所有记录。由于是快照读,它仍然读取的是事务开始时(或第一次SELECT时)的那个版本。
-- 客户端A SELECT * FROM account; -- lilei余额仍然是450。不可重复读没有发生!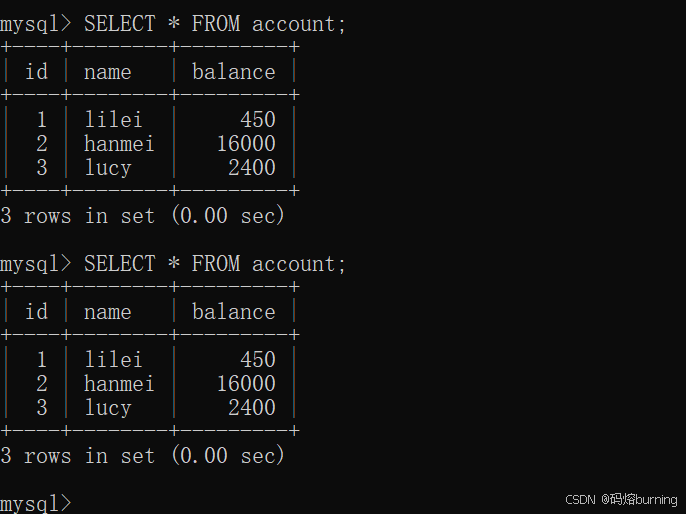
(4)客户端A自己更新lilei的余额,减50。这是一个当前读然后写。
lilei的balance没有变成400-50=350,lilei的balance值用的是步骤2中的350来算的,所以是300。
这里我们要注意:- A的快照里lilei是450。
- B已提交,数据库里lilei最新是350。
- A执行
UPDATE account SET balance = balance - 50 WHERE id = 1(假设lilei id=1)。- 这个UPDATE是当前读,它会读到数据库里最新的已提交值,即350。
- 然后基于350计算
350 - 50 = 300。 - 所以lilei的余额会被更新为300。
-- 客户端A UPDATE account SET balance = balance - 50 WHERE id = 1; -- lilei id=1 SELECT * FROM account WHERE id = 1; -- 查出来 lilei balance = 300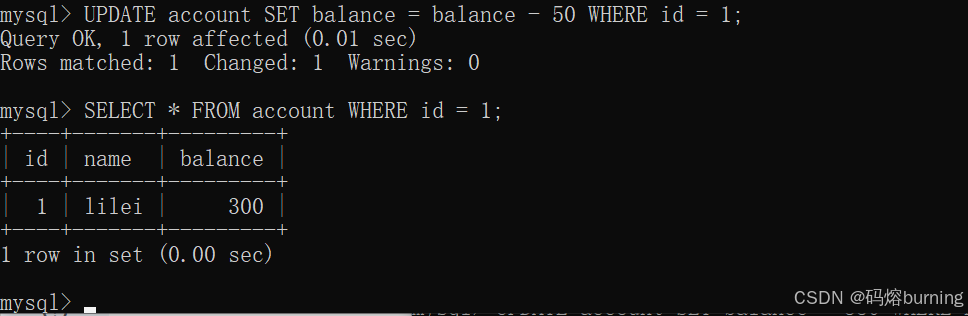
这里有“数据的一致性倒是没有被破坏”,是的,因为更新是基于最新提交的值进行的。
同时,事务A如果此时查询其他未被自己修改的行,比如hanmei,依然会从它的快照里读取旧值。(5)客户端B(可以新开一个B事务,或者就用之前的)插入一条新数据
('xiaogang', 5000)并提交。-- 客户端B START TRANSACTION; INSERT INTO account (name, balance) VALUES ('xiaogang', 5000); COMMIT; -- 新增用户xiaogang并提交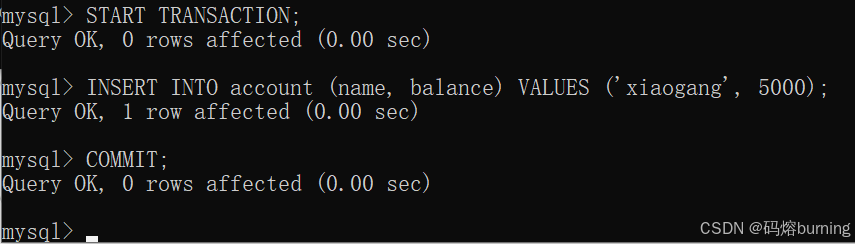
(6)客户端A再次查询所有记录 (快照读)。
-- 客户端A SELECT * FROM account; -- 结果:依然看不到xiaogang这条新数据。对于快照读来说,幻读没有发生。 -- lilei (id=1) 的余额是300 (因为A自己改了) -- hanmei, lucy 还是旧值。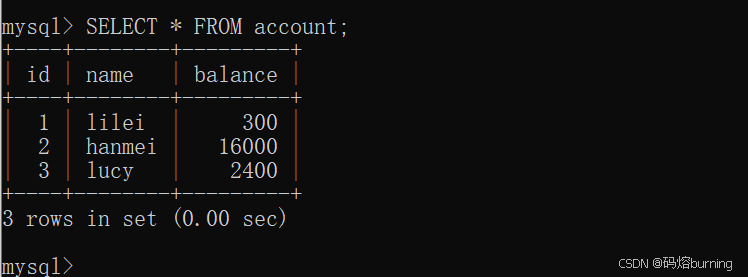
(7)验证幻读 (当前读场景下可能出现的问题,或者说MySQL如何避免它)
案例:在客户端A执行UPDATE account SET balance=888 WHERE id = 4(假设xiaogang的id是4);能更新成功,再次查询能查到客户端B新增的数据。-- 客户端A -- 假设xiaogang插入后 id 为 4 (需要确认) -- 如果我们先 SELECT * FROM account WHERE id = 4; (快照读,应该查不到) -- 现在执行一个当前读的更新: UPDATE account SET balance = 888 WHERE id = 4; -- 如果这条记录存在(B已插入并提交),那么这个UPDATE会成功执行。 -- 它会锁定 id=4 的行(如果存在)。 -- MySQL的RR级别下,由于Next-Key Lock的存在,理论上B在A的事务期间是很难在A关注的范围内插入数据的。 -- 但如果A的查询范围没有完全锁定,或者B的操作恰好在间隙中,幻读问题在“当前读”时才需要特别关注。 -- A先select,没看到id=4的数据。 -- 然后A执行 update id=4,影响行数0。 -- 然后A再select,还是没看到id=4。(这和文字描述的“能更新成功,再次查询能查到”不符) -- -- -- A: UPDATE account SET balance = 888 WHERE id = 4; (0 rows affected) -- A: SELECT * FROM account; (还是看不到 id=4) -- 结果表明,在A的事务中,通过快照读,始终看不到B新插入的id=4。 -- 如果想让A“看到”并更新它,A需要进行“当前读”类型的操作,例如: -- SELECT * FROM account WHERE id = 4 FOR UPDATE; -- 如果这条记录被B提交了,A的这条语句会读到最新的id=4并加锁。 -- 然后A再UPDATE id=4,就能成功。 -- 真正的幻读场景,通常是指: -- 事务A: SELECT COUNT(*) FROM account WHERE balance > 1000; (假设得到 N) -- 事务B: INSERT INTO account (name, balance) VALUES ('new_rich_guy', 200000); COMMIT; -- 事务A: UPDATE account SET name = CONCAT(name, '_vip') WHERE balance > 1000; -- (此时这个UPDATE可能会作用到B新插入的行,导致更新的行数可能 > N) -- 事务A: SELECT COUNT(*) FROM account WHERE balance > 1000; (可能得到 N+1) -> 这就是幻读的体现 -- MySQL的RR + Next-Key Lock 会尝试阻止事务B的插入,或者让事务A的UPDATE感知不到。小结MySQL的RR对幻读的处理:
- 对于快照读(普通SELECT),MVCC保证了可重复读,你看不到其他事务新插入的行,所以不会有幻读。
- 对于当前读(SELECT…FOR UPDATE/SHARE, UPDATE, DELETE),InnoDB会使用Next-Key Locks(行锁+间隙锁)来锁定一个范围,阻止其他事务在这个范围内插入数据,从而避免幻读。
所以,MySQL的RR级别已经很大程度上解决了幻读问题,比标准SQL定义的RR更强。
4. 可串行化 (Serializable): “单行道,请排队!” 🚶♂️🚶♀️🚶
-
隔离效果:最高的隔离级别。它强制事务串行执行,即一个接一个地处理,完全避免了脏读、不可重复读和幻读。
-
优点:数据一致性最强,绝对安全可靠。
-
缺点:并发性能极差,因为事务基本上是排队执行的,吞吐量很低。
-
幽默比喻:办公室只有一个门,而且是旋转门,一次只能进出一个人。所有人想进办公室都得在外面排长队。绝对不会互相干扰,但也急死个人。
-
实现机制:通常会对事务中所有读取到的行都加锁(共享锁或范围锁),如果其他事务想修改这些数据,或者在这个范围内插入数据,都会被阻塞。
-
使用场景:对数据一致性要求极度严格,且可以接受较低并发的场景。比如,银行的某些核心转账业务的特定步骤,或者需要确保数据绝对不会出错的批量跑批任务。大部分应用场景都不会使用这个级别。
-
案例分析
(1)客户端A设置隔离级别为
SERIALIZABLE,开启事务,查询所有记录。-- 客户端A SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE; START TRANSACTION; SELECT * FROM account; -- 查询会给所有读取到的行加上锁 (通常是共享锁)(2)客户端B也设置隔离级别为
SERIALIZABLE,开启事务。- 如果客户端B尝试更新客户端A查询过的行(比如id=1的lilei),它会被阻塞,直到客户端A提交或回滚。
- 如果客户端B尝试更新客户端A未查询过的行(比如id=2的hanmei,假设A只查了lilei),可能更新id为2的记录可以成功。这取决于A的查询范围。如果A是
SELECT *,那么所有行都被锁了。如果A是SELECT * WHERE id = 1,那么只有id=1被锁。 - 如果查询的记录不存在会给这条不存在的记录加上锁(这种是间隙锁,后面会详细讲)。 是的,在Serializable下,范围查询会使用间隙锁或范围锁来防止其他事务在间隙中插入数据,从而避免幻读。
- 如果客户端A执行的是一个范围查询 (比如
SELECT * FROM account WHERE balance > 100),那么该范围内的所有行以及行之间的间隙都会被加锁。此时如果客户端B想在该范围内插入数据,也会被阻塞。
-- 客户端B SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE; START TRANSACTION; -- 尝试更新 lilei (id=1) UPDATE account SET balance = balance - 10 WHERE id = 1; -- 此时会发生阻塞,等待A释放锁结果:Serializable通过严格的加锁机制,确保了事务的串行化执行,从而彻底解决了所有并发问题,但牺牲了并发性。
隔离级别就像一把双刃剑,你需要根据你的业务场景,在数据一致性和并发性能之间做出权衡和选择。没有最好的,只有最合适的!
第四章:MySQL的“秘密武器”——MVCC与锁机制初探 🛡️⚔️
前面我们反复)提到 MVCC 和锁,它们是实现隔离性的两大功臣。尤其是InnoDB引擎,把MVCC玩得炉火纯青。
MVCC (Multi-Version Concurrency Control - 多版本并发控制): “时间旅行者的数据库” ⏳
MVCC 不是某个具体命令,而是一种并发控制的思想和机制。你可以把它想象成:数据库里的每一行数据,都可能同时存在好几个“版本”。
-
核心思想:写操作会创建新版本,读操作去读某个旧的、合适的版本。这样读写就可以不冲突(或者说,读不阻塞写,写也不阻塞读)。
-
InnoDB中的实现要素:
- 隐藏列:每行数据除了你定义的列,InnoDB还会悄悄加上几列:
DB_TRX_ID(6字节): 记录最后一次插入或更新这行数据的事务ID。DB_ROLL_PTR(7字节): 指向这行数据的Undo Log记录。通过这个指针可以找到这行之前的版本。DB_ROW_ID(6字节, 可选): 如果表没有显式主键,InnoDB会用它生成一个隐藏的聚集索引。
- Undo Log 版本链:当一行数据被修改时,旧版本的数据会被存到Undo Log里,并通过
DB_ROLL_PTR串联起来,形成一个“版本链”。最新的数据在链头,最老的数据在链尾。 - ReadView (读视图/快照):这是MVCC实现“一致性非锁定读”的关键。当一个事务开始(在RR级别下是第一次SELECT时,在RC级别下是每次SELECT时)进行快照读时,会生成一个ReadView。这个ReadView包含了:
m_ids: 创建ReadView时,当前活跃的(未提交的)事务ID列表。min_trx_id: 活跃事务列表中的最小事务ID。max_trx_id: 创建ReadView时,预计下一个要分配的事务ID。creator_trx_id: 创建该ReadView的事务ID。
- 可见性判断规则:当一个事务(拿着它的ReadView)去读取某行数据时,它会顺着版本链找,对每个版本的数据,根据其
DB_TRX_ID和ReadView进行比较,判断这个版本对当前事务是否可见:- 如果版本的
DB_TRX_ID等于creator_trx_id:可见(自己改的当然可见)。 - 如果版本的
DB_TRX_ID小于min_trx_id:可见(说明这个版本在当前事务创建ReadView前就已经提交了)。 - 如果版本的
DB_TRX_ID大于等于max_trx_id:不可见(说明这个版本是在当前事务创建ReadView时尚未开始的事务创建的)。 - 如果版本的
DB_TRX_ID在min_trx_id和max_trx_id之间:- 如果它在
m_ids(活跃事务列表)中:不可见(是其他未提交事务改的)。 - 如果它不在
m_ids中:可见(是已提交事务改的,但在min_trx_id之后)。
如果当前版本不可见,就继续顺着DB_ROLL_PTR找上一个版本,直到找到一个可见的版本,或者链结束。
- 如果它在
- 如果版本的
- 隐藏列:每行数据除了你定义的列,InnoDB还会悄悄加上几列:
-
MVCC的好处:
- 读不加锁:大部分读操作(快照读)都不需要加锁,极大地提高了并发性能。
- 解决脏读、不可重复读:通过读取合适的历史版本,自然就避免了这些问题。
- 部分解决幻读(在MySQL的RR级别下):快照读读不到新插入的行。
段子手小剧场:MVCC的自白
MVCC:“大家好,我是MVCC,数据库界的‘版本管理大师’。我让每个事务都能活在自己的‘平行宇宙’里,看到属于自己的那个特定时间点的数据版本。你们尽管并发读写,能让你们互相干扰算我输!哦,当然,对于那些非要‘当前读’的家伙,我还是得请我的老伙计‘锁’出面管管。”
锁 (Locks): “数据库俱乐部的保安天团” 👮♂️👮♀️
虽然MVCC很牛,但它主要解决的是“读-写”冲突问题。对于“写-写”冲突,或者某些需要强一致性的“当前读”场景,还是得靠锁机制。
MySQL InnoDB中的锁,种类繁多,我们挑几个重要的脸熟一下:
-
按锁的粒度分:
- 表锁 (Table Locks):开销小,加锁快;不会出现死锁;但锁定粒度大,发生锁冲突的概率最高,并发度最低。MyISAM引擎主要用表锁。InnoDB也支持表锁,比如
LOCK TABLES ... WRITE;。 - 行锁 (Row Locks):开销大,加锁慢;会出现死锁;但锁定粒度最小,发生锁冲突的概率最低,并发度也最高。InnoDB引擎的拿手好戏,也是它支持高并发的关键。
- 表锁 (Table Locks):开销小,加锁快;不会出现死锁;但锁定粒度大,发生锁冲突的概率最高,并发度最低。MyISAM引擎主要用表锁。InnoDB也支持表锁,比如
-
按共享程度/锁模式分 (主要针对行锁):
- 共享锁 (Shared Lock, S锁):也叫读锁。多个事务可以同时对同一个资源(行)持有S锁,大家都可以读,但任何事务都不能获取该资源的X锁(写锁)进行修改,直到所有S锁释放。
- 用法:
SELECT ... LOCK IN SHARE MODE;
- 用法:
- 排他锁 (Exclusive Lock, X锁):也叫写锁。如果一个事务获取了某资源的X锁,其他事务既不能再获取该资源的S锁,也不能获取X锁,必须等待X锁释放。保证了同一时间只有一个事务能修改数据。
- 用法:
SELECT ... FOR UPDATE;以及INSERT,UPDATE,DELETE操作会自动加上X锁。
- 用法:
- 共享锁 (Shared Lock, S锁):也叫读锁。多个事务可以同时对同一个资源(行)持有S锁,大家都可以读,但任何事务都不能获取该资源的X锁(写锁)进行修改,直到所有S锁释放。
-
InnoDB特有的行锁算法 (处理幻读的关键):
- 记录锁 (Record Lock):单个行记录上的锁,它只锁住索引记录。
- 间隙锁 (Gap Lock):锁定一个范围,但不包括记录本身。它锁定的是索引记录之间的“间隙”。比如锁定
(3, 5)这个开区间。Gap Lock的目的是防止其他事务在这个间隙中插入新的记录,从而防止幻读。Gap Lock之间不冲突,一个事务持有的Gap Lock不会阻止其他事务持有相同间隙的Gap Lock。 - 临键锁 (Next-Key Lock):记录锁 + 间隙锁的组合。它锁定一个左开右闭的区间。比如,一个索引有10, 20, 30三个值,Next-Key Lock可能锁定
(negative infinity, 10],(10, 20],(20, 30],(30, positive infinity]这些区间。这是InnoDB在RR隔离级别下防止幻读的主要手段。当进行范围查询并加锁(当前读)时,InnoDB会使用Next-Key Lock来锁定匹配到的记录以及它们之间的间隙。
举个栗子理解Next-Key Lock如何防幻读:
表
students有id(主键) 和age(有普通索引) 字段。
当前age索引有值: 18, 20, 25。
事务A执行:SELECT * FROM students WHERE age > 19 AND age < 23 FOR UPDATE;
InnoDB可能会使用Next-Key Lock锁定以下范围(依赖于具体实现和数据分布):- 锁定
age=20这条记录 (Record Lock on 20)。 - 锁定
age=20和age=25之间的间隙(20, 25](Gap Lock on the gap after 20, or Next-Key lock on 25 covering (20,25])。 - 可能还会锁定
age=18和age=20之间的间隙(18, 20](Gap Lock on the gap after 18, or Next-Key lock on 20 covering (18,20]),确保age=19这个值也无法插入。
这样,在事务A结束前,其他事务就无法在
age为(19, 23)这个逻辑范围内(实际锁定的物理范围可能更大)插入新的学生记录,事务A再次查询时就不会出现幻读。
锁的世界博大精深,死锁问题也是一个让人头疼的话题。但理解了基本的锁类型和它们的目的,就能更好地分析并发问题了。
第五章:日志双雄——Undo Log 与 Redo Log 的前世今生 📜📜
我们在讲ACID的时候,已经提到了这两个日志界的大佬。它们是MySQL(尤其是InnoDB)能够保证原子性和持久性的基石,也是MVCC的重要参与者。
Undo Log (撤销日志): “后悔药,保证原子性与MVCC的关键” ⏪
-
干啥的?
- 实现事务回滚 (原子性):当事务需要回滚时,InnoDB会利用Undo Log中的信息,执行与原操作相反的操作,将数据恢复到事务开始前的状态。比如你
INSERT了一条记录,Undo Log就会记录一条对应的DELETE信息(逻辑上的)。你UPDATE了一条记录,Undo Log就会记录如何把它UPDATE回去。 - 实现MVCC (隔离性):对于快照读,如果当前数据版本对事务不可见,InnoDB会通过
DB_ROLL_PTR顺着Undo Log版本链找到上一个合适的旧版本数据提供给事务读取。
- 实现事务回滚 (原子性):当事务需要回滚时,InnoDB会利用Undo Log中的信息,执行与原操作相反的操作,将数据恢复到事务开始前的状态。比如你
-
长啥样? Undo Log是逻辑日志,它记录的是“如何撤销”或者“数据的旧版本长什么样”。
-
存在哪? Undo Log存储在共享表空间或者独立的Undo表空间中(取决于配置)。
-
啥时候删? 当一个Undo Log记录不再被任何事务所需要时(即没有更老的事务或ReadView需要访问这个旧版本,并且产生这个Undo Log的事务已经提交或回滚),它才可能被清理线程回收。
Undo Log小笑话
Undo Log:“我就是数据库界的‘时光倒流机’+‘平行宇宙传送门’!想反悔?找我!想看过去?也找我!就是有点占地方,而且清理起来得看时机,别催我,我忙着呢!”
Redo Log (重做日志): “保险柜,保证持久性,掉电也不怕” 🔏
-
干啥的?
- 保证事务持久性:当事务提交后,即使数据还没完全写入磁盘数据文件,只要Redo Log(包含了这次修改的信息)已经安全落盘,那么在系统崩溃重启后,MySQL就能通过Redo Log把这些已提交事务的修改重新应用到数据文件中,确保数据不会丢失。
-
长啥样? Redo Log是物理日志(大部分情况下是物理到逻辑页的日志),它记录的是某个数据页上做了什么修改。比如“在表空间X的Y号数据页的偏移量Z处写入了数据ABC”。
-
存在哪? Redo Log有自己的日志文件(通常是
ib_logfile0,ib_logfile1等)。 -
WAL (Write-Ahead Logging) 核心思想:
- 先写日志,再写数据页。事务提交时,必须保证对应的Redo Log已经刷到磁盘。而数据页可以稍后再慢慢刷(这个过程叫“脏页刷新”)。
- 为什么这么做?
- 写Redo Log是顺序IO,速度快。
- 写数据页是随机IO,速度慢。
- 如果每次修改都等数据页刷盘,那性能会惨不忍睹。
- 有了Redo Log,即使只写了Redo Log数据页还没写就崩了,重启也能恢复,所以可以大胆地延迟写数据页,提升性能。
-
Redo Log Buffer: 为了进一步提高性能,Redo Log也不是直接写磁盘,而是先写到内存中的Redo Log Buffer,然后根据一定策略(比如每秒刷一次、事务提交时刷、Buffer满了刷)批量刷到磁盘。
Redo Log小剧场
Redo Log(拍着胸脯):“有我在,你们提交的数据就丢不了!宕机?小意思!断电?毛毛雨!只要我这本‘账’还在,重启后照样给你恢复得妥妥的!我就是你们数据持久性的最后一道防线!”
总结一下日志双雄:
- Undo Log:向后看,用于回滚和MVCC,保证“如果出错了,我们能退回去”。
- Redo Log:向前看,用于崩溃恢复,保证“如果成功了,我们能找回来”。
它俩就像哼哈二将,一个负责“撤销”,一个负责“重做”,共同守护着InnoDB数据的完整和安全。
第六章:当事务“发福”——大事务的危害与瘦身指南 🏋️♂️➡️💪
我们常说事务要尽量小而快,但有时候,一不小心就可能搞出个“大事务”(也叫长事务)。这种“胖子事务”对数据库来说,简直是噩梦般的存在!
“大事务”的典型特征:
- 执行时间超长。
- 涉及操作的数据量巨大。
- 长时间持有锁。
大事务的“七宗罪” (危害):
-
并发性能直线下降,连接池易被撑爆:
- 大事务长时间占用数据库连接,如果并发量高,连接池里的连接很快就会被耗尽,新的请求就得排队等着,甚至直接报错。你的应用看起来就像卡死了一样。
- “喂,数据库连接吗?我这有个几百万行数据的导入事务,可能要跑几个小时,你先给我占着哈,别让别人用了!” —— 连接池已哭晕在厕所。
-
锁定资源过多过久,造成大量阻塞和锁超时:
- 大事务为了保证一致性,可能会锁定大量的数据行,甚至是整个表。这些锁在事务结束前都不会释放。
- 其他想要访问这些被锁定数据的事务,只能眼巴巴地等着,等到花儿也谢了,可能就直接锁超时报错了。
- “此路是我开,此树是我栽,要想从此过,等我事务完!” —— 大事务嚣张地喊道。
-
执行时间长,主从延迟的“元凶”之一:
- 在主从复制的架构中,主库上的大事务执行完毕后,对应的binlog才会被发送到从库。如果一个事务在主库跑了1小时,那么从库至少要延迟1小时才能同步到这个事务的修改。
- 这对于需要高可用和读写分离的应用来说是致命的。用户在从库上可能一直读到的是“N久之前”的老数据。
-
回滚时间漫长,堪比“世纪大撤退”:
- 如果大事务在执行过程中不幸失败,需要回滚,那简直是一场灾难。数据库需要根据Undo Log一点点把修改过的数据恢复原状。操作的数据越多,回滚时间就越长。
- 在这漫长的回滚期间,事务依然会持有锁,继续阻塞其他事务。
- “报告老板!那个跑了3个小时的大事务崩了,现在正在回滚…预计还要2个小时…期间相关表都动不了哈!” —— DBA小哥含泪汇报。
-
Undo Log 急剧膨胀,撑爆存储空间:
- 大事务修改的数据越多,产生的Undo Log就越多。如果Undo Log空间不足,可能会导致新的事务无法执行。
- 而且,这些Undo Log因为事务还未结束,不能被及时清理,会一直占用空间。
-
更容易引发死锁:
- 事务越大,持有锁的时间越长,与其他事务发生锁依赖和循环等待的可能性就越高,从而更容易触发死锁。
- 死锁就像交通堵塞,大家都卡在那儿动弹不得,数据库不得不选择一个“倒霉蛋”事务进行回滚,来打破僵局。
-
在极端情况下可能导致数据库崩溃或重启:
- 过于庞大的事务,尤其是在资源紧张的情况下,可能会耗尽数据库的内存、IO或其他关键资源,迫使数据库“罢工”。
如何给“大事务”瘦身?—— 优化指南:
-
核心原则:拆!拆!拆!
- 将大事务拆分成多个小事务分批处理:这是最直接有效的方法。比如,要更新100万行数据,可以每1000行或10000行提交一次事务。
// 伪代码示例 int batchSize = 1000; int totalRows = 1000000; for (int i = 0; i < totalRows; i += batchSize) { // 开启新事务 (或确保当前在事务中) // 处理从 i 到 i + batchSize - 1 的数据 // 提交事务 } - 优点:每个小事务持有锁的时间短,释放连接快,回滚也快。
- 挑战:需要仔细设计,保证拆分后的业务逻辑依然正确,可能需要额外的状态记录和错误处理机制。
- 将大事务拆分成多个小事务分批处理:这是最直接有效的方法。比如,要更新100万行数据,可以每1000行或10000行提交一次事务。
-
数据准备操作先行,事务内只做“核心修改”:
- 将查询、数据校验、复杂计算等不直接修改数据的操作,尽量放到事务开始之前完成。
- 事务内部只保留必要的
INSERT,UPDATE,DELETE等写操作。 - “情报收集、战略制定都在帐外完成,进帐(开启事务)就是直捣黄龙!”
-
避免在事务中进行RPC或外部API调用:
- 远程调用耗时不可控,网络一抖,或者对方服务一慢,你的数据库事务就得傻等着,锁也释放不了。
- 如果必须调用,一定要设置合理的超时时间,并且考虑好调用失败时的补偿机制。
- 最好是将远程调用放到事务之外,或者采用异步消息等方式解耦。
-
加锁操作尽量后置:
- 在事务中,把那些会产生锁(尤其是排他锁)的
UPDATE,DELETE,SELECT ... FOR UPDATE操作,尽可能地往后放。 - 先做一些不加锁或加共享锁的读操作,等万事俱备,再“快准狠”地进行写操作并提交。这样可以缩短锁的持有时间。
- 在事务中,把那些会产生锁(尤其是排他锁)的
-
异步大法好,非核心逻辑异步处理:
- 对于那些不需要立即反馈结果,或者不是事务核心组成部分的操作(比如发送通知邮件、记录日志、更新统计数据等),可以考虑把它们从主事务中剥离出来,通过消息队列等方式进行异步处理。
- 主事务只负责核心数据的变更,保持短小精悍。
-
极端情况:应用侧保证最终一致性,放弃数据库强事务:
- 对于某些超大规模的、可以接受短暂不一致的业务场景(比如双十一的某些非核心订单状态更新),有时会考虑在应用层面通过补偿事务、重试、对账等机制来保证最终一致性,而数据库层面则采用更宽松的事务甚至不用事务。这属于高级玩法,需要谨慎评估。
记住,一个“苗条”的事务,不仅自己跑得快,也能让整个数据库系统更健康、更高效!
第七章:火眼金睛——事务问题定位与优化锦囊 🕵️♀️🛠️
理论学了不少,但实战中遇到事务相关的性能问题、阻塞、死锁时,该如何下手呢?
1. 定位慢事务/长事务:
MySQL的 information_schema 库里有个宝藏表:INNODB_TRX。它可以实时查看到当前InnoDB中正在运行的所有事务信息。
-- 查询执行时间超过N秒的事务 (比如超过60秒)
SELECT
trx_id,
trx_state,
trx_started,
trx_mysql_thread_id, -- 这个ID很重要,用于kill
trx_query, -- 当前事务正在执行的SQL (如果能获取到)
TIME_TO_SEC(TIMEDIFF(NOW(), trx_started)) AS duration_seconds,
trx_tables_in_use,
trx_tables_locked,
trx_rows_locked,
trx_rows_modified
FROM information_schema.INNODB_TRX
WHERE TIME_TO_SEC(TIMEDIFF(NOW(), trx_started)) > 60 -- 单位:秒
ORDER BY duration_seconds DESC;
trx_id: 事务ID。trx_state: 事务状态 (RUNNING, LOCK WAIT, ROLLING BACK, COMMITTING等)。trx_started: 事务开始时间。trx_mysql_thread_id: 该事务对应的MySQL线程ID。如果发现某个事务是“罪魁祸首”且无法自行结束,可以通过KILL <trx_mysql_thread_id>;命令来强制终止它(慎用!)。trx_query: 当前事务正在执行的SQL语句(注意:并非总能显示完整的或当前的语句)。duration_seconds: 事务已执行时长。
2. 分析锁等待和死锁:
- 查看锁信息:
-- 查看当前锁定的表 SHOW OPEN TABLES WHERE In_use > 0; -- 查看InnoDB行锁等待情况 (老版本,新版本中部分信息移到performance_schema) -- SHOW ENGINE INNODB STATUS\G -- 在输出结果中搜索 "LATEST DETECTED DEADLOCK" 和 "TRANSACTIONS" 部分 - Performance Schema (推荐):MySQL 5.5之后引入了Performance Schema,提供了更详细、更细粒度的性能监控和诊断信息。通过配置和查询
performance_schema下的表(如data_locks,data_lock_waits,metadata_locks等),可以非常精确地分析锁竞争和死锁链。- 例如,查询当前有哪些事务在等待锁:
SELECT r.trx_id AS waiting_trx_id, r.trx_mysql_thread_id AS waiting_thread, r.trx_query AS waiting_query, b.trx_id AS blocking_trx_id, b.trx_mysql_thread_id AS blocking_thread, b.trx_query AS blocking_query, w.lock_type, w.lock_mode, w.object_schema, w.object_name, w.index_name FROM information_schema.INNODB_LOCK_WAITS lw JOIN information_schema.INNODB_TRX r ON lw.requesting_trx_id = r.trx_id JOIN information_schema.INNODB_TRX b ON lw.blocking_trx_id = b.trx_id JOIN performance_schema.data_locks w ON lw.requested_lock_id = w.lock_id; -- 注意: 上述查询依赖于特定的表结构和版本,可能需要调整。 -- 推荐使用 performance_schema.data_lock_waits 直接查询。
- 例如,查询当前有哪些事务在等待锁:
- 开启死锁日志:在MySQL配置文件 (
my.cnf或my.ini) 中设置innodb_print_all_deadlocks = ON,可以将所有死锁信息记录到MySQL的错误日志中,方便事后分析。
3. 事务优化的黄金法则 (回顾与补充):
- 事务尽可能小而快:核心原则,前面已详述。
- 避免不必要的事务:如果操作本身就是原子性的(比如单条
UPDATE且不依赖其他操作),或者业务允许一定的中间状态,可以考虑不显式使用事务,或者降低隔离级别。 - 合理选择隔离级别:根据业务需求,在一致性和并发性之间找平衡。不是所有场景都需要RR甚至Serializable。RC能解决脏读,满足很多场景了。
- 优化SQL和索引:慢查询是长事务的温床。确保事务中的SQL语句本身是高效的,相关的查询字段都建有合适的索引。用
EXPLAIN分析你的SQL! - 控制事务并发度:在高并发场景下,如果大量事务竞争少量热点资源,可以通过应用层的限流、队列等机制,适当控制同时进入数据库执行的事务数量。
- 业务逻辑的补偿机制:对于一些长流程、跨服务的操作,可以考虑使用柔性事务的方案(如Saga、TCC、本地消息表+MQ等),通过业务层面的补偿来保证最终一致性,而不是依赖数据库的强事务。
事务的调优是一个系统工程,需要结合业务场景、数据库设计、SQL写法、服务器配置等多方面因素综合考虑。
终章:江湖路远,与事务同行 🌅
呼~终于把ACID四兄弟、并发的妖魔鬼怪、隔离级别的社交距离、MVCC和锁的秘密武器、日志双雄的丰功伟绩,以及大事务的瘦身秘籍都给大家细细盘了一遍。不知道各位侠客感觉如何?是不是对“事务”这位数据库世界的“定海神针”有了更“性感”的认识?
记住,事务不仅仅是面试时需要背诵的枯燥概念,它更是保证我们数据安全、业务可靠的基石。理解它,善用它,优化它,是我们每个和数据打交道的程序员必备的内功心法。
数据库的江湖依然广阔,事务的故事也远未结束。随着分布式、云原生时代的到来,分布式事务又带来了新的挑战和精彩。但万变不离其宗,掌握了单机事务的精髓,再去探索更广阔的天地,你会更有底气。
愿各位在代码的江湖中,事务顺利,永无BUG,数据一致,早日封神!
如果觉得这篇文章对你有点儿用,别忘了点赞、收藏、转发三连哦!也欢迎在评论区留下你的“骚操作”和“踩坑经验”,我们一起交流,共同进步!青山不改,绿水长流,回见!👋😉

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









