







 本文概述了在尝试登录Oracle数据库时遇到的常见问题,包括错误ORA-01034和ORA-27101的解决方法,涉及检查监听、服务启动、SID确认、日志空间和通信通道等问题,提供详细的步骤和可能的原因分析。
本文概述了在尝试登录Oracle数据库时遇到的常见问题,包括错误ORA-01034和ORA-27101的解决方法,涉及检查监听、服务启动、SID确认、日志空间和通信通道等问题,提供详细的步骤和可能的原因分析。
登录Oracle数据库的时候,出现了这个问题:

报错内容:
请输入用户名: system
输入口令:ERROR:
ORA-01034: ORACLE not available
ORA-27101: shared memory realm does not exist
进程 ID: 0
会话 ID: 0 序列号: 0
网上搜到的解决方案一:
原回答链接:
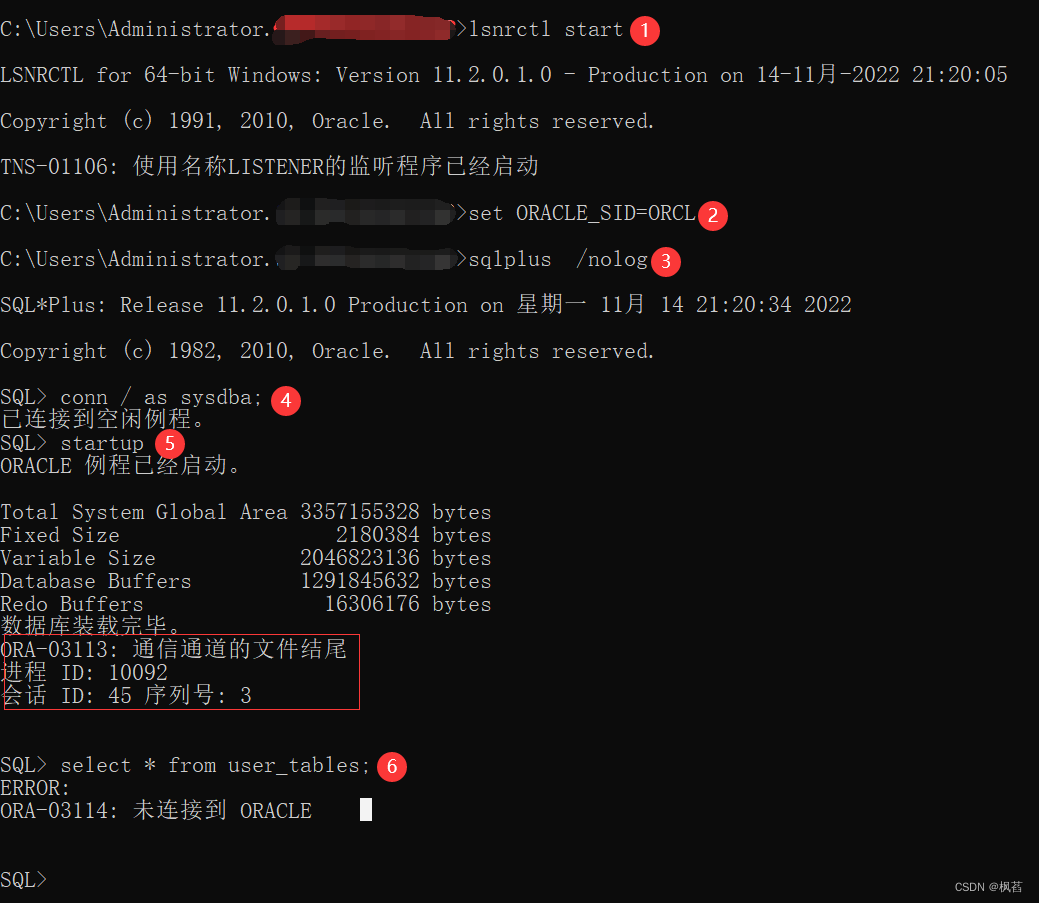
报错内容:
SQL> startup
ORACLE 例程已经启动。
Total System Global Area 3357155328 bytes
Fixed Size 2180384 bytes
Variable Size 2046823136 bytes
Database Buffers 1291845632 bytes
Redo Buffers 16306176 bytes
数据库装载完毕。
ORA-03113: 通信通道的文件结尾
进程 ID: 10092
会话 ID: 45 序列号: 3
SQL> select * from user_tables;
ERROR:
ORA-03114: 未连接到 ORACLE网上搜到的解决方案二:
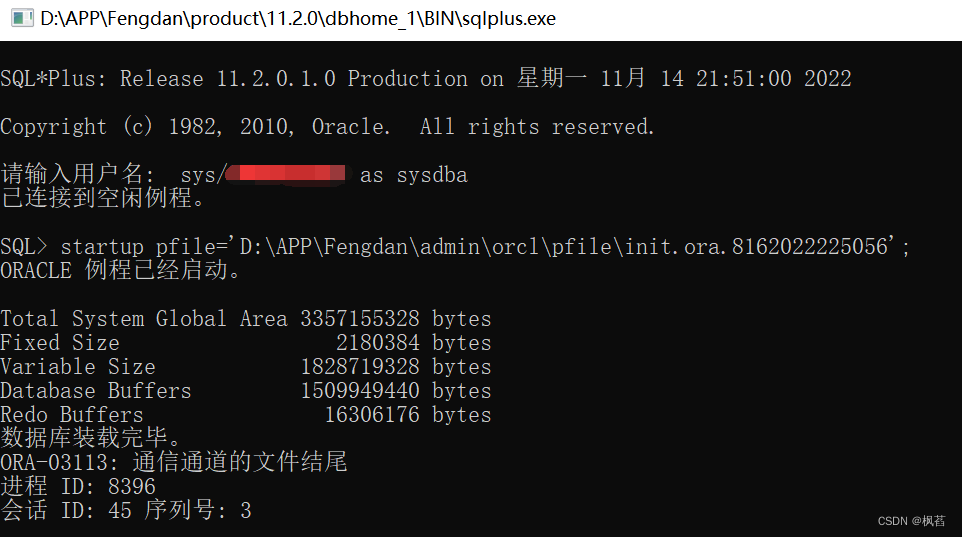
报错内容:
SQL> startup pfile='D:\APP\Fengdan\admin\orcl\pfile\init.ora.8162022225056';
ORACLE 例程已经启动。
Total System Global Area 3357155328 bytes
Fixed Size 2180384 bytes
Variable Size 1828719328 bytes
Database Buffers 1509949440 bytes
Redo Buffers 16306176 bytes
数据库装载完毕。
ORA-03113: 通信通道的文件结尾
进程 ID: 8396
会话 ID: 45 序列号: 3网上搜到的解决方案三:
原回答链接:
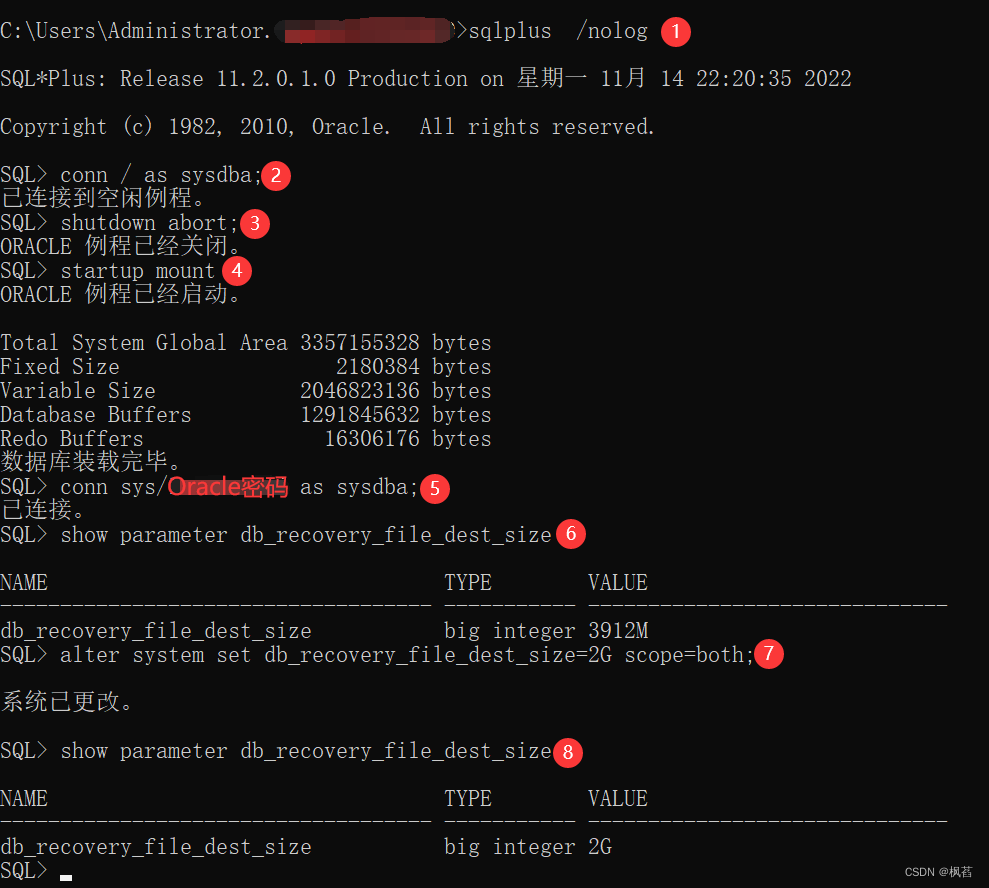
网上搜到的解决方案四:
原回答链接:
按照此文章步骤操作后,结果如下: (还没操作该方案)


















 4777
4777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









