一、提出任务
- 分组求TopN是大数据领域常见的需求,主要是根据数据的某一列进行分组,然后将分组后的每一组数据按照指定的列进行排序,最后取每一组的前N行数据。
- 数据表t_grade
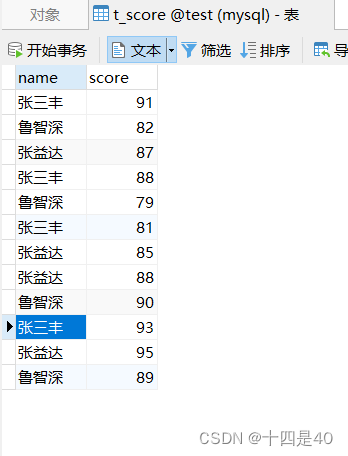
- 执行查询
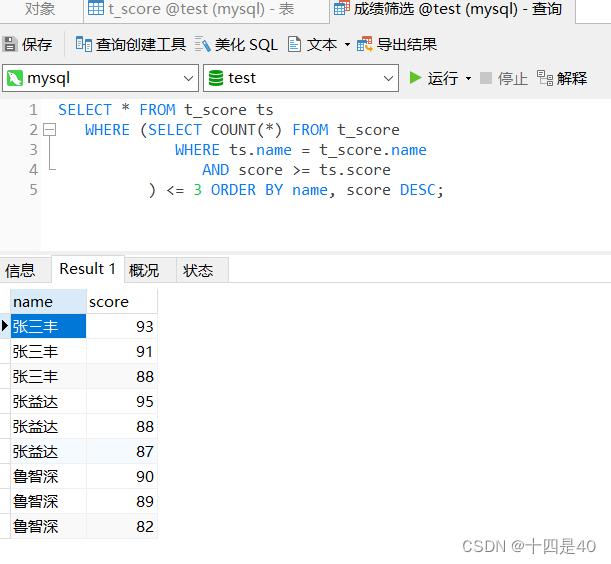
SELECT * FROM t_grade tg
WHERE (SELECT COUNT(*) FROM t_grade
WHERE tg.name = t_grade.name
AND score >= tg.score
) <= 3 ORDER BY name, score DESC;
二、完成任务
(一)新建Maven项目
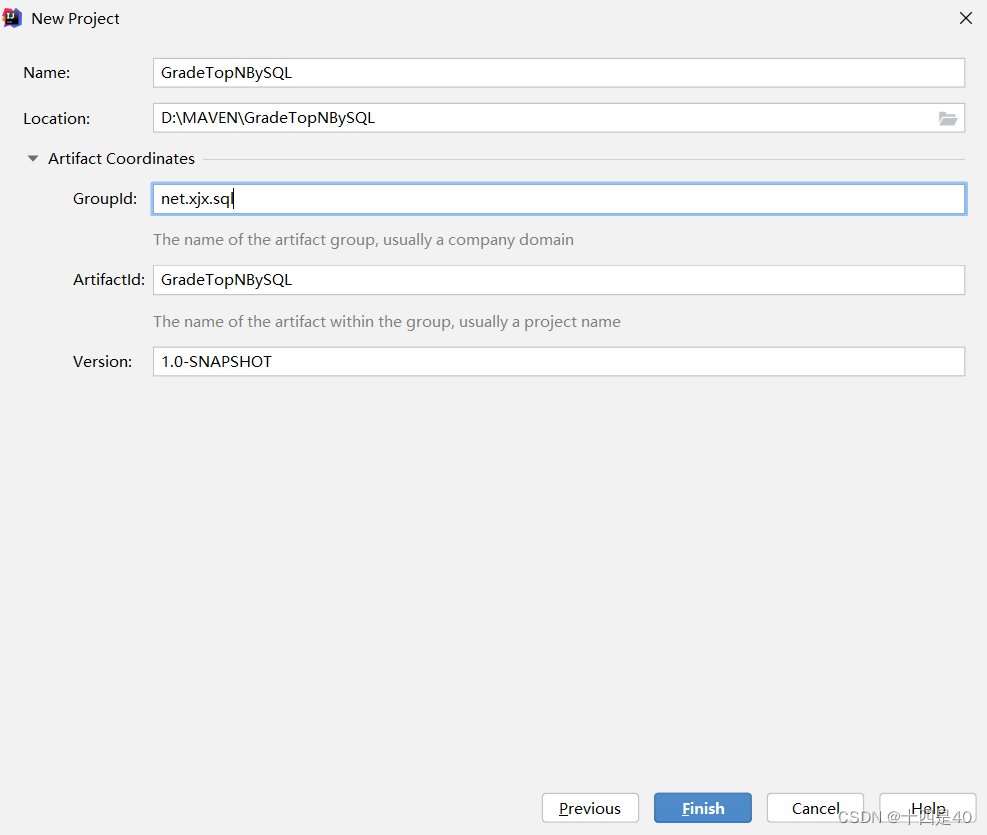
- 点击Finish创建项目
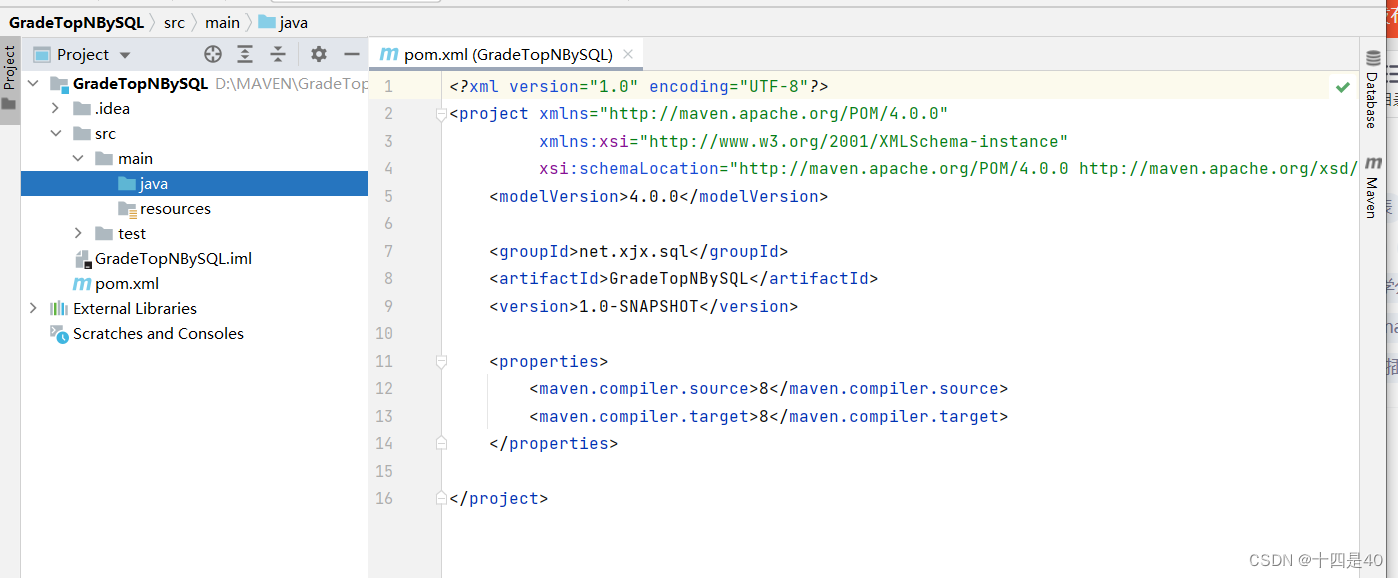
(二)添加相关依赖和构建插件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>net.huawei.sql</groupId>
<artifactId>GradeTopNBySQL</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>








 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6087
6087











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









