






Lightweight Image Super-Resolution with Superpixel Token Interaction
Aiping Zhang1 Wenqi Ren1* Yi Liu2 Xiaochun Cao1 1School of Cyber Science and Technology, Sun Yat-Sen University 2Baidu Inc.
代码链接:https://github.com/ArcticHare105/SPIN
摘要:基于Transformer的方法在单图像超分辨率(SISR)任务上展示了令人印象深刻的结果。然而,当应用于整个图像时,自注意力机制计算成本较高。因此,目前的方法将低分辨率输入图像划分为小的补丁,分别处理这些补丁,然后将它们融合以生成高分辨率图像。然而,这种常规的固定补丁划分过于粗糙且缺乏可解释性,导致注意力操作期间出现伪影和结构干扰。为了解决这些挑战,我们提出了一种新的超级令牌交互网络(SPIN)。我们的方法使用超像素来聚类相似的局部像素,形成可解释的局部区域,并利用超像素内的注意力来实现局部信息交互。这种方法具有可解释性,因为只有相似的区域相互补充,而不相似的区域被排除在外。此外,我们设计了一个超像素交叉注意力模块,通过代理超像素促进信息传播。大量的实验证明,所提出的SPIN模型在准确性和轻量级方面优于最先进的SR方法。代码可在https://github.com/ArcticHare105/SPIN获取。
1. 介绍
单图像超分辨率(SISR)是计算机视觉中的一个重要任务,旨在提高低分辨率(LR)图像的分辨率和视觉质量。SISR的目标是从给定的低分辨率图像生成高分辨率(HR)图像,这在需要高质量图像的应用中特别有用,例如医学成像、监控和数字摄影。
自从Dong等人的开创性工作以来,许多神经网络已经被开发出来,以应对从低分辨率输入重建高质量图像的挑战。一些基于CNN的方法使用更深、更复杂的体系结构来获得更好的性能。然而,这些方法伴随着计算资源的增加和成本的提高,限制了它们的应用场景。注意机制[37]已被证明对高级视觉任务和低级视觉领域都有显著影响,包括超分辨率(SR)。注意机制允许网络有选择地关注输入的相关区域,从而提高SR输出的质量。利用注意力机制,transformer已被应用于SR任务,如SwinIR[20]和ESRT[26]。这些模型强调了全局特征提取能力在SISR中的重要性。此外,为了提高效率,ELAN[43]提出了一种分组自注意模块,并在计算补丁关联时共享权重。然而,注意机制具有较高的计算复杂度和内存消耗,需要将大图像分割成小斑块进行单独处理。
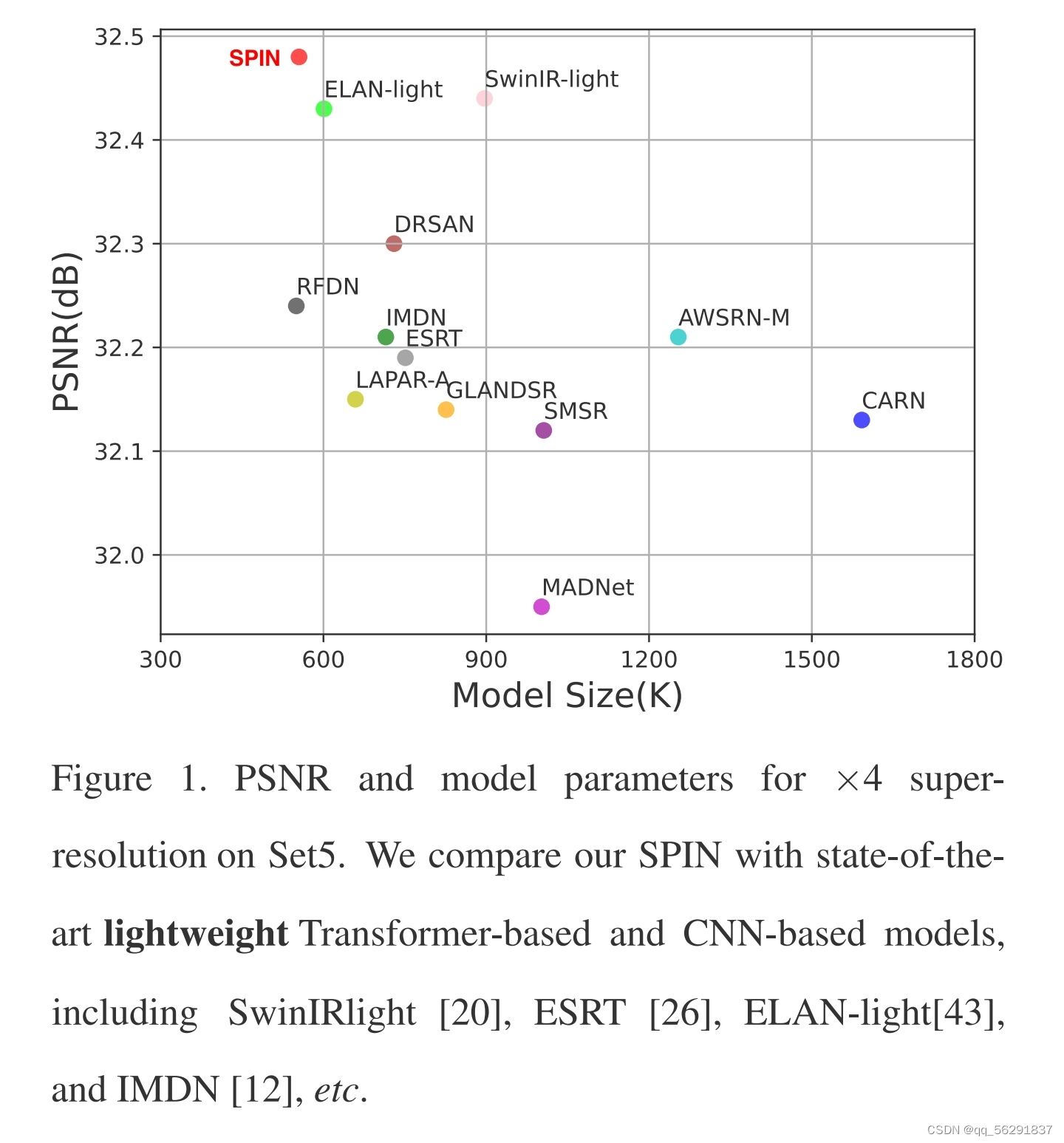
(图1. 在Set5数据集上,我们提出的SPIN模型与现有的轻量级Transformer和CNN模型(包括SwinIRlight [20],ESRT [26],ELAN-light[43],IMDN [12]等)进行×4超分辨率比较的结果。其中,PSNR表示峰值信噪比,用于衡量原始图像和重建图像之间的差异;模型参数则反映了模型的复杂性,参数越少,模型越轻量。从图中可以看出,SPIN模型在这两种指标上都优于其他模型。)
这种策略提高了基于transformer的模型的效率,但也带来了一些问题。根据固定形状划分补丁会导致连续结构被分割,从而阻碍了在其他地区使用相似信息来增强图像细节的能力。此外,在每个补丁内应用的局部注意机制涉及无关区域的计算,导致不良的相互影响。因此,在使用这种策略时需要仔细考虑其潜在的问题,并采取适当的措施来解决这些问题。
为了解决这些问题,我们提出了一种新颖的方法,将局部和全局注意力机制与单个超像素部分结合起来。我们从输入图像的像素开始,使用基于CNN的浅层特征提取,并对相邻像素进行聚类以形成超像素。然后,我们根据相似性对超像素进行聚类以获得局部区域,并分别对它们进行局部特征提取。与之前使用固定形状划分补丁的方法[20,43]不同,该方法仅用于提高并行计算效率,而我们的策略对于区域划分更具可解释性,允许更灵活和自适应地分割输入图像,并防止连续结构的分裂。
接下来,我们引入了超像素交叉注意力模块,通过超像素的替代来实现长距离信息交互。此外,我们设计了一个内部超像素注意力(ISPA)机制,应用于超像素的像素上,仅在规则图像区域扩展原始的注意力操作。这确保了局部注意力机制的信息交互发生在相似的区域中,消除干扰和无关计算。这两种提出的注意力机制相互交织,共同参与局部和全局特征提取。如图1所示,所提出的SPIN在PSNR和模型大小之间具有良好的平衡。
我们的贡献总结如下:
(a) 提出一种结合超像素聚类和transformer结构的新颖的超分辨率模型,结果是一个更易于解释的框架。
(b) 提出内部超像素注意力(ISPA)和超像素交叉注意力(SPCA)模块,它们在超像素内和之间运行,使计算能够在非规则区域进行,同时保持捕捉长距离依赖关系的能力。
(c) 实验表明,所提出的方法比当前最轻量级的SR方法取得了更好的重建性能。
2. 相关工作
2.1 用于超分辨率的深度网络
随着深度学习的最近进展,基于神经网络的方法已经成为单图像超分辨率(SR)的主要解决方案。SRCNN[5]使用一个三层的CNN网络从其双三次下采样的低分辨率(LR)图像中重建高分辨率(HR)图像。为了进一步提高准确性,最近的基于CNN的方法已经采用了更复杂和有效的结构。例如,Kim等人[15]应用了一个带有残差连接的深层CNN架构来提高SR的准确性。
注意力机制也被引入到SR中,以提取最重要和最有信息的特征。例如,Zhang等人[44]使用了一个通道注意力机制,而Hu等人[10]则将空间注意力与通道注意力结合在SR中。此外,受到ViT [6]在高级视觉任务成功的影响,Chen等人[4]介绍了Trans-former到SR中,但它需要大量的参数。为了减小模型大小,SwinIR [20]通过将整个图像分割成8×8大小的小窗口并在应用多头注意力机制时移动窗口,将Swin- Transformer [24]框架应用于SR。虽然上述方法在提取有信息特征方面有效,但它们可能需要大量的参数。
2.2 轻量级超分辨率方法
轻量化是深度SR模型的关键考虑因素,许多方法已经被提出来提高其效率。例如,FSRCNN[5]和ESPCN[34]利用了后上采样技术来减轻计算负担,而CARN[1]则利用了组卷积和级联机制来提高效率但损害了性能。IMDN[12]应用了三步蒸馏来提取特征和切片操作来划分提取的特征,但带来了灵活性问题。LatticeNet[28]引入了具有低计算复杂性的晶格块。BSRN[19]设计了一个深度可分离卷积来减少模型复杂性,并利用注意力机制来提高SR重建性能。同时,提出了基于轻量级Transformer的SR方法,通过使用窗口注意力[20]和采用移位卷积和分组自注意[43]来减少模型复杂性。尽管这些方法是轻量的并且高效,但SR重建的质量仍有改进的空间。
2.3 图像处理中的像素聚类
像素聚类是图像处理中一个被广泛研究的任务,最近深度学习方法的进展在这个领域取得了显著的进展。一种常见的像素聚类方法是使用卷积神经网络(CNN)生成将相似像素分组在一起的像素级嵌入。例如,Liu等人[23]开发了一个深度亲和力网络,该网络学习像素级的亲和性来进行像素聚类。同样地,Sun等人[35]提出了一个网络,该网络学习像素级别的表示来对图像块进行聚类。
除了使用CNN生成像素级嵌入之外,聚类算法也可以应用于CNN特征,将相似的像素分组到簇中。Jegou等人[14]引入了一种一次聚类方法,该方法使用CNN特征生成初始簇,然后使用聚类算法进一步细化这些簇。Li等人[17]提出了一种弱监督聚类方法,该方法使用CNN特征和一个稀疏标记方案将像素聚类到对象区域中。这些方法利用了CNN和聚类算法的优势,使得在图像处理任务中能够实现更准确和高效的像素聚类。
最近,人们越来越关注使用图卷积网络(GCN)进行像素聚类。GCN能够通过构建图像的图表示来建模图像中像素之间的依赖关系,其中每个像素都是一个节点,边表示像素之间的关系。这使得GCN能够捕捉到比传统CNN更复杂和非局部的像素之间相互作用。例如,Zeng等人[40]提出了一个基于GCN的框架用于高光谱图像分类,该框架使用了两种聚类策略来利用多跳相关性。第一种聚类策略根据像素的光谱相似性将相似像素分组在一起,而第二种聚类策略根据像素的空间邻接性将像素分组在一起。
尽管像素聚类在各种图像处理任务中已经展示了有希望的结果,但它尚未在超分辨率应用中得到有效应用。
3. 提出的方法
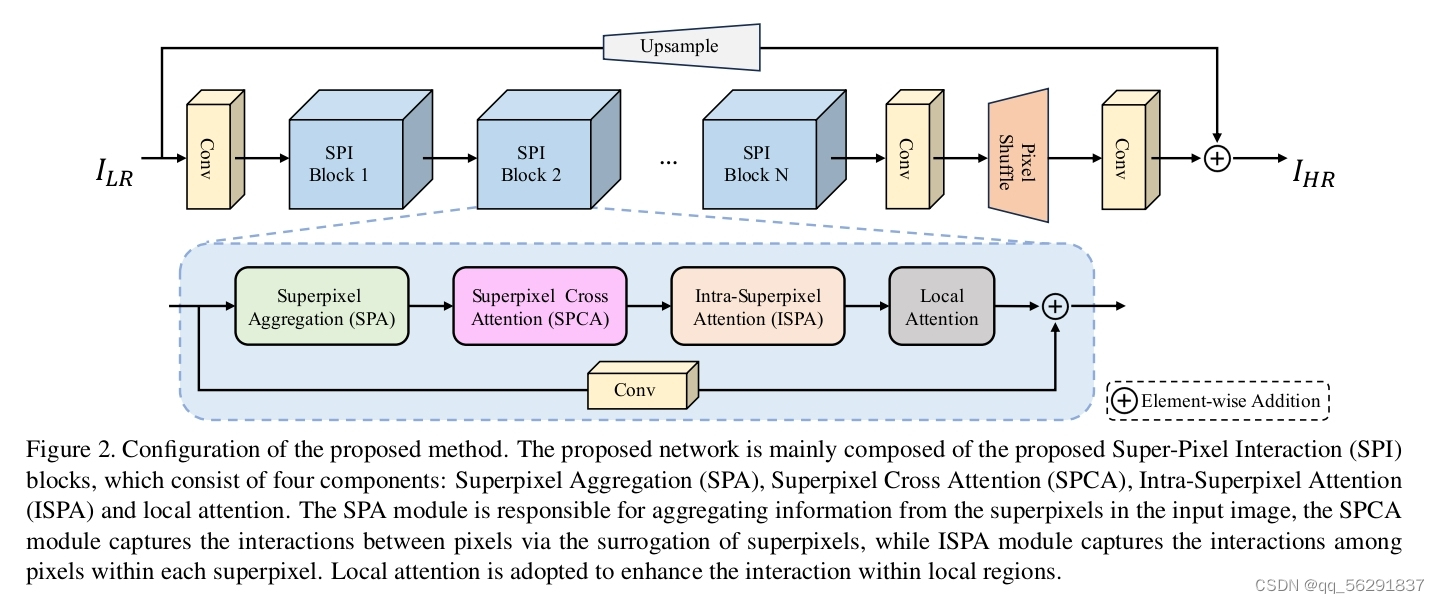
图2. 所提出方法的配置。该网络主要由提出的超像素交互(SPI)块组成,它包括四个组成部分:超像素聚合(SPA)、超像素交叉连接(SPCA)、超像素内注意(ISPA)和局部注意。SPA模块负责聚合输入图像中的超像素信息,SPCA模块通过超像素的替代捕获像素间的相互作用,ISPA模块捕获每个超像素内像素间的相互作用。采用局部关注来加强局部区域内的互动。
本文提出的模型架构如图2所示,主要由提出的超级像素交互(SPI)块组成。在SPI块之前,我们使用一个编码器,即一个3×3的卷积,将低分辨率图像ILR嵌入到一个高维特征空间中。
给定编码器,我们可以获取浅层特征Xemb如下:
 其中 fencoder()表示提出的模型的编码器。
其中 fencoder()表示提出的模型的编码器。
然后,我们在编码器之上堆叠K个SPI块以提取包含输入图像的丰富低级别和高级别信息的深层特征。每个SPI块包括四个组件:超级像素聚合(SPA),超级像素跨注意力(SPCA),超像素内注意力(ISPA)和局部注意力。
每个块的输入特征首先通过SPA模块聚合成超级像素。然后,ISPA模块捕获每个超级像素内像素的依赖关系和相互作用,而SPCA模块捕获长范围像素之间的依赖关系和相互作用。为了增强局部区域内像素之间的相互作用,我们在ISPA和SPCA模块之后使用局部注意力模块,该模块使用基于窗口的注意力[24, 20, 21]。我们使用重叠的补丁来加强特征交互。形式上,对于第i个SPI块,整个过程可以表示为: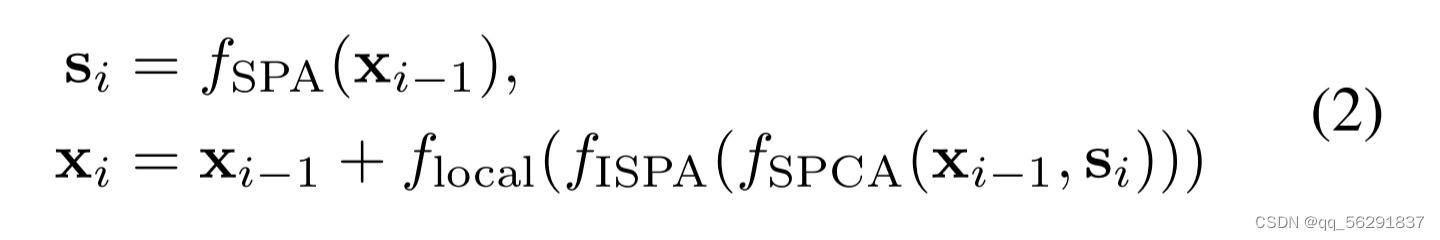
其中Si表示第i个SPI块中的超级像素的特征,f(·)表示每个单独组件的函数。遵循先前的工作,我们使用残差连接来简化整个训练过程。
在K个SPI块之后,我们采用3×3卷积层和像素洗牌操作[34]来获取全局残差信息,将其添加到ILR的上采样图像中以解决高分辨率图像ISR。
3.1 SPA模块
与以往将输入图像或特征划分为规则块的方法不同,本文提出将输入特征划分为超像素。

图3。我们的方法的超像素聚合(SPA)模块,它通过平均池初始化超像素,然后以迭代的方式更新它们。
规则补丁可以很容易地将连接区域裁剪成不同的补丁,超像素分区可以感知地将相似的像素分组在一起,从而可以描绘更精确的边界,减少产生模糊和不准确边界的风险。
与可能容易将相邻区域分割成不同区域的常规补丁相比,超像素级的划分可以从感知上将相似的像素分组在一起,从而描绘出更精确的边界,降低生成模糊和不准确边界的风险。具体来说,在超像素聚合的过程中,我们使用了SSN [13]中基于软k-means的超像素算法。给定视觉标记x∈RN×C(其中N=H×W是视觉标记的数量),每个标记x(i)∈RC被假设属于M个超像素s∈RM×C中的一个,因此需要计算视觉标记和超像素标记之间的关联性。形式上,超像素聚合的过程是一个期望最大化的过程,包含总共T次迭代。首先,如图3所示,我们通过在规则网格中平均标记来采样初始超级标记s0,这个过程被称为Patchify。假设网格大小为Hs×Ws,那么超级标记的数量为M =(H×W) /(Hs×Ws)。对于第t次迭代,我们计算关联映射如下: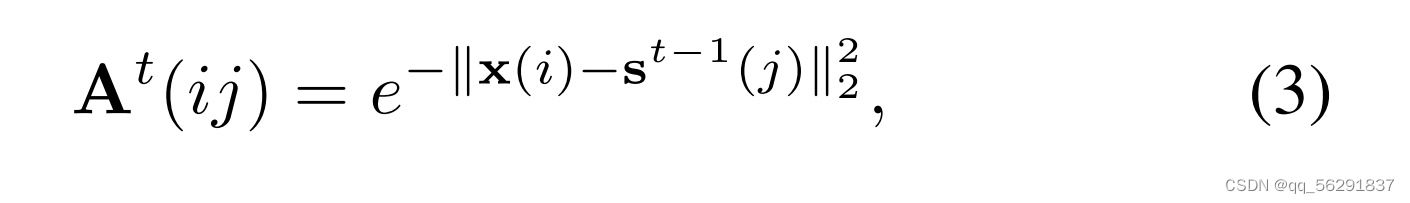
其中At∈RN×M是关联映射,At(ij)是在第i行和第j列的值。需要注意的是,超像素聚合只计算了每个标记到周围超像素的关联映射,这保证了超像素的局部性,使其在计算和内存方面都高效[13]。
之后,我们可以将超像素st作为视觉标记的加权和获得,定义为: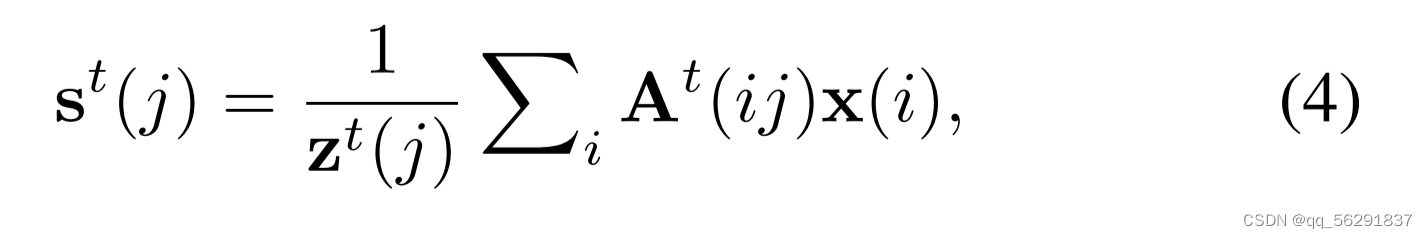
其中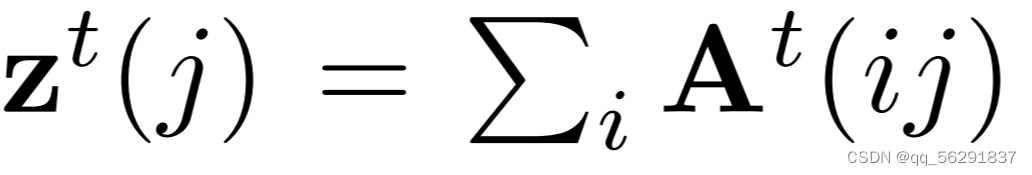 表示沿着列的归一化项。经过T次迭代后,我们可以得到最终的关联映射AT。为了简单起见,我们在以下部分省略了上标。
表示沿着列的归一化项。经过T次迭代后,我们可以得到最终的关联映射AT。为了简单起见,我们在以下部分省略了上标。
3.2. SPCA模块
由于超像素仅捕获局部区域中像素的位置和局部连接,可能缺乏捕获超分辨率长程依赖性的能力。在这里,我们利用自我注意力范式[37]通过超像素的代理增强长程通信,这有助于利用特征之间的互补性来生成高质量的超分辨率图像。由于像素特征与所属的超像素特征高度相似,使超像素成为在像素之间尽可能多地传播信息的有希望的代理。
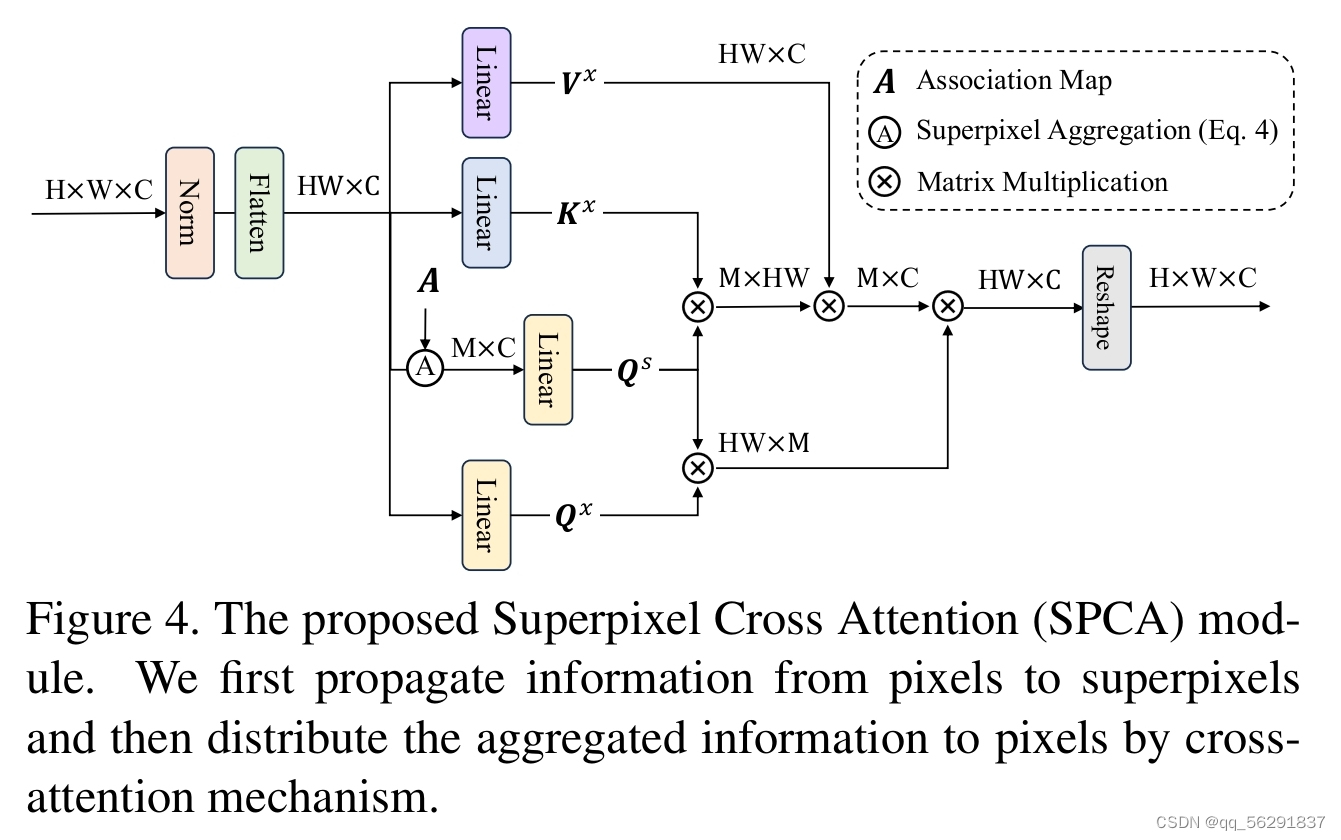
如图4所示,给定超像素特征s ∈ R M×C ,其中M表示超像素的数量,以及展平的像素特征x ∈ RHW×C 。我们使用注意力机制[37]首先将像素信息传播到超像素。具体来说,我们使用线性投影来计算查询:Qs ∈ R M×D,键:Kx ∈ RHW×D,值:Vx ∈ RHW× C 作为: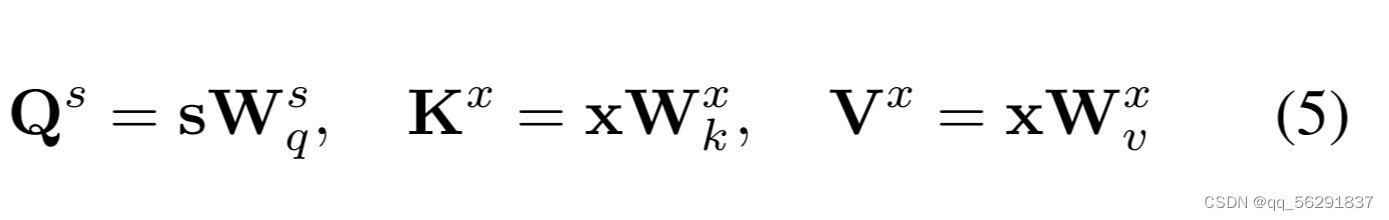
其中,Wsq∈ RC×D, Wsk∈ RC×D, Wsv∈ RC×C 是根据查询、键和值分别选择的权重矩阵。输出可以通过首先计算查询和键之间的相似性并将其用作聚合值的权重来获得,可以公式化为: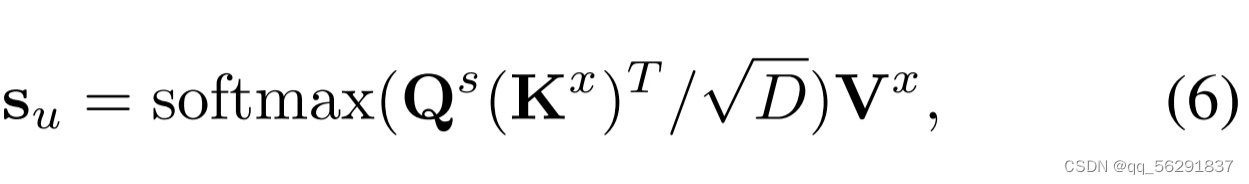
其中√ D是一个避免梯度消失的缩放因子,su是更新后的超像素特征。值得注意的是,与超像素聚合不同,此过程不考虑邻居限制,确保长程信息的传播。
一旦信息从像素传播到超像素,就需要将聚合的信息分发回像素,以实现像素之间的信息传播。在这里,我们进一步使用注意力机制。具体来说,我们使用另一个权重矩阵Wqx从像素特征中获得查询。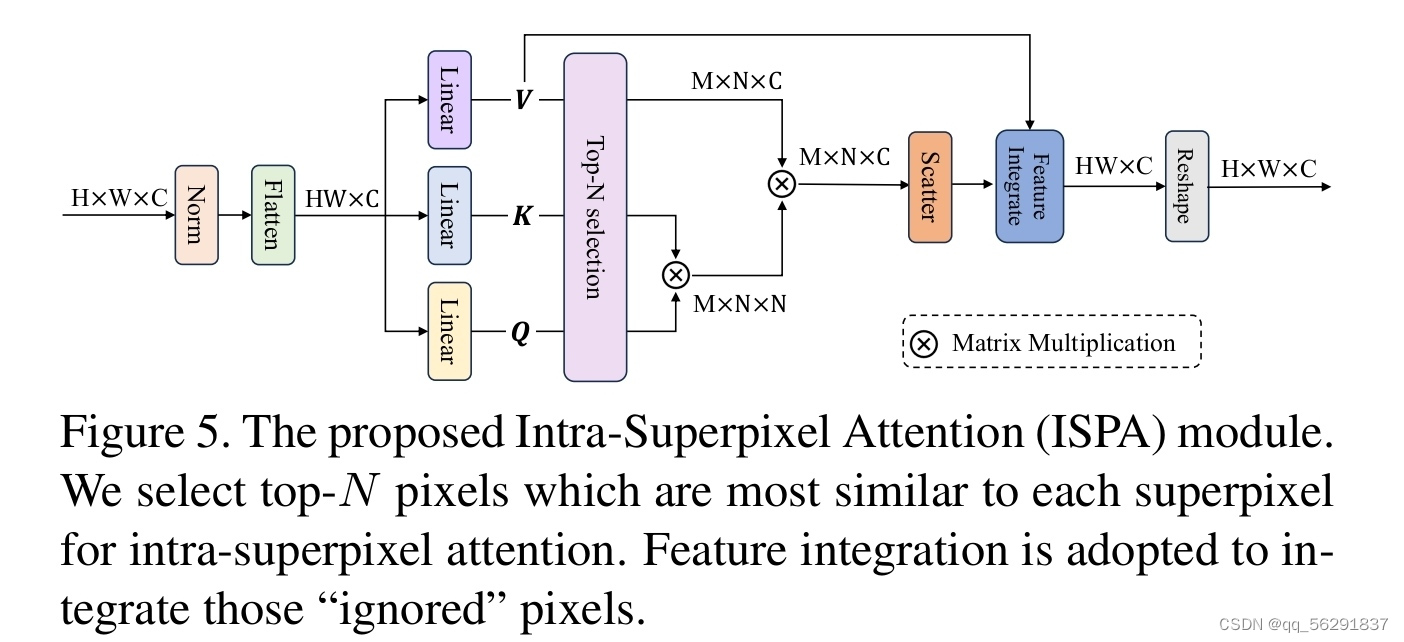
图5. 提出的超像素内部注意力(ISPA)模块。
我们选择与每个超像素最相似的前N个像素进行超像素内部注意力。采用特征集成来整合那些被“忽略”的像素。
为了减少参数的数量,我们直接使用超像素特征Qs作为键,并将更新后的超像素特征作为值,并利用交叉注意力将更新后的超像素特征映射回像素级别。类似于Transformer块[37],我们还在上述过程之后采用前馈网络(FFN)。我们的FFN包含一个层归一化[2]层,然后我们使用特征门控[33]来调制输入特征和通道注意力[9]来提取全局信息。之后,我们使用两个全连接层和GELU [8]激活函数。
3.3. ISPA模块
考虑到关联图,一种直观的提高超分辨率图像质量的方法是利用同一超像素内相似像素的互补性。为了实现这一点,我们需要获取每个超像素的对应像素。然而,不同的超像素可能包含不同数量的像素,这使得并行处理变得困难,也会导致意外的内存消耗,因为总是有一些超像素包含大量的像素。为了解决这个问题,如图5所示,我们借助关联图AT选择与每个超像素最相似的前N个像素。假设一个超像素的相关像素为f = {x(i)}N ∈ RN×C ,其中N表示所选像素的数量。我们遵循标准的自注意力机制[37],即等式5和等式6,进行超像素内的自注意力,其中包括查询、键和值投影的权重矩阵Wq f 、W f k 和W f v 。在超像素内交互之后,我们利用在top-N选择过程中生成的索引将细化后的像素特征分散回它们在图像中各自的位置。
top-N选择可能会导致一些“被忽略”的像素,即那些没有被任何超像素包括的像素。对于这些“被忽略”的像素,我们利用值投影W f v 来投影它们以获得更新的特征,然后将这些特征与那些通过超像素内交互更新的像素进行整合。类似于SPCA模块,我们在ISPA模块后采用相同的FFN。
4. 实验
在这一部分,我们详细描述了每个模块的消融实验以及我们的方法在不同尺度超分辨率任务上的性能。
4.1. 数据集
我们使用DIV2K [36]作为训练集,这是一个高清晰度数据集,包括各种自然场景的图像。这个数据集包含900张高分辨率图像,前800张用于训练,后100张用于验证。根据RCAN [44],LR样本是通过双三次下采样方法生成的。此外,我们在五个常用的基准测试上评估了我们的方法,包括Set5 [3], Set14 [41],
BSDS100 [29], Urban100 [11], 和 Manga109 [30]。
4.2. 实现细节
在训练过程中,初始学习率设置为5e-4,训练过程在1000个epoch后停止。使用的优化器是带有β1为0.9和β2为0.999的Adam优化器。为了训练模型,我们采用随机旋转90°, 180°, 270°, 和水平翻转进行数据增强。
在最终模型中,所有块的输出通道都设置为40。我们将SPI块的数量设置为8,并在整个SPI块中采用不同的初始补丁进行超像素聚合,范围从12到24。
对于评估,我们主要使用常用的评估指标,包括峰值信噪比(PSNR)和结构相似性(SSIM)。我们遵循RCAN [44],在将RGB转换为YCbCr格式后,在Y通道上测量这些指标。
4.3. 与轻量级模型的比较
我们将我们的模型与最先进的轻量级SR模型进行比较,包括基于CNN的CARN [1]、IMDN [12]、LatticeNet [28]等模型,以及基于Transformer的ESRT [26]和SwinIR [20]和ELAN [43]模型定量比较。不同方法的定量指标报告在表1中。我们可以看到,基于Transformer的模型[20, 26, 43]通过利用图像块之间的长距离相似性,在PSNR和SSIM方面始终优于基于CNN的方法[1, 12, 38, 16, 18, 22,42]。然而,它们总是将图像划分为规则的块,这可能会在输入图像中破坏对象、边界等。
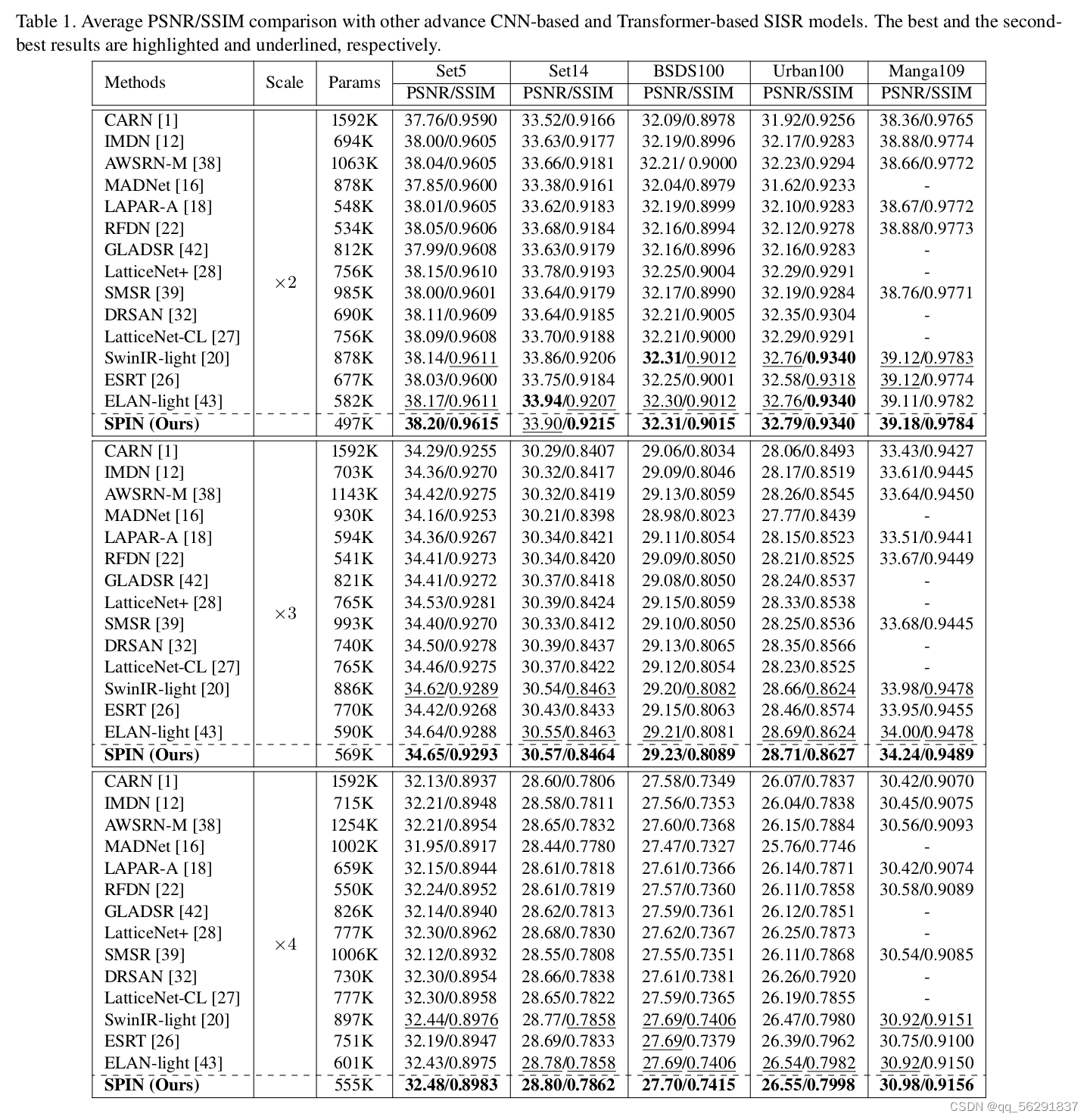
相比之下,我们的方法利用超像素来实现可解释性和连续的区域划分,对Transformer进行了解释。我们在所有五个基准测试数据集和所有三个尺度上都获得了最佳或次佳的PSNR/SSIM分数。此外,参数数量小于现有的基于Transformer的方法。

- 定性比较。图6展示了在Urban100,BSDS100和Set14数据集上,尺度因子×4的视觉比较结果。结果显示,所提出的SPIN模型可以在LR图像中提供相应的非局部信息的情况下,有效地恢复受损的纹理。相比之下,缺乏非局部注意力的深度SISR模型无法准确地重建受损的纹理。例如,当比较图像‘B100/148026’的重建结果时,很明显我们的模型产生的结果非常接近HR,而其他没有非局部注意力的竞争性SISR模型,如CARN [1]和IMDN [12]则不适合恢复这种严重受损的区域。此外,与其他基于注意力的深度SISR方法(如ESRT [26],SwinIR-light [20]和ELAN-light [43])相比,我们的SPIN模型仍然保持优越的重建质量。另外,对于图像‘Urban100/img020’,即使没有太多的纹理信息,我们的方法也可以准确地恢复受损的图像。
5. 消融研究
我们进一步进行消融研究以更好地理解和评估提出的SPIN中的每个组件。为了与设计的基础设置进行公平比较,我们在×4 SPIN的基础上进行所有实验,并在相同的设置下进行训练。表2中的实验结果在DIV2K-val [36]和Manga109 [31]数据集上进行测量。
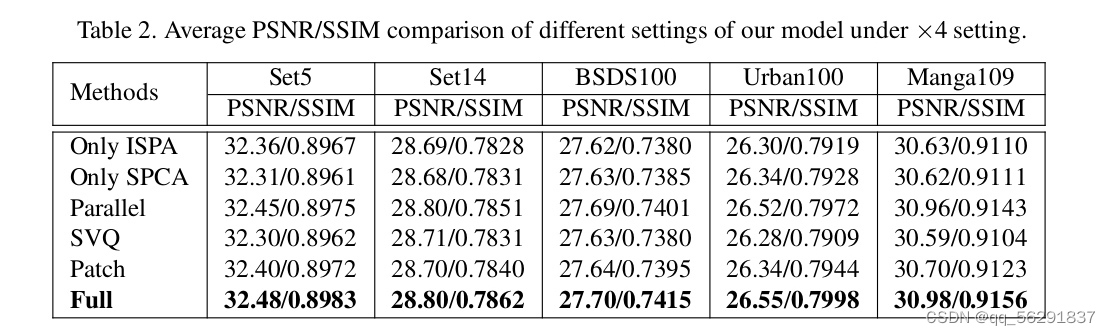
- ISPA和SPCA模块的有效性。ISPA模块和SPCA模块在我们的方法中起着捕获长范围和短范围信息以恢复受损图像的重要角色。为了评估所提出模块的有效性,我们在表2中显示了它们的表现。具体来说,我们评估了仅使用ISPA模块或SPCA模块的设置。为了保证与我们基础设置的公平比较,我们使用12个块来确保与我们最终模型具有相似的参数数量。显然,仅使用一个模块会导致性能下降,因为它缺乏短范围或长范围的信息。此外,我们还尝试采用并行设置,其中块内的相互作用和块间的相互作用以并行方式进行。正如我们所看到的,这种方式获得的性能略低于我们最终的设置,但仍然大大优于上述两种设置,证明了同时捕获长范围和短范围信息的必要性。在我们的最终设置中,我们选择顺序实现,因为它的性能更好。
- 像素聚合。为了评估我们提出的像素聚合的有效性,我们在表2中验证了两种其他像素聚合策略。第一种策略是使用软矢量量化(SVQ)或高斯混合模型(GMM)的过程。具体来说,软矢量量化与我们的大像素聚合类似,但没有仅计算相邻像素之间相似性的限制。因此,像素与超像素之间的亲和力是非局部的。如图所示,这种方法实际上获得的性能略低于我们的。原因可能是软矢量量化对图像中的所有像素都给予同等的重视,而没有考虑它们之间的空间关系,这可能导致区域之间的模糊性。正如LAM [7]所述,输入LR图像中每个像素相对于SR图像的重要像素通常位于其邻域内。此外,我们还尝试在我们的方法中使用仅本地注意力模块,这实际上类似于Swin Transformer [25]但没有窗口移动。结果可以预见地不如我们的好,因为常规补丁通常会破坏对象、边界等的结构信息,证明了我们方法的有效性。
- 网络的深度。我们评估了所提出网络深度的影响。我们主要改变网络的块数,从4个块增加到10个块。
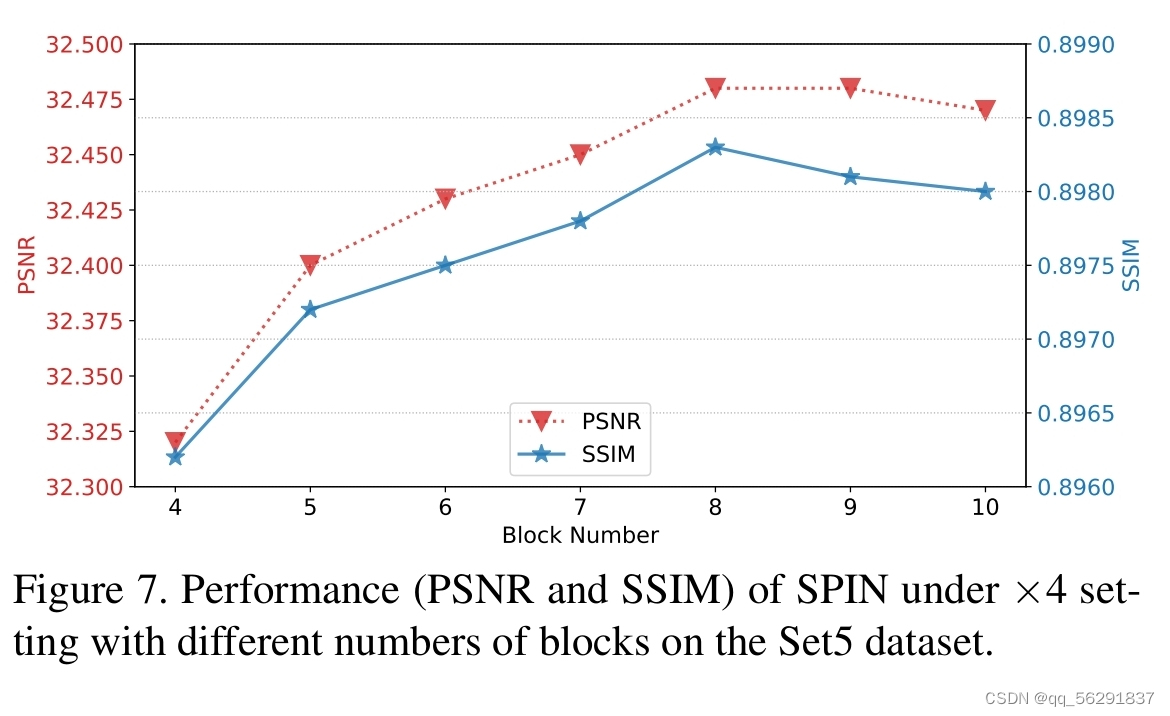
如图7所示,随着块数的增加,我们网络的性能也得到了提高。然而,当块数大于8时,性能开始下降。我们认为原因可能是过度参数化的网络过拟合了训练数据,导致在其他基准测试上泛化能力较差。
6. 结论
在本文中,我们提出了一种名为超级标记交互网络(SPIN)的新颖方法,该方法利用超像素将局部相似的像素分组为可解释的局部区域。我们的方法采用超像素内注意力来促进不规则局部超像素区域内的局部信息交互,而超像素交叉注意力模块通过超像素的代理促进长范围的信息交互。大量实验证明,SPIN在准确性和轻量化方面优于最先进的超分辨率方法。此外,所提出的方法为处理整个图像的可解释区域划分挑战提供了有前景的解决方案。
致谢
本工作得到国家自然科学基金(No. 62025604, 62172409, 62261160653)、深圳市科技计划项目(No. 20220016, RCYX20221008092849068)和中国国家关键研发计划(Grant 2022YFB3103504)的支持。
参考文献

















 9273
9273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









