







目录
前言
Redis我们最近学习必备工具之一了, 接下来我们将讲解Redis的简单应用 ,以及相关原理
安装redis的俩种方法
第一种: 在Linux上安装Redis
yum -y install redis
启动Redis
redis-server /etc/redis.conf &
链接Redis
redis-cli
出现这个说明链接成功了

简单的读和取数据

设置远程链接
- 将redis的配置文件下载到本地: 配置文件是Linux底下的 /etc/redis.conf 目录
cd /etc 进入目录
- 下载文件
sz redis.conf
- 查找文件中的bind 127.0.0.1 将找到的这一行注释掉(ctrl + F 查找快捷键)
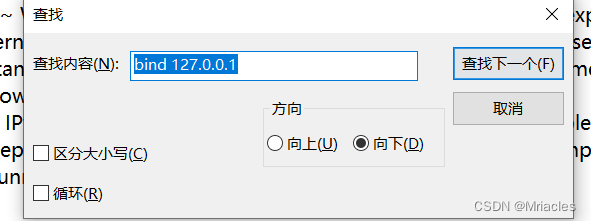
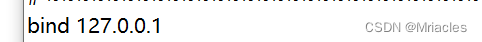
4. 将redis.conf 中的protected-mode yes 中的yes 改为no

5. 保存文件,将修改后的文件在上传到Linux中etc 的目录下
6. 使用命令 redis-cli shutdown 先关闭redis 服务 ,再使用 redis-server /etc/redis.conf & 启动redis命令
7. 最后,如果不能远程访问, 请试着查看服务器是否开放了6379的端口号

第二种 在Windows中安装 Redis
Redis 与 MySQL的区别
MySQL : 是关系型数据库
Redis : 是文档型数据库 (以键值对的方式存储)(也叫非关系型数据库)
关系型数据局库描述的是对象与对象之间的关系
而文档型数据库中 , 没有关系,是动态的,所有内容都在一块, 增加删除数据不影响之前的数据,所以说Redis天然支持分布式
举个例子
我们都知道session 信息, 一般是存储在服务器中的 ,而加入有多台服务器的话, session还是存储在每个服务器中, 那么就意味着一个用户, 每次访问不同的服务器(物理上的多台),就必须重新验证一下session , 这不得烦死. 而Redis就 向一个安检门一样, 你在我这里验证一次, 无论进那台服务器都不需要再次验证了 , 这就是分布式
Redis可以实现那些功能
- 会话存储 -也就是上面我们说的存储session
- 存储缓存 - 这个也很好理解: 我们的服务器可以不停的买, 然后来突破单台服务器的瓶颈, 但是我们的数据库怎么办呢? 所以在企业中数据库是最容易达到瓶颈的 ,虽然我们可以分库分表, 但是这样的库 和表过多的时候 ,我们查询的效率无疑会大大降低, 这时候 ,就需要将数据库的一部分数据 添加到Redis中的缓存中, 让服务器查询数据的时候先去缓存中查询, 查不到再去数据库中查, 这样就大大提高了数据库查询的效率
- 实现分布式锁 - 与存储会话功能一样 ,是换个用途
- 简单的消息队列
Redis常用的数据类型
String字符串类型
Redis支持的字符串类型不是定长分配的字符串,是动态变长字符串,修改字符串在没有增加特别多内容的情况下不需要重新分配内存空间,
字符串类型常用的场景有以下这些:
(1)缓存结构体信息:
(2)计数功能:
List列表类型
常用使用场景
(1)list列表结构常用来做异步队列使用
(2)list可用于秒杀抢购场景
Hash数据类型
常用使用场景
(1)保存结构体信息
Set集合类型
用在一些去重的场景里
Zset有序集合
常用使用场景
(1)各类热门排序场景
有序列表的底层是如何实现的?
答:当数据比较少时,有序集合是压缩列表ziplist实现的,反之则为跳跃表skiplist实现。使用压缩列表存储必满足以下两个条件:
1有序集合保存的元素个数要小于128个;
2有序集合保存的所有元素成员的长度都必须小于64字节。
如果不能满足以上两个条件中的任意一个,有序集合将会使用跳跃表skiplist结构进行存储。
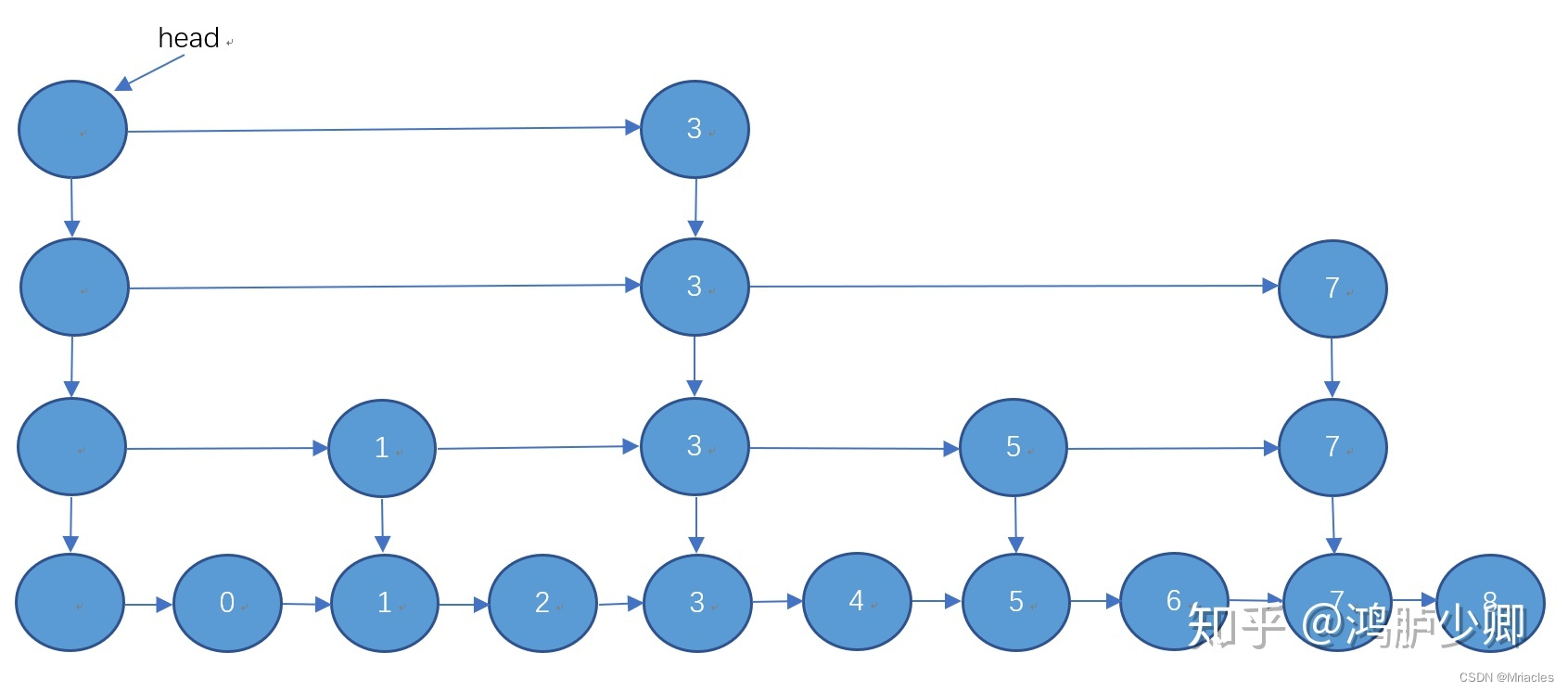
什么是跳跃表
答:跳跃表SkipList,也称之为跳表,是一种数据结构,用于在有序元素的集合中进行高效的查找操作。它通过添加多层链表的方式,提供了一种以空间换时间的方式来加速查找。
跳跃表由一个带有多层节点的链表组成,每一层都是原始链表的一个子集。最底层是一个完整的有序链表,包含所有元素。每个更高层级都是下层级的子集,通过添加额外的指针来跳过一些元素。这些额外的指针称为“跳跃指针”,它们允许快速访问更远的节点,从而减少了查找所需的比较次数。
跳跃表的平均查找时间复杂度为O(logn),其中n是元素的数量。这使得它比普通的有序链表具有更快的查找性能,并目与平衡二叉搜索树(如红黑树)相比,实现起来更为简单。
目录
Redis在Spring中的使用
- 添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis-reactive</artifactId>
</dependency>
- 配置全局文件
# 设置redis的相关信息
# 链接那台redis : 这里拦截的是本地的 - 要开启服务
spring.redis.host = 127.0.0.1
# redis的端口号 : 默认是6379
spring.redis.port = 6379
# 密码没有就空着, 也可以不写
spring.redis.password=
# 默认是16个库
spring.redis.database = 1
#以上是最关键的配置, 其他可以不设置
- 使用Redis来读取
package com.example.demo.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class TestController {
@Autowired
private RedisTemplate redisTemplate;// 自动装配
@RequestMapping("/serval")
public void setval(String val){
redisTemplate.opsForValue().set("test",val);//得到操作redis的类型,(String)
}
@RequestMapping("/getval")
public String getval(){
return (String) redisTemplate.opsForValue().get("test");
}
}
Redis 中为什么单线程比多线程快
Redis使用键值对的方式存储数据, 所以查询的时候很快, 单线程效率完全够用, 如果引入多线程的话, 多个线程抢占一个操作的事情就会发生, 结果效率反而会变慢
Redis的分布式锁如何实现
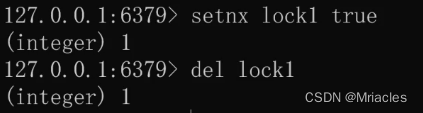
前提启动redis
使用 setnx lock true 命令实现, 如果出现1 则表示加锁成功 , 如果出现0 则表示加锁失败
使用 del lock 释放锁
当一个线程加锁的时候, 其他线程再去尝试加锁就会失败
Redis 分布式锁可能出现的问题
1: 死锁
Redis分布式锁可能出现死锁, 在什么场景下呢. 就是当 一个线程给Redis加上锁之后 ,经历停电, 或是线程崩溃等情况, 那么Redis的锁就释放不掉了,形成了死锁 (在Redis中默认是持久占用的),
解决方案: 给Redis加上超时时间(也是Mysql的解决方法) , 但是 如果 先获取到锁在去设置超时时间 , 这样就变成了俩步操作了 , 依然可能出现问题, Redis 给我们提供了一条原子命令来 完成这俩个操作, 这样俩个步骤合二为一, 就解决了死锁的问题
set lock true ex 30 nx
这里解释下含义 , ex 是设置超时时间 ,nx 是为元素非空判断,用来判断是否能正确使用锁
2: 误删
那误删又是一种什么情况呢, 假设有这么一种情况, 一个线程 上锁 并 设置了超时时间, 但是 当这个 线程 过了超时时间还在使用, 在这个线程A还在使用的时间段中, 线程B 也上锁了 并且锁的名称与线程A之前设置锁的名称一样, 那么当线程A 工作结束, 释放锁的时候, 就有可能 释放掉线程B加的锁.
解决方案 : 给锁加上 版本号 😦 也是ABA问题版本号的解决方案)(也就是给每个锁都加上一个版本号, 释放锁的时候, 先判断一下是不是同一个锁的版本)
1: 使用 lua 脚本,来设置俩个操作的原子性
2: 使用Redisson 框架,(底层也是Lua .只是给你封装了)
Redis保持数据不丢失的方式
1: 快照方式 - RDB : 将某一个时刻的内存数据, 都写入到硬盘之中 : 缺点 - 效率低
2: 追加方式- AOF : 记录所有的操作命令(除了查询操作) , 然后以文本的方式追加到文件中 : 缺点 - 有时会记录很多更新数据, 是无用数据
3: 混合方式 - 结合了 RDB 和 AOF 的优点,在写入的时候,先把当前的数据以 RDB 的形式写入文件的开头,再将后续的操作命令以 AOF 的格式存入文件,这样既能保证 Redis 重启时的速度,又能减低数据丢失的风险
AOF持久化序列的方式有哪些
1: always : 每天Redis的命令都写入硬盘, 最多丢失一条数据
2: everysec : 每秒钟写入一次硬盘, 最多丢失一秒数据(默认持久化策略)
3:no : 不设置,写入硬盘的规则,有当前的操作系统决定什么时候写入 , Linux默认30s
Redis 的内存淘汰策略有哪些
这里简单介绍集中常用的
1: noeviction : 不淘汰任何数据, 当内存不足的时候, 新增操作会报错(默认策略)
2: allkeys - lru : 淘汰最久未使用的键值
3: volite - lru : 淘汰所有设置了过期时间的, 最久未使用的键值














 4944
4944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









