







文章目录
- 《datawhale2411组队学习模型压缩技术1:模型剪枝(上)》:介绍模型压缩的几种技术;模型剪枝基本概念、分类方式、剪枝标准、剪枝频次、剪枝后微调等内容
- 《datawhale11月组队学习 模型压缩技术2:PyTorch模型剪枝教程》:介绍PyTorch的prune模块具体用法
- 《datawhale11月组队学习 模型压缩技术3:2:4结构稀疏化BERT模型》:介绍基于模式的剪枝——2:4结构稀疏化及其在BERT模型上的测试效果
- 《datawhale 2411组队学习 模型压缩4 模型量化理论(数据类型、int8量化方法、PTQ和QWT)》
- 《datawhale 2411组队学习 模型压缩5 神经网络架构搜索》
- 《datawhale 2411组队学习 模型压缩6 :模型蒸馏》
- 《datawhale2411组队学习 模型压缩技术7:NNI剪枝》:介绍了NNI基础的剪枝示例,包括配置剪枝信息配置config_list,微调剪枝模型。第三章中介绍了如何在对Bert base模型进行三段剪枝之后,使用知识蒸馏,恢复被剪枝模型的精度。
整个剪枝过程分为三个步骤:
- 剪枝注意力层(
attention layers)。由于修剪后模型性能下降,使用动态蒸馏(dynamic distiller)进行微调,恢复模型性能(将修剪前后的模型分别作为教师模型和学生模型,将二者Transformer Block每一层都进行对齐蒸馏,实现跨层知识传递);- 剪枝前馈层(
feed forward layers),进一步减少模型的参数量,然后同样使用动态蒸馏进行微调;- 剪枝嵌入层(
embedding layers)。剪枝后学生模型的Transformer Block维度和教师模型不一致,不能再使用动态蒸馏方法。此时要使用自适应蒸馏(adapt_distiller),它会将学生模型和教师模型的每个Transformer Block的输出层添加一个线性层,对齐二者的维度,进行蒸馏(也就是只蒸馏二者的输出层)。
一、 引言
- 项目地址:awesome-compression、在线阅读
神经网络架构搜索(NAS, Neural Architecture Search)是自动化设计神经网络模型的一种技术,它的核心目标是通过算法自动搜索出最优的神经网络架构。随着深度学习技术的广泛应用,模型的性能和效果在很大程度上依赖于网络架构的设计。
传统的神经网络模型往往依赖于手动设计,这不仅需要专家经验,而且耗时耗力。NAS应运而生,它旨在通过自动化手段解决神经网络架构的设计问题。通过设计一个优化框架,NAS能够自动选择出最合适的网络架构,这对于提高深度学习模型的性能和效率具有极大的意义。
二、 基本概念
神经网络架构的设计是一个高度复杂且计算密集的过程,涉及选择合适的层类型、网络深度、连接方式等多个决策变量。NAS不仅仅局限于某一类型的神经网络,它可以用于多种类型的网络架构搜索,包括卷积神经网络(CNN)、循环神经网络(RNN)、强化学习模型等。
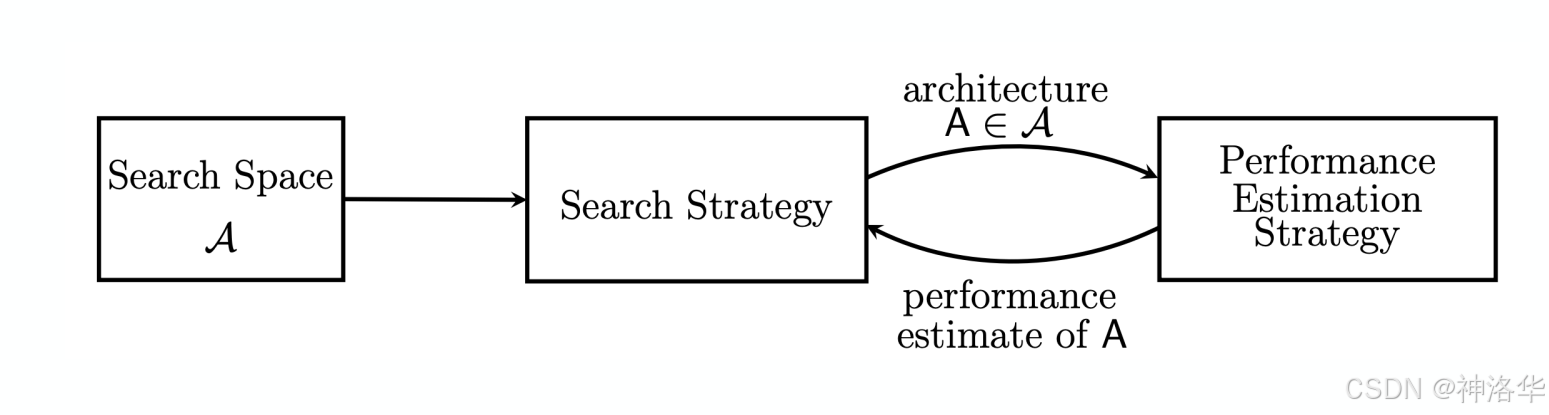
在NAS中,通常需要解决以下几个核心问题:
- 搜索空间:定义可以被搜索的神经网络架构的所有可能组合。
- 搜索策略:通过某种优化算法,探索和评估搜索空间中的不同架构。
- 评估方法:评估每种候选架构的性能,通常使用验证集来估计架构的实际表现。
NAS的基本流程通常分为三个主要步骤:搜索空间的设计、搜索策略的选择和评估策略的定义。每个步骤都是NAS成功的关键。
2.1 搜索空间设计
搜索空间是NAS的基础,它定义了所有可能的网络架构,因此精心设计搜索空间是NAS成功的关键。搜索空间的大小直接决定了搜索的复杂度,一个好的搜索空间能够覆盖大部分有潜力的架构,同时又不会过于庞大和复杂,避免计算成本的爆炸性增长。常见的搜索空间包括:
- 层类型:卷积层、池化层、全连接层、循环层等。
- 层的结构:每个层的具体超参数,例如层数、每层的神经元数、激活函数等。
- 连接方式:比如残差连接(residual connections)、跳跃连接(skip connections)等。
一些NAS方法还引入了单元级搜索空间和网络级搜索空间的概念。前者主要针对不同基础结构进行组合(如卷积核的大小、步幅等),后者主要针对模块/网络进行组合。
2.2 搜索策略
搜索策略决定了如何从定义的搜索空间中有效地选择和生成候选架构。由于搜索空间可能非常大,因此搜索策略需要非常高效,以确保能够在合理的时间内找到最佳架构。常见的搜索策略包括:
- 网格搜索(Grid search):将不同的组合都列出来能够组成一张“网格”,通过在网格上进行搜索,以找到最好的结果。以下图为例,将图像解析度和网络宽度作为搜索变量,对其进行网格化处理,通过数据验证能够得到对应的准确度(如图像分类),则在满足时延限制下的结果进行比较,选择最好的神经网络架构。

- 随机搜索(Random search):随机搜索在网格搜索的基础上打乱搜索顺序,有可能能够更快地找到合适的神经网络架构。

-
强化学习(Reinforcement learning): 对于网格搜索和随机搜索来说,其计算量仍然是巨大的。强化学习(RL)通过一个控制网络(比如下图的RNN)概率采样来生成神经网络架构,然后利用这些架构在目标任务上进行训练和评估,最终根据反馈到控制网络的性能调整生成策略。

-
进化算法(Evolutionary search):模拟生物进化过程,通过选择、交叉和变异操作来逐步改进架构。常见的进化算法有遗传算法(GA)和遗传编程(GP)。
如下图所示,我们希望模型能够既兼顾时延,同时也兼顾准确率。首先,在原来的网络架构中采样出子网络,对其进行训练和评估得到时延和准确率的信息,通过进化算法判断是否需要丢弃还是保留。然后对保留的字网络进行,比如变异,交叉等操作,模拟细胞分裂时基因的行为。最终选择最优的“基因”,即子网络作为最优的神经网络架构结果。

-
贝叶斯优化(Bayesian Optimization):通过建立一个代理模型来估计架构性能,然后使用该模型选择下一组最有可能最优的架构进行评估。
-
梯度下降(Gradient descent):也叫可微分架构搜索。将搜索空间中的每个操作(如卷积、池化等)转化为连续的权重,使得整个搜索空间可微,让网络架构能够像普通神经网络一样进行反向传播和梯度下降优化,最终得到一个最优的子网络架构。

-
超网络(One-shot Model):通过构建一个共享参数的超网络(包含了所有可能的架构)来进行架构搜索,并在这个超网络上一次性地训练所有可能的子网络,大大提升了搜索效率。
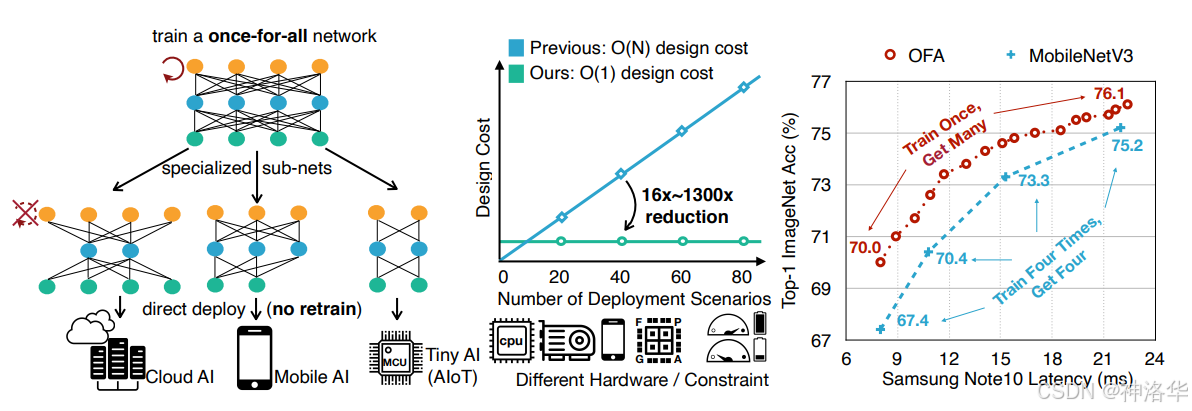
左侧:训练一个单一的一次性训练(Once-for-All)网络,以支持多种架构配置,包括深度、宽度、卷积核大小和分辨率。在给定的部署场景下,可以直接从一次性训练网络中选择一个专用子网络,无需重新训练。中间:这种方法将专用深度学习部署的成本从 O(N) 降低到 O(1)。右侧:一次性训练的网络加上模型选择,可以通过一次训练得到多个准确度-延迟折衷,而传统方法需要重复训练。
-
2.3 评估策略
一旦生成了候选架构,NAS需要评估每个架构的性能。评估策略通常使用验证集来估计每个候选架构在实际任务上的表现。NAS的性能评估通常涉及以下几个方面:
- 验证准确性(Validation Accuracy):在特定任务上的测试结果,如图像分类、目标检测等。
- 搜索效率(Search Efficiency):包括搜索时间、计算资源消耗、内存占用等。
- 架构复杂度:包括模型的参数量、计算量(FLOPs)等。
- 迁移性:搜索出来的架构能否有效迁移到其他任务或数据集。
由于神经网络的训练通常需要消耗大量的计算资源和时间,直接训练每个候选架构通常是不可行的。因此,NAS中的评估策略通常采用以下几种方法:
- 代理模型:使用代理模型(例如,超网络)来预测网络架构的性能,从而避免对每个候选架构进行完整训练。
- 权重共享:对于不同的候选架构,可以共享部分计算资源,如共享前几层的权重,减少训练开销。
- 权重继承:当新的神经网络架构得到的时候,其权重能够从上一个架构继承,使其减少训练成本。
Net2Wider在原始网络基础上进行宽度拓展,其权值也进行了复制,但也要保持输入和输出的一致Net2Deeper在原始网络基础上进行深度拓展,拓宽的模型参数可以从之前的网络中直接映射过去。

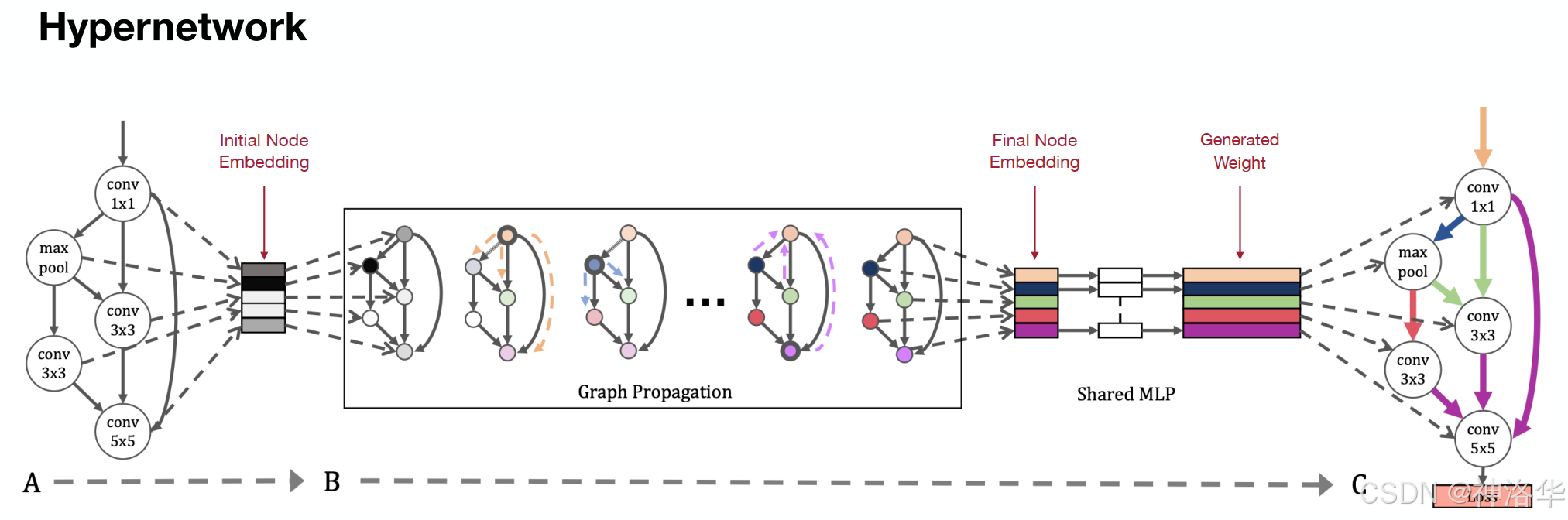
- 超网络:如下图所示。其过程为,在每一个训练阶段,都从搜索空间随机采样一个神经网络架构。利用图传播得到每一个节点的嵌入向量,再利用MLP生成网络参数,最后利用损失函数进行参数优化。所以该网络并不需要额外对其得到的神经网络架构结果进行训练,因为其已经生成了对应的模型参数。
2.4 硬件优化
上述的神经网络架构搜索方法并不针对特殊的硬件进行优化,这种方法相对是昂贵的,比如NASNet在Cifar数据集上需要48,000个GPU小时,在单个GPU下需要运行约5年,DARTS方法直接运行在ImageNet需要100GB的内存。
在实际应用中,不同的设备会有不同的计算速度和存储速度。 为此,就需要针对硬件设备的限制对搜索空间做限制,或者增加“代理任务”(provxy tasks)。


虽然“代理任务”能够降低计算量,但这种方法会损失部分精度,ProxylessNAS通过一个超网络直接在硬件平台上进行端到端的架构搜索。该方法构建一个过量参数的模型,在单个训练过程中采样对应的NAS架构对模型参数进行训练,在架构参数上剪枝掉额外的路径。最后将架构参数二值化,使其只有一条路径是活动的,此时的内存就从O(N)下降到O(1)。ProxylessNAS 避免了常规的代理模型的使用,实现了高效的硬件适配,同时避免了代理模型引入的误差。

2.4 NAS的主要挑战
尽管NAS能够为神经网络架构设计提供自动化的解决方案,但在实际应用中仍然面临着一些挑战。
-
计算开销巨大
NAS通常需要训练大量的候选架构,而每个架构的训练都可能需要大量的计算资源。尽管已经有一些方法(如权重共享、快速训练等)尝试缓解这一问题,但计算开销依然是NAS面临的一个重大挑战。 -
搜索空间设计困难
如何设计一个合理的搜索空间是NAS中的一个关键问题。过于复杂的搜索空间可能导致搜索效率低下,而过于简单的搜索空间则可能无法探索到有潜力的网络架构。 -
泛化能力差
NAS通常依赖于一定的数据集进行搜索,但某些在特定数据集上表现良好的架构,可能并不适用于其他数据集或任务。因此,如何确保NAS搜索到的架构具有较好的泛化能力是一个亟待解决的问题。
三、 NAS的发展历程和主要流派
3.1 基于强化学习的NAS方法
最早的NAS工作可以追溯到2017年,Barret Zoph 和 Quoc V. Le提出的Neural Architecture Search with Reinforcement Learning这篇论文,开启了NAS的研究热潮。该方法使用强化学习(RL)作为搜索策略,通过一个控制网络来生成神经网络架构,然后利用这些架构在目标任务上进行训练和评估,最终根据性能反馈调整生成策略。
- 搜索空间:作者定义了一个基于卷积神经网络的搜索空间,包括卷积层、全连接层、池化层等。
- 控制器:使用LSTM作为控制器,该控制器输出网络架构的选择(例如卷积核大小、步幅等)。
- 奖励机制:每当一个架构被生成并训练后,模型的准确率或损失作为奖励反馈给LSTM控制器,以调整下一步的架构选择。
Zoph等人(2018)提出了NASNet,主要贡献是设计了一个新的架构搜索空间(NASNet Search Space,卷积操作和池化操作),核心思想是在小数据集(如 CIFAR-10)上搜索高效的基础单元(cell),再将其迁移到大数据集(如 ImageNet)中,通过堆叠这些单元构建复杂的神经网络。
NASNet在ImageNet上超越了许多传统的卷积神经网络架构,取得了接近人类设计的性能(Top-1 准确率提升至82.7%),还被成功迁移到其他任务中,表现出强大的可迁移性(使用Faster-RCNN 框架在COCO目标检测数据集中,取得43.1%的 mAP)。
ENAS(Efficient Neural Architecture Search)是2018年由Google Brain提出的一种基于强化学习的NAS方法,但与传统的RL-based NAS方法不同,ENAS引入了一个显著的优化技巧:权重共享机制。
在ENAS中,通过一个控制网络(LSTM)生成不同的子网络架构(即不同的操作序列),所有子网络共享同一组权重,这样模型在进行架构搜索时,所有候选架构都基于相同的权重进行训练,而不是为每个架构单独训练一组新的权重,从而避免了每次评估时从头训练模型的计算成本。这种方法大大减少了计算资源的消耗,加快了搜索过程。
在CIFAR-10数据集上,ENAS设计的架构测试错误率为2.89%,与NASNet的2.65%相当,但计算成本远低于后者。

上表表第一部分展示了由人类专家设计的最先进架构之一,DenseNet。第二部分展示了尝试设计完整卷积网络的方法的性能,以及这些方法发现最终模型所需的GPU数量和时间。第三部分展示了尝试设计一个或多个模块化单元(cell),然后将它们组合成最终网络的方法的性能。
比如ENAS仅需11.5小时即可发现卷积单元和降维单元(见图8)。将卷积单元重复N=6次(参考图4),ENAS在CIFAR-10上的测试错误率为3.54%。使用CutOut技术后,ENAS的错误率进一步降低至2.89%。
3.2 基于进化算法的NAS方法
进化算法(Evolutionary Algorithms, EA) 是一种受生物进化启发的优化算法,通过模拟选择、交叉、变异等操作,逐步逼近问题的最优解。其优势在于能够在复杂的、高维的搜索空间中寻找全局最优解,在搜索神经网络架构时具有较好的全局搜索能力和鲁棒性。
进化算法在NAS中的应用一般包括以下几个主要步骤:
- 初始化种群:随机生成一组不同的神经网络架构,作为“初始种群”。
- 适应度评估:对每个网络架构进行训练和评估(如验证集精度),得到适应度分数。
- 选择操作:根据适应度对种群进行选择,选出表现较好的架构作为父代。
- 交叉操作:将选择出来的架构进行组合和变异,产生新的网络架构。
- 变异操作:对现有的网络架构进行小的修改,可能是改变网络层的类型、数量或者超参数等。
- 更新种群:将新产生的架构加入种群,并进行下一轮的选择和变异操作。
Real等人在《Large-Scale Evolution of Image Classifiers》中提出了基于进化算法的NAS方法,采用遗传算法(GA)来自动搜索卷积神经网络架构。在ImageNet分类任务中,该方法取得了与手工设计网络相当的效果(在 CIFAR-10 和 CIFAR-100的准确率达到 94.6%和 77.0%) ,且能够高效地探索较大的架构空间。
2018年, Liu等人提出渐进式神经架构搜索(PNAS,Progressive Neural Architecture Search ),通过序列模型优化(SMBO) 策略,逐步搜索最优的网络架构(按照网络结构的复杂度,从简单到复杂逐步搜索架构,而不是一次性搜索整个结构空间),同时使用代理模型来预测不同网络架构的性能,从而引导搜索过程。论文显示,PNAS比NASNet在评估模型的数量上效率高出5倍,在总计算时间上快8倍。

3.3 基于梯度优化的NAS方法
随着深度学习的广泛应用和神经网络架构的复杂性增加,基于梯度优化的NAS方法逐渐受到关注。相比于进化算法,可微分架构搜索(Differentiable NAS)能够通过梯度下降策略更加高效地搜索架构,并且能够直接借用现有的深度学习框架,如TensorFlow或PyTorch进行训练。
DARTS (Differentiable Architecture Search, 2018)是基于梯度优化的NAS方法中的一个突破性工作。DARTS的搜索空间表示为一个超网络(supernet),这个超网络包含了许多可能的子网络架构。DARTS的关键创新在于,它将搜索空间中的每个操作(如卷积、池化等)转化为连续的权重(同时共享权重),使得整个搜索空间可微,让网络架构能够像普通神经网络一样进行反向传播和梯度下降优化。通过梯度下降方法优化这些权重,最终得到一个最优的子网络架构。
SNAS(Stochastic Neural Architecture Search)通过在DARTS的基础上引入随机性的因素,使得搜索过程更加稳健,避免了DARTS中可能出现的“过拟合”现象。
3.4 基于贝叶斯优化的NAS方法
贝叶斯优化(Bayesian Optimization)是一种用于全局优化的概率模型方法,特别适用于计算代价高昂的黑盒优化问题。在NAS中,贝叶斯优化被用来智能地选择网络架构,减少计算开销。其主要流程为:
- 构建代理模型:建立一个代理模型来近似评估架构的性能,通常是高斯过程回归模型(Gaussian Process, GP)。
- 选择架构:根据代理模型的预测结果选择下一个待评估架构,通常采用“最大化采集函数”的方式,即选择最不确定或者最有可能提升性能的架构。
- 评估与更新:对选中的架构进行训练,获取其实际性能,并用该结果更新代理模型。
- 迭代优化:重复上述过程,直到找到最优的网络架构。
Snoek等人在《Practical Bayesian Optimization of Machine Learning Algorithms,2012》中提出了使用贝叶斯优化来优化机器学习算法超参数的工作,括如何选择先验知识、如何设计采集函数(acquisition function),以及如何实现有效的优化策略。
Kandasamy等人在《Neural Architecture Search with Bayesian Optimisation and Optimal Transport,2018》中将贝叶斯优化与最优传输相结合,通过建立高效的代理模型,成功优化了神经网络架构。
-
贝叶斯优化:利用高斯过程(Gaussian Process)等概率模型来预测不同架构的性能,并选择最有潜力的架构进行评估。
-
最优传输:在NAS中,最优传输理论可以用来比较和选择不同的神经网络架构。通过计算架构之间的距离,可以量化它们的差异,并优化架构搜索过程,使得搜索更加高效和目标明确。
3.5 超网络(One-shot Model)
超网络(SuperNet),又常被称为One-shot model,其核心思想是训练一个“超网络”,该网络包含了所有可能的架构(即候选架构的参数化表示)。“超网络”通过将不同的网络架构作为一个共享参数化模型(代理模型)来进行搜索,可以在一次训练过程中同时评估多个架构,不需要为每个候选架构单独训练一个独立的模型,显著提高了架构搜索的效率和可扩展性。
-
DARTS
DARTS是超网络方法的代表性工作之一。它通过对架构搜索空间进行连续化,使得架构的优化变得可微分,从而可以通过梯度下降优化架构。在此过程中,DARTS通过共享权重的方式显著减少了计算开销,并通过权重共享来同时搜索多个架构。 -
MnasNet
MnasNet是Google提出的一种基于超网络的NAS方法,结合了强化学习与多目标优化。通过引入基于资源约束的目标(如计算量、延迟等),在搜索过程中同时优化计算资源和准确率,使得搜索的结果更加适应移动设备等计算受限的环境。 -
ProxylessNAS
在传统的NAS方法中,通常会使用代理模型来减少计算开销,但这种方法会损失部分精度。ProxylessNAS 通过一个超网络来进行端到端的架构搜索,避免了常规的代理模型的使用,直接在硬件平台上进行进行搜索,实现了高效的硬件适配,同时避免了代理模型引入的误差。
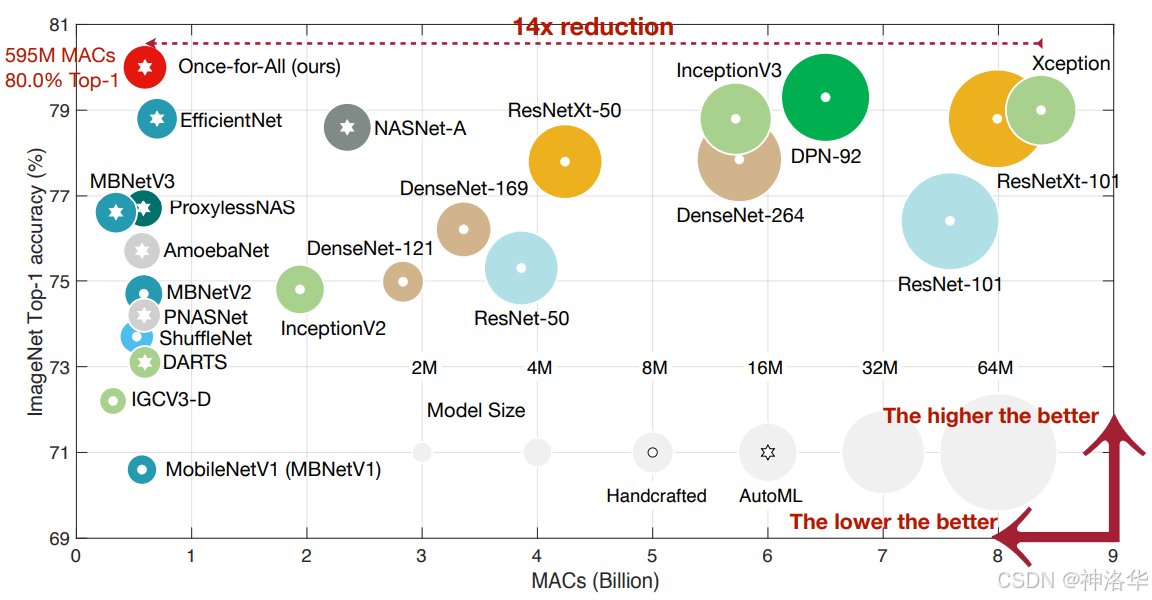
Once-for-All (OFA) 也通过一个超网络来训练多个架构,并且通过权重共享来提高搜索效率。然而,OFA 的独特之处在于它强调一次训练适应多种硬件环境,通过解耦训练和搜索,生成具有不同计算复杂度和资源需求的子网络(一个离散的、大规模的候选子网络),并通过微调进行适配,快速得到专用网络,而无需额外训练。因此,OFA 在训练过程中的效率更高。
为了高效训练,OFA 提出了一种新颖的渐进式缩减算法,这种方法能在多个维度(如深度、宽度、卷积核大小、分辨率)上减少模型大小,比传统剪枝方法更具优势。
OFA在多个边缘设备上表现优异,超越了最先进的NAS方法。在ImageNet上,相较于MobileNetV3提高了最多4.0%的Top-1准确率,或在相同准确率下推理速度快1.5倍。在与EfficientNet的延迟比较中,OFA速度快2.6倍。在移动设备中(600M MACs),达到了80.0%的ImageNet Top-1准确率。
Once-for-All提供了代码和50个预训练模型,适用于多种设备和延迟约束,代码见once-for-all。
四、NAS的主要成果与应用
4.1 计算机视觉
-
图像分类
图像分类是计算机视觉中的经典任务之一,NAS在该领域的应用主要集中在优化卷积神经网络(CNN)的架构。通过NAS,研究人员能够发现比手工设计更优的网络架构,从而提升图像分类的精度和效率。- NASNet (Zoph et al., 2017):Zoph等人提出的NASNet是基于强化学习的架构搜索方法,在ImageNet分类任务中获得了比现有手工设计网络更优的性能。
- MobileNetV3(Andrew et al., 2019):MobileNet 是一种为移动设备和嵌入式系统设计的轻量级卷积神经网络(CNN)架构。它通过使用深度可分离卷积来显著减少模型的计算量和参数,从而使得其适合在计算资源有限的设备上运行。在MobileNetV3的开发中,强化学习和神经架构搜索被结合使用,进一步优化了网络架构。
- MobileNetV3的搜索空间包括了不同的卷积操作类型(例如标准卷积、深度可分离卷积)和不同的网络结构(如瓶颈层、非线性激活函数等)
- EfficientNet (Tan & Le, 2019):EfficientNet通过NAS和复合缩放策略,找到了一个高效的网络架构,使得模型在图像分类任务中以较少的计算量取得了更好的效果。
-
目标检测与实例分割
NAS能为实时检测任务提供高效架构,适应不同的硬件平台,进一步提升检测速度。- NAS-SSD (Tan et al., 2019):NAS-SSD利用NAS优化了单阶段目标检测网络,结合了卷积层和目标检测任务的特定需求,获得了更好的检测精度。
- Auto-DeepLab (Chen et al., 2019):DeepLab系列网络采用深度卷积神经网络(CNN)架构来进行语义分割。Auto-DeepLab通过NAS对DeepLab架构进行优化,搜索到了一个针对语义分割任务优化的网络架构,该架构在多个标准数据集上表现出了优异的性能,尤其在实时性和精度之间找到了良好的平衡。
4.2 Once-for-All模型
- 在NLP上的应用
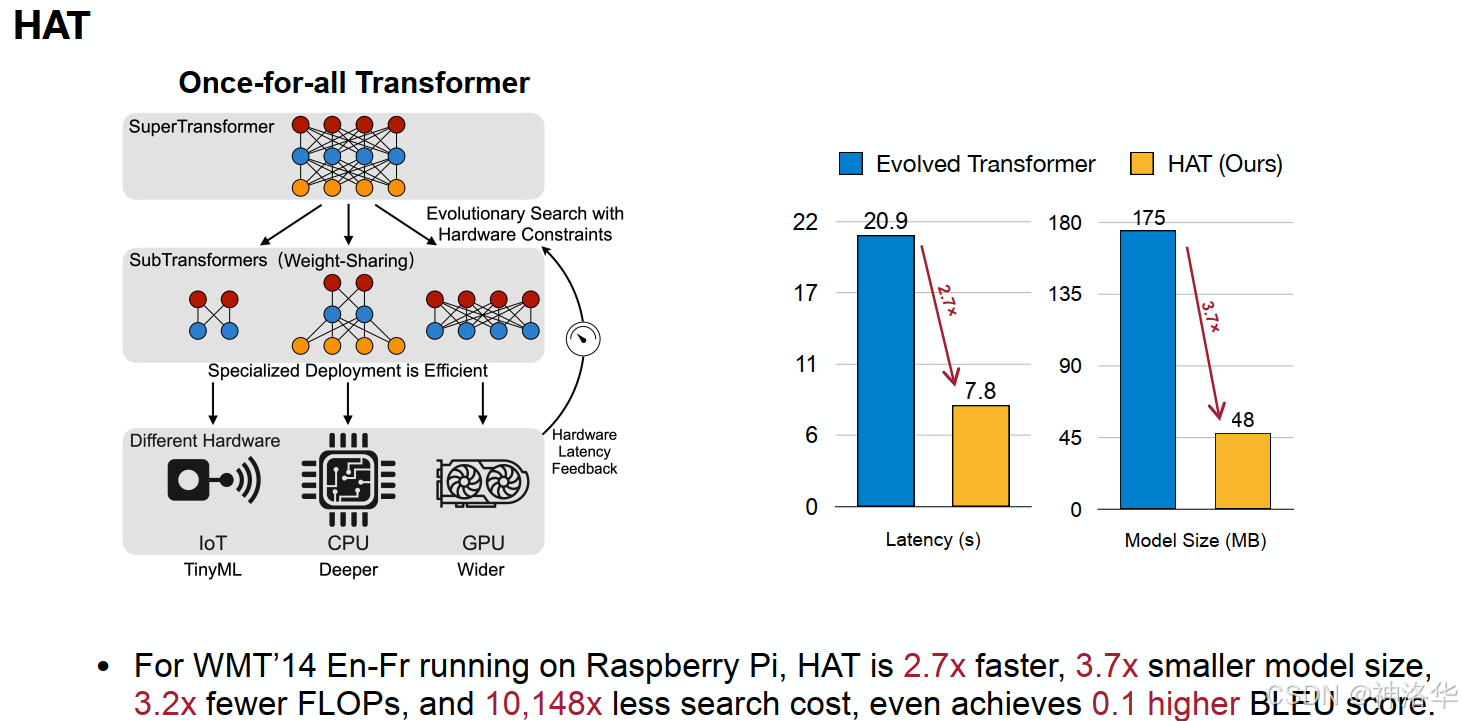
从上图可以看到,通过对Transformer进行架构搜索,能够在不同的设备上进行运行,使得模型的时延和大小都能够大幅度下降。
-
点云理解的应用
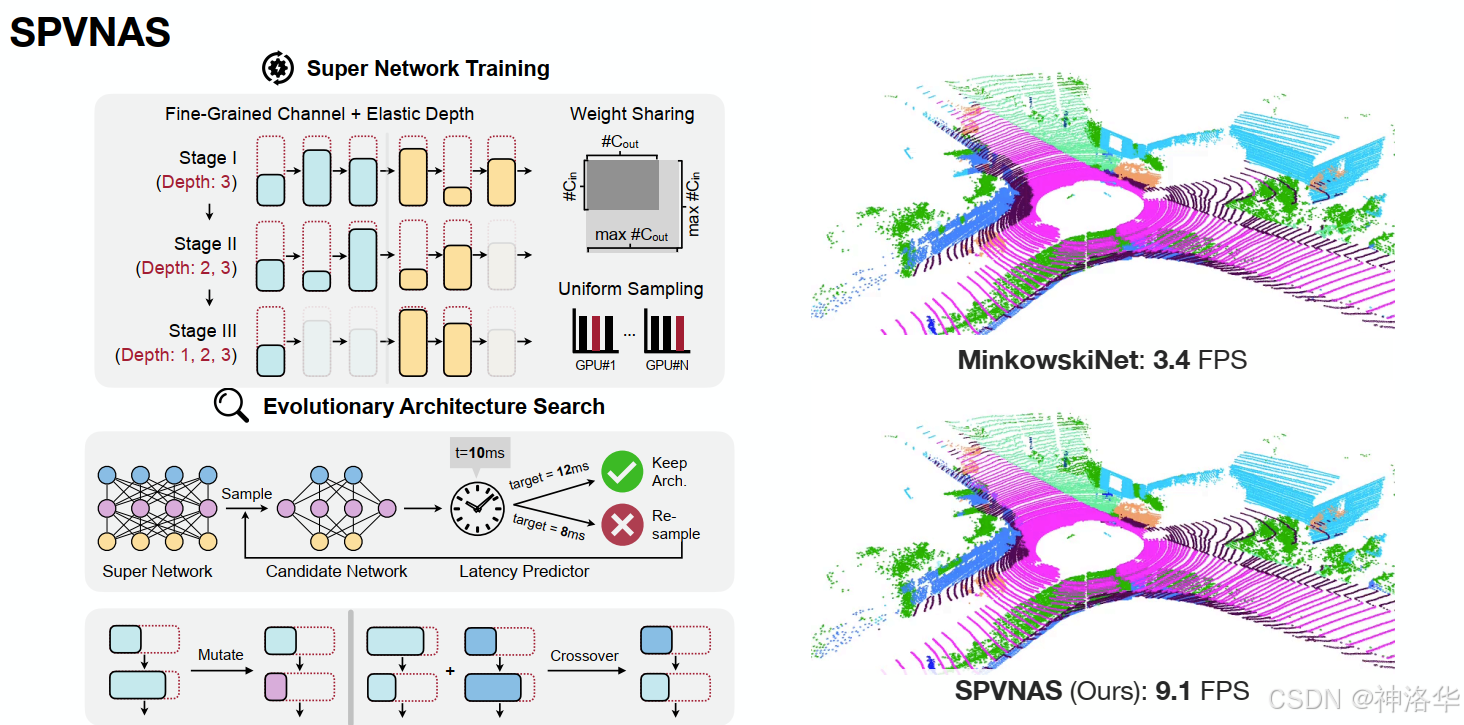
-
GAN生成的应用。 该方法能够在不同设备上使用,同时保持能够接受的时延。

-
姿态检测
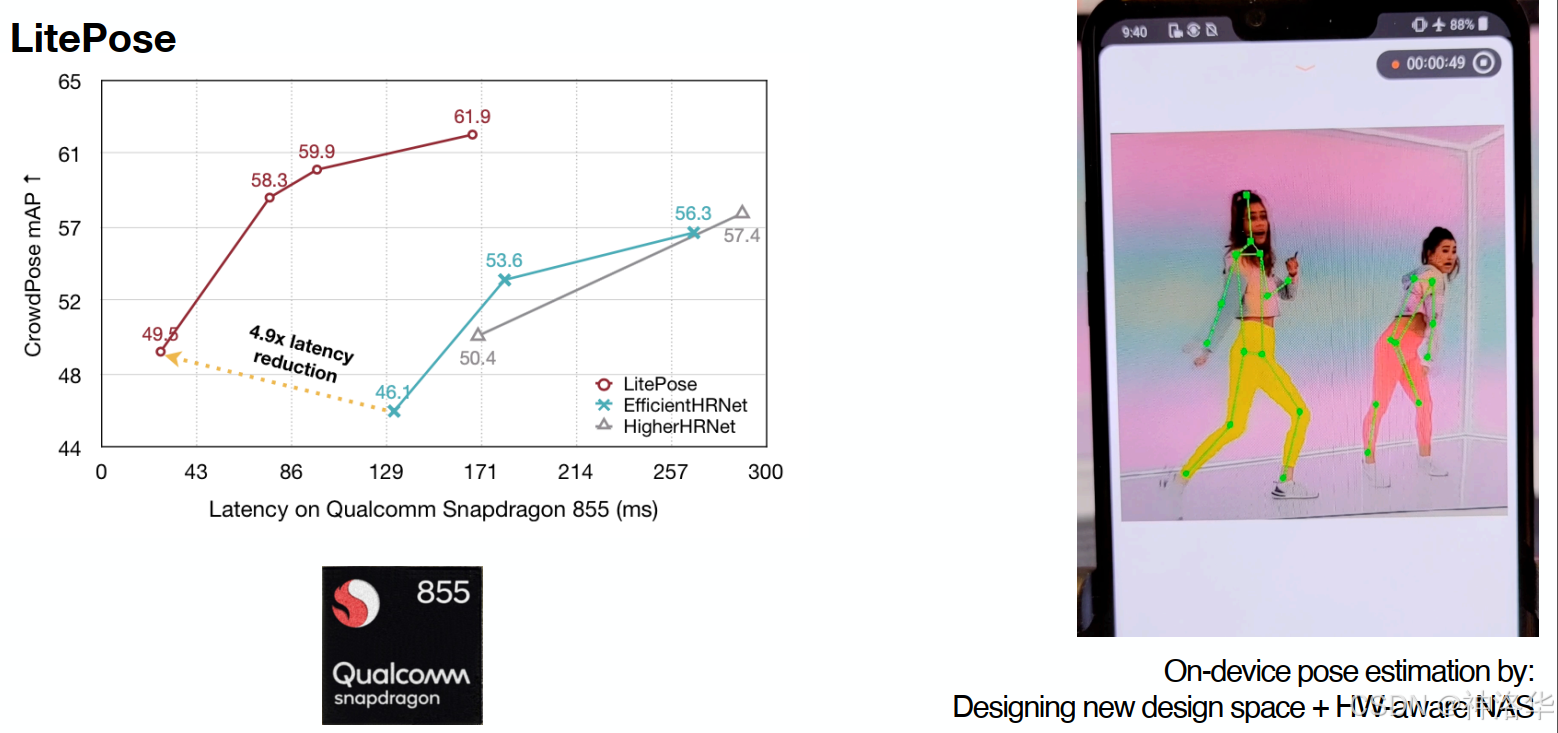



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











