







1.yolo与其他神经网络的不同之处:
YOLO将物体检测作为回归问题求解。基于一个单独的end-to-end网络,完成从原始图像的输入到物体位置和类别的输出。从网络设计上,YOLO与rcnn、fast rcnn及faster rcnn的区别如下:
[1] YOLO训练和检测均是在一个单独网络中进行。YOLO没有显示地求取region proposal(下采样)(翻译为区域提案)的过程。而rcnn/fast rcnn 采用分离的模块(独立于网络之外的selective search方法)求取候选框(可能会包含物体的矩形区域),训练过程因此也是分成多个模块进行。Faster rcnn使用RPN(region proposal network)卷积网络替代rcnn/fast rcnn的selective
search(可选择的搜索)模块,将RPN集成到fast rcnn检测网络中,得到一个统一的检测网络。尽管RPN与fast rcnn共享卷积层,但是在模型训练过程中,需要反复训练RPN网络和fast rcnn网络(注意这两个网络核心卷积层是参数共享的)。

faster-rcnn神经网络
(解释:利用regin proposal的提取出一个框架,然后计算出p值,如果p值大于一定的值,然后才会把这个框架进行下一步操作ROI pooling)
2
YOLO将物体检测作为一个回归问题进行求解,输入图像经过一次inference,便能得到图像中所有物体的位置和其所属类别及相应的置信概率。而rcnn/fast rcnn/faster rcnn将检测结果分为两部分求解:物体类别(分类问题),物体位置即bounding box(回归问题,优化)。
由于yolo v3发生巨大的改善,所以这里就从yolo v3开始解释
yolov3检测分两步:
1、确定检测对象位置
2、对检测对象分类(是什么东西)
即在识别图片是什么的基础上,还需定位识别对象的位置,并框出
(与RCNN/Fast rcnn/fater rcnn不同的地方)
首先一张图片传进yolo,yolo会将其转化为416×416大小的网格
1.首先,理解一下框的基本信息:中点的坐标(x,y)
和框的大小(w,h),confidence(置信度);
2.框架的类型:
3种
大物体:13×13
中物体:26*26
小物体:52*52
3.详细过程:
yolov3主干网络为Darknet53,重要的是使用了残差网络Residual,darknet53的每一个卷积部分使用了特有的DarknetConv2D结构,每一次卷积的时候进行l2正则化( 如果不知道,可以看补充),完成卷积后进行BatchNormalization标准化(将数据规定在一定的数值范围)与LeakyReLU激活函数
(由于darknet 和 resnet 思路一样,所以这里解释残差神经网络:(Resnet)
resnet学习的是残差函数F(x) = H(x) - x
残差模块:

将原来的数据块x,经过weight处理,然后将未经过处理的数据块,二个concat(拼接)
,这样做的好处是
用梯度下降算法训练一个神经网络,若没有残差,会发现随着网络加深,训练误差先减少后增加,理论上训练误差越来越小比较好。而对于残差网络来讲,随着层数增加,训练误差越来越减小,这种方式能够到达网络更深层,有助于解决梯度消失和梯度爆炸的问题,让我们训练更深网络同时又能保证良好的性能
这里展现一下resnet的shortcut的效果:
这样做可以减少损失

)
物体检测:
1、yolov3提取多特征层进行目标检测,一共提取三个特征层,三个特征层位于主干特征提取网络darknet53的不同位置,分别位于中间层,中下层,底层,三个特征层的shape分别为(52,52,256)、(26,26,512)、(13,13,1024),这三个特征层后面用于与上采样后的其他特征层堆叠拼接(Concat)
2、第三个特征层(13,13,1024)进行5次卷积处理(为了特征提取),处理完后一部分用于卷积+上采样UpSampling,另一部分用于输出对应的预测结果(13,13,75),用于小物体检测,Conv2D 3×3和Conv2D1×1两个卷积起通道调整的作用,调整成输出需要的大小。
3、卷积+上采样后得到(26,26,256)的特征层,然后与Darknet53网络中的特征层(26,26,512)进行拼接,得到的shape为(26,26,768),再进行5次卷积,处理完后一部分用于卷积上采样,另一部分用于输出对应的预测结果(26,26,75),用于中物体检测,Conv2D 3×3和Conv2D1×1同上为通道调整
4、之后再将3中卷积+上采样的特征层与shape为(52,52,256)的特征层拼接(Concat),再进行卷积得到shape为(52,52,128)的特征层,最后再Conv2D 3×3和Conv2D1×1两个卷积,得到(52,52,75)特征层,用于大物体
最后图中有三个红框原因就是有些物体相对在图中较大,就用13×13检测,物体在图中比较小,就会归为52×52来检测
预测结果的选择:
预测结果解码原因:预测结果(红框)并不对应着最终的预测框在图片上的位置,还需要解码)
yolov3的预测原理是分别将整幅图分为13x13、26x26、52x52的网格,每个网络点负责一个区域的检测。解码过程就是计算得出最后显示的边界框的坐标bx,by,以及宽高bw,bh,这样就得出了边界框的位置,计算过程如图(b–为bounding box 缩写)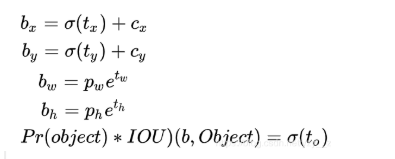
(cx,cy):该点所在网格的左上角距离最左上角相差的格子数。
(pw,ph):先验框的边长
(tx,ty):目标中心点相对于该点所在网格左上角的偏移量
(tw,th):预测边框的宽和高
σ:激活函数,这里用的是sigmoid函数,[0,1]之间概率,之所以用sigmoid取代之前版本的softmax,原因是softmax会扩大最大类别概率值而抑制其他类别概率值 ,图解如下
注:最终得到的边框坐标值是bx,by,bw,bh.而网络学习目标是tx,ty,tw,th。
另外cy向下此处为正向
这里也讲一下,softmax和softmoid二个函数的区别,不如直接看图像来的清楚,
softmaxy函数

softmoid函数

sofmax函数不如softmoid函分的更加清楚,明了
对预测出的边界框架得出排序与非极大预制筛选
这步就是将最大概率的框筛选出来
IoU 计算的是 “预测的边框” 和 “真实的边框” 的交集和并集的比值,利用iou进行排序,取最大值的框
1、取出每一类得分大于一定阈值的框和得分进行排序。
2、利用框的位置和得分进行非极大抑制。最后可以得出概率最大的边界框,也就是最后显示出的框
补充:focus模块:
下采样
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
# return self.conv(self.contract(x))
Conv模块作用:
对输入的特征图执行卷积,BN,激活函数操作,在新版的YOLOv5中,作者使用Silu作为激活函数.
class Conv(nn.Module):
# Standard convolution
# ch_in, ch_out, kernel, stride, padding, groups
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
# k为卷积核大小,s为步长
# g即group,当g=1时,相当于普通卷积,当g>1时,进行分组卷积。
# 分组卷积相对与普通卷积减少了参数量,提高训练效率
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.Hardswish() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
Bottleneck模块
作用:
先将channel 数减小再扩大(默认减小到一半),具体做法是先进行1×1卷积将channel减小一半,再通过3×3卷积将通道数加倍,并获取特征(共使用两个标准卷积模块),其输入与输出的通道数是不发生改变的。
shortcut参数控制是否进行残差连接(使用ResNet)。
在yolov5的backbone中的Bottleneck都默认使shortcut为True
与ResNet对应的,使用add而非concat进行特征融合,使得融合后的特征数不变。
SPP模块
作用:
SPP是空间金字塔池化的简称,其先通过一个标准卷积模块将输入通道减半,然后分别做kernel-size为5,9,13的maxpooling(对于不同的核大小,padding是自适应的)。
对三次最大池化的结果与未进行池化操作的数据进行concat,最终合并后channel数是原来的2倍。
class SPP(nn.Module):
# Spatial pyramid pooling layer used in YOLOv3-SPP
def __init__(self, c1, c2, k=(5, 9, 13)):
super(SPP, self).__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
正则化:
- 为什么要正则化:让模型不要过于依赖样本数据
- 正则化主要思想:降低模型的复杂度
- 正则化主要目的:防止模型过拟合
- 正则化实现思路:最小化损失Loss+ 最小复杂度
- 正则化终极目标:提升模型泛化Generalization的能力

- 正则化有不同的策略,目前来讲主要有参数正则化、经验正则化
1.参数正则化
参数正则的L2/L1 Regularization 范数正则化目前用的是最多的。。。
参数正则化方法的核心主要是对损失函数Loss Function 添加惩罚项 Penalty:
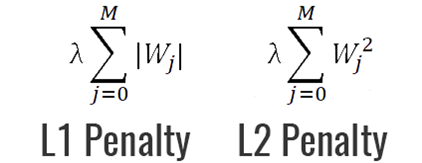
L2/L1正则化都是通过添加一个惩罚项,来调节模型参数(权重w),使loss最小,(例如w一开始数值大,则loss会变大,则在反向传播每次更新权重时,就会对这个w进行惩罚,既降低w,直到模型认为loss已经最优)
yolo中需要转化格式:在yolov5训练之前可能要用到的几个脚本_PH影子呀的博客-CSDN博客














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









