







requests与selenium对比
requests
requests是一个python的第三方库,用来做爬虫项目等,以我小白的理解,我觉得它比scrapy简单不少。
接下来,让我们对它来个简单的使用吧,以QQ空间为例。
1,获取响应头,进行UA伪装:
我们只需要打开网页,然后按下F12,便会获得以下界面:
按下CTRL+R,如下:

随便点击一个,下滑找到这东西:
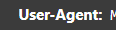
然后复制下来。
2,获取网页的整个页面数据
我们找到网址,然后复制网址之后进行代码的编写
导入相关模块,然后把准备好的参数填进去:
import requests
headers={
'Mozilla':'5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.38'
}
url='https://user.qzone.qq.com/此处键入QQ号码/infocenter'
编写如下代码:
page=requests.get(url=url,headers=headers)
page.text
我们就请求到了QQ空间的网页源码:

xpath解析
接下来,我们来进阶一下,我们尝试去解析一下QQ空间的第一条说说的文本内容。
xpath是解析网页的一个工具,当然,常用的解析工具可不止这个,还有re(正则)和BeautifulSoup(bs4)之类的。
xpath的基本使用如下:
from lxml import etree
tree=etree.HTML()
page_text=tree.xpath('此处填写xpath表达式')
print(page_text)
那么,我们来共同看一下怎么编写xpath表达式:
xpath中,一个‘/’表示一层目录,相应地,’//‘就表示多层目录,所以我们只需要使用一个或多个’/‘就可以自由的在网页文件穿梭。当到达你想要的标签后,只需要编写"[@标签名=标签]",如果一开始就要引用到标签位置的话,就需要在标签前面加上’",例如:"//[@name=name]"。
然后解析文本时候,到达标签位置,如果想解析当前标签下文本,就只需要编写如下’/text()’,如果想查看当前标签下的所有文本(也就是子标签的文本),就需要’//text()’
那么,接下来就尝试一下使用requests加xpath解析QQ空间的第一条说说文本内容:
tree=etree.HTML(page)
page_text=tree.xpath('//*[@id="feed_532779964_311_0_1635564302_0_1"]/div[1]//text()')
page_text
利用我们的xpath基本使用的代码,然后接入上面的QQ空间源码,。
ps:这里的xpath表达式可以快速生成,你只需要定位到标签:

点击这个图标开始定位,找到第一条说说,然后如下:
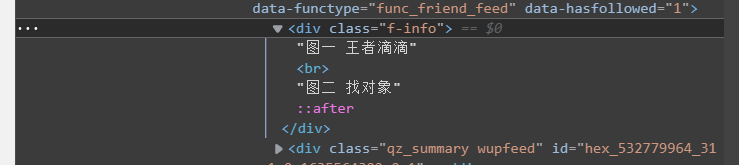
然后右键复制,复制下path,就获得了xpath表达式。最后添加读取文本的//text()即可。
最终的源码:
import requests
from lxml import etree
headers={
'Mozilla':'5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.38'
}
url='https://user.qzone.qq.com/此处填写QQ号/infocenter'
page=requests.get(url=url,headers=headers)
page=page.text
tree=etree.HTML(page)
page_text=tree.xpath('//*[@id="feed_532779964_311_0_1635564302_0_1"]/div[1]//text()')
page_text
查看一下输出:
可以发现是[],为什么没解析到呢?这就是网站的机制了。所以我们需要使用自动化模块来模拟人点击,最后获得输出。
selenium
selenium是一个自动化模块,可以模拟人的点击,从而获得一些动态加载的文本或图像。
使用selenium之前,我们需要怎么做呢?
1,安装浏览器驱动
我们点击浏览器右上角三个点,设置,关于然后查看我们的浏览器版本

然后去到驱动下载网站下载相应版本的浏览器驱动(版本一定要相同):
浏览器驱动网站
下载之后把驱动放到edge的application文件夹,我的路径就是C:\Program Files (x86)\Microsoft\Edge\Application,应该windows都是一样。然后解压,复制该路径。
2,selenium代码的编写(模拟登录QQ空间)
在使用selenium过程中,我们一般导入time库,使页面看起来连贯
from selenium import webdriver
from time import sleep
bro=webdriver.Edge(executable_path="此处填写浏览器驱动的路径")
我们开始编写登录QQ空间的代码:
bro.get('https://qzone.qq.com/')
我们先对网站发起请求,然后有一个值得注意的点:iframe标签,遇到这个标签我们应该编写如下代码:
bro.switch_to.frame('login_frame')
不然会出现selenium无法定位标签的现象。
然后我们开始定位:
找到账号密码登录的标签,点击。
找到输入账户号标签,点击。
找到输入密码标签,点击。
最后点击登录。
tag=bro.find_element_by_id('switcher_plogin')
tag.click()
Name=bro.find_element_by_id('u')
Password=bro.find_element_by_id('p')
Name.send_keys('此处输入QQ号')
sleep(2)
Password.send_keys('此处输入QQ密码')
sleep(2)
btn=bro.find_element_by_id('login_button')
btn.click()
这里的标签定位方法全部使用的是:
bro.find_element_by_id()
然后输入数值使用的是:
Password.send_keys('')
最近的QQ空间登录没有滑动验证了,如果需要滑动验证,我们就需要导入动作链,由于没有滑动验证,我们不再过多赘述。
# from selenium.webdriver import ActionChains
# sleep(2)
# #注意标签的iframe,不然会定位失败
# bro.switch_to.frame('tcaptcha_iframe')
# #div=bro.find_element_by_class_name('tc-drag-thumb')
# div=bro.find_element_by_id('tcaptcha_drag_thumb')
# #构造动作链
# action=ActionChains(bro)
# #点击且长按
# action.click_and_hold(div)
# for i in range(2):
# #move_by_offset()
# action.move_by_offset(58,0).perform()#立即执行动作链
# sleep(0.2)
# #点击一下,登录成功
# div.click()
# sleep(5)
# #动作链释放
# action.release()
# #bro.quit()
3,解析第一条说说
我们导入xpath模块:
from lxml import etree
然后跟requests模块一样,开始解析:
page_text=bro.page_source
tree=etree.HTML(page_text)
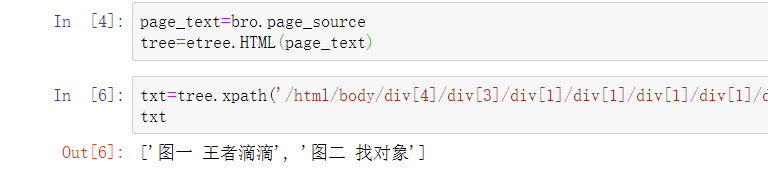
编写xpath表达式,输出爬取到的文本:
txt=tree.xpath('/html/body/div[4]/div[3]/div[1]/div[1]/div[1]/div[1]/div[3]/div[2]/div/div/ul/li[1]/div[2]/div/div[1]//text()')
txt
查看输出:
然后查看QQ空间,看看是否一致:

源码:
from selenium import webdriver
from selenium.webdriver import ActionChains
from time import sleep
bro=webdriver.Edge(executable_path="C:\Program Files (x86)\Microsoft\Edge\Application\msedgedriver")
bro.get('https://qzone.qq.com/')
bro.switch_to.frame('login_frame')
tag=bro.find_element_by_id('switcher_plogin')
tag.click()
Name=bro.find_element_by_id('u')
Password=bro.find_element_by_id('p')
Name.send_keys('你的QQ号')
sleep(2)
Password.send_keys('你的密码')
sleep(2)
btn=bro.find_element_by_id('login_button')
btn.click()
# sleep(2)
# #注意标签的iframe,不然会定位失败
# bro.switch_to.frame('tcaptcha_iframe')
# #div=bro.find_element_by_class_name('tc-drag-thumb')
# div=bro.find_element_by_id('tcaptcha_drag_thumb')
# #构造动作链
# action=ActionChains(bro)
# #点击且长按
# action.click_and_hold(div)
# for i in range(2):
# #move_by_offset()
# action.move_by_offset(58,0).perform()#立即执行动作链
# sleep(0.2)
# #点击一下,登录成功
# div.click()
# sleep(5)
# #动作链释放
# action.release()
# #bro.quit()
from lxml import etree
page_text=bro.page_source
tree=etree.HTML(page_text)
txt=tree.xpath('/html/body/div[4]/div[3]/div[1]/div[1]/div[1]/div[1]/div[3]/div[2]/div/div/ul/li[1]/div[2]/div/div[1]//text()')
txt
那么,我们的爬虫自动化爬取QQ空间就完成了。















 1211
1211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









