






在上篇博文中我们已经简单介绍了docker的层级架构,现在将Host OS进一步划分为Host OS kernel与Host OS User Space对其进行介绍:
最底层:基础设施
第二层:宿主操作系统内核 (Host OS Kernel)
这是操作系统的核心,负责管理硬件资源,并提供系统调用接口。
第三层:宿主操作系统用户空间 (Host OS User Space)
之前为了便于理解,我们提到Docker Engine的层级是处于Host OS的内核之上的,现在更准确地说"Engine是运行在OS用户空间的进程,通过系统调用与内核交互,同时Engine依赖、使用Host OS中的Bins/Lins"。
第四层:容器 (Container)
容器是Docker Daemon管理的独立、隔离的用户空间环境。Docker 曾经利用 LXC 来作为默认容器环境,自 0.9 版本起,Docker 已经用 libcontainer(他们自己的虚拟化格式)取代 LXC 作为默认容器环境。
每个容器内部包含:应用程序及其所有必要的依赖项和环境资源(例如,文件系统、运行时、库等)。
上图为全文架构,下面对其进行具体介绍:
Docker利用Linux内核层面的两个底层技术:namespace和cgroups,通过对其进行封装与调用来安全地为其容器创建虚拟环境。
Namespace将OS资源封装到不同的实例中从而实现"资源视图隔离",即每个实例只能看到自己的资源与信息。容器化技术的核心在于提供进程隔离,使其感觉拥有独立的操作系统资源。
Cgroups(control groups)提供了一种机制来核算和限制每个容器中的进程可以访问的资源,从而实现"资源管控",保证每个容器都有合理的资源可以使用,避免出现资源不够用或资源浪费的情况。
下面对这两种技术分别进行介绍:
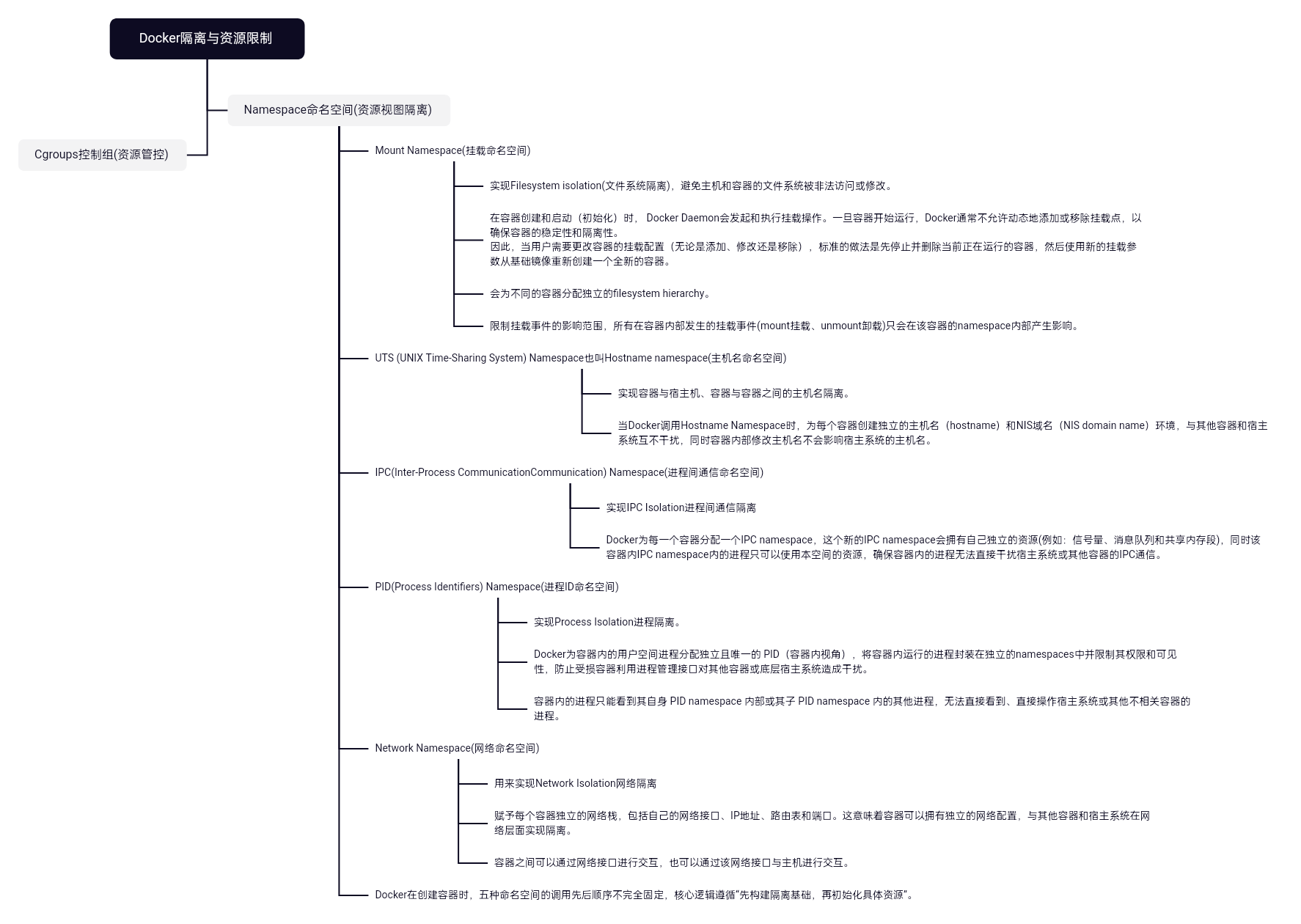
Namespace命名空间:
Docker总共用到Linux内核的五种命名空间:Mount、UTS、IPC、PID 和 Network。
下面先从宏观的角度去解释Docker调用命名空间的工作流程:
1.用户通过 Docker Client 发送命令。
2.Docker Client 将命令发送给 Docker Daemon。
3.Docker Daemon 利用LUX或Libcontainer这个抽象层内部调用Linux内核的系统接口(如 clone() 系列系统调用),并传入相应的标志(如 CLONE_NEWPID , CLONE_NEWNET 等)。
4.Linux 内核解析clone()调用及命名空间标志,为新创建的容器进程分配独立的Mount、UTS、IPC、PID 和 Network 命名空间。
5. 容器进程启动后,其后续创建的子进程会自动继承该容器的所有命名空间,确保容器内所有进程始终处于统一的隔离环境中,与宿主机及其他容器完全隔离。
下面对五种命名空间进行具体介绍:
1. Mount Namespace(挂载命名空间):
实现Filesystem isolation(文件系统隔离),避免主机和容器的文件系统被非法访问或修改。
在容器创建和启动(初始化)时, Docker Daemon会发起和执行挂载操作,为不同的容器分配独立的filesystem hierarchy。一旦容器开始运行,Docker通常不允许动态地添加或移除挂载点,以确保容器的稳定性和隔离性。
当用户需要更改容器的挂载配置(无论是添加、修改还是移除),标准的做法是先停止并删除当前正在运行的容器,然后使用新的挂载参数从基础镜像重新创建一个全新的容器。
同时还会限制挂载事件的影响范围,所有在容器内部发生的挂载事件(mount挂载、unmount卸载)只会在该容器的namespace内部产生影响。
2. Hostname Namespace(主机名命名空间):
实现容器与宿主机、容器与容器之间的主机名隔离。
当Docker调用Hostname Namespace时,为每个容器创建独立的主机名(hostname)和NIS域名(NIS domain name)环境,与其他容器和宿主系统互不干扰,同时容器内部修改主机名不会影响宿主系统的主机名。
3. Inter-Process Communication (IPC) Namespace(进程间通信命名空间):
实现IPC Isolation进程间通信隔离。
Docker为每一个容器分配一个IPC namespace,这个新的IPC namespace会拥有自己独立的资源(例如:信号量、消息队列和共享内存段),同时该容器内IPC namespace内的进程只可以使用本空间的资源,确保容器内的进程无法直接干扰宿主系统或其他容器的IPC通信。
4. Process Identifiers (PID) Namespace(进程ID命名空间):
实现Process Isolation进程隔离。
Docker为容器内的用户空间进程分配独立且唯一的 PID(容器内视角),将容器内运行的进程封装在独立的namespaces中并限制其权限和可见性,防止受损容器利用进程管理接口对其他容器或底层宿主系统造成干扰。
容器内的进程只能看到其自身 PID namespace 内部或其子 PID namespace 内的其他进程,无法直接看到、直接操作宿主系统或其他不相关容器的进程。
5. Network Namespace(网络命名空间):
用来实现Network Isolation网络隔离。
赋予每个容器独立的网络栈,包括自己的网络接口、IP地址、路由表和端口。这意味着容器可以拥有独立的网络配置,与其他容器和宿主系统在网络层面实现隔离。
容器之间可以通过网络接口进行交互,也可以通过该网络接口与主机进行交互。
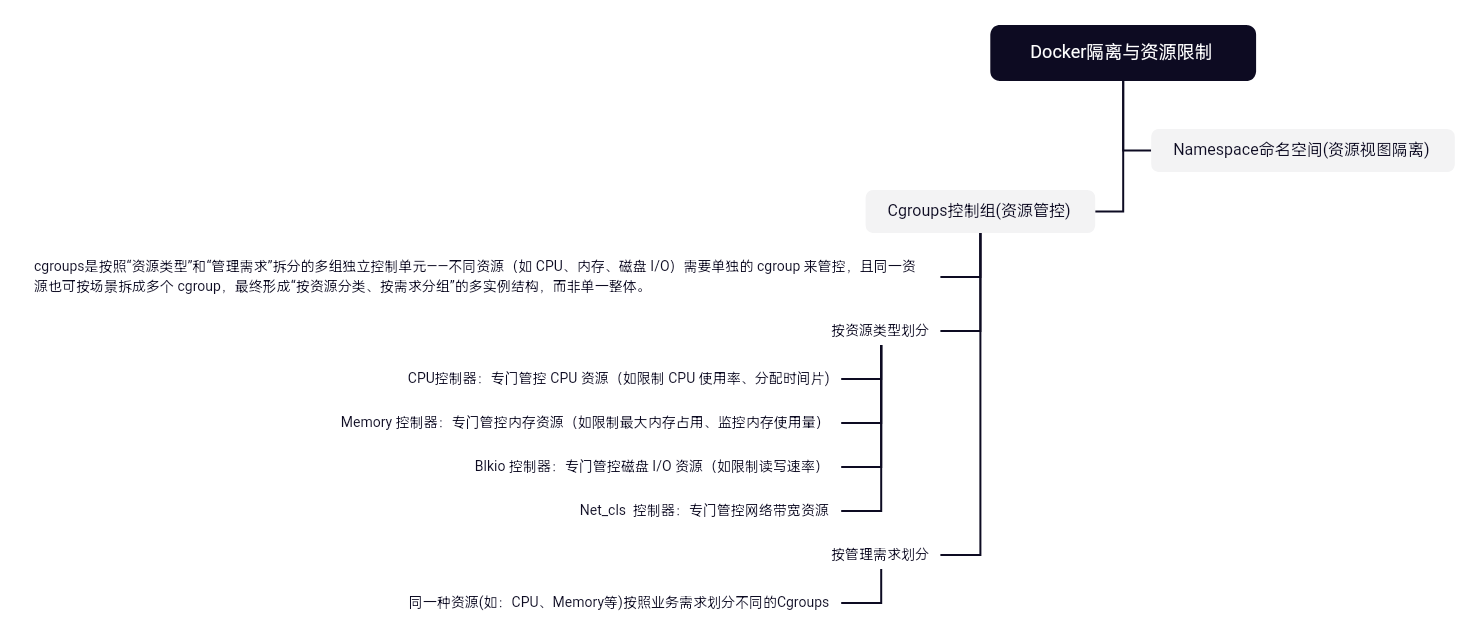
Cgroups(Control Groups)控制组:
Cgroups是按照“资源类型”和“管理需求”拆分的多组独立控制单元——不同资源(如 CPU、内存、磁盘 I/O)需要单独的 cgroup 来管控,且同一资源也可按场景拆成多个 cgroup,最终形成“按资源分类、按需求分组”的多实例结构,而非单一整体。
下面先从宏观角度解释Docker调用cgroups时的工作流程:
1. 用户通过Docker Client(如执行 docker r发送创建容器的命令,并指定资源限制参数(如内存、CPU 配额)。
2. Docker Client 将命令及资源配置参数封装为请求,发送给后台运行的 Docker Daemon。
3. Docker Daemon 接收到请求后,先完成容器基础环境准备(如镜像解压、创建文件系统),再通过LUX或Libcontainer调用 Linux 内核的cgroups接口,在 /sys/fs/cgroup/ 下为容器创建专属的cgroups子目录(按资源类型分类,如 CPU、内存目录),并将资源限制参数写入对应子目录的控制文件。
4. Linux 内核读取 cgroups 控制文件中的配置规则,为容器进程绑定对应的 cgroups 组,实时监控并强制容器进程遵守资源限制(如超内存时触发 OOM、超 CPU 配额时限流),实现对容器资源的精准管控。
按资源类型划分:
CPU控制器:专门管控 CPU 资源(如限制 CPU 使用率、分配时间片);
Memory 控制器:专门管控内存资源(如限制最大内存占用、监控内存使用量);
Blkio 控制器:专门管控磁盘 I/O 资源(如限制读写速率);
Net_cls 控制器:专门管控网络带宽资源;
按照管理需求划分:
同一种资源(如:CPU、Memory等)按照业务需求划分不同的Cgroups。

















 1196
1196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









