







(一) 批量创建空白的excel文件
代码如下:
#导入openpyxl模块
import openpyxl
#设置分公司名称列表
mynames = ["北京", "上海", "重庆"]
#循环列表(mynames)的分公司名称(myname)
for myname in mynames:
#根据分公司名称(myname)设置excel文件名称
mypath="结果表"+myname+"2022总结表.xlsx"
#新建空白工作簿
mybook=openpyxl.Workbook()
#根据参数(mypath)保存空白工作簿(mybook),即创建保存多个空白的excel文件
mybook.save(mypath)注意:在pycharm中导入模块的方法措施;到settings中下载模块
相当于图形界面的新建空白文件并命名
(二)批量创建非空白的excel文件
代码如下:
#导入openpyxl模块
import openpyxl
#设置分公司名称列表
mynames = ["北京", "上海", "重庆"]
#根据“利润表.xlsx”文件创建工作簿
mybook=openpyxl.load_workbook("利润表.xlsx")
i=0
mylength=len(mynames)
#在while循环中批量创建与“利润表.xlsx”内容完全相同的excel文件
while i<mylength:
#根据分公司名称设置各个excel文件名称
mypath="结果表"+mynames[i]+"年度利润表.xlsx"
i+=1
#保存工作簿(mybook)或者说将工作簿(mybook)另存为excel文件
mybook.save(mypath)
① 以 "利润表.xlsx" 文件中的内容为模板,再新建 excel 文件且文件内容全都与 "利润表.xlsx"相同
② 相当于图形界面的复制和重命名操作
(三)使用字典拆分多个工作簿
代码如下:
#导入openpyxl模块
import openpyxl
#根据“录取表.xlsx”文件创建工作簿
mybook=openpyxl.load_workbook("录取表.xlsx")
mysheet=mybook['录取表'] #读取工作簿中的名为“录取表”的工作表
#按行获取录取表(mysheet)的单元格数据(myrange)
myrange=list(mysheet.values) #应该是二维列表
#创建空白字典
mydict={}
#从录取表(myrange)的第四行开始循环(到最后一行)二维列表
for myrow in myrange[3:]:
#如果在字典(mydict)存在某录取院校(myrow[0]).则直接在某录取院校(myrow[0])中添加考生(myrow)
if myrow[0] in mydict.keys():
mydict[myrow[0]]+=[myrow]
#否则创建新录取院校
else:
mydict[myrow[0]]=[myrow]
#循环字典(mydict)的成员
for mykey,myvalue in mydict.items:
#创建新工作簿
mynewbook=openpyxl.Workbook()
mynewsheet=mynewbook.active #获取当前的活动工作表
#在新工作表(mynewsheet)中添加表头(录取院校,专业,考生姓名,总分)
mynewsheet.append(myrange[2]) #添加原表中的第三行数据
#在新工作表(mynewsheet)中添加键名(录取院校)下的多个键值(考生)
for myrow in myvalue:
mynewsheet.append(myrow) #按行添加
mynewsheet.title=mykey+"录取表" #为当前活动工作表命名
#保存拆分之后(各个录取院校)的工作簿(mynewbook),或者说保存各个excel文件
mypath="结果表"+mykey+"录取表.xlsx" #为工作簿即excel文件命名
mynewbook.save(mypath)
(四)使用嵌套字典拆分多个工作簿
代码如下:
#导入openpyxl模块
import openpyxl
#读取“录取表.xlsx”文件内容
mybook=openpyxl.load_workbook("录取表.xlsx")
mysheet=mybook['录取表']
#按行获取录取表(mysheet)的单元格数据(myrange)
myrange=list(mysheet.values)
#创建空白字典
mydict={}
#从录取表(myrange)的第四行开始循环(到最后一行)
for myrow in myrange[3:]:
#如果在字典(mydict)存在某录取院校(myrow[0]).且存在该录取院校的某专业
if myrow[0] in mydict.keys() and myrow[1] in mydict[myrow[0]].keys():
# 则直接在某录取院校(myrow[0])中添加考生(myrow)
mydict[myrow[0]][myrow[1]]+=[myrow]
else:
#如果在字典(mydict)中不存在某录取院校,则首先创建录取院校和专业
if myrow[0] not in mydict.keys():mydict[myrow[0]]={}
mydict[myrow[0]][myrow[1]]=[myrow]
#循环字典(mydict)的成员
for mykey1,myvalue1 in mydict.items:
#创建新工作簿
mynewbook=openpyxl.Workbook()
for mykey2,myvalue2 in myvalue1.items:
#根据键名(mykey2)创建新工作表(mynewsheet)
mynewsheet=mynewbook.create_sheet(mykey2+"专业录取表")
#在新工作表(mynewsheet)中添加键名(专业)下的多个键值(学生)
for myrow in myvalue2:
mynewsheet.append(myrow)
mynewbook.remove(mynewbook["sheet"])
#保存拆分之后(各个录取院校)的工作簿(mynewbook),或者说保存各个excel文件
mypath="结果表"+mykey1+"录取表.xlsx"
mynewbook.save(mypath)
(五)在工作簿中创建空白工作表
代码:
# 导入openpyxl模块
import openpyxl
# 读取“利润表.xlsx”文件内容并创建工作簿
mybook = openpyxl.load_workbook("利润表.xlsx")
mynames = ['1月份利润', '2月份利润', '3月份利润', '4月份利润', '5月份利润', '6月份利润', '7月份利润']
#循环列表(mynames)的表名(myname)
for myname in mynames:
#根据表明(myname)在工作簿(mybook)中创建空白的工作表
mybook.create_sheet(myname)
mybook.save("结果表-利润表.xlsx")工作簿会自动创建一个sheet工作表
(六)根据指定位置创建工作表
代码如下:
# 导入openpyxl模块
import openpyxl
# 读取“录取表.xlsx”文件内容
mybook = openpyxl.load_workbook("利润表.xlsx")
mynames = ['2月份利润', '4月份利润', '6月份利润', '8月份利润', '10月份利润', '12月份利润']
i=0
mylength=len(mybook.worksheets) #表示工作簿中已有的工作表个数
while i<mylength:
#在工作表指定位置(i*2+1)创建空白工作表
mybook.create_sheet(mynames[i],i*2+1)
i+=1
mybook.save("结果表-利润表.xlsx")效果如下:

由图知,① 是在原有工作表的前面重新创建新的工作表(可以说是插入工作表)
② 插入新的工作表后,会在插入新工作表的工作簿中重新插入另一个工作表 (针对最新的工 作簿插入工作表) 即每执行一次插入操作则工作表的索引会发生变化 注意该算法问题
(七)在工作簿中复制多个工作表
代码:
# 导入openpyxl模块
import openpyxl
# 读取“录取表.xlsx”文件内容
mybook = openpyxl.load_workbook("利润表.xlsx")
mynames = ['1月份利润', '2月份利润', '3月份利润', '4月份利润', '5月份利润', '6月份利润']
#循环列表(mynames)的表名(myname),如一月份利润
for myname in mynames:
#在工作簿mybook中根据利润表mybook.worksheet[0]复制工作表mysheet
mysheet=mybook.copy_worksheet(mybook.worksheets[0])
mysheet.title=myname
mybook.save("结果表-利润表.xlsx")mysheet=mybook.copy_worksheet(mybook.worksheets[0]) 表示在工作簿mybook复制一个与利润表(mybook.worksheets[0]) 的内容和格式完全相同的工作表mysheet注意:mybook.worksheets[0] 是工作表对象,不是工作表表名
效果:

(八)在工作簿中根据表名删除工作表
代码:
# 导入openpyxl模块
import openpyxl
# 读取“录取表.xlsx”文件内容并创建工作簿对象
mybook = openpyxl.load_workbook("利润表.xlsx")
#循环工作簿mybook中的工作表mysheet
for mysheet in mybook:
#如果工作表mysheet的表名包含华东,则删除该工作表
if mysheet.title.split('-')[0]=='华东':
mybook.remove(mysheet)
mybook.save("结果表-利润表.xlsx")mysheet.title.split('-')[0]=='华东' 表示使用 '-' 符号将工作表mysheet的表名拆分为多个列表成员,若列表的第一个成员是 '华东' 则使用 mybook.remove(mysheet) 从该工作簿mybook中删除该工作表mysheet
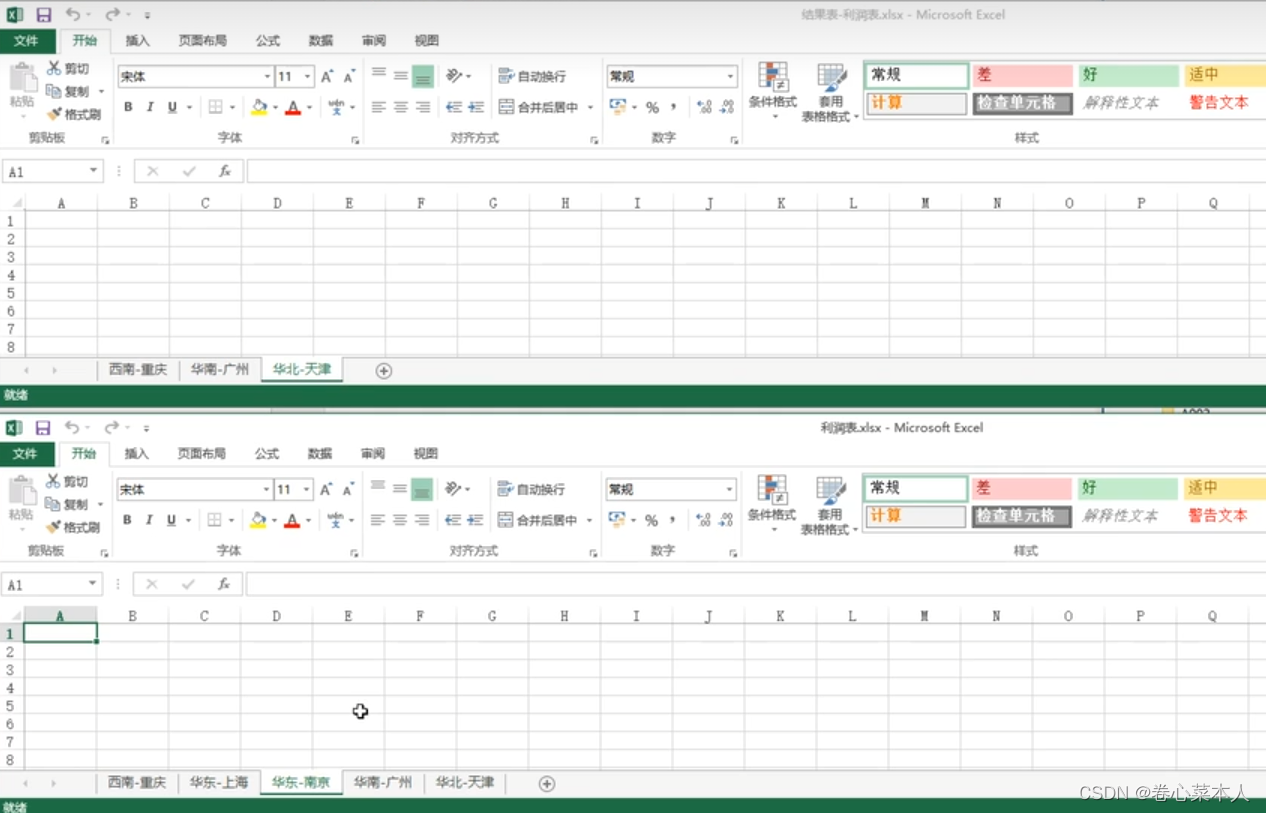
(九)在工作簿中根据位置删除工作表
代码如下:
# 导入openpyxl模块
import openpyxl
# 读取“录取表.xlsx”文件内容,
mybook = openpyxl.load_workbook("利润表.xlsx")
mynames=mybook.sheetnames #mynames已经赋值固定不变,所以后面的位置索引不会改变
i=0
mylength=len(mynames)
#循环工作簿mybook中的工作表mysheet
while i<mylength:
#如果工作表表名的月份数是奇数,则删除
if i%2==0:
mybook.remove(mybook[mynames[i]])
i+=1
mybook.save("结果表-利润表.xlsx")结果:
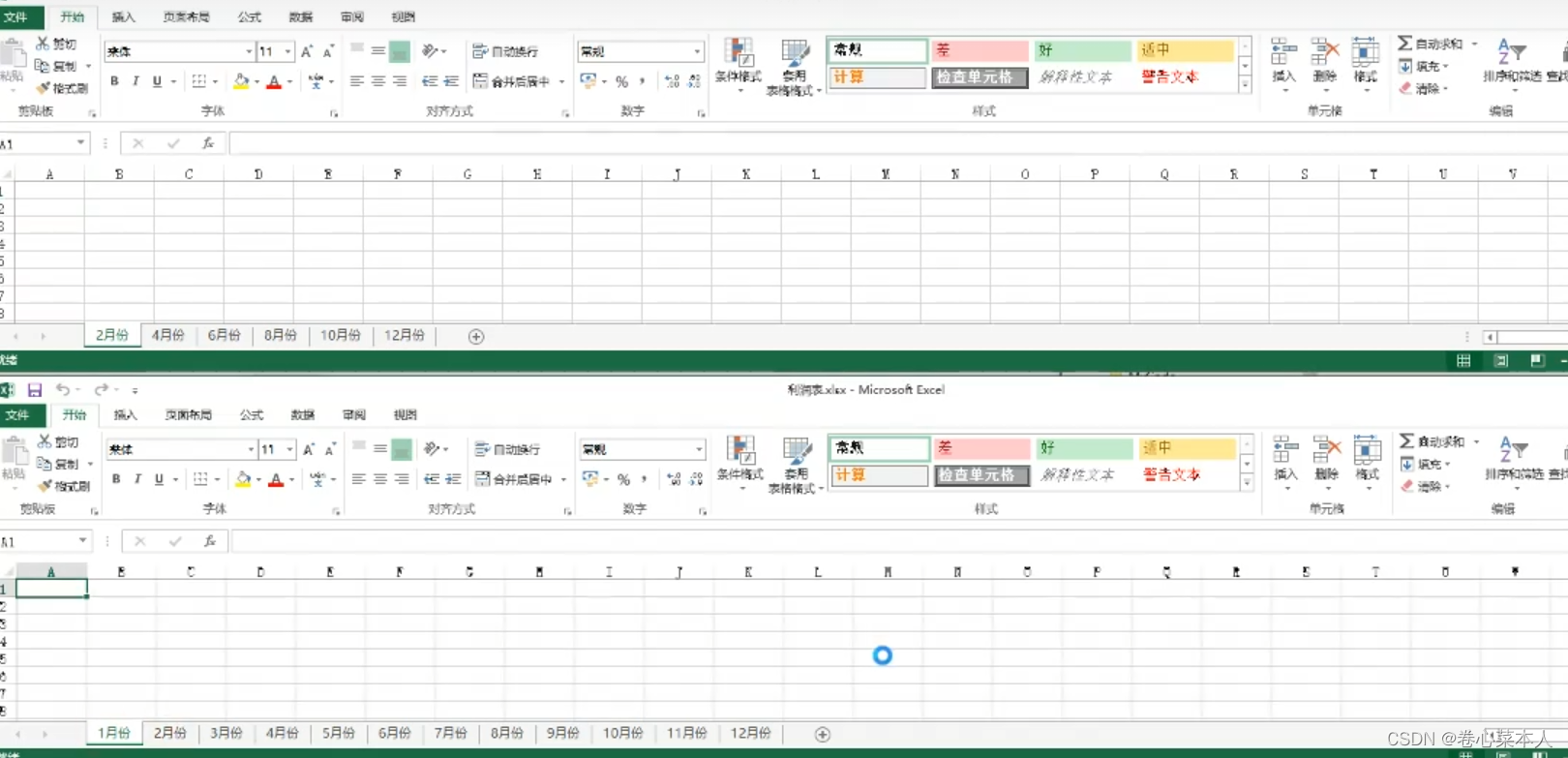
需要注意的是,当在工作簿中删除多个工作表时,应该小心使用指定将要删除的工作表,因为每执行一次删除工作表操作,工作簿中所有的工作表索引会发生改变
(十)自定义活动工作表的表名
# 导入openpyxl模块
import openpyxl
# 读取“录取表.xlsx”文件内容,
mybook = openpyxl.load_workbook("利润表.xlsx")
mysheet=mybook.active
mysheet.title='2020年'+mysheet.title
mybook.save("结果表-利润表.xlsx")通过 active 属性获取工作簿的活动工作表
结果:
















 375
375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









