







计算机进程使用的内存地址不是真正的内存地址,是一套虚拟地址,操作系统会将不同进程的虚拟地址和物理地址映射起来
虚拟内存地址:程序所使用的内存地址
物理内存地址:实际存在硬件里的空间地址
操作系统通过分页和分段来管理虚拟地址和物理地址的映射
分段
程序是由若干个逻辑分段组成的,如可由代码分段、数据分段、栈段、堆段组成。不同的段是有不同的属性的,所以就用分段(Segmentation)的形式把这些段分离出来。
分段机制下的虚拟地址由两部分组成,段选择因子和段内偏移量。
段选择因子和段内偏移量:
段选择子就保存在段寄存器里面。段选择子里面最重要的是段号,用作段表的索引。段表里面保存的是这个段的基地址、段的界限和特权等级等。
虚拟地址中的段内偏移量应该位于 0 和段界限之间,如果段内偏移量是合法的,就将段基地址加上段内偏移量得到物理内存地址。
在上面,知道了虚拟地址是通过段表与物理地址进行映射的,分段机制会把程序的虚拟地址分成 4 个段,每个段在段表中有一个项,在这一项找到段的基地址,再加上偏移量,于是就能找到物理内存中的地址
详情:https://xiaolincoding.com/os/3_memory/vmem.html#%E5%86%85%E5%AD%98%E5%88%86%E6%AE%B5
分段的缺点:
内存碎片化 内存交换效率低
为什么交换效率低?
对于多进程的系统来说,用分段的方式,内存碎片是很容易产生的,产生了内存碎片,那不得不重新 Swap 内存区域,这个过程会产生性能瓶颈。
因为硬盘的访问速度要比内存慢太多了,每一次内存交换,我们都需要把一大段连续的内存数据写到硬盘上。
所以,如果内存交换的时候,交换的是一个占内存空间很大的程序,这样整个机器都会显得卡顿。
分页
分页是把整个虚拟和物理内存空间切成一段段固定尺寸的大小。这样一个连续并且尺寸固定的内存空间,我们叫页(Page)。在 Linux 下,每一页的大小为 4KB。
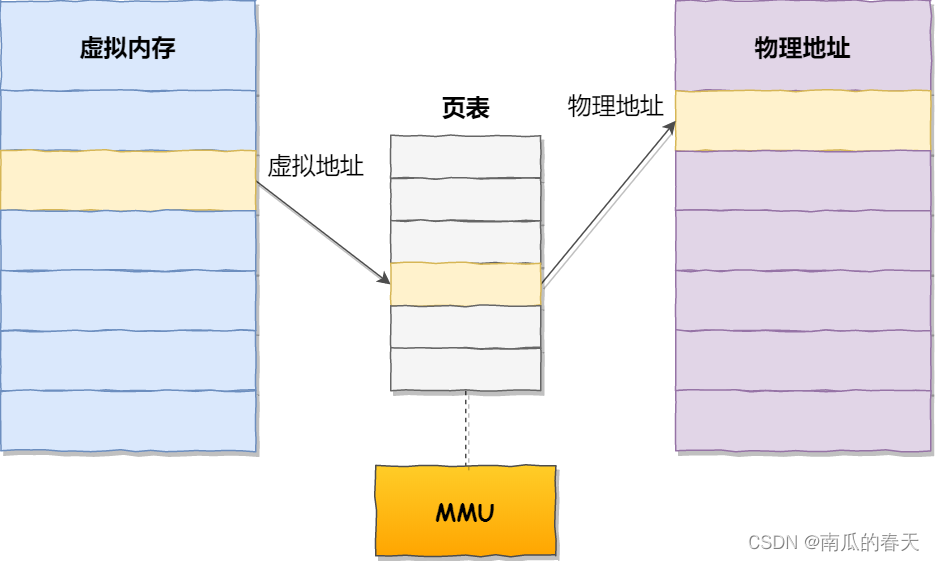
虚拟内存和物理地址通过页表映射
页表是存储在内存里的,内存管理单元 (MMU)就做将虚拟内存地址转换成物理地址的工作。
当进程访问的虚拟地址在页表中查不到时,系统会产生一个缺页异常,进入系统内核空间分配物理内存、更新进程页表,最后再返回用户空间,恢复进程的运行。
如何解决内存碎片化和交换效率低的问题?
由于内存空间是预先划分好的,不会像分段产生间隙非常小的内存碎片(但是页内还是有可能有内存空间没被利用)
如果内存不足,OS会通过某些算法(LRU)把最近没怎么使用的页写到硬盘上,这叫换出(Swap Out),需要时再加载进来,称为换入(Swap In)。也就是说,加载程序时不需要把程序全部加载到内存中,只需要加载需要的部分,不需要的部分就先放在磁盘里,这样提高内存交换效率
如何映射
在分页机制下,虚拟地址分为两部分,页号和页内偏移。页号作为页表的索引,页表包含物理页每页所在物理内存的基地址,这个基地址与页内偏移的组合就形成了物理内存地址
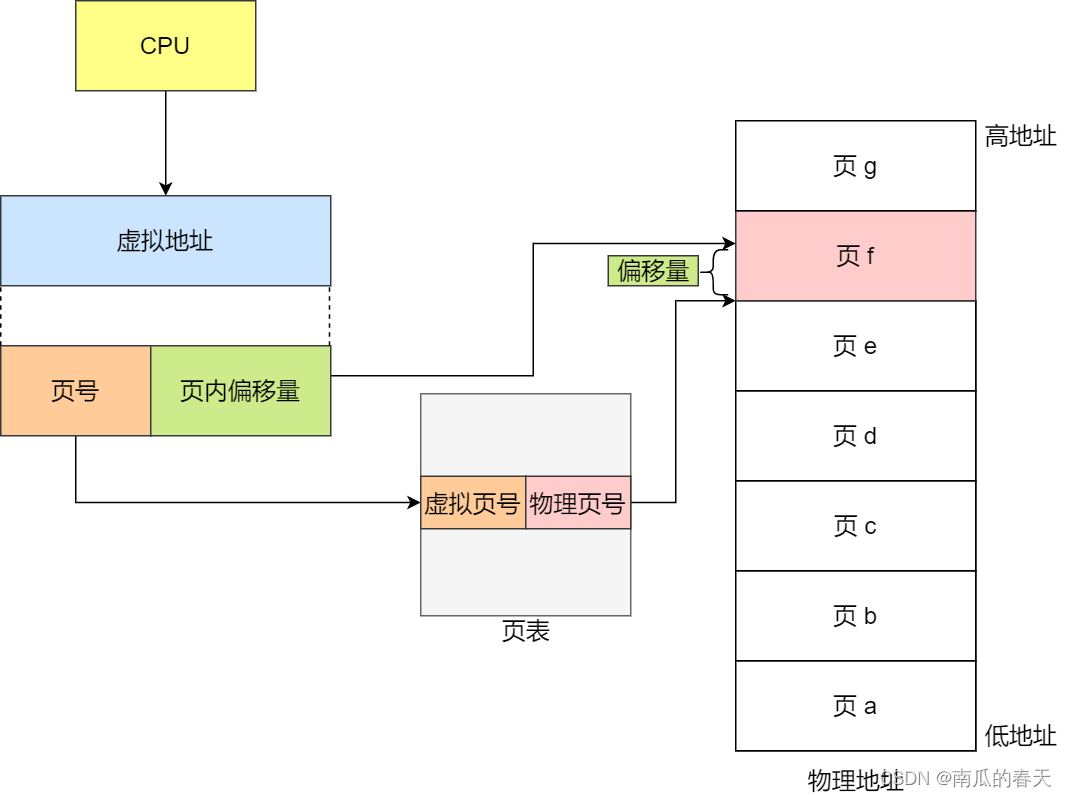
1.把虚拟内存地址,切分成页号和偏移量;
2.根据页号,从页表里面,查询对应的物理页号;
3.直接拿物理页号,加上前面的偏移量,就得到了物理内存地址。
但是简单的分页仍有缺陷,OS可以同时运行很多进程,意味着页表会很庞大
在 32 位的环境下,虚拟地址空间共有 4GB,假设一个页的大小是 4KB(2^12),那么就需要大约 100 万 (2^20) 个页,每个「页表项」需要 4 个字节大小来存储,那么整个 4GB 空间的映射就需要有 4MB 的内存来存储页表。
这 4MB 大小的页表,看起来也不是很大。但是要知道每个进程都是有自己的虚拟地址空间的,也就说都有自己的页表。
那么,100 个进程的话,就需要 400MB 的内存来存储页表,这是非常大的内存了,更别说 64 位的环境了。
多级页表
可采用多级页表解决以上问题
将单级页表再分页,把之前的页表(二级页表)再交给页表管理(一级页表)。根据局部性原理,一级页表的页表项如果没被用到,看可以先不创建对应的二级页表,等需要时再创建二级页表。页表的作用是建立虚拟地址和物理地址的映射,所以页表一定要覆盖所有虚拟地址空间,不分级页表需要一百多万页表项来映射,但二级分页只要1024个页表项(一级页表覆盖了所有虚拟地址空间,二级页表在需要时再创建)(这是针对32位系统的,64位需要4级页表)
段页式内存管理
实现方式:
先将程序划分为多个有逻辑意义的段,也就是前面提到的分段机制;
接着再把每个段划分为多个页,也就是对分段划分出来的连续空间,再划分固定大小的页;
地址结构由段号、页号、页内地址组成
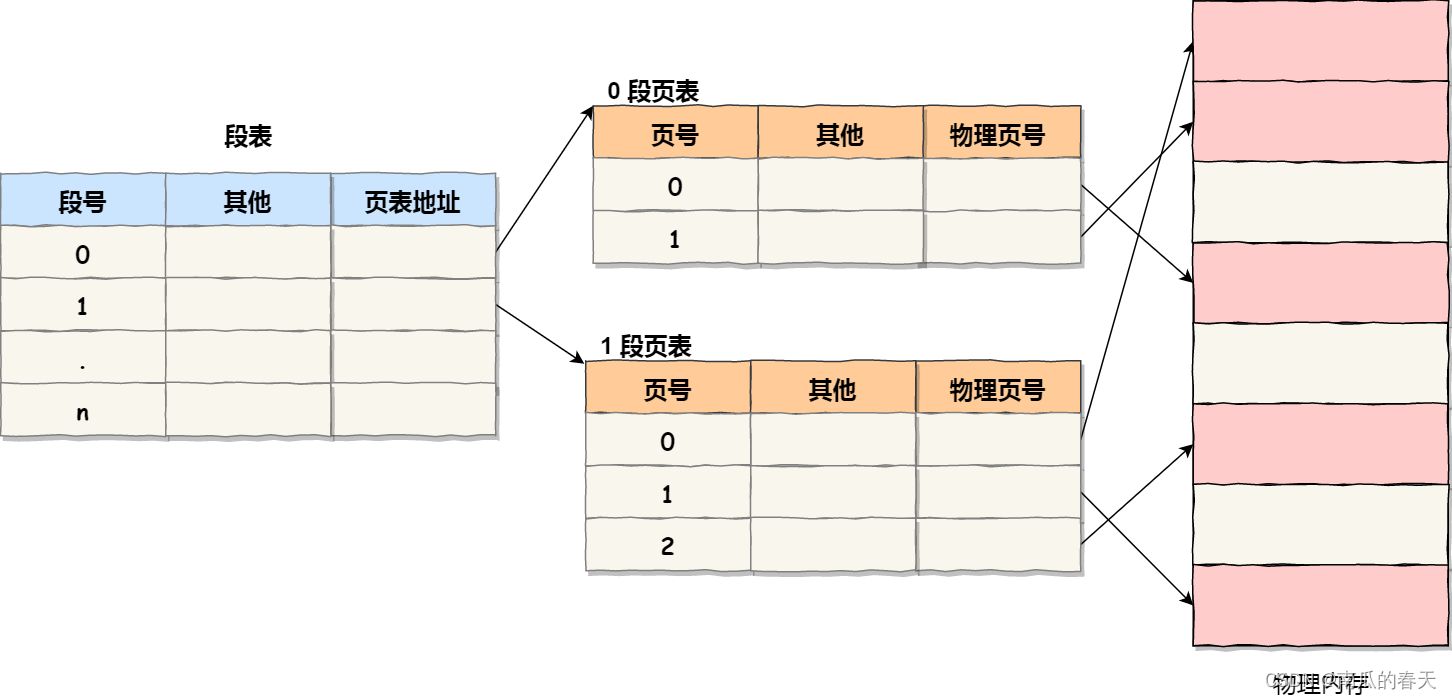
第一次访问段表,得到页表起始地址;
第二次访问页表,得到物理页号;
第三次将物理页号与页内位移组合,得到物理地址。
linux内存管理
linux主要采用页式内存管理,同时设计段机制
Linux 系统中的每个段都是从 0 地址开始的整个 4GB 虚拟空间(32 位环境下),也就是所有的段的起始地址都是一样的。这意味着,Linux 系统中的代码,包括操作系统本身的代码和应用程序代码,所面对的地址空间都是线性地址空间(虚拟地址),这种做法相当于屏蔽了处理器中的逻辑地址概念,段只被用于访问控制和内存保护。
在 Linux 操作系统中,虚拟地址空间的内部又被分为内核空间和用户空间两部分
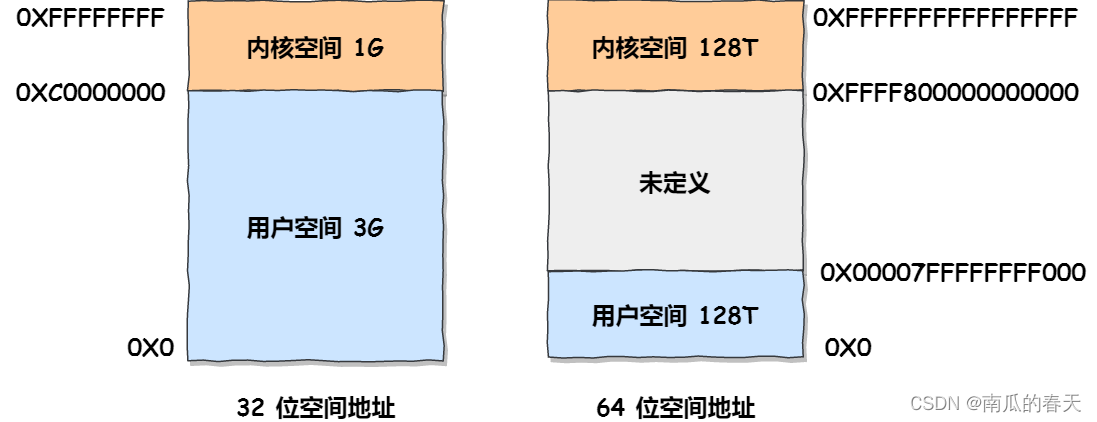
内核空间与用户空间的区别:
进程在用户态时,只能访问用户空间内存;
只有进入内核态后,才可以访问内核空间的内存;
总结
为了在多进程环境下,使得进程之间的内存地址不受影响,相互隔离,于是操作系统就为每个进程独立分配一套虚拟地址空间,每个程序只关心自己的虚拟地址就可以,实际上大家的虚拟地址都是一样的,但分布到物理地址内存是不一样的。作为程序,也不用关心物理地址的事情。
每个进程都有自己的虚拟空间,而物理内存只有一个,所以当启用了大量的进程,物理内存必然会很紧张,于是操作系统会通过内存交换技术,把不常使用的内存暂时存放到硬盘(换出),在需要的时候再装载回物理内存(换入)。
那既然有了虚拟地址空间,那必然要把虚拟地址「映射」到物理地址,这个事情通常由操作系统来维护。
那么对于虚拟地址与物理地址的映射关系,可以有分段和分页的方式,同时两者结合都是可以的。
内存分段是根据程序的逻辑角度,分成了栈段、堆段、数据段、代码段等,这样可以分离出不同属性的段,同时是一块连续的空间。但是每个段的大小都不是统一的,这就会导致内存碎片和内存交换效率低的问题。
于是,就出现了内存分页,把虚拟空间和物理空间分成大小固定的页,如在 Linux 系统中,每一页的大小为 4KB。由于分了页后,就不会产生细小的内存碎片。同时在内存交换的时候,写入硬盘也就一个页或几个页,这就大大提高了内存交换的效率。
再来,为了解决简单分页产生的页表过大的问题,就有了多级页表,它解决了空间上的问题,但这就会导致 CPU 在寻址的过程中,需要有很多层表参与,加大了时间上的开销。于是根据程序的局部性原理,在 CPU 芯片中加入了 TLB,负责缓存最近常被访问的页表项,大大提高了地址的转换速度。
Linux 系统主要采用了分页管理,但是由于 Intel 处理器的发展史,Linux 系统无法避免分段管理。于是 Linux 就把所有段的基地址设为 0,也就意味着所有程序的地址空间都是线性地址空间(虚拟地址),相当于屏蔽了 CPU 逻辑地址的概念,所以段只被用于访问控制和内存保护。
另外,Linux 系统中虚拟空间分布可分为用户态和内核态两部分,其中用户态的分布:代码段、全局变量、BSS、函数栈、堆内存、映射区。
内存满会发生什么
内核在给应用程序分配物理内存的时候,如果空闲物理内存不够,那么就会进行内存回收的工作,主要有两种方式:
后台内存回收:在物理内存紧张的时候,会唤醒 kswapd 内核线程来回收内存,这个回收内存的过程异步的,不会阻塞进程的执行。
直接内存回收:如果后台异步回收跟不上进程内存申请的速度,就会开始直接回收,这个回收内存的过程是同步的,会阻塞进程的执行。
可被回收的内存类型有文件页和匿名页:
文件页的回收:对于干净页是直接释放内存,这个操作不会影响性能,而对于脏页会先写回到磁盘再释放内存,这个操作会发生磁盘 I/O 的,这个操作是会影响系统性能的。
匿名页的回收:如果开启了 Swap 机制,那么 Swap 机制会将不常访问的匿名页换出到磁盘中,下次访问时,再从磁盘换入到内存中,这个操作是会影响系统性能的。
文件页和匿名页的回收都是基于 LRU 算法,也就是优先回收不常访问的内存。回收内存的操作基本都会发生磁盘 I/O 的,如果回收内存的操作很频繁,意味着磁盘 I/O 次数会很多,这个过程势必会影响系统的性能。
针对回收内存导致的性能影响,常见的解决方式。
设置 /proc/sys/vm/swappiness,调整文件页和匿名页的回收倾向,尽量倾向于回收文件页;
设置 /proc/sys/vm/min_free_kbytes,调整 kswapd 内核线程异步回收内存的时机;
设置 /proc/sys/vm/zone_reclaim_mode,调整 NUMA 架构下内存回收策略,建议设置为 0,这样在回收本地内存之前,会在其他 Node 寻找空闲内存,从而避免在系统还有很多空闲内存的情况下,因本地 Node 的本地内存不足,发生频繁直接内存回收导致性能下降的问题;
在经历完直接内存回收后,空闲的物理内存大小依然不够,那么就会触发 OOM 机制,OOM killer 就会根据每个进程的内存占用情况和 oom_score_adj 的值进行打分,得分最高的进程就会被首先杀掉。
我们可以通过调整进程的 /proc/[pid]/oom_score_adj 值,来降低被 OOM killer 杀掉的概率。
详情:https://xiaolincoding.com/os/3_memory/mem_reclaim.html
在4G内存的机器上申请8G内存会怎样
在 32 位操作系统,因为进程最大只能申请 3 GB 大小的虚拟内存,所以直接申请 8G 内存,会申请失败。
在 64位 位操作系统,因为进程最大只能申请 128 TB 大小的虚拟内存,即使物理内存只有 4GB,申请 8G 内存也是没问题,因为申请的内存是虚拟内存。如果这块虚拟内存被访问了,要看系统有没有 Swap 分区:
如果没有 Swap 分区,因为物理空间不够,进程会被操作系统杀掉,原因是 OOM(内存溢出);
如果有 Swap 分区,即使物理内存只有 4GB,程序也能正常使用 8GB 的内存,进程可以正常运行;
详情:https://xiaolincoding.com/os/3_memory/alloc_mem.html#%E5%AE%9E%E9%AA%8C%E4%BA%8C-%E6%9C%89%E5%BC%80%E5%90%AF-swap-%E6%9C%BA%E5%88%B6
参考链接:小林coding















 1804
1804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









