






用来给自己存档的
1.复现D-DBPN时遇到的问题
(1)import ,from … import 和 import...as...——导入文件夹及函数
import 模块:导入一个模块;注:相当于导入的是一个文件夹,是个相对路径。

- from…import:导入了一个模块中的一个函数;注:相当于导入的是一个文件夹中的文件,是个绝对路径。

- import...as...:用于引入一个模块的同时为该模块取一个别名。import multiprocessing as mp 表示引入multiprocessing模块并取别名为mp,在该文件的后续调用中mp就相当于是multiprocessing。
- 参考:from…import * 语句与 import 区别 (runoob.com)
- 自己读的时候总是弄不清楚哪里来的稀奇古怪的名字,于是追根溯源:
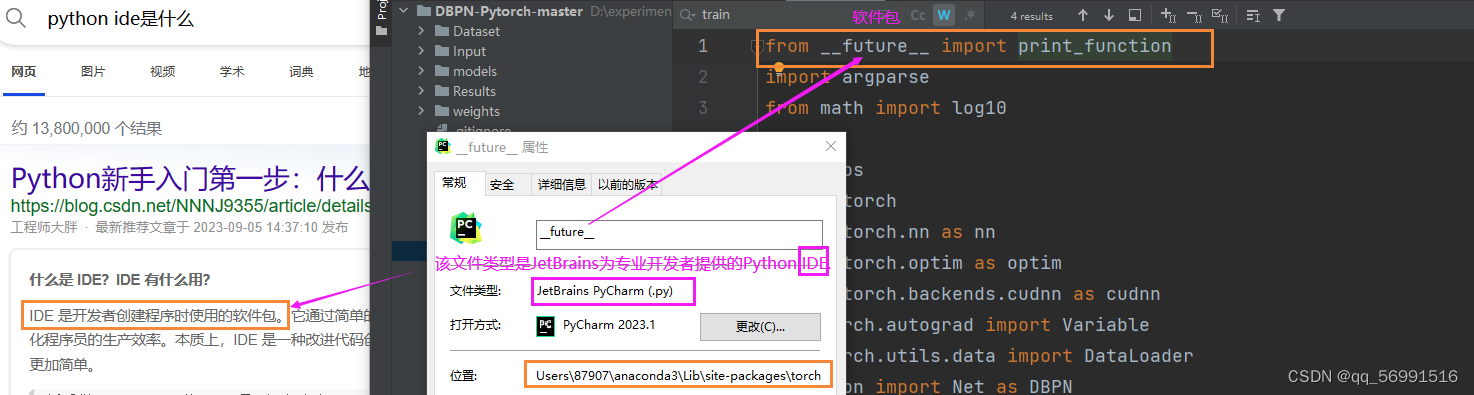
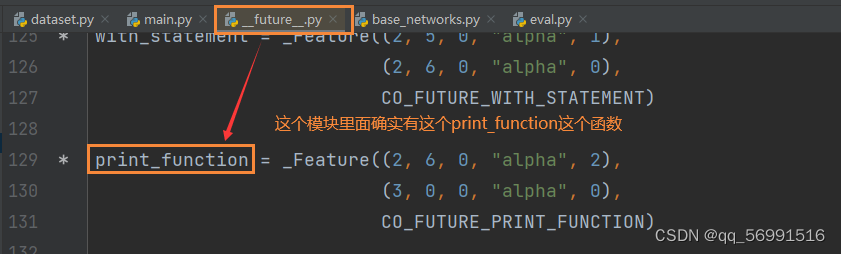
-
(2)torch.cat() / torch.concat() ——拼接张量
-
torch.cat是将两个张量(tensor) 拼接在一起,cat是concatnate的意思, 即拼接,联系在一起。使用torch.cat((A,B),dim)时,除拼接维数dim数值可不同外,其余维数数值需相同,方能对齐。y即:当dim=0时,按行拼接;当dim=1时,按列拼接。
-
(3)for i in range ()/for _ in range(n)——遍历赋值
-
for i in range ()作用:
range()是一个函数, for i in range () 就是给 i 赋值:
比如 for i in range (1,3):就是把1,3依次赋值给i
range () 函数:range(start, stop[, step]),分别是起始、终止和步长
range(3)即:从0到3,不包含3,即0,1,2(左闭右开)
-
for _ in range(n)作用:
_只是一个占位符,只在乎遍历次数。range(n)就是把for前面的东西遍历n次。for_in range(n)和for each in range(n)是一样的,只不过_在下面不会用到,这里的_可以替换成任何符合规定的字符串。
-
(4)append函数——在数组后加元素
- append函数会在数组后加上相应的元素

- 用append生成多维数组:

-
(5)cuda()——GPU
- 在pytorch中,即使是有GPU的机器,它也不会自动使用GPU,而是需要在程序中显示指定。调用model.cuda(),可以将模型加载到GPU上去。这种方法不被提倡。
- 而建议使用model.to(device)的方式,这样可以显示指定需要使用的计算资源,特别是有多个GPU的情况下。
-
(6)nn.Linear()——定义一个神经网络的线性层
- nn.Linear定义一个神经网络的线性层
-


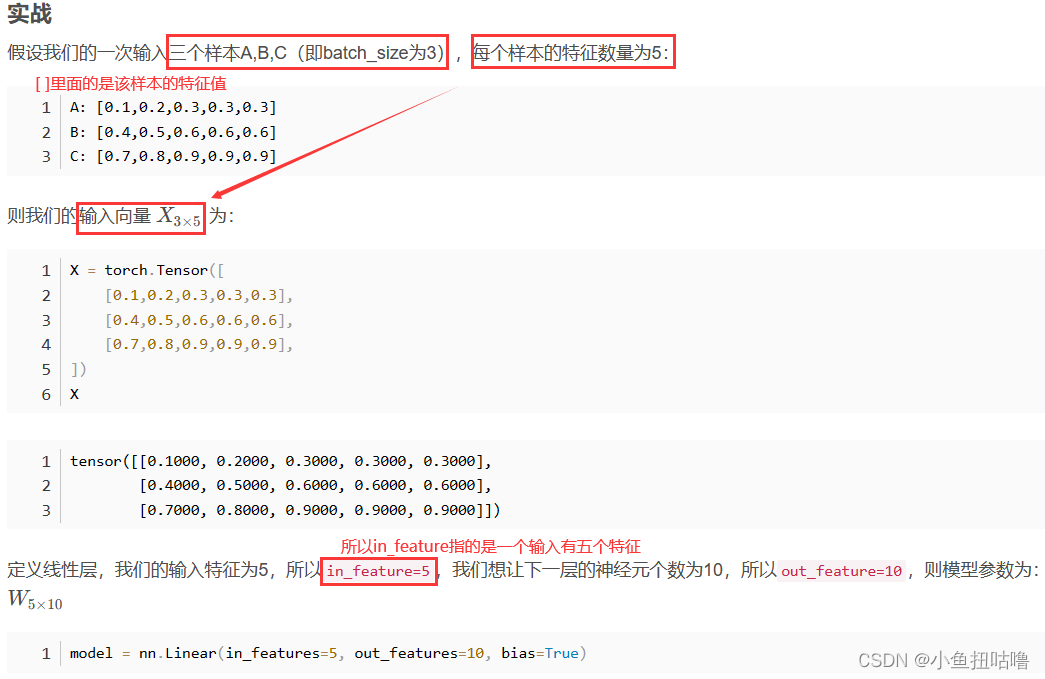
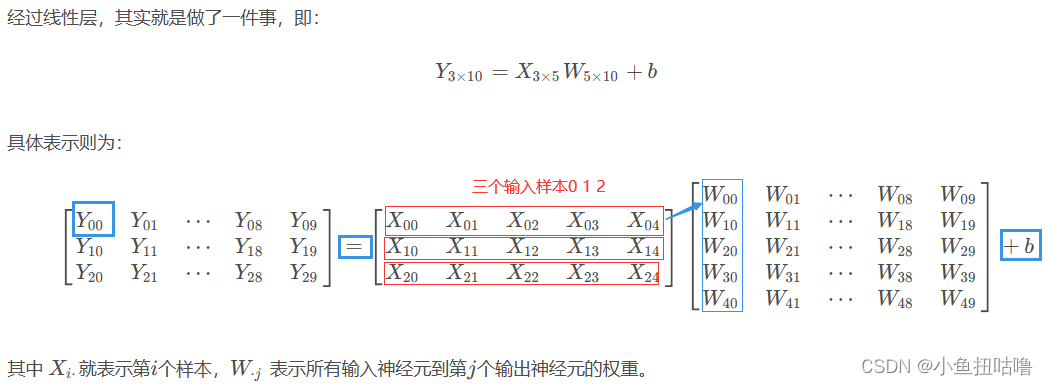


- 参考:http://t.csdnimg.cn/APSAK
-
(7)nn.BatchNorm1d——批量标准化
- 参考:http://t.csdnimg.cn/mznDx
-
(8)nn.InstanceNorm1d——归一化

- 批量归一化和实例归一化的辨析:http://t.csdnimg.cn/gaTDn


(9) torch.nn.PixelShuffle 和 torch.nn.UnpixelShuffle——上/下采样,将张量重新排列
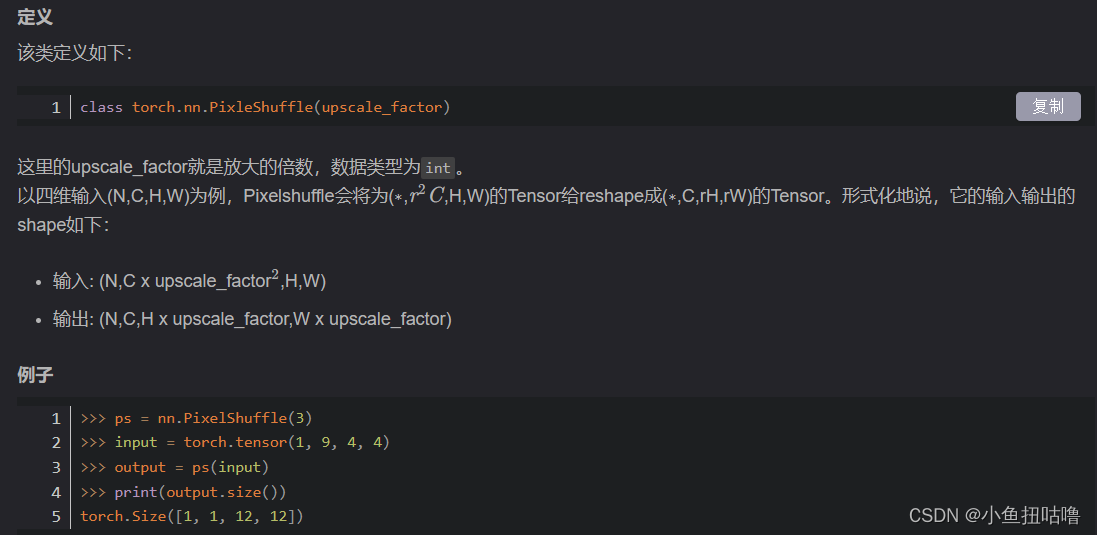
其中C是通道数,HxW是低分辨率输入图像
参考:http://t.csdnimg.cn/6NpLV :这篇文章写的很全面,写了:在PyTorch中,上采样的层被封装在torch.nn中的Vision Layers里面,一共有4种。
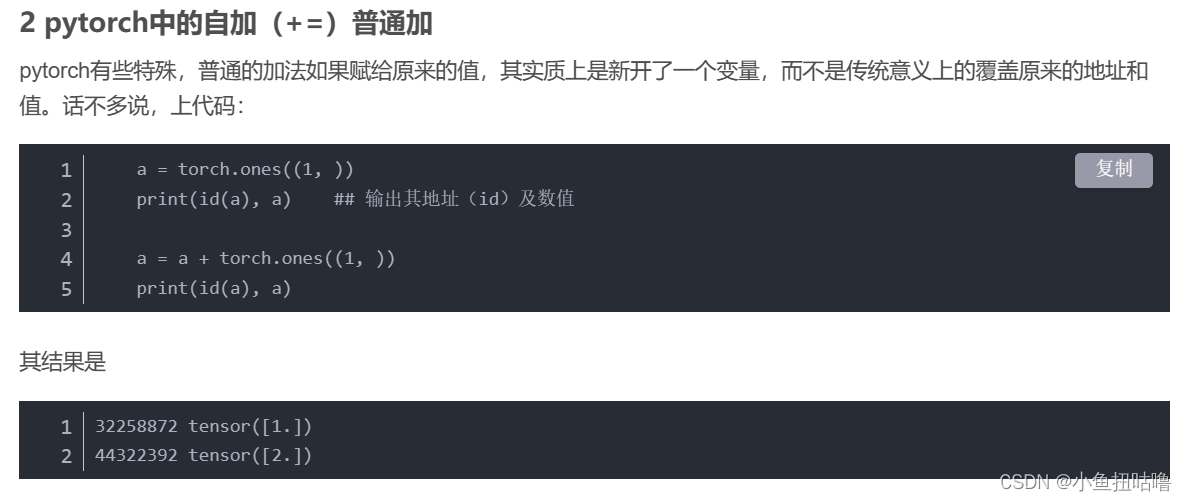
(10)pytorch中自加(+=)与 普通 +


(11)criterion()——损失函数

2.复现PNN和PanNet时遇到的问题
(1)class、def、super()、forward:各种基本函数
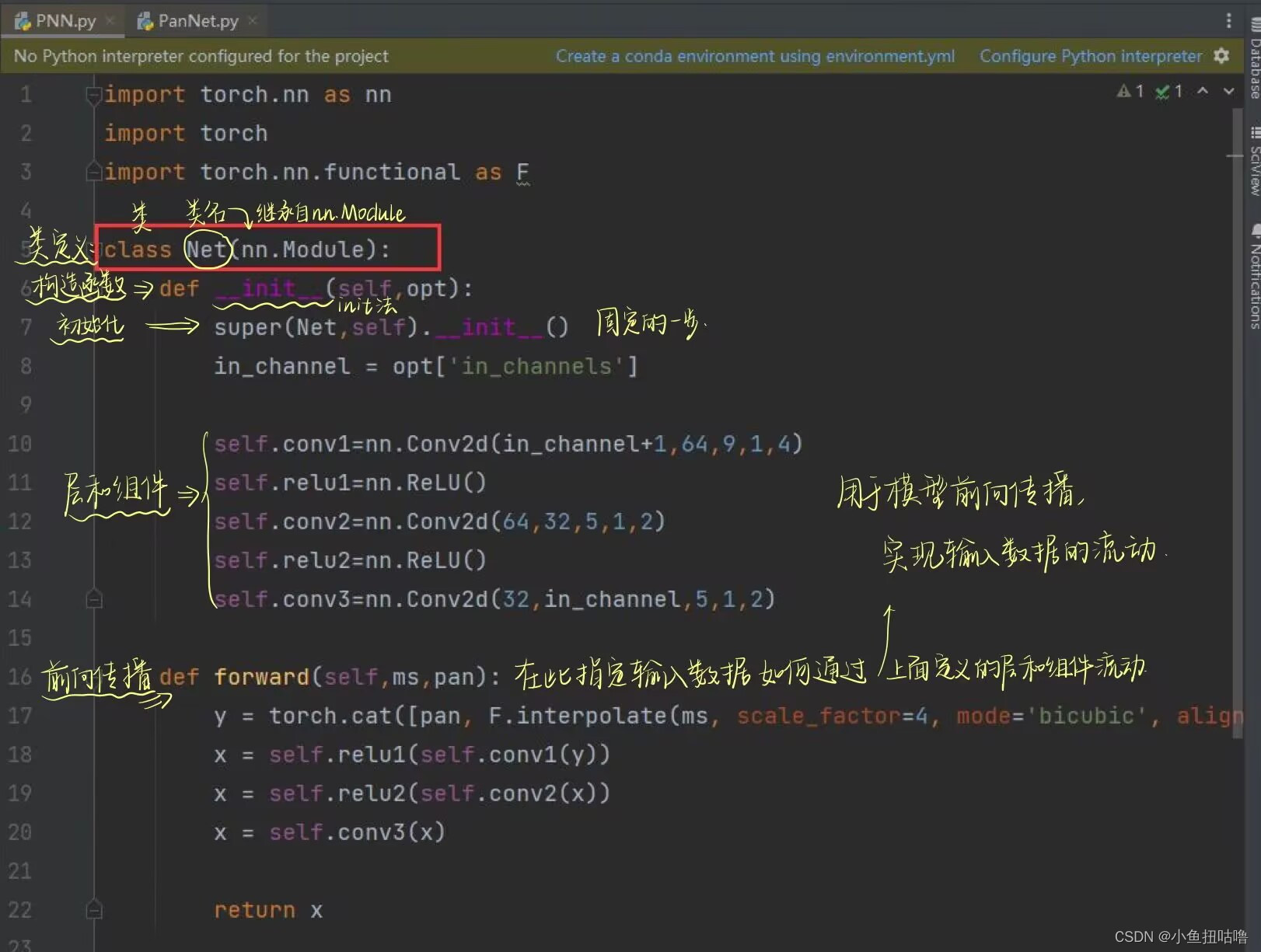
nn.Module----pytorch 中的重要模块化接口
torch.nn是专门为神经网络设计的模块化接口,nn构建于autgrad之上,可以用来定义和运行神经网络
nn.Module是nn中重要的类,其包含网络各层的定义函数,即构造函数 def init(self),以及前向传递函数def forward(self,x)
参考:http://t.csdnimg.cn/ZsaiN http://t.csdnimg.cn/9OHmR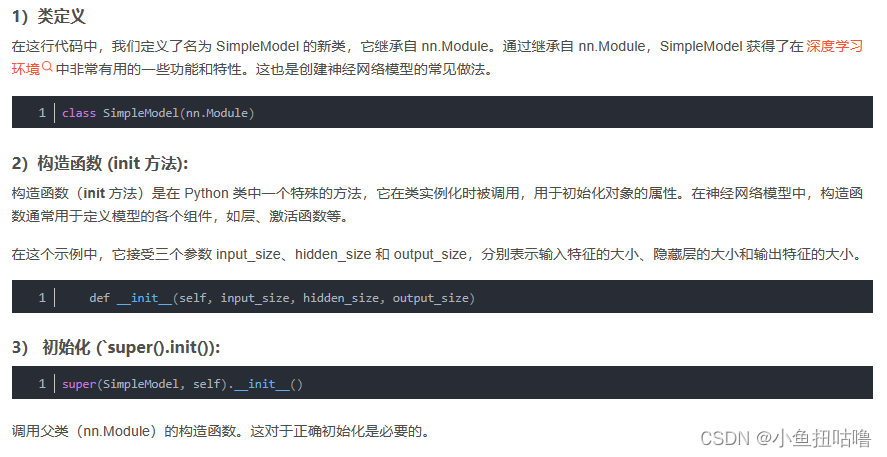

(2)nn.BatchNorm2d——批量标准化操作
-
批量归一化:批量归一化是一种用于加速深度神经网络训练的技术。它通过对每个小批量的输入数据进行归一化,使得网络在训练过程中更加稳定和快速收敛。批量归一化可以减少梯度消失和梯度爆炸问题,并且有正则化的效果,可以一定程度上防止过拟合。它的主要目的是加速神经网络的训练过程并提高模型的性能。以下是使用批量归一化的几个原因:
-
梯度消失和梯度爆炸问题:在深度神经网络中,随着网络层数的增加,梯度的传播容易出现梯度消失或梯度爆炸的问题。批量归一化通过对每个批次的输入进行归一化,使得输入的均值接近0,方差接近1,从而缓解了梯度消失和梯度爆炸问题。
-
加速训练过程:批量归一化可以使得每一层的输入都具有相似的分布,这有助于加速网络的收敛过程。通过减少内部协变量偏移(Internal Covariate Shift),批量归一化可以使得每一层的参数更容易学习。
-
正则化效果:批量归一化在一定程度上起到了正则化的效果,减少了模型对于输入数据的依赖性,从而提高了模型的泛化能力。
-
具有一定的正则化效果:批量归一化在一定程度上起到了正则化的效果,减少了模型对于输入数据的依赖性,从而提高了模型的泛化能力。
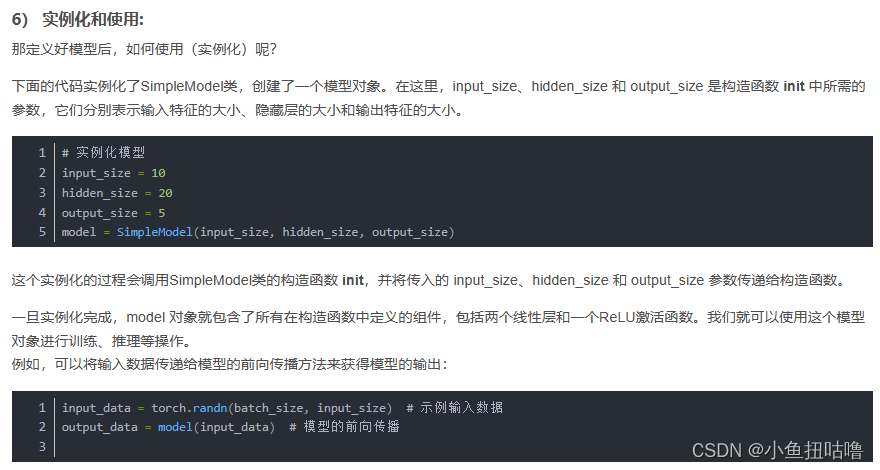
(3)nn.Conv2d——二维卷积
![]()
(4) nn.Sequential()——多个计算层按照顺序组合成一个模型
nn.Sequential()是PyTorch中的一个类,它允许用户将多个计算层按照顺序组合成一个模型。在深度学习中,模型可以是由各种不同类型的层组成的,例如卷积层、池化层、全连接层等。nn.Sequential()方法可以将这些层组合在一起,形成一个整体模型。
torch.nn.Sequential(*args)参数:args:一个由层组成的列表。

(5) torch.split()——将tensor分成块结构
torch.split(tensor, split_size_or_sections, dim=0)torch.split()作用将tensor分成块结构。

(6) torch.unsqueeze()和torch.squeeze()——升维和降维
(7)torch.ones——返回元素是1的tensor
torch.ones(*size, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor

3.复现HyperTransformer时遇到的问题
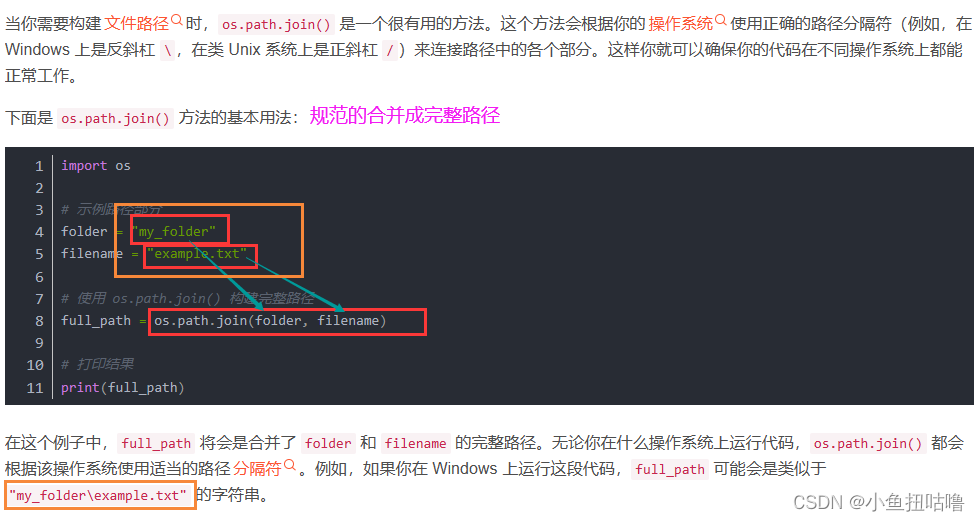
(1)os.path.join


(2).rstrip()
删除 string 字符串末尾的指定字符,默认为空白符,包括空格、换行符、回车符、制表符。它不会修改原始字符串,而是返回删除了尾随空格的新字符串。
line.rstrip("\n") 那就是 删除line这个字符串的末尾指定的字符(这里是换行符)
(3)open()
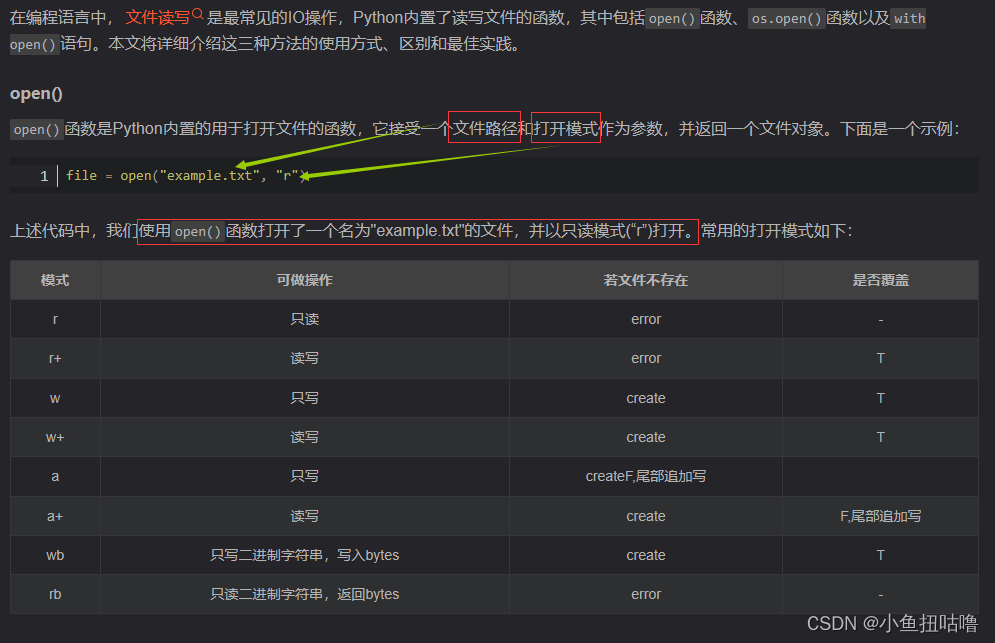
上面的链接包含了具体是怎么open的,以及os.open()和with open()
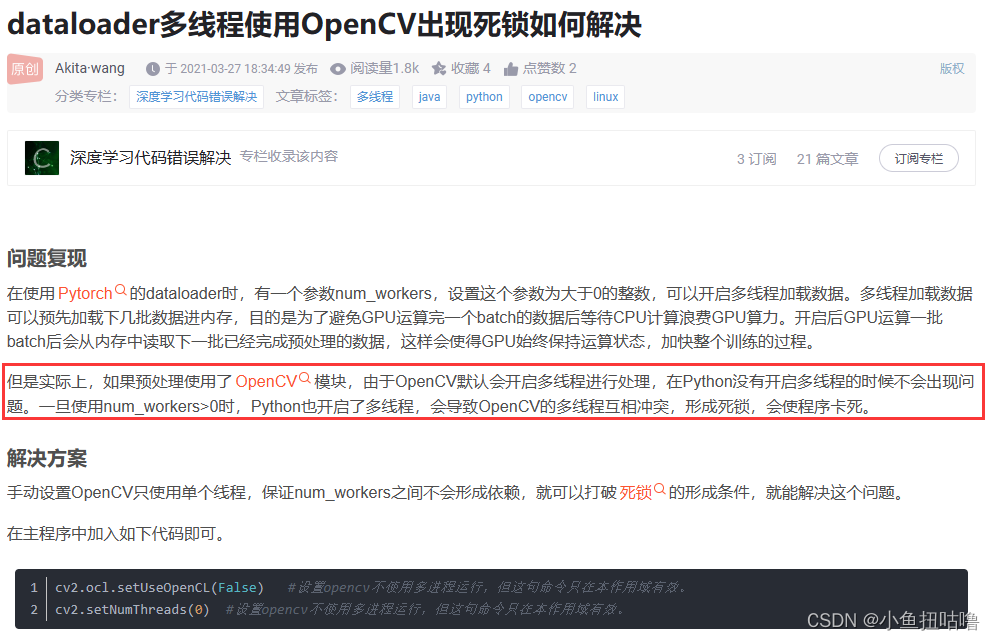
(4) cv2.setNumThreads()
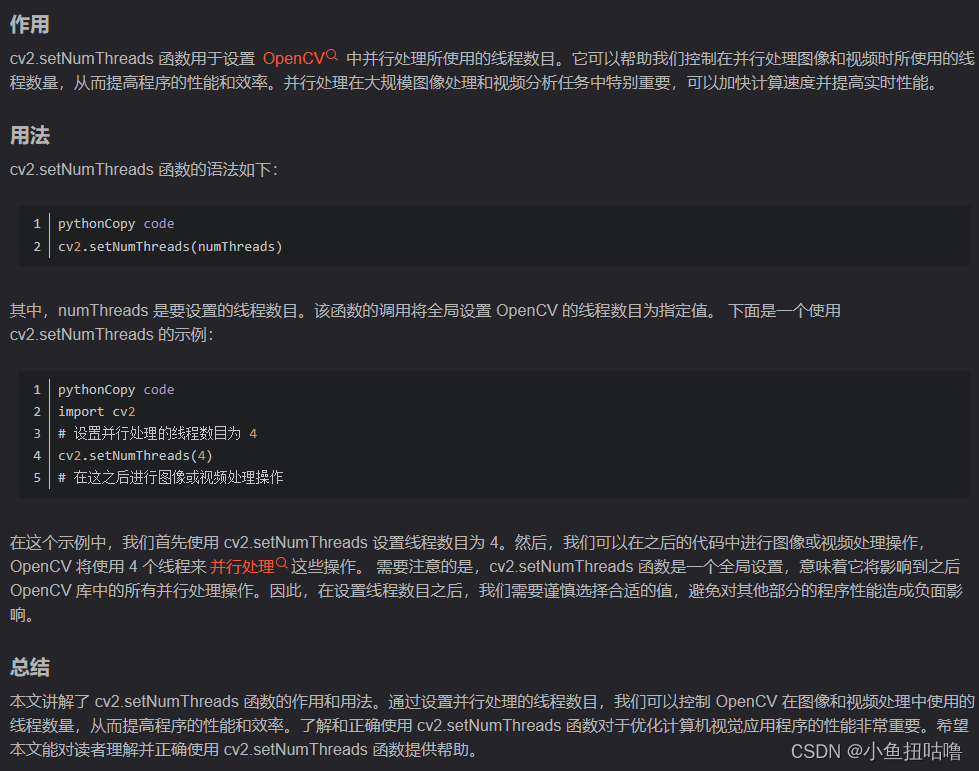
其实就是 避免CV线程和Pytorch线程在调整大小时发生死锁















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









