







1.数据库概述
1.1 什么是数据库
数据库简称DB,全称为database。
从字面来看,数据库就是存储各种不同数据类型的数据. 就是一个存储数据的仓库
1.2 为什么要使用数据库
唯一的目的: 持久化保存数据。
IO(读写文件数据)虽然也可以实现持久化。但是操作较复杂,数据存储文件,可读性不是很高。
因此,很多开发厂商,站在程序员多样化需求前提下,开发了数据库这样一个软件。可以直观的看到不同类型的数据,以及实现数据持久化操作。
1.3 数据库分类
- 按存储位置的不同进行分类:
- 基于磁盘的存储,MySQL,Oracle,SQLServer等。将数据写入文件,底层是IO.
优势: 完全保证数据的持久化。
弊端: 底层是IO实现,读写性能偏低。 - 基于内存的存储。将数据存储内存或者缓存。比如Redis。
优势:查询性能高。
弊端:不能完全保数据持久化。比如Redis后期可以使用RDB以及AOF进行解决。
- 基于磁盘的存储,MySQL,Oracle,SQLServer等。将数据写入文件,底层是IO.
- 按从数据间是否存在关系进行分类:
- 关系型数据库:MySQL,Oracle,SQLServer等。表与表,字段与字段,数据与数据之间存在一定的关系。
- 非关系型数据库:我们又称为NOSQL(not only sql)。redis,mongodb 等
1.4 DBMS
在上面,我们简单描述了数据库的基本概念和分类。但是对于经常我们所听说到的MySQL、SQLServer、Oracle等,不能直接称为数据库。
他们是一个软件,仅仅是一个服务(服务器)。所以,我们要学习的也不是数据库,而是要学习一个软件。称为数据库管理系统软件。更深一步来说,我们要学习MySQL,他就是一个DBMS,或者说RDBMS(关系型数据库管理系统软件).
RDBMS 即关系数据库管理系统(Relational Database Management System)的特点:
- 数据以表格的形式出现
- 每行为各种记录名称
- 每列为记录名称所对应的数据域
- 许多的行和列组成一张表单
- 若干的表单组成database
1.5 RDBMS 术语
在我们开始学习MySQL 数据库前,让我们先了解下RDBMS的一些术语:
- 数据库: 数据库是一些关联表的集合。
- 数据表: 表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
- 列: 一列(数据元素) 包含了相同类型的数据, 例如邮政编码的数据。
- 行:一行(元组,或记录)是一组相关的数据,例如一条用户订阅的数据。
- 冗余:存储两倍数据,冗余降低了性能,但提高了数据的安全性。
- 主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
- 外键:外键用于关联两个表。
- 复合键:复合键(组合键)将多个列作为一个索引键,一般用于复合索引。
- 索引:使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排- 序的一种结构。类似于书籍的目录。
- 参照完整性: 参照的完整性要求关系中不允许引用不存在的实体。与实体完整性是关系模型必须满足的完整性约束条件,目的是保证数据的一致性。
2.MySQL入门
2.1 什么是MySQL
MySQL 是一个关系型数据库管理系统,由瑞典 MySQL AB 公司开发,目前属于 Oracle 公司。MySQL 是一种关联数据库管理系统,关联数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
MySQL特点:
- MySQL 数据库是关系型的
- MySQL 软件是开源的
- 使用 C 和 C++ 编写
- MySQL 数据库服务器非常快速、可靠、可扩展且易于使用
- 使用非常快速的B树磁盘表(MyISAM)和索引压缩
- 使用非常快速的基于线程的内存分配系统
2.2 安装MySQL
- MySQL安装教程
1. 从MySQL官网下载安装软件 https://dev.mysql.com/downloads/windows/installer/8.0.html(咱们学习用的是8.0.*的版本)
2. 双击打开安装
3. 只需要选择安装 server即可。
4. 记住MySQL端口号: 3306(一般不改)
5. 记住MySQL的用户名: root 密码: root(密码是自定义的,自己牢记即可)
6. msi文件安装方式,不能手动选择安装目录路径。默认安装在c盘
7. 对本地磁盘的改动
C:\Program Files\MySQL 可执行的工具bin、lib、doc....
C:\ProgramData\MySQL\MySQL Server 8.0 (隐藏目录) 数据库的数据以及mysql的配置 my.ini
- MySQL配置文件my.ini的部分内容
default-character-set=UTFMB4
character-set-server=
port=3306
datadir=C:/ProgramData/MySQL/MySQL Server 8.0\Data
default-storage-engine=INNODB
max_connections=151 允许的最大的并发量
- 验证是否安装成功
打开cmd窗口使用相关指令验证。输入 mysql,没有生效的话需要配置MySQL的环境变量。
需要配置mysql的环境变量: 在path配置安装MySQl目录的bin目录。
3.SQL概述
3.1 SQL简介
SQL (structure query language) 结构化查询语言,专门与DBMS通信的语言,所有RDBMS(关系型数据库 如MySQL,Oracle,SQLserver等)都支持;可使用SQL操作里面的库、表、字段、数据等。
- SQL分类:
DDLdata nation language 数据定义语言。 用来定义数据库对象:库、表、列等
CREATE DROP ALTER TRUNCATEDML数据操作语言。 INSERT DELETE UPDATE (更新)DQL数据查询语言。 SELECT- DCL 数据控制语言。 GRANT
TCL事务控制语言。 COMMIT ROLLBACK
3.2 常用命令
- mysql -hip -uroot -p – 在cmd窗口 使用此指令连接数据库服务器
- show databases; – 查看mysql所有的数据库
- select database(); – 查看目前正在操作的数据库
- use 数据库的名称; – 切换要操作的数据库
- show tables; – 展示指定的数据库里面所有的表
- desc 表名; – 查看指定的表的表结构 属性/列,数据类型,约束
mysql> show databases; -- 查看mysql所有的数据库
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
mysql> select database();-- 查看目前正在操作的数据库
+------------+
| database() |
+------------+
| NULL |
+------------+
mysql> use mysql -- use 数据库的名称; 切换要操作的数据库
mysql> show tables; -- 展示指定的数据库里面所有的表
+------------------------------------------------------+
| Tables_in_mysql |
+------------------------------------------------------+
| columns_priv
mysql> desc user; -- desc 表名; 查看指定的表的表结构 属性/列,数据类型,约束
+--------------------------+-----------------------------------+------+-----+-----------------------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------------------+-----------------------------------+------+-----+-----------------------+-------+
| Host | char(255) | NO | PRI | | |
| User | char(32) | NO | PRI | | |
| Select_priv | enum('N','Y') | NO | | N | |
| Insert_priv
-- 查询数据 sql----> select
mysql> select * from user; -- 查询指定表里面所有的记录 select * from 表名;
-- * : 通配符 通配表里面所有的字段/列/属性
mysql> select host,user from user; -- 查询指定的表的列
+-----------+------------------+
| host | user |
+-----------+------------------+
| localhost | mysql.infoschema |
| localhost | mysql.session |
| localhost | mysql.sys |
| localhost | root |
+-----------+------------------+
3.3 数据类型
3.3.1 整数类型
- 可以选择有符号表示 和无符号表示(正数,可以使用unsigned属性修饰);
- 对于整数类型,支持指定显示宽度
- 整数型有个属性auto_increment, 此属性只用于整数类型。 一个表最多只有一个auto_increment 列,标识自增
| 类型 | 大小 | 有符号范围 | 无符号范围 |
|---|---|---|---|
| TINYINT(m) | 1 | -128-127 | 0 - 255 |
| SMALLINT(m) | 2 | -32768-32767 | 0 - 65535 |
| MEDIUMINT(m) | 3 | -8388608-8388607 | 0 - 16777215 |
| INT(m) | 4 | -2147483648-2147483647 | 0 - 4294967295 |
| BIGINT(m) | 8 | -9223372036854775808 - 9223372036854775807 | 0 - 18446744073709551615 |
- m表示SELECT查询结果集中的显示宽度,与取值范围无关。 m最大值11
- tinyint(1) unsingned ,数值只能是0与1,对应java里面的boolean类型。否则就是对应java语言里面的byte或者int
- zerodfill属性: int(5) 00100 如果不满5个数字,会在数值之前使用0进行填充。
3.3.2 浮点类型
| 类型 | 大小 | 有符号范围 |
|---|---|---|
| FLOAT(m,d) | 4 | -3.402823466E+38 to -1.165494351E-38 |
| DOUBLE(m,d) | 7 | |
| DECIMAL(m,d) | 可变 | 根据M和D 的值 |
m为数字的总个数,d为小数点之后的个数。- 定点数在MySQL内部以字符串形式存放 比浮点数更精确 适合用来存放货币等精度高的数据;
- 浮点数和定点数都可以在后面加(M,D) M表示显示的位数 D表示小数的位数,当存入的小数位过长时 此三者都会进行四舍五入
- Decimal(m,d) 定点数 参数m<65 是总个数,d<30且 d<m 是小数位。 BigDecimal
- decimal在不指定精度时,默认的整数位时10,默认的小数位是0
3.3.3 字符类型
| 类型 | 最大长度 | 描述 |
|---|---|---|
| CHAR(m) | 255字符 | 定长字符 |
| VARCHAR(m) | 65535 | 变长字符 |
| TEXT | 16KB | 可变长度。最多存储65535个字符。 |
| LONGTEXT | 4G | 最多存储2的32次方-1个字符 |
- char与varchar 类似都是用来保存MySQL中较短的字符串,主要区别在于存储方式不同。
- char列的长度固定为创建表时声明的长度 长度可以是0-255中的任意值;
- varchar为可变长字符串 长度可以指定0-65535间的任意值
3.3.4 日期时间类型
| 类型 | 字节 | 最小值 | 最大值 |
|---|---|---|---|
| date | 4 | 1000-01-01 | 9999-12-31 |
| datetime | 8 | 1000-01-01 00:00:00 | 9999-12-31 23:59:59 |
| timestamp | 4 | 1970-01-01 08:00:01 | 2038年某个时刻 |
| time | 3 | -838:59:59 | 838:59:59 |
| year | 1 | 1901 | 2155 |
timestamp和datetime的区别:
- timestamp的取值范围小,最大到2038年的某个时间,datetime取值范围更大;两者都支持 on update current_timestamp属性 使得日期列可以随着其他列的更新而自动更新为最新时间.
- timestamp的插入和查询受到时区的影响 更能反映出实际的日期;datetime只能反映插入时当时的时区
- timestamp的属性受到MySQL版本和服务器sqlMode的影响很大
设置自动更新示例:
CREATE TABLE t2(
c1 int,
-- 添加了2个属性 使得此纪录其他数据更新时这列的时间也会更新
c2 TIMESTAMP default CURRENT_TIMESTAMP on UPDATE CURRENT_TIMESTAMP
)
4.DDL
数据定义语言,主要包含:
- 创建库/表CREATE
- 删除库/表DROP
- 更新表结构ALTER
4.1 操作库
- 创建数据库
语法: create database 数据库名称 [if not exsits];
CREATE DATABASE mydb; --数据库一旦创建成功 数据库的名称无法更改的。
- 删除数据库
语法:DROP DATABASE mydb 数据库名称
DROP DATABASE mydb; -- 删除数据库 数据无法回滚
- 修改数据库
语法:ALTER DATABASE 数据库名称 参数
ALTER DATABASE mydb COLLATE Chinese_PRC_CI_AS; --修改数据库排序规则
4.2 操作表
- 创建表
- 语法:
CREATE TABLE 表名(
列1 数据类型 [约束],
列2 数据类型 [约束],
列3 数据类型 [约束],
....
列n 数据类型 [约束]
);
注意:
- 列名必须要唯一,在mysql里面 所有的列名都必须是小写,有多个单词 使用_关联即可。
- 表名一般还是小写 不要使用复数 有多个单词 使用_关联即可
- 映射的概念:
表==>实体类 表字段===>类的属性 表字段的数据类型==>属性的数据类型 表每行记录===>类的每个对象
CREATE TABLE student(
id int,
stu_name varchar(20),
stu_age tinyint(2) unsigned,
stu_score float(4,1),
birthday date,
school_date datetime,
school_money decimal(6,1) -- 最后一个列不要加逗号
);
- 删除表
语法:drop table 表名
DROP TABLE student -- 数据不会回滚 会一起将表数据全部清除
- 修改表结构
ALTER TABLE tb_userinfo add address varchar(50); -- 1. 新增新的列/字段 address
ALTER TABLE tb_userinfo drop address; -- 2.删除指定的列
ALTER TABLE tb_userinfo change age user_age tinyint(2) unsigned; -- 3.修改指定列的列名 age->user_age
ALTER TABLE tb_userinfo change username username char(30); -- 4.修改指定列的数据类型
ALTER TABLE tb_userinfo modify username varchar(30);
ALTER TABLE tb_userinfo rename userinfo; -- 5.修改指定表的表名
5.DML
数据操作语言,主要包含:
- INSERT 新增
- DELETE 删除
- UPDATE 修改
5.1 新增记录
新增行记录,可以一次新增一行,也可以批处理新增多行。
- 新增并赋值所有列
语法:INSERT INTO 表名 VALUES (数据1,数据2…数据n); 数据的数量取决于列的数量
INSERT INTO userinfo VALUES (1,'张三',20,'1234','男','游戏,代码',100000,'2000-01-01','2022-12-03 12:00:00',null);
- 新增并赋值指定列
语法:INSERT INTO 表名 (列1,列2…列n) VALUES(数据1,数据2…数据n);
INSERT INTO userinfo (id,username,password,create_time) VALUES (4,'李四','1111',now());
5.2 修改记录
- 修改记录
语法:UPDATE 表名 SET 列1=新数据1,列2=新数据3…列n=新数据n WHERE 条件1 AND/OR 条件2
UPDATE userinfo SET user_age=18,gender='男',birthday=now(),update_time=now() WHERE id=4;
5.3 删除记录
- 删除记录
语法:DELETE from 表名 where 条件1 and/or 条件2;
DELETE FROM userinfo WHERE username='张三';
DELETE FROM userinfo WHERE id=1001;
DELETE FROM userinfo WHERE user_age IS NULL;
DELETE FROM userinfo WHERE id=1001 OR id = 3;
DELETE FROM userinfo WHERE id IN (1002,4);
- 清空表数据
语法:DELETE FROM 表名; 清空表数据(在开启事务的前提下 数据可以回滚的)
DELETE FROM userinfo; --不加条件,清空表数据
6.DQL
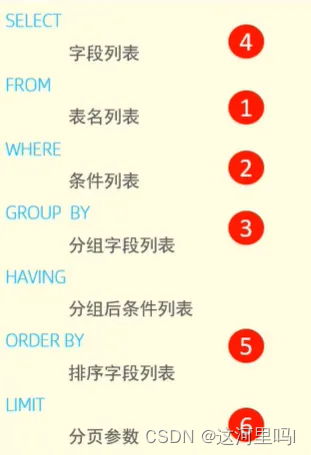
6.1 基本语法
SELECT DISTINCT
列名1,列名2....列名n /*要查询的字段,多个字段用逗号隔开*/
FROM
表1,表2...表n /*要查询的表名称*/
[WHERE 条件1 AND/OR 条件1] -- 条件过滤
[GROUP BY 列] -- 根据指定的列进行分组
[HAVING 条件1 AND/OR 条件1] -- 条件过滤(分组之后的数据进行过滤)
[ORDER BY 列1,列2 ASC/DESC] -- 根据列进行排序 默认升序 ASC 降序: DESC
[LIMIT ?/?,?] -- 限定结果集(分页查询);
6.2 基础查询
- 查询所有列
SELECT * FROM stu;
- 查询指定列
SELECT sid,sname,sage FROM stu;
6.3 条件查询
条件查询就是在查询时给出WHERE子句,在WHERE子句中可以使用如下运算符及关键字:
=、!=、<>不等于、<、<=、>、>=;
- BETWEEN…AND;是否满足一个区间范围 >= <=
- IN(set);条件的集合
- IS NULL;是否非空
- AND; 连接多个条件的查询
- OR;or 满足其中一个条件就可以
- NOT;条件取反
-- 1、查询学生性别为女,并且年龄50的记录
SELECT * FROM stu WHERE gender='FEMALE' AND age=15;
-- 2、查询学号为S_1001,S_1002,S_1003的记录
SELECT * FROM stu WHERE sid ='s_1001' OR sid ='s_1002' OR sid ='s_1003';
SELECT * FROM stu WHERE sid IN ('s_1001','s_1002','s_1003');
-- 3、查询学号不是S_1001,S_1002,S_1003的记录
SELECT * FROM stu WHERE sid !='s_1001' AND sid <>'s_1002' AND sid !='s_1003';
SELECT * FROM stu WHERE sid NOT IN ('s_1001','s_1002','s_1003');
-- 4、查询年龄为null的记录
SELECT * FROM stu WHERE age IS NOT NULL;
-- 5、查询年龄在20到40之间的学生记录
SELECT * FROM stu WHERE age>=20 AND age<=40;
SELECT * FROM stu WHERE age BETWEEN 20 AND 40;
-- 6、查询性别非男的学生记录
SELECT * FROM stu WHERE gender !='male' OR gender IS NULL;
6.4 模糊查询
模糊查询,处理字符类型.
- _:通配任意一个字符(数字,字母,汉字,特殊符号等)
- %:表示0个或多个字符
-- 1、查询姓名由5个字符构成的学生记录
-- 通配符: 数据 一个字符使用 _
SELECT * FROM stu WHERE sname LIKE '_____';
SELECT * FROM stu WHERE CHAR_LENGTH(sname)=5;
-- 通配不定数量的字符的数据 %
-- 2、查询姓名以“z”开头的学生记录
SELECT * FROM stu WHERE sname LIKE 'z%';
-- 3、查询姓名中第2个字母为“i”的学生记录
SELECT * FROM stu WHERE sname LIKE '_i%';
-- 4、查询姓名中包含“a”字母的学生记录
SELECT * FROM stu WHERE sname LIKE '%a%';
6.5 字段控制查询
- DISTINCT
对指定的列的数据进行去重.
去除重复记录(两行或两行以上记录中系列的上的数据都相同),例如emp表中sal字段就存在相同的记录。当只查询emp表的sal字段时,那么会出现重复记录,那么想去除重复记录,需要使用DISTINCT:
-- 1. 查询学生表中的所有性别
SELECT gender FROM stu;
SELECT DISTINCT gender FROM stu ;
-- 2. 查询所有的员工信息
SELECT empno,ename,esal,mgr FROM emp;
-- -- DISTINCT去重 后面有多个字段 当这多个字段的值都相同的时候认为是重复的
SELECT DISTINCT empno,ename,esal,mgr FROM emp;
- IFNULL(列名,默认值)
数据为NULL时可替换成默认值
-- 查询学生的明年的年龄
-- 概念: 临时表/虚拟表 所有的查询的结果都在一张临时表/虚拟表中。
-- 查询的虚拟表 在物理内存中不一定存在的。
-- 列的数据是null 执行任意算术运算 结果还是null
-- IFNULL(列,默认数据)
SELECT sid,sname,age,gender,age+1 FROM stu;
-- 查询所有员工的薪水+奖金之和
SELECT empno,ename,sal,comm, sal+IFNULL(comm,0) FROM emp;
- AS
在上面查询中出现列名为sal+IFNULL(comm,0),这很不美观,现在我们给这一列给出一个别名,为total:
给列起别名时,是可以省略AS关键字的
表名,字段名等都可以使用别名查询
-- 很多时候 在查询期间 会有 很多新的列 列名使用默认的数据作为列名
-- 建议起别名进行查询 AS AS 可以省略
-- 重名情况使用别名可以区分
-- 对列 表都可以起别名
SELECT empno,ename,sal,comm, sal+IFNULL(comm,0) AS money FROM emp;
SELECT u.id FROM demo.tb_userinfo AS u;
SELECT sid AS '学生id',sname AS '学生姓名' FROM stu;
6.6 排序
对行记录进行升序或者降序排列。
可以跟单个字段,多个字段,表达式,函数,别名进行排序。
默认是升序 ASC , 降序为DESC.
-- 查询所有学生记录,按成绩进行降序排序
-- 缺省是ASC升序
SELECT * FROM stu ORDER BY age DESC;
-- 查询所有学生记录,首先先按成绩进行降序排序,如果成绩相同,按名字进行升序排序
SELECT * FROM stu ORDER BY age DESC, sid ASC;
-- 查询emp的薪水 降序排列 sal相同 根据comm进行降序排序
-- 多个列排序的话 根据其中一个排序 列的数据相同了 再根据另外一个列排序
-- 一次select里面只能有一个 ORDER BY
SELECT * FROM emp ORDER BY sal DESC,comm DESC;
-- 查询sal>1500 根据sal降序排列 sal相同 根据comm进行降序排序
SELECT * FROM emp WHERE sal>1500 ORDER BY sal DESC,comm DESC;
6.7 聚合函数
聚合函数还可以称为组函数、分组函数
用作统计使用,又称为聚合函数或者统计函数或者组函数
聚合函数是用来做纵向运算的函数:
- COUNT(字段/列):统计指定列不为NULL的记录行数;一般使用count(*)统计行数
- MAX(字段/列):计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算;
- MIN(字段/列):计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算;
- SUM(字段/列):计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0;
- AVG(字段/列):计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0;
- SUM、AVG一般处理数值型
- MAX、MIN、COUNT可以处理任意数据类型
- 分组函数都忽略了NULL值,可以和DISTINCT搭配使用
注意点:组函数可以出现多个,但是不能嵌套;如果没有GROUP BY 子句,结果集中所有行数作为一组
-- 查询emp表中有佣金的人数,统计指定列不为NULL的记录行数
SELECT count(comm) a FROM emp;
-- SELECT 200+null;
SELECT count(empno) AS '总人数' FROM emp;
SELECT count(*) AS '总人数' FROM emp;
SELECT count(1) AS '总人数' FROM emp;
-- 查询emp表中有佣金的人数
SELECT count(comm) FROM emp;
-- 查询emp表中月薪大于2500的人数:
SELECT * FROM emp WHERE sal>2500;
-- 统计月薪与佣金之和大于2500元的人数: ifnull(表达式1,表达式2) 如果表达式1为null那么取表达式2的值,否则取表达式1的值
SELECT * FROM emp WHERE sal+ifnull(comm,0) >2500;
-- 查询有佣金的人数,以及有领导的人数:
SELECT count(comm) FROM emp WHERE mgr is not null;
-- 查询所有雇员月薪和:
SELECT sum(sal) 总薪资 FROM emp;
-- 查询所有雇员月薪和,以及所有雇员佣金和:
SELECT sum(sal) 总薪资,SUM(comm) 总佣金 FROM emp;
-- 查询所有雇员月薪+佣金和
SELECT sum(sal+ifnull(comm,0)) 总佣金 FROM emp;
SELECT sum(sal)+sum(ifnull(comm,0)) 总佣金 FROM emp;
-- 统计所有员工平均工资
SELECT avg(sal) 平均薪资 FROM emp;
-- 查询最高工资和最低工资
SELECT max(sal),min(sal) FROM emp;
6.8 分组查询
- 普通分组查询
- 对行记录进行分组查询。
- 查询出来的字段要求是 GROUP BY 后的字段,查询字段中可以出现组函数
- SELECT 后面的字段 是分组字段
- GROUP BY后面可以跟聚合函数 可以起别名
-- 查询每个部门的部门编号和每个部门的工资和
SELECT deptno,SUM(sal) FROM emp GROUP BY deptno;
-- 查询每个部门的部门编号以及每个部门的人数
SELECT deptno,SUM(sal),COUNT(1) FROM emp GROUP BY deptno;
-- 查询每个部门的部门编号以及每个部门员工工资大于1500的人数:
SELECT deptno,COUNT(1) FROM emp WHERE sal>1500 GROUP BY deptno;
-- 查询stu 根据gender统计学生的数量
SELECT gender,COUNT(*) FROM stu GROUP BY gender;
- 分组后过滤
与WHERE的功能一样,都是用来实现条件过滤。
- WHERE VS HAVING
- WHERE是对分组前进行过滤;HAVING是对分组后进行过滤
- WHERE是比分组先执行的,HAVING是在分组之后执行的;
- WHERE中不能出现分组/聚合函数,HAVING中可以出现
- HAVING后面可以跟别名
-- 查询工资总和大于9000的部门编号以及工资和:
SELECT deptno,sum(sal) FROM emp GROUP BY deptno HAVING sum(sal)>9000;
-- having中使用别名
SELECT deptno,sum(sal) 总薪资 FROM emp GROUP BY deptno HAVING 总薪资>9000;
-- 查询部门员工个数大于3的,having中使用了别名
SELECT COUNT(1) AS cc,deptno FROM emp GROUP BY deptno HAVING cc>3;
6.9 LIMIT
LIMIT可实现分页查询。对最后的结果进行限定(mysql独有)。
- SELECT * FROM 表 LIMIT size; 指定从第一条记录开始查询 查size条
- SELECT * FROM 表 LIMIT ?,size 指定从第n条记录(index)开始查询 查size条
-- 分页展示员工表的数据
-- size:5 每页展示的数据量
-- totalPage=totalCount/size;
-- totalCount = SELECT COUNT(*) FROM emp; 14
-- totalPage=3
-- 用户请求查询第page页的数据
-- 第一页 page=1
-- SELECT * FROM emp WHERE 1=1 LIMIT size;
-- SELECT * FROM emp WHERE 1=1 LIMIT 5; -- 从第1行记录查询 展示size条数据
SELECT * FROM emp WHERE 1=1 LIMIT 0,5;
-- 第二页page=2
-- SELECT * FROM emp WHERE 1=1 LIMIT start,size;
-- start: 查询第几行记录的index size: 查询的每页展示的数据量
SELECT * FROM emp WHERE 1=1 LIMIT 5,5;
-- 第三页page=3
SELECT * FROM emp WHERE 1=1 LIMIT 10,5;
-- 通用的写法
SELECT * FROM emp WHERE 1=1 LIMIT (page-1)*size ,size;
6.10 多表查询
- 笛卡尔积
如果多表查询中进行分组且不指定条件,就会产生笛卡尔集
例:SELECT * FROM AA,BB ORDER BY a1,b1
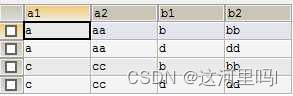
a1和b1表本来都是2行2列的数据
形成笛卡尔积后会对(非空)数据进行拼接,最终产生4行4列的数据
使用WHERE子句设置筛选条件,可排除无效数据
- 内连接
- 多表等值连接的结果是多表的交集部分,N表连接,至少需要N-1个连接条件,没有顺序要求,一般起别名
- 非等值连接,只要不是等号连接的都是非等值连接
-- 多表关联查询 起别名查询 AS
-- 多表关联查询 有可能出现笛卡尔积的结果。必带条件 where(表与表的关系---> 外键列)
-- 2张 至少1个 3 至少2
-- 1、查询员工信息,要求显示员工号,姓名,月薪,部门名称
-- 笛卡尔积 (a, b) (1,2,3) --(a,1) (a,2) (a,3) (b,1) (b,2) (b,3)--》会生成一个中间表
SELECT
e.empno,e.ename,e.sal,d.deptno,d.dname,d.loc
FROM
emp AS e,dept AS d
WHERE e.deptno=d.deptno ORDER BY d.deptno;
-- 2、查询员工信息,要求显示:员工号,姓名,月薪,薪水的级别
SELECT
e.empno,e.ename,e.sal,s.grade
FROM
emp AS e,salgrade AS s
-- WHERE e.sal>=s.LowSAL AND e.sal<=s.HISAL ORDER BY s.GRADE;
WHERE e.sal BETWEEN s.lowsal AND s.hisal ORDER BY s.GRADE;
-- 3、查询员工信息,要求显示:员工号,姓名,月薪,部门名称,薪水的级别
SELECT
e.*,d.dname,d.loc,s.grade
FROM
emp AS e,dept AS d,salgrade AS s
WHERE
e.deptno=d.deptno AND e.sal BETWEEN s.lowsal AND s.hisal;
- 外连接
- 外连接,有主表有从表,主表肯定会显示完整的内容
- 左外连接,以左表为主,右表没有的数据使用NULL或者0进行填充。
- 右外连接,以右表为主,左表 没有的数据使用NULL或者0进行填充。
- 左外与右外的条件必须使用ON进行关联。
- ON后面的条件(ON条件)和WHERE条件的区别:
- ON条件:是过滤两个链接表笛卡尔积形成中间表的约束条件。
- WHERE条件:在没有ON的单表查询中,是限制物理表或者中间查询结果返回记录的约束。
在两表或多表连 接中是限制连接形成最终中间表的返回结果的约束。- 建议:ON只进行外连接操作,WHERE只过滤中间表的记录
使用场景:
- 进行多表查询,且表中数据存在空值时,由于笛卡尔积中不会对空值进行处理,所有合并后会造成数据缺失
- 使用外连接可对没有的数据使用NULL或者0进行填充。从而保证数据完整。
-- 外连接
-- 查询员工信息,要求显示员工号,姓名,月薪,部门名称 使用内连接和等值连接等同
SELECT empno,ename,sal,emp.deptno,dname FROM emp INNER JOIN dept on emp.deptno=dept.deptno;
-- 左外连接(左连接) 左边的表内容全部显示,右边的表没有的以null进行填充
SELECT empno,ename,sal,emp.deptno,dname FROM emp LEFT JOIN dept on emp.deptno=dept.deptno;
-- 右外连接,右表内容全部显示,左表没有的以null进行填充
SELECT empno,ename,sal,emp.deptno,dname FROM emp RIGHT JOIN dept on emp.deptno=dept.deptno;
-- SELECT deptno,COUNT(*) FROM emp GROUP BY deptno;
-- 查询所有部门的名称以及每个部门的员工数量 count
-- 展示部门编号 部门名称 位置 员工数量
SELECT
d.*,COUNT(*) AS '员工数量'
FROM
dept AS d,emp AS e
WHERE e.deptno=d.deptno
GROUP BY d.deptno;
SELECT
d.*,COUNT(*) AS '员工数量'
FROM
dept AS d INNER JOIN emp AS e ON e.deptno=d.deptno
WHERE 1=1 AND 2=2
GROUP BY d.deptno;
SELECT
d.*,COUNT(e.empno) AS '员工数量'
FROM
emp AS e RIGHT JOIN dept AS d ON e.deptno=d.deptno
GROUP BY d.deptno;
- 自连接
- 本表与本表进行关联查询。 把一张表看成多张表进行处理。
- 通过别名,将同一张表视为多张表;
- 什么情况下使用自连接;同一张表中某个字段要去关联另外一个字段
-- 1、查询员工信息,员工的老板的名称。 14
-- mgr
SELECT
e1.*,e2.empno,e2.ename
FROM
emp AS e1,emp AS e2
WHERE e1.mgr=e2.empno;
-- 外连接
SELECT
e1.*,e2.empno,e2.ename
FROM
emp AS e1 LEFT JOIN emp AS e2 ON e1.mgr=e2.empno;
-- 2、查询员工信息 14 展示部门名称 薪资级别 上级领导名
SELECT
e1.empno,e1.ename,e1.mgr,d.deptno,d.dname,s.grade,e2.empno,e2.ename
FROM
emp AS e1,dept AS d,salgrade AS s,emp AS e2
WHERE
e1.deptno=d.deptno AND e1.mgr=e2.empno AND e1.sal BETWEEN s.LowSAL AND s.hisal;
-- 外连接与普通关联可以在一起使用
SELECT
e1.empno,e1.ename,e1.mgr,d.deptno,d.dname,s.grade,e2.empno,e2.ename
FROM
emp AS e1 LEFT JOIN emp AS e2 ON e1.mgr=e2.empno
,dept AS d ,salgrade AS s
WHERE
e1.deptno=d.deptno AND e1.sal BETWEEN s.LowSAL AND s.hisal;
6.11 子查询
子查询也可称为嵌套查询。
- 子查询的作用:查询条件未知的事物.
- 查询条件已知的问题:例如:查询工资为800的员工信息
- 查询条件未知的问题:例如:查询工资为20号部门平均工资的员工信息
根据子查询查询的结果不同,分为:
- 标量子查询(子查询结果为单个值)
- 列子查询(子查询结果为1列)
- 行子查询(子查询结果为1行)
- 表子查询(子查询结果为多行多了)
- 标量子查询
子查询返回的结果是单个值(数字,字符串,日期等),最简单的方式。
常用的操作符:
= <> > < >= <=等
-- 1.查询'销售部'的所有员工信息
-- 2.查询smith入职之后的员工信息
-- 3.查询员工的薪资= 20号部门的平均的薪资
- 列子查询
子查询返回的结果是1列(可以是多行)。
常用操作符:
- IN , NOT IN, ANY, SOME, ALL
- any: 子查询返回的列表中,有任意一个满足即可。
- some: 与any相同,使用some的地方都可以使用any
- all: 子查询返回列表的所有值都必须满足。
-- 1. 查询销售部,研发部所有员工信息
SELECT * FROM emp WHERE deptno in
(SELECT deptno FROM dept WHERE dname='销售部' or dname='研发部' )
-- 2. 查询比财务部所有人工资都高的员工信息
SELECT * FROM emp WHERE sal > ALL (select sal from emp WHERE deptno=(select deptno from dept WHERE dname='财务部'))
-- 3.查询比财务部任意一人工资高的员工信息
SELECT * FROM emp WHERE sal > any (select sal from emp WHERE deptno=(select id from dept WHERE dname='财务部'))
- 行子查询
子查询返回的结果是一行(可以是多列)。
常用操作符:= <> IN NOT IN
-- 1. 查询smith薪资与直属上级相同的员工信息。
SELECT sal,mgr FROM emp WHERE ename='smith';
SELECT * FROM emp WHERE sal=8000 AND mgr=7902;
SELECT * FROM emp WHERE (sal,mgr)=(8000,7902);
SELECT * FROM emp WHERE (sal,mgr)=(SELECT sal,mgr FROM emp WHERE ename='smith');
- 表子查询
子查询返回的结果是多行多列。
常用操作符: IN
-- 1.查询与smith,ford职位,薪资相同的员工信息。
SELECT sal,job FROM emp WHERE ename='smith' OR ename = 'ford';
SELECT * FROM emp WHERE (sal,job) IN (SELECT sal,job FROM emp WHERE ename='smith' OR ename = 'ford')
--2.查询入职日期是‘1981-12-03’之后的员工信息,及其部门信息
SELECT * FROM (SELECT * FROM emp WHERE hiredate>'1981-12-03') AS t1 ,dept AS t2 WHERE t1.deptno=t2.id;
6.12 集合运算
- UNION VS UNION ALL
- UNION:二个集合中,如果都有相同的,取其一(行记录)
- UNION ALL:二个集合中,如果都有相同的,两者都取
-- 一张表数据分成多张表处理的时候
-- 前提: 查询的列的数量以及列的数据类型。
-- 使用1条sql: 查询所有的用户信息
-- 12条
-- 需要将多次查询的结果集合并在一起
-- 集合运算
-- UNION 可以去重
-- UNION ALL 全部展示
SELECT DISTINCT * FROM
(SELECT * FROM user0
UNION ALL
SELECT * FROM user1
UNION ALL
SELECT * FROM user2
UNION ALL
SELECT * FROM user3
UNION ALL
SELECT * FROM user4) AS temp;
SELECT * FROM user0
UNION
SELECT * FROM user1
UNION
SELECT * FROM user2
UNION
SELECT * FROM user3
UNION
SELECT * FROM user4;
SELECT empno, ename FROM emp
UNION
SELECT sid,sname FROM stu;
- MySQL 可以实现去重的操作:
- DISTINCT
- UNION
- GROUP BY
6.13 执行顺序
7.DCL
DCL(Data Control Language)数据控制语言,用来管理数据库用户,控制数据库的访问权限。
7.1 管理用户
MySQL里面,所有与系统用户相关的信息都存储在了mysql数据库中的user表中。
程序员操作较少,一般都是DBA/运维使用。
- 语法
1. 查询用户
USE mysql;
SELECT * FROM user;
2. 创建用户
CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码';
3. 修改用户密码
ALTER USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '新密码'
4.删除用户
DROP USER '用户名'@'主机名';
- 示例:
USE mysql;
SELECT * FROM user;
-- 创建用户
-- 默认没有权限,只能在localhost访问
CREATE USER 'lisa'@'127.0.0.1' IDENTIFIED BY '1234';
CREATE USER 'jim'@'localhost' IDENTIFIED BY '1234';
-- 创建用户,可以在任意主机访问该数据库
CREATE USER 'zhangsan'@'%' IDENTIFIED BY '1234';
-- 修改用户密码
ALTER USER 'zhangsan'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
-- 删除用户
DROP USER 'jim'@'localhost';
7.2 权限控制
- 常用权限:
| 权限 | 说明 |
|---|---|
| ALL, ALL PRIVILEGES | 所有权限 |
| SELECT | 查询数据 |
| INSERT | 新增数据 |
| UPDATE | 修改数据 |
| DELETE | 删除数据 |
| DROP | 删除数据库/表/视图 |
| CREATE | 创建数据库/表 |
| ALTER | 修改表结构 |
- 语法:
-- 查询权限
SHOW GRANTS FOR '用户名'@'主机名';
-- 授予权限
GRANT 权限列表 ON 数据库名.表名 TO '用户名'@'主机名';
-- 撤销权限
REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'主机名';
- 示例:
-- 1. 查询权限
SHOW GRANTS FOR 'zhangsan'@'%';
SHOW GRANTS FOR 'root'@'localhost';
-- 2.授予权限
GRANT ALL ON demo.* TO 'zhangsan'@'%';
-- 3. 撤销权限
REVOKE ALL ON demo.* FROM 'zhangsan'@'%';
8.约束
在MySQL服务中,约束分为行级约束与表级约束。
限制列的数据,保证数据的正确性。维护表与表的关系。
分类:
- 行级约束
- 非空约束 not null
- 唯一性约束/索引 unique
- 默认约束 default
- 主键约束 primary key
- 表级约束
- 主键约束 primary key
- 外键约束
8.1 NOT NULL
非空约束。限制列的数据不能为NULL
-- 1.非空约束:NOT NULL
-- 在创建table的时候 直接对列进行约束
CREATE TABLE demo(
id INT,
name VARCHAR(20),
age TINYINT UNSIGNED
);
-- 在创建表成功的前提下 使用alter操作即可
ALTER TABLE demo modify id int NOT NULL;
8.2 UNIQUE
唯一性约束,限制列的值不能重复。
在查询的sql中,有索引的列作为条件进行查询,性能会比普通列的性能高很多。
-- 2.唯一性约束
CREATE TABLE b(
id INT UNIQUE NOT NULL,
name varchar(20) NOT NULL,
age int
);
8.3 DEFAULT
默认约束。对指定的列设置默认值。
-- 3.默认约束
CREATE TABLE b(
id INT UNIQUE NOT NULL,
name varchar(20) NOT NULL,
gender CHAR(1) DEFAULT '男'
);
8.4 PRIMARY KEY
主键约束/索引、自带索引
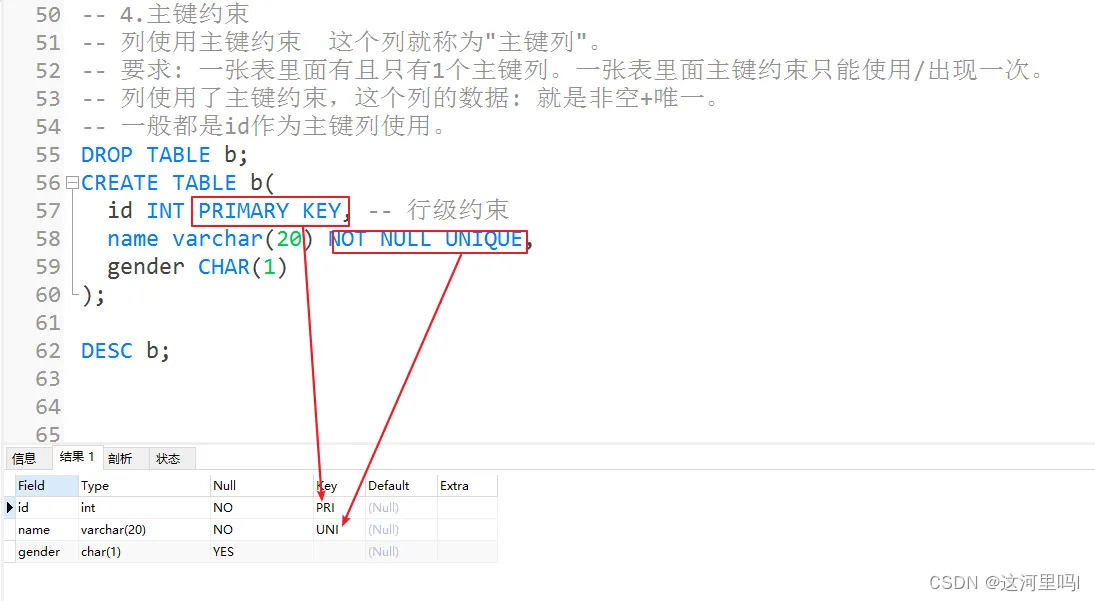
id 可作为主键列存在 保证数据的唯一性。 标识每行记录的唯一性。
id是数值类型 int bigint 这个时候可以将主键列更改为值可以自增处理。
注:auto_increment 只能与主键列一块使用。
ALTER TABLE b modify id int auto_increment;
-- id的数据就可以自己自增。 从1开始 每次+1
-- 修改自增的初始值 自增的步长
ALTER TABLE b auto_increment 1001;
SET GLOBAL auto_increment_increment=1;
- 联合主键。
多个列同时作为一个主键列存在的。----> 表级约束
一般是体现在中间表使用(维护多表的关系)
CREATE TABLE d(
name VARCHAR(20),
pass VARCHAR(20),
age int,
PRIMARY KEY (name,pass) -- 表级约束
);
9.常用函数
9.1字符函数
| 函数 | 功能 |
|---|---|
| concat(str1,str2,…) | 连接字符串 |
| insert(str,pos,len,newstr) | 字符串str从第pos位置开始的len个字符替换为新字符串newstr |
| lower(str) | 转成小写 |
| upper(str) | 转成大写 |
| length(str) | 返回字符串str的长度 |
| char_length(str) | 返回字符串str的长度 |
| lpad(str,ien,padstr) | 返回字符串str,其左边由字符串padstr填补到len字符串长度 |
| rpad(str,len,padstr) | 返回字符串str,其左边由字符串padstr填补到len字符串长度 |
| trim(str) | 去掉字符串str前缀和后缀的空格 |
| repeat(str,count) | 返回str重复count次的结果 |
| replace(str,from_str,to_str) | 用字符串to_str替换字符串str中所有的字符串from_str |
| substring(str,pos,len) | 从字符串str的pos位置起len个字符长度的子串 |
示例:
-- 字符串连接
SELECT concat('java','sun','aa');
-- length() 字节长度
SELECT length(sname),sname FROM tb_stu;
-- 字符长度
SELECT CHAR_LENGTH('java');
-- 去除前后空格
SELECT trim(' ja va ');
-- 重复指定次数
SELECT repeat('ja',4);
-- 字符串替换
SELECT REPLACE('javaoror','or','sun');
-- 截取字串
SELECT substring('javasun',5,3);
9.2 数值函数
| 函数 | 功能 |
|---|---|
| abs(x) | 返回x的绝对值 |
| ceil(x) | 返回不小于x的最小整数 |
| floor(x) | 返回不大于x的最大整数 |
| mod(x,y) | 返回x/y的模 |
| rand() | 返回0-1之间的随机浮点数 |
| round(x,y) | 返回x的四舍五入有y位的小数值 |
| truncate(x,y) | 返回x截断位y位的小数值 |
示例:
-- 取绝对值
SELECT abs(-32);
-- 向上取最小整数
SELECT ceil(3.2);
-- 向下取最大整数
SELECT floor(3.2);
SELECT floor(score),score FROM tb_stu;
-- 取余数
SELECT mod(21,3);
-- 得到 0-1之间的随机值
SELECT rand();
-- 有2位小数的四舍五入值
SELECT round(5.678,2);
-- 截断,小数位保持2位
SELECT TRUNCATE(5.67888,2);
9.3 日期函数
| 函数 | 功能 |
|---|---|
| CURDATE() | 返回当前日期 |
| CURTIME() | 返回当前时间 |
| NOW() | 返回当前的日期和时间 |
| WEEK(date) | 返回指定日期为一年中的第几周 |
| YEAR(date) | 返回日期的年份 |
| HOUR(time) | 返回time的小时值 |
| MINUTE(time) | 返回time的分钟值 |
| MONTHNAME(date) | 返回date的月份名 |
| DATEDIFF(expr,expr2) | 返回起始时间expr和结束时间exrp2之间的天数 |
| DATE_FORMAT(date,fmt) | 返回按字符串fmt格式化日期date值 |
| from_unixtime(unix_timestamp,”%Y-%m-%d %H:%i:%S”):常用来将毫秒数转换为时间格式 | |
%M 月名字(January……December)
%W 星期名字(Sunday……Saturday)
%D 有英语前缀的月份的日期(1st, 2nd, 3rd, 等等。)
%Y 年, 数字, 4 位
%y 年, 数字, 2 位 20
%a 缩写的星期名字(Sun……Sat)
%d 月份中的天数, 数字(00……31) 09
%e 月份中的天数, 数字(0……31) 9
%m 月, 数字(01……12)
%c 月, 数字(1……12)
%b 缩写的月份名字(Jan……Dec)
%j 一年中的天数(001……366)
%H 小时(00……23)
%k 小时(0……23)
%h 小时(01……12)
%I 小时(01……12)
%l 小时(1……12)
%i 分钟, 数字(00……59)
%r 时间,12 小时(hh:mm:ss [AP]M)
%T 时间,24 小时(hh:mm:ss)
%S 秒(00……59)
%s 秒(00……59)
%p AM或PM
%w 一个星期中的天数(0=Sunday ……6=Saturday )
%U 星期(0……52), 这里星期天是星期的第一天
%u 星期(0……52), 这里星期一是星期的第一天
%% 一个文字“%”。
示例:
-- 当前日期,当前时间,日期和时间
SELECT CURDATE(),CURTIME(),now();
-- 指定日期是一年中的第几周
SELECT WEEK(now());
-- 返回指定日期的年份
SELECT YEAR(now());
-- 返回指定时间的小时
SELECT hour(now()),hour(CURTIME());
-- 返回date的月份名
SELECT MONTHNAME(now());
9.4 流程函数
SELECT if(value,m,n); -- 如果value为true,则返回m,否则返回n
SELECT ifnull(value,default);
-- 如果value为null,则返回default,否则返回value
CASE WHEN END 函数
简单函数:
CASE 列 WHEN 数据 THEN 数据 ELSE 数据 END;
搜索函数:
CASE
WHEN 条件1 THEN 数据1
WHEN 条件2 THEN 数据2
...
WHEN 条件n THEN 数据n
ELSE 数据
END
9.5 其他函数
SELECT VERSION();
SELECT USER();
SELECT DATABASE();
SELECT MD5();
SELECT UUID();
SELECT LAST_INSERT_ID();
SELECT IF(10>2,'10','2') a;
10.数据库事务
10.1 事务概念
事务:一个最小的不可再分的工作单元;通常一个事务对应一个完整的业务(例如银行账户转账业务,该业务就是一个最小的工作单元)
一个完整的业务需要批量的DML(INSERT、UPDATE、DELETE)语句共同联合完成
事务只和DML语句有关,或者说DML语句才有事务。这个和业务逻辑有关,业务逻辑不同,DML语句的个数不同
10.2 四大特性ACID
一般来说,事务是必须满足4个条件(ACID)::原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
- 原子性(Atomicity):事务中的全部操作在数据库中是不可分割的,要么全部完成,要么全部不执行。
- 一致性(Consistency):几个并行执行的事务,其执行结果必须与按某一顺序 串行执行的结果相一致。
- 隔离性(Isolation):事务的执行不受其他事务的干扰,事务执行的中间结果对其他事务必须是透明的。
- 持久性(Durability):对于任意已提交事务,系统必须保证该事务对数据库的改变不被丢失,即使数据库出现故障。
事务能保证AID,即原子性,隔离性,持久性。但是一致性无法通过事务来保证,一致性依赖于应用层,开发者。
10.3 TCL
TCL (Transaction Control Language) 是事务控制语言的简称,主要用来管理和控制数据库中的事务(Transaction),以保证数据库操作的完整性和一致性。
BEGIN 或 START TRANSACTION– 用于开始一个事务:
BEGIN; -- 或者使用 START TRANSACTION;
COMMIT– 用于提交事务,将所有的修改永久保存到数据库:
COMMIT;
ROLLBACK– 用于回滚事务,撤销自上次提交以来所做的所有更改:
ROLLBACK;
SAVEPOINT– 用于在事务中设置保存点,以便稍后能够回滚到该点:
SAVEPOINT savepoint_name;
ROLLBACK TO SAVEPOINT– 用于回滚到之前设置的保存点:
ROLLBACK TO SAVEPOINT savepoint_name;
示例:
-- 开始事务
START TRANSACTION;
-- 执行一些SQL语句
UPDATE accounts SET balance = balance - 100 WHERE user_id = 1;
UPDATE accounts SET balance = balance + 100 WHERE user_id = 2;
-- 判断是否要提交还是回滚
IF (条件) THEN
COMMIT; -- 提交事务
ELSE
ROLLBACK; -- 回滚事务
END IF;
在 MySQL 命令行的默认设置下,事务都是自动提交的,即执行 SQL 语句后就会马上执行 COMMIT 操作。
因此要显式地开启一个事务务须使用命令BEGIN或START TRANSACTION,或者执行命令SET AUTOCOMMIT=0,用来禁止使用当前会话的自动提交。
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











