







✨前言✨
📘 博客主页:to Keep博客主页
🙆欢迎关注,👍点赞,📝留言评论
⏳首发时间:2024年5月22日
📨 博主码云地址:博主码云地址
📕参考书籍:《C++ Primer》《C++编程规范》
📢编程练习:牛客网+力扣网
**由于博主目前也是处于一个学习的状态,如有讲的不对的地方,请一定联系我予以改正!!!
1 布隆过滤器的引入
位图的有关知识
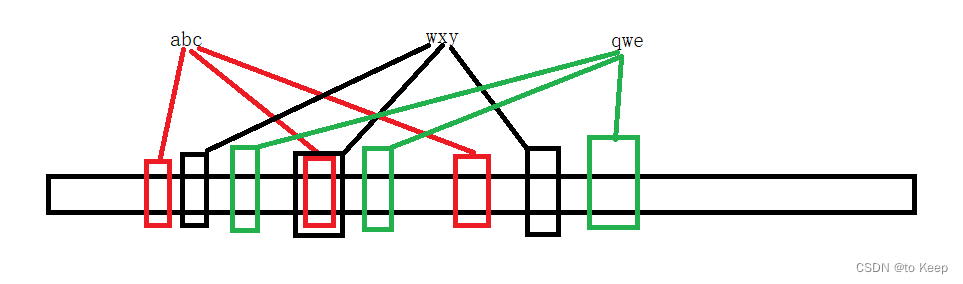
在位图中,我们就了解到了对于海量数据的整形,我们可以采取使用位图的方式进行快速的判断一个数字是否存在!那如果是字符串类型呢?位图是否可以判断呢?答案是位图可以判断的,但是误判率就会很高,效果就不好了!例如,我们存入的是“abc”这样的一个字符串,但是我们查找的是“bac”或是“cba”等字符串,但是上述字符串转化为整形与“abc”转化为整形的值是一样的!于是就有人提出了,可以多增加几个比特位来进行判断,一个字符串转化为整形,可以映射3个位置甚至更多!以此来降低误判率,这种就被我们称为是布隆过滤器,本文就以映射3个位置为示例(多几个位置就是多需要几个哈希函数去进行映射),展开介绍!
2 布隆过滤器内容
对于哈希函数的选择,我们可以参考下面这篇博客:各种字符串哈希函数,我们就采用性能较好的APHash,SDBMHash,BKDRHash三种哈希映射方式来实现我们的布隆过滤器!由上面图示中我们就可以发现:
1️⃣布隆过滤器依旧存在误判的情况,当一个字符串不在的时候,判断结果是正确的,但是当一个字符串在时候(3个位置全部置为1),判断结果就不一定完全正确的!
2️⃣布隆过滤器不可以直接进行删除,因为说不定会有许多字符串都映射到了三个位置中的某一个位置,贸然的直接删除一个字符串,会导致其他字符串找不到!
了解了上述问题了之后,我们再来想一想,对于位图我们一般就是开整形的范围大小(或者是根据有几个数字来开空间),那么对于布隆过滤器我们应该开多大的:布隆过滤器的原理,在这篇文章就讲述了基本的原理以及布隆过滤器所要开辟的长度是多长!本文的实现代码:布隆过滤器的简单实现
3 经典的场景面试题
- 给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法
query就是请求字符串,假设平均每个字符串是50个字节,那么100亿个字符串就相当于有500G大小的文件,对于近似算法就是采用我们本文学过的布隆过滤器! 精确算法应该如何判断呢?有人就提出过将A与B平均切分成1000个小文件,然后依次读取A的小文件,在读A的小文件的同时,遍历B中的1000个文件,从而寻找到交集!这样确实可以找到,但是时间复杂度就上去了可以达到O(N^2)!其实我们可以采取哈希切分(不平均切分)的思想来做,如下图所示:
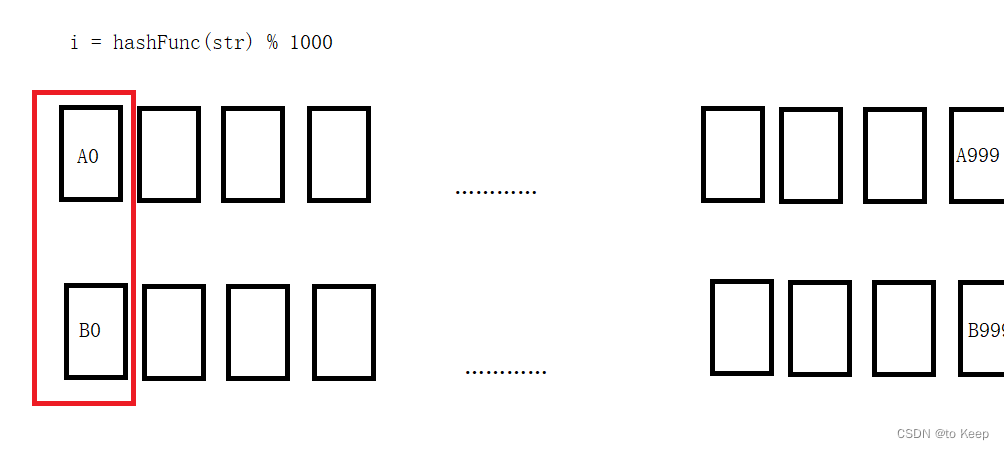
我们利用同一个哈希函数,文件切分成1000块大小,对于是交集的,就一定在数字下标一样的小文件中(例如A0 B0),我们就可以读取对应的小文件(一个小文件平均算起来就是0.5G),对小文件进行处理找交集就行了。但是有可能出现冲突次数多的或者是一样的很多就会在同一个小文件中,数据量就大了,就有可能出现某个小文件出现超过0.5G大小的情况!对于字符串是一样的,此时我们就可以进行set去重处理就行了,对于字符串不是一样而冲突的超过内存的情况,我们就需要再次进行哈希切分,反复即可!
- 如何扩展BloomFilter使得它支持删除元素的操作
可以采用引用计数的方式,将映射位置加8bit位标记有几个字符串映射到了该位置!
3 给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?与上题条件相同,如何找到top K的IP?
对于本题中的思想也是哈希切分的思想,再利用小根堆找到TOP-K的ip!
















 1356
1356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











