







利用MPI进行分布式内存编程
1.1 大部分并行多指令多数据流计算机,都分为本服饰内存系统和共享内存系统两种。在消息传递程序中,运行在一个核-内存对上的程序通常称为一个进程。使用消息传递的实现称为消息传递接口(Message-Passing Interface,MPI)。
1.2 $mpicc -g -Wall -o 编译后文件名字 文件名字
mpicc是C语言编译器的包装脚本,-g表示测试,-Wall开启错误信息,-o标识输出文件
$mpiexec -n 4 ./文件名字
用四个进程运行相应的程序
1.3 MPI相应的函数
(1)MPI_Init和MPI_Finalize
MPI_Init函数是为了告知MPI系统进行所有必要的初始化设置,MPI_Finalize函数告知MPI系统MPI使用完毕,需要释放资源。

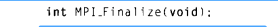
(2)通信子、MPI_Comm_size和MPI_Comm_rank
在MPI中,通信子(communicator)指的是一组可以互相发送消息的进程集合,MPI_Comm_size函数在它的第二个参数里返回通信子的进程数,MPI_Comm_rank在第二个参数返回正在调用进程在通信子当中的进程号。

(3)MPI_Send函数和MPI_Recv函数(点对点通信)
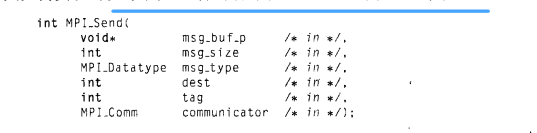
MPI_Send函数用于发送消息,msg_buf_p是一个指向包含消息内容的内存块的指针,第二个参数和第三个参数分别定义了发送数据量大小以及数据类型,dest表示接受消息的进程号,tag用于区分看上去完全一样的消息,如同一个数据一些进程需要计算一些需要打印,communicator表示当下进程集合。

MPI_Recv函数用于接受消息,其中前三个参数同MPI_Recv,source表示来源,tag表示标记,只有当Recv和Send相应参数匹配才能成功接收。p_status通常不用,赋予MPI_STATUS_IGNORE常量即可。
△status_p参数:MPI_Status是一个至少含有三个成员的结构,MPI_SOURCE、MPI_TAG和MPI_ERROR,接受到的相关参数可以通过MPI_Get_count找到其相关信息,如:

发送和接收消息分为阻塞和非阻塞,MPI要求信息是不可超越的,即q向r发送第一条消息必须在第二条信息之前可用,如果一个进程需要接受消息但却未收到,将会被一直悬挂。
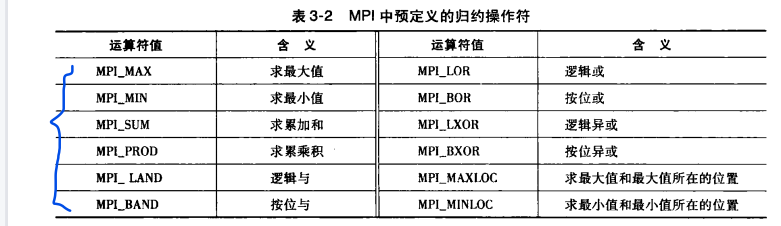
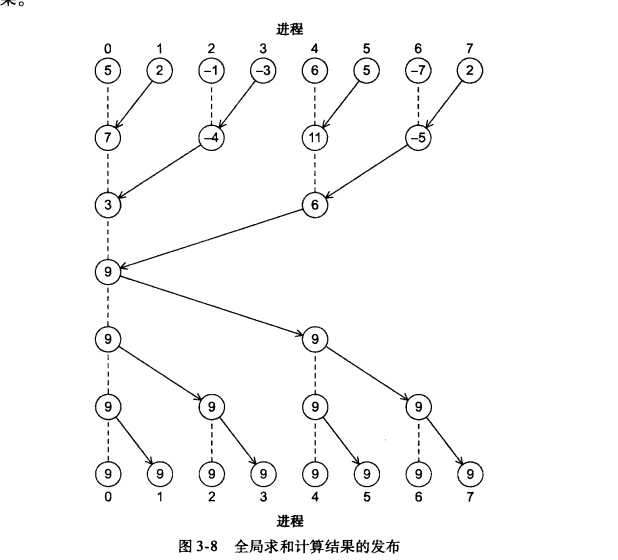
(4)MPI_Reduce(集合通信)

其应用如下(求N维向量的加法):

而operator对应的操作如下:
(5)MPI_Allreduce

MPI_Allreduce和MPI_Reduce几乎差不多,除了没有dest参数,因为所有的进程都将得到结果。
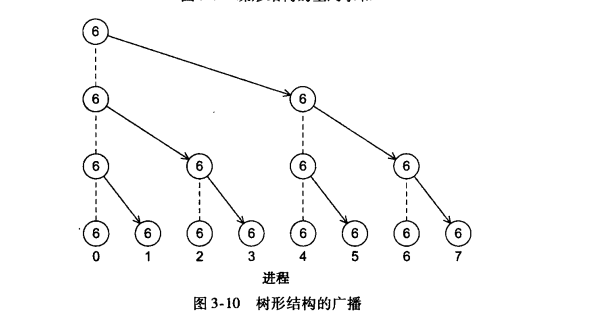
(6)MPI_Bcast函数
在一个集合通信中,如果一个进程的数据被发送到通信子中的所有进程,这样的集合通信就叫做广播。相应的函数如下:

其内部采用的通信结构如下:
(7)MPI_Scatter和MPI_Gather
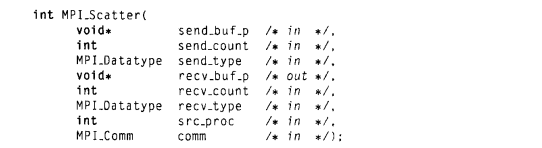
MPI_Scatter负责将读入整个向量按照所需分给某个进程,MPI_Scatter函数将send_count个对象组成的第一个块发给0号进程,下一个块发送给1号进程,依次类推。

MPI_Gather是聚集函数,是scatter的相反过程的函数,在0号进程中,send_buf_p所引用的内存区的数据存储在recv_buf_p的第一个块中,1号进程第二个块,一次类推。
(8)MPI_Allgather

MPI_Allgather和MPI_gather功能相似,不同点在于MPI_Allgather所有进程都有计算后的数据。
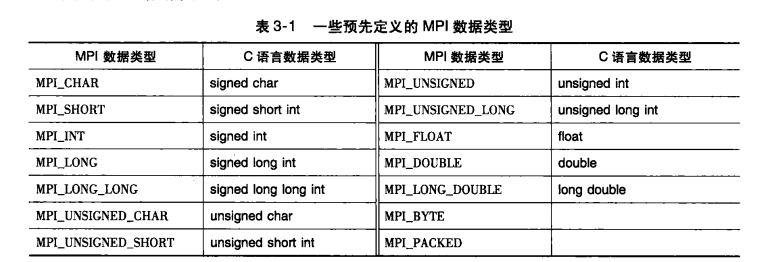
(9)派生数据类型(减少信息发送数量,提高程序性能)
在MPI中,通过同时存储数据项的类型以及它们在内存中的相对位置,派生数据类型可以用于表示内存中数据项的任意集合。

用MPI_Type_create_struct函数创建不同的派生类型:



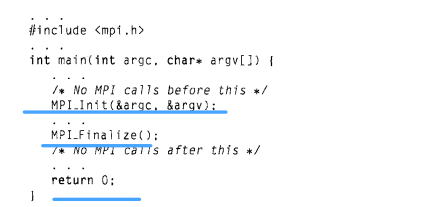
1.4一个典型的MPI程序有如下的结构
1.5 集合通信,点对点通信函数是通过标签和通信子来匹配的,集合通信函数不使用标签,只通过通信子和调用的顺序来进行匹配。
(1)树形结构全局求和
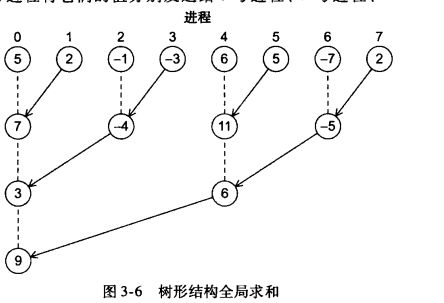
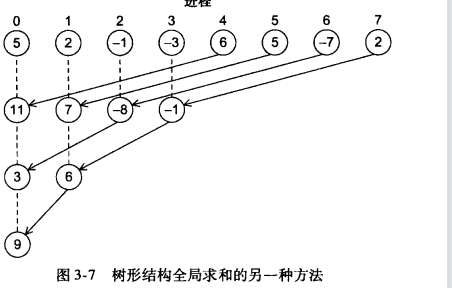
1.6 性能评估(通常报告最小时间)
c语言中的clock函数返回的是cpu执行时间。
MPI_Wtime函数返回从过去某一时刻开始所经过的秒数。对一个MPI代码块进行计时:

MPI的集合通信函数MPI_Barrier能够确保同一个通信子中的所有进程都完成调用该函数之前,没有进程能够提前返回。

1.7并行排序算法(奇偶排序)

并行执行例子如下:
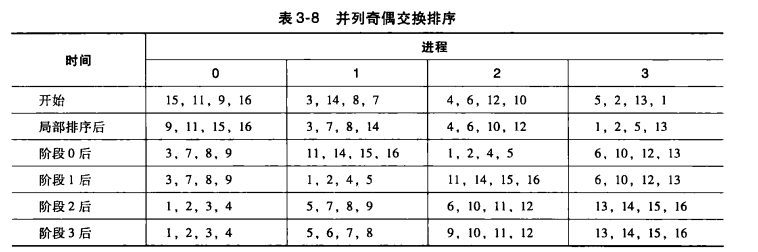
伪代码如下:

MPI_PROC_NULL是MPI定义的一个常量,在点对点通信中,将它作为源进程或目标进程的进程号,调用函数会直接返回不会产生任何通信。
1.8使用MPI_Send和MPI_Recv是不安全的:在现有MPI标准中,MPI_Send简单将消息复制到缓冲区返回(小数据,大数据堵塞)或者MPI_Send会陷入阻塞直到被Recv,对于大型,如果同时send不存在接收,该系统就会陷入死锁。
(1)MPI_Ssend保证了对应接收端接受之前,发送端一直阻塞。其参数和MPI_Send一直是相同的。

(2)同时MPI提供了自己调度通信的方法MPI_Sendrecv:
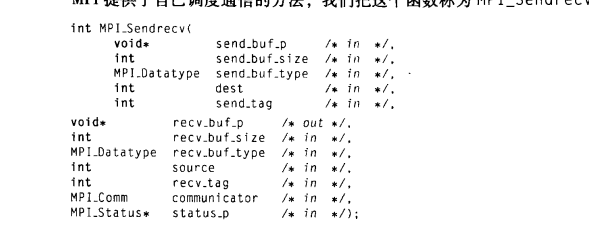
调用一次这个函数,他会执行一次阻塞式消息发送和一次消息接收,如果发送和接收使用的是同一个缓冲区:

用Pthreads进行共享内存编程
2.1 对共享内存区域进行更新的代码段称为临界区(critical section)。局部变量保存在栈中。一个用户的进程是绝对不允许访问其他用户进程拥有的内存。Pthreads不是编程语言,而是一个可以连接到C程序中的库。线程的调度是有操作系统来控制的。
$gcc-g -Wall -o 编译文件名 文件名 -lpthread
-lpthread表示link连接到pthread库
$ ./编译文件名 number
2.2
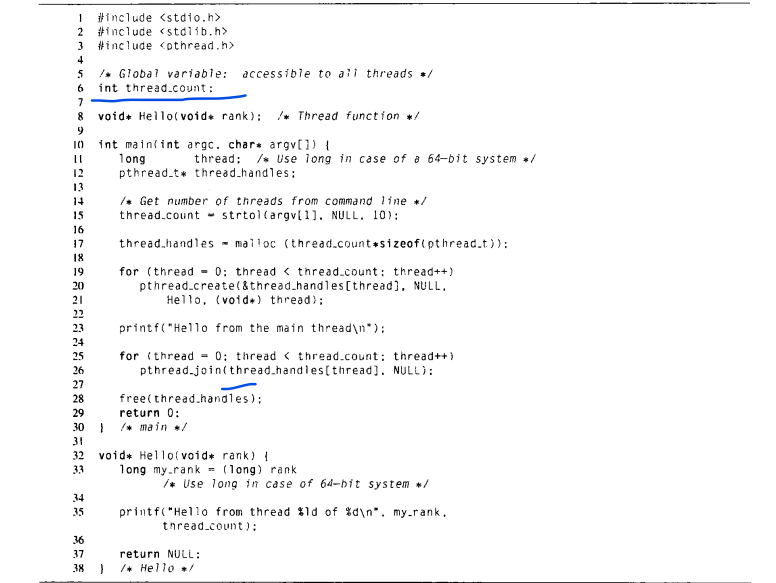
thread_count为一个全局变量,在Pthread程序中,全局变量被所有的线程共享,局部变量则是线程私有。
strtol函数的功能是将字符串转化为long int,函数声明如下:

返回有number_p所指向字符串转化得到的长整数,base是这个整数的基,如果end_p不是NULL,指向第一个无效字符(非数字字符)
2.3 pthread相关函数(单程序多数据):
(1)pthread_create函数

pthread_create函数用来生成线程,第一个参数是一个指针,指向对应的pthread_t对象,第二个参数不用,为NULL,第三个参数则是要执行的函数,最后一个参数也是一个指针,表示传参。
(2)pthread_join函数

pthread_join函数用来回收线程,第二个参数可以接受一个返回值
2.4临界区问题:当多个线程尝试更新同一个共享变量时,就会出现问题。当多个线程都要访问共享变量或共享文件这样的共享资源时,如果至少有一个访问是更新操作,那么这些访问就可能会导致某种错误,我们称之为竞争条件(race condition)。
解决方案:
(1)忙等待:(利用while循环实现)
注意,忙等待的代码编写顺序要严格顺序来写,将临界区代码放在while之后,否则就会出现未难题。


(2)互斥量
互斥量是互斥锁(mutual exclusion lock)的简称,它是一个特殊类型的变量,保证一次只有一个线程进入临界区。
-1.pthread_mutex_init函数,对互斥量进行初始化,第二个参数一般不使用,赋值为NULL。

-2.pthread_mutex_destroy函数,使用完互斥量之后需要调用该函数
-3. pthread_mutex_lock获得临界区访问权

-4. pthread_mutex_unlock释放临界区访问权


(3)信号量
上述的忙等待我们可以控制线程进入临界区的顺序,而如果采用互斥量则是完全随机的,因此引入了信号量(semaphore)
牵涉到信号量的函数如下:

其中sem_init中的第二个参数不使用只要传入0即可,信号量不是pthreads线程库的一部分,所以需要在使用信号量的程序开头加头文件。

sema_post函数(信号量+1),sema_wait函数,v操作释放锁(信号量-1)
V操作+1 P操作-1
-5.路障和条件变量
并行程序设计中路障是调试测试以及测量程序运行时间的重要实现,再次引入新的实现方式,条件变量(conditional variable)
(1)忙等待和互斥量

这种实现主要存在如下问题:
①线程处于忙等待的循环浪费了cpu周期,当线程多于核数会导致性能显著下降。
②counter无法重置,无法重复利用
(2)信号量


(3)条件变量(条件变量是一个数据对象,允许线程在某个特定条件或者事件发生前处于挂起状态,当事件或者条件发生时,另一个线程可以通过信号来唤醒挂起的线程)
①相应的函数:
-1. pthread_cond_signal函数解锁一个阻塞的线程

-2. pthread_cond_broadcast函数解锁所有阻塞的线程

-3.pthread_cond_wait函数通过互斥量mutex_p来阻塞线程,直到其他线程调用上面的函数。当线程解锁后重新获得互斥量

条件变量实现的代码如下:

除了调用pthread_cond_broadcast函数,其他时间也可能解锁,因此pthread_cond_wait放置于while循环内,如果线程不是由相应的函数解锁,则其返回值不是0,则会继续执行该函数。
条件变量也应该初始化和销毁:

我们不使用pthread_cond_init的第二个参数,设置为NULL。
2.5 读写锁
在访问链表时,有如下加锁方案:整个链接加锁、每个节点加锁以及每个节点加读写锁来实现。(读锁可以同时访问,而写同时只能有一个线程访问)
相应函数为:

性能:
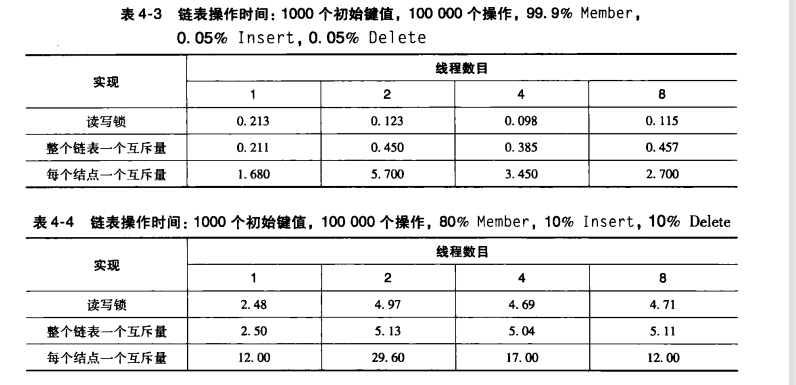
每个节点一个互斥量,导致过多的加锁和解锁使得开销巨大。且读操作越多,读写锁的性能相比越高。
用OpenMP进行共享内存编程
3.1 OpenMP的特征:任务并行化和显式线程同步
OpenMP提供“基于指令”的共享内存API。在c和c++中,有一些特殊的预处理器指令pragma。不支持pragma的编译器会自动忽略pragma指令提示的那些语句,这样允许使用pragma的程序在不支持他们的平台上运行。pragma的默认长度是一行,如果多行,要加上转义字符"\"。
$ gcc -g -Wall -fopenmp -o 编译文件名 文件名
$./编译文件名 number of threads
3.2 一个简单的OpenMP程序如下:

在c和c++中pragma总以#pragma作为开始,pragma后面第一条指令是一条parallel指令,表示应该被多个线程执行·。如果没有其他线程启动,经典情况下系统将在每个核上运行一个线程。在OpenMP语法中,执行并行块的线程集合称为线程组,原始的线程称为主线程,额外的线程称为从线程。当代码块执行完时,当线程从Hello调用中返回时,有一个隐式路障。这意味着完成代码块的线程将等待线程组中的所有线程完成代码块,在上述例子中,当所有线程都完成了代码块,从线程将终止,主线程继续执行之后的代码。
①错误检查:首先strtol在使用前应当确保参数存在,第二个问题在于编译器可能不支持OpenMP,那么它会忽略parallel的代码,为了处理,应当提前检验是否支持:

3.3 临界区问题:
int omp_get_thread_num(void)得到标号
int omp_get_num_threads(void)得到线程数量
#pragma omp critical 保证一次只有一个线程执行
在parallel块之前声明的变量对所有程序都可见,缺省域是共享的,块中声明的变量是私有的。
3.4 规约子句:
归约操作符(reduction operator)是一个二元操作,归约就是将相同的归约操作符重复地应用到操作数序列来得到一个结果的计算,所有的中间结果存储在归约变量(reduction variable)

利用规约子句后如下所示:

reduction子句的语法是:
reduction(<operator>:<variable list>)
注意:浮点运算不符合结合律即(a+b)+c和a+(b+c)可能不相同,线程的私有变量初始化为0
3.5 parallel for 指令
串行版梯形积分:

并行可以简单如下实现:

系统通过在线程见划分循环迭代来进行for循环,大部分系统会粗略使用块划分,即如果有m次迭代,大约m/thread_count次迭代会分配给0,接下来一次类图。
限制:①有for语句本身(即for(……;……;……))来确定。
②迭代次数确定(如果无限迭代或者中间有break无法用该指令,但存在唯一的例外exit,再循环中可以存在一个exit调用)

一个或更多的迭代结果依赖于其他迭代的循环,一般不能被OpenMP正确并行化。依赖分为数据依赖和循环依赖。如fibo[6]和fibo[5]之间计算的依赖关系称为数据依赖,计算出来的fibo[5]的结果在之后的迭代中使用,该关系称为循环依赖(loop-carried dependence)。一般的数据依赖并不会影响parallel for的结果。
3.6 看如下计算π的程序
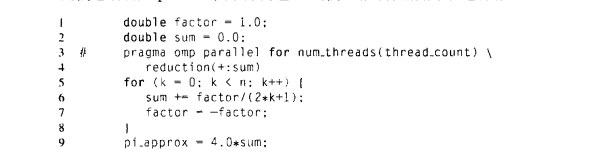
可以清楚看到factor存在数据依赖,其取决于前面的factor,而线程执行无序,所以此处的程序很容易出现问题。如果将factor的计算改为:
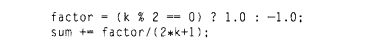
这个仍然存在问题,factor是全局范围内的共享变量,在0号线程为其赋值-1的时候,在未执行sum前很可能被其他线程赋值,因此应该将其改为私有变量

在private子句内列举的变量,在每个线程上都有一个私有副本被创建。一个私有变量的值在parallel块或者parallel for 块的开始处是为指定的,则其在parallel或parallel for块完成之后也是未指定的。如果使用了default子句,需要我们制定每个变量的作用范围,如果没有则有默认决定,一般要求我们显示决定变量的作用域。
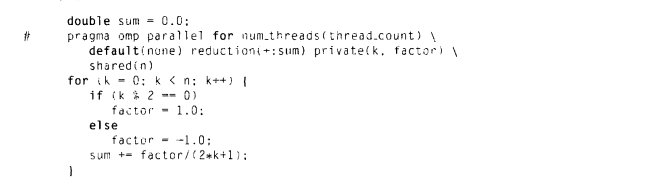
3.7 OpenMP排序

此处我们可以看到,每次循环中都需要创建thread_count个线程,线程的创建和销毁开销巨大,故可以直接在for开始之前就创建足够大线程,然后使用:

#pragma omp for 与#pragma omp parallel for不同,这里for不会创建线程。
3.8 循环调度
在OpenMP中,将循环分配给线程称为调度,schedule子句用于在parallel for 或者for指令中进行迭代分配。一般而言,schedule子句有如下的形式:
schedule<type> [.<checksize>]
type可以是下面中的一个:

(1)static调度

其中chunksize可以被忽略,如果缺省,近似等于总迭代次数/thread_count。
(2)dynamic和guided调度类型
在dynamic调度中,迭代也被分为chunksize个连续迭代的块。每个线程执行一块,并且当一个线程完成一块是,他从运行时系统请求另一块,直到所有的迭代完成。chunksize缺省后为1。
在guided调度中,每个线程也执行一块,并且当一个线程完成一块时,将请求另一块。然而,在guided调度中,当块完成后,新块的大小会变。chunksize缺省为1。
如下:
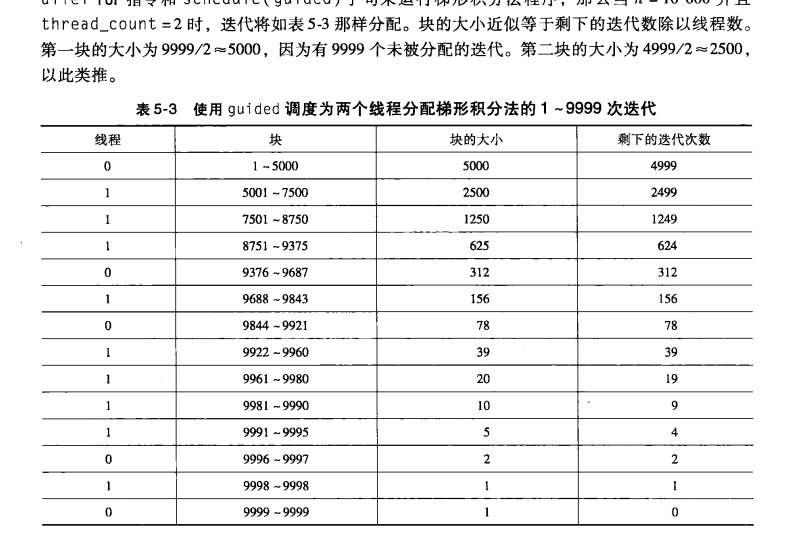
(3)runtime调度类型
环境变量是能够被运行时系统所访问的命名值。当schedule(runtime)指定时,系统使用环境变量OMP_SCHEDULE在运行时来决定如何调度循环。OMP_SCHEDULE环境变量会呈现任何能被static、dynamic或guided调度所使用的值。

3.9 atomic指令
#pragma omp atomic 指示下一条指令是原子操作,它只能保护由一条C语言赋值语句形成的临界区,此外语句必须是一下几种形式之一:

#pragma omp critical(name) 为不同的临界区命名,两个用不同名字的critical指令保护得代码块就可以同时执行。可以采用锁加临界区让不同的线程执行相同的互斥代码块

OpenMP有两种锁:简单锁(simple lock)和嵌套锁(nested lock)。简单锁在释放前前只能获得一次,而一个嵌套锁在释放前可以被同一个线程获得多次。定义简单锁的函数如下:

△注意:




伪共享:


















 2233
2233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









