









目录
isTraversableAgain 判断序列是否可以反复遍历
iterator 对序列中的每个元素产生一个 iterator
lastIndexOf 取得序列中最后一个等于 elem 的元素的位置,索引值
lastIndexWhere 返回当前序列中最后一个满足条件的元素的索引
mkString(start: String, sep: String, end: String) 分隔符和开头结尾
init 返回当前序列中不包含最后一个元素的序列
语法:def init: Array[T]
注解:返回当前序列中不包含最后一个元素的序列
var a = Array(1, 2, 3, 4, 5)
var b = a.init
print(b.mkString(","))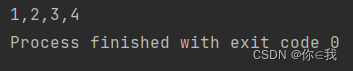
inits 对集合中的元素进行 init 操作
语法:def inits: collection.Iterator[Array[T]]
注解:对集合中的元素进行 init 操作,该操作的返回值中, 第一个值是当前序列的副本,包含当前序列所有的元素,最后一个值是空的,对头尾之间的值进行init操作,上一步的结果作为下一步的操作对象
var e = Array(1, 2, 3)
e.inits.foreach(x => println(x.mkString(",")))
intersect 取两个集合的交集
语法:def intersect(that: collection.Seq[T]): Array[T]
注解:取两个集合的交集
var a = Array(1, 2, 3, 4, 5)
var b = Array(3, 4, 5, 6, 7)
print(a.intersect(b).mkString(","))

isDefinedAt 判断序列中是否存在指定索引
语法:def isDefinedAt(idx: Int): Boolean
注解: 判断序列中是否存在指定索引
var a = Array(1, 2, 3, 4, 5, 6, 7)
println(a.isDefinedAt(1))
print(a.isDefinedAt(10))
isEmpty 判断当前序列是否为空
语法:def isEmpty: Boolean
注解:判断当前序列是否为空
var a = Array(1, 2, 3, 4, 5, 6, 7)
var b: Array[Int] = Array()
println(a.isEmpty)
print(b.isEmpty)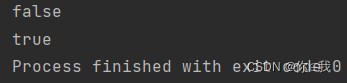
isTraversableAgain 判断序列是否可以反复遍历
语法:def isTraversableAgain: Boolean
注解:判断序列是否可以反复遍历(迭代器不能反复遍历,即判断是否是迭代器)
(该方法是GenTraversableOnce中的方法,对于 Traversables 一般返回true,对于 Iterators 返回 false,除非被复写)
var a = Array(1, 2, 3, 4, 5, 6, 7)
print(a.isTraversableAgain)
iterator 对序列中的每个元素产生一个 iterator
语法:def iterator: collection.Iterator[T]
注解:对序列中的每个元素产生一个 iterator(任何集合都有iterator方法)
var a = Array(1, 2, 3, 4, 5, 6, 7)
print(a.iterator)

last 取得数组中最后一个元素
语法:def last: T
注解:取得序列中最后一个元素
var a = Array(1, 2, 3, 4, 5, 6, 7)
print(a.last)
lastIndexOf 取得序列中最后一个等于 elem 的元素的位置,索引值
语法1:def lastIndexOf(elem: T): Int
注解1:取得序列中最后一个等于 elem 的元素的位置,索引值
var a = Array(1, 2, 3, 4, 5, 6, 7)
print(a.lastIndexOf(3))
语法2:def lastIndexOf(elem: T, end: Int): Int
注解2:取得序列中最后一个等于 elem 的元素的位置,可以指定在 end 之前的元素(包括end)中查找
var a = Array(1, 2, 3, 4, 5, 6, 7)
println(a.lastIndexOf(3, 5))
print(a.lastIndexOf(3, 1))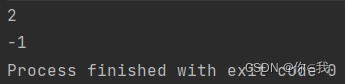
lastIndexOfSlice 获取某值最后一次出现索引
语法1:def lastIndexOfSlice[B >: A](that: GenSeq[B]): Int
注解1:判断当前序列中是否包含序列 that,并返回最后一次出现该序列的位置处的索引
var a = Array(1, 2, 3, 4, 5, 6, 7, 1, 2)
var b = Array(1, 2)
print(a.lastIndexOfSlice(b))
语法2:def lastIndexOfSlice[B >: A](that: GenSeq[B], end: Int): Int
注解2::判断当前序列中是否包含序列 that,并返回最后一次出现该序列的位置处的索引,可以指定在 end 之前的元素(包括end)中查找
var a = Array(1, 2, 3, 4, 5, 6, 7, 1, 2)
var b = Array(1, 2)
print(a.lastIndexOfSlice(b, 5))

lastIndexWhere 返回当前序列中最后一个满足条件的元素的索引
语法1:def lastIndexWhere(p: (T) ⇒ Boolean): Int
注解1:返回当前序列中最后一个满足条件 p 的元素的索引
var a = Array(1, 2, 3, 4, 5, 6, 7, 1, 2)
print(a.lastIndexWhere(x => x < 8))
语法2:def lastIndexWhere(p: (T) ⇒ Boolean, end: Int): Int
注解2:返回当前序列中最后一个满足条件 p 的元素的索引,可以指定在 end 之前(包括)的元素中查找
var a = Array(1, 2, 3, 4, 5, 6, 7, 1, 2)
print(a.lastIndexWhere(x => x < 5, 5))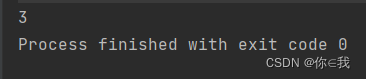
lastOption 返回当前数组中最后一个对象,
语法:def lastOption: Option[T]
注解:返回当前序列中最后一个对象,若序列为空,返回None
var a = Array(1, 2, 3, 4, 5, 6, 7)
print(a.lastOption)
length 返回当前序列中元素个数
语法:def length: Int
注解:返回当前序列中元素个数
var a = Array(1, 2, 3, 4, 5, 6, 7)
print(a.length)

lengthCompare 参数和数组长度作比较
语法:def lengthCompare(len: Int): Int
注解:比较序列的长度和参数 len,根据二者的关系返回不同的值,比较规则是
var a = Array(1, 2, 3)
println(a.lengthCompare(2))
println(a.lengthCompare(3))
print(a.lengthCompare(5)) 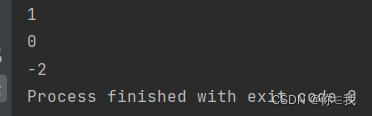
比较规则:
x < 0 if this.length < len
x == 0 if this.length == len
x > 0 if this.length > len
结果:this.length - len
lift 按给定索引取值
语法:def lift: A1 => Option[B1]
注解:按给定索引取值,返回Optition类型的值。
val a = Array(1, 2, 3, "a")
println(a.lift(1))
println(a.lift(3))
println(a.lift(5))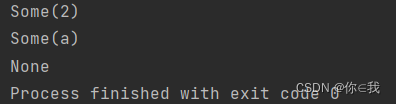
map 对序列中的元素进行操作
语法:def map[B](f: (A) ⇒ B): Array[B]
注解:对序列中的元素进行 f 操作
var a = Array(1, 2, 3, 4, 5)
var b = a.map(x => x * 10)
print(b.mkString(",")) 
max 返回序列中最大的元素
语法:def max: A
注解:返回序列中最大的元素
var a = Array(1, 2, 3, 4, 5)
print(a.max)

maxBy 返回序列中第一个符合条件的元素
语法:def maxBy[B](f: (A) ⇒ B): A
注解:返回序列中第一个符合条件的元素
var a = Array(1, 2, 3, 4, 5)
print(a.maxBy(x => x > 3))
min 返回序列中最小的元素
语法:def min: A
注解:返回序列中最小的元素
var a = Array(1, 2, 3, 4, 5)
print(a.mkString)minBy 返回序列中第一个不符合条件的元素
语法:def minBy[B](f: (A) ⇒ B): A
注解:返回序列中第一个不符合条件的元素
var a = Array(1, 2, 3, 4, 5)
print(a.maxBy(x => x > 3))
mkString 将所有元素组合成一个字符串
mkString
语法:def mkString: String
注解:将所有元素组合成一个字符串
var a = Array(1, 2, 3, 4, 5)
print(a.mkString) 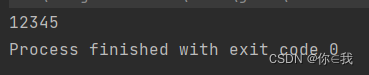
mkString(sep: String) 分隔符
语法:def mkString(sep: String): String
注解:将所有元素组合成一个字符串,以 sep 作为元素间的分隔符
var a = Array(1, 2, 3, 4, 5)
print(a.mkString(",")) 
mkString(start: String, sep: String, end: String) 分隔符和开头结尾
语法:def mkString(start: String, sep: String, end: String): String
注解:将所有元素组合成一个字符串,以 start 开头,以 sep 作为元素间的分隔符,以 end 结尾
var a = Array(1, 2, 3, 4, 5)
print(a.mkString("{", ",", "}"))
nonEmpty 判断序列不是空
语法:def nonEmpty: Boolean
注解:判断序列不是空
var a = Array(1, 2, 3, 4, 5, 6, 7)
var b: Array[Int] = Array()
println(a.nonEmpty)
print(b.nonEmpty)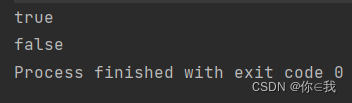
orElse 返回参数
语法:def orElse[A1 <: Int, B1 >: Any](that: PartialFunction[A1,B1]): PartialFunction[A1,B1]
注解:参数:Some;返回:如果Option不为None返回Some否则返回参数的Some
val a = Some("Hello Option")
println(a.orElse(null))
val c = None
println(c.orElse(Some("New Value")))

padTo 扩充数列
语法:def padTo(len: Int, elem: A): Array[A]
注解:后补齐序列,如果当前序列长度小于 len,那么新产生的序列长度是 len,多出的几个位值填充 elem,如果当前序列大于等于 len ,则返回当前序列
var a = Array(1, 2, 3, 4, 5)
println(a.padTo(7, 0).mkString(","))
//需要一个长度为 7 的新序列,空出的填充 0

par 将集合转换为并行集合
语法:def par: ParArray[T]
注解:将集合转换为并行集合;返回一个并行实现,产生的并行序列,不能被修改。
var a = Array(1, 2, 3, 4, 5)
print(a.par)
partition 拆分序列
语法:def partition(p: (T) ⇒ Boolean): (Array[T], Array[T])
注解:偏函数;按条件将序列拆分成两个新的序列,满足条件的放到第一个序列中,其余的放到第二个序列。
var a = Array(1, 2, 3, 4, 5)
var b: (Array[Int], Array[Int]) = a.partition(x => x > 2)
println(b._1.mkString(","))
print(b._2.mkString(","))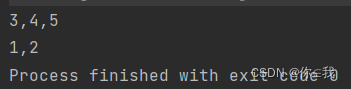
var varue = (1, 2) print(varue._1)

patch 批量替换
语法:def patch(from: Int, that: GenSeq[A], replaced: Int): Array[A]
注解: 批量替换,从原序列的 from 处开始,后面的 replaced 数量个元素,将被替换成序列 that
var a = Array(1, 2, 3, 4, 5)
var b = Array(3, 4, 6)
var c = a.patch(1, b, 2)
print(c.mkString(","))
permutations 排列组合
语法:def permutations: collection.Iterator[Array[T]]
注解:排列组合,他与combinations不同的是,组合中的内容可以相同,但是顺序不能相同,combinations不允许包含的内容相同,即使顺序不一样
var a = Array(1, 2, 3, 4, 5)
var b = a.permutations.toList
b.foreach(x => println(x.mkString(",")))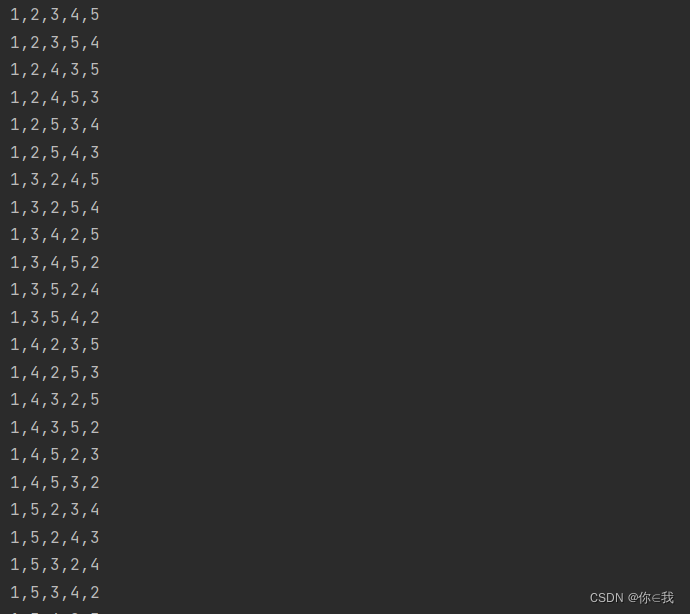
combinations
var a = Array(1, 2, 3, 4, 5)
var c = a.combinations(5).toList
c.foreach(x => print(x.mkString(",")))

prefixLength 返回给定长度的序列长度
语法:def prefixLength(p: (T) ⇒ Boolean): Int
注解:给定一个条件 p,截止到第一个不满足条件的元素,返回一个前置数列的长度,这个数列中的元素都满足 p
var a = Array(1, 2, 3, 4, 5)
print(a.prefixLength(x => x < 4))

product 返回所有元素乘积的值
语法:def product: A
注解:返回所有元素乘积的值(只能是数值型)
var a = Array(1, 2, 3, 4, 5)
println(a.product)
reduce 二元运算
语法:def reduce[A1 >: A](op: (A1, A1) ⇒ A1): A1
注解:对序列中的每个元素进行二元运算(一次取2个值),不需要初始值
var a = Array(1, 2, 3, 4, 5)
print(a.reduce(_ + _)) 
def seq(m: Int, n: Int): Int = { var s = "seq_exp=%d+%d" println(s.format(m, n)) return m + n } var a = Array(1, 2, 3, 4, 5) var b = a.reduce(seq) println(b) /** * seq_exp=1+2 * seq_exp=3+3 * seq_exp=6+4 * seq_exp=10+5 */
reduceLeft 从左向右计算
语法:def reduceLeft[B >: A](op: (B, T) ⇒ B): B
注解:从左向右计算
var a = Array(1, 2, 3, 4)
println(a.reduceLeft(_ + _))
print(a.reduceLeft(_ - _))
reduceRight 从右向左计算
语法:def reduceRight[B >: A](op: (T, B) ⇒ B): B
注解:从右向左计算
var a = Array(1, 2, 3, 4, 5)
println(a.reduceRight(_ + _))
print(a.reduceRight(_ - _))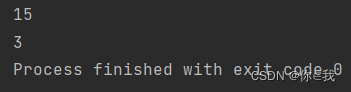
reduceLeftOption
语法:def reduceLeftOption[B >: A](op: (B, T) ⇒ B): Option[B]
注解:计算Option,参考reduceLeft,防止空数组报错,若空,返回None
var a = Array(1, 2, 3, 4, 5)
println(a.reduceLeftOption(_ + _))
print(a.reduceLeftOption(_ - _))
reduceRightOption
语法:def reduceRightOption[B >: A](op: (T, B) ⇒ B): Option[B]
注解:计算Option,参考reduceRight,防止空数组报错,若空,返回None
var a = Array(1, 2, 3, 4, 5)
println(a.reduceRightOption(_ + _))
print(a.reduceRightOption(_ - _))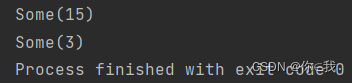
repr 将序列对象转化为供解释器读取的形式
语法:def repr: Array[A1]
注解:将序列对象转化为供解释器读取的形式
var a = Array(1, 2, 3, 4, 5)
print(a.repr.mkString(",")) 
reverse 反转序列
语法:def reverse: Array[T]
注解:反转序列
var a = Array(1, 2, 3, 4, 5)
print(a.reverse.mkString(","))
reverseIterator 反向生成迭代
语法:def reverseIterator: collection.Iterator[T]
注解:反向生成迭代
var a = Array(1, 2, 3, 4, 5)
print(a.reverseIterator.mkString(","))
reverseMap 同 map 方向相反
语法:def reverseMap[B](f: (A) ⇒ B): Array[B]
注解:同 map 方向相反
var a = Array(1, 2, 3, 4, 5)
var b = a.reverseMap(x => x + 1)
println(b.mkString(","))
runWith 判断参数是否在序列中
语法:def runWith[U](action: A1 => U): Int => Boolean
注解:执行偏函数,当参数不在定义域内时,返回false,否则返回true,并执行action
var b = Array.range(1, 20)
print(b.runWith(x => x match {
case x if x % 2 == 0 => x
})(17))
















 6220
6220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









