






 本文详细介绍了Scala中数组的一系列操作,包括sameElements用于比较两个序列元素是否相同,scan、scanLeft、scanRight进行累积计算,segmentLength找出满足条件的连续元素长度,以及slice、sliding、sortBy、sorted等其他常用方法,展示了Scala在处理集合时的强大功能和灵活性。
本文详细介绍了Scala中数组的一系列操作,包括sameElements用于比较两个序列元素是否相同,scan、scanLeft、scanRight进行累积计算,segmentLength找出满足条件的连续元素长度,以及slice、sliding、sortBy、sorted等其他常用方法,展示了Scala在处理集合时的强大功能和灵活性。
目录
sameElements 判断两个序列是否顺序和对应位置上的元素都一样
sliding(size: Int): collection.Iterator[Array[T]]
sliding(size: Int, step: Int): collection.Iterator[Array[T]]
stringPrefix 返回 toString 结果的前缀
zipWithIndex 序列中的每个元素和它的索引组成一个序
sameElements 判断两个序列是否顺序和对应位置上的元素都一样
语法:def sameElements(that: GenIterable[A]): Boolean
注解:判断两个序列是否顺序和对应位置上的元素都一样
var a = Array(1, 2, 3, 4, 5)
var b = Array(1, 2, 3, 4, 5)
var c = Array(1, 2, 3, 4, 6)
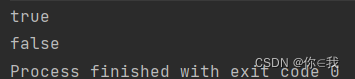
println(a.sameElements(b))
print(a.sameElements(c))
scan 对数组进行二元运算
语法:def scan[B >: A, That](z: B)(op: (B, B) ⇒ B)(implicit cbf: CanBuildFrom[Array[T], B, That]): That
注解:用法同 fold,scan会把每一步的计算结果放到一个新的集合中返回,而 fold 返回的是单一的值
var a = Array(1, 2, 3, 4, 5)
print(a.scan(5)(_ + _).mkString(","))
/**
* 5
* 5+1=6
* 6+2=8
* 8+3=11
* 11+4=15
* 15+5=20
* */
scanLeft 从左向右计算
语法:def scanLeft[B, That](z: B)(op: (B, T) ⇒ B)(implicit bf: CanBuildFrom[Array[T], B, That]): That
注解:从左向右计算
var a = Array(1, 2, 3, 4, 5)
print(a.scanLeft(5)(_ + _).mkString(","))
scanRight 从右向左计算
语法:def scanRight[B, That](z: B)(op: (T, B) ⇒ B)(implicit bf: CanBuildFrom[Array[T], B, That]): That
注解:从右向左计算
var a = Array(1, 2, 3, 4, 5)
print(a.scanRight(5)(_ + _).mkString(",")) 
segmentLength 返回满足条件索引处后面元素长度
语法:def segmentLength(p: (T) ⇒ Boolean, from: Int): Int
注解:从序列的索引 from 处开始向后查找,所有满足 p 的连续元素的长度
var a = Array(1, 2, 3, 1, 1, 1, 1, 1, 4, 1, 5)
println(a.segmentLength(x => x < 3, 3))
print(a.segmentLength(x => x < 3, 4)) 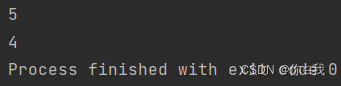
seq 产生一个引用当前序列的 sequential 视图
语法:def seq: collection.mutable.IndexedSeq[T]
注解:产生一个引用当前序列的 sequential 视图
var a = Array(1, 2, 3, 4, 5)
var b = a.slice(1, 4)
var c = a.slice(1, 3)
println(b.mkString(","))
print(c.mkString(","))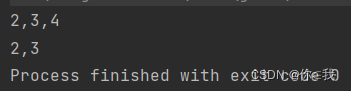
size 返回元素个数
语法:def size: Int
注解:序列元素个数,同 length
var a = Array(1, 2, 3, 4, 5)
print(a.size)

slice 取出范围内元素
语法:def slice(fro m: Int, until: Int): Array[T]
注解:取出当前序列中,from 到 until 之间的片段(左包右不包)
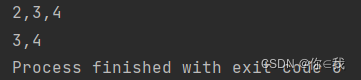
var a = Array(1, 2, 3, 4, 5, 6)
println(a.slice(1, 4).mkString(","))
print(a.slice(2, 4).mkString(","))
sliding 新序列
sliding(size: Int): collection.Iterator[Array[T]]
语法: def sliding(size: Int): collection.Iterator[Array[T]]
注解:从第一个元素开始,每个元素和它后面的 size - 1 个元素组成一个数组,最终组成一个新的集合返回,当剩余元素不够 size 数,则停止
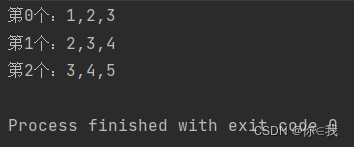
var a = Array(1, 2, 3, 4, 5)
var b = a.sliding(3).toList
for (i <- 0 to b.length - 1) {
var s = "第%d个:%s"
println(s.format(i, b(i).mkString(",")))
}
sliding(size: Int, step: Int): collection.Iterator[Array[T]]
语法:def sliding(size: Int, step: Int): collection.Iterator[Array[T]]
注解:从第一个元素开始,每个元素和它后面的 size - 1 个元素组成一个数组,最终组成一个新的集合返回,当剩余元素不够 size 数,则停止该方法,可以设置步进 step,第一个元素组合完后,下一个从 上一个元素位置+step后的位置处的元素开始
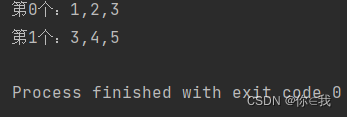
var a = Array(1, 2, 3, 4, 5)
var b = a.sliding(3, 2).toList //第一个从1开始, 第二个从3开始,因为步进是 2
for (i <- 0 to b.length - 1) {
var s = "第%d个:%s"
println(s.format(i, b(i).mkString(",")))
}
sortBy 按指定的排序规则排序
语法:def sortBy[B](f: (T) ⇒ B)(implicit ord: math.Ordering[B]): Array[T]
注解:按指定的排序规则排序
var a = Array(3, 2, 1, 4, 5)
var b = a.sortBy(x => x)
println(b.mkString(","))
//倒序
var c = a.sortBy(x => -x)
println(c.mkString(","))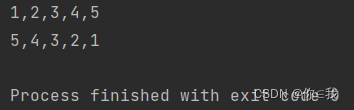
sortWith 自定义排序方法
语法:def sortWith(lt: (T, T) ⇒ Boolean): Array[T]
注解:自定义排序方法
var a = Array(3, 2, 1, 4, 5)
var b = a.sortWith(_.compareTo(_) > 0)
println(b.mkString(","))
var c = a.sortWith(_.compareTo(_) < 0)
println(c.mkString(","))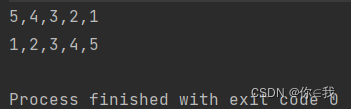
sorted 使用默认的排序规则对序列排序(升序)
语法:def sorted[B >: A](implicit ord: math.Ordering[B]): Array[T]
注解:使用默认的排序规则对序列排序(升序)
var a = Array(3, 2, 1, 4, 5)
var b = a.sorted
println(b.mkString(","))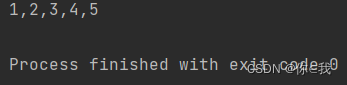
span 分割序列
语法:def span(p: (T) ⇒ Boolean): (Array[T], Array[T])
注解:分割序列为两个集合,从第一个元素开始,直到找到第一个不满足条件的元素止,之前的元素放到第一个集合,其它的放到第二个集合
var a = Array(3, 2, 1, 4, 5)
var b = a.span(x => x > 2)
println(b._1.mkString(","))
println(b._2.mkString(","))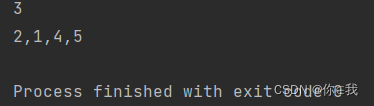
splitAt 从指定位置开始,把序列拆分成两个集合
语法:def splitAt(n: Int): (Array[T], Array[T])
注解:从指定位置开始,把序列拆分成两个集合
var a = List(3, 2, 1, 4, 5)
println(a.splitAt(2))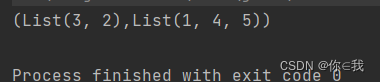
startsWith 从指定偏移处,是否以某个序列开始
语法1:def startsWith[B](that: GenSeq[B], offset: Int): Boolean
注解1:从指定偏移处,是否以某个序列开始
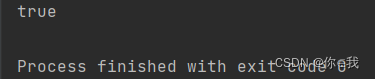
var a = Array(0, 1, 2, 3, 4, 5)
var b = Array(1, 2)
println(a.startsWith(b, 1))
语法2:def startsWith[B](that: GenSeq[B]): Boolean
注解2:是否以某个序列开始
var a = Array(0, 1, 2, 3, 4, 5)
var b = Array(0, 1)
var c = Array(1, 2)
println(a.startsWith(b))
println(a.startsWith(c))

stringPrefix 返回 toString 结果的前缀
语法:def stringPrefix: String
注解:返回 toString 结果的前缀
var a = Array(0, 1, 2, 3, 4, 5)
println(a.toString())
var b = a.stringPrefix
println(b)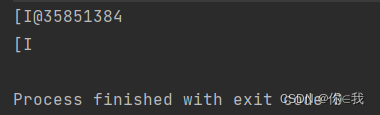
subSequence 返回区间内的序列
语法:def subSequence(start: Int, end: Int): CharSequence
注解:返回 start 和 end 间的字符序列(数组类型必须是Array[Char])(左包右不包)
var chars = Array('a', 'b', 'c', 'd')
var b = chars.subSequence(0, 3)
println(b.toString)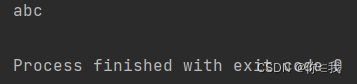
sum 求和
语法:def sum: A
注解:序列求和,元素需为Numeric[T]类型
var a = Array(1, 2, 3, 4, 5)
println(a.sum)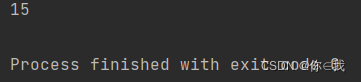
tail 返回除了当前序列第一个元素的其它元素组成的序列
语法:def tail: Array[T]
注解:返回除了当前序列第一个元素的其它元素组成的序列(与init相反)
var a = Array(1, 2, 3, 4, 5)
var b = a.tail
println(b.mkString(" ")) 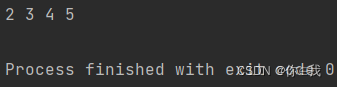
tails 对集合中的元素进行 tail 操作
语法:def tails: Array[T]
注解:对集合中的元素进行 tail 操作,该操作的返回值中, 第一个值是当前序列的副本,包含当前序列所有的元素,最后一个值是空的,对头尾之间的值进行tail操作,上一步的结果作为下一步的操作对象
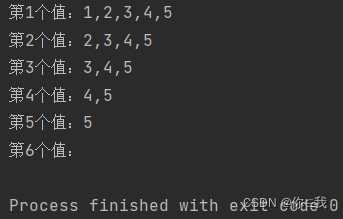
var a = Array(1, 2, 3, 4, 5)
var b = a.tails.toList
for (i <- 1 to b.length) {
var s = "第%d个值:%s"
println(s.format(i, b(i - 1).mkString(",")))
}
take 返回当前序列中前 n 个元素组成的序列
语法:def take(n: Int): Array[T]
注解:返回当前序列中前 n 个元素组成的序列
var a = Array(1, 2, 3, 4, 5)
var b = a.take(3)
println(b.mkString(" "))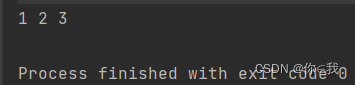
takeRight 从右边开始
语法:def takeRight(n: Int): Array[T]
注解:返回当前序列中,从右边开始,选择 n 个元素组成的序列
var a = Array(1, 2, 3, 4, 5)
var b = a.takeRight(3)
println(b.mkString(" "))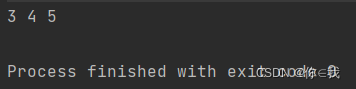
takeWhile 从左边开始
语法:def takeWhile(p: (T) ⇒ Boolean): Array[T]
注解:返回当前序列中,从第一个元素开始,到第一不满足条件的元素为止,满足条件的连续元素组成的序列。
var a = Array(1, 2, 3, 4, 5)
var b = a.takeWhile(x => x < 3)
println(b.mkString(" "))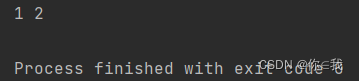
类型转换
toArray
语法:def toArray: Array[A]
注解:转换成 Array 类型
scala> var a = List(1,2,3,4)
a: List[Int] = List(1, 2, 3, 4)
scala> a.toArray
res0: Array[Int] = Array(1, 2, 3, 4)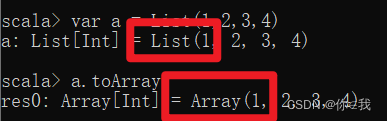
toBuffer
语法:def toBuffer[A1 >: A]: Buffer[A1]
注解:转换成 Buffer 类型
scala> a.toBuffer
res1: scala.collection.mutable.Buffer[Int] = ArrayBuffer(1, 2, 3, 4)
toIndexedSeq
语法:def toIndexedSeq: collection.immutable.IndexedSeq[T]
注解:转换成 IndexedSeq 类型
scala> a.toIndexedSeq
res2: scala.collection.immutable.IndexedSeq[Int] = Vector(1, 2, 3, 4)
toIterable
语法:def toIterable: collection.Iterable[T]
注解: 转换成可迭代的类型
scala> a.toIterable
res0: Iterable[Int] = List(1, 2, 3, 4)
toIterator
语法:def toIterator: collection.Iterator[T]
注解:同 iterator 方法
scala> a.toIterator
res1: Iterator[Int] = <iterator>
toList
语法:def toList: List[T]
注解:同 List 类型
scala> var b = Array(1,2,3,4,5)
b: Array[Int] = Array(1, 2, 3, 4, 5)
scala> b.toList
res3: List[Int] = List(1, 2, 3, 4, 5)
toMap
语法:def toMap[T, U]: Map[T, U]
注解:同 Map 类型,需要被转化序列中包含的元素时 Tuple2 类型数据
var chars = Array(("a", "b"), ("c", "d"), ("e", "f"))
var b = chars.toMap
println(b)
var a = Array(1, 3, 4, 5, 2, 5)
var c = a.map((_, 1))
var d = c.toMap
println(d)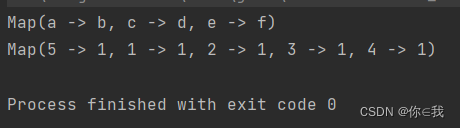
toSeq
语法:def toSeq: collection.Seq[T]
注解:同 Seq 类型
scala> b.toSeq
res5: Seq[Int] = WrappedArray(1, 2, 3, 4, 5)
toSet
语法:def toSet[B >: A]: Set[B]
注解:同 Set 型
scala> b.toSet
res6: scala.collection.immutable.Set[Int] = Set(5, 1, 2, 3, 4)![]()
toStream
语法:def toStream: collection.immutable.Stream[T]
注解:同 Stream 类型(流)
scala> b.toStream
res7: scala.collection.immutable.Stream[Int] = Stream(1, ?)
toVector
语法:def toVector: Vector[T]
注解:同 Vector 类型
scala> b.toVector
res8: Vector[Int] = Vector(1, 2, 3, 4, 5)![]()
toTraversable
语法:def toTraversable: Traversable[T]
注解:同 Traversable类型
scala> b.toTraversable
res9: Traversable[Int] = WrappedArray(1, 2, 3, 4, 5)
transform 对序列中所有元素进行替换操作
语法: def transform(f: T => T): scala.collection.mutable.WrappedArray[T]
注解:提供一个lambda表达式,对序列中所有元素进行替换操作
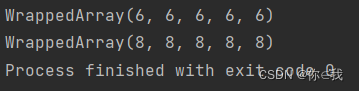
val a = Array(1, 2, 3, 4, 5)
println(a.transform(x => 6))
val c = Array(1, 3, "a", Array(1, 2))
print(a.transform(x => 8))
transpose 矩阵转换
语法:def transpose[U](implicit asArray: (T) ⇒ Array[U]): Array[Array[U]]
注解:矩阵转换,二维数组行列转换(转置)
scala> var k = Array(Array(1, 3, 2), Array(5, 8, 2), Array(7, 9, 8), Array(2, 7, 5))
k: Array[Array[Int]] = Array(Array(1, 3, 2), Array(5, 8, 2), Array(7, 9, 8), Array(2, 7, 5))
scala> k.transpose
res0: Array[Array[Int]] = Array(Array(1, 5, 7, 2), Array(3, 8, 9, 7), Array(2, 2, 8, 5))
union 联合两个序列
语法:def union(that: collection.Seq[T]): Array[T]
注解:联合两个序列,同操作符 ++(不去重)
var a = Array(1, 2, 3, 4, 5)
var b = Array(6, 7)
var c = a.union(b)
println(c.mkString(","))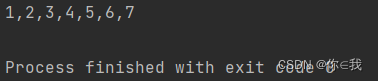
unzip 组合序列(两个元素)
语法:def unzip[T1, T2](implicit asPair: (T) ⇒ (T1, T2), ct1: ClassTag[T1], ct2: ClassTag[T2]): (Array[T1], Array[T2])
注解:将含有两个元素的数组,第一个元素取出组成一个序列,第二个元素组成一个序列
var chars = Array(("a", "b"), ("c", "d"))
var b = chars.unzip
println(b._1.mkString(","))
println(b._2.mkString(",")) 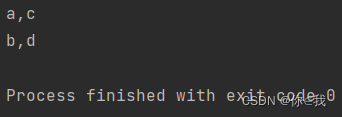
unzip3 组合序列(三个元素)
语法:def unzip3[T1, T2, T3](implicit asTriple: (T) ⇒ (T1, T2, T3), ct1: ClassTag[T1], ct2: ClassTag[T2], ct3: ClassTag[T3]): (Array[T1], Array[T2], Array[T3])
注解:将含有三个元素的三个数组,第一个元素取出组成一个序列,第二个元素组成一个序列,第三个元素组成一个序列
var chars = Array(("a", "b", "x"), ("c", "d", "y"), ("e", "f", "z"))
var b = chars.unzip3
println(b._1.mkString(","))
println(b._2.mkString(","))
println(b._3.mkString(","))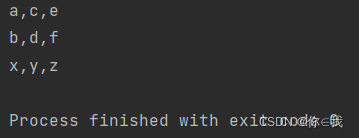
update 更新索引处元素
语法1:def update(i: Int, x: T): Unit
注解:将序列中 i 索引处的元素更新为 x
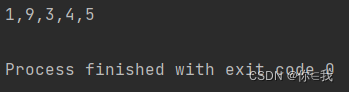
var a = Array(1, 2, 3, 4, 5)
a.update(1, 9)
println(a.mkString(","))
语法2:def updated(index: Int, elem: A): Array[A]
注解:将序列中 i 索引处的元素更新为 x ,并返回替换后的数组
var a = Array(1, 2, 3, 4, 5)
var b = a.view(1, 3).toArray
println(b.mkString(","))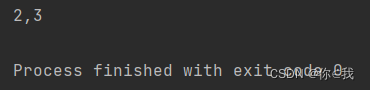
view 返回区间内的元素
语法:def view(from: Int, until: Int): IndexedSeqView[T, Array[T]]
注解:返回 from 到 until 间的序列,不包括 until 处的元素
var a = Array(1, 2, 3, 4, 5)
var b = a.view(1, 3).toArray
println(b.mkString(","))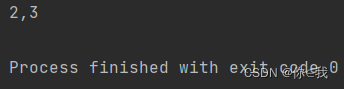
withFilter 根据条件过滤元素
语法:def withFilter(p: (T) ⇒ Boolean): FilterMonadic[T, Array[T]]
注解:根据条件 p 过滤元素(返回特殊类型FilterMonadic[T, Array[T]])
var a = Array(1, 2, 3, 4, 5)
var b = a.withFilter(x => x > 3)
var c = b.map(x => x)
println(c.mkString(","))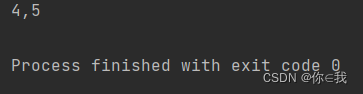
zip 将两个序列对应位置上的元素组成一个pair序列
语法:def zip[B](that: GenIterable[B]): Array[(A, B)]
注解:将两个序列对应位置上的元素组成一个pair序列
var a = Array(1, 2, 3, 4, 5)
var b = Array(5, 4, 3, 2, 1)
var c = a.zip(b)
println(c.mkString(",")) 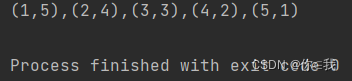
zipAll 同zip不足自动填充
语法:def zipAll[B](that: collection.Iterable[B], thisElem: A, thatElem: B): Array[(A, B)]
注解:同 zip ,但是允许两个序列长度不一样,不足的自动填充,如果当前序列端,空出的填充为 thisElem,如果 that 短,填充为 thatElem
var a = Array(1, 2, 3, 4, 5, 6, 7)
var b = Array(5, 4, 3, 2, 1)
var c = a.zipAll(b, 9, 8)
println(c.mkString(","))
zipWithIndex 序列中的每个元素和它的索引组成一个序列
语法:def zipWithIndex: Array[(A, Int)]
注解:序列中的每个元素和它的索引组成一个序列
var a = Array(10, 20, 30, 40)
var b = a.zipWithIndex
println(b.mkString(","))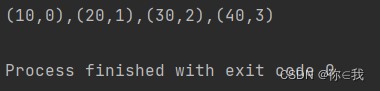

















 774
774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









