









 Spark是快速、通用的大数据分析引擎,作为Apache顶级项目,它提供了一站式解决方案,涵盖批处理、交互式查询、实时流处理和机器学习。Spark相比MapReduce速度更快,支持多语言编程,且具有易用性和通用性。文章详细介绍了Spark的安装步骤,包括解压、配置环境变量和启动等。
Spark是快速、通用的大数据分析引擎,作为Apache顶级项目,它提供了一站式解决方案,涵盖批处理、交互式查询、实时流处理和机器学习。Spark相比MapReduce速度更快,支持多语言编程,且具有易用性和通用性。文章详细介绍了Spark的安装步骤,包括解压、配置环境变量和启动等。
目录
Spark介绍
概述
Spark是一种快速、通用、可扩展的大数据分析引擎,于2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache顶级项目。项目是用Scala进行编写。
Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLib、SparkR等子项目,Spark是基于内存计算的大数据并行计算框架。除了扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。Spark适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理、迭代算法、交互式查询、流处理。通过在一个统一的框架下支持这些不同的计算,Spark 使我们可以简单而低耗地把各种处理流程整合在一起。而这样的组合,在实际的数据分析 过程中是很有意义的。不仅如此,Spark 的这种特性还大大减轻了原先需要对各种平台分 别管理的负担。
Spark致力于打造大一统的软件栈,各个组件关系密切并且可以相互调用,这种设计有几个好处:
1、软件栈中所有的程序库和高级组件 都可以从下层的改进中获益。
2、运行整个软件栈的代价变小了。不需要运 行 5 到 10 套独立的软件系统了,一个机构只需要运行一套软件系统即可。系统的部署、维护、测试、支持等大大缩减。
3、能够构建出无缝整合不同处理模型的应用。
为什么要使用spark
MapReduce编程模型的局限性
繁杂
- 只有Map和Reduce两个操作卜复杂的逻辑需要大量的样板代码
处理效率低:
- Map中间结果写磁盘,Reduce写HDFS,多个Map通过HDFS交换数据
- 任务调度与启动开销大
不适合迭代处理。交互式处理和流式处理
Spark是类Hadoop MapReduce的通用并行框架
Job中间输出结果可以保存在内存,不再需要读写HDFS
比MapReduce平均快10倍以上
spark优势
速度快
- 基于内存数据处理,比MR快100个数量级以上(逻辑回归算法测试)
- 基于硬盘数据处理,比MR快10个数量级以上
易用性
- 支持Java、Scala、Python.R语言
- 交互式shell方便开发测试
通用性
- 一栈式解决方案:批处理、交互式查询、实时流处理、图计算及机器学习
多种运行模式
- YARN、Mesos、EC2、Kubernetes、Standalone、Local
spark技术栈(内置组件)
- Spark Core:核心组件,分布式计算引擎
- Spark SQL:高性能的基于Hadoop的SQL解决方案
- Spark Streaming:可以实现高吞吐量○具备容错机制的准实时流处理系统
- Spark Graphx:分布式图处理框架
- Spark MLlib:构建在Spark上的分布式机器学习库
Spark安装
在opt/install下面拷贝压缩包
一个为scala一个为spark

解压
[root@hadoop3 install]# tar -zxf spark-3.1.2-bin-hadoop3.2.tgz -C ../soft
[root@hadoop3 install]# tar -zxf scala-2.12.10.tgz -C ../soft/
改名
在soft目录下面
[root@hadoop3 soft]# mv spark-3.1.2-bin-hadoop3.2/ spark312
[root@hadoop3 soft]# mv scala-2.12.10/ scala212
配置环境变量
vim /ect/profile
#SPARK_HOME
export SPARK_HOME=/opt/soft/spark312
export PATH=$PATH:$SPARK_HOME/bin
#SCALA_HOME
export SCALA_HOME=/opt/soft/scala212
export PATH=$PATH:$SCALA_HOME/bin修改配置文件
编辑spark-env.sh文件
cd /opt/soft/spark312/conf
把零时文件修改正式文件
[root@hadoop3 conf]# cp spark-env.sh.template spark-env.sh
编辑文件
[root@hadoop3 conf]# vim spark-env.sh
在文件最后加上下面代码
export SCALA_HOME=/opt/soft/scala212
export JAVA_HOME=/opt/soft/jdk180
export SPARK_HOME=/opt/soft/spark312
export HADOOP_INSTALL=/opt/soft/hadoop313
export HADOOP_CONF_DIR=$HADOOP_INSTALL/etc/hadoop
export SPARK_MASTER_IP=hadoop3
export SPARK_DRIVER_MEMORY=2G
export SPARK_LOCAL_DIRS=/opt/soft/spark312
export SPARK_EXECUTOR_MEMORY=2G编辑workers文件
[root@hadoop3 conf]# cp workers.template workers
[root@hadoop3 conf]# vim workers

这里已经有一个localhost,则不需要添加,如果需要配置集群只需要在这里添加主机名即可
刷新资源
source /etc/profile
启动spark
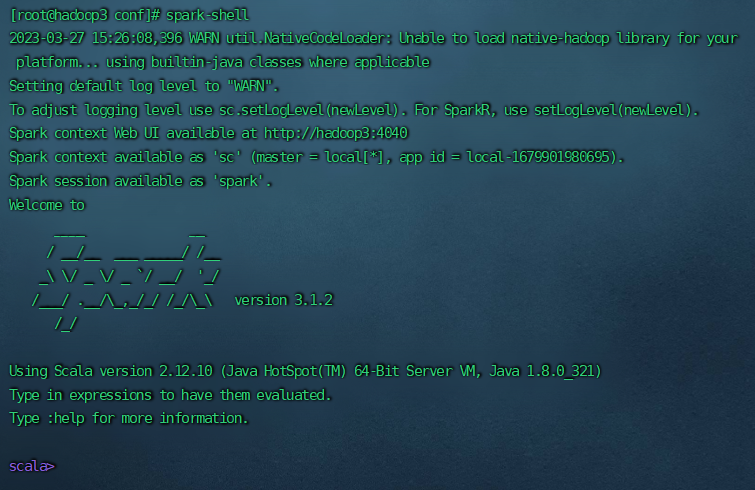
[root@hadoop3 conf]# spark-shell
出现下图则为已经安装成功















 301
301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









