







本文搭建hadoop的环境为 centos7.9 Hadoop3.1.3 jdk-8u301 zookeeper-3.4.6,我们首先需要准备好三台虚拟机,修改好主机名,设置静态IP,关闭防火墙,关闭selinux,以其中一台master节点为例具体操作如下
[root@master ~]# yum -y install vim
[root@master ~]# vim /etc/hostname #只有一行,改为master,其他两台分别改为slave1,slave2
[root@master ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33 #内网下一般都是ens33,有些人的或许不同 但是都是-ensXX只需修改有注释部分
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static" #将dhcp改为static
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="b5b8e893-1fbf-425c-a6c5-d679072ac952"
DEVICE="ens33"
ONBOOT="yes" #将NO改为yes
IPADDR="192.168.83.128" #设置为主机IP
PREFIX="24" #此处和netmask=255.255.255.0等效
GATEWAY="192.168.83.2" #网关
DNS1="192.168.83.2" #DNS服务器 默认和网关相同
IPV6_PRIVACY="no"
接下来,关闭防火墙和selinux,代码如下
[root@master ~]# systemctl stop firewalld
[root@master ~]# systemctl disable firewalld
[root@master ~]# vim /etc/selinux/config #将SELINUX的值改为disabled
[root@master ~]# reboot #重启使配置生效
重启后就开始安装环境,首先先把各个安装包解压,使用Xftp或者rz将所有安装包放到指定目录下
[root@master opt]# mkdir /opt/software module #创建两个目录,将软件包放在software目录,解压在module目录下
[root@master software]# ll
总用量 489556
-rw-r--r-- 1 root root 338075860 9月 28 19:33 hadoop-3.1.3.tar.gz
-rw-r--r-- 1 root root 145520298 9月 28 19:33 jdk-8u301-linux-x64.tar.gz
-rw-r--r-- 1 root root 17699306 9月 28 19:33 zookeeper-3.4.6.tar.gz
[root@master software]# tar -zxvf jdk-8u301-linux-x64.tar.gz -C /opt/module/
[root@master software]# tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
[root@master software]# tar -zxvf zookeeper-3.4.6.tar.gz -C /opt/module/配置环境变量,新建一个文件存放我们自己的环境变量
[root@master module]# vim /etc/profile.d/my_env.sh
添加以下内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_301
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#ZOOKEEPER_HOME
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.4.6
export PATH=$PATH:$ZOOKEEPER_HOME/bin 验证,使环境变量生效
[root@master module]# source /etc/profile
[root@master module]# java -version
java version "1.8.0_301"
Java(TM) SE Runtime Environment (build 1.8.0_301-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.301-b09, mixed mode)
[root@master module]# hadoop version
Hadoop 3.1.3
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579
Compiled by ztang on 2019-09-12T02:47Z
Compiled with protoc 2.5.0
From source with checksum ec785077c385118ac91aadde5ec9799
This command was run using /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar编写同步配置脚本,首先需要更改hosts文件,修改如下
192.168.83.128 master #分别对应 主机IP 主机名
192.168.83.129 slave1
192.168.83.130 slave2
验证 分别ping 对应主机 主机名 能ping通 说明hosts文件配置无误
[root@master module]# ping master
[root@master module]# ping slave1
[root@master module]# ping slave2编写同步文件脚本 进到/usr/bin目录下
[root@master bin]# vim xsync
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in master slave1 slave2
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done添加执行权限
[root@master bin]# chmod +x xsync再安装脚本中使用的同步工具rsync
[root@master bin]# yum -y install rsync将环境变量和解压软件的目录进行分发,分发前须做好SSH免密登录,方便操作,第一次使用SSH会有提示,输入yes即可,exit退回原终端,我们进到/root/.ssh目录下,该目录须使用过ssh后才会生成。
[root@master .ssh]# ssh-keygen -t rsa #三个主机都需进行
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:sbbwtp49+lktMLOcVLqrdlU7F0QS9xCHjakubPPCgWM root@master
The key's randomart image is:
+---[RSA 2048]----+
| o=O.|
| *+o|
| . ... .|
| o o. .. |
| . So*. . ..|
| +E+*Bo.o .|
| .++=*o .o |
| ..+=+.. |
| o*==o |
+----[SHA256]-----+
将公钥拷贝到需免密登录的主机上(三个主机上都进行设置)
[root@master .ssh]# ssh-copy-id master
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@master's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'master'"
and check to make sure that only the key(s) you wanted were added[root@master .ssh]# ssh-copy-id slave1
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@slave1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'slave1'"
and check to make sure that only the key(s) you wanted were added.[root@master .ssh]# ssh-copy-id slave2
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@slave2's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'slave2'"
and check to make sure that only the key(s) you wanted were added.测试,分发环境变量my_env.sh文件
[root@master .ssh]# xsync /etc/profile.d/my_env.sh
==================== master ====================
sending incremental file list
sent 47 bytes received 12 bytes 118.00 bytes/sec
total size is 318 speedup is 5.39
==================== slave1 ====================
sending incremental file list
my_env.sh
sent 412 bytes received 35 bytes 894.00 bytes/sec
total size is 318 speedup is 0.71
==================== slave2 ====================
sending incremental file list
my_env.sh
sent 412 bytes received 35 bytes 298.00 bytes/sec
total size is 318 speedup is 0.71
配置hadoop集群,我们需要更改四个配置文件分别是core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml 进到/opt/module/hadoop-3.1.3/etc/hadoop目录下
core-site.xml配置如下
<configuration>
<!-- 把两个NameNode)的地址组装成一个集群mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置zookeeper所在的节点和端口 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
</configuration>hdfs-site.xml配置如下
<configuration>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中NameNode节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>master:9000</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>slave1:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>master:9870</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>slave1:9870</value>
</property>
<!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/mycluster</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh无秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 声明journalnode服务器存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/module/hadoop-3.1.3/data/jn</value>
</property>
<!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/module/hadoop-3.1.3/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/module/hadoop-3.1.3/data/datanode</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>yarn-site.xml配置如下
<configuration>
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave1</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>slave1:8088</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value>
</property>
</configuration>mapred-site.xml配置如下
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>slave1:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>slave1:19888</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>接下来,修改workers文件,因为我们三台主机都作为datanode,所以三个主机名都加上
[root@master hadoop]# vim workers
master #每行末尾不允许有空格
slave1
slave2
hadoop3.x新特性需要更改hadoop-env.sh yarn-env.sh
hadoop-env.sh添加如下内容
export JAVA_HOME=/opt/module/jdk1.8.0_301
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=root
yarn-env.sh添加如下内容
export YARN_RESOURCEMANAGER_USER=root
export HADOOP_SECURE_DN_USER=yarn
export YARN_NODEMANAGER_USER=root接下来配置zookeeper,先把module目录分发一下
[root@master hadoop]# xsync /opt/module/配置zookeeper,在/opt/module/zookeeper-3.4.6/目录下创建zkData
[root@master zookeeper-3.4.6]# mkdir -p zkData进入当前目录的conf目录下,并把zoo_sample.cfg改为zoo.cfg
[root@master conf]# mv zoo_sample.cfg zoo.cfg配置zoo.cfg文件
dataDir=/opt/module/zookeeper-3.4.6/zkData末尾添加以下内容
#######################cluster##########################
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888在zkData目录下创建myid文件,输入主机名所对应的server号,即在master主机上时设置为1
[root@master zkData]# vim myid
1分发刚刚修改的配置
[root@master zkData]# xsync /opt/module/zookeeper-3.4.6/记得修改其他主机的myid文件,分别对应 2 3
启动zookeeper集群,记得在其他两个主机source一下配置文件
[root@master zkData]# zkServer.sh start
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@slave1 zkData]# zkServer.sh start
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@slave2 zkData]# zkServer.sh start
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED查看状态
[root@master zkData]# zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
[root@slave1 zkData]# zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: leader
[root@slave2 zkData]# zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower高可用集群启动顺序
1.启动zookeeper
[root@master zkData]# zkServer.sh start
[root@slave1 zkData]# zkServer.sh start
[root@slave2 zkData]# zkServer.sh start2.启动journalnode
[root@master zkData]# hdfs --daemon start journalnode
WARNING: /opt/module/hadoop-3.1.3/logs does not exist. Creating.
[root@slave1 zkData]# hdfs --daemon start journalnode
WARNING: /opt/module/hadoop-3.1.3/logs does not exist. Creating.
[root@slave2 zkData]# hdfs --daemon start journalnode
WARNING: /opt/module/hadoop-3.1.3/logs does not exist. Creating.3.在其中一个Namenode主机上格式化zkfc
[root@master zkData]# hdfs zkfc -formatZK4.格式化master主机Namenode,并启动
[root@master zkData]# hdfs namenode -format
[root@master zkData]# hdfs --daemon start namenode5.在slave1上同步master的元数据信息,并启动namenode
[root@slave1 zkData]# hdfs namenode -bootstrapStandby
[root@slave1 zkData]# hdfs --daemon start namenode6.启动集群
[root@master zkData]# start-all.sh
[root@slave1 .ssh]# start-yarn.sh完成效果
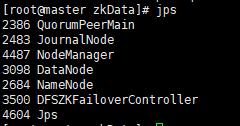
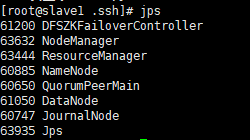
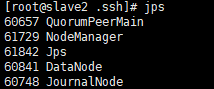
还可以在浏览器上输入 192.168.83.128(主机IP):9870


当你看到这两个页面,恭喜你,HDFS HA 搭建成功了,刚兴趣的朋友可以跳转至我的下一篇文章YARN-HAhttps://blog.csdn.net/qq_57193542/article/details/120555168![]() https://blog.csdn.net/qq_57193542/article/details/120555168
https://blog.csdn.net/qq_57193542/article/details/120555168














 2339
2339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









