






锁是java中用来保证线程操作原子性的一种机制
锁是数据库中用来保证事务操作原子性的一种机制
i++


Java中的锁有synchronized和Lock锁
Synchronized是关键字,可以锁代码块,也可以锁方法
Lock是类(官方推荐) ,只能锁代码块

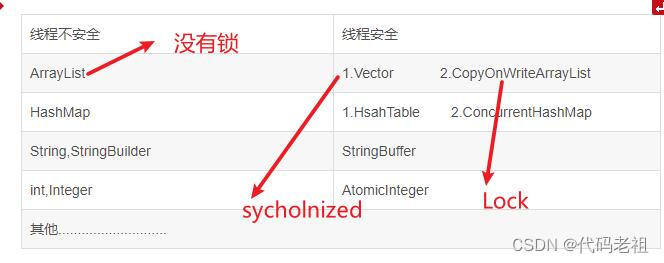
我们把数据类型分为线程安全类型和线程不安全类型
如一个数据类型需我们自己手动加锁来保证其操作的原子性,那么他就是线程不安全的数据类型,如果一个数据类型能够自己在方法中加锁来保证其操作的原子性,那么他就是线程安全的
| 线程不安全 | 线程安全 |
| ArrayList | 1.Vector 2 . CopyOnWriteArrayList |
| HashMap | 1.Hashtable 2.ConcurrentHashMap |
| String StringBuilder | StringBuffer |
| int Integer | AtomicInteger |
| 其他。。。。。。。。 | |
产生死锁的条件是什么?(死锁产生的原因)
1.互斥条件:锁要具有排他性,在同一时刻,锁只能被一个线程持有
2.请求与保持条件:一个线程因为请求其他资源被阻塞的时,对已获取的资源保持不释放
3.不剥夺条件:一个线程没有主动开锁释放资源之前,是不能被其他线程强行剥夺的
4.循环等待条件:A线程持有资源a的锁,b线程持有资源b的锁,在互相不释放自己持有的锁的情况下,去请求对方持有的锁,这时候会形成双方循环等待,造成永久阻塞
如何解决死锁
破坏任意一个条件即可
1.破坏互斥条件:用共享锁,在同一时刻,锁可以被多个线程持有
2.破坏请求与保持条件:一次性申请所有的资源
3.破坏不可剥夺条件:一个线程因为请求其他资源被阻塞的时,主动释放已获取的资源
4.破坏循环等待条件:所有的线程按照同样的顺序请求资源
1.创建线程的几种方式
java中实现多线程的方式有4种
1.继承Thread类,重写run方法
package chapter13;
public class Demo01 {
public static void main(String[] args) {
System.out.println("主线程开始");
MyTread mt=new MyTread();
mt.start();//start是子类从父类中的方法,start在子线程中调用run
mt.run();//直接调用run,在当前主线程中运行run
System.out.println("主线程结束");
}
//静态内部类
//实现线程的方法一:实现Thread类,重写Run方法
static class MyTread extends Thread{
@Override
public void run() {
System.out.println("子线程开始");
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("子线程结束");
}
}
}
2.实现Runable接口,重写run方法
package chapter13;
public class Demo02 {
public static void main(String[] args) {
System.out.println("主线程开始");
MyRunable mr=new MyRunable();//创建Runable对象
Thread t=new Thread(mr);//用官方的Thread类创建线程对象,并把Run able对象作为Thread构造方法的参数
t.start();//调用start
//t.run();
System.out.println("主线程结束");
}
//静态内部类
//实现线程的方法二:实现Runable接口,重写run方法
//Dog有父类Animal,还能继承Thread吗
//官方的意思是:当一个类有父类,此时不方便继承Thread,可以用实现Runable接口的方式
static class MyRunable implements Runnable{@Override
public void run() {
System.out.println("子线程开始");
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("子线程结束");
}
}
}
3.实现Callable接口,重写call方法
package chapter13;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;public class Demo03 {
public static void main(String[] args) {
Mycallable mc=new Mycallable();//创建一个Callable对象
FutureTask<Integer>ft=new FutureTask<>(mc);//创建一个FutureTask对象,用Callable对象作为构造方法的参数
Thread t=new Thread(ft);//创建一个Thread对象,用FutureTask对象作为构造方法的参数
t.start();//用FutureTask对象的get()方法读取子线程call方法的返回值
while (true){
try {
if (ft.isDone()) {//判定子线程有没有运行结束
Integer sum=ft.get();//在取子线程返回值的时候,可以正常返回,也可以异常返回
System.out.println("子线程返回值:"+sum);
break;
} else {
System.out.println("子线程未结束");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
//静态内部类
//实现线程的方法三:实现Callable接口,重写call方法
//需要指定泛型,这个泛型作为子线程返回值的数据类型
//实现线程的方式1和方式2都无法实现子线程运行结束后返回一个结果,因为run方法返回值为void
static class Mycallable implements Callable<Integer>{@Override
public Integer call() throws Exception {
int sum=0;
for (int i = 0; i < 100; i++) {
sum+=i;
Thread.sleep(100);
}
return sum;
}
}
}
4.使用线程池类
2.线程的生命周期
1.新建(new):新创建了一个线程对象。
2.可运行(runnable):线程对象创建后,当调用线程对象的start()方法,该线程处于就绪状态,等待被线程调度选中,获取cpu的使用权。
3.运行(running):可运行状态(runnable)的线程获得了cpu时间片(timeslice),执行程序代码。注:就绪状态是进入到运行状态的唯一入口,也就是说,线程要想进入运行状态执行,首先必须处于就绪状态中;
4.阻塞(block):处于运行状态中的线程由于某种原因,暂时放弃对CPU的使用权,停止执行,此时进入阻塞状态,直到其进入到就绪状态,才有机会再次被CPU调用以进入到运行状态。阻塞的情况分两种:1.阻塞时候释放锁 2.阻塞时候不释放锁
5.死亡(dead):线程run()、main()方法执行结束,或者因异常退出了run()方法,则该线程结束生命周期。死亡的线程不可再次复生。
3.死锁
见上面
4.进程和线程 的区别
进程(process)是操作系统的任务单元,每一个程序启动后,操作系统都会为其分配进程编号PID
线程(Thread)是进程中的任务单元,程序启动的时候,首先会创建主线程,可以在主线程中开辟子线程,每一个线程都对应一个虚拟机栈,栈是线程私有的,堆和方法区是线程共享的
5.调用start()方法和run()方法的区别
调用start()会开辟新的线程,然后在新线程中执行
run不会
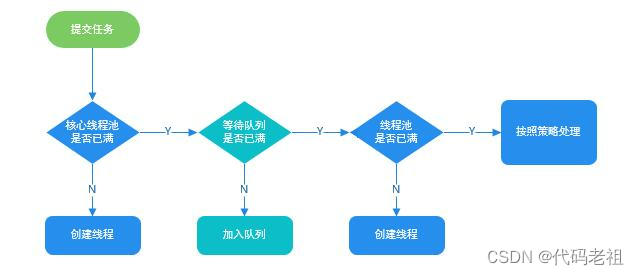
线程池
集合容器整理
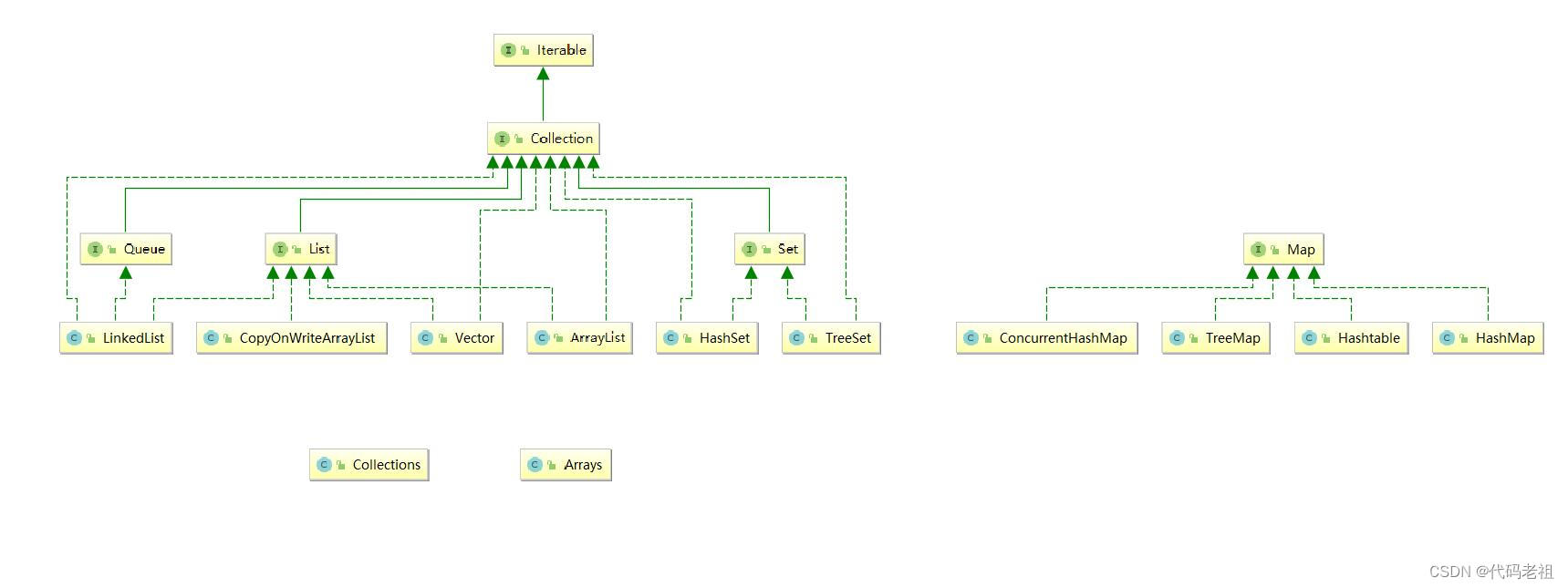
1.Collection和Map的区别
1.Collection和Map是官方提供的集合容器的两大体系的顶层接口
2.Collection代表单元素集合体系
3.Map代表kv键值对结合体系
4.Collection接口继承了Iterable接口,所有的子类都提供了迭代器的实现。Map体系没有
2.List,Set,Queue的区别
1.List,Set,Queue都是Collection体系下的子接口,分别代表三个体系
2.List体系的特点是有序,不唯一
3.Set体系的特点是无序,唯一
4.Queue体系的特点是先入先出
3.队列(Queue)和栈(Stack)的区别
1.队列是一种FIFO(First In First Out)先入先出的结构
2.栈是一种FILO(First In Last Out)先入后出的结构
Java集合体系中的LinkedList类可以实现队列和栈结构
在链表头部插入,尾部取出,或者尾部插入头部取出就是队列 (插入和取出在不同方向进行)
在链表头部插入,头部取出,或者尾部插入尾部取出就是栈(插入和取出在相同方向进行)
4.Array和ArrayList的区别
Array是数组ArrayList是类
Array是定长的(需要手动扩容),ArrayList长度可变(使用过程中自动扩容)
ArrayList的底层是Array
5.ArrayList和LinkedList的区别
1.底层数据结构实现︰ArrayList底层数据结构是动态数组,而 LinkedList的底层数据结构是双向链表
2.随机访问(即读)效率∶ArrayList比LinkedList在随机访问的时候效率要高,因为ArrayList底层是数组,可以通过索引号快速访问,LinkedList是通过二分查找法逼历链表节点进行查找的
3.增加和删除效率∶在非首尾的增加和删除操作,LinkedList 要比 ArrayList 效率要高,因为ArrayList增删操作需要大量的前移或后移,这个过程中涉及到大量的赋值操作比较耗时间,LinkedList只需要修改节点对象的左右指针即可。
4.内存空间占用:LinkedList 比 ArrayList更占内存,因为 LinkedList的节点除了存储数据,还存储了两个引用,一个指向前一个元素,一个指向后一个元素。
5.综合来说,在需要频繁读取集合中的元素时,更推荐使用ArrayList,而在插入和删除操作较多时,更推荐使用 LinkedList。
6.ArrayList和vector的区别(带一下CopyOfWriteArrayList)
1.ArrayList是线程不安全的,Vector是线程安全的,ArrayList中所有的方法都没有加同步锁,
Vector中所有的方法都加了synchronized同步锁。官方在JDK1.5版本中又推出了一个CopyOnWriteArrayList,使用Lock锁实现线程安全,然后弃用了Vector,因为Lock锁的性能比synchronized锁的性能更好
在开发编程中,如果多个线程共享一个ArrayList,那么必须考虑线程安全的问题,可以自己在代码中对ArrayList操作代码加锁,或者直接用线程安全的CopyOnWriteArrayList类,在不考虑线程安全的环境下,用ArrayList性能更好,因为加锁开锁是很耗费性能的
7.Array怎么转换为ArrayList,ArrayList怎么转换为Array
1.官方提供的数组工具类Arrays中提供了一个静态方法asList()可以把数组转换为List,参数是数组,返回值是List
2.ArrayList类中提供了toArray()的方法,可以把ArrayList转换为Array后返回
8.HashSet和TreeSet的区别
HashSet和TreeSet都是set接口下面的子类
HashSet的底层是HashMap,他将数据存储在HashMap的key中
HashSet是无序唯一的,其实是因为HashMap的key是无序唯一的
TreeSet的底层是TreeMap,他将数据存储在TreeMap的key中
HashSet是有序唯一的,其实是因为TreeMap的key是有序唯一的
9.HashMap和Hashtable有什么区别(带一下ConcurrentHashMap)
1.HashMap是线程不安全的,Hashtable是线程安全的,HashMap中所有的方法都没有加同步锁,
Hashtable中所有的方法都加了synchronized同步锁。官方在JDK1.5版本中又推出了一个ConcurrentHashMap,使用Lock锁实现线程安全,然后弃用了Hashtable,因为Lock锁的性能比synchronized锁的性能更好
在开发编程中,如果多个线程共享一个HashMap,那么必须考虑线程安全的问题,可以自己在代码中对HashMap操作代码加锁,或者直接用线程安全的ConcurrentHashMap类,在不考虑线程安全的环境下,用HashMap性能更好,因为加锁开锁是很耗费性能的
对Null key和Null value的支持:HashMap支持key为null,但只能有一个,Hashtable不支持,报NPE,HashMap和HashTable支持value为空,不限制个数
ConcurrentHashMap的key和value都不支持null
HashMap在1.8以后,设置了阈值=8,当链表长度超过阈值的时候,会将链表转换为红黑树以减少检索时间,Hashtable被弃用了,没有更新
初始容量大小和扩容容量大小的区别:
HashMap默认初始容量是16,扩容策略是原来的2倍
Hashtable默认初始容量是11,扩容策略是原来的2n+1
HashMap如果手动指定了初始容量,不是2的n次方,他也会找到最近的一个2的n次方作为初始容量
Hashtable如果手动指定了初始容量,会直接使用给定 的大小
HashMap采用的锁全表的机制,ConcurrentHashMap采用分段锁的设计,锁的粒度更细,性能更好
10.HashMap和TreeMap的区别
HashMap底层是数组+链表/红黑树,key无序且唯一
TreeMap底层就是红黑树,key是有序唯一的
HashMap的性能比TreeMap更好,但如果需要一个有序的key的集合,需要使用TreeMap
11.HashMap的底层原理(数据结构+put()流程+resize()流程)
1. HashMap的底层实现,HashSet的底层实现
HashMap在]DK1.8之前是数组+链表,JDK1.8之后是数组+链表/红黑树
HashSet的底层是HashMap
2. HashMap的put方法的底层原理
1.根据key的hashCode计算出数组index
2.落槽时
1.如果数组中节点为null,创建新的节点对象,把k,v存储在节点对象中,把节点对象存储在数组中
2.如果数组的节点不为null,判断节点的key与插入元素的key是否相等
1.相等,直接用新的k ,v覆盖原节点中的k,v
2.不相等,判断此时节点是否为红黑树
1.是红黑树,创建红黑树节点对象存储k,v,插入到红黑树中
2.不是红黑树,创建链表节点对象存储k,v,插入到链表中,判断链表长度是否大于阈值8
1.大于阈值8,链表转换为红黑树
3.判断++size是否大于阈值,是就扩容
3.HashMap的resize()扩容方法的底层原理
HashMap默认初始容量是16
resize()方法是在hashmap中的size大于阈值时或者初始化时,就调用resize方法进行扩容
每次扩容的时候始终是原数组长度的2倍,即长度永远是2的n次方
扩容后节点对象的位置要么在原位置,要么偏移到两倍的位置
12. HashMap的长度为什么是2的幂次方
为了能让HashMap存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀,每个链表/红黑树长度大致相同。这个实现就是把数据存到哪个链表/红黑树中的算法。
13.什么是哈希碰撞/哈希冲突,怎么解决哈希冲突,HashMap采用的是什么策略
如果两个字符串通过同样的哈希算法计算出来的哈希码是一样的,那称他们发生了哈希碰撞,哈希冲突
怎么解决哈希碰撞/冲突?
1.开放地址法 课后自己看资料
2.再哈希法
3.拉链法(链地址法)HashMap默认使用的就是这种
4.建立公共溢出区
14.HashMap为什么不直接使用key的hashCode()函数返回的哈希码作为落槽时的索引号,那HashMap是怎么解决的呢?
HashMap的底层是如何计算key落槽时的索引号的
`hashCode()`方法返回的是int整数类型,其范围为-(2 ^ 31)~(2 ^ 31 - 1),约有40亿个映射空间,而HashMap的容量范围是在16(初始化默认值)~2 ^ 30,HashMap通常情况下是取不到最大值的,并且设备上也难以提供这么多的存储空间,从而导致通过`hashCode()`计算出的哈希值可能不在数组大小范围内,进而无法匹配存储位置;
1. HashMap自己实现了自己的`hash()`方法,通过两次扰动使得它自己的哈希值高低位自行进行异或运算,降低哈希碰撞概率也使得数据分布更平均;
15.==和equals()方法的区别
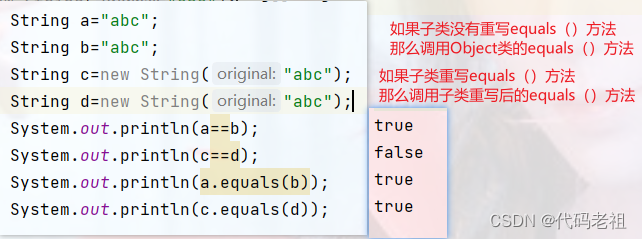
==和equals()都可以用于比较,语法是a==b,a.equals(b)
==比较的是内存地址
equals()方法是Object类中的方法,可以被任意类继承或重写,通过看官方Object类源码可以知道equals()方法默认也是用==比较内存地址
如果想要修改equals()方法的比较规则,可以重写equals()方法
String类就重写equals()方法的比较规则,由默认的比较两个字符串对象的内存地址,修改为比较字符串中每个字符是否相等,
因为堆区中可能会出现两个一模一样的字符串对象,但内存地址不一样,所以字符串的比较必须使用equals()方法,否则可能出现两个内容一模一样的字符串,因为地址不一样比较后出现不相等的情况

16.为什么重写了equals()方法,也要重写HashCode()方法
HashMap的底层采用了采用了key的HashCode()来计算索引index,
如果数组的【index】为null说明key不存在,直接落槽插入
如果数组的【index】不为null说明该位置有key存在,但不能一定说明已存在的key与要插入的key重复,因为有可能发生哈希碰撞,此时应进一步用equals方法比较已存在的key与要插入的key是否相等,如果相等说明一定是重复的,应该覆盖,如果不相等,说明发生了哈希碰撞,那么应该插入到链表中
重写equals方法的目的是为了不去比较两个对象的内存地址,改为比较对象的内容,如果一个类重写equals,没有重写HashCode,尽可能出现两个地址不同的对象equals比较相等,但是hashCode比较不相等,这样会违反HashMap的唯一性,因此,重写了equals()方法,也要重写HashCode()方法,且必须满足两个对象equals相等,hashCode也必须相等
















 6656
6656











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











