






 数据预处理包括数据清洗、数据集成和数据归约,旨在去除脏数据、处理缺失值和异常值,以及整合和简化数据。数据清洗涉及缺失值的删除、插补等策略,异常值处理则可能选择删除或修正。数据集成通过实体识别、冗余性识别和数据变换确保数据完整性。数据归约则通过属性规约和数值规约降低数据复杂性,对数据挖掘至关重要。
数据预处理包括数据清洗、数据集成和数据归约,旨在去除脏数据、处理缺失值和异常值,以及整合和简化数据。数据清洗涉及缺失值的删除、插补等策略,异常值处理则可能选择删除或修正。数据集成通过实体识别、冗余性识别和数据变换确保数据完整性。数据归约则通过属性规约和数值规约降低数据复杂性,对数据挖掘至关重要。
目录
数据预处理简单来说就是在进行数据探索数据处理之前对数据进行一系列处理,将数据中的脏数据去除,之后进行数据分析的时候保证结果的准确性。
数据预处理主要分为三个部分:数据清洗、数据集成、数据归约
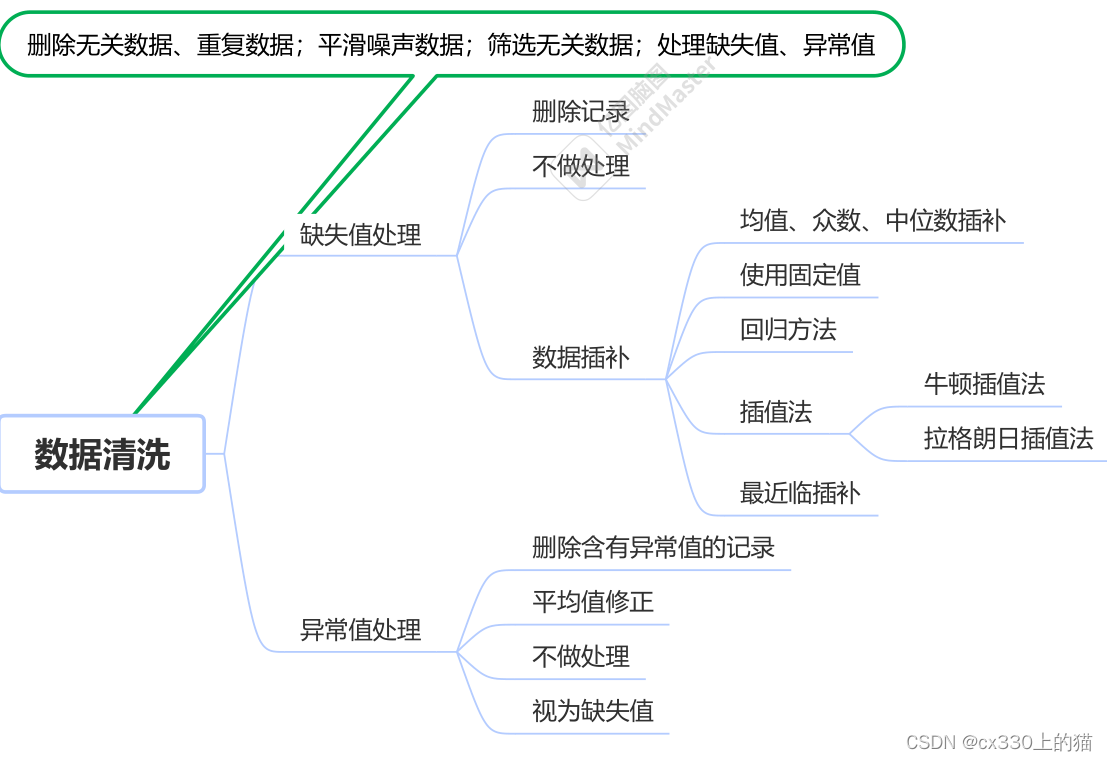
一、数据清洗
数据清洗主要来删除无关数据、重复数据、平滑噪声数据、筛选无关数据、处理缺失值和异常值;Ⅰ、对于缺失值的处理分为三种:
①删除记录
②不做处理
③数据插补:对于数据插补来说,是通过一定的计算方法将缺失的值补齐
主要的计算方法有:
使用均值、众数、中位数插补。就是通过这个缺失值属性中的其他值,求出它们的均值、众数、中位数将缺失值补齐;
使用固定值就是设置一个恒定值,将所有缺失值都用这个恒定值来补齐;
插值法:有牛顿插值法和拉格朗日插值法;
最近临插补:用knn找到这个值最近距离的值来填补空缺。
Ⅱ、对于异常值的处理方法有:删除含有异常值的记录;平均值修正;不做处理;视为缺失值。
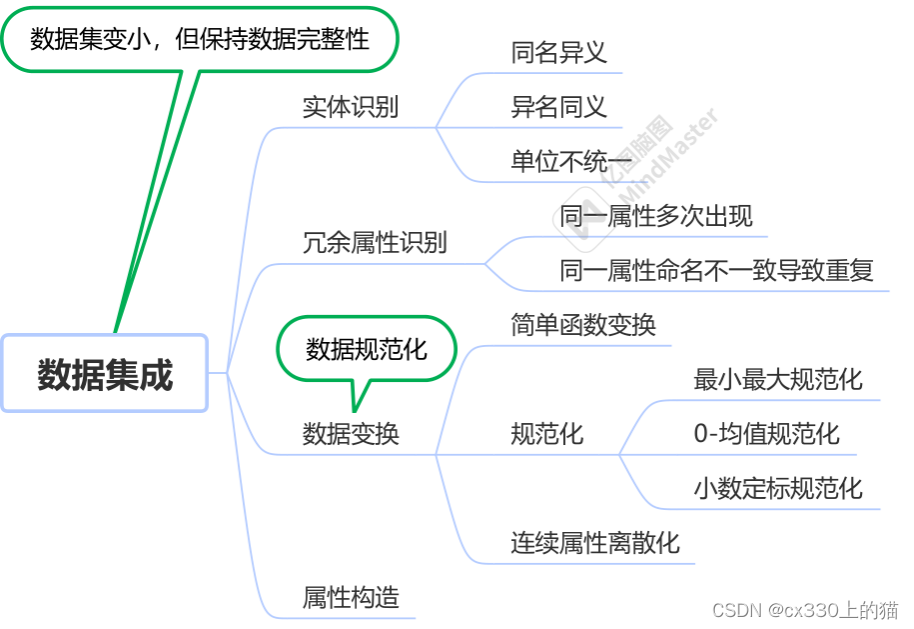
二、数据集成
数据集成的目的是将数据集变小的同时,保持数据的完整性。
主要的方法有:
①实体识别:实体识别时,对于同名异义的属性进行更改,消除异名同义的属性,统一属性的的单位;
②冗余性识别:冗余性识别是对同一属性多次出现、同一属性命名不一致导致重复这两种情况进行识别。
③数据变换:数据变换也是数据规范化,可进行简单函数变换、规范化(最小最大规范化、0-均值规范化、小数定标规范化)、连续属性离散化。
④属性构造
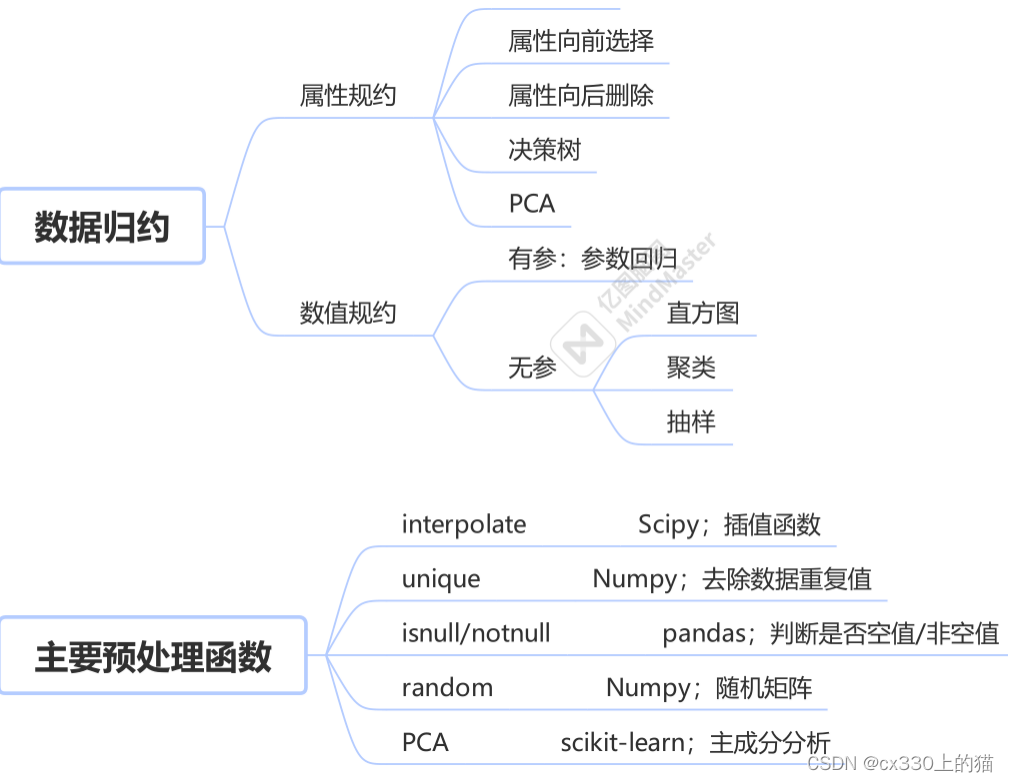
三、数据归约
数据规约分为属性规约和数值规约。
Ⅰ属性规约的方法主要有:
①合并属性
②属性向前选择
③属性向后删除
④决策树和PCA
Ⅱ数值规约分为有参和无参两种形式,有参就用参数回归,无参就有直方图、聚类、抽样。
数据预处理对数据挖掘以及进一步分析甚至是深度学习都有很大的影响。
以上内容的思维导图:

















 9819
9819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









