







目录
一、了解爬虫基本概念
1、什么是爬虫,爬虫有什么用?
按照一定的规则,自动地抓取互联网信息的程序或者脚本叫做爬虫;
作用:相当于探测机器,可以模拟人的行为去各个网站溜达,点点按钮,查查数据,或者把看到的信息背回来。
2、爬虫是怎么运行的?
基本上是按照,发送请求——获得页面——解析页面——抽取并储存内容,这样的流程来进行操作,模拟了我们实验电脑或者手机使用浏览器获取网页信息的过程。
二、requests简介
1、如何安装?
在Pycharm等编译器中直接导入模块:import requests;
方法一(最容易): 此时会出现波浪线提示,我们将鼠标移动到波浪线上,会出现此模块未下载的提示(Modul no found),我们直接点击提示的下载该模块,等待2分钟左右即下载成功;
方法二(pip命令安装): 在控制台输入:pip install requests(win操作系统),pip3 install requests(Mac操作系统),linux操作系统还没咋学,还不知道(搜索引擎找找也很快能解决这个问题)。
2、如何验证是否成功安装?
在Pycharm等编译器中直接导入模块:import requests,未出现波浪线警告则证明已经下载成功。
3、requests库作用
是用来模拟我们电脑或者手机发起的请求的,相当于是一个模拟我们电脑或者手机身份的库。
4、requests基本使用
1、get方法:requests.get(url,headers等参数),url参数是我们需要爬取的网站,headers参数是我们的请求头,是用来防止爬取过程中被反爬的(一旦被反爬,我们无法返回数据,我们发起的请求被拒绝了)。该方法会返回一个请求的结果,该结果会返回我们爬取到的数据。
如下图2.1:
import requests
url = "我们爬取的网站"
resp = requests.get(url)
print(resp.text) # 输出我们返回请求的源代码,即为爬取的url源代码图2.1
若网站不存在反爬,则我们会获取到网页的源代码,如存在反爬则返回内容为空。
怎么解决呢?这时需要我们重新访问该网站,F12打开开发者模式,进入network,点击一个文件(一个找不到,就多点击几个,一般是点击前面的文件才有user-agent),复制,回到我们的Pycharm等编译器,把内容放进字典。
如下图2.2、图2.3:
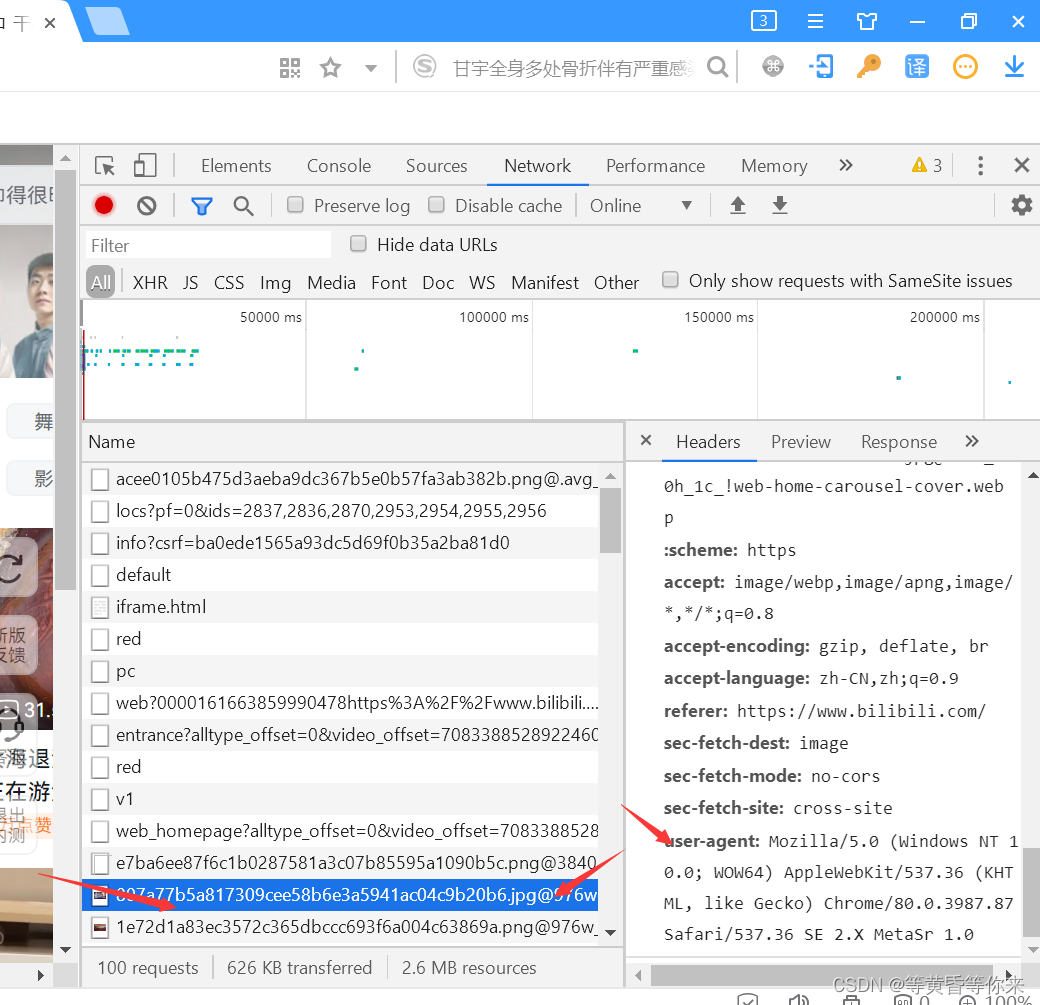
图2.2
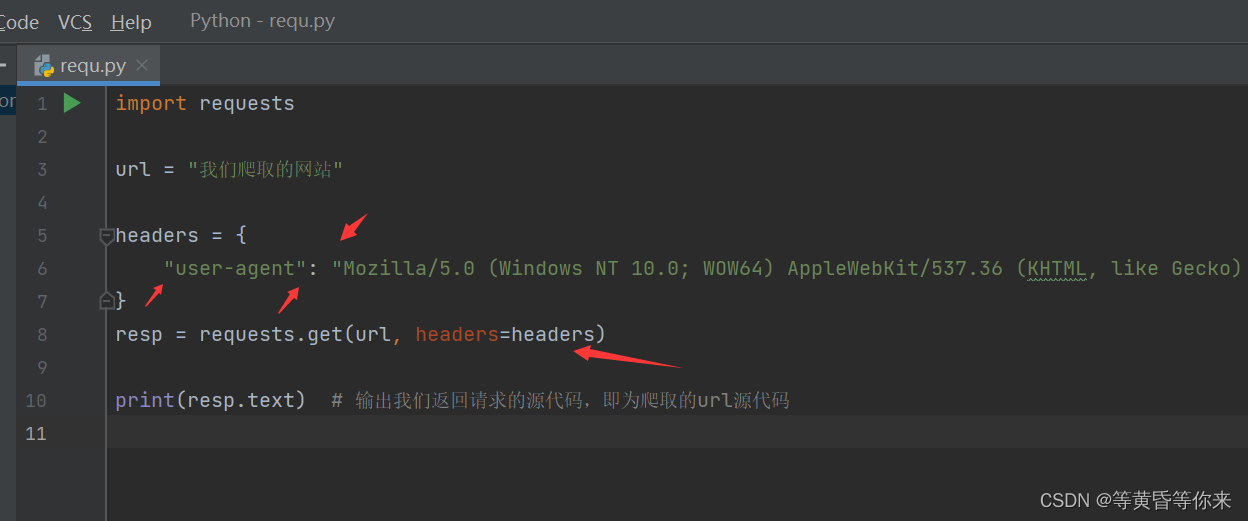
图2.3
本次只讲了比较常用的get方法,其它方法还在学习,此时基本上大部分网站我们都可以爬取到源代码并输出源代码,完成爬取的功能。
三、总结
1、完成一个爬虫的基本步骤,有目标url->获取请求->输出返回请求的结果(源码等结果);
2、把源码爬取回来之后,进行所需内容的提取(re,bs4,xpath)等方法;
3、内容提取成功后,进行数据的保存与数据可视化等步骤。
4、思考,如何进行多页面的爬取?如何进行页面的转化?
5、分布式爬虫是啥?
6、如何优化代码等。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









