







综述
用栈实现队列:leetcode232
用队列实现栈:leetcode225
有效的括号:leetcode20
删除字符串中的所有相邻重复项:leetcode1047
逆波兰表达式求值:leetcode150
滑动窗口最大值:leetcode239
前 K 个高频元素:leetcode347
引言
栈与队列
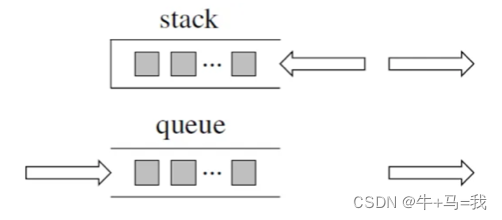
栈是先进后出,队列是先进先出
C++标准库是有多个版本的,其中三个最为普遍的STL版本:
- HP STL 其他版本的C++ STL,一般是以HP STL为蓝本实现出来的,HP STL是C++ STL的第一个实现版本,而且开放源代码。
- P.J.Plauger STL 由P.J.Plauger参照HP STL实现出来的,被Visual C++编译器所采用,不是开源的。
- SGI STL 由Silicon Graphics Computer Systems公司参照HP STL实现,被Linux的C++编译器GCC所采用,SGI STL是开源软件,源码可读性甚高。
以下介绍的都是 SGI STL 里面的数据结构
栈和队列提供 push 和 pop 等等接口,不提供迭代器(iterator)。 不像是set 或者map 提供迭代器iterator来遍历所有元素。
在 SGI STL 默认是使用 deque 来实现的 stack 和 queue,当然 vector 和 list 也可以实现
比如,以 vector 为底层实现 stack:std::stack<int, std::vector<int>> st;
以 list 为底层实现 queue:std::queue<int, std::list<int>> que;
因此在 STL 中其实 stack 和 queue 是不被归类为容器的,而是归类为 container adapter(容器适配器)
大顶堆和小顶堆
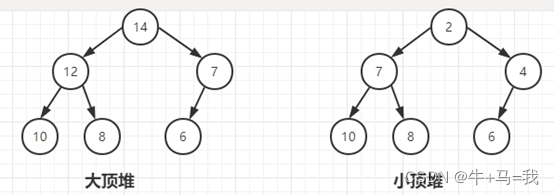
什么是大顶堆,小顶堆
堆是一种完全二叉树。完全二叉树的定义:所有节点从上往下,从左往右的依次排列,不能有空位置,是为完全二叉树。
大顶堆定义:父节点都大于左右子节点。
小顶堆定于:父节点都小于左右子节点。
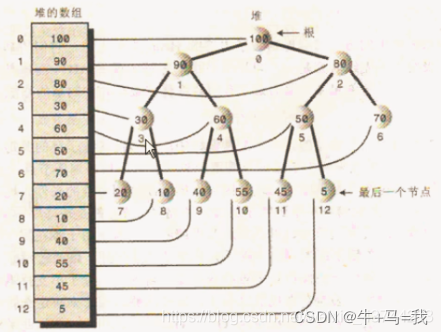
堆的底层结构
堆本质就是一颗完全二叉树,所以底层就是完全二叉树的样子
template<class T>
class BstNode {
private:
T content;
BstNode* left;
BstNode* right;
public:
BstNode() : left(nullptr), right(nullptr){};
BstNode(T content) : left(nullptr), right(nullptr){
this->content = content;
}
};
实际上,一般用数组来表示这样的二叉树,因为这样节省内存。由于堆是完全二叉树,所以父节点和子节点有数学关系: 用数组来存储二叉树:如果父节点的数组下标是 i,那么它的左孩子就是 i * 2 + 1,右孩子就是 i * 2 + 2 。 所以使用数组是可以根据父节点方便的找到子节点,也可以根据子节点方便的找到父节点,而且可以节省存储两个子节点的指针的内存。
简单实现小顶堆(大顶堆类似)
定义小顶堆:
template<class T>
class MinHeap {
private:
T* heap; //指向堆区中的小顶堆的指针
int size; //数组当前size
int capacity; //数组最大存储能力
public:
MinHeap(int capacity = 10);
~MinHeap();
void push(T data);
void pop();
T& top();
};
构造函数:
注意,此处不涉及异常处理,假设输入的值都是正常值,不会导致异常
template<class T>
MinHeap<T>::MinHeap(int capacity){
this->capacity = capacity;
heap = new T[this->capacity];
this->size = 0;
}
插入:
- 首先将需插入的数据放在堆的最后一个位置
- 然后依次和父节点比较,比父节点小就和父节点交换,再向上比较;比父节点大就停止比较。

template<class T>
void MinHeap<T>::push(T data){
if (size == capacity) { //堆满了,动态扩容
int newCapacity = capacity * 2; //动态扩容2倍
T* newHeap = new T[newCapacity];
std::copy(heap.begin(), heap.end(), newHeap.begin()); //原数据拷贝到新heap
delete[] heap;
heap = newHeap;
capacity = newCapacity;
}
heap[size] = data;
int sonIndex = size; //子节点下标
int fatherIndex = (sonIndex - 1) / 2; //父节点下标
while (sonIndex > 0) {
if (heap[sonIndex] < heap[fatherIndex]) {
std::swap(heap[sonIndex], heap[fatherIndex]); //子 < 父,就交换
sonIndex = fatherIndex;
fatherIndex = (sonIndex - 1) / 2;
} else break;
}
size++;
}
删除:(删除小顶堆的头节点)
- 首先把堆顶元素删除
- 接着把堆的最后一个数据放在堆顶
- 最后把堆顶数据向下渗透,不断的和两个子节点比较,若父节点不比两个子节点的任意一个小,取两个子节点中小的和父节点交换,一直这样下去,直到父节点比左右子节点都小。

template<class T>
void MinHeap<T>::pop() {
heap[0] = heap[--size]; //删除堆顶,并将最后一个数据放在堆顶
int fatherIndex = 0;
int leftIndex = fatherIndex * 2 + 1;
int rightIndex = leftIndex + 1;
while (leftIndex < size) { //为什么用leftIndex, 而不是rightIndex ,因为不一定有右节点
int minIndex; //较小值的索引
if (rightIndex < size) { //意味着有右节点,找左右节点的较小值
minIndex = heap[leftIndex] < heap[rightIndex] ? leftIndex : rightIndex;
} else minIndex = leftIndex; //没有右节点,那较小值就是左节点
if (heap[fatherIndex] > heap[minIndex]) //满足 父 > 子,就交换
std::swap(heap[fatherIndex], heap[minIndex]);
else break;
fatherIndex = minIndex; //更新下标
leftIndex = fatherIndex * 2 + 1;
rightIndex = leftIndex + 1;
}
}
返回头节点:
template<class T>
T& MinHeap<T>::top() {
return heap[0];
}
析构函数:
template<class T>
MinHeap<T>::~MinHeap() {
delete[] heap;
}
C++中大顶堆和小顶堆的应用
priority_queue 模板参数
priority_queue (优先级队列) 其实就是大顶堆或小顶堆
priority_queue 声明形式:priority_queue<type, container, function>;
使用时,第一个不能省略,后面的可以省略
type:数据类型;
container:实现优先队列的底层容器,必须是可随机访问的容器,例如 vector、deque,而不能使用list;默认是 vector
function:元素之间的比较方式;默认是 operator< 为比较方式,也就是创建大顶堆。(这里需要注意,这点和平常的常识不一样, operator< 是大顶堆,也就是说 less<int> 是大顶堆,greater 是小顶堆)
成员函数
bool empty() const :返回值为 true,说明队列为空;
int size() const :返回优先队列中元素的数量;
void pop() :删除队列顶部的元素,也即根节点
int top() :返回队列中的顶部元素,但不删除该元素;
void push(type arg):将元素 arg 插入到队列之中;
示例
//创建大顶堆
priority_queue<int> maxHeap;
priority_queue<int, vector<int>, less<int>> maxHeap;
//创建小顶堆
priority_queue<int, vector<int>, greater<int>> minHeap;
时间复杂度
增、删时间复杂度均为 O(logn)
获取堆头节点是 O(1)
刷题总结
滑动窗口最大值 这个题需要多去刷两遍,因为转过头就忘了,且第一次接触没有啥思路。并且这是使用单调队列的经典题目,单调队列一般需要自己动手实现。
且 通过本题知道内部类如何实现
需要注意一般都是使用 deque 来实现 queue 和 stack 的
前 K 个高频元素,通过此题了解大顶堆与小顶堆
priority_queue 的第三个参数是比较器,而不是函数对象,比较器传进去之后,会自动创建实例,所以传递函数对象的话会报错
return left > right 小顶堆,left < right 是大顶堆,正好和排序是相反的
如果面试中提问 “求一组数的前 k 个较大值或较小值时”,就可以考虑使用 大小为 k 的 小顶堆 或 大顶堆
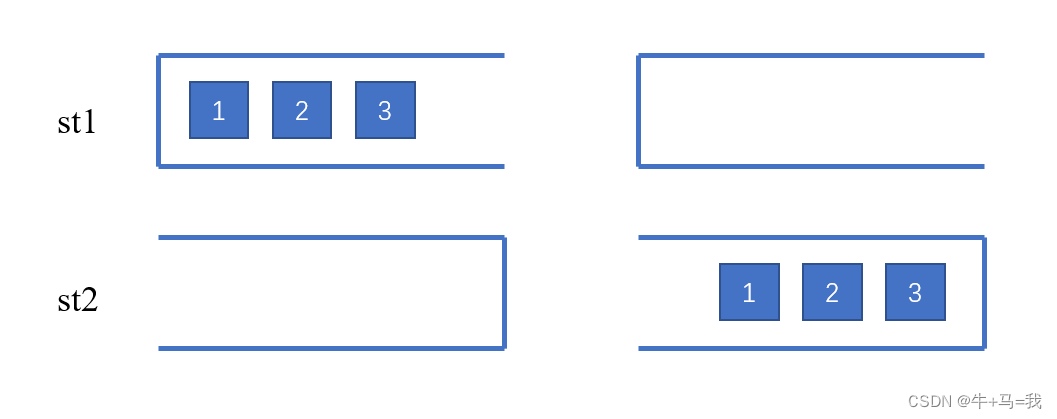
用栈实现队列
题目
题解
两个栈实现,一个输入栈,一个输出栈
class MyQueue {
public:
MyQueue() {
}
void push(int x) {
st1.push(x);
}
int pop() {
if (st2.empty()) {
while (!st1.empty()) {
int x = st1.top();
st1.pop();
st2.push(x);
}
}
int x = st2.top();
st2.pop();
return x;
}
int peek() {
if (st2.empty()) {
while (!st1.empty()) {
int x = st1.top();
st1.pop();
st2.push(x);
}
}
return st2.top();
}
bool empty() {
return st1.empty() && st2.empty();
}
private:
stack<int> st1;
stack<int> st2;
};
时间复杂度: push和empty为O(1), pop和peek为O(n)
空间复杂度: O(n)
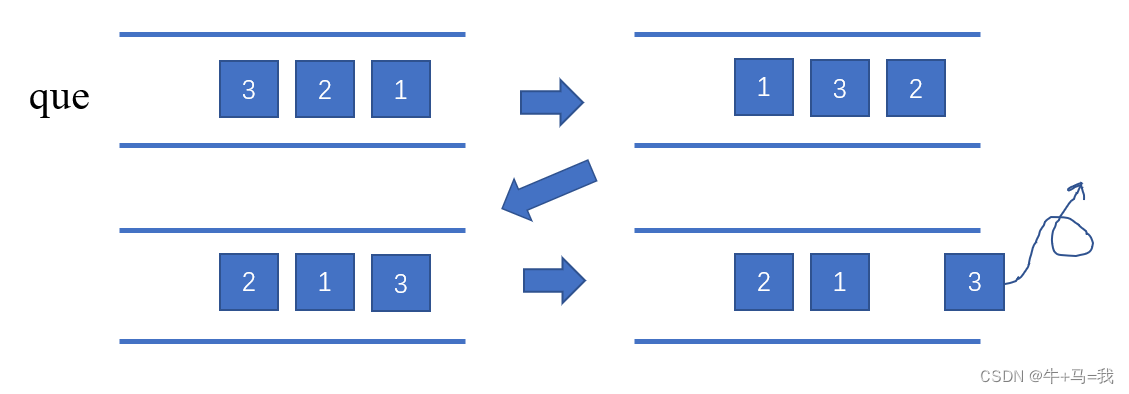
用队列实现栈
题目

题解
其实一个队列就够了
class MyStack {
public:
MyStack() {
}
void push(int x) {
que.push(x);
}
int pop() {
int size = que.size();//需要一个size来记录原来的尺寸
for (int i = 0; i < size - 1; i++) {
que.push(que.front());
que.pop();
}
int x = que.front();
que.pop();
return x;
}
int top() {
int size = que.size();
for (int i = 0; i < size - 1; i++) {
que.push(que.front());
que.pop();
}
int x = que.front();
que.pop();
que.push(x);
return x;
}
bool empty() {
return que.empty();
}
private:
queue<int> que;
};
时间复杂度: pop为O(n),其他为O(1)
空间复杂度: O(n)
有效的括号
题目

题解
class Solution {
public:
bool isValid(string s) {
if (s.size() % 2 != 0) return false;
stack<char> st;
for (int i = 0; i < s.size(); i++) {
if (!st.empty()) {
if (s[i] == ')' && st.top() == '(') st.pop();
else if (s[i] == ']' && st.top() == '[') st.pop();
else if (s[i] == '}' && st.top() == '{') st.pop();
else st.push(s[i]);
} else {
st.push(s[i]);
}
}
return st.empty();
}
};
时间复杂度: O(n)
空间复杂度: O(n)
删除字符串中的所有相邻重复项
题目

题解
本题只需要注意栈如何转换成字符串效率高即可。尽量少用 reverse,因为耗时
class Solution {
public:
string removeDuplicates(string s) {
//使用栈进行消除重复项
stack<char> st;
for (int i = 0; i < s.size(); i++) {
if (!st.empty() && s[i] == st.top()) st.pop();
else st.push(s[i]);
}
//将栈转换成字符串
string res(st.size(), '0');
int size = st.size() - 1;
for (int i = size; i >= 0; i--) {
res[i] = st.top();
st.pop();
}
return res;
}
};
时间复杂度: O(n)
空间复杂度: O(n)
逆波兰表达式求值
题目

题解
stack 尽量使用 存放 int, 而不是 string
class Solution {
public:
int evalRPN(vector<string>& tokens) {
stack<int> st;//尽量使用int存放,而不是string,这样方便
for (int i = 0; i < tokens.size(); i++) {
if (tokens[i] == "+" || tokens[i] == "-" || tokens[i] == "*" || tokens[i] == "/") {
int x = st.top();
st.pop();
int y = st.top();
st.pop();
if (tokens[i] == "+") st.push(y + x);
else if (tokens[i] == "-") st.push(y - x);
else if (tokens[i] == "*") st.push(y * x);
else st.push(y / x);
} else st.push(std::stoi(tokens[i]));
}
return st.top();
}
};
时间复杂度: O(n)
空间复杂度: O(n)
对于计算机来说,很多使用的都是后缀表达式,这样计算机可以使用 stack 来进行计算。如果使用 中缀表达式,如 4 + 13 / 5,计算机不知道先算加法还是除法
滑动窗口最大值
题目
题解
这道题比较难,需要多练几遍
这是使用单调队列的经典题目。单调队列,即单调递减或单调递增的队列。C++中没有直接支持单调队列,需要我们自己来实现一个单调队列
本题中,队列没有必要维护窗口里的所有元素,只需要维护有可能成为窗口里最大值的元素就可以了,同时保证队列里的元素数值是由大到小的。
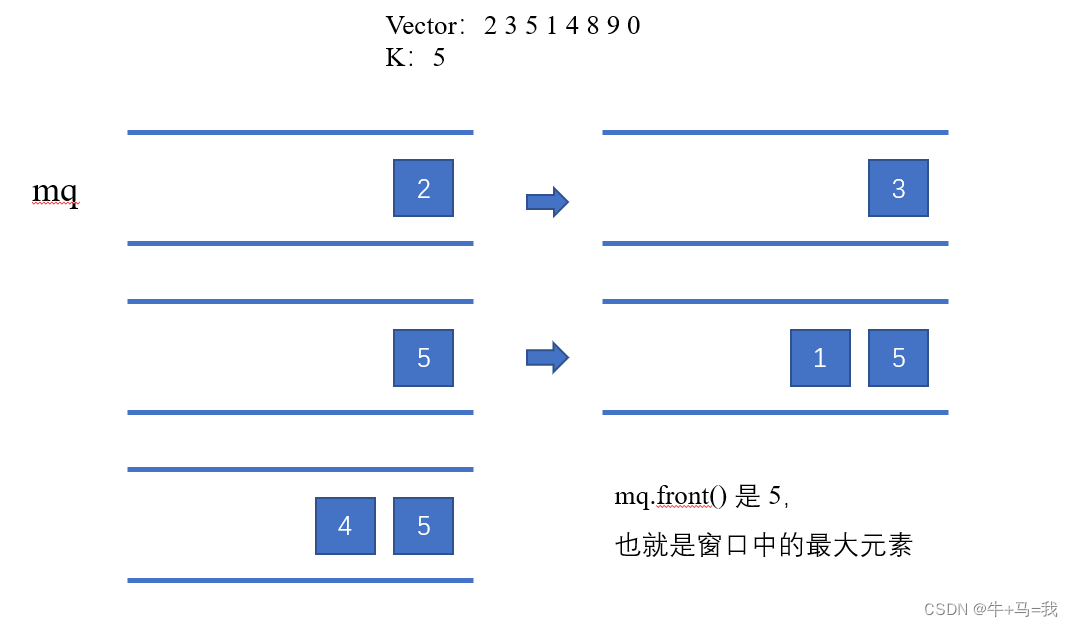
对于上述队列,其实只需要维护从大到小的数字即可,不需要维护所以的值,为此,需要设计一个单调队列 mq,包含 push,pop,front 方法
- push(x):如果 push 的元素 x 大于 mq.back() 的数值,那么就将 mq.back() 弹出,直到 push
元素的数值小于等于队列 mq.back() 为止 - pop(x):如果窗口移除的元素 x 等于单调队列的出口元素,那么队列弹出元素,否则不用任何操作
- front():返回当前窗口的最大值
注意:
通过本题知道内部类如何实现
一般都是使用 deque 来实现 queue 和 stack 的
class Solution {
public:
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
MotonicQueue mq;
vector<int> res;
for (int i = 0; i < k; i++) mq.push(nums[i]);//先push前k个元素
res.push_back(mq.front());
for (int i = k; i < nums.size(); i++) {//处理后面的元素
mq.pop(nums[i - k]);
mq.push(nums[i]);
res.push_back(mq.front());
}
return res;
}
private:
//内部类实现单调队列
class MotonicQueue {
public:
deque<int> d;
void push(int x) {
while (!d.empty() && d.back() < x) {
d.pop_back();
}
d.push_back(x);
}
void pop(int x) {
if (!d.empty() && d.front() == x) d.pop_front();
}
int front() {//返回单调队列的最前面的值也就是最大值
return d.front();
}
};
};
时间复杂度: O(n)
空间复杂度: O(k)
前 K 个高频元素
题目

题解
常规思路
class Solution {
public:
vector<int> topKFrequent(vector<int>& nums, int k) {
//使用unordered_map统计频率
unordered_map<int, int> umap;
for (int ele : nums) {
umap[ele]++;
}
//将unordered_map转成vector并排序
vector<pair<int, int>> vec(umap.begin(), umap.end());
sort(vec.begin(), vec.end(), mySort);
//找前k个大的值的结果
vector<int> res;
for (int i = 0; i < k; i++) {
res.push_back(vec[i].first);
}
return res;
}
private:
static bool mySort(pair<int, int>& a, pair<int, int>& b) {
return a.second > b.second;//return left>right 就是从大到小,return left<right 就是从小到大。
}
};
时间复杂度: O(nlogn)
空间复杂度: O(n)
使用小顶堆计算
对于此题来说,统计频率可以用 unordered_map
计算前 k 个较大值时,可以使用 大顶堆 / 小顶堆
对于此题来说,维护一个大小 k 的小顶堆即可。为什么不用大顶堆呢,因为个数大于 k 之后需要 pop 掉 堆顶的元素,如果是大顶堆,那就是把最大的值给 pop 掉了,而我们想要的是最大值。
因此使用小顶堆,一直保留最小值到堆顶,这样 pop 掉的就是最小值,小顶堆保留的就是 较大值
class Solution {
public:
vector<int> topKFrequent(vector<int>& nums, int k) {
//使用unordered_map统计频率
unordered_map<int, int> umap;
for (int ele : nums) {
umap[ele]++;
}
//维护一个size是k的小顶堆
priority_queue<pair<int, int>, vector<pair<int, int>>, mySort> minHeap;//第三个参数是比较器,而不是函数对象,比较器传进去之后,会自动创建实例
for (unordered_map<int, int>::iterator it = umap.begin(); it != umap.end(); it++) {
minHeap.push(*it);
if (minHeap.size() > k) minHeap.pop();
}
//minHeap转vector
vector<int> res(k);
for (int i = 0; i < k; i++) {
res[i] = (minHeap.top().first);
minHeap.pop();
}
return res;
}
private:
class mySort {
public:
bool operator()(const pair<int, int>& a, const pair<int, int>& b) {
return a.second > b.second;//return left > right 小顶堆,left < right 是大顶堆,正好和排序是相反的
}
};
};
时间复杂度: O(nlogk)
空间复杂度: O(n)
注意:
priority_queue 的第三个参数是比较器,而不是函数对象,比较器传进去之后,会自动创建实例,所以传递函数对象的话会报错
return left > right 小顶堆,left < right 是大顶堆,正好和排序是相反的















 6853
6853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









