







目录
1、如果我们需要从XML文件中检索需要的某个信息(如name)怎么解决?
一、XML检索技术:Xpath
1、如果我们需要从XML文件中检索需要的某个信息(如name)怎么解决?
Dom4j需要进行文件的全部解析,然后再寻找数据。
Xpath技术更加适合做信息检索。
XPath介绍
XPath在解析XML文档方面提供了一独树一帜的路径思想,更加优雅,高效
XPath使用路径表达式来定位XML文档中的元素节点或属性节点。
需求:使用Dom4J把一个XML文件的数据进行解析
2、实现步骤:
1、导入jar包(dom4j和jaxen-1.1.2.jar),Xpath技术依赖Dom4j技术
2、通过dom4j的SAXReader获取Document对象
3、利用XPath提供的API,结合XPath的语法完成选取XML文档元素节点进行解析操作。
4、Document中与Xpath相关的API如下:
| 方法名 | 说明 |
| Node selectSingleNode("表达式") | 获取符合表达式的唯一元素 |
| List<Node> selectNodes("表达式") | 获取符合表达式的元素集合 |
3、Xpath的四大检索方案
3.1、绝对路径
采用绝对路径获取从根节点开始逐层的查找/contactList/contact/name节点列表并打印信息
| 方法名 | 说明 |
| /根元素/子元素/孙元素 | 从根元素开始,一级一级向下查找,不能跨级 |
演示代码:
/**
1.绝对路径: /根元素/子元素/子元素。
*/
@Test
public void parse01() throws Exception {
// a、创建解析器对象
SAXReader saxReader = new SAXReader();
// b、把XML加载成Document文档对象
Document document =
saxReader.read(XPathDemo.class.getResourceAsStream("/Contacts2.xml"));
// c、检索全部的名称
List<Node> nameNodes = document.selectNodes("/contactList/contact/name");
for (Node nameNode : nameNodes) {
Element nameEle = (Element) nameNode;
System.out.println(nameEle.getTextTrim());
}
}
结果展示:
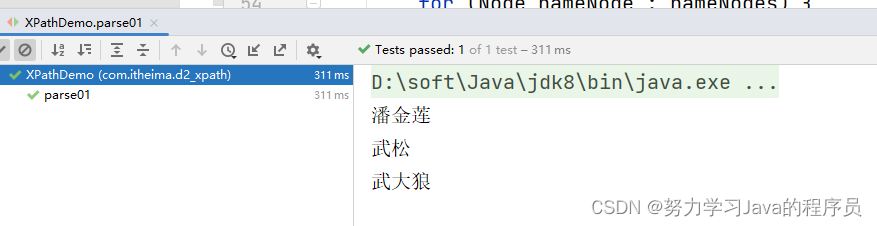
3.2、相对路径
先得到根节点contactList
再采用相对路径获取下一级contact 节点的name子节点并打印信息
| 方法名 | 说明 |
| ./子元素/孙元素 | 从当前元素开始,一级一级向下查找,不能跨级 |
演示代码:
/**
2.相对路径: ./子元素/子元素。 (.代表了当前元素)
*/
@Test
public void parse02() throws Exception {
// a、创建解析器对象
SAXReader saxReader = new SAXReader();
// b、把XML加载成Document文档对象
Document document =
saxReader.read(XPathDemo.class.getResourceAsStream("/Contacts2.xml"));
Element root = document.getRootElement();
// c、检索全部的名称
List<Node> nameNodes = root.selectNodes("./contact/name");
for (Node nameNode : nameNodes) {
Element nameEle = (Element) nameNode;
System.out.println(nameEle.getTextTrim());
}
}结果展示:
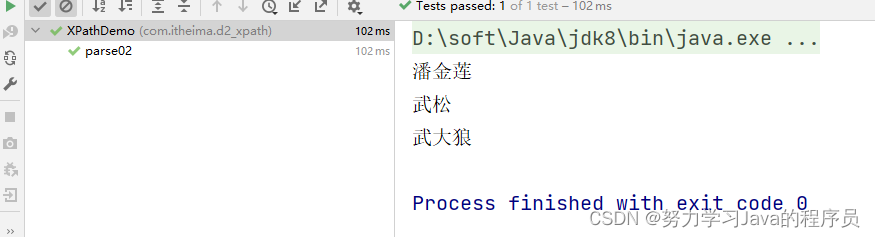
3.3、全文检索
直接全文搜索所有的name元素并打印
代码展示:
/**
3.全文搜索:
//元素 在全文找这个元素
//元素1/元素2 在全文找元素1下面的一级元素2
//元素1//元素2 在全文找元素1下面的全部元素2
*/
@Test
public void parse03() throws Exception {
// a、创建解析器对象
SAXReader saxReader = new SAXReader();
// b、把XML加载成Document文档对象
Document document =
saxReader.read(XPathDemo.class.getResourceAsStream("/Contacts2.xml"));
// c、检索数据
//List<Node> nameNodes = document.selectNodes("//name");
// List<Node> nameNodes = document.selectNodes("//contact/name");
List<Node> nameNodes = document.selectNodes("//contact//name");
for (Node nameNode : nameNodes) {
Element nameEle = (Element) nameNode;
System.out.println(nameEle.getTextTrim());
}
}结果展示: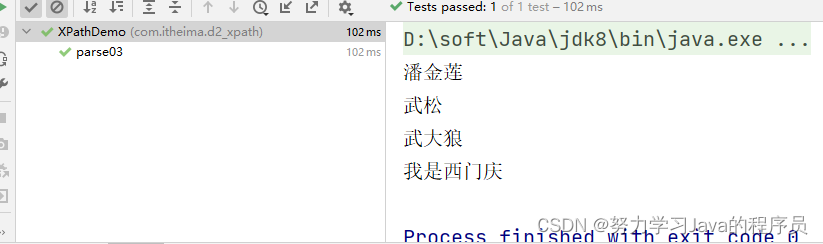
3.4、属性查找
在全文中搜索属性,或者带属性的元素
| 方法名 | 说明 |
| //@属性名 | 查找属性对象,无论是哪个元素,只要有这个属性即可。 |
| //元素[@属性名] | 查找元素对象,全文搜索指定元素名和属性名。 |
| //元素//[@属性名=‘值’] | 查找元素对象,全文搜索指定元素名和属性名,并且属性值相等。 |
代码展示:
/**
4.属性查找。
//@属性名称 在全文检索属性对象。
//元素[@属性名称] 在全文检索包含该属性的元素对象。
//元素[@属性名称=值] 在全文检索包含该属性的元素且属性值为该值的元素对象。
*/
@Test
public void parse04() throws Exception {
// a、创建解析器对象
SAXReader saxReader = new SAXReader();
// b、把XML加载成Document文档对象
Document document =
saxReader.read(XPathDemo.class.getResourceAsStream("/Contacts2.xml"));
// c、检索数据
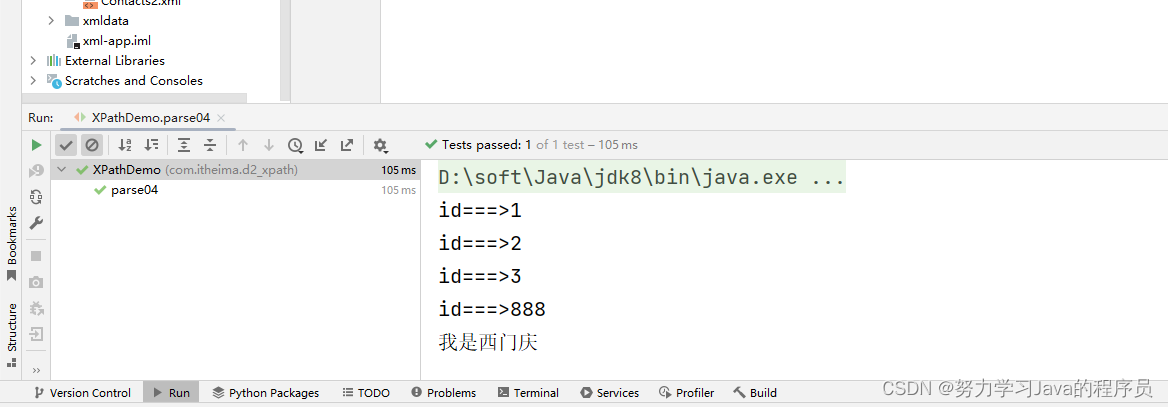
List<Node> nodes = document.selectNodes("//@id");
for (Node node : nodes) {
Attribute attr = (Attribute) node;
System.out.println(attr.getName() + "===>" + attr.getValue());
}
// 查询name元素(包含id属性的)
// Node node = document.selectSingleNode("//name[@id]");
Node node = document.selectSingleNode("//name[@id=888]");
Element ele = (Element) node;
System.out.println(ele.getTextTrim());
}
}结果展示::
二、设计模式:工厂模式
1、什么是工厂设计模式?
之前我们创建类对象时, 都是使用new 对象的形式创建,在很多业务场景下也提供了不直接new的方式 。
工厂模式(Factory Pattern)是 Java 中最常用的设计模式之一, 这种类型的设计模式属于创建型模式,它提供了一种获取对象的方式。
2、工厂设计模式的作用:
工厂的方法可以封装对象的创建细节,比如:为该对象进行加工和数据注入。
可以实现类与类之间的解耦操作(核心思想)。
三、设计模式:装饰模式
1、什么是装饰设计模式?
创建一个新类,包装原始类,从而在新类中提升原来类的功能。
2、装饰设计模式的作用:
作用:装饰模式指的是在不改变原类的基础上, 动态地扩展一个类的功能。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











