







DualTeacher: 桥接无标签类共存的半监督增量对象检测
原文:https://arxiv.org/abs/2401.05362
文章使用双教师网络,也就是两个蒸馏,一个用于解决灾难性遗忘,一个用于半监督,总结里有我个人一点浅显的理解,可以看看作简单了解。
摘要
In real-world applications, an object detector often encounters object instances from new classes and needs to accommodate them effectively. Previous work formulated this critical problem as incremental object detection (IOD), which assumes the object instances of new classes to be fully annotated in incremental data. However, as supervisory signals are usually rare and expensive, the supervised IOD may not be practical for implementation. In this work, we consider a more realistic setting named semi-supervised IOD (SSIOD), where the object detector needs to learn new classes incrementally from a few labelled data and massive unlabelled data without catastrophic forgetting of old classes. A commonlyused strategy for supervised IOD is to encourage the current model (as a student) to mimic the behavior of the old model (as a teacher), but it generally fails in SSIOD because a dominant number of object instances from old and new classes are coexisting and unlabelled, with the teacher only recognizing a fraction of them. Observing that learning only the classes of interest tends to preclude detection of other classes, we propose to bridge the coexistence of unlabelled classes by constructing two teacher models respectively for old and new classes, and using the concatenation of their predictions to instruct the student. This approach is referred to as DualTeacher, which can serve as a strong baseline for SSIOD with limited resource overhead and no extra hyperparameters. We build various benchmarks for SSIOD and perform extensive experiments to demonstrate the superiority of our approach (e.g., the performance lead is up to 18.28 AP on MS-COCO). Our code is available at
https://github.com/chuxiuhong/DualTeacher
在实际应用中,对经常遇到来自新类的对象实例,目标检测器需要有效地适应它们。之前的工作将这个关键问题表述为增量对象检测(IOD),它假设新类的对象实例在增量数据中被完全注释。然而,由于监督信号通常很少且昂贵,因此监督IOD可能不适合实施。在这项工作中,我们考虑了一个更现实的设置,称为半监督增量目标检测(SSIOD),其中对象检测器需要从一些标记数据和大量未标记数据中逐步学习新类,而不会灾难性地忘记旧类。监督式IOD的一种常用策略是鼓励当前模型(作为学生)模仿旧模型(作为教师)的行为,但在SSIOD中通常会失败,因为新旧类中的大多数对象实例共存且未标记,教师只识别其中的一小部分。观察到只学习感兴趣的课程往往会排除对其他课程的检测,我们建议通过分别为新旧课程构建两个教师模型,并使用它们的预测连接来指导学生,从而弥合未标记课程的共存。这种方法被称为DualTacher,它可以作为SSIOD的强基线,具有有限的资源开销,并且没有额外的超参数。我们为SSIOD建立了各种基准,并进行了广泛的实验来证明我们方法的优越性(例如,MS-COCO的性能领先高达18.28 AP)。我们的代码可在https://github.com/chuxiuhong/DualTeacher

文章中面对IOD任务中新类别监督信号通常很少且昂贵的情况,提出了SSIOD
介绍
文章介绍了IOD的常用策略
A commonly-used strategy is to perform knowledge distillation from a frozen copy of the old model: The current model acts as a student to learn the new classes, while the old model acts as a teacher (denoted as the old teacher) to stabilize the predictions of old classes. Since the object instances of new classes have been fully annotated, the student can faithfully inherit the predictions of old classes and thus achieves satisfactory performance.
这里说的是将具有旧类别知识的老模型冻结参数后充当教师模型在蒸馏训练的过程中稳定学生网络对旧类别的检测。
但是这是基于完全监督的方式,现实中往往更具挑战性:
For example, self-driving cars collect massive amounts of data every day, and it is expensive and impractical to annotate them completely.
所以,为了应对这种标记稀缺性的实际挑战,就有了半监督增量目标检测。(SSIOD)
In response to the practical challenge of labelling scarcity, we consider here a more realistic setting where new classes are annotated for only a small fraction of incremental data, referred to as semi-supervised IOD (SSIOD).
在SSIOD中,新教师模型仍然遭受灾难性遗忘问题,原因在于增量标记数据只能监督新类别,对旧类别的检测性能又受限于旧教师网络 的性能。而新旧类别的对象实例往往共存于增量未标记数据中,而知识有限且脱节的两位教师只能识别其中的一部分。
贴一下原文的表述吧:
The disjoint knowledge stems from the non-overlapping annotations in incremental labelled data, i.e., only the currently learned classes are annotated and the other classes are left as the “background”. As a result, the old teacher has learned to both identify old classes and “ignore” new classes, and vice versa for the new teacher. This property leads to their conflicting predictions for incremental unlabelled data, but also prevents low-quality predictions of uncertain classes. In order to bridge the coexistence of unlabelled classes, here we propose DualTeacher as a simple but effective approach for SSIOD. Specifically, we construct the old teacher that can identify old classes and train a new teacher with labelled data of new classes. Then we use the concatenation of their predictions as pseudo-labels (see Fig. 2, d) to train a student model with unlabelled data, and progressively update the new teacher with EMA. Therefore, the new teacher can obtain knowledge of both old and new classes from incremental unlabelled data and further improve its predictions to benefit the student model. We perform extensive experiments to demonstrate the superiority of DualTeacher in SSIOD, which clearly outperforms strong IOD baselines under different labelling ratios and task splits (e.g., the improvement is up to 18.28 AP on MS-COCO).
不相交的知识来源于增量标注数据中不重叠的标注,即只标注当前学习的类,其余类作为“背景”。因此,老教师学会了识别老的类别,同时“忽略”新类别,而新教师则反之。这一特性导致他们对增量未标记数据的预测相互矛盾,但也防止了对不确定类别的低质量预测。为了弥合未标记类的共存,这里我们提出DualTeacher作为SSIOD的简单但有效的方法。具体来说,我们构建了能够识别旧类别的老教师,并利用新课程的标记数据来训练新教师。然后我们使用他们的预测作为伪标签(见图2,d)来训练一个没有标记数据的学生模型,并逐步用EMA更新新老师。因此,新教师可以从增量的未标记数据中获得新旧班级的知识,并进一步改进其预测,从而使学生模型受益。我们进行了大量的实验来证明DualTeacher在SSIOD方面的优势,在不同的标记比率和任务分割下,它明显优于强IOD基线(例如,MS-COCO的改进高达18.28 AP)。
Our contributions include: (1) To the best of our knowledge, we are the first to consider semi-supervised incremental object detection (SSIOD), which is practical for updating object detectors in realistic applications; (2) We attribute the central challenge of SSIOD to the conflict in predicting old and new classes that coexist in incremental unlabelled data, and propose a simple but effective approach to address it; (3) We build a variety of SSIOD benchmarks and extensively validate the superiority of our approach.
我们的贡献包括:(1)据我们所知,我们是第一个考虑半监督增量对象检测(SSIOD)的人,这对于在现实应用中更新对象检测器是实用的;(2)我们将SSIOD的核心挑战归因于预测增量未标记数据中共存的新旧类别的冲突,并提出了一种简单但有效的方法来解决这一问题;(3)我们建立了各种SSIOD基准测试,并广泛验证了我们方法的优越性。

Problem Formulation
好吧,下面来看看 Problem Formulation,有这么几个东西:
- x就是image,y就是image的注释
- D t = D t l ∪ D t u \mathcal{D}_{t}^{}= \mathcal{D}_{t}^{l}\cup\mathcal{D}_{t}^{u} \, \quad Dt=Dtl∪Dtu,这是t任务的训练数据集,任务t也被称为“增量阶段”,标记子集 D t l = { ( x t , n l , y t , n l ) } n = 1 N t l \mathcal{D}_t^l=\{(\mathcal{x}_{t,n}^l,\mathcal{y}_{t,n}^l)\}_{n=1}^{{N}_t^l} \, Dtl={(xt,nl,yt,nl)}n=1Ntl,有 N t l {N}_t^l Ntl个数据-标签对
- D t u \mathcal{D}_t^u Dtu也就是未标记子集, D t l = { ( x t , n u ) } n = 1 N t u \mathcal{D}_t^l=\{(\mathcal{x}_{t,n}^u)\}_{n=1}^{N_t^u} \, Dtl={(xt,nu)}n=1Ntu,有 N t u N_t^u Ntu个未标记数据
-
C
i
l
\mathcal{C}_i^l
Cil表示标签
y
t
,
n
l
\mathcal{y}_{t,n}^l
yt,nl的所有标记类
- 这里注意一点,新旧类别是disjoint——不相交的,也就是 C i l ∩ C j l = ∅ \mathcal{C}_i^l\cap\mathcal{C}_j^l=\empty \, Cil∩Cjl=∅ for i / = j i\mathrlap{\,/}{=}j i/=j
Preliminaries of Object Detection
两阶段检测
论文关注的是两阶段的RCNN
这里将检测器看作为一个函数的组合(compositions of functions):
f
r
o
i
∘
f
r
p
n
∘
f
b
\ f_{roi} \circ \ f_{rpn} \circ \ f_{b} \quad
froi∘ frpn∘ fb,以
θ
r
o
i
,
θ
r
p
n
,
θ
b
参数化。
\theta _{roi} , \theta_{rpn} , \theta _{b}参数化。 \quad
θroi,θrpn,θb参数化。
- f b \ f_{b} fb是骨干网络,它将输入图像 x t , n \ x_{t,n} xt,n投影到其特征映射 h t , n , h t , n ∈ R C × H × W \ h_{t,n},\ h_{t,n}\isin \R^{C\times H\times W} ht,n, ht,n∈RC×H×W。
- f r p n \ f_{rpn} frpn,RPN从 h t , n \ h_{t,n} ht,n中提出潜在对象实例的区域,为多个proposals提供打分和位置。
- f r o i \ f_{roi} froi,预测这些提案的类,并将proposals回归出最终的结果。
半监督
为了有效地利用Dt中的部分标记数据,主流的半监督学习技术构建了两个相互依赖的模型作为一个师生框架,分别表示为
f
t
e
a
,
θ
t
e
a
和
f
s
t
u
,
θ
s
t
u
。
\ f_{tea}, θ_{tea}和f_{stu}, θ_{stu}。
ftea,θtea和fstu,θstu。
具体来说:
通过RPN的分类损失
L
r
p
n
c
l
s
\mathcal{L}_{rpn}^{cls}
Lrpncls和回归损失
L
r
p
n
r
e
g
\mathcal{L}_{rpn}^{reg}
Lrpnreg,以及ROI的分类损失
L
r
o
i
c
l
s
\mathcal{L}_{roi}^{cls}
Lroicls和回归损失
L
r
o
i
r
e
g
\mathcal{L}_{roi}^{reg}
Lroireg训练目标检测器,此时数据集使用的是
D
t
l
\mathcal{D}_t^l
Dtl,训练阶段为磨合阶段1。
L sup = 1 N t l ∑ n = 1 N l t [ L rpn cls ( x t , n l , y t , n l ) + L rpn reg ( x l , t , n l , y l , t , n l ) + L roi cls ( x t , n l , y t , n l ) + L roi reg ( x t , n l , y t , n l ) ] (1) L_{\text{sup}} = \frac{1}{N_t^l} \sum_{n=1}^{N_l^t} \left[ L_{\text{rpn}}^{\text{cls}}(x_{t,n}^l, y_{t,n}^l) + L_{\text{rpn}}^{\text{reg}}(x_{l,t,n}^l, y_{l,t,n}^l) + L_{\text{roi}}^{\text{cls}}(x_{t,n}^l, y_{t,n}^l) + L_{\text{roi}}^{\text{reg}}(x_{t,n}^l, y_{t,n}^l) \right] \tag{1} Lsup=Ntl1n=1∑Nlt[Lrpncls(xt,nl,yt,nl)+Lrpnreg(xl,t,nl,yl,t,nl)+Lroicls(xt,nl,yt,nl)+Lroireg(xt,nl,yt,nl)](1)
实际过程中,使用Facol lass来代替交叉熵损失,可以缓解类别不平衡,接下来,
f
f
f分别用得到的权值
θ
\theta
θ初始化学生网络和教师网络的权值
θ
tea
←
θ
,
θ
stu
←
θ
\theta_{\text{tea}} \leftarrow \theta, \quad \theta_{\text{stu}} \leftarrow \theta
θtea←θ,θstu←θ
初始化后的
f
t
e
a
\ f_{tea}
ftea为
D
t
u
D^u_t
Dtu中的每个
x
t
,
n
u
x^u_{t,n}
xt,nu生成伪标签:
y ^ t , n u = f tea ( x t , n u ) (2) \hat{y}^{u}_{t,n} = f_{\text{tea}}(x^{u}_{t,n}) \tag{2} y^t,nu=ftea(xt,nu)(2)
此时, f t e a f_{tea} ftea中的 θ t e a θ_{tea} θtea是固定的,只有 f s t u f_{stu} fstu中的 θ s t u θ_{stu} θstu通过反向传播更新:
θ stu ← θ stu + α stu ∂ ( L sup + λ unsup L unsup ) ∂ θ stu (3) \theta_{\text{stu}} \leftarrow \theta_{\text{stu}} + \alpha_{\text{stu}} \frac{\partial (\mathcal{L}_{\text{sup}} + \lambda_{\text{unsup}} \mathcal{L}_{\text{unsup}})}{\partial \theta_{\text{stu}}} \tag{3} θstu←θstu+αstu∂θstu∂(Lsup+λunsupLunsup)(3)
L unsup = 1 N t u ∑ n = 1 N t u [ L rpn cls ( x t , n u , y ^ t , n u ) + L roi cls ( x t , n u , y ^ t , n u ) ] (4) \mathcal{L}_{\text{unsup}} = \frac{1}{N_t^u} \sum_{n=1}^{N_t^u} \left[ \mathcal{L}_{\text{rpn}}^{\text{cls}}(x_{t,n}^u, \hat{y}_{t,n}^u) + \mathcal{L}_{\text{roi}}^{\text{cls}}(x_{t,n}^u, \hat{y}_{t,n}^u) \right] \tag{4} Lunsup=Ntu1n=1∑Ntu[Lrpncls(xt,nu,y^t,nu)+Lroicls(xt,nu,y^t,nu)](4)
有这么几个超参数:学生网络的学习率 α stu \alpha_{\text{stu}} αstu教师网络的学习率 α t e a \alpha_{tea} αtea以及无监督占比的 λ unsup \lambda_{\text{unsup}} λunsup
θ tea ← α tea θ tea + ( 1 − α tea ) θ stu (5) \theta_{\text{tea}} \leftarrow \alpha_{\text{tea}} \theta_{\text{tea}} + (1 - \alpha_{\text{tea}}) \theta_{\text{stu}} \tag{5} θtea←αteaθtea+(1−αtea)θstu(5)
教师网络 f t e a \ f_{tea} ftea的更新基于学生网络的权重,这种更新方式能够确保教师网络在不大幅度波动的情况下逐渐适应学生网络的学习过程,从而提升伪标签的质量。这种方法通常在半监督学习中使用,以充分利用未标注的数据。
增量学习
增量学习的出现,是为了解决灾难性遗忘问题
一种通用的策略:创建旧模型的冻结副本,表示为
f
o
l
d
f_{old}
fold,并添加知识蒸馏损失来惩罚
f
f
f和
f
o
l
d
f_{old}
fold之间输出的差异。
KD的Loss:
L kd sup = 1 N t l ∑ n = 1 N l t d [ f ( x t , n l ) , f old ( x t , n l ) ] (6) \mathcal{L}_{\text{kd}}^{\text{sup}} = \frac{1}{N_t^l} \sum_{n=1}^{N_l^t} d[f(x^l_{t,n}), f_{\text{old}}(x^l_{t,n})] \tag{6} Lkdsup=Ntl1n=1∑Nltd[f(xt,nl),fold(xt,nl)](6)
where d is the function of measuring differences, and the supervised loss L s u p L_{sup} Lsup becomes
L sup ′ = L sup + λ sup kd L sup kd (7) \mathcal{L}'_{\text{sup}} = L_{\text{sup}} + \lambda^{\text{kd}}_{\text{sup}} \mathcal{L}^{\text{kd}}_{\text{sup}} \tag{7} Lsup′=Lsup+λsupkdLsupkd(7)
其中, λ kd sup \lambda_{\text{kd}}^{\text{sup}} λkdsup 是一个超参数,用于控制 L kd sup \mathcal{L}_{\text{kd}}^{\text{sup}} Lkdsup 的强度。
- ILOD (Shmelkov et al. 2017) 最初对 f roi f_{\text{roi}} froi进行了知识蒸馏,使用 L2 距离量化;
- Faster ILOD (Peng et al. 2020) 进一步扩展到 Faster R-CNN,分别使用 L1 和 L2 距离量化 f b f_b fb和 f rpn f_{\text{rpn}} frpn。
- 其他方法也根据不同目标检测器的架构和输出设计了知识蒸馏损失 (Peng et al. 2021; Li et al. 2019; Feng et al. 2022; Zhang et al. 2020)。
由于旧类别和新类别的对象实例通常会共存, L kd sup L_{\text{kd}}^{\text{sup}} Lkdsup 和 L sup L_{\text{sup}} Lsup 允许在它们之间进行显式的平衡2。
SSIOD
知识蒸馏损失在未标注数据 D t u \mathcal{D}^u_t Dtu上的适应定义为:
L kd unsup = 1 N t u ∑ n = 1 N u t d [ f stu ( x t , n u ) , f old ( x t , n u ) ] (8) \mathcal{L}_{\text{kd}}^{\text{unsup}} = \frac{1}{N^u_t} \sum_{n=1}^{N_u^t} d[f_{\text{stu}}(x^u_{t,n}), f_{\text{old}}(x^u_{t,n})] \tag{8} Lkdunsup=Ntu1n=1∑Nutd[fstu(xt,nu),fold(xt,nu)](8)
相应地,无监督损失的综合定义为:
L unsup ′ = L unsup + λ unsup kd L unsup kd (9) \mathcal{L}'_{\text{unsup}} = \mathcal{L}_{\text{unsup}} + \lambda^{\text{kd}}_{\text{unsup}} \mathcal{L}^{\text{kd}}_{\text{unsup}} \tag{9} Lunsup′=Lunsup+λunsupkdLunsupkd(9)
其中, λ unsup kd \lambda^{\text{kd}}_{\text{unsup}} λunsupkd 是一个超参数,用于控制 L unsup kd \mathcal{L}^{\text{kd}}_{\text{unsup}} Lunsupkd的强度,从而平衡旧类别和新类别的学习。
The optimization of the student model f s t u \ f_{stu} fstu in Eq. 3 becomes
θ stu ← θ stu + α stu ∂ ( L sup ′ + λ unsup L unsup ′ ) ∂ θ stu (10) \theta_{\text{stu}} \leftarrow \theta_{\text{stu}} + \alpha_{\text{stu}} \frac{\partial ( \mathcal{L}'_{\text{sup}} + \lambda_{\text{unsup}} \mathcal{L}'_{\text{unsup}})}{\partial \theta_{\text{stu}}} \tag{10} θstu←θstu+αstu∂θstu∂(Lsup′+λunsupLunsup′)(10)
实际上,无监督蒸馏和有监督蒸馏在更新学生模型时的损失计算以及损失起到的功能是极为相似的,那么,KD在SSIOD中的实现可以分为三个方向:
- 使用 L kd sup L_{\text{kd}}^{\text{sup}} Lkdsup对 f tea f_{\text{tea}} ftea, f tea + KD f_{\text{tea}} + \text{KD} ftea+KD
- 使用 L kd sup L_{\text{kd}}^{\text{sup}} Lkdsup和 L kd unsup L_{\text{kd}}^{\text{unsup}} Lkdunsup对 f stu f_{\text{stu}} fstu, f stu + KD f_{\text{stu}} + \text{KD} fstu+KD
- 同时使用 L kd sup L_{\text{kd}}^{\text{sup}} Lkdsup和 L kd unsup L_{\text{kd}}^{\text{unsup}} Lkdunsup, Both + KD \text{Both + KD} Both + KD
方法
问题
- 尽管在监督下的增量目标检测(IOD)中表现良好,但常用的知识蒸馏(KD)策略在 SSIOD 中表现不佳。
- 我们在 MS-COCO 数据集(Lin et al. 2014)上进行了不同标注比例和任务拆分的实验。如图 4 所示,使用 KD 的三种可能方式仅在性能上有所提升或甚至导致性能下降,相比之下,顺序训练虽然存在严重的灾难性遗忘问题,但表现更为稳定。
- 特别是,当处理更多增量阶段时,KD 的表现趋向于更差,进一步限制了其适应现实世界变化的能力。针对 SSIOD 的特定挑战,我们进行了更深入的分析,并在下文中提出了我们的改进方法。

先说问题:
文中定义了这么一个问题,叫做错误积累
错位积累来源于模型在可塑性与稳定性上的冲突,这种冲突具体表现在
- 稳定性: 旧教师模型在识别旧类别方面表现良好,但无法适应新类别。
- 可塑性: 新教师模型适应新类别,但可能忽视旧类别。这种不重叠的标注问题暴露在处理增量未标注数据时。
当学生网络
f
s
t
u
\ f_{stu}
fstu通过二者给出的伪标签训练时,二者在预测上产生的冲突,通过学生网络的学习更新会传导到下一次训练,这种错误被更新到教师网络中带来更大的偏差,这种差异引发的错误会在半监督学习的训练过程种逐步积累,带来性能下降。
而这种稳定性和可塑性之间冲突的来源又在于增量标注数据的限制——源于增量标记数据
D
t
l
D^l_t
Dtl中的不重叠注释,并在处理增量未标记数据
D
t
u
D^u_t
Dtu时暴露出来。
针对这
- 这里提一下个人看到这反应过来的一个点,就是这个增量标记数据与增量未标记数据,是同时包含旧类别和新类别的。到这里思路就清晰了
- 文章大体的思路是:模型在处理任务 t t t时,只针对新任务的新类别做了标记,在burn in阶段通过蒸馏训练出了针对新类别敏感的教师网络,而对旧类别敏感的老网络作为第二个教师网络,也就形成了DualTeacher中两个教师网络。
The particular dilemma between stability and plasticity stems from the non-overlapping annotations in incremental labelled data D t l D^l_t Dtl , and is exposed in processing incremental unlabelled data D t u D^u_t Dtu . Although the object instances of old and new classes usually coexist, only the currently learned classes are annotated and the other classes are left as the “background”. As a result, the old teacher fold is optimized for recognizing old classes and ignoring potential new classes, while the new teacher ftea is optimized for recognizing new classes and ignoring potential old classes (see Fig. 2, b, c). This property causes their predictions to conflict with each other when updating the student fstu with unlabelled data, but also prevents low-quality predictions of uncertain classes. A desirable model should recognize the object instances of all classes ever seen, which in this case corresponds to the concatenation of predictions specific to each task or incremental phase (see Fig. 2, a, d).

解决办法——DualTeacher

- 伪标签生成
- 将教师网络和旧网络的预测结果结合,生成伪标签 y ^ t , n d t \hat{y}^{dt}_{t,n} y^t,ndt
y ^ t , n d t = f old ( x t , n u ) ∪ f tea ( x t , n u ) (11) \hat{y}^{dt}_{t,n} = f_{\text{old}}(x^u_{t,n}) \cup f_{\text{tea}}(x^u_{t,n}) \tag{11} y^t,ndt=fold(xt,nu)∪ftea(xt,nu)(11)
- 无监督损失 L unsup \mathcal{L}_{\text{unsup}} Lunsup
L unsup d t = 1 N t u ∑ n = 1 N t u [ L cls rpn ( x t , n u , y ^ t , n d t ) + L cls roi ( x t , n u , y ^ t , n d t ) ] (12) \mathcal{L}^{dt}_{\text{unsup}} = \frac{1}{N^u_t} \sum_{n=1}^{N^u_t} \left[ \mathcal{L}_{\text{cls}}^{\text{rpn}}(x^u_{t,n}, \hat{y}^{dt}_{t,n}) + \mathcal{L}_{\text{cls}}^{\text{roi}}(x^u_{t,n}, \hat{y}^{dt}_{t,n}) \right] \tag{12} Lunsupdt=Ntu1n=1∑Ntu[Lclsrpn(xt,nu,y^t,ndt)+Lclsroi(xt,nu,y^t,ndt)](12)
- 学生网络 θ stu \theta_{\text{stu}} θstu的优化
θ stu ← θ stu + α stu ∂ ( L sup + λ unsup L unsup d t ) ∂ θ stu (13) \theta_{\text{stu}} \leftarrow \theta_{\text{stu}} + \alpha_{\text{stu}} \frac{\partial (L_{\text{sup}} + \lambda_{\text{unsup}} L^{dt}_{\text{unsup}})}{\partial \theta_{\text{stu}}} \tag{13} θstu←θstu+αstu∂θstu∂(Lsup+λunsupLunsupdt)(13)
重要设计要点
- 教师网络的冻结:
- 在更新学生网络
f
s
t
u
\ f_{stu}
fstu时,旧教师
f
o
l
d
\ f_{old}
fold和新教师
f
t
e
a
\ f_{tea}
ftea都是冻结的,即它们的参数不再改变。
更新结束后,新教师通过指数滑动平均(EMA,见公式5)逐渐更新。
- 在更新学生网络
f
s
t
u
\ f_{stu}
fstu时,旧教师
f
o
l
d
\ f_{old}
fold和新教师
f
t
e
a
\ f_{tea}
ftea都是冻结的,即它们的参数不再改变。
- 进步性的知识获取:
- 通过此过程,学生网络能够获得正确且兼容的监督,逐步提高其处理未标记数据的能力。同时,新教师网络也逐步获得识别新旧类别的知识。
- 无需额外超参数:
- 该方法没有引入额外的超参数,这对增量学习中的实现非常关键,因为在增量学习场景下,超参数的常规搜索可能无法实现3。
实验
实验设置
benchmark
实验数据集使用的是MS-COCO数据集,包含80的实例,共118287训练图像和5000测试图像。
Following the protocol of supervised IOD (Shmelkov, Schmid, and Alahari 2017; Peng, Zhao, and Lovell 2020), we split them into multiple incremental phases, with the training images for each phase containing only the annotations of new classes. For SSIOD, we only use a small fraction of labelled data and leave the rest unlabelled. In other words, only a few images have annotations of new classes rather than old classes, while the others have no annotations (see Fig. 1). In experiments, we analyze the impact of labelling ratios (e.g., 1% or 5%) (Liu et al2021) and task splits (e.g., 40-40 or 60-20) (Feng, Wang, and Yuan 2022) under the settings of 5- and 2-phase, respectively
遵循监督IOD协议(Shmelkov, Schmid, and Alahari 2017;Peng, Zhao, and Lovell 2020),我们将它们分成多个增量阶段,每个阶段的训练图像仅包含新类的注释。对于SSIOD,我们只使用一小部分标记数据,其余的不标记。换句话说,只有少数图像有新类别的注释,而不是旧类别的注释,而其他图像没有注释(见图1)。在实验中,我们分析了标记比率(例如1%或5%)的影响(Liu et al .)2021)和任务划分(例如,40-40或60-20)(Feng, Wang, and Yuan 2022)分别在五阶段和两阶段的设置下
文中提到的标准,2017年的论文我恰好看过,也写了论文学习笔记
Implementation-实现
文章选择的是Ubiased Teacher作为半监督学习的默认方法,它具有代表性并且易于适用于其他SSL技术。
Evaluation Metric-评估指标
We report the average precision (AP) with a wide range of IoU thresholds as the evaluation metric. Specifically, AP, AP50 and AP75 apply the IoU threshold of 0.50 to 0.95, 0.50 and 0.75, respectively. APS, APM and APL calculate AP for object instances with different pixel areas, corresponding to smaller than 3 2 2 32^2 322 , 3 2 2 32^2 322 to 9 6 2 96^2 962 and larger than 9 6 2 96^2 962 , respectively.
Baseline
- 以顺序训练方式为带有严重灾难性遗忘的持续学习的下界
- 又考虑了两种IOD代表性方式如ILOD (Shmelkov, Schmid, and Alahari 2017)和Faster ILOD (Peng, Zhao, and Lovell 2020)。
- ILOD对两级目标检测器的分类和回归的最终输出进行了正则化。
- Faster ILOD是专门为更快的R-CNN设计的,并对中间输出的差异进行了正则化。
- 又进一步评估了重放标记数据的效果(图像分类任务的半监督持续学习的有效策略)
Overall Performance 超参数
当前一些流行的监督式增量目标检测方法,通过超参数搜索进行性能优化。但对于SSIOD任务,典型IOD方法的知识蒸馏就不适当了,反而可能导致性能下降或无改善。
实验验证与超参数调整:
- 研究首先通过构建一个仅包含标注数据的任务序列(相当于监督式增量学习),验证这些方法在其预期设计中是否能够提升性能。这是为了确保实验设置是合理的,避免在不恰当条件下得出负面结论。
- 随后,研究在SSIOD的实验中使用了针对所有方法选择的最佳超参数。
在增量学习场景下,常规的超参数搜索方法并不总是可行的,因为这些方法通常需要大量资源进行多次实验。而DualTeacher模型通过避免引入额外的超参数,使得它更适合实际的应用场景,减少了复杂度和实现难度。
Overall Performance 总体性能
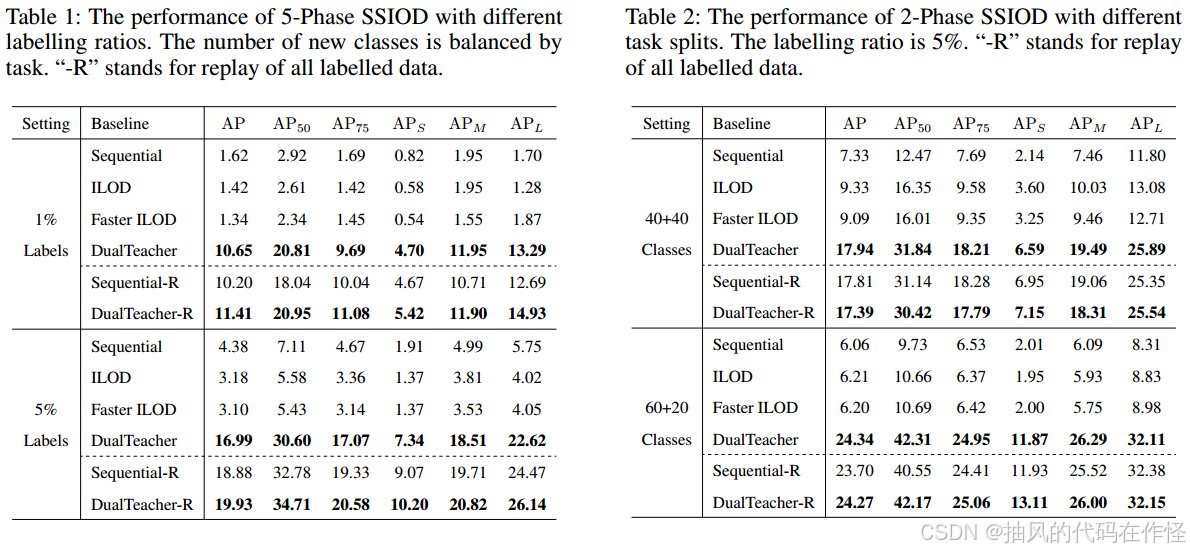
如表1和表2所示,我们的DualTeacher在5阶段和2阶段SSIOD设置中都显示出显著的性能领先(高达18.28 AP)。具体来说,具有代表性的IOD方法(例如ILOD和Faster ILOD)仅略微提高甚至干扰顺序训练的性能,其中仅在2阶段设置中出现改善,并且在40+40类设置中变得更小。结果显示随着新类别的增加,在SSIOD中使用知识蒸馏将产生越来越多的负面影响。相比之下,我们的DualTeacher在不同的标签比率和任务划分下始终提供强劲的性能提升。我们进一步探讨了体验回放的效果。与图像分类的结果一致(Wang et al . 2021a),所有标记数据的回放对于半监督场景下的持续/增量学习确实非常有效。由于所有已标记的数据都已被重新访问,因此SSIOD问题将克服增量数据中未标记部分的灾难性遗忘。在这个策略的顶端,我们的DualTeacher仍然可以明显提高性能,验证其动机。此外,Unbiased Teacher (Liu et al . 2021)在1%标签和5%标签下的半监督学习性能(即部分标记数据的联合训练)分别为20.75 AP和28.27 AP。我们期望SSIOD的后续工作能够进一步缩小性能差距。
Detailed Analysis 详细分析
Detailed Analysis: As our DualTeacher only introduces the old teacher’s predictions to generate pseudo-labels, the performance improvement over sequential training has provided an explicit ablation study. Below, we analyze its advantages more extensively. First, we present the subsequent performance of the first-phase classes to evaluate the extent of catastrophic forgetting. As shown in Fig. 5, sequential training, ILOD and Faster ILOD all suffer from severe catastrophic forgetting, where the performance of old classes drops to almost zero in subsequent learning phases. Our DualTeacher can largely alleviate catastrophic forgetting, with the performance of old classes decaying slowly. Second, we evaluate the resource overhead in terms of storage and computation. The storage overhead of all methods is equivalent to that of the object detector itself. Meanwhile, our DualTeacher creates smaller computational overheads than ILOD and Faster ILOD (see Fig. 6) but achieves significantly better performance in SSIOD. Together with the advantages in hyperparameters, our DualTeacher is both effective and practical for incremental learning of object detectors.
这段就是再说,DualTeacher通过引入旧教师预测来生成伪标签,有效地减轻了灾难性遗忘,同时在存储和计算开销方面优于ILOD和Faster ILOD。这种方法在不增加额外超参数的前提下,表现出有效性和实用性,为增量学习中的目标检测提供了一个强有力的解决方案。
结论
In this work, we present semi-supervised incremental object detection (SSIOD) as a realistic setting for incremental learning of object detectors. In contrast to supervised incremental object detection, the coexistence of old and new classes in massive unlabelled data becomes a particular challenge, which severely affects the effectiveness of widely-used knowledge distillation strategies. To overcome this challenging issue, we leverage the property of nonoverlapping annotations and the resulting exclusivity of predictions in incremental learning, concatenating as pseudolabels the predictions of two teachers dedicated for old and new classes, respectively. Extensive experiments demonstrate the validity and practicality of our approach. We expect this work to provide a new perspective as well as a strong baseline for incremental learning of object detectors in real-world applications. Subsequent work could further explore the effective usage of limited supervision and massive unlabelled data of dynamic distributions.
- 与传统的监督增量对象检测不同,SSIOD面对的是大量未标记数据中新旧类别共存的情况,这带来了特别的挑战。这一问题严重影响了当前广泛使用的知识蒸馏策略的有效性。
- 本文的方法是将分别针对旧类和新类的两个教师模型的预测结果连接为伪标签,用于指导学生模型的学习。这种双教师策略有效解决了增量学习中的知识冲突问题。
实现细节
- 任务划分 (Task Split):
数据集:使用的是MS-COCO数据集,包含80个类别的目标实例。
实验任务分为三种不同的任务划分方式:- 5阶段 (5-phase):将80类划分为5个子集,每个子集16类。
- 2阶段 (40+40 classes):将80类划分为两个子集,每个子集40类。
- 2阶段 (60+20 classes):将80类划分为两个子集,一个子集60类,另一个子集20类。
- 实现细节 (Implementation):
- 框架:工作是在Unbiased Teacher框架下实现的,这是一种代表性的半监督学习方法,用于目标检测。
- 网络结构:使用了与Unbiased Teacher类似的Faster R-CNN架构,主干网络为ResNet-50,初始化自ImageNet预训练模型。
- 数据增强:
- 弱增强:随机水平翻转。
- 强增强:颜色抖动、灰度、Gaussian模糊和遮挡块(cutout patches)。
- 优化器:使用SGD优化器,学习率为0.01,动量为0.9。
- 批量大小:有标签和无标签数据的批量大小均设置为16。
- 训练流程:首先执行burn-in阶段,持续2k次迭代,然后进入教师-学生的互学习阶段。总共训练180k次迭代,按任务的训练集大小分配迭代次数。
- 超参数 (Hyperparameters):
半监督学习的超参数与Unbiased Teacher的官方实现一致。
伪标签过滤:根据网络输出的分数过滤新教师和老教师的伪标签,只有分数大于0.7的伪标签才会用于训练学生模型。
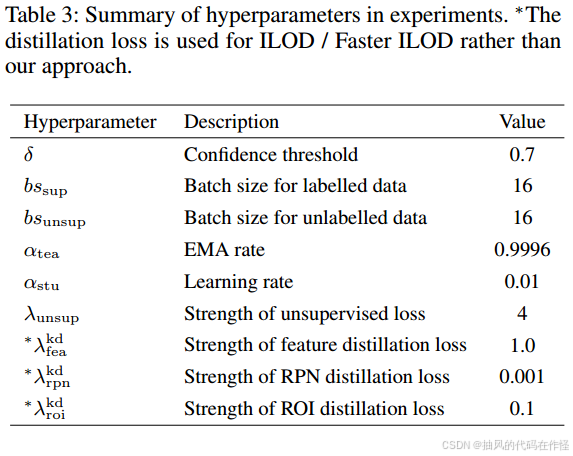
本方法没有引入额外的超参数,避免了对超参数的搜索。
4. 实验环境 (Environment):
实验环境使用的是4个Tesla V100-SXM2-32GB GPU,操作系统为CentOS 7,CUDA版本为9.2,PyTorch版本为1.7.0,Detectron2版本为0.5。
由于半监督学习的计算开销较大,报告的性能是基于每个任务序列运行一次的结果。
这些细节确保了实验的可复现性,并强调了在该特定实验框架下的设置。
扩展结果

上图为只使用1%和5%的标记数据进行增量学习的结果,其中有代表性的知识蒸馏方法比顺序训练取得了很大的改进。
SSIOD在不同平均精度指标下的表现(下图)

总结
文章里面有些东西,还没理解透,就先简单说说吧:
-
文章的网络设计中的实际环境,是我有一个训练好的网络,相同的任务环境下出现了新类别(new class),我需要我的模型适应这些新类别,同时,旧任务下的已有类别(old class)也需要进行目标检测,同时,我还不想花费太高的成本来进行新类别的标注
面对上面这些前提,我们大致能想到两点:- 增量学习:因为要增加新类别嘛,对抗灾难性遗忘的同时学习新类别,一般就会想到用蒸馏来实现增量了
- 半监督学习:因为想节省成本嘛,肯定是标注的越少越好嘛,半监督这种方式最贴合我们的需求了
-
首先文中使用的半监督的模式需要一个学生网络和教师网络,这里使用有标签的数据训练出一个初始模型,这一步就叫"burn in"阶段,然后使用这个模型的参数初始化两个模型,也就是学生模型和教师模型。
-
然后呢,需要引入旧模型的知识来保证对旧类别的检测能力,那就用蒸馏的方式吧
-
问题就出现了,旧模型和新模型对于同一个未标注的输入的预测有冲突,这种冲突会影响到学生网络的训练更新,而半监督训练的特点就在于教师网络会通过EMA更新,好了,这种冲突不但没有消失,反而逐渐的被学生网络学习并被传播到了教师网络,致使这种冲突得以保留甚至加剧,这就是文中提到的稳定性和可塑性的冲突
-
这里也就引出了文章中的DualTeacher,通过将两个模型的输出桥接,将新模型输出的新类别和老模型输出的旧类别共同作为学生网络的伪标签训练,使得学生网络总是向更确信的方向靠近。这个桥接将两模型的输出取并集完成的。
在RNN中,"burn-in"过程是指在开始学习之前先通过网络运行一段时间的序列数据,使得RNN的隐藏状态有机会收敛到某种有意义的状态。这样,当我们开始学习时,RNN的隐藏状态就已经包含了一些有用的历史信息,而不仅仅是初始的零状态。这种方法尤其对处理长序列的任务有帮助,因为这些任务可能需要网络记住距离当前时刻较远的历史信息。 ↩︎
显式的平衡意味着在训练过程中,通过明确调整损失函数的权重来平衡模型对不同任务或目标的关注。这种调整是通过设置和优化超参数来实现的,从而确保模型在学习过程中的不同目标能够得到适当的考虑和优化. ↩︎
在增量学习场景中,常规的超参数搜索方法(如网格搜索、随机搜索)可能不适用,因为这些方法通常假设可以反复训练和评估模型。然而,增量学习需要模型能够快速适应新任务,同时保留旧任务的知识,导致超参数难以动态调整或优化。 ↩︎

















 601
601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









