






手写体数字识别是计算机视觉中最常用的图像分类任务,让计算机识别出给定图片中的手写体数字(0-9共10个数字)。由于手写体风格差异很大,因此手写体数字识别是具有一定难度的任务。
我们采用常用的手写数字识别数据集:MNIST数据集。
MNIST数据集是计算机视觉领域的经典入门数据集,包含了60,000个训练样本和10,000个测试样本。
这些数字已经过尺寸标准化并位于图像中心,图像是固定大小(28×28像素)。
5.3 基于LeNet实现手写体数字识别实验
LeNet-5虽然提出的时间比较早,但它是一个非常成功的神经网络模型。
基于LeNet-5的手写数字识别系统在20世纪90年代被美国很多银行使用,用来识别支票上面的手写数字。
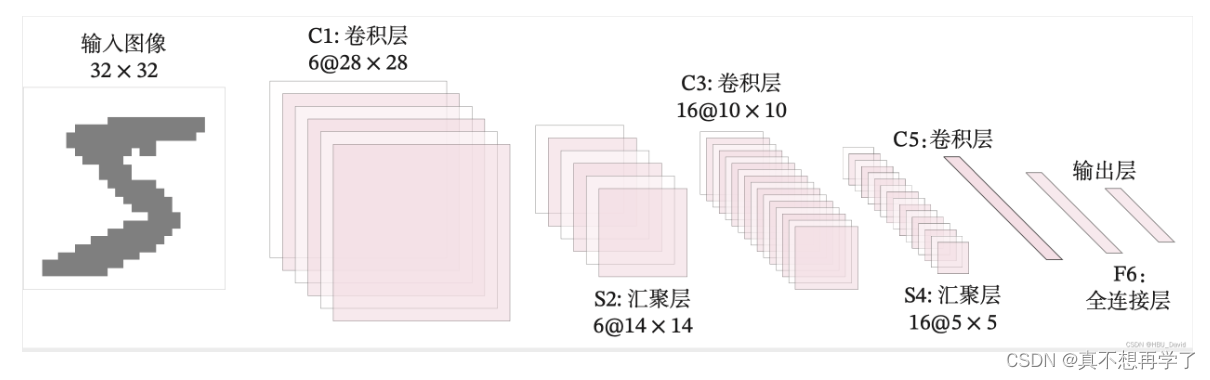
5.3.2 模型构建
这里的LeNet-5和原始版本有4点不同:
C3层没有使用连接表来减少卷积数量。
汇聚层使用了简单的平均汇聚,没有引入权重和偏置参数以及非线性激活函数。
卷积层的激活函数使用ReLU函数。
最后的输出层为一个全连接线性层。
网络共有7层,包含3个卷积层、2个汇聚层以及2个全连接层的简单卷积神经网络接,受输入图像大小为32×32=1024,输出对应10个类别的得分。
1.测试LeNet-5模型,构造一个形状为 [1,1,32,32]的输入数据送入网络,观察每一层特征图的形状变化。
2.使用自定义算子,构建LeNet-5模型
自定义的Conv2D和Pool2D算子中包含多个for循环,所以运算速度比较慢。
飞桨框架中,针对卷积层算子和汇聚层算子进行了速度上的优化,这里基于paddle.nn.Conv2D、paddle.nn.MaxPool2D和paddle.nn.AvgPool2D构建LeNet-5模型,对比与上边实现的模型的运算速度。
使用pytorch中的相应算子,构建LeNet-5模型
torch.nn.Conv2d();torch.nn.MaxPool2d();torch.nn.avg_pool2d()
3.测试两个网络的运算速度。
4.令两个网络加载同样的权重,测试一下两个网络的输出结果是否一致。
5.统计LeNet-5模型的参数量和计算量。
在飞桨中,还可以使用paddle.flopsAPI自动统计计算量。pytorch可以么?
5.3.3 模型训练
使用交叉熵损失函数,并用随机梯度下降法作为优化器来训练LeNet-5网络。
用RunnerV3在训练集上训练5个epoch,并保存准确率最高的模型作为最佳模型。
5.3.4 模型评价
使用测试数据对在训练过程中保存的最佳模型进行评价,观察模型在测试集上的准确率以及损失变化情况。
5.3.5 模型预测
同样地,我们也可以使用保存好的模型,对测试集中的某一个数据进行模型预测,观察模型效果。
实验过程:
首先为了能实现反向传播,将之前基于numpy的卷积类中的参数从array数组转换为tensor对象。
别让我从最后一层一步步链式求导到第一层,那实在是太麻烦、太复杂了,正常人都不会这么干。这也体现出了自动求导的优势。
#coding:utf-8
import json
import math
import numpy as np
import torch
import torchvision
from matplotlib import pyplot as plt
from torchvision import transforms
class myMultipassageConv():
def __init__(self,in_chanels,out_chanels,kernel_size,padding,stride=(1,1),padding_str='zeros',use_bias=True,use_redundancy=False):
'''
:param in_chanels: 输入通道数
:param out_chanels: 输出通道数
:param kernel_size: 卷积核尺寸 tuple类型
:param padding: 边缘填充数
:param stride: 步长 tuple类型 (可选)默认为(1,1)
:param padding_str: 边缘填充方式 str类型(可选)
:param use_bias: 是否使用偏置 bool类型(可选)
use_redundancy:是否使用冗余值 bool 默认舍弃
'''
self.kernel_size=kernel_size
self.in_chanels=in_chanels
self.out_chanels=out_chanels
self.padding=padding
self.stride=stride
(self.kernel_hight,self.kernel_width)=kernel_size
self.weights,self.bias=self.__parameters()
self.padding_str=padding_str
self.use_bias=use_bias
self.use_redundancy=use_redundancy
def __parameters(self):
'''内部函数,默认标准正态分布初始化参数'''
'''权重尺寸为in_chanels*out_chanels*kernelsize'''
weights=torch.randn(self.out_chanels,self.in_chanels,self.kernel_hight,self.kernel_width,requires_grad=True)
'''偏置尺寸为out_kernels'''
bias=torch.randn(self.out_chanels,1,requires_grad=True)
return weights,bias
def forward(self,x):
'''前向计算'''
'''输入格式(batch_size,chanels,hight,width)'''
output =[]
(batch_size, chanels, hight, width)=x.shape
for batch_num in range(batch_size):
img_chanel=x[batch_num,:,:,:]
print('img_chanel:\n',img_chanel)
out_chanel=[]
for out_kernel_num in range(self.weights.shape[0]):
'''各个输出通道对应的权重'''
kernels=self.weights[out_kernel_num,:,:,:]
for_sum = []
for chanel_img_num in range(chanels):
'''对应项进行卷积'''
kernel = kernels[chanel_img_num, :, :]
_img=img_chanel[chanel_img_num,:,:]
print('current input_img:\n', _img)
print('current kernel:\n',kernel)
if self.padding>0:
_img = self.__paddingzeros(_img)#边缘填充
print('padded img:\n',_img)
out_img,out_shape=self.__myConv(_img,kernel)
for_sum.append(out_img.tolist())
print('unsumed out img:\n',for_sum)
sumed_out_img=np.array(for_sum).sum(axis=0)
print('sumed out_img:\n',sumed_out_img)
if self.use_bias:
sumed_out_img+=self.bias[out_kernel_num].detach().numpy()
out_chanel.append(sumed_out_img.tolist())
print('out chanel:',out_chanel)
output.append(out_chanel)
'''计算输出图像的尺寸 '''
'''img=x[0,0,:,:]
if self.padding>0:
img = self.__paddingzeros(img) # 边缘填充
kernel=self.weights[0,0,:,:]
_,out_shape=self.__myConv(img,kernel)'''
output=torch.Tensor(np.array(output).astype(np.float32))
print('final output:\n', output)
return output
def __paddingzeros(self,img):
'''内部函数,默认 边缘0填充'''
if self.padding_str=='zeros':
out=torch.zeros((img.shape[0]+self.padding*2,img.shape[1]+self.padding*2))
out[self.padding:-self.padding,self.padding:-self.padding]=img
return out
elif self.padding_str=='ones':
out=torch.ones((img.shape[0]+self.padding*2,img.shape[1]+self.padding*2))
out[self.padding:-self.padding,self.padding:-self.padding]=img
return out
else:
raise ValueError('Value error: unexcepted key value of \'padding\'. excepted key values:zeros,ones')
def __myConv(self,img, kernel):#单层单核卷积
'''内部参数,用于计算单图像单核卷积'''
if (self.stride==(1,1))&(self.kernel_size==(3,3)):
k1 = int((kernel.shape[0] - 1) / 2)
k2 = int((kernel.shape[1] - 1) / 2)
out_img = []
for i in range(k1, img.shape[0] - k1):
for j in range(k2, img.shape[1] - k2):
sight = img[i - 1:i + 2, j - 1:j + 2]
out_img.append(np.sum(np.multiply(np.array(sight), np.array(kernel))))
return torch.from_numpy(np.array(out_img).astype(np.float32).reshape((img.shape[0] - 2 * k1, img.shape[1] - 2 * k2))),(img.shape[0] - 2 * k1, img.shape[1] - 2 * k2)
else:
k1 = int((kernel.shape[0] - 1) / 2)
k2 = int((kernel.shape[1] - 1) / 2)
#print('k1,k2=',k1,k2)
#print('stride:',self.stride)
out_img = []
right_line=[]
bottom_line=[]
botton_right=[]
#print('img.shape:',img.shape)
for x_index,i in enumerate(range(k1, img.shape[0] - k1)):
if x_index%self.stride[1]==0:#纵向移动
for y_index,j in enumerate(range(k2, img.shape[1] - k2)):
if y_index%self.stride[0]==0:#横向移动
#print('current i j', i, j)
sight = img[i - k1:i + k2+1, j - k1:j + k2+1]
#print(sight)
#print(kernel)
out_img.append(np.sum(np.multiply(np.array(sight), kernel.detach().numpy())))
#print('out img:',out_img)
''' 这里考虑到步长大于1时卷积到右侧边缘或下侧会有边缘不足的情况,因此尝试对边界的溢出进行检测与处理 '''
'''处理边界冗余值'''
if (j+self.stride[0]+k1)>(img.shape[1]-1):
#print('列索引',(j+self.stride[0]+k1),'>',(img.shape[1]-k1))
#print('检测到达右边界,向右移动并填充后几列')
_j=j+self.stride[0]
redundancy=img[i - k1:i + k2+1,_j - k1:]
split_kernel = kernel[:, :np.array(redundancy).shape[1]]
#print(redundancy)
#print(split_kernel)
right_line.append(np.sum(np.multiply(np.array(redundancy), split_kernel.detach().numpy())))
#print( 'right line',right_line)
if (i+self.stride[1]+k2)>(img.shape[0]-1):
#print('行索引',(i+self.stride[1]),'>',(img.shape[0]-1))
#print('检测到达下边界,向下移动并填充下几行')
'''达下边界,向下移动并分别获取冗余值以及分割的卷积核,在对两者计算点积和,其他几种也是这种方法'''
_i=i+self.stride[1]
redundancy=img[_i - k2:, j - k1:j + k2+1]
split_kernel=kernel[:np.array(redundancy).shape[0], :]
#print(redundancy)
#print(split_kernel)
bottom_line.append(np.sum(np.multiply(np.array(redundancy), split_kernel.detach().numpy())))
#print('bottopn line:',bottom_line)
if ((j+self.stride[0]+k1)>(img.shape[1]-1))&((i+self.stride[1]+k2)>(img.shape[0]-1)):
#print('达右下角,向右下移动并填充')
_i+=self.stride[0]
_j+=self.stride[1]
redundancy = img[_i - k2:, _j - k1:]
split_kernel = kernel[:np.array(redundancy).shape[0], :np.array(redundancy).shape[1]]
#print(redundancy)
#print(split_kernel)
botton_right.append(np.sum(np.multiply(np.array(redundancy),split_kernel.detach().numpy())))
out_shape=[0,0]
for i in range( img.shape[0] - 2*k1):
if i%self.stride[1]==0:
out_shape[0]+=1
for i in range( img.shape[1] - 2*k2):
if i %self.stride[0]==0:
out_shape[1]+=1
#print(out_shape)
if self.use_redundancy:
base_img=np.array(out_img).reshape(out_shape)
#print(base_img)
#print(right_line)
#print(bottom_line)
#print(botton_right)
return self.__Conbine(base_img,right_line,bottom_line,botton_right),self.__Conbine(base_img,right_line,bottom_line,botton_right).shape
else:
return torch.Tensor(np.array(out_img).astype(np.float32).reshape(out_shape)), out_shape
def __Conbine(self,baseimg,rightline,bottomline,rightbottom):
'''内置函数,用于将冗余值信息与基本信息组合到一起'''
br=np.append(np.array(baseimg),np.array(rightline).reshape(len(rightline),1),axis=1)
#print(br)
bbr=np.append(np.array(bottomline),np.array(rightbottom))
bbrr=bbr.reshape(1,len(bbr))
#print(bbr)
#print(bbrr)
return torch.from_numpy(np.append(br,bbrr,axis=0).astype(np.float32))
def get_parameters(self):
return self.weights,self.bias
def set_parameters(self,weights,bias):
self.weights, self.bias=weights,bias
def set_weights(self,weights):
self.weights=weights
def set_bias(self,bias):
self.bias=bias
def show_img(img):
plt.figure()
plt.imshow(img, cmap='gray')
plt.show()
def crossentropy_loss():
return torch.nn.CrossEntropyLoss()
if __name__=='__main__':
# 数据预处理
transform = transforms.Compose([transforms.ToTensor()])
# 下载mnist库数据并定义读取器
train_dataset = torchvision.datasets.MNIST(root='./mnist', train=True, transform=transform, download=True)
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=5000, shuffle=True, num_workers=6)
test_dataset = torchvision.datasets.MNIST(root='./mnist', train=False, transform=transform, download=True)
test_dataloader = torch.utils.data.DataLoader(test_dataset, batch_size=10000, shuffle=True, num_workers=0)
img = np.array([[
[
[0, 1, 1, 0, 2],
[2, 2, 2, 2, 1],
[1, 0, 0, 2, 0],
[0, 1, 1, 0, 0],
[1, 2, 0, 0, 2]
],
[
[1, 0, 2, 2, 0],
[0, 0, 0, 2, 0],
[1, 2, 1, 2, 1],
[1, 0, 0, 0, 0],
[1, 2, 1, 1, 1]
],
[
[2, 1, 2, 0, 0],
[1, 0, 0, 1, 0],
[0, 2, 1, 0, 1],
[0, 1, 2, 2, 2],
[2, 1, 0, 0, 1]
]]
])
kernel_weights = torch.Tensor([[
[
[-1, 1, 0],
[0, 1, 0],
[0, 1, 1]
],
[
[-1, -1, 0],
[0, 0, 0],
[0, -1, 0]
],
[
[0, 0, -1],
[0, 1, 0],
[1, -1, -1]
]
],
[
[
[1, 1, -1],
[-1, -1, 1],
[0, -1, 1]
],
[
[0, 1, 0],
[-1, 0, -1],
[-1, 1, 0]
],
[
[-1, 0, 0],
[-1, 0, 1],
[-1, 0, 0]
]
]])
bias = torch.Tensor([[1], [0]])
target_feature = torch.Tensor([
[
[
[3., 7., 5.],
[4., -1., -1.],
[2., -6., 4.]
],
[[2., -7., -8.],
[1., -2., -4.],
[9., -7., -5.]
]
]
])
kernel_weights.requires_grad=True
bias.requires_grad=True
print('input img shape:',img.shape)
print('kernel shape',kernel_weights.shape)
myconv = myMultipassageConv(3, 2, kernel_size=(3,3), padding=1, stride=(2,2), use_bias=True,
use_redundancy=False,padding_str='zeros')
myconv.set_weights(kernel_weights)
myconv.set_bias(bias)
output=myconv.forward(torch.Tensor(img.astype(np.float32)))
print('output shape:\n',output.shape)
loss=crossentropy_loss()
l=loss(target_feature,output)
l.requires_grad=True
l.backward()
print('output shape:\n',output.shape)
print(kernel_weights.grad)
将参数设置requires_grad=True,调用backward(),但是发现,输出的grad结果为none,原因可能是因为自定义卷积类中的很多关键地方的计算还是靠numpy来实现的,接下来将其改掉,全用tensor来实现。
#coding:utf-8
import json
import math
import numpy as np
import torch
import torchvision
from matplotlib import pyplot as plt
from torchvision import transforms
class myMultipassageConv():
def __init__(self,in_chanels,out_chanels,kernel_size,padding,stride=(1,1),padding_str='zeros',use_bias=True,use_redundancy=False):
'''
:param in_chanels: 输入通道数
:param out_chanels: 输出通道数
:param kernel_size: 卷积核尺寸 tuple类型
:param padding: 边缘填充数
:param stride: 步长 tuple类型 (可选)默认为(1,1)
:param padding_str: 边缘填充方式 str类型(可选)
:param use_bias: 是否使用偏置 bool类型(可选)
use_redundancy:是否使用冗余值 bool 默认舍弃
'''
self.kernel_size=kernel_size
self.in_chanels=in_chanels
self.out_chanels=out_chanels
self.padding=padding
self.stride=stride
(self.kernel_hight,self.kernel_width)=kernel_size
self.weights,self.bias=self.__parameters()
self.padding_str=padding_str
self.use_bias=use_bias
self.use_redundancy=use_redundancy
def __parameters(self):
'''内部函数,默认标准正态分布初始化参数'''
'''权重尺寸为in_chanels*out_chanels*kernelsize'''
weights=torch.randn(self.out_chanels,self.in_chanels,self.kernel_hight,self.kernel_width,requires_grad=True)
'''偏置尺寸为out_kernels'''
bias=torch.randn(self.out_chanels,1,requires_grad=True)
return weights,bias
def forward(self,x):
'''前向计算'''
'''输入格式(batch_size,chanels,hight,width)'''
output =[]
(batch_size, chanels, hight, width)=x.shape
for batch_num in range(batch_size):
img_chanel=x[batch_num,:,:,:]
print('img_chanel:\n',img_chanel)
out_chanel=[]
for out_kernel_num in range(self.weights.shape[0]):
'''各个输出通道对应的权重'''
kernels=self.weights[out_kernel_num,:,:,:]
for_sum = []
for chanel_img_num in range(chanels):
'''对应项进行卷积'''
kernel = kernels[chanel_img_num, :, :]
_img=img_chanel[chanel_img_num,:,:]
print('current input_img:\n', _img)
print('current kernel:\n',kernel)
if self.padding>0:
_img = self.__paddingzeros(_img)#边缘填充
print('padded img:\n',_img)
out_img,out_shape=self.__myConv(_img,kernel)
for_sum.append(out_img)
print('unsumed out img:\n',for_sum)
for_sum=torch.stack(for_sum,0)
sumed_out_img=torch.sum(for_sum,dim=0)
print('sumed out_img:\n',sumed_out_img)
if self.use_bias:
sumed_out_img+=self.bias[out_kernel_num]
out_chanel.append(sumed_out_img)
print('out chanel:',out_chanel)
out_chanel=torch.stack(out_chanel)
output.append(out_chanel)
output=torch.stack(output,0)
'''计算输出图像的尺寸 '''
'''img=x[0,0,:,:]
if self.padding>0:
img = self.__paddingzeros(img) # 边缘填充
kernel=self.weights[0,0,:,:]
_,out_shape=self.__myConv(img,kernel)'''
print('final output:\n', output)
return output
def __paddingzeros(self,img):
'''内部函数,默认 边缘0填充'''
if self.padding_str=='zeros':
out=torch.zeros((img.shape[0]+self.padding*2,img.shape[1]+self.padding*2))
out[self.padding:-self.padding,self.padding:-self.padding]=img
return out
elif self.padding_str=='ones':
out=torch.ones((img.shape[0]+self.padding*2,img.shape[1]+self.padding*2))
out[self.padding:-self.padding,self.padding:-self.padding]=img
return out
else:
raise ValueError('Value error: unexcepted key value of \'padding\'. excepted key values:zeros,ones')
def __myConv(self,img, kernel):#单层单核卷积
'''内部参数,用于计算单图像单核卷积'''
k1 = int((kernel.shape[0] - 1) / 2)
k2 = int((kernel.shape[1] - 1) / 2)
#print('k1,k2=',k1,k2)
#print('stride:',self.stride)
out_img = []
right_line=[]
bottom_line=[]
botton_right=[]
#print('img.shape:',img.shape)
for x_index,i in enumerate(range(k1, img.shape[0] - k1)):
if x_index%self.stride[1]==0:#纵向移动
for y_index,j in enumerate(range(k2, img.shape[1] - k2)):
if y_index%self.stride[0]==0:#横向移动
#print('current i j', i, j)
sight = img[i - k1:i + k2+1, j - k1:j + k2+1]
#print(sight)
#print(kernel)
out_img.append(torch.sum(torch.mul(torch.Tensor(sight), kernel)))
#print('out img:',out_img)
''' 这里考虑到步长大于1时卷积到右侧边缘或下侧会有边缘不足的情况,因此尝试对边界的溢出进行检测与处理 '''
'''处理边界冗余值'''
if (j+self.stride[0]+k1)>(img.shape[1]-1):
#print('列索引',(j+self.stride[0]+k1),'>',(img.shape[1]-k1))
#print('检测到达右边界,向右移动并填充后几列')
_j=j+self.stride[0]
redundancy=img[i - k1:i + k2+1,_j - k1:]
split_kernel = kernel[:, :np.array(redundancy).shape[1]]
#print(redundancy)
#print(split_kernel)
right_line.append(torch.sum(torch.mul(torch.Tensor(redundancy), split_kernel)))
#print( 'right line',right_line)
if (i+self.stride[1]+k2)>(img.shape[0]-1):
#print('行索引',(i+self.stride[1]),'>',(img.shape[0]-1))
#print('检测到达下边界,向下移动并填充下几行')
'''达下边界,向下移动并分别获取冗余值以及分割的卷积核,在对两者计算点积和,其他几种也是这种方法'''
_i=i+self.stride[1]
redundancy=img[_i - k2:, j - k1:j + k2+1]
split_kernel=kernel[:np.array(redundancy).shape[0], :]
#print(redundancy)
#print(split_kernel)
bottom_line.append(torch.sum(torch.mul(torch.Tensor(redundancy), split_kernel)))
#print('bottopn line:',bottom_line)
if ((j+self.stride[0]+k1)>(img.shape[1]-1))&((i+self.stride[1]+k2)>(img.shape[0]-1)):
#print('达右下角,向右下移动并填充')
_i+=self.stride[0]
_j+=self.stride[1]
redundancy = img[_i - k2:, _j - k1:]
split_kernel = kernel[:np.array(redundancy).shape[0], :np.array(redundancy).shape[1]]
#print(redundancy)
#print(split_kernel)
botton_right.append(torch.sum(torch.mul(torch.Tensor(redundancy), split_kernel)))
out_shape=[0,0]
for i in range( img.shape[0] - 2*k1):
if i%self.stride[1]==0:
out_shape[0]+=1
for i in range( img.shape[1] - 2*k2):
if i %self.stride[0]==0:
out_shape[1]+=1
#print(out_shape)
if self.use_redundancy:
base_img=np.array(out_img).reshape(out_shape)
#print(base_img)
#print(right_line)
#print(bottom_line)
#print(botton_right)
return self.__Conbine(base_img,right_line,bottom_line,botton_right),self.__Conbine(base_img,right_line,bottom_line,botton_right).shape
else:
return torch.stack(out_img).reshape(out_shape), out_shape
def __Conbine(self,baseimg,rightline,bottomline,rightbottom):
'''内置函数,用于将冗余值信息与基本信息组合到一起'''
br=np.append(np.array(baseimg),np.array(rightline).reshape(len(rightline),1),axis=1)
#print(br)
bbr=np.append(np.array(bottomline),np.array(rightbottom))
bbrr=bbr.reshape(1,len(bbr))
#print(bbr)
#print(bbrr)
return torch.from_numpy(np.append(br,bbrr,axis=0).astype(np.float32))
def get_parameters(self):
return self.weights,self.bias
def set_parameters(self,weights,bias):
self.weights, self.bias=weights,bias
def set_weights(self,weights):
self.weights=weights
def set_bias(self,bias):
self.bias=bias
def show_img(img):
plt.figure()
plt.imshow(img, cmap='gray')
plt.show()
if __name__=='__main__':
# 数据预处理
transform = transforms.Compose([transforms.ToTensor()])
# 下载mnist库数据并定义读取器
train_dataset = torchvision.datasets.MNIST(root='./mnist', train=True, transform=transform, download=True)
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=5000, shuffle=True, num_workers=6)
test_dataset = torchvision.datasets.MNIST(root='./mnist', train=False, transform=transform, download=True)
test_dataloader = torch.utils.data.DataLoader(test_dataset, batch_size=10000, shuffle=True, num_workers=0)
img = np.array([[
[
[0, 1, 1, 0, 2],
[2, 2, 2, 2, 1],
[1, 0, 0, 2, 0],
[0, 1, 1, 0, 0],
[1, 2, 0, 0, 2]
],
[
[1, 0, 2, 2, 0],
[0, 0, 0, 2, 0],
[1, 2, 1, 2, 1],
[1, 0, 0, 0, 0],
[1, 2, 1, 1, 1]
],
[
[2, 1, 2, 0, 0],
[1, 0, 0, 1, 0],
[0, 2, 1, 0, 1],
[0, 1, 2, 2, 2],
[2, 1, 0, 0, 1]
]]
])
kernel_weights = torch.Tensor([[
[
[-1, 1, 0],
[0, 1, 0],
[0, 1, 1]
],
[
[-1, -1, 0],
[0, 0, 0],
[0, -1, 0]
],
[
[0, 0, -1],
[0, 1, 0],
[1, -1, -1]
]
],
[
[
[1, 1, -1],
[-1, -1, 1],
[0, -1, 1]
],
[
[0, 1, 0],
[-1, 0, -1],
[-1, 1, 0]
],
[
[-1, 0, 0],
[-1, 0, 1],
[-1, 0, 0]
]
]])
bias = torch.Tensor([[1], [0]])
target_feature = torch.Tensor([
[
[
[3., 7., 5.],
[4., -1., -1.],
[2., -6., 4.]
],
[[2., -7., -8.],
[1., -2., -4.],
[9., -7., -5.]
]
]
])
kernel_weights.requires_grad=True
bias.requires_grad=True
print('input img shape:',img.shape)
print('kernel shape',kernel_weights.shape)
myconv = myMultipassageConv(3, 2, kernel_size=(3,3), padding=1, stride=(2,2), use_bias=True,
use_redundancy=False,padding_str='zeros')
myconv.set_weights(kernel_weights)
myconv.set_bias(bias)
output=myconv.forward(torch.Tensor(img.astype(np.float32)))
print('output shape:\n',output.shape)
loss=torch.nn.CrossEntropyLoss()
l=loss(target_feature,output)
l.backward()
print('output shape:\n',output.shape)
print(myconv.weights.grad)
花了一些时间,终于全部改好了。最后输出的是交叉熵损失loss对myconv的kernel_weights的导数。(use_redundancy还没改,先用着)
有时间我会整理一下numpy和torch的代码实现的对应关系。
LeNet模型中还用到了池化层,因此还需要将numpy的池化层改成tensor的。
import matplotlib.pyplot as plt
import numpy as np
import torch
class myPooling():
def __init__(self,size,pooling_mode,stride):
self.h,self.w=size
self.pool_mode=pooling_mode
self.stride=stride
def __mypool(self, img):
output=[]
for x_index, i in enumerate(range(img.shape[0] )):
if x_index % self.stride == 0: # 纵向移动
for y_index, j in enumerate(range(img.shape[1])):
if y_index % self.stride== 0: # 横向移动
_img=img[i:i+self.h,j:j+self.w]
print(_img)
if self.pool_mode == 'ave':
output.append(torch.mean(_img))
elif self.pool_mode == 'max':
output.append(torch.max(_img))
elif self.pool_mode == 'min':
output.append(torch.min(_img))
else:
raise ValueError('Value error: unexcepted key value of \'pooling_mode\'. excepted key values:ave,max,min')
out_shape = [0, 0]
for i in range(img.shape[0]):
if i % self.stride == 0:
out_shape[0] += 1
for i in range(img.shape[1]):
if i % self.stride == 0:
out_shape[1] += 1
print(out_shape)
return torch.stack(output).reshape(out_shape), out_shape
def forward(self, x):
'''前向计算'''
'''输入格式(batch_size,chanels,hight,width)'''
output = []
(batch_size, chanels, hight, width) = x.shape
for batch_num in range(batch_size):
img = x[batch_num, :, :, :]
chanel=[]
for chanel_num in range(chanels):
_img = img[chanel_num, :, :]
out_img,out_shape=self.__mypool(_img)
chanel.append(out_img)
chanel=torch.stack(chanel)
output.append(chanel)
output=torch.stack(output)
return output
if __name__=='__main__':
img=torch.Tensor([[
[
[1,0,0,0,0],
[0,1,0,0,0],
[0,0,1,0,0],
[0,0,0,1,0],
[0,0,0,0,1]
]
]])
img.requires_grad=True
mypool=myPooling(size=(2,2),stride=1,pooling_mode='ave')
out_img=mypool.forward(img)
print(out_img)
由于池化层没有权重,不需要参数更新,因此只需要检查是否能对requires_grad=True的输入特征图进行处理,并输出requires_grad=True的特征图即可。
可以看到是可以的,那么基本上是改好了,至少用于实现LeNet应该是没问题。下面再来回顾一下LeNet神经网络:
它一共有三次卷积,两次池化,最后还有2层全连接层。(C5的输出是
120
∗
1
∗
1
120*1*1
120∗1∗1被平铺到120后输入到全连接层)
池化层和卷积层都有了,现在还需要全连接层,直接用torch写的,就不用再改了,因为之前都没写过基于numpy的全连接层的类,所以也没有可改的,那就现在临时写了一个。我记得当时前馈神经网络的时候就是用numpy写了几个函数,也没有写过封装好的类。为了体现更好的逻辑关系,把他们封装好会更好一些,同时实例化时也更简洁美观一些,当时写卷积类时也是这么想的。
简单写了一个。
线性层:
#coding:utf-8
import torch
class mylinear():
def __init__(self,in_size,out_size,use_bias=True):
self.in_size=in_size
self.out_size=out_size
self.weights,self.bias=self.__parameters()
self.use_bias=use_bias
def __parameters(self):
'''内部函数,默认标准正态分布初始化参数'''
'''权重尺寸为outsize,insize'''
weights = torch.randn(self.out_size, self.in_size, requires_grad=True)
'''偏置尺寸为outsize 1'''
bias = torch.randn(self.out_size, 1, requires_grad=True)
return weights, bias
def forward(self,X):
'''前向计算'''
output=[]
for i in range(self.out_size):
w=self.weights[i,:]
b=self.bias[i]
if self.use_bias:
y=torch.mul(w,X)+b
else:
y=torch.mul(w,X)
output.append(y)
output=torch.stack(output)
return output
def get_parameters(self):
return self.weights,self.bias
def set_parameters(self,weights,bias):
self.weights=weights
self.bias=bias
if __name__=='__main__':
X=torch.Tensor([1,2,3,4,5,6])
w=torch.Tensor([
[0.1,0.2,0.3 ,0.4, 0.5,0.6],
[0.1, 0.2, 0.3, 0.4, 0.5, 0.6],
[0.1,0.2,0.3 ,0.4, 0.5,0.6],
[0.1, 0.2, 0.3, 0.4, 0.5, 0.6]
])
b=torch.Tensor([
[0.1],
[0.2],
[0.3],
[0.4]
])
linear=mylinear(in_size=6,out_size=4)
output=linear.forward(X)
print(linear.get_parameters())
print(output)
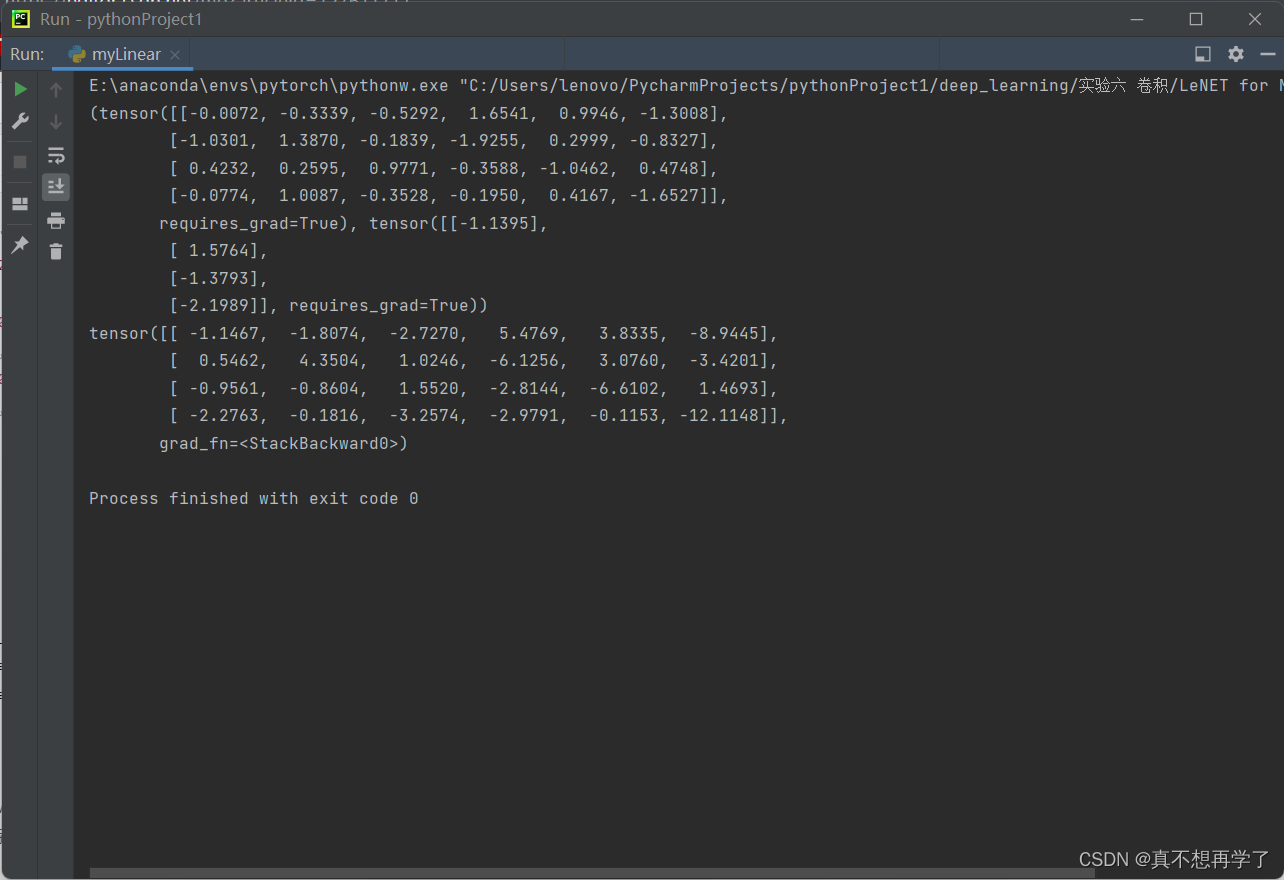
还得试一下全连接类能否自动求梯度。
#coding:utf-8
import torch
class mylinear():
def __init__(self,in_size,out_size,use_bias=True):
self.in_size=in_size
self.out_size=out_size
self.weights,self.bias=self.__parameters()
self.use_bias=use_bias
def __parameters(self):
'''内部函数,默认标准正态分布初始化参数'''
'''权重尺寸为in_chanels*out_chanels*kernelsize'''
weights = torch.randn(self.out_size, self.in_size, requires_grad=True)
'''偏置尺寸为out_kernels'''
bias = torch.randn(self.out_size, 1, requires_grad=True)
return weights, bias
def forward(self,X):
'''前向计算'''
output=[]
for i in range(self.out_size):
w=self.weights[i,:]
b=self.bias[i]
if self.use_bias:
y=torch.mul(w,X)+b
else:
y=torch.mul(w,X)
output.append(y)
output=torch.stack(output)
return output
def get_parameters(self):
return self.weights,self.bias
def set_parameters(self,weights,bias):
self.weights=weights
self.bias=bias
if __name__=='__main__':
X=torch.Tensor([1,2,3,4,5,6])
target=torch.Tensor([
[0.1,0.2,0.3 ,0.4, 0.5,0.6],
[0.1, 0.2, 0.3, 0.4, 0.5, 0.6],
[0.1,0.2,0.3 ,0.4, 0.5,0.6],
[0.1, 0.2, 0.3, 0.4, 0.5, 0.6]
])
b=torch.Tensor([
[0.1],
[0.2],
[0.3],
[0.4]
])
linear=mylinear(in_size=6,out_size=4)
output=linear.forward(X)
loss=torch.nn.CrossEntropyLoss()
l=loss(target,output)
l.backward()
print(linear.get_parameters())
print(output)
print(linear.weights.grad)
print(linear.bias.grad)
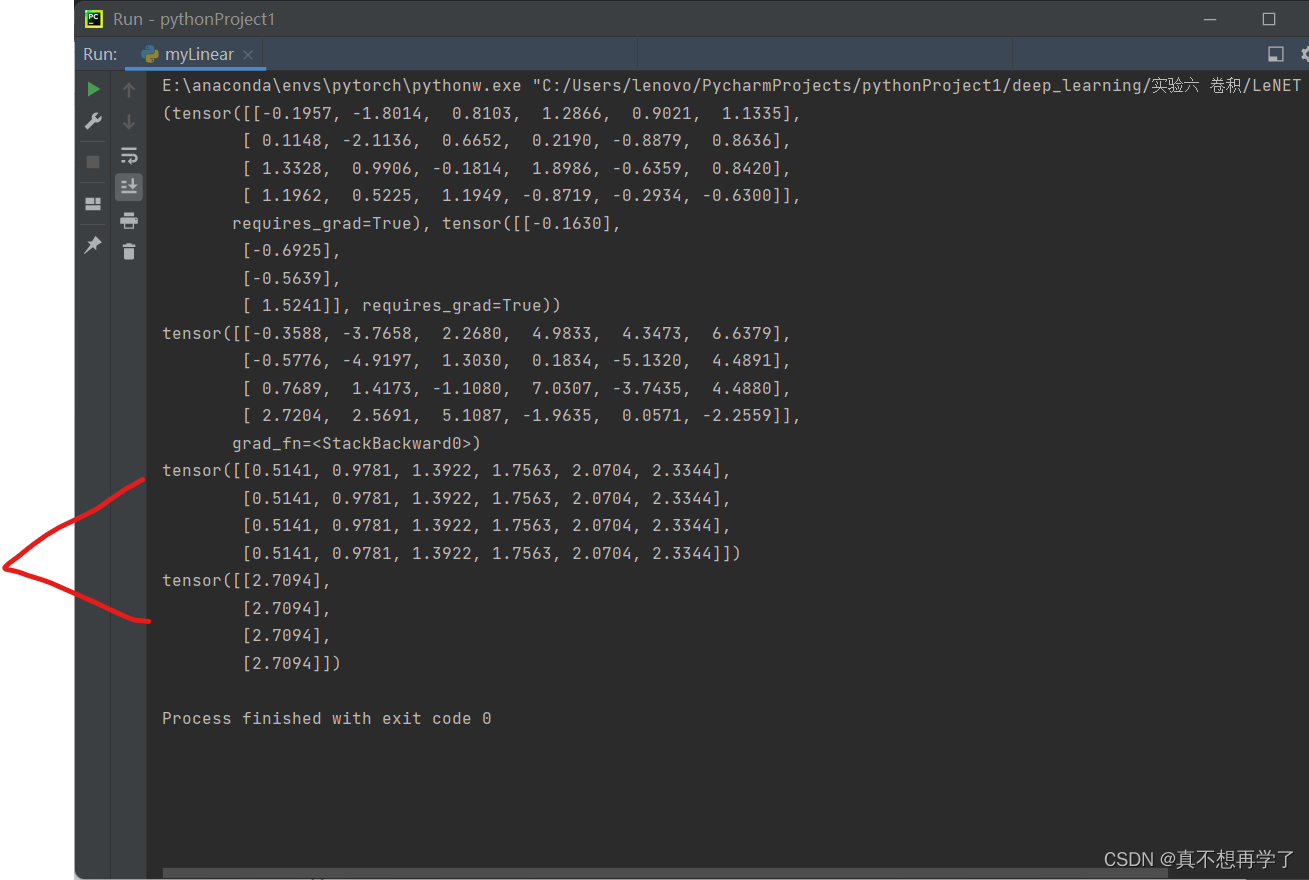
最后两项是loss对linear 的weights、bias的梯度。
大功告成,接下来实例化组建LeNet网络就行了。
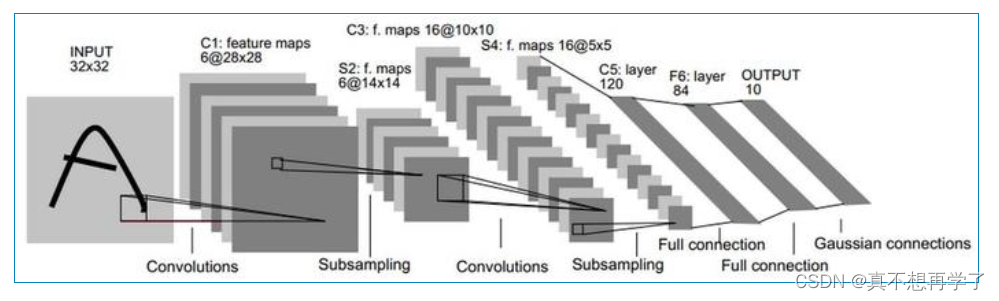
Lenet-5
#coding:utf-8
import json
import math
import numpy as np
import torch
import torchvision
from matplotlib import pyplot as plt
from torchvision import transforms
class myMultipassageConv():
def __init__(self,in_chanels,out_chanels,kernel_size,padding,stride=(1,1),padding_str='zeros',use_bias=True,use_redundancy=False):
'''
:param in_chanels: 输入通道数
:param out_chanels: 输出通道数
:param kernel_size: 卷积核尺寸 tuple类型
:param padding: 边缘填充数
:param stride: 步长 tuple类型 (可选)默认为(1,1)
:param padding_str: 边缘填充方式 str类型(可选)
:param use_bias: 是否使用偏置 bool类型(可选)
use_redundancy:是否使用冗余值 bool 默认舍弃
'''
self.kernel_size=kernel_size
self.in_chanels=in_chanels
self.out_chanels=out_chanels
self.padding=padding
self.stride=stride
(self.kernel_hight,self.kernel_width)=kernel_size
self.weights,self.bias=self.__parameters()
self.padding_str=padding_str
self.use_bias=use_bias
self.use_redundancy=use_redundancy
def __parameters(self):
'''内部函数,默认标准正态分布初始化参数'''
'''权重尺寸为in_chanels*out_chanels*kernelsize'''
weights=torch.randn(self.out_chanels,self.in_chanels,self.kernel_hight,self.kernel_width,requires_grad=True)
'''偏置尺寸为out_kernels'''
bias=torch.randn(self.out_chanels,1,requires_grad=True)
return weights,bias
def forward(self,x):
'''前向计算'''
'''输入格式(batch_size,chanels,hight,width)'''
output =[]
(batch_size, chanels, hight, width)=x.shape
for batch_num in range(batch_size):
img_chanel=x[batch_num,:,:,:]
#print('img_chanel:\n',img_chanel)
out_chanel=[]
for out_kernel_num in range(self.weights.shape[0]):
'''各个输出通道对应的权重'''
kernels=self.weights[out_kernel_num,:,:,:]
for_sum = []
for chanel_img_num in range(chanels):
'''对应项进行卷积'''
kernel = kernels[chanel_img_num, :, :]
_img=img_chanel[chanel_img_num,:,:]
#print('current input_img:\n', _img)
#print('current kernel:\n',kernel)
if self.padding>0:
_img = self.__paddingzeros(_img)#边缘填充
#print('padded img:\n',_img)
out_img,out_shape=self.__myConv(_img,kernel)
for_sum.append(out_img)
#print('unsumed out img:\n',for_sum)
for_sum=torch.stack(for_sum,0)
sumed_out_img=torch.sum(for_sum,dim=0)
#print('sumed out_img:\n',sumed_out_img)
if self.use_bias:
sumed_out_img+=self.bias[out_kernel_num]
out_chanel.append(sumed_out_img)
#print('out chanel:',out_chanel)
out_chanel=torch.stack(out_chanel)
output.append(out_chanel)
output=torch.stack(output,0)
'''计算输出图像的尺寸 '''
'''img=x[0,0,:,:]
if self.padding>0:
img = self.__paddingzeros(img) # 边缘填充
kernel=self.weights[0,0,:,:]
_,out_shape=self.__myConv(img,kernel)'''
#print('final output:\n', output)
return output
def __paddingzeros(self,img):
'''内部函数,默认 边缘0填充'''
if self.padding_str=='zeros':
out=torch.zeros((img.shape[0]+self.padding*2,img.shape[1]+self.padding*2))
out[self.padding:-self.padding,self.padding:-self.padding]=img
return out
elif self.padding_str=='ones':
out=torch.ones((img.shape[0]+self.padding*2,img.shape[1]+self.padding*2))
out[self.padding:-self.padding,self.padding:-self.padding]=img
return out
else:
raise ValueError('Value error: unexcepted key value of \'padding\'. excepted key values:zeros,ones')
def __myConv(self,img, kernel):#单层单核卷积
'''内部参数,用于计算单图像单核卷积'''
k1 = int((kernel.shape[0] - 1) / 2)
k2 = int((kernel.shape[1] - 1) / 2)
#print('k1,k2=',k1,k2)
#print('stride:',self.stride)
out_img = []
right_line=[]
bottom_line=[]
botton_right=[]
#print('img.shape:',img.shape)
for x_index,i in enumerate(range(k1, img.shape[0] - k1)):
if x_index%self.stride[1]==0:#纵向移动
for y_index,j in enumerate(range(k2, img.shape[1] - k2)):
if y_index%self.stride[0]==0:#横向移动
#print('current i j', i, j)
sight = img[i - k1:i + k2+1, j - k1:j + k2+1]
#print(sight)
#print(kernel)
out_img.append(torch.sum(torch.mul(torch.Tensor(sight), kernel)))
#print('out img:',out_img)
''' 这里考虑到步长大于1时卷积到右侧边缘或下侧会有边缘不足的情况,因此尝试对边界的溢出进行检测与处理 '''
'''处理边界冗余值'''
'''if (j+self.stride[0]+k1)>(img.shape[1]-1):
#print('列索引',(j+self.stride[0]+k1),'>',(img.shape[1]-k1))
#print('检测到达右边界,向右移动并填充后几列')
_j=j+self.stride[0]
redundancy=img[i - k1:i + k2+1,_j - k1:]
split_kernel = kernel[:, :np.array(redundancy).shape[1]]
#print(redundancy)
#print(split_kernel)
right_line.append(torch.sum(torch.mul(torch.Tensor(redundancy), split_kernel)))
#print( 'right line',right_line)
if (i+self.stride[1]+k2)>(img.shape[0]-1):
#print('行索引',(i+self.stride[1]),'>',(img.shape[0]-1))
#print('检测到达下边界,向下移动并填充下几行')
''''''达下边界,向下移动并分别获取冗余值以及分割的卷积核,在对两者计算点积和,其他几种也是这种方法''''''
_i=i+self.stride[1]
redundancy=img[_i - k2:, j - k1:j + k2+1]
split_kernel=kernel[:np.array(redundancy).shape[0], :]
#print(redundancy)
#print(split_kernel)
bottom_line.append(torch.sum(torch.mul(torch.Tensor(redundancy), split_kernel)))
#print('bottopn line:',bottom_line)
if ((j+self.stride[0]+k1)>(img.shape[1]-1))&((i+self.stride[1]+k2)>(img.shape[0]-1)):
#print('达右下角,向右下移动并填充')
_i+=self.stride[0]
_j+=self.stride[1]
redundancy = img[_i - k2:, _j - k1:]
split_kernel = kernel[:np.array(redundancy).shape[0], :np.array(redundancy).shape[1]]
#print(redundancy)
#print(split_kernel)
botton_right.append(torch.sum(torch.mul(torch.Tensor(redundancy), split_kernel)))'''
out_shape=[0,0]
for i in range( img.shape[0] - 2*k1):
if i%self.stride[1]==0:
out_shape[0]+=1
for i in range( img.shape[1] - 2*k2):
if i %self.stride[0]==0:
out_shape[1]+=1
#print(out_shape)
if self.use_redundancy:
base_img=np.array(out_img).reshape(out_shape)
#print(base_img)
#print(right_line)
#print(bottom_line)
#print(botton_right)
return self.__Conbine(base_img,right_line,bottom_line,botton_right),self.__Conbine(base_img,right_line,bottom_line,botton_right).shape
else:
return torch.stack(out_img).reshape(out_shape), out_shape
def __Conbine(self,baseimg,rightline,bottomline,rightbottom):
'''内置函数,用于将冗余值信息与基本信息组合到一起'''
br=np.append(np.array(baseimg),np.array(rightline).reshape(len(rightline),1),axis=1)
#print(br)
bbr=np.append(np.array(bottomline),np.array(rightbottom))
bbrr=bbr.reshape(1,len(bbr))
#print(bbr)
#print(bbrr)
return torch.from_numpy(np.append(br,bbrr,axis=0).astype(np.float32))
def get_parameters(self):
return self.weights,self.bias
def set_parameters(self,weights,bias):
self.weights, self.bias=weights,bias
def set_weights(self,weights):
self.weights=weights
def set_bias(self,bias):
self.bias=bias
def show_img(img):
plt.figure()
plt.imshow(img, cmap='gray')
plt.show()
class mylinear():
def __init__(self,in_size,out_size,use_bias=True):
self.in_size=in_size
self.out_size=out_size
self.weights,self.bias=self.__parameters()
self.use_bias=use_bias
def __parameters(self):
'''内部函数,默认标准正态分布初始化参数'''
'''权重尺寸为in_chanels*out_chanels*kernelsize'''
weights = torch.randn(self.out_size, self.in_size, requires_grad=True)
'''偏置尺寸为out_kernels'''
bias = torch.randn(self.out_size, 1, requires_grad=True)
return weights, bias
def forward(self,X):
'''前向计算'''
output=[]
for i in range(self.out_size):
w=self.weights[i,:]
b=self.bias[i]
if self.use_bias:
y=torch.mul(w,X)+b
else:
y=torch.mul(w,X)
output.append(y)
output=torch.stack(output)
return output
def get_parameters(self):
return self.weights,self.bias
def set_parameters(self,weights,bias):
self.weights=weights
self.bias=bias
class myPooling():
def __init__(self,size,pooling_mode,stride):
self.h,self.w=size
self.pool_mode=pooling_mode
self.stride=stride
def __mypool(self, img):
output=[]
for x_index, i in enumerate(range(img.shape[0] )):
if x_index % self.stride == 0: # 纵向移动
for y_index, j in enumerate(range(img.shape[1])):
if y_index % self.stride== 0: # 横向移动
_img=img[i:i+self.h,j:j+self.w]
print(_img)
if self.pool_mode == 'ave':
output.append(torch.mean(_img))
elif self.pool_mode == 'max':
output.append(torch.max(_img))
elif self.pool_mode == 'min':
output.append(torch.min(_img))
else:
raise ValueError('Value error: unexcepted key value of \'pooling_mode\'. excepted key values:ave,max,min')
out_shape = [0, 0]
for i in range(img.shape[0]):
if i % self.stride == 0:
out_shape[0] += 1
for i in range(img.shape[1]):
if i % self.stride == 0:
out_shape[1] += 1
#print(out_shape)
return torch.stack(output).reshape(out_shape), out_shape
def forward(self, x):
'''前向计算'''
'''输入格式(batch_size,chanels,hight,width)'''
output = []
(batch_size, chanels, hight, width) = x.shape
for batch_num in range(batch_size):
img = x[batch_num, :, :, :]
chanel=[]
for chanel_num in range(chanels):
_img = img[chanel_num, :, :]
out_img,out_shape=self.__mypool(_img)
chanel.append(out_img)
chanel=torch.stack(chanel)
output.append(chanel)
output=torch.stack(output)
return output
class LENet():
def __init__(self):
self.conv1=myMultipassageConv(in_chanels=1,out_chanels=6,kernel_size=(5,5),padding=0)#stride默认为(1,1)
self.conv2=myMultipassageConv(in_chanels=6,out_chanels=16,kernel_size=(5,5),padding=0)
self.conv3=myMultipassageConv(in_chanels=16,out_chanels=120,kernel_size=(5,5),padding=0)
self.pool1=myPooling(size=(2,2),pooling_mode='ave',stride=(2,2))
self.pool2=myPooling(size=(2,2),pooling_mode='ave',stride=(2,2))
self.linear1=mylinear(in_size=120,out_size=84)
self.linear2=mylinear(in_size=84,out_size=10)
def forward(self,x):
x1=self.pool1.forward(self.conv1.forward(x))
x2=self.pool2.forward(self.conv2.forward(x1))
x3=self.conv3.forward(x2)
x4=self.linear1.forward(x3)
x5=self.linear2.forward(x4)
return x5
if __name__=='__main__':
# 数据预处理
transform = transforms.Compose([transforms.ToTensor()])
# 下载mnist库数据并定义读取器
train_dataset = torchvision.datasets.MNIST(root='./mnist', train=True, transform=transform, download=True)
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=5000, shuffle=True, num_workers=6)
test_dataset = torchvision.datasets.MNIST(root='./mnist', train=False, transform=transform, download=True)
test_dataloader = torch.utils.data.DataLoader(test_dataset, batch_size=10000, shuffle=True, num_workers=0)
for X,target in train_dataloader:
test_X=X[0]
test_target=target[0]
print(X)
print(target)
break
lenet=LENet()
output=lenet.forward(X)
print(output)
一开始还好好的,打印计算过程十分顺畅,但是迟迟没有输出结果,然后就把打印过程注释掉了,觉得会运行的快一点,但是万万没想到。
这一运行电脑都要炸了,而且最后报错
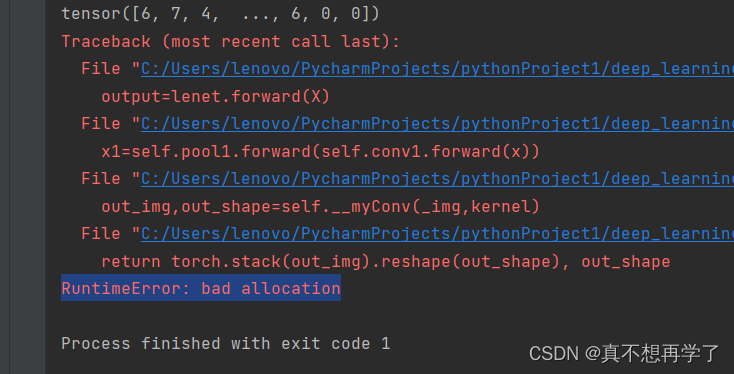
查了一下,是内存已满的意思,内存已满,说明程序设计的不好,因为自己设计的代码有大量的遍历、迭代还有临时列表等占内存的东西,所以最终导致内存炸了。我是真的累了。

那就到此为止吧,再写就不礼貌了。
我在想用内存在大一点的电脑能不能跑下来。
…………………………………………………………以上为day1……………………………………………………………
第一天做的有点急了,没有改那个数据集加载那块的代码,直接粘的上次的,上次为了加快训练速度,把batchsize设为了5000和10000.难怪内存崩了。。。。
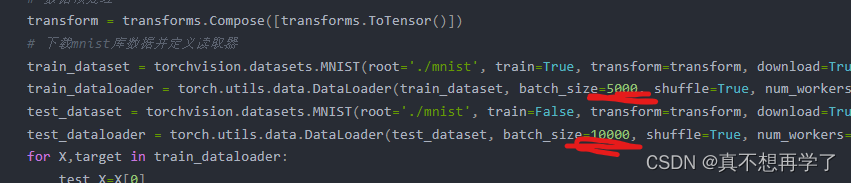

所以就改了一下。除此之外还忘记了对最后一层卷积的结果进行展平。。。
因为要支持多通道,所以这里的展平是这样的。否则会将所有通道都铺到一起。这里的reshape效果和flatten是一样的。

对应的线性层也修正了一下,现在真正支持多通道了。
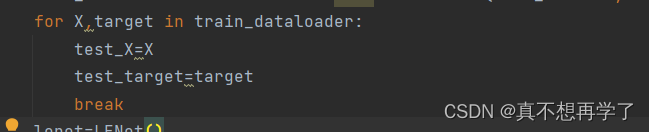
这一次batchsize只有10,运行没有问题。
利用了上次老师使用数据集的方法,迭代一次就break掉,这样就拿到了第一次的dataset,真神奇。我就直接用了这个了,没有自建一个(1,1,32,32)尺寸的图像。用这个顺便还能测试一下多通道能不能正常运行。
还忽略了一点就是输入尺寸的问题,minist的数据集尺寸为
28
∗
28
28*28
28∗28,LeNet的输入要求为
32
∗
32
32*32
32∗32,所以实际上需要对输入补两层零。

除此之外,还将之前卷积层那个烦人的冗余值相关的代码删去了,因为这里也用不到。代码简洁了许多。(不过我还没打算放弃它)
#coding:utf-8
import json
import math
import numpy as np
import torch
import torchvision
from matplotlib import pyplot as plt
from torchvision import transforms
class myMultipassageConv():
def __init__(self,in_chanels,out_chanels,kernel_size,padding,stride=(1,1),padding_str='zeros',use_bias=True,use_redundancy=False):
'''
:param in_chanels: 输入通道数
:param out_chanels: 输出通道数
:param kernel_size: 卷积核尺寸 tuple类型
:param padding: 边缘填充数
:param stride: 步长 tuple类型 (可选)默认为(1,1)
:param padding_str: 边缘填充方式 str类型(可选)
:param use_bias: 是否使用偏置 bool类型(可选)
use_redundancy:是否使用冗余值 bool 默认舍弃
'''
self.kernel_size=kernel_size
self.in_chanels=in_chanels
self.out_chanels=out_chanels
self.padding=padding
self.stride=stride
(self.kernel_hight,self.kernel_width)=kernel_size
self.weights,self.bias=self.__parameters()
self.padding_str=padding_str
self.use_bias=use_bias
self.use_redundancy=use_redundancy
def __parameters(self):
'''内部函数,默认标准正态分布初始化参数'''
'''权重尺寸为in_chanels*out_chanels*kernelsize'''
weights=torch.randn(self.out_chanels,self.in_chanels,self.kernel_hight,self.kernel_width,requires_grad=True)
'''偏置尺寸为out_kernels'''
bias=torch.randn(self.out_chanels,1,requires_grad=True)
return weights,bias
def forward(self,x):
'''前向计算'''
'''输入格式(batch_size,chanels,hight,width)'''
output =[]
(batch_size, chanels, hight, width)=x.shape
for batch_num in range(batch_size):
img_chanel=x[batch_num,:,:,:]
#print('img_chanel:\n',img_chanel)
out_chanel=[]
for out_kernel_num in range(self.weights.shape[0]):
'''各个输出通道对应的权重'''
kernels=self.weights[out_kernel_num,:,:,:]
for_sum = []
for chanel_img_num in range(chanels):
'''对应项进行卷积'''
kernel = kernels[chanel_img_num, :, :]
_img=img_chanel[chanel_img_num,:,:]
#print('current input_img:\n', _img)
#print('current kernel:\n',kernel)
if self.padding>0:
_img = self.__paddingzeros(_img)#边缘填充
#print('padded img:\n',_img)
out_img,out_shape=self.__myConv(_img,kernel)
for_sum.append(out_img)
#print('unsumed out img:\n',for_sum)
for_sum=torch.stack(for_sum,0)
sumed_out_img=torch.sum(for_sum,dim=0)
#print('sumed out_img:\n',sumed_out_img)
if self.use_bias:
sumed_out_img+=self.bias[out_kernel_num]
out_chanel.append(sumed_out_img)
#print('out chanel:',out_chanel)
out_chanel=torch.stack(out_chanel)
output.append(out_chanel)
output=torch.stack(output,0)
#print('final output:\n', output)
return output
def __paddingzeros(self,img):
'''内部函数,默认 边缘0填充'''
if self.padding_str=='zeros':
out=torch.zeros((img.shape[0]+self.padding*2,img.shape[1]+self.padding*2))
out[self.padding:-self.padding,self.padding:-self.padding]=img
return out
elif self.padding_str=='ones':
out=torch.ones((img.shape[0]+self.padding*2,img.shape[1]+self.padding*2))
out[self.padding:-self.padding,self.padding:-self.padding]=img
return out
else:
raise ValueError('Value error: unexcepted key value of \'padding\'. excepted key values:zeros,ones')
def __myConv(self,img, kernel):#单层单核卷积
'''内部参数,用于计算单图像单核卷积'''
k1 = int((kernel.shape[0] - 1) / 2)
k2 = int((kernel.shape[1] - 1) / 2)
#print('k1,k2=',k1,k2)
#print('stride:',self.stride)
out_img = []
right_line=[]
bottom_line=[]
botton_right=[]
#print('img.shape:',img.shape)
for x_index,i in enumerate(range(k1, img.shape[0] - k1)):
if x_index%self.stride[1]==0:#纵向移动
for y_index,j in enumerate(range(k2, img.shape[1] - k2)):
if y_index%self.stride[0]==0:#横向移动
#print('current i j', i, j)
sight = img[i - k1:i + k2+1, j - k1:j + k2+1]
#print(sight)
#print(kernel)
out_img.append(torch.sum(torch.mul(torch.Tensor(sight), kernel)))
#print('out img:',out_img)
out_shape=[0,0]
for i in range( img.shape[0] - 2*k1):
if i%self.stride[1]==0:
out_shape[0]+=1
for i in range( img.shape[1] - 2*k2):
if i %self.stride[0]==0:
out_shape[1]+=1
#print(out_shape)
return torch.stack(out_img).reshape(out_shape), out_shape
def get_parameters(self):
return self.weights,self.bias
def set_parameters(self,weights,bias):
self.weights, self.bias=weights,bias
def set_weights(self,weights):
self.weights=weights
def set_bias(self,bias):
self.bias=bias
class mylinear():
def __init__(self,in_size,out_size,use_bias=True):
self.in_size=in_size
self.out_size=out_size
self.weights,self.bias=self.__parameters()
self.use_bias=use_bias
def __parameters(self):
'''内部函数,默认标准正态分布初始化参数'''
'''权重尺寸为in_chanels*out_chanels*kernelsize'''
weights = torch.randn(self.out_size, self.in_size, requires_grad=True)
'''偏置尺寸为out_kernels'''
bias = torch.randn(self.out_size, 1, requires_grad=True)
return weights, bias
def forward(self,X):
'''前向计算'''
'''X.shape batchsize,insize'''
output=[]
for batchnum in range(X.shape[0]):
x=X[batchnum,:]
batch_output=[]
for i in range(self.out_size):
w=self.weights[i,:]
b=self.bias[i]
if self.use_bias:
y=torch.sum(torch.mul(w,x))+b
else:
y=torch.sum(torch.mul(w,x))
batch_output.append(y)
batch_output=torch.stack(batch_output,dim=1)
output.append(batch_output.squeeze())
output=torch.stack(output)
return output
def get_parameters(self):
return self.weights,self.bias
def set_parameters(self,weights,bias):
self.weights=weights
self.bias=bias
class myPooling():
def __init__(self,size,pooling_mode,stride):
self.h,self.w=size
self.pool_mode=pooling_mode
self.stride=stride
def __mypool(self, img):
output=[]
for x_index, i in enumerate(range(img.shape[0] )):
if x_index % self.stride[1] == 0: # 纵向移动
for y_index, j in enumerate(range(img.shape[1])):
if y_index % self.stride[0]== 0: # 横向移动
_img=img[i:i+self.h,j:j+self.w]
#print(_img)
if self.pool_mode == 'ave':
output.append(torch.mean(_img))
elif self.pool_mode == 'max':
output.append(torch.max(_img))
elif self.pool_mode == 'min':
output.append(torch.min(_img))
else:
raise ValueError('Value error: unexcepted key value of \'pooling_mode\'. excepted key values:ave,max,min')
out_shape = [0, 0]
for i in range(img.shape[0]):
if i % self.stride[0] == 0:
out_shape[0] += 1
for i in range(img.shape[1]):
if i % self.stride[1] == 0:
out_shape[1] += 1
#print(out_shape)
return torch.stack(output).reshape(out_shape), out_shape
def forward(self, x):
'''前向计算'''
'''输入格式(batch_size,chanels,hight,width)'''
output = []
(batch_size, chanels, hight, width) = x.shape
for batch_num in range(batch_size):
img = x[batch_num, :, :, :]
chanel=[]
for chanel_num in range(chanels):
_img = img[chanel_num, :, :]
out_img,out_shape=self.__mypool(_img)
chanel.append(out_img)
chanel=torch.stack(chanel)
output.append(chanel)
output=torch.stack(output)
return output
class LENet():
def __init__(self):
self.conv1=myMultipassageConv(in_chanels=1,out_chanels=6,kernel_size=(5,5),padding=2)#stride默认为(1,1)
self.conv2=myMultipassageConv(in_chanels=6,out_chanels=16,kernel_size=(5,5),padding=0)
self.conv3=myMultipassageConv(in_chanels=16,out_chanels=120,kernel_size=(5,5),padding=0)
self.pool1=myPooling(size=(2,2),pooling_mode='ave',stride=(2,2))
self.pool2=myPooling(size=(2,2),pooling_mode='ave',stride=(2,2))
self.linear1=mylinear(in_size=120,out_size=84)
self.linear2=mylinear(in_size=84,out_size=10)
self.relu=torch.nn.ReLU()
def forward(self,x):
#print('x:\n',x)
print('x.shape:\n',x.shape)
x1=self.relu(self.conv1.forward(x))
#print('X1:\n',x1)
print('x1.shape:\n',x1.shape)
x2=self.pool1.forward(x1)
#print('x2:\n',x2)
print('x2.shape:\n',x2.shape)
x3=self.relu(self.conv2.forward(x2))
#print('x3:\n',x3)
print('x3.shape:\n',x3.shape)
x4=self.pool2.forward(x3)
#print('x4:\n',x4)
print('x4.shape:\n',x4.shape)
x5=self.conv3.forward(x4)
#print('x5:\n',x5)
print('x5.shape:\n',x5.shape)
x5=x5.reshape(x.shape[0],-1)
#print('flatten x5:\n', x5)
print('flatten x5.shape:\n',x5.shape)
x6=self.linear1.forward(x5)
#print('x6:\n',x6)
print('x6.shape:\n',x6.shape)
x7=self.linear2.forward(x6)
#print('x7:\n',x7)
print('x7.shape:\n',x7.shape)
return x7
if __name__=='__main__':
# 数据预处理
transform = transforms.Compose([transforms.ToTensor()])
# 下载mnist库数据并定义读取器
train_dataset = torchvision.datasets.MNIST(root='./mnist', train=True, transform=transform, download=True)
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=10, shuffle=True, num_workers=6)
test_dataset = torchvision.datasets.MNIST(root='./mnist', train=False, transform=transform, download=True)
test_dataloader = torch.utils.data.DataLoader(test_dataset, batch_size=10, shuffle=True, num_workers=0)
for X,target in train_dataloader:
test_X=X
test_target=target
break
lenet=LENet()
output=lenet.forward(test_X)
#print(output)
E:\anaconda\envs\pytorch\pythonw.exe "C:/Users/lenovo/PycharmProjects/pythonProject1/deep_learning/实验六 卷积/LeNET for MINIST/LeNet for mnist.py"
x.shape:
torch.Size([10, 1, 28, 28])
x1.shape:
torch.Size([10, 6, 28, 28])
x2.shape:
torch.Size([10, 6, 14, 14])
x3.shape:
torch.Size([10, 16, 10, 10])
x4.shape:
torch.Size([10, 16, 5, 5])
x5.shape:
torch.Size([10, 120, 1, 1])
flatten x5.shape:
torch.Size([10, 120])
x6.shape:
torch.Size([10, 84])
x7.shape:
torch.Size([10, 10])
Process finished with exit code 0
附:测试了捆绑数的极限,batchsize为200的时候就很吃力了。运行了大概一两分钟。
你以为完事了?还没有,还需要参数更新。
总共有三个卷积层需要更新,两个全连接层需要更新。
此外dataset中的labels只是分类的标签,而网络的输出是一维的10个元素 ,因此要把标签规范到相同的形式。
for X,target in train_dataloader:
test_X=X
test_target=target
print(test_X)
print(test_target)
target_list=[]
for target in test_target:
if target==1:
target_list.append(torch.Tensor([1,0,0,0,0,0,0,0,0,0]))
elif target==2:
target_list.append(torch.Tensor([0, 1, 0, 0, 0, 0, 0, 0, 0, 0]))
elif target == 3:
target_list.append(torch.Tensor([0, 0, 1, 0, 0, 0, 0, 0, 0, 0]))
elif target == 4:
target_list.append(torch.Tensor([0, 0, 0, 1, 0, 0, 0, 0, 0, 0]))
elif target == 5:
target_list.append(torch.Tensor([0, 0, 0, 0, 1, 0, 0, 0, 0, 0]))
elif target == 6:
target_list.append(torch.Tensor([0, 0, 0, 0, 0, 1, 0, 0, 0, 0]))
elif target == 7:
target_list.append(torch.Tensor([0, 0, 0, 0, 0, 0, 1, 0, 0, 0]))
elif target == 8:
target_list.append(torch.Tensor([0, 0, 0, 0, 0, 0, 0, 1, 0, 0]))
elif target == 9:
target_list.append(torch.Tensor([0, 0, 0, 0, 0, 0, 0, 0, 1, 0]))
else:
target_list.append(torch.Tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 1]))
test_target=torch.stack(target_list)
print(test_target)
break
tensor([1, 5, 3, 9, 5, 3, 0, 2, 1, 8])
tensor([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 1., 0., 0.]])
更新参数选用随机梯度下降法,把参数更新直接写入创建的LeNet类中了,因为就是针对LeNet的参数更新,所以不对其他网络具有普适性。
为LeNet类添加更新参数和偏导置零两个函数。训练时直接调用就行了。
def SGD_step_grad(self,lr=0.01):
'''用于更新参数'''
self.conv1.weights.data-=self.conv1.weights.grad.data*lr
self.conv1.bias.data-=self.conv1.bias.grad.data*lr
self.conv2.weights.data-=self.conv2.weights.grad.data*lr
self.conv2.bias.data-=self.conv2.bias.grad.data*lr
self.conv3.weights.data-=self.conv3.weights.grad.data*lr
self.conv3.bias.data-=self.conv3.bias.grad.data*lr
self.linear1.weights.data-=self.linear1.weights.grad.data*lr
self.linear1.bias.data-=self.linear1.bias.grad.data*lr
self.linear2.weights.data-=self.linear2.weights.grad.data*lr
self.linear2.bias.data-=self.linear2.bias.grad.data*lr
def zero_grad(self):
self.conv1.weights.grad.data.zero_()
self.conv2.weights.grad.data.zero_()
self.conv3.weights.grad.data.zero_()
self.linear1.weights.grad.data.zero_()
self.linear2.weights.grad.data.zero_()
self.conv1.bias.grad.data.zero_()
self.conv2.bias.grad.data.zero_()
self.conv3.bias.grad.data.zero_()
self.linear1.bias.grad.data.zero_()
self.linear2.bias.grad.data.zero_()
LeNet的网络参数是很多的,全部打印出来看的眼花。所以就检查第一个卷积层和最后一个线性层的参数是否更新,因为这两个的参数比较少。发现还行。
#coding:utf-8
import json
import math
import numpy as np
import torch
import torchvision
from matplotlib import pyplot as plt
from torchvision import transforms
class myMultipassageConv():
def __init__(self,in_chanels,out_chanels,kernel_size,padding,stride=(1,1),padding_str='zeros',use_bias=True,use_redundancy=False):
'''
:param in_chanels: 输入通道数
:param out_chanels: 输出通道数
:param kernel_size: 卷积核尺寸 tuple类型
:param padding: 边缘填充数
:param stride: 步长 tuple类型 (可选)默认为(1,1)
:param padding_str: 边缘填充方式 str类型(可选)
:param use_bias: 是否使用偏置 bool类型(可选)
use_redundancy:是否使用冗余值 bool 默认舍弃
'''
self.kernel_size=kernel_size
self.in_chanels=in_chanels
self.out_chanels=out_chanels
self.padding=padding
self.stride=stride
(self.kernel_hight,self.kernel_width)=kernel_size
self.weights,self.bias=self.__parameters()
self.padding_str=padding_str
self.use_bias=use_bias
self.use_redundancy=use_redundancy
def __parameters(self):
'''内部函数,默认标准正态分布初始化参数'''
'''权重尺寸为in_chanels*out_chanels*kernelsize'''
weights=torch.randn(self.out_chanels,self.in_chanels,self.kernel_hight,self.kernel_width,requires_grad=True)
'''偏置尺寸为out_kernels'''
bias=torch.randn(self.out_chanels,1,requires_grad=True)
return weights,bias
def forward(self,x):
'''前向计算'''
'''输入格式(batch_size,chanels,hight,width)'''
output =[]
(batch_size, chanels, hight, width)=x.shape
for batch_num in range(batch_size):
img_chanel=x[batch_num,:,:,:]
#print('img_chanel:\n',img_chanel)
out_chanel=[]
for out_kernel_num in range(self.weights.shape[0]):
'''各个输出通道对应的权重'''
kernels=self.weights[out_kernel_num,:,:,:]
for_sum = []
for chanel_img_num in range(chanels):
'''对应项进行卷积'''
kernel = kernels[chanel_img_num, :, :]
_img=img_chanel[chanel_img_num,:,:]
#print('current input_img:\n', _img)
#print('current kernel:\n',kernel)
if self.padding>0:
_img = self.__paddingzeros(_img)#边缘填充
#print('padded img:\n',_img)
out_img,out_shape=self.__myConv(_img,kernel)
for_sum.append(out_img)
#print('unsumed out img:\n',for_sum)
for_sum=torch.stack(for_sum,0)
sumed_out_img=torch.sum(for_sum,dim=0)
#print('sumed out_img:\n',sumed_out_img)
if self.use_bias:
sumed_out_img+=self.bias[out_kernel_num]
out_chanel.append(sumed_out_img)
#print('out chanel:',out_chanel)
out_chanel=torch.stack(out_chanel)
output.append(out_chanel)
output=torch.stack(output,0)
#print('final output:\n', output)
return output
def __paddingzeros(self,img):
'''内部函数,默认 边缘0填充'''
if self.padding_str=='zeros':
out=torch.zeros((img.shape[0]+self.padding*2,img.shape[1]+self.padding*2))
out[self.padding:-self.padding,self.padding:-self.padding]=img
return out
elif self.padding_str=='ones':
out=torch.ones((img.shape[0]+self.padding*2,img.shape[1]+self.padding*2))
out[self.padding:-self.padding,self.padding:-self.padding]=img
return out
else:
raise ValueError('Value error: unexcepted key value of \'padding\'. excepted key values:zeros,ones')
def __myConv(self,img, kernel):#单层单核卷积
'''内部参数,用于计算单图像单核卷积'''
k1 = int((kernel.shape[0] - 1) / 2)
k2 = int((kernel.shape[1] - 1) / 2)
#print('k1,k2=',k1,k2)
#print('stride:',self.stride)
out_img = []
right_line=[]
bottom_line=[]
botton_right=[]
#print('img.shape:',img.shape)
for x_index,i in enumerate(range(k1, img.shape[0] - k1)):
if x_index%self.stride[1]==0:#纵向移动
for y_index,j in enumerate(range(k2, img.shape[1] - k2)):
if y_index%self.stride[0]==0:#横向移动
#print('current i j', i, j)
sight = img[i - k1:i + k2+1, j - k1:j + k2+1]
#print(sight)
#print(kernel)
out_img.append(torch.sum(torch.mul(torch.Tensor(sight), kernel)))
#print('out img:',out_img)
out_shape=[0,0]
for i in range( img.shape[0] - 2*k1):
if i%self.stride[1]==0:
out_shape[0]+=1
for i in range( img.shape[1] - 2*k2):
if i %self.stride[0]==0:
out_shape[1]+=1
#print(out_shape)
return torch.stack(out_img).reshape(out_shape), out_shape
def get_parameters(self):
return self.weights,self.bias
def get_weights(self):
return self.weights
def get_bias(self):
return self.bias
def set_parameters(self,weights,bias):
self.weights, self.bias=weights,bias
def set_weights(self,weights):
self.weights=weights
def set_bias(self,bias):
self.bias=bias
class mylinear():
def __init__(self,in_size,out_size,use_bias=True):
self.in_size=in_size
self.out_size=out_size
self.weights,self.bias=self.__parameters()
self.use_bias=use_bias
def __parameters(self):
'''内部函数,默认标准正态分布初始化参数'''
'''权重尺寸为in_chanels*out_chanels*kernelsize'''
weights = torch.randn(self.out_size, self.in_size, requires_grad=True)
'''偏置尺寸为out_kernels'''
bias = torch.randn(self.out_size, 1, requires_grad=True)
return weights, bias
def forward(self,X):
'''前向计算'''
'''X.shape batchsize,insize'''
output=[]
for batchnum in range(X.shape[0]):
x=X[batchnum,:]
batch_output=[]
for i in range(self.out_size):
w=self.weights[i,:]
b=self.bias[i]
if self.use_bias:
y=torch.sum(torch.mul(w,x))+b
else:
y=torch.sum(torch.mul(w,x))
batch_output.append(y)
batch_output=torch.stack(batch_output,dim=1)
output.append(batch_output.squeeze())
output=torch.stack(output)
return output
def get_parameters(self):
return self.weights,self.bias
def set_parameters(self,weights,bias):
self.weights=weights
self.bias=bias
def get_weights(self):
return self.weights
def get_bias(self):
return self.bias
class myPooling():
def __init__(self,size,pooling_mode,stride):
'''
:param size:
:param pooling_mode:
:param stride:
'''
self.h,self.w=size
self.pool_mode=pooling_mode
self.stride=stride
def __mypool(self, img):
output=[]
for x_index, i in enumerate(range(img.shape[0] )):
if x_index % self.stride[1] == 0: # 纵向移动
for y_index, j in enumerate(range(img.shape[1])):
if y_index % self.stride[0]== 0: # 横向移动
_img=img[i:i+self.h,j:j+self.w]
#print(_img)
if self.pool_mode == 'ave':
output.append(torch.mean(_img))
elif self.pool_mode == 'max':
output.append(torch.max(_img))
elif self.pool_mode == 'min':
output.append(torch.min(_img))
else:
raise ValueError('Value error: unexcepted key value of \'pooling_mode\'. excepted key values:ave,max,min')
out_shape = [0, 0]
for i in range(img.shape[0]):
if i % self.stride[0] == 0:
out_shape[0] += 1
for i in range(img.shape[1]):
if i % self.stride[1] == 0:
out_shape[1] += 1
#print(out_shape)
return torch.stack(output).reshape(out_shape), out_shape
def forward(self, x):
'''前向计算'''
'''输入格式(batch_size,chanels,hight,width)'''
output = []
(batch_size, chanels, hight, width) = x.shape
for batch_num in range(batch_size):
img = x[batch_num, :, :, :]
chanel=[]
for chanel_num in range(chanels):
_img = img[chanel_num, :, :]
out_img,out_shape=self.__mypool(_img)
chanel.append(out_img)
chanel=torch.stack(chanel)
output.append(chanel)
output=torch.stack(output)
return output
class LENet():
def __init__(self):
self.conv1=myMultipassageConv(in_chanels=1,out_chanels=6,kernel_size=(5,5),padding=2)#stride默认为(1,1)
self.conv2=myMultipassageConv(in_chanels=6,out_chanels=16,kernel_size=(5,5),padding=0)
self.conv3=myMultipassageConv(in_chanels=16,out_chanels=120,kernel_size=(5,5),padding=0)
self.pool1=myPooling(size=(2,2),pooling_mode='ave',stride=(2,2))
self.pool2=myPooling(size=(2,2),pooling_mode='ave',stride=(2,2))
self.linear1=mylinear(in_size=120,out_size=84)
self.linear2=mylinear(in_size=84,out_size=10)
self.sigmoid=torch.nn.Sigmoid()
self.softmax=torch.nn.Softmax(dim=1)
self.relu=torch.nn.ReLU()
def forward(self,x):
#print('x:\n',x)
#print('x.shape:\n',x.shape)
x1=self.relu(self.conv1.forward(x))
#print('X1:\n',x1)
#print('x1.shape:\n',x1.shape)
x2=self.pool1.forward(x1)
#print('x2:\n',x2)
#print('x2.shape:\n',x2.shape)
x3=self.relu(self.conv2.forward(x2))
#print('x3:\n',x3)
#print('x3.shape:\n',x3.shape)
x4=self.pool2.forward(x3)
#print('x4:\n',x4)
#print('x4.shape:\n',x4.shape)
x5=self.conv3.forward(x4)
#print('x5:\n',x5)
#print('x5.shape:\n',x5.shape)
x5=x5.reshape(x.shape[0],-1)
#print('flatten x5:\n', x5)
#print('flatten x5.shape:\n',x5.shape)
x6=self.relu(self.linear1.forward(x5))
#print('x6:\n',x6)
#print('x6.shape:\n',x6.shape)
x7=self.relu(self.linear2.forward(x6))
#print('x7:\n',x7)
#print('x7.shape:\n',x7.shape)
return x7
def parameters(self):
return self.conv1.get_parameters(),self.conv2.get_parameters(),\
self.conv3.get_parameters(),self.linear1.get_parameters(),\
self.linear2.get_parameters()
def SGD_step_grad(self,lr=0.01):
'''用于更新参数'''
self.conv1.weights.data-=self.conv1.weights.grad.data*lr
self.conv1.bias.data-=self.conv1.bias.grad.data*lr
self.conv2.weights.data-=self.conv2.weights.grad.data*lr
self.conv2.bias.data-=self.conv2.bias.grad.data*lr
self.conv3.weights.data-=self.conv3.weights.grad.data*lr
self.conv3.bias.data-=self.conv3.bias.grad.data*lr
self.linear1.weights.data-=self.linear1.weights.grad.data*lr
self.linear1.bias.data-=self.linear1.bias.grad.data*lr
self.linear2.weights.data-=self.linear2.weights.grad.data*lr
self.linear2.bias.data-=self.linear2.bias.grad.data*lr
def zero_grad(self):
self.conv1.weights.grad.data.zero_()
self.conv2.weights.grad.data.zero_()
self.conv3.weights.grad.data.zero_()
self.linear1.weights.grad.data.zero_()
self.linear2.weights.grad.data.zero_()
self.conv1.bias.grad.data.zero_()
self.conv2.bias.grad.data.zero_()
self.conv3.bias.grad.data.zero_()
self.linear1.bias.grad.data.zero_()
self.linear2.bias.grad.data.zero_()
def save_model(self,filepath):
pass
if __name__=='__main__':
# 数据预处理
transform = transforms.Compose([transforms.ToTensor()])
# 下载mnist库数据并定义读取器
batchsize=10
train_dataset = torchvision.datasets.MNIST(root='./mnist', train=True, transform=transform, download=True)
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batchsize, shuffle=True, num_workers=6)
test_dataset = torchvision.datasets.MNIST(root='./mnist', train=False, transform=transform, download=True)
test_dataloader = torch.utils.data.DataLoader(test_dataset, batch_size=batchsize, shuffle=True, num_workers=0)
lenet=LENet()
proces=0
epoches=1
for epoch in range(epoches):
finall_process = int(60000 / batchsize)
epoches = 1
for X,target in train_dataloader:
proces+=1
test_X=X
test_target=target
#print(test_X)
#print(test_target)
target_list=[]
for target in test_target:
if target==1:
target_list.append(torch.Tensor([1,0,0,0,0,0,0,0,0,0]))
elif target==2:
target_list.append(torch.Tensor([0, 1, 0, 0, 0, 0, 0, 0, 0, 0]))
elif target == 3:
target_list.append(torch.Tensor([0, 0, 1, 0, 0, 0, 0, 0, 0, 0]))
elif target == 4:
target_list.append(torch.Tensor([0, 0, 0, 1, 0, 0, 0, 0, 0, 0]))
elif target == 5:
target_list.append(torch.Tensor([0, 0, 0, 0, 1, 0, 0, 0, 0, 0]))
elif target == 6:
target_list.append(torch.Tensor([0, 0, 0, 0, 0, 1, 0, 0, 0, 0]))
elif target == 7:
target_list.append(torch.Tensor([0, 0, 0, 0, 0, 0, 1, 0, 0, 0]))
elif target == 8:
target_list.append(torch.Tensor([0, 0, 0, 0, 0, 0, 0, 1, 0, 0]))
elif target == 9:
target_list.append(torch.Tensor([0, 0, 0, 0, 0, 0, 0, 0, 1, 0]))
else:
target_list.append(torch.Tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 1]))
test_target=torch.stack(target_list)
#print(test_target)
output = lenet.forward(test_X)
loss = torch.nn.CrossEntropyLoss()
l = loss(test_target, output) * 0.001#损失比较大,会导致梯度比较大,因此给他乘小一点
print('[epoches:{}],procress:[{}/{}],current loss: {}'.format(epoch,proces,finall_process,l.item()))
l.backward()
lenet.SGD_step_grad(lr=0.01)
lenet.zero_grad()
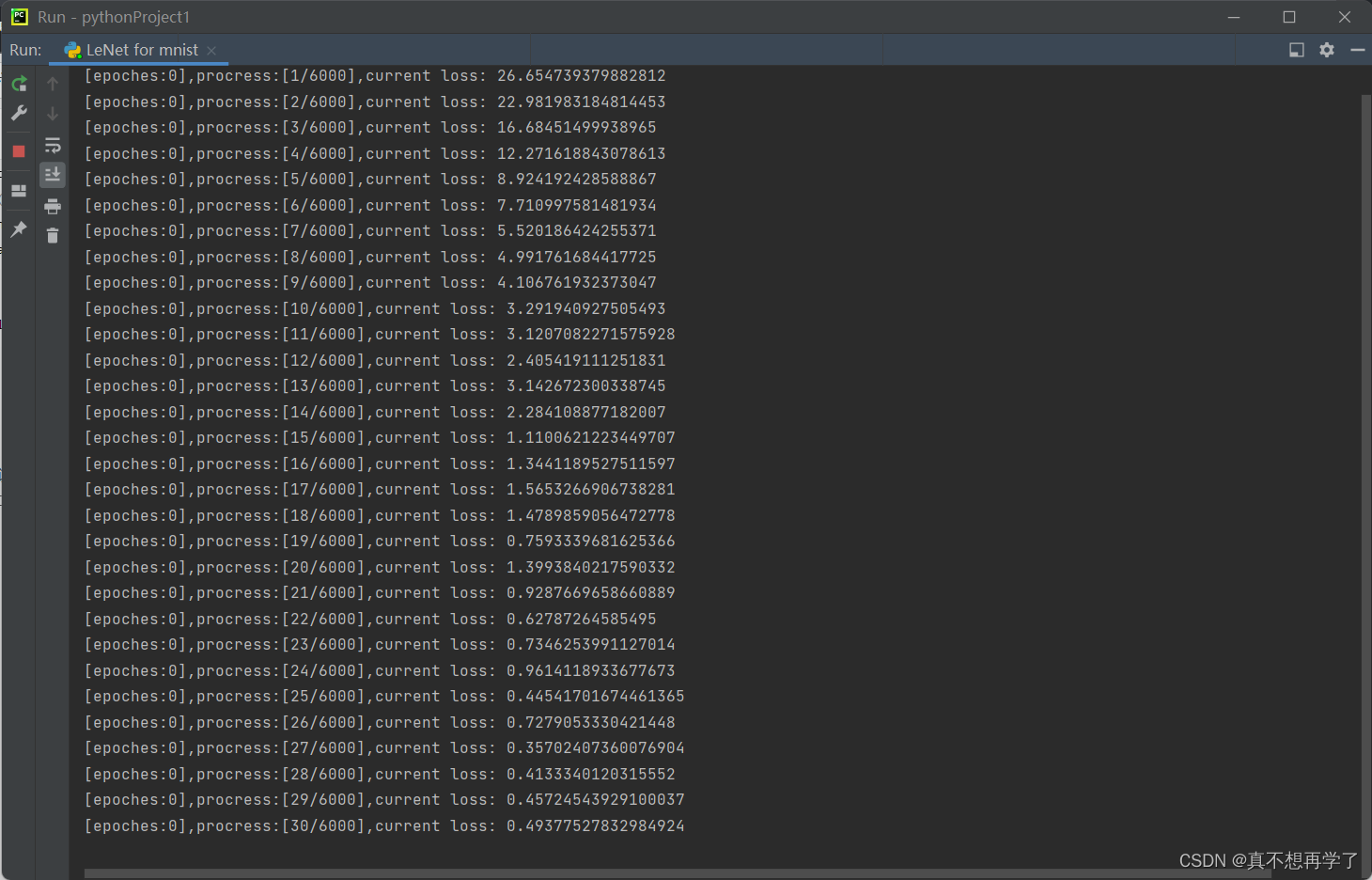
就这样实现了半全手搓的lenet神经网络,每一层都是自建层,没有继承torch.nn.Module类,我觉得应该还是挺有借鉴意义的。自动求导用到了pytorch,还有数据预处理用到了torch。速度的话平均8到9秒打印一次,一次代表训练了10个图片,还是十分缓慢的。
因为每层网络都是遍历迭遍历,有这样的速度在正常不过了,而且batchsize再大一点都运行不了了,训练到一半就会内存已满,可见循环套循环占用的空间很大。
到这里我对LeNet网络的掌握已经差不多了,手搓部分就到此为止了。
接下来全部用pytorch训练一下
内容有点多了,会写在下一篇文章中。















 647
647











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









