







Tensor介绍
TensorRT是一个高性能的深度学习推理(Inference)优化器,可以为深度学习应用提供低延迟、高吞吐率的部署推理。
TensorRT可用于对超大规模数据中心、嵌入式平台或自动驾驶平台进行推理加速。TensorRT现已能支持TensorFlow、Caffe、Mxnet、Pytorch等几乎所有的深度学习框架,将TensorRT和NVIDIA的GPU结合起来,能在几乎所有的框架中进行快速和高效的部署推理。
TensorRT 是一个C++库,从 TensorRT 3 开始提供C++ API和Python API,主要用来针对 NVIDIA GPU进行 高性能推理(Inference)加速。
关于推理(Inference):
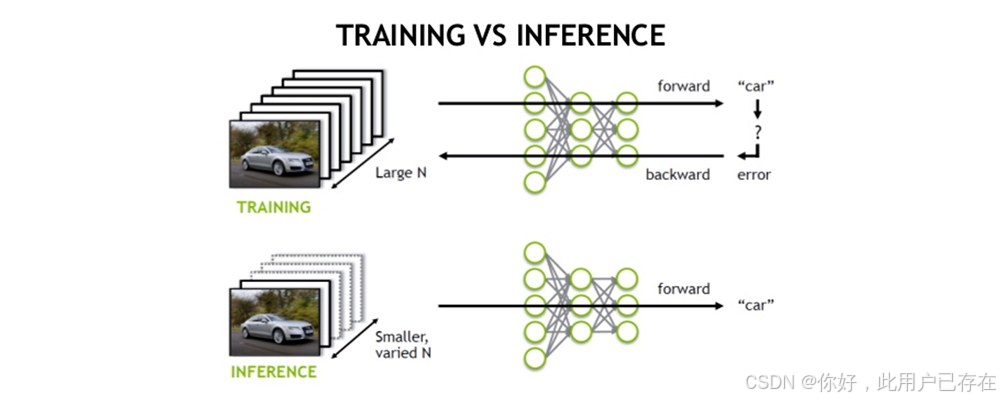
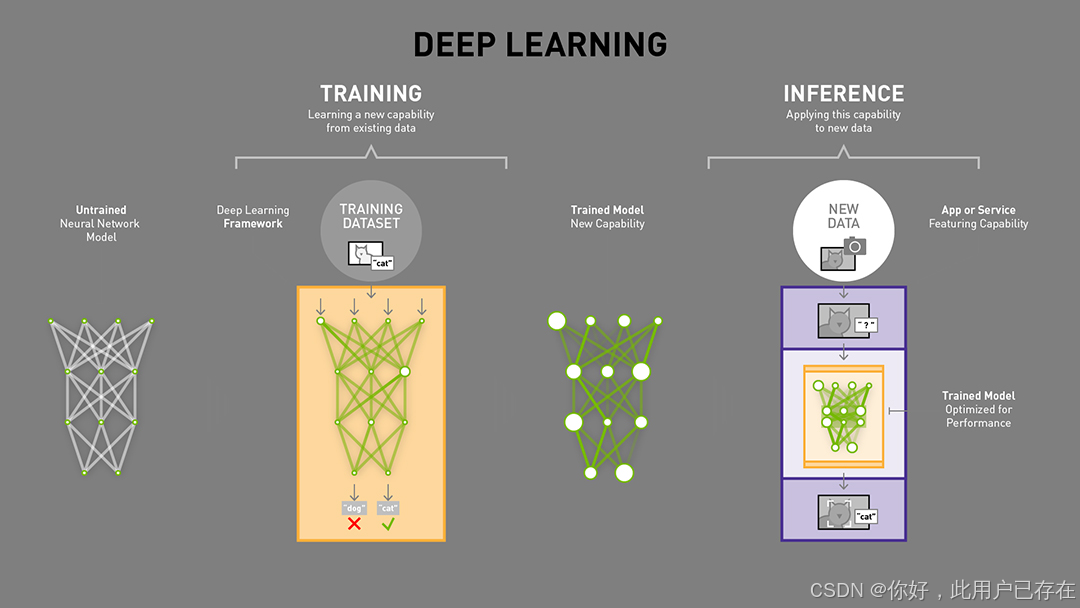
由以上两张图可以很清楚的看出,训练(training)和 推理(inference)的区别:
- 训练(training)包含了前向传播和后向传播两个阶段,针对的是训练集。训练时通过误差反向传播来不断修改网络权值(weights)。
- 推理(inference)只包含前向传播一个阶段,针对的是除了训练集之外的新数据。可以是测试集,但不完全是,更多的是整个数据集之外的数据。其实就是针对新数据进行预测,预测时,速度是一个很重要的因素。
一般的深度学习项目,训练时为了加快速度,会使用多GPU分布式训练。但在部署推理时,为了降低成本,往往使用单个GPU机器甚至嵌入式平台(比如 NVIDIA Jetson)进行部署,部署端也要有与训练时相同的深度学习环境,如caffe,TensorFlow等。
由于训练的网络模型可能会很大(比如,inception,resnet等),参数很多,而且部署端的机器性能存在差异,就会导致推理速度慢,延迟高。这对于那些高实时性的应用场合是致命的,比如自动驾驶要求实时目标检测,目标追踪等。
训练对于深度学习来说是为了获得一个性能优异的模型,其主要的关注点在于模型的准确度等指标。推理则不一样,其没有了训练中的反向迭代过程,是针对新的数据进行预测,而我们日常生活中使用的AI服务都是推理服务。相较于训练,推理的关注点不一样,从而也给现在有技术带来了新的挑战:
| 需求 | 现有框架的局限性 | 影响 |
|---|---|---|
| 高吞吐率 | 无法处理大量和高速的数据 | 增加了单次推理的开销 |
| 低响应时间 | 应用无法提供实时的结果 | 损害了用户体验(语音识别、个性化推荐和实时目标检测) |
| 高效的功耗以及显存消耗控制 | 非最优效能 | 增加了推理的开销甚至无法进行推理部署 |
| 部署级别的解决方案 | 非专用于部署使用 | 框架复杂度和配置增加了部署难度以及生产率 |
根据上图可知,推理更关注的是高吞吐率、低响应时间、低资源消耗以及简便的部署流程,而TensorRT就是用来解决推理所带来的挑战以及影响的部署级的解决方案。
TensorRT是对训练好的模型进行优化,它只是个推理优化器。当你的网络训练完之后,可以将训练模型文件直接丢进tensorRT中,而不再需要依赖深度学习框架(Caffe,TensorFlow等),如下:
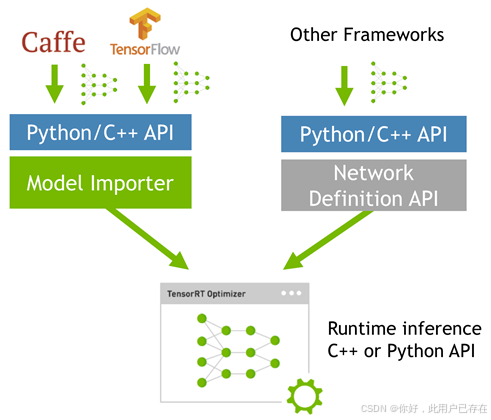
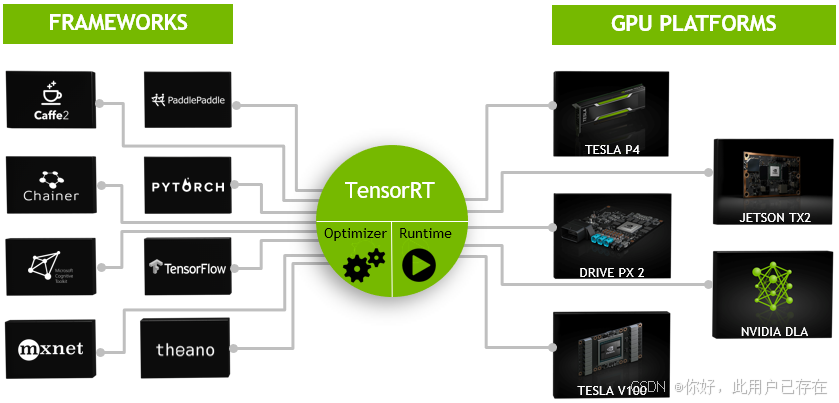
因此可以认为tensorRT是一个只有前向传播的深度学习框架,这个框架可以将 Caffe,TensorFlow的网络模型解析,然后与tensorRT中对应的层进行一一映射,把其他框架的模型统一全部 转换到tensorRT中,然后在tensorRT中可以针对NVIDIA自家GPU实施优化策略,并进行部署加速
目前TensorRT4.0 几乎可以支持所有常用的深度学习框架,对于caffe和TensorFlow来说,tensorRT可以直接解析他们的网络模型;对于caffe2,pytorch,mxnet,chainer,CNTK等框架则是首先要将模型转为 ONNX 的通用深度学习模型,然后对ONNX模型做解析。而tensorflow和MATLAB已经将TensorRT集成到框架中去了。
有关pytorch模型转换为ONNX模型文件可参考
ONNX / TensorFlow / Custom deep-learning frame模型的工作方式:
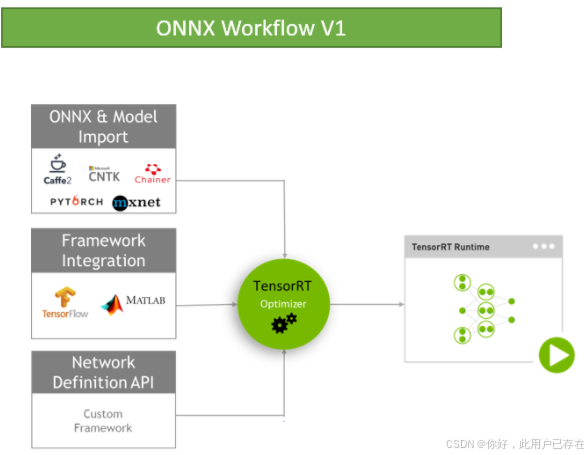
现在tensorRT支持的层有:
- Activation: ReLU, tanh and sigmoid
- Concatenation : Link together multiple tensors across the channel dimension.
- Convolution: 3D,2D
- Deconvolution
- Fully-connected: with or without bias
- ElementWise: sum, product or max of two tensors
- Pooling: max and average
- Padding
- Flatten
- LRN: cross-channel only
- SoftMax: cross-channel only
- RNN: RNN, GRU, and LSTM
- Scale: Affine transformation and/or exponentiation by constant values
- Shuffle: Reshuffling of tensors , reshape or transpose data
- Squeeze: Removes dimensions of size 1 from the shape of a tensor
- Unary: Supported operations are exp, log, sqrt, recip, abs and neg
- Plugin: integrate custom layer implementations that TensorRT does not natively support.
基本上比较经典的层比如,卷积,反卷积,全连接,RNN,softmax等,在tensorRT中都是有对应的实现方式的,tensorRT是可以直接解析的。
但是由于现在深度学习技术发展日新月异,各种不同结构的自定义层(比如:STN)层出不穷,所以tensorRT是不可能全部支持当前存在的所有层的。那对于这些自定义的层该怎么办?
tensorRT中有一个 Plugin 层,这个层提供了 API 可以由用户自己定义tensorRT不支持的层。 如下图:
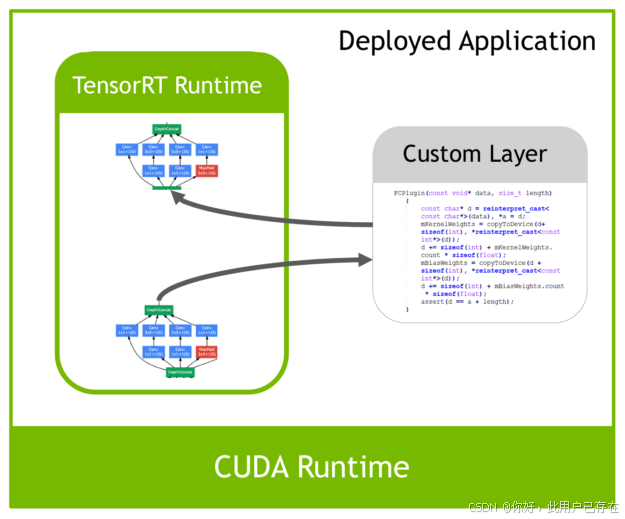
这就解决了适应不同用户的自定义层的需求。
优化方式
TentsorRT 优化方式:
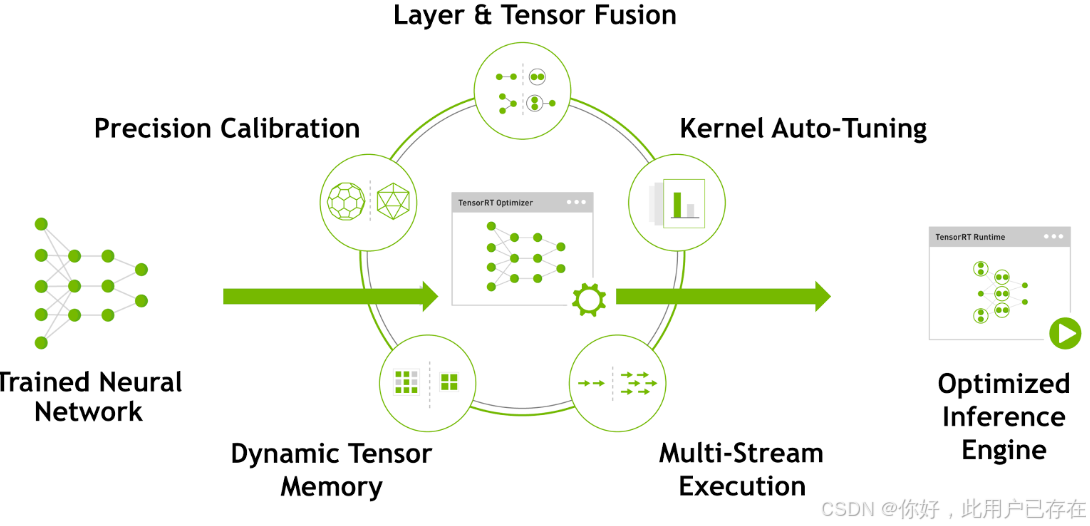
TensorRT优化方法主要有以下几种方式,最主要的是前面两种。
层间融合或张量融合(Layer & Tensor Fusion)
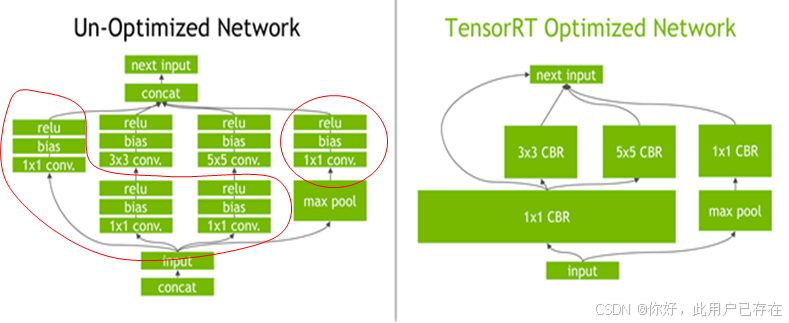
如下图左侧是GoogLeNetInception模块的计算图。这个结构中有很多层,在部署模型推理时,这每一层的运算操作都是由GPU完成的,但实际上是GPU通过启动不同的CUDA(Compute unified device architecture)核心来完成计算的,CUDA核心计算张量的速度是很快的,但是往往大量的时间是浪费在CUDA核心的启动和对每一层输入/输出张量的读写操作上面,这造成了内存带宽的瓶颈和GPU资源的浪费。
TensorRT通过对层间的横向或纵向合并(合并后的结构称为CBR,意指 convolution, bias, and ReLU layers are fused to form a single layer),使得层的数量大大减少。横向合并可以把卷积、偏置和激活层合并成一个CBR结构,只占用一个CUDA核心。纵向合并可以把结构相同,但是权值不同的层合并成一个更宽的层,也只占用一个CUDA核心。
合并之后的计算图(图4右侧)的层次更少了,占用的CUDA核心数也少了,因此整个模型结构会更小,更快,更高效。
数据精度校准(Weight &Activation Precision Calibration)
大部分深度学习框架在训练神经网络时网络中的张量(Tensor)都是32位浮点数的精度(Full 32-bit precision,FP32),一旦网络训练完成,在部署推理的过程中由于不需要反向传播,完全可以适当降低数据精度,比如降为FP16或INT8的精度。更低的数据精度将会使得内存占用和延迟更低,模型体积更小。
如下表为不同精度的动态范围:

INT8只有256个不同的数值,使用INT8来表示 FP32精度的数值,肯定会丢失信息,造成性能下降。不过TensorRT会提供完全自动化的校准(Calibration )过程,会以最好的匹配性能将FP32精度的数据降低为INT8精度,最小化性能损失。
Kernel Auto-Tuning
网络模型在推理计算时,是调用GPU的CUDA核进行计算的。TensorRT可以针对不同的算法,不同的网络模型,不同的GPU平台,进行 CUDA核的调整(怎么调整的还不清楚),以保证当前模型在特定平台上以最优性能计算。
TensorRT will pick the implementation from a library of kernels that delivers the best performance for the target GPU, input data size, filter size, tensor layout, batch size and other parameters.
Dynamic Tensor Memory
在每个tensor的使用期间,TensorRT会为其指定显存,避免显存重复申请,减少内存占用和提高重复使用效率。
Multi-Stream Execution
Scalable design to process multiple input streams in parallel,这个应该就是GPU底层的优化了。
TensorRT 部署流程
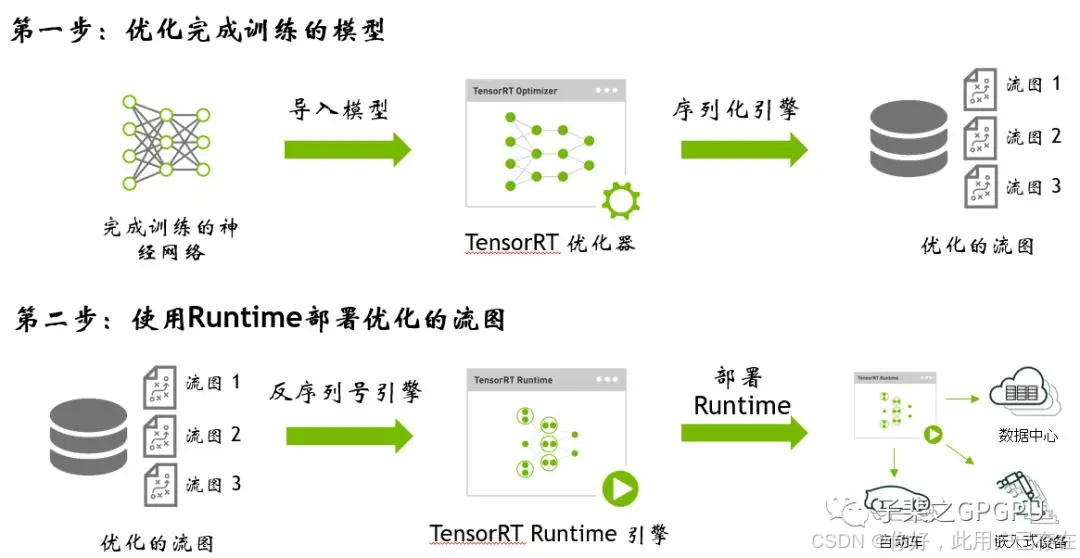
TensorRT的部署分为两个大的部分:
优化训练好的模型并生成计算流图
使用TensorRT Runtime部署计算流图
主要步骤其实就6个
- Export the Model: 导出模型
- Select A Batch Size: 根据自己的实际项目选择一个合适的Batch Size
- Select A Precision: 选择一个精度类型,比如INT8,FLOAT16,FLOAT32
- Convert The Model: 转换模型
- Deploy The Model: 部署模型
完成TensorRT优化后可以得到一个Runtime inference engine,这个文件可以被系列化保存至硬盘中,而这个保存的序列化文件我们称之为“Plan”(流图),之所以称之为流图,因此其不仅保存了计算时所需的网络weights也保存了Kernel执行的调度流程。TensorRT提供了write_engine_to_file()函数以来保存流图。
在获得了流图之后就可以使用TensorRT部署应用。为了进一步的简化部署流程,TensorRT提供了TensorRT Lite API,它是高度抽象的接口会自动处理大量的重复的通用任务例如创建一个Logger,反序列化流图并生成Runtime inference engine,处理输入的数据。以下代码提供了一个使用TensorRT Lite API的范例教程,只需使用API创建一个Runtime Engine即可完成前文提到的通用任务,之后将需要推理的数据载入并送入Engine即可进行推理。
有关理论的部分就介绍到这里,接下来我们介绍tensorRT的安装及使用
参考


















 840
840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









