






1.查看主机名
查看master 虚拟机名
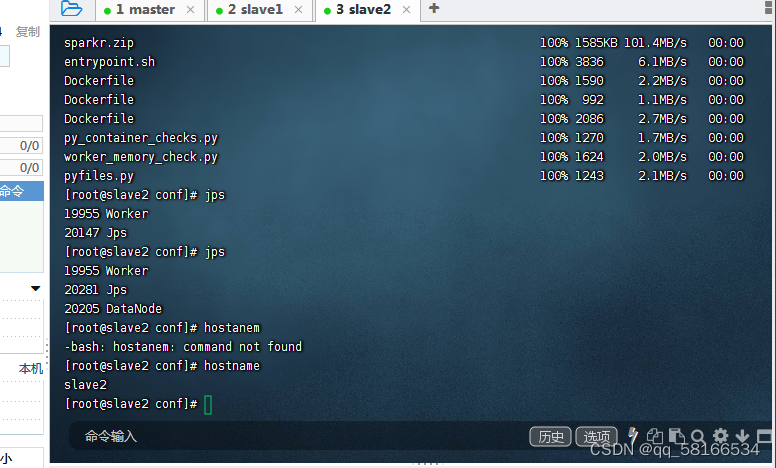
查看slave1主机名

查看slave2主机名

2.在master上配置主机映射vim /etc/hosts

在slave1和slave2上配置主机映射


3.关闭所有节点的防火墙
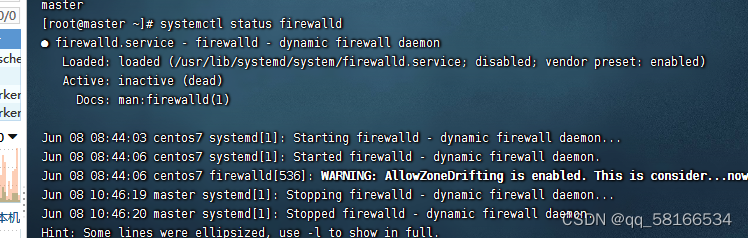
禁用防火墙

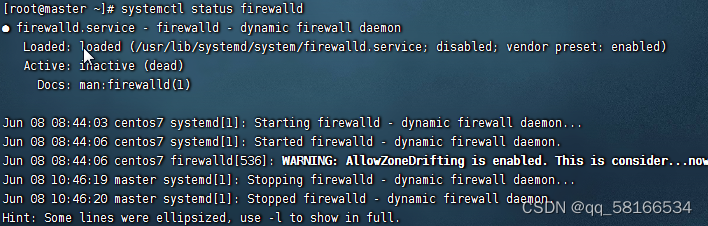
查看防火墙状态
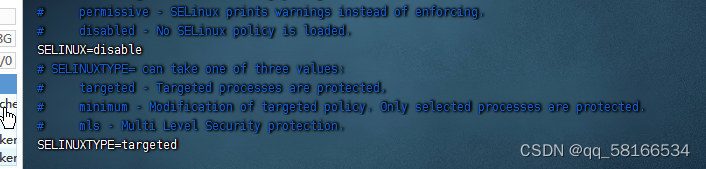
4。关闭三个节点的安全机制
命令:vim /etc/sysconfig/selinux(其余子节点一样的操作)
5.完成虚拟机免密登录
命令:ssh-keygen,生成密钥对

命令:ssh-copy-id root@master,将公钥拷贝到master
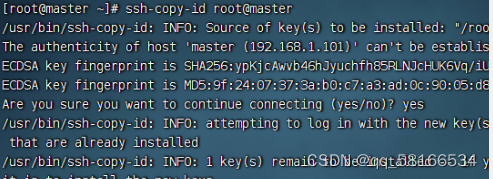
在此处需要输入密码后生成免密
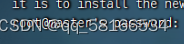
登录并退出免密成功
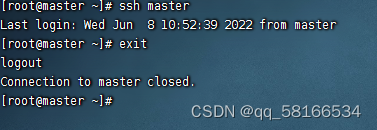
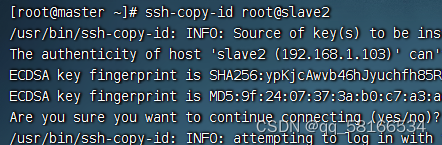
命令:ssh-copy-id root@slave2,将公钥拷贝到slave2,确认输入yes,并输入密码
命令:ssh-copy-id root@slave,将公钥拷贝到slave,确认输入yes,并输入密码

5.在opt目录上上传相关压缩包
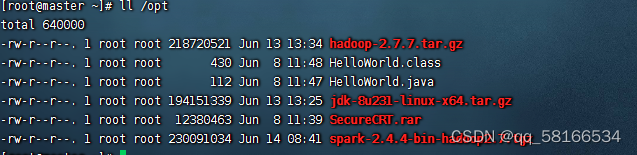
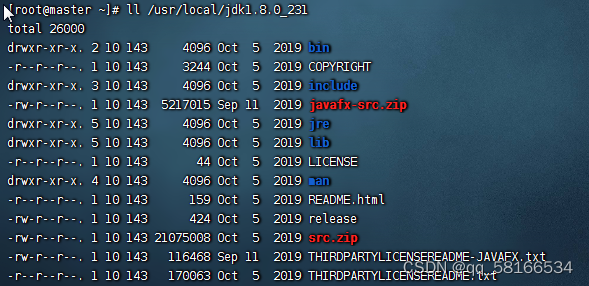
命令:tar -zxvf jdk-8u162-linux-x64.tar.gz -C /usr/local,将Java安装包解压到指定目录
解压后在目录下查看jdk_231
用命令vim /etc/profile,配置环境变量
export JAVA_HOME=/usr/local/jdk1.8.0_162
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
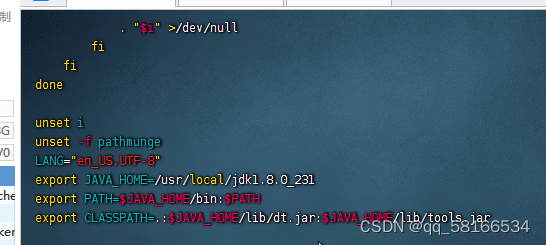
保存退出,source /etc/profile,让配置生效
![]()
查看版本号

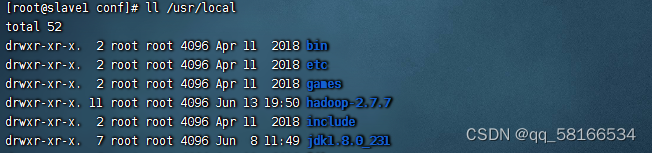
6.将JDK分发到slave1和slave2子节点上
命令:scp -r $JAVA_HOME root@slave1:$JAVA_HOME

查看slave1目录下是否有jdk1.8.0_231
命令:scp -r $JAVA_HOME root@slave2:$JAVA_HOME JDK分发到slave2

查看是否存在

7.将配置环境分发到slave1和slave2上
scp /etc/profile root@slave2:/etc上传至slave2

scp /etc/profile root@slave1:/etc上传至slave1

在slave1与slave2节点上执行命令:source /etc/profile,让环境配置生效


2.在虚拟机上上传Hadoop,并配置Hadoop环境
1.上传至opt目录后,执行解压命令:tar -zxvf hadoop-2.7.7.tar.gz -C /usr/local

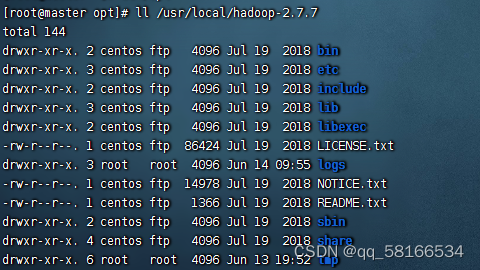
解压后查看是否有etc:配置目录,bin:执行文件,sbin:关闭执行命令,
2.配置hadoop环境变量:vim /etc/profile
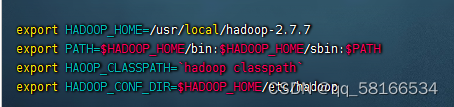
export HADOOP_HOME=/usr/local/hadoop-2.7.7
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_CLASSPATH=`hadoop classpath`
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
存盘退出,执行命令:source /etc/profile,让配置生效

3.配置Hadoop环境变量
cd $HADOOP_HOME/etc/hadoop,进入hadoop配置目录

vim hadoop-env.sh

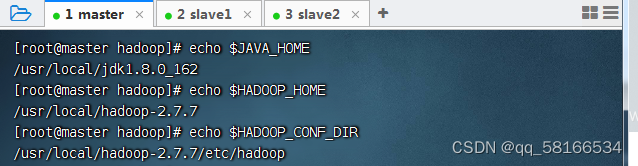
export JAVA_HOME=/usr/local/jdk1.8.0_162
export HADOOP_HOME=/usr/local/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
存盘退出后,执行命令source hadoop-env.sh,让配置生效

查看三个配置的三个环境变量
4.配置Hadoop 核心文件
vim core-site.xml
<configuration>
<!--用来指定hdfs的老大-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!--用来指定hadoop运行时产生文件的存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.7.7/tmp</value>
</property>
</configuration>

5.配置hdfs文件:vim hdfs-site.xml

<configuration>
<property>
<!--设置名称节点的目录-->
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop-2.7.7/tmp/namenode</value>
</property>
<property>
<!--设置数据节点的目录-->
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop-2.7.7/tmp/datanode</value>
</property>
<property>
<!--设置辅助名称节点-->
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
</configuration>
6.基于模板生成配置文件:cp mapred-site.xml.template mapred-site.xml

vim mapred-site.xml
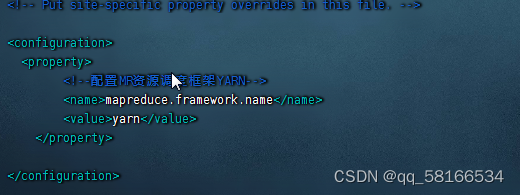
<configuration>
<property>
<!--配置MR资源调度框架YARN-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
7.编辑配置yarn文件 vim yarn-site.xml
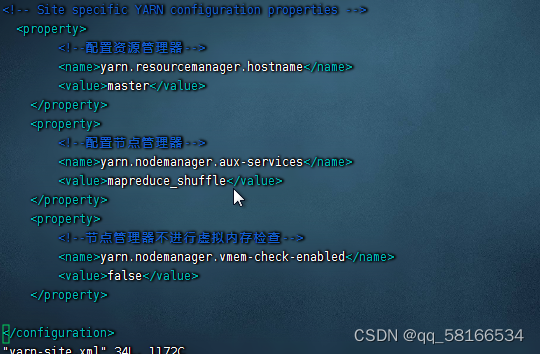
<configuration>
<property>
<!--配置资源管理器-->
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<!--配置节点管理器-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!--节点管理器不进行虚拟内存检查-->
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
3.配置slaves文件
vim slaves
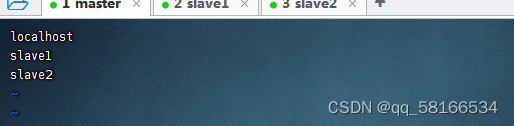
将master虚拟机上的hadoop分发到slave1 和slave2虚拟机
scp -r $HADOOP_HOME root@slave1:$HADOOP_HOME上传至slave1
scp -r $HADOOP_HOME root@slave2:$HADOOP_HOME上传至slave2
将变量分发至子节点
scp /etc/profile root@slave1:/etc/profile
~切换至子节点:命令:source /etc/profile,使文件生效
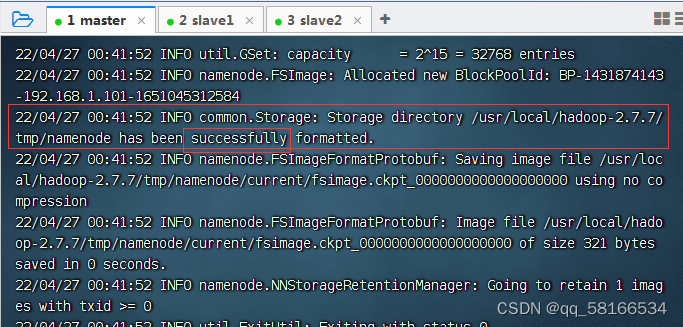
4.在主节点master格式化节点名称
在master虚拟机上,执行命令:hdfs namenode -format
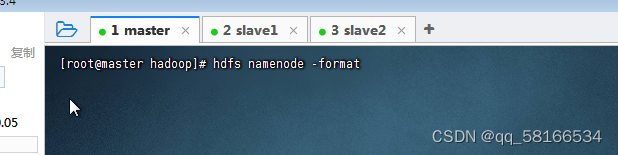
出现successfully代表成功
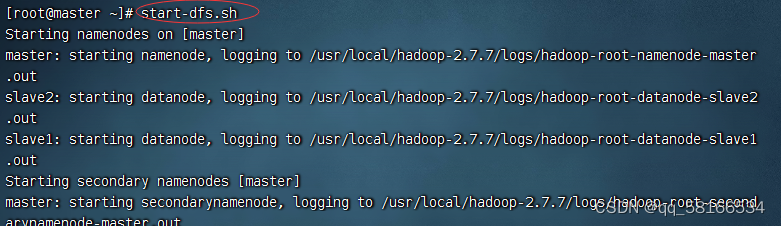
启动Hadoop节点
start-dfs.sh
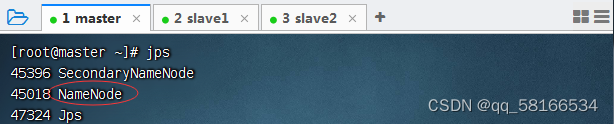
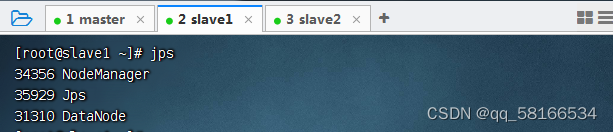
命令:jps查看master守护节点
jps:查看子节点守护节点
slave1

slave2

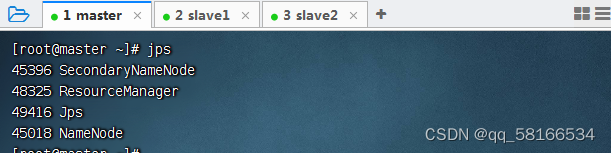
start-yarn.sh,启动YARN服务

查看守护节点

二。配置Spark Standalone集群
上传spark包在opt目录下

解压spark包:tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /usr/local

配置spark环境:vim /etc/profile

export SPARK_HOME=/usr/local/spark-2.1.1-bin-hadoop2.7
export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
存盘退出后,执行命令:source /etc/profile,让配置生效

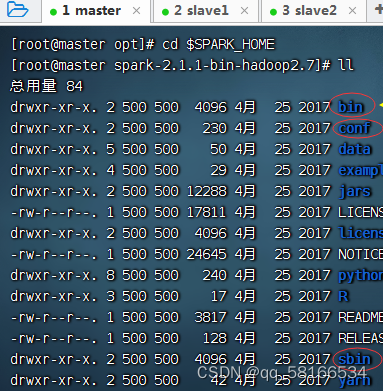
查看spark安装目录(bin、sbin和conf)
1.配置spark环境配置
执行命令:cp spark-env.sh.template spark-env.sh与vim spark-env.sh

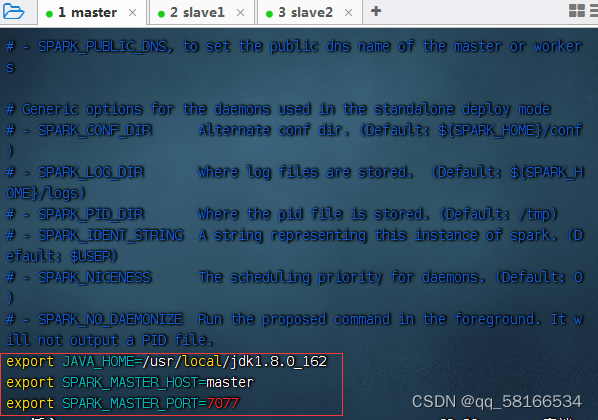
export JAVA_HOME=/usr/local/jdk1.8.0_162
export SPARK_MASTER_HOST=master
export SPARK_MASTER_PORT=7077
存盘退出,执行命令:source spark-env.sh,让配置生效
(三)将spark发送至子节点
scp -r $SPARK_HOME root@slave1:$SPARK_HOME

scp -r $SPARK_HOME root@slave2:$SPARK_HOME发送至slave2
发送spark变量
scp /etc/profile root@slave1:/etc/profile

scp /etc/profile root@slave2:/etc/profile发送至slave2
1.在子节点上source命令,使文件生效
在master虚拟机上执行命令:start-dfs.sh
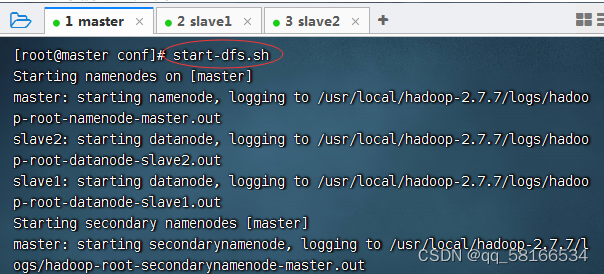
start-all.sh 启动所有spark集群
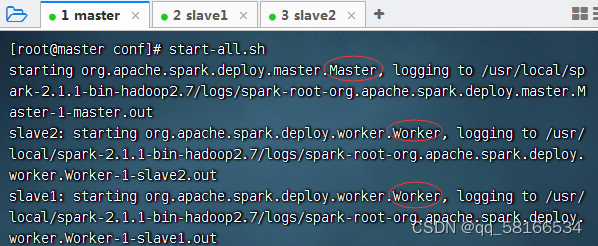
- 查看
start-all.sh的源码启动Master与Worker的命令
# Start Master
"${SPARK_HOME}/sbin"/start-master.sh
# Start Worker
s"${SPARK_HOME}/sbin"/start-slaves.sh
jps查看守护进程
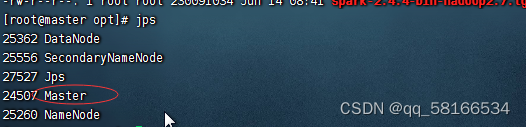
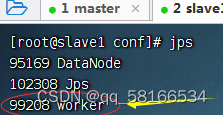
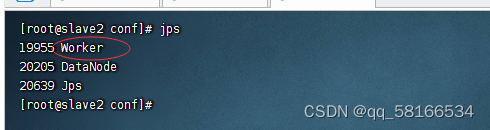
启动spark shell:
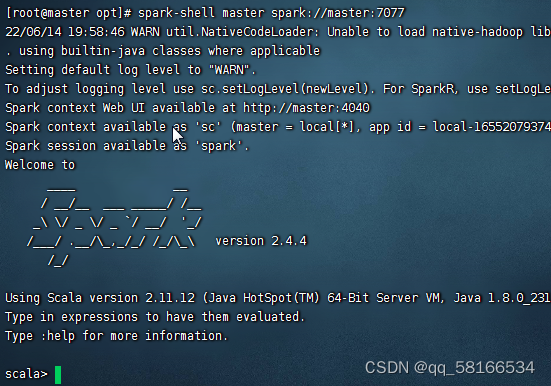
spark-shell --master spark://master:7077















 1346
1346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









