







spark部署运行方式
一、基础
1、Spark 有多种运行模式
(1)可以运行在一台机器上,称为 Local(本地)运行模式。
(2)可以使用 Spark 自带的资源调度系统,称为 Standalone 模式。
(3)可以使用 Yarn、Mesos、Kubernetes 作为底层资源调度系统,称为 Spark On Yarn、Spark On Mesos、Spark On K8S。
2、Client 和 Cluster 提交模式
Driver 是 Spark 中的主控进程,负责执行应用程序的 main() 方法,创建 SparkContext 对象,负责与 Spark 集群进行交互,提交 Spark 作业,并将作业转化为 Task(一个作业由多个 Task 任务组成),然后在各个 Executor 进程间对 Task 进行调度和监控。
根据应用程序提交方式的不同,Driver 在集群中的位置也有所不同,应用程序提交方式主要有两种:Client 和 Cluster,默认是 Client,可以在向 Spark 集群提交应用程序时使用 --deploy-mode 参数指定提交方式。
(1)client模式
1)client mode下Driver进程运行在Master节点上,不在Worker节点上,所以相对于参与实际计算的Worker集群而言,Driver就相当于是一个第三方的“client”。
2)正由于Driver进程不在Worker节点上,所以其是独立的,不会消耗Worker集群的资源。
3)client mode下Master和Worker节点必须处于同一片局域网内,因为Drive要和Executorr通信,例如Drive需要将Jar包通过Netty HTTP分发到Executor,Driver要给Executor分配任务等。
4)client mode下没有监督重启机制,Driver进程如果挂了,需要额外的程序重启。
(2)cluster模式
1)Driver程序在worker集群中某个节点,而非Master节点,但是这个节点由Master指定。
2)Driver程序占据Worker的资源。
3)cluster mode下Master可以使用–supervise对Driver进行监控,如果Driver挂了可以自动重启。
4)cluster mode下Master节点和Worker节点一般不在同一局域网,因此就无法将Jar包分发到各个Worker,所以cluster mode要求必须提前把Jar包放到各个Worker几点对应的目录下面。
3、各种模式对比
| Master URL | 解释 |
|---|---|
| local | 在本地运行,只有一个工作进程,无并行计算能力。 |
| local[K] | 在本地运行,有 K 个工作进程,通常设置 K 为机器的CPU 核心数量。 |
| local[*] | 在本地运行,工作进程数量等于机器的 CPU 核心数量。 |
| spark://HOST:PORT | 以 Standalone 模式运行,这是 Spark 自身提供的集群运行模式,默认端口号: 7077。 |
| mesos-client | ./spark-shell --master mesos://host:port --deploy-mode client |
| mesos-cluster | ./spark-shell --master mesos://host:port --deploy-mode cluster |
| yarn-client | 在 Yarn 集群上运行,Driver 进程在本地,Work 进程在 Yarn 集群上。./spark-shell --master yarn --deploy-mode client |
| yarn-cluster | 在 Yarn 集群上运行,Driver 和Work 进程都在 Yarn 集群上。./spark-shell --master yarn --deploy-mode cluster。 |
二、local
所谓的 Local 模式,就是不需要其他任何节点资源就可以在本地执行 Spark 代码的环境,一般用于教学,调试,演示等。
local: 所有计算都运行在一个线程当中,没有任何并行计算,通常在本机执行一些测试代码,或者练手,就用这种模式。
local[K]: 指定使用几个线程来运行计算,比如local[4]就是运行4个worker线程。通常cpu有几个core,就指定几个线程,最大化利用cpu的计算能力。
local[*]: 这种模式按照cpu最多cores来设置线程数了。
bin/spark-submit \
--class <main-class>
--master <master-url>\
--deploy-mode <deploy-mode>\
--conf <key>=<value> \
... # other options
<application-jar>\
[application-arguments]
三、standalone
在 Spark Standalone 模式中,资源调度是由 Spark 自己实现的。 Spark Standalone 模式是 Master-Slaves 架构的集群模式。
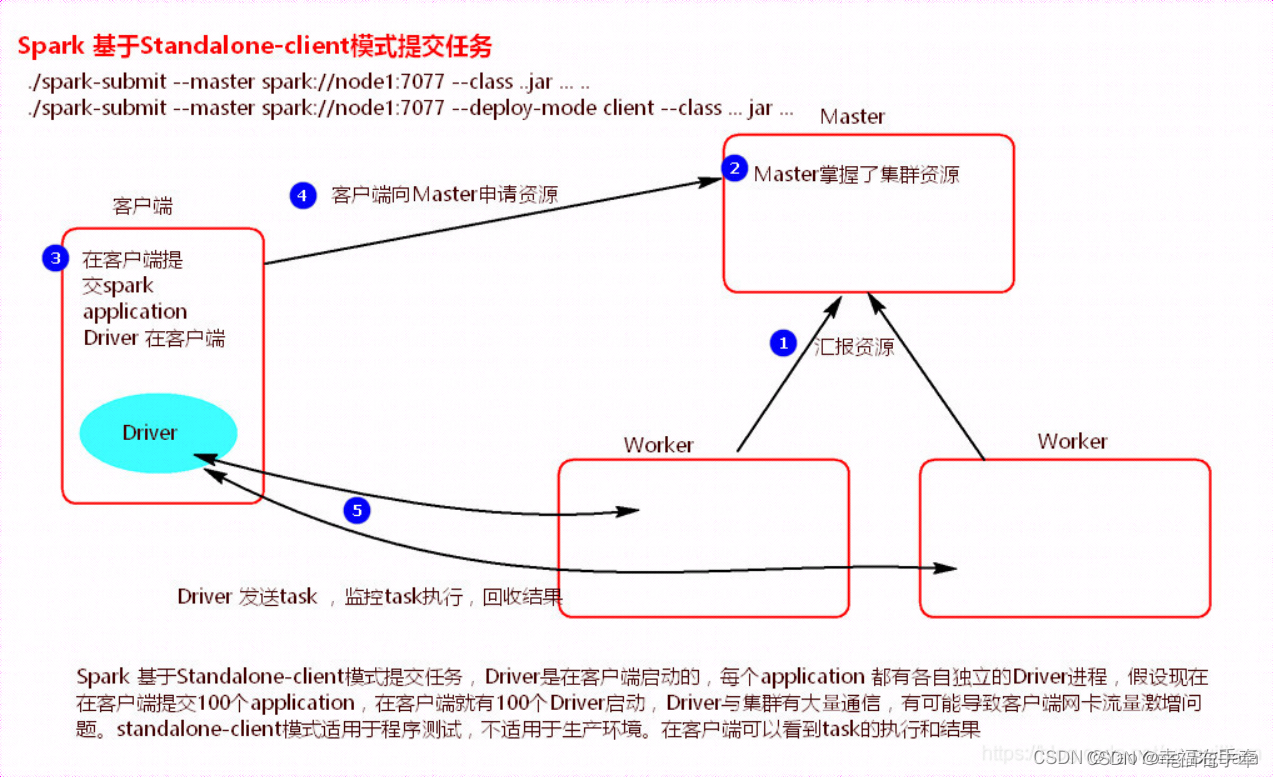
1、standalone-client
./spark-submit
--master spark://node1:7077
--deploy-mode client
--class org.apache.spark.examples.SparkPi
../lib/spark-examples-1.6.0-hadoop2.6.0.jar
100
执行流程
1)client模式提交任务后,会在客户端启动Driver进程。
2)Driver会向Master申请启动Application启动的资源。
3)资源申请成功,Driver端将task发送到worker端执行。
4)worker将task执行结果返回到Driver端。
总结:
client模式适用于测试调试程序。Driver进程是在客户端启动的,这里的客户端就是指提交应用程序的当前节点。在Driver端可以看到task执行的情况。生产环境下不能使用client模式,是因为:假设要提交100个application到集群运行,Driver每次都会在client端启动,那么就会导致客户端100次网卡流量暴增的问题。
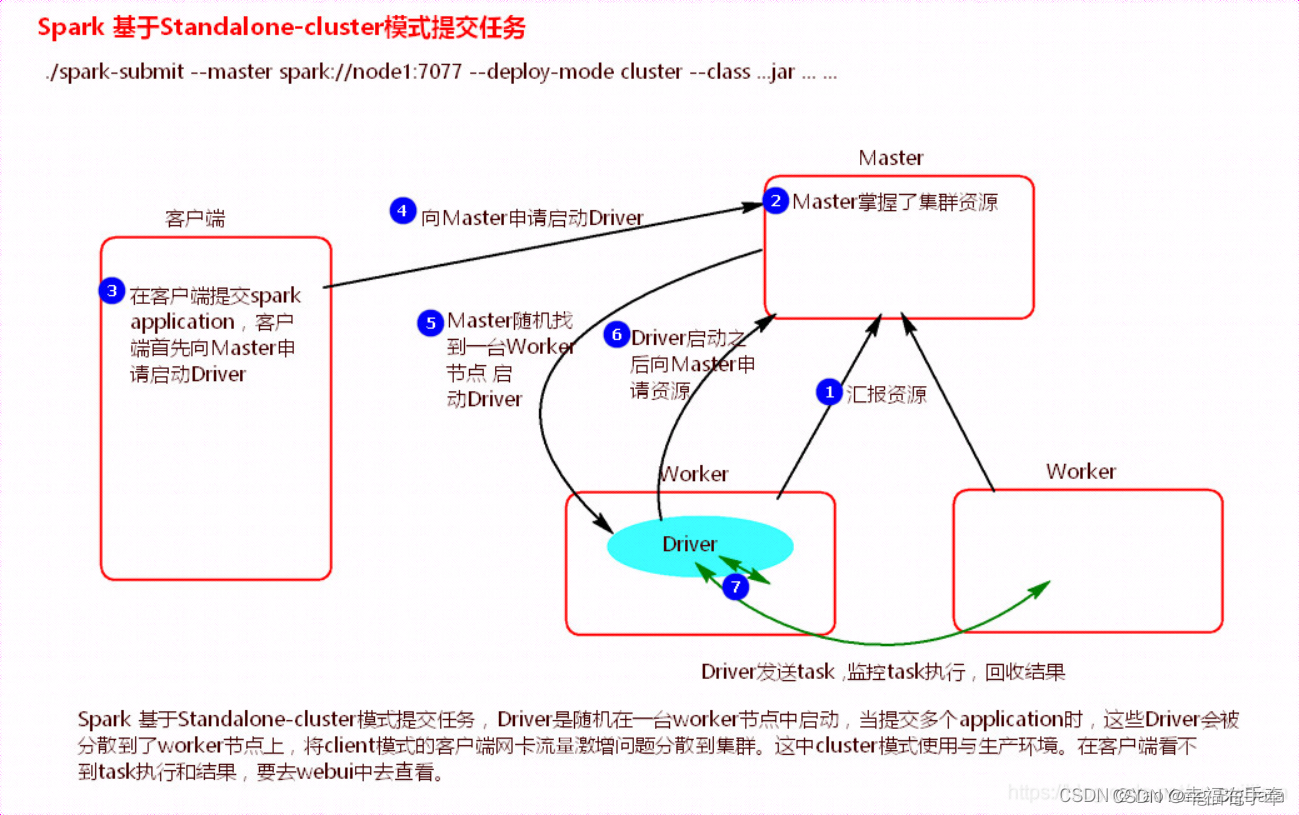
2、standalone-cluster
./spark-submit
--master spark://node1:7077
--deploy-mode cluster
--class org.apache.spark.examples.SparkPi
../lib/spark-examples-1.6.0-hadoop2.6.0.jar
100
执行流程
1)cluster模式提交应用程序后,会向Master请求启动Driver。
2)Master接受请求,随机在集群一台节点启动Driver进程。
3)Driver启动后为当前的应用程序申请资源。
4)Driver端发送task到worker节点上执行。
5)worker将执行情况和执行结果返回给Driver端。
总结:
Driver进程是在集群某一台Worker上启动的,在客户端是无法查看task的执行情况的。假设要提交100个application到集群运行,每次Driver会随机在集群中某一台Worker上启动,那么这100次网卡流量暴增的问题就散布在集群上。
四、yarn
独立部署(Standalone)模式由 Spark 自身提供计算资源,无需其他框架提供资源。这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是你也要记住,Spark 主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是和其他专业的资源调度框架集成会更靠谱一些。
如果采用yarn来管理资源调度,就应该用yarn模式,由于很多时候我们需要和mapreduce使用同一个集群,所以都采用Yarn来管理资源调度,这也是生产环境大多采用yarn模式的原因。
Spark On Yarn 模式的搭建比较简单,仅需要在 Yarn 集群的一个节点上安装 Spark 客户端即可,该节点可以作为提交 Spark 应用程序到 Yarn 集群的客户端。Spark 本身的 Master 节点和 Worker 节点不需要启动。前提是我们需要准备好 Yarn 集群。
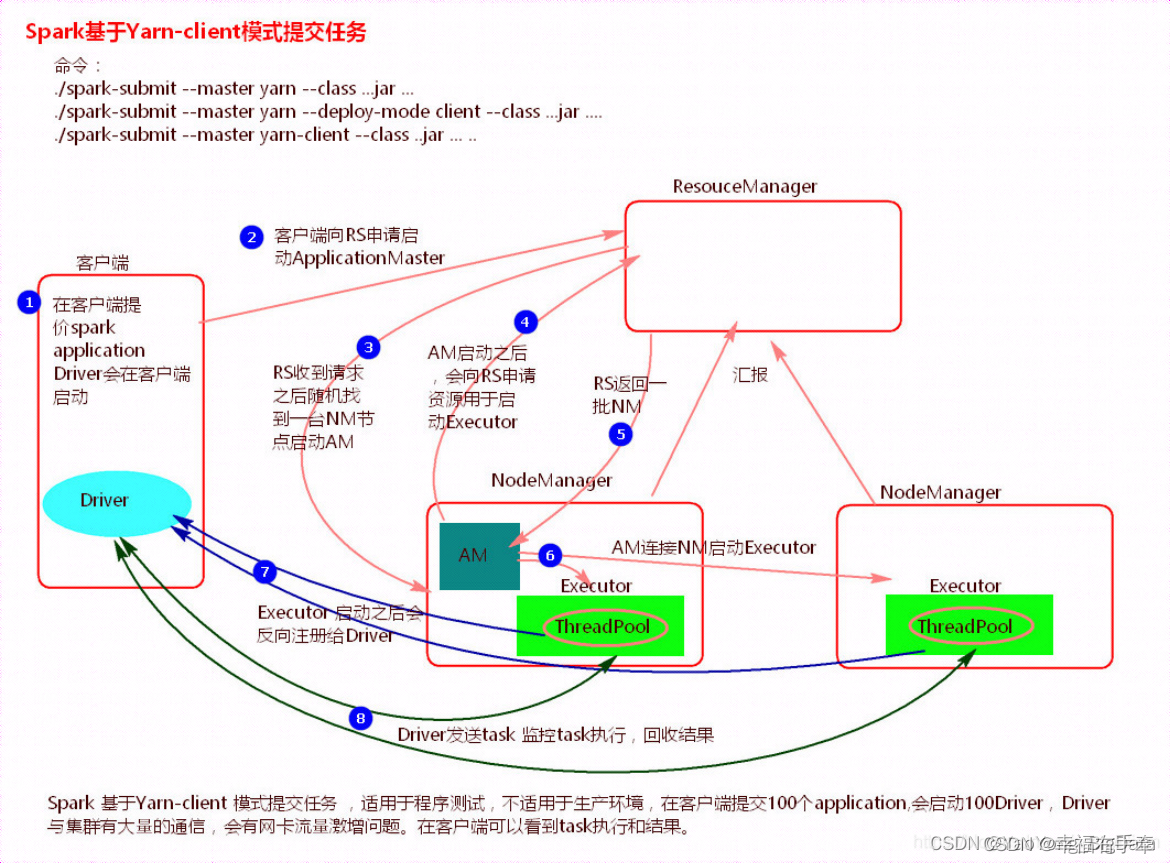
1、yarn-client
./spark-submit
--master yarn
--deploy-mode client
--class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar
100
执行流程
1)客户端提交一个Application,在客户端启动一个Driver进程。
2)应用程序启动后会向RS(ResourceManager)发送请求,启动AM(ApplicationMaster)的资源。
3)RS收到请求,随机选择一台NM(NodeManager)启动AM。这里的NM相当于Standalone中的Worker节点。
4)AM启动后,会向RS请求一批container资源,用于启动Executor.
5)RS会找到一批NM返回给AM,用于启动Executor。
6)AM会向NM发送命令启动Executor。
7)Executor启动后,会反向注册给Driver,Driver发送task到Executor,执行情况和结果返回给Driver端。
总结:
Yarn-client模式同样是适用于测试,因为Driver运行在本地,Driver会与yarn集群中的Executor进行大量的通信,会造成客户机网卡流量的大量增加。
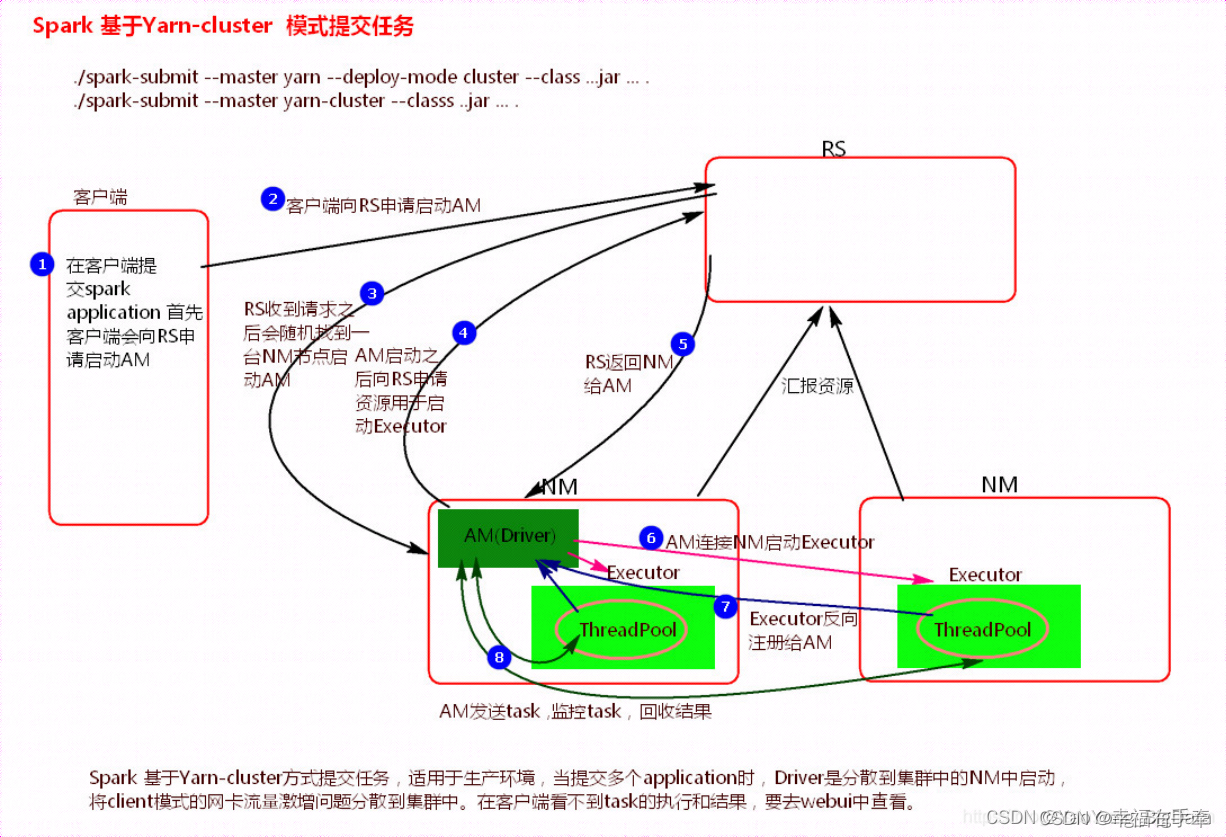
2、yarn-cluster
./spark-submit
--master yarn
--deploy-mode cluster
--class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar
100
执行流程
1)客户机提交Application应用程序,发送请求到RS(ResourceManager),请求启动AM(ApplicationMaster)。
2)RS收到请求后随机在一台NM(NodeManager)上启动AM(相当于Driver端)。
3)AM启动,AM发送请求到RS,请求一批container用于启动Executor。
4)RS返回一批NM节点给AM。
5)AM连接到NM,发送请求到NM启动Executor。
6)Executor反向注册到AM所在的节点的Driver。Driver发送task到Executor。
总结:
Yarn-Cluster主要用于生产环境中,因为Driver运行在Yarn集群中某一台nodeManager中,每次提交任务的Driver所在的机器都是随机的,不会产生某一台机器网卡流量激增的现象,缺点是任务提交后不能看到日志。只能通过yarn查看日志。















 742
742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









