






一、具体语法格式
官方文档对具体的语法格式是这样解释的:
DataFrame.drop(labels=None, *, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
Drop specified labels from rows or columns.
Remove rows or columns by specifying label names and corresponding axis, or by specifying directly index or column names. When using a multi-index, labels on different levels can be removed by specifying the level. See the user guide for more information about the now unused levels.
Parameters
labels: single label or list-like 就是要删除的行列的名字,用列表给定。
Index or column labels to drop. A tuple will be used as a single label and not treated as a list-like.
axis:{0 or ‘index’, 1 or ‘columns’}, default 0 用于确定要删除的是行还是列,0表示行,1表示列
Whether to drop labels from the index (0 or ‘index’) or columns (1 or ‘columns’).
index:single label or list-like,删除的行索引
Alternative to specifying axis (labels, axis=0 is equivalent to index=labels).
columns:single label or list-like,删除的列索引。
Alternative to specifying axis (labels, axis=1 is equivalent to columns=labels).
level:int or level name, optional,只适用于具有多层索引的数据帧,指定要删除的级别。
For MultiIndex, level from which the labels will be removed.
inplace:bool, default False, 指定是否在原始数据帧中进行删除操作。默认值为False。
If False, return a copy. Otherwise, do operation inplace and return None.
errors:{‘ignore’, ‘raise’}, default ‘raise’,指定如何处理无效标签。如果它们是raise,则引发异常。否则,可以将它们忽略或打印警告信息。
If ‘ignore’, suppress error and only existing labels are dropped.
Returns
DataFrame or None
DataFrame without the removed index or column labels or None if inplace=True.
Raises
KeyError
If any of the labels is not found in the selected axis.
二、具体应用举例
import pandas as pd
# 创建一个数据框
data = {'name': ['Alice', 'Bob', 'Charlie', 'David'],
'age': [25, 32, 18, 47],
'gender': ['F', 'M', 'M', 'M'],
'score': [85, 90, 76, 67]}
df = pd.DataFrame(data) 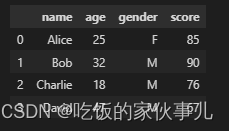
以下举例都是在数据框 的基础上进行。
(一)使用drop()方法删除pandas.DataFrame的行
1.使用索引删除行:
df.drop(1,axis=0) 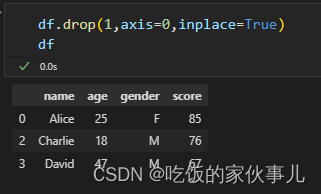
对比结果我们可以看出,索引为1的行被删除了。
2.使用索引删除多行
方法一:直接在列表中列举行索引名称
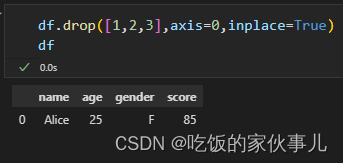
df.drop([1,2,3],axis=0) 与 df.drop(index=[1,2,3])等效。
方法二:使用索引批量删除连续行
(注意此时需要借助df.index)

3. 删除某列指定值所在的行
df = df.drop(df[df['name'] == 'Bob'].index) # 删除姓名列名子叫Bob的行
df 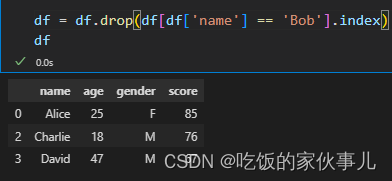
4. 根据某列条件删除多行的值
df = df.drop(df[df['score'] < 80].index) # 删除分数小于80的行
df 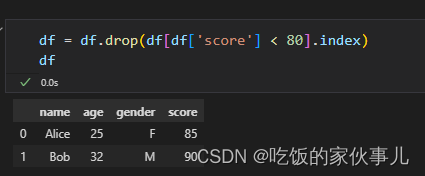
5. 根据多个列的条件删除行
(1)多条件相 或
# 删除性别为M或者分数小于90的行
df = df.drop(df[(df['gender'] == 'M') | (df['score'] < 90)].index)
df 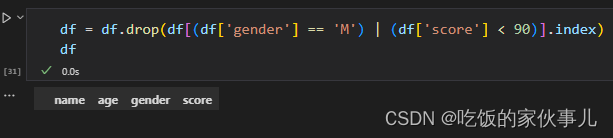
(2)多条件相与情况的删除
# 删除性别为M 同时分数小于90的行
df = df.drop(df[(df['gender'] == 'M') & (df['score'] < 90)].index)
df 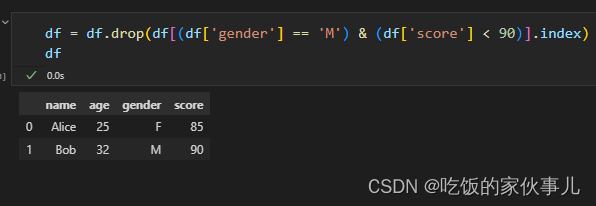
(二)删除列
由于方法和删除行没有本质的区别,简单举例
1.删除单列
# 删除单列
df.drop('score', axis=1, inplace=True) # 注意此处 axis参数为1
print(df)上面语句和下面语句等效
# 删除单列
df = df.drop('score', axis=1) # 注意此处 axis参数为1
print(df)2.删除多列
# 删除多列
df.drop(df.columns[1:3], axis=1, inplace=True)
print(df)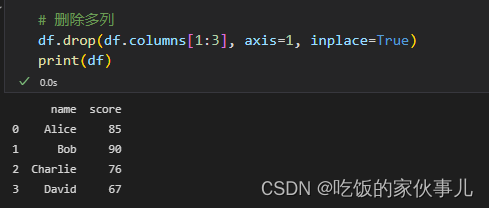
(三)删除重复行
详见前期文章:
数据清洗处理实战:pandas查找与删除重复行(duplicate()与drop_duplicate()方法详解)_pandas删除重复值_吃饭的家伙事儿的博客-CSDN博客
文章总结收集处理不易,帮到您了,别忘了点攒收藏,如有什么问题,欢迎留言讨论。





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











