






TurboEdit: Instant text-based image editing
**摘要:**本文旨在少步骤扩散模型的基础上,实现精确的图像重建与精准的图像编辑(仅修改单个目标属性,保持其他属性不变)。在图像重建方面,设计了一个反演网络(文中用F表示 ),其输入为原图像和上一步网络输出的重建图像,输出预测的噪音图,再把噪音图放入一个Turb的模型中得到重建图像。在精准图像编辑方面,利用大语言模型描述图像生成详细文本,通过修改详细文本中的单个属性,以修改后的文本为指导达成精准图像编辑。该方法运用四次反演(即进行 4 次重建),每次反演时,需先经反演网络F生成加噪后的图像,再借助生成器G得到重建后的图像,因此反演过程共需 8 次函数评估(NFEs),NFEs 用于衡量计算过程中的操作数量。在图像编辑环节,仅需利用图像生成器进行 4 次推理即可完成,无需进行加噪操作。
一,引言
本文主要任务:给定一张真实图像和提示文本(例如把狗换成猫),再保留其他属性不变的情况下实现精准的图像编辑。这个任务分成两个子任务:
- 图像重建:找到一条扩散路径,实现精确的图像重建。这个方式有DDPM,DDIM依旧它们的变体。
- 精确的图像编辑:只改变目标属性对象,其他属性不发生改变。这种方式有:冻结注意力图,优化文本嵌入,或者利用一些特定方法生成配对数据集,这样就不需要进行图像重建和精确图像编辑。
上述这些方法依赖于逐步加噪和去噪,需要的时间步长再30-50步,消耗时间长,交互性差。于是少步骤的方法应运而生,但是多步骤的方法不能直接应用于小步骤的图像。
- 多步骤的DDIM应用于少步骤图像重建:只进行四步的加噪去噪,重建图像会很模糊。
- **冻结注意力机制应用于少步骤图像编辑:**在多步骤扩撒那模型中,生成图像的早期,图像比较模糊,结构不明显,这时候冻结注意力图可以实现大的结构变化。但是在少扩散步骤中,模型是在一步内进行编辑,注意力图结构已经定性了,这时候就很很难实现大的结构变化了,比如把狗变成猫,模型可能无法对狗实现很大的修改。
TurboEdit实现了少步骤的精确重建和编辑。文本主要贡献:
- **提出了一种反演网络F:**这个网络的输入是原图和上一步的重建图像,输出的噪音ϵt,再把这个噪音根据加噪公式带入到x0中得到加噪后图像,然后再把这个噪音图输入到冻结的SDXL-Turbo模型中,生成下一步的重建图。
- **发现了蒸馏特性:**图像经过LLaVA生成长的详细详细文本,我们改变这个详细文本的一个属性,相应的图像空间也只有相应属性的到了修改。
- 快速:相比于其他多步骤的扩散模型,TurboEdit是少步骤的,可以实现快速图像编辑和图像重建。
二,相关工作
***文本到图像扩散模型:***将高斯噪音在以文本提示为条件的基础上生成自然图像,但是生成速度慢,需要30-50步左右的去噪步骤。利用蒸馏方法,对详细文本描述修改目标属性词汇,可以加速这一过程,并且生成质量也较好。
***基于文本的图像编辑方法:***完成这个任务,我们需要干的第一步是确保输入图像和重图像相似。
- 第一种方式是DDIM:需要50个小的的扩散步骤,通常会采用空文本既claasfier-free guidance实现更准确的图像重建。
- 第二种方式是:DDPM,他在图像重建的过程中,每一步都会产生一定的误差,现在我们使用更多的参数和维度来刻画噪音,那么这个噪音蕴含的信息也就越多,误差几类也就越小。
- 第三种方式是:LEdits++,采用高阶求解器和自动掩膜编辑,自动淹没编辑是可以自动根据文本编辑修改修改的掩码。
精确的图像编辑:
- **在早期生成步骤中冻结自注意力和交叉注意力图保持结构相似性:**假设有一张人物的源图像,我们想要将人物的姿势从站立改为坐姿,同时保持人物的面部特征、身体比例等结构信息不变。使用基于注意力的方法,在早期生成步骤中冻结注意力图,可以帮助模型在改变人物姿势的过程中,更好地保留人物的整体结构,避免出现身体部分比例失调等问题。
- **基于优化文本嵌入标记或模型本身的方法:**优化文本嵌入可以让模型更好的理解文本提示,但是这种优化消耗的计算机资源多。
- **基于微调的方式:**例如IP2P在基于合成的三元组数据集上进行模型微调。这种方式的缺点就是无法实现精确的图像编辑。
- **本文方式:**条件反演网络:以上一次重建对象作为条件输入,不断优化重建效果,使得最终生成的图像和原始图像在结构和语义上差距不大(这一点是保证生成图像和原图结构一致)。第二点是文本描述作为条件,利用了蒸馏的特性实现精确的图像编辑。(这一点是保障生成图像和原图只有编辑的地方不一致)。掩码:只修改需要编辑的地方,其他地方不改变。
下面这张图展示了:以 SDXL Turbo 为基础模型进行实验,发现 DDIM 和 DDPM 反演方法在单步反演时无法成功,四步反演时也存在不能有效改变结构和产生伪影的问题。

三,实现方法
3.1,预备知识
条件扩散模型和普通的扩散模型的的原理大致一样。
**扩散过程:**是指在T个时间步内逐步向一张干净的图像x0中添加不同量的高斯噪音,让其最后结果Xt趋于高斯分布N(0,I),加噪公式如下:
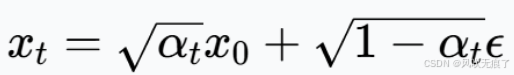
去噪过程:通过一个U-Net网络来逐预测噪音,从噪音图像Xt开始逐步去噪,得到干净的图像x0,目标函数如下:模型ϵθ输入Xt,t和文本提示c,预测噪音ϵt,不断最小化预测噪音和真实噪音的L2范数
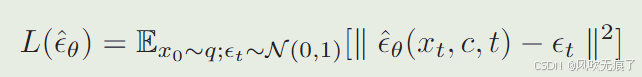
**重建过程:**在模型训练好之后,我们将预测的噪音带入到扩散过程中的公式中进行整理,就可以根据xt对图像进行重建得到x0了。普通情况下,这种去噪过程要20-50步,但是随着蒸馏方式的提出,我么可以实现在1-4步内高质量的图像重建。
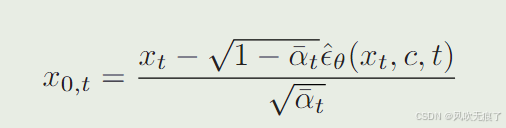
3.2,单步图像反演也叫单步图像重建
目前对于精确图像编辑依旧存在许多方法,但是那些方法都是基于多步骤进行扩散的,不适合交互式使用。而且由于设计的限制,无法直接将多步骤扩散直接应用到少步骤中。例如DDPM,和DDDIM直接用到多步骤的话,会使生成结果产生伪影。本文的思想借鉴于GAN的编码器思路。训练两个模型F和G。F是预测加噪后的图像XT,G 是将加噪后的图像进行恢复或编辑。
单步图像重建的思路:(G网络不需要训练,F网络需要训练)
- ***反演网络F:**这个网络模拟的其实是扩散模型的加噪过程。模型的初始化是SDXL-Turbo(这其实就是经过蒸馏的SDXL模型)。模型的输入是:原图x0,时间步t,文本条件c。输出预测加入x0的噪音ϵt,*然后将噪音和x0结合得到噪音图xt。
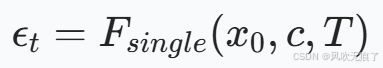
经过F预测出加入到x0的噪音后,代入公式得出xt
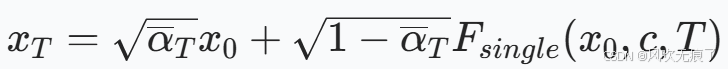
它的损失函数是将xt带入G中生成重建图像x0,t;在比较x0与x0,t之间的差异。
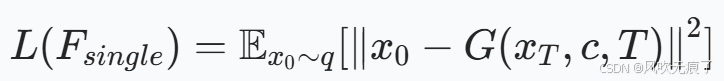
- ***生成器G:***在这里我们用的网络架构是SDXL-Turbo。模型的输入是时间步t,文本提示c,F输出的噪音图XT。输出是重建图像x0,t。
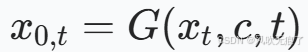
***单步图像编辑的思路:***反演网络F不变,保存F输出的噪音和每一过程的重建图像,根据这两个值得到xt带入到G中,再把G中的文本描述变为经过修改之后的文本表述,表达式如下。
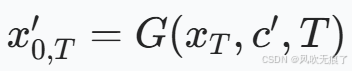
这种单步编码器的方式可以在保留细节的同时进行很好的编辑。但是它的生成结果有时候会产生伪影和椒盐噪音(图像随机出现白色和黑色像素点),质量依旧不是很高。于是作者就想到了多步图像反演和编辑。
3.2,多步图像反演
多步图像反演其实就是单步图像反演中将F中的条件多加了一个上一步的重建图像x0,t。对于t=T时(T是从大变小),由于第一次没有重建图像,我们第一次就设置为全零矩阵进行代替。以下是多步骤的图像重建过程:
多步骤图像重建:
- ***反演网络F:***模型的输入是:原图x0,上一步重建图像x0,t+1,文本描述c,时间步t。输出是加入到x0中的噪音。
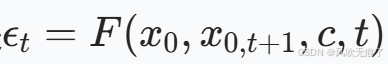
把这个预测的噪音带入到加噪公式,得到xt
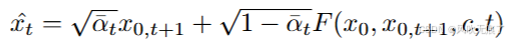
这样我们就得到了反演网络F需要的输出,等同于扩散模型的扩散过程。它的损失函数就是将xt带入G中生成重建图像x0,t,再比较重建图像和x0之间的L2范数:
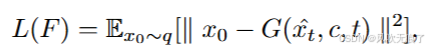
- ***生成器G:***同样是不训练的所以它的目标和单步图像反演没有区别。
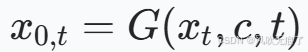
***多步骤图像编辑:***和单步一模一样,F保持不变,把G中的文本描述变为经过修改之后的文本表述。
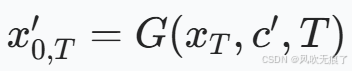
3.3,本文方法
当直接应用模型F预测的噪音后,这个噪音包含许多高值,噪音蕴含较多图像的结构信息,这会导致重建图像出现伪影。于是作者采用重参数化的思想,网络F预测的不再是噪音,而是噪音分布的均值和方差,在经过重参数化从分布中进行采样,得到预测的噪音。
-
模型F预测的是噪音的分布。如果图像是23233。那么模型的输出是两个23233的矩阵,代表每个像素的均值u,和方差σ2
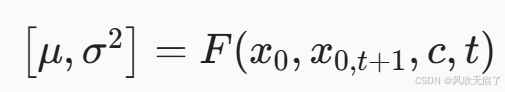
-
将得到的均值和方差经过重参数化得到我们需要的噪音
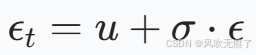
-
这个噪音就是我们预测的加入到x0中的噪音。然后按照多步骤同样进行即可。
-
我们现在预测的是均值和方差,那么这同样是一种损失,所以这部分的损失函数为将预测的噪音的分布同标准正太分布的KL散度
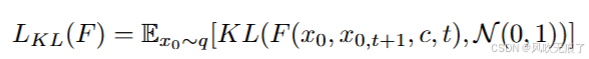
-
结合重参数化和训练损失,我们总体的训练目标是二者加权之和,λ是一个超参数,用来平衡重建质量和可编辑性。λ越大,可编辑性越大,可能会牺牲一点重建质量。

本文发现多步骤图像反演只需要设置为4步就可以达到很好的效果,网络F其实就是用来预测噪音,给定噪音和改变之后的文本描述c‘,我们就可以生成一张新的图片得到精确编辑后的图像。对于一张需要编辑的图片,我们首先要进行4次F,4次G进行图像重建。然后把4次F得到的结果和新的文本描述输入到G中,经过四次编辑得到最终图像。所以我们编辑一张图片要经过8+4=12次,重建的话只要经过8次。
***图释:***下面这张图是不同步骤数的编辑效果,以第一行人脸为例,可以发现,单步图像反演虽然能捕捉到输入图像的大部分信息,但是无法很好的保留图像中物体的特征和局部细节,并且在背景区域有伪影。

3.4,图像精确编辑——详细文本
之前的实现图像精确编辑的方法有冻结注意力图,但是再少步骤扩散中无法进行大结构改变的图像编辑。作者的思路是如果我们给定的描述文本是非常详细的话,那么我们修改文本提示中的单个属性,那么改变之后的文本描述和原来相比只有微小的变化。单个属性的变动对整体语义结构影响有限,这样就不会使模型采样和原图差距太大,从而使除了被修改的属性其他和原图几乎完全相同。为了从原图到目标图像平滑过度。作者提出了一种线性插值技术,用户很难写出详细的文本描述,所以作者使用chatGPT或LLaVA生成详细的文本描述。
方法对比:本文和之前的方法在精确图像编辑上的对比
- 操作空间:之前在文本嵌入空间实现关键词替换,本文操作空间是文本空间
- **控制编辑强度:**之前的方法是通过重新缩放描述性单词嵌入的权重或者奇异值分解,本文是采用线性插值。
**线性插值例子:**假设源文本提示是:一只白色的狗在草地上玩耍,对应的文本嵌入是v0=[0.2, 0.3, 0.5 ];修改之后的文本是:一致黑色的猫在森林中奔跑,对应的文本嵌入是v1=[0.6, 0.7, 0.8]。进行线性插值,假如插值因子是t=0.5,那么根据线性插值公式v = (1-t)v0 + t v1=[0.4, 0.5, 0.65]得到新的文本描述就是一个中间向量,这样就可以生成介于原图像和目标图像之间的中间图像,实现平滑过渡。
***图释1:***下面这张图是线性插值的之间平滑过度的图像:

***图释2:***下面这张图展示了我们采用的详细文本相比于短文本的优势:短文本会对图像重建造成大的结构变变化。文本描述:
**Short Text: “**a man wearing a trench coat (, a hat,) with black hair (in heavy snow).”
Detailed Text: “a young man wearing a brown trench coat (and a hat,) and grey t-shirt with black
hair, standing in front of subtropical flowers (in heavy snow). He is looking directly at the camera,
giving a sense of focus and determination. The coat is open, revealing the man’s attire underneath.
The overall scene is well-lit, with the man being the main subject of the image.”
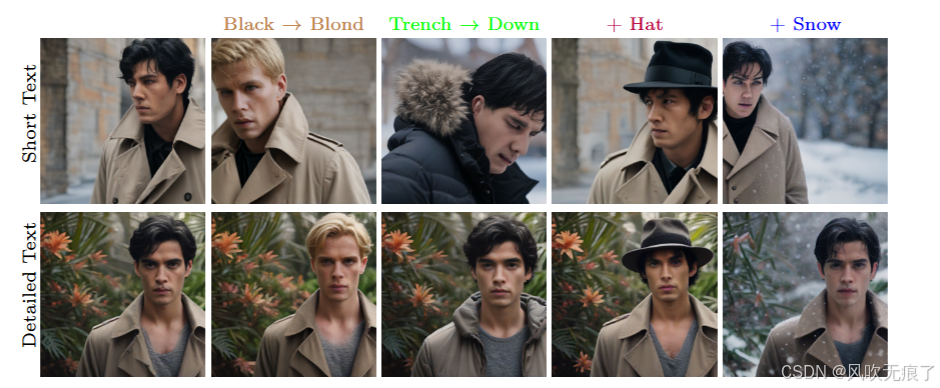
3.5,掩码的选择
- ***掩码的作用:***是选择编辑区域,编辑区域用编辑后的图像,未编辑区域用重建的图像
- 掩码的产生方式:有两种,手动绘制的精确掩码和注意力机制的生成的粗糙掩码,本文采用都是粗糙掩码,以达到快速的图像编辑。
- ***注意力机制掩码的制作方式:**对于详细文本,我们将其转化为一个个token,我们只提取目标文本与源文本不一致token的注意力图(分辨率在1616),然后在通道维度上进行相加求和然后除于其中的最大值,那样我们就可以得到一个单通道的注意力机制掩码了。里面的值全在0-1之间。对于需要编辑的区域,都是较大的值。于是我们设置一个阈值为0.6,大于0.6的为1,小于为0,将连续的注意力掩码转为二进制掩码。
3.6,流程图和原理图
- ***图像反演的基本流程:***将T时刻的前一步重建图像设置为0,T从大到小开始,先把通过网络F预测噪音,把噪音带入加噪公式得到xt,再把xt带入到生成网络G中的到重建图像。保存F网络预测的噪音和重建图像。

- ***图像编辑的基本流程:*图像编辑永远在图像重建之后,如果你想编辑一张图像,先经过重建过程,得到预测的噪音ϵt和重建图像x0,t;将第一次重建对象设置为0,带入加噪公式得到xt,把这个xt和改变之后的本文描述带入到G中得到编辑之后的图像x0,t’。如果有掩码,则按照掩码将重建图像x0,t和编辑后的图像x0.t’进行融合,然后得到最终第一次编辑之后的结果。再把这个结果加噪,依次进行4次。

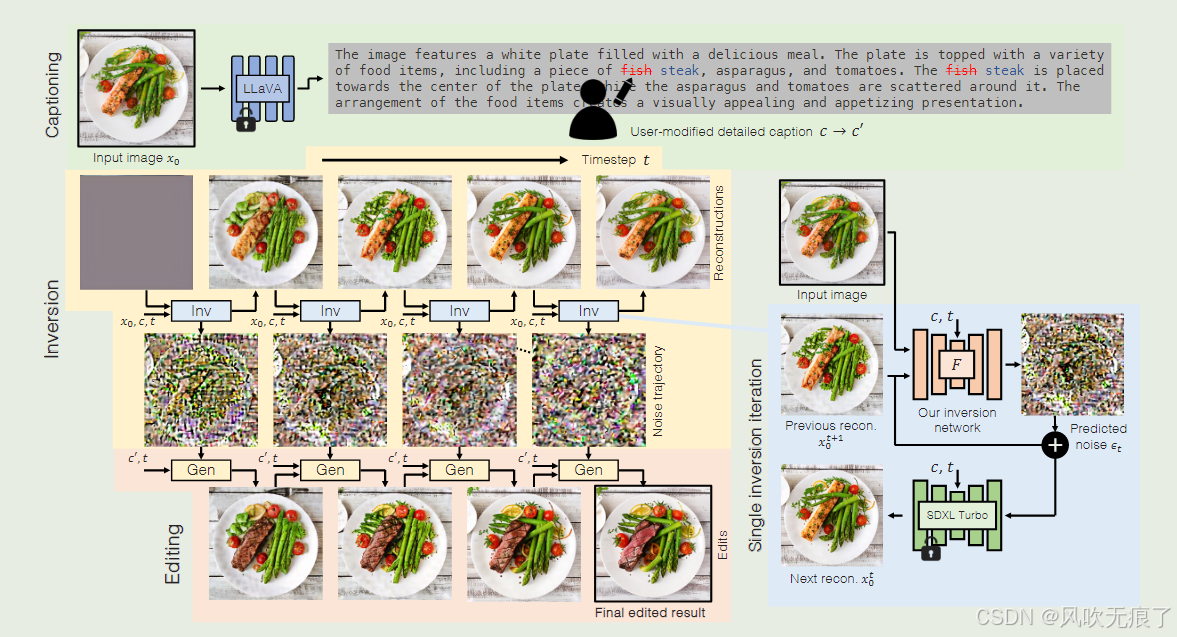
- ***图像编辑的整体过程介绍:***任务的输入是原图和指令条件:把图中盘子中的鱼肉变为牛肉。
- 生成文本描述:将图片和指令输入到 LLaMA 模型中,生成关于原图的详细文本描述 c,以及针对期望改变的详细文本描述 c′。这里需要注意的是,确保输入的指令能够准确引导模型生成符合需求的文本描述,以便后续基于这些描述进行图像操作。
- 训练阶段的反演过程:在训练时,对原始图像 x0 随机添加一个高斯噪声,得到带噪图像 xt+1。然后,通过单步的 SDEdit 对 xt+1 进行处理,生成的结果作为 t=T 时的重建图像 x0,T+1(在推理阶段,将 t=T 时的上一次重建图像 x0,T+1 设置为全零矩阵)。接下来,将原始图像 x0、重建图像 x0,T+1、文本描述 c 以及时间步 t 一同输入到网络 F 中,预测出噪声 ϵt,T。根据噪声公式将该噪声添加到 x0,T 中,得到加噪图像 xt,T。再把加噪图像 xt,T 输入到生成器 G 中,生成重建图像 x0,T−1。按照这样的方式依次类推,得到噪声序列 ϵt,T,ϵt,T−1,ϵt,T−2,ϵt,T−3和重建图像序列 x0,T−1,x0,T−2,x0,T−3,x0,T−4。
- 图像编辑阶段(训练时):在训练进行图像编辑时,将步骤 2 中得到的 x0,T+1、噪声 ϵt,T 以及新的文本条件 c′ 输入到生成器 G 中,得到编辑后的图像 x0,T−1′。
- 图像编辑的组合与迭代过程:将得到的 x0,T−1′ 和 x0,T−1 按照掩码 m 进行组合,得到 t=T−1 时的编辑图像。然后,把这个编辑后的重建结果 x0,T−1′ 输入到生成器 G 中,得到 x0,T−2′。按照这样的方式依次类推,逐步完成整个图像编辑过程。
4,实验分析
4.1,实验设置
- 训练数据集:没有指明数据集来源和数据集的类型。在数据集中找到25万张像数值大于512512的图片,再将其进行中心裁剪得到25万张512512的数据集。
- **模型训练:**反演网络F和生成网络G均以SDXL-Turbo初始化,但是F是需要训练的,G是不训练。SDXL-Turbo再训练时加噪要很多不步,本文设置了的时间步为(1000,750,500,250),但是再推理阶段只要一步生成。
- **参数:**学习率选择10-5,再八块A100的GPU训练一天。
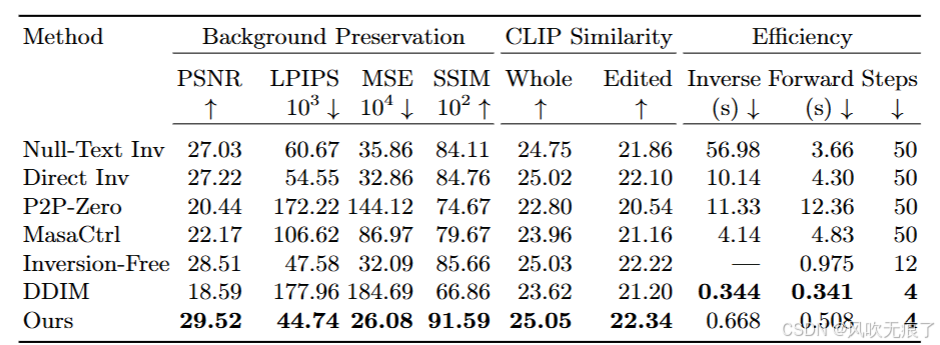
4.2,定量比较
- **比较数据集:**对于模型评估我们是在PIE-Bench数据集上进行的,这个数据集包含700张图像,每个图像有10种不同的编辑类型,每个样本都包含:源文本提示,目标文本提示,指令文本提示和原图像。例如(源图像:一张棕色的狗在绿色草地上奔跑的照片;源文本提示:一只棕色的狗在绿色草地上欢快地奔跑;目标文本提示:一只白色的猫在绿色草地上安静地坐着;指令文本提示:把动物从狗换成猫,改变颜色为白色,将动作从奔跑改为坐着)。
- **比较方法:**基于指令的方法,基于文本描述的方法。为例公平起见,为了描述性文本实现较为精确的图像编辑,我在对描述性的方法在生成早期冻结注意力图。对于本文方法我们将指令输入到LLaMA生成详细的文本描述。
- **分析:**从下面的表格可以看到,我们的方法效果优于其他的方法,背景保留能力效果最好,生成区域的CLIP相似度(文本-图片)最好,并且生成速度只低于DDIM。
4.3,定性分析

从这张图我们可以得出:DDIM生成结果会产生伪影,DDPM生成图像和原图差异较大,本方法生成结果和原图非常相似,经过在手和脸部区域存在一些小的掩码。

从这张图我们可以得出:这比较的是四步方法和其他多步骤扩散且使用描述性提示作为指导的方法。InfEdit 和 Pix2PixZero 扭曲了诸如房屋、泰迪熊和吉他等物体的结构;Ledits 和 Ledits++ 在处理较大的结构变化时遇到了困难,比如添加一顶帽子或把一个男人变成一个女人。相比之下我们的方法在进行准确编辑的同时还能很好的保留不需要编辑的结构和纹理。

这比较的是本文和基于指令的编辑方法:InstructPix2Pix需要大规模的特殊训练集,而本文只要通过重建损失进行训练,效率更好,并且相比其他方法在内容保留和文本一致性方面实现的很好。
4.4,消融研究
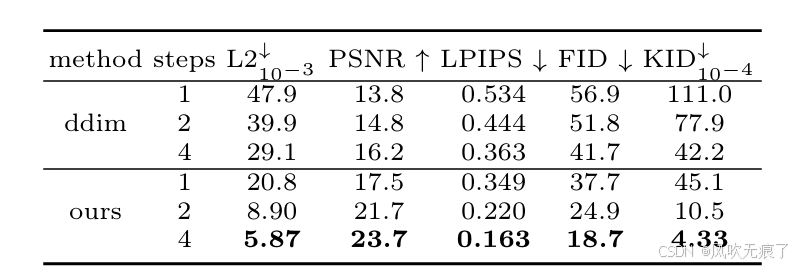
- **消融研究1:**不同反演步骤下的可视化结果。随着反演步骤的增肌,重建效果逐渐变好

- ***消融研究2:***详细文本提示的作用,详细的文本提示在保持图像中物体和场景(物体形状,位置关系)依旧防止出现伪影有着关键影响。

- ***消融研究3:***有无掩码,精确掩码和粗糙掩码,有掩码比没有掩码效果好,没有掩码会导致背景区域发生一些改变。精确手绘掩码比粗糙注意力机制掩码效果展示好,可以发现使用粗糙的注意力机制掩码生成的图片在红色区域和原图不一致。所以文本并不是完全的精确编辑。但是速度快。


4.5,不足和可以改进的地方
- 模型瓶颈问题:LLaVA 模型在生成详细图像说明文字方面被使用,但因为该方法反演步骤少,而 LLaVA 计算量大,所以它限制了整个系统的效率,需要寻找更轻量的替代模型来实现实时图像反演,提高系统运行速度。想法:可以使用一些轻量级的网络,比如:Xmodel-VLM等
- 注意力掩码的局限性:注意力掩码虽能限定编辑区域,但存在精度问题,会覆盖周边区域,提高阈值也无法彻底解决。在靠近人脸等对身份特征敏感的区域编辑时,会导致身份特征轻微偏移,用户提供的粗略掩码可在一定程度上改善这个问题。想法是否可以通过制作精确的掩码来解决这个问题:比如论文,ZONE:零样本指令引导的局部图像编辑
- 姿态变化编辑的不足:该方法在处理较大的姿态变化编辑任务时存在能力局限,如不能将跑步的人变为坐着的人。想法:是否可以通过制作掩码来实现大姿态的图像编辑。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









