






了解Redis用处
Redis是一个内存中存储数据的中间件; 用于作为数据库, 用于作为数据缓存;并且在分布式系统中也能大展拳脚;
作为数据库:与MySQL相比Redis的访问速度比较慢,Redis的空间有限;、
作为数据缓存:通常缓存20%的热点数据,还有临时性的数据(不用入库的数据,用了就销毁的数据),作为session存储;
注:Redis存的是部分数据;全量数据都是以mysql为主;哪怕Redis的数据没有了,还可以从mysql这边加载回来;
关于session的存储:
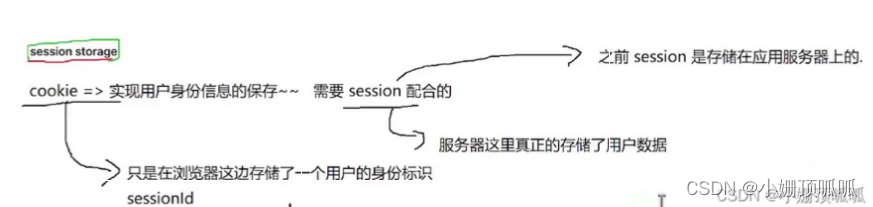
现在我们变成了分布式系统,組引入了负载均衡器,如果我们要把session会话存在服务器上,会出现一个问题:如下图:登录一次后在一个服务器 上存了session,下一步操作的时候通过负载均衡器就访问到别的服务器上了,没有上一次的绘画内容; 就得重新登录;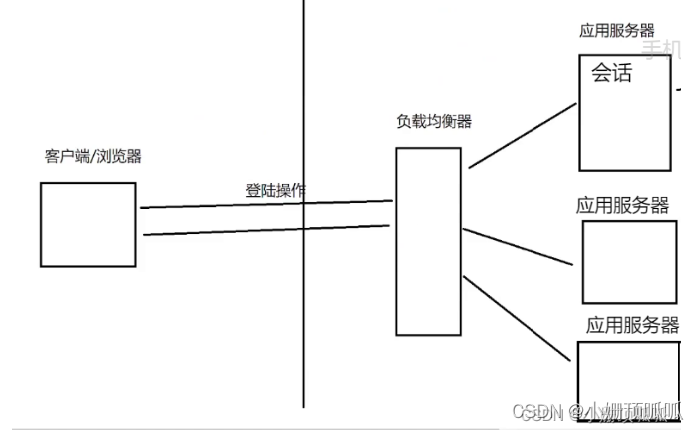
解决这一问题的方法
1.让负载均衡器把同一个用户的请求始终达到同一 个服务器 上(不要轮询,通过userid类的方式来分配机器)
2.把会话数据单独拎出来,放到-组独立的机器上存储(Redis)
redis为啥快?
1. Redis数据在内存中.就比访问硬盘的数据库,要快很多
2. Redis核心功能都是比较简单的逻辑~~核心功能都是比较简单的操作内存的数据结构~~
3.从网络角度上, Redis使用了10多路复用的方式(epoll),使用一个线程,管理很多个socket ~~
4. Redis使用的是单线程模型(虽然更高版本的Redis引入了多线程)这样的单线程模型,减少了不必要的线程之间的竞争开销
下载安装Redis
1.搜索redis安装包
2.搜出来的安装包(装下面这个绿色标记出来的版本)
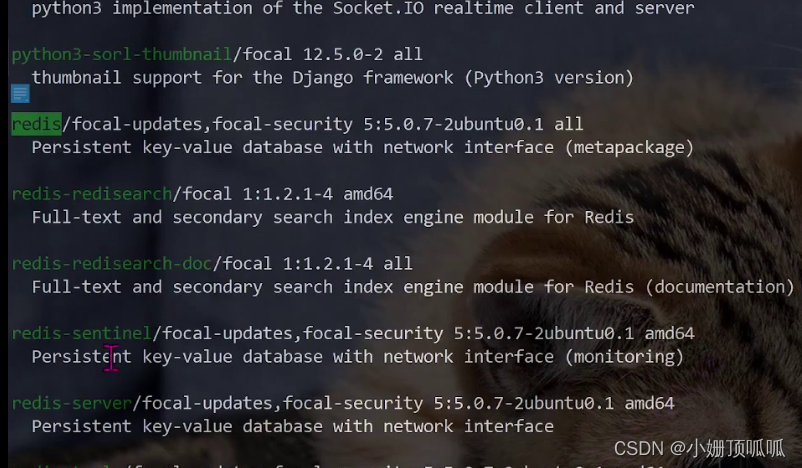
3.下载安装这个 (搞好了就默认redis启动起来了)
4.用这个命令查一下启动好没有(redis默认端口就是6379)
这个127.0.0.1这个是环回ip需要修改配置文件

修改配置文件
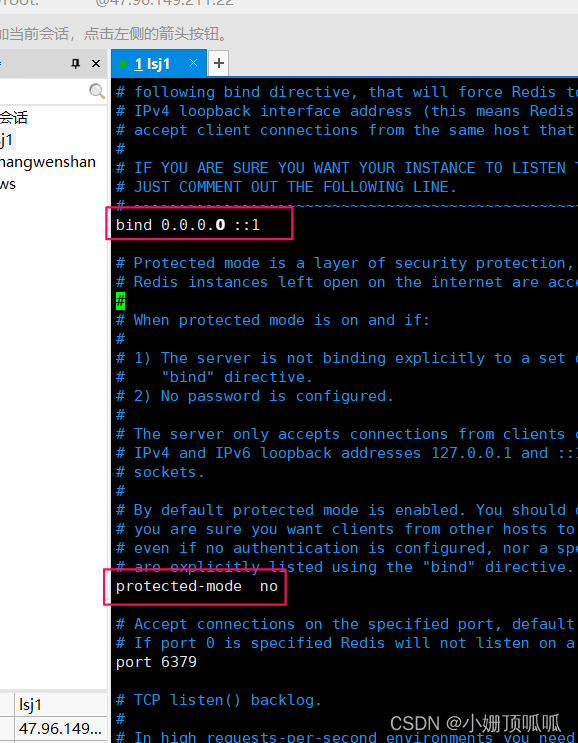
安装好了之后修改配置文件(因为这个ip是本地环回IP,跨主机访问不了)
先 cd /etc/redis/ 然后ll 最后 vim redis.conf进入配置文件

修改下面这两个地方
重启服务器service redis-server restart
查看服务器运行状态service redis-server status 下图(active(running))就是正在运行之中的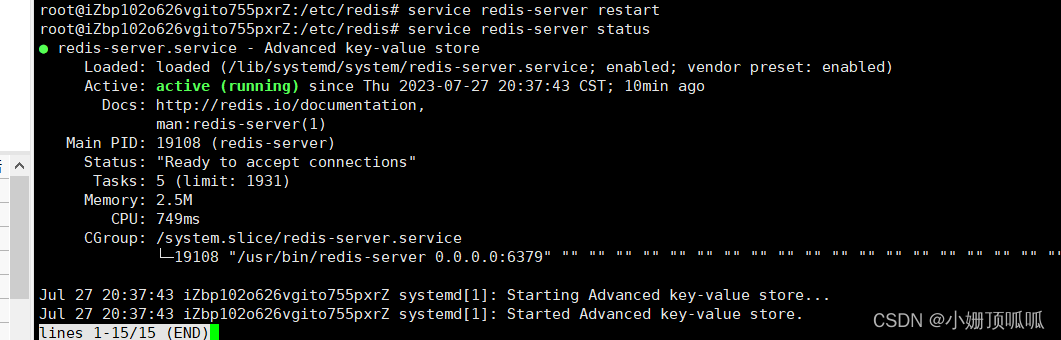
使用redis自带的客户端连接到服务器
redis-cli
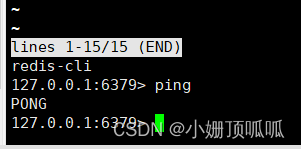
ping-pong命令是--*作*=为连通性的测试
写ping他返回pong这样就连好了,ctrl+d就退出了客户端
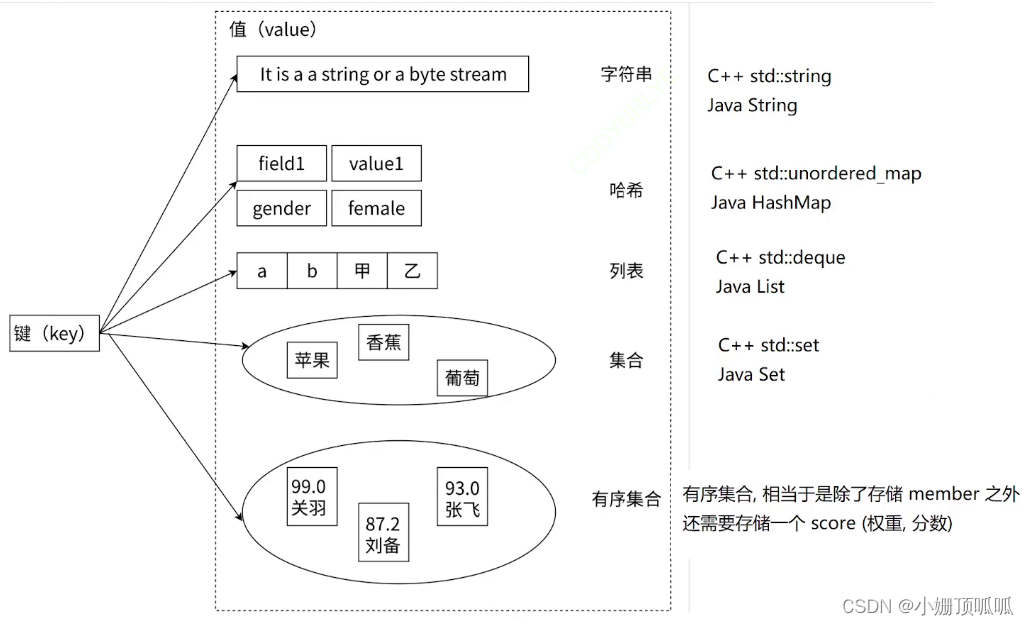
Redis的命令: (redis支持多种数据结构:key固定是字符串,value是多种类型【字符串,哈希表,列表,集合,有序集合】,每种类型都有不同的命令)也有全局命令,就是能够搭配任意一个数据结构来使用的命令。
全局命令:keys:

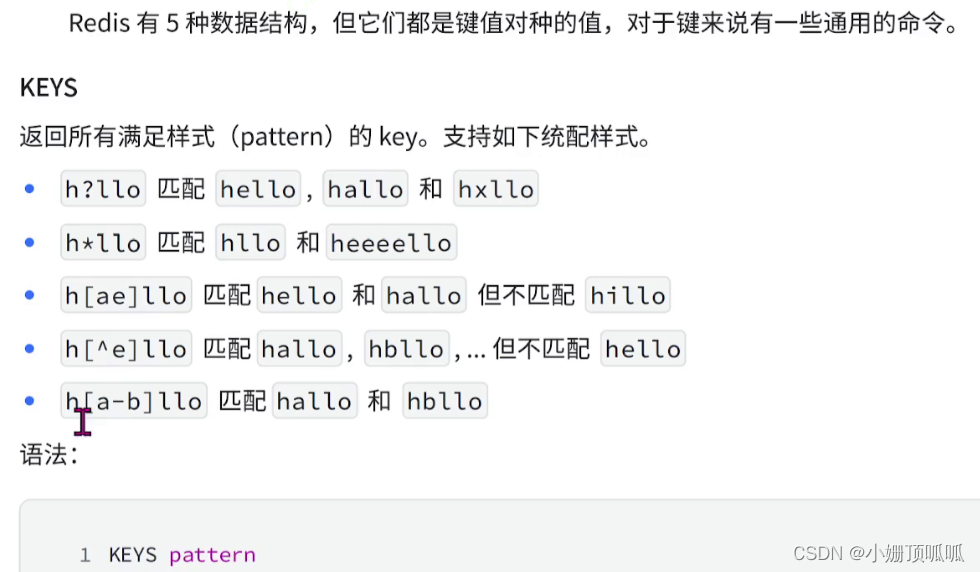
生产环境里不要用keys*容易搞挂
全局命令:exists:

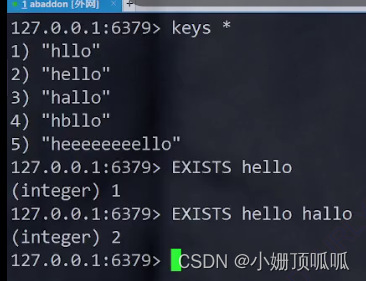
这里返回的1 和 2都是存在的意思
redis很多命令都是支持一次就能操作多个key的。因为分开写会产生多轮次的网络通信(产生多次的封装和分用) 与直接操作内存比起来导致效率低,成本高。
全局命令:del 语法:del key
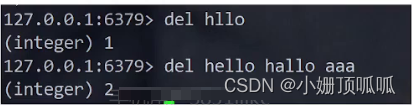
这上面是返回key删除的个数;
在redis作为缓存场景下:redis的删除不是很危险,因为只是一部分热点数据;
在redis作为数据库场景下:redis的删除有危险;
在作为消息队列的场景下:要看具体的业务场景;
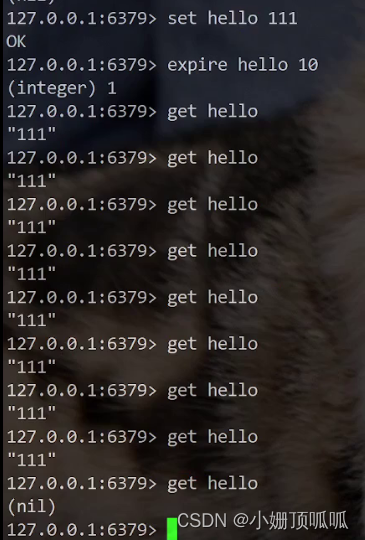
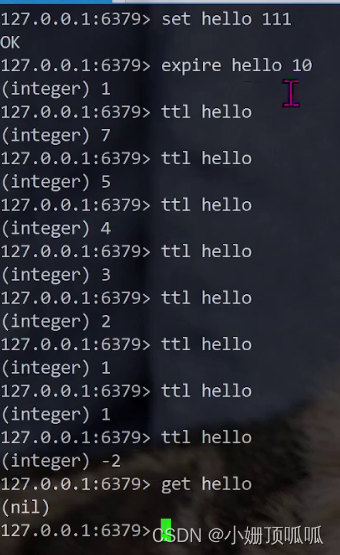
全局命令:expire:语法:expire key 秒数
用于设定过期时间;应用场景类似于5分钟内验证码失效
下面这个例子就是给hello设置10秒的存在时间,过了10秒就拿不到hello了
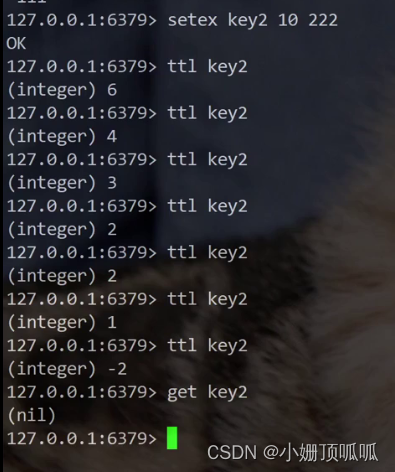
全局命令:TTL
获取指定key的过期时间,秒级。语法:TTL key; 返回值:-1表示没有关联过期时间,-2表示key不存在。
总结:全局命令

经典面试题: redis的key的过期策略怎么实现的?
(一个redis中可能同时存在很多key,这些key中可能大部分都有过期时间,redis咋知道哪些key过期了要被删除,哪些key还没过期?)
redis整体的策略是:1.定期删除(隔一段时间看有没有过期)
2.惰性删除(在用之前检查一下他过期没有,过期了就删掉;平时不删;)
Redis里value的类型:主要有 none,string,list,set,zset,hash,stream(作为消息队列用到的类型).
不同的value类型 插入 命令不一样
none类型: 不用插入
string类型: set
list类型 : lpush(相当于left插入也就是头插)
set类型 : sadd
hash类型:hset


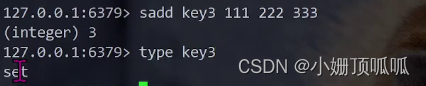
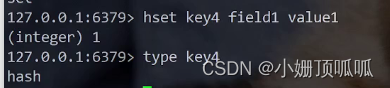
认识每个类型:
多个请求同时到达Redis服务器要在队列中排队,等redis服务器一个一个取出里面的命令执行;微观上讲redis服务器是串行/顺序执行这多个命令的;
一个重要面试题:
redis虽然是单线程模型,为啥效率这么高?速度这么快?(参照物是数据库:SQL,oracle)
1.redis访问内存;数据库则是访问硬盘;
2.redis核心功能,比数据库的核心功能更简单;(比如,针对插入删除,数据库中的各种约束,都会使数据库做额外工作;或者查询的时候排序,查询的时候做个表达式,或者分组,联表查;相比与redis就是按照key取value,普通的增删改查)
3.单线程模型,避免了不必要的线程竞争开销;(因为redis每个操作都是短平快的,就是简单操作内存数据,不是特别消耗CPU的操作,就算搞多线程提升也不大)
4.处理网络IO的时候,使用了epoll这样的IO多路复用机制;(一个线程管理多个socket;Linux上提供IO多路复用,主要三套API其中 epoll是比较新的,效率高的)
set命令:
运用一下nx 和xx

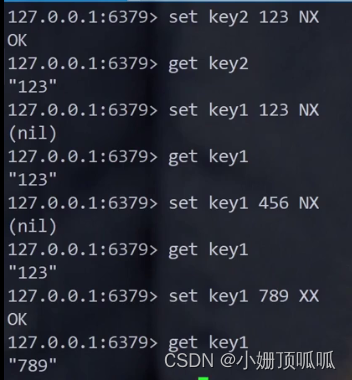
get命令:
对get来说,只是支持字符串类型的value。如果value是其他类型,使用get获取就会出错!

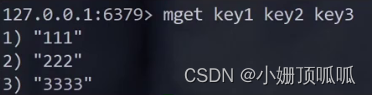
mget 和mset命令:
一次操作多组键值对,因为每次操作redis命令是一次网络传输,如果能一次操作多组键值对就能减少开销;
语法:MSET key value [key value...]
mget key1 key2 key3

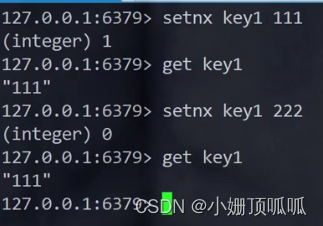
命令 setnx setex psetex

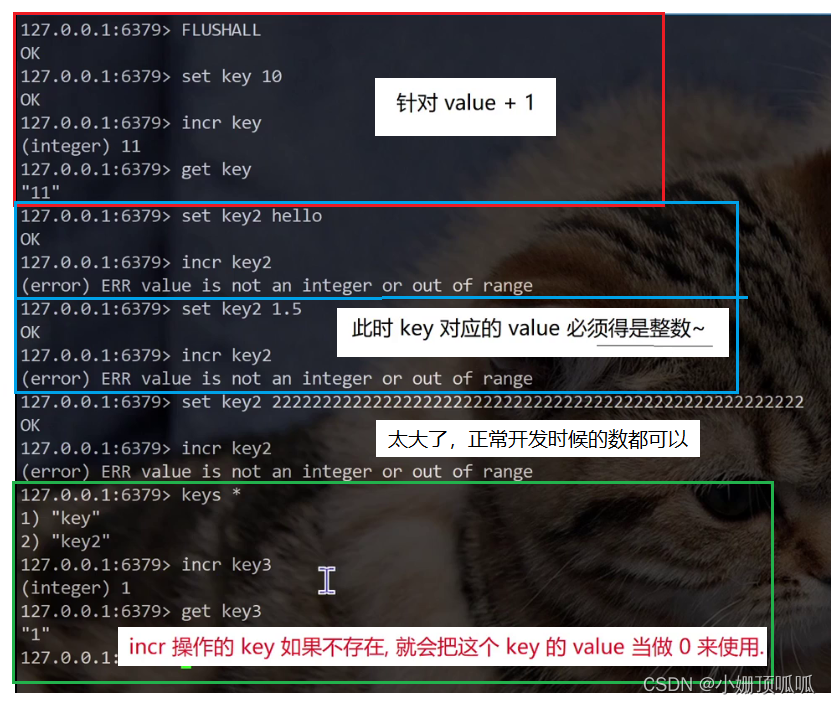
计数功能的命令:
incr 命令:value+1
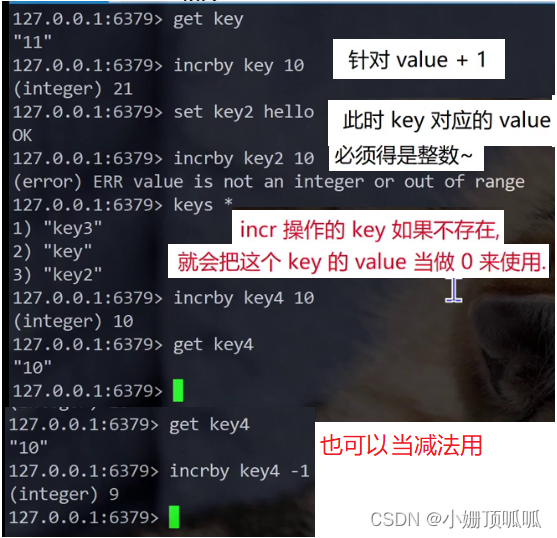
incrby命令:value +n
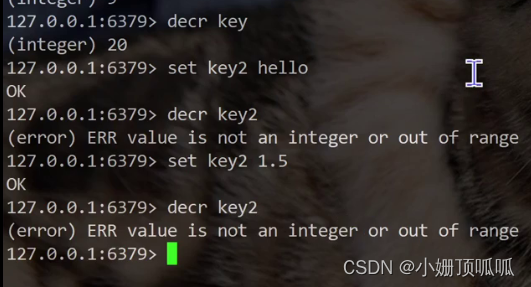
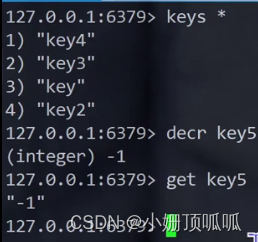
decr命令:value -1
decrby命令:value -n
incrbyfloat命令:value + - 小数

上述操作的时间复杂度都是O(1),因为就是哈希所以是O(1);
redis处理命令是单线程的,多个用户同时针对同一个key进行incr操作,不会引起“线程安全”问题。
字符串支持 拼接,获取/修改 字符串的部分内容,获取字符串长度
append getrange setrange strlen
append命令
这里的数字表示字节长度(当前xshell默认utf8, utf8字符集里汉字3个字节)
redis存储汉字时,redis启动客户端的时候,加上一个--raw选项可以使redis客户端自动把二进制数据尝试翻译,redis存的时候不管编码,只存二进制;(ctrl+d退出客户端,然后再次启动redis-cli)
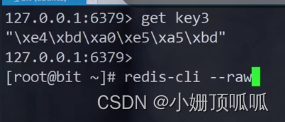
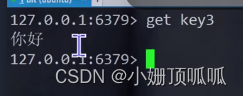
注意,在Linux里不要乱按ctrl +s, 在xshell中是冻结当前页面(方便看日志),ctrl+q 解除冻结;
getrange命令
返回key对应的string子串,用start和end决定(左闭右闭,一般都是左闭右开);(redis支持下标为负数,-1就是倒数第一个元素)
汉字不能切
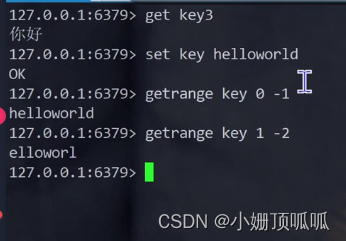
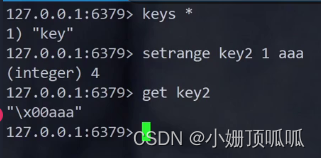
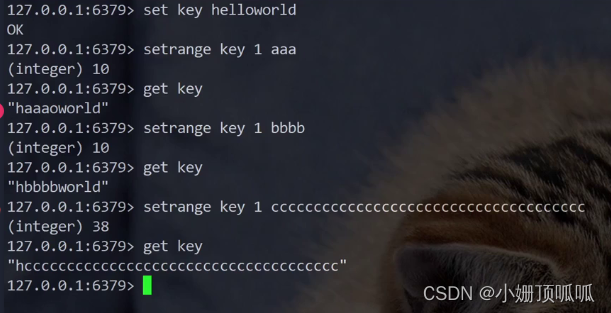
setrange命令:
把一个子串替换成其他字符串内容 语法:setrange key offset value;offset就是从第几个下标开始被替换
特殊情况在空的value里替换字符串

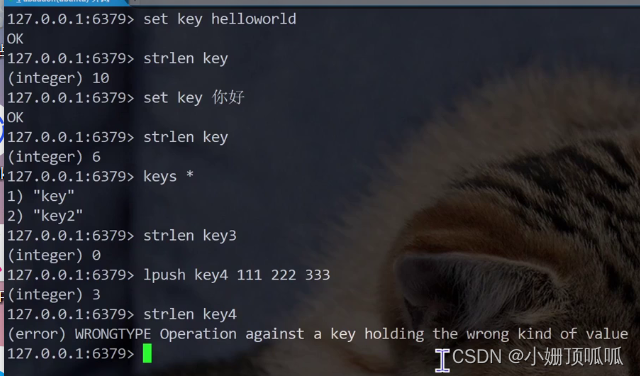
strlen命令: 获取到字符串长度单位是字节(汉字在java里,用unicode编码,是两个字节;汉字在redis,用utf8编码,是三个字节)
语法:strlen key(如果value不是string类型就报错)
细节:
















 1187
1187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









