







ACM大牛带你玩转算法与数据结构-课程资料
本笔记属于船说系列课程之一,课程链接:
你也可以选择购买『船说系列课程-年度会员』产品『船票』,畅享一年内无限制学习已上线的所有船说系列课程:船票购买入口
https://www.bilibili.com/cheese/pages/packageCourseDetail?productId=598
做题网站OJ:HZOJ - Online Judge
Leetcode :力扣 (LeetCode) 全球极客挚爱的技术成长平台
二分查找
二分查找是一种在有序数组中查找特定元素的高效算法。它通过逐步缩小查找范围,将问题规模减半,最终找到目标元素或确定其不存在。二分查找的时间复杂度为
。
对于二分查找最基本的一个用法,对于一个有序数组查找元素:
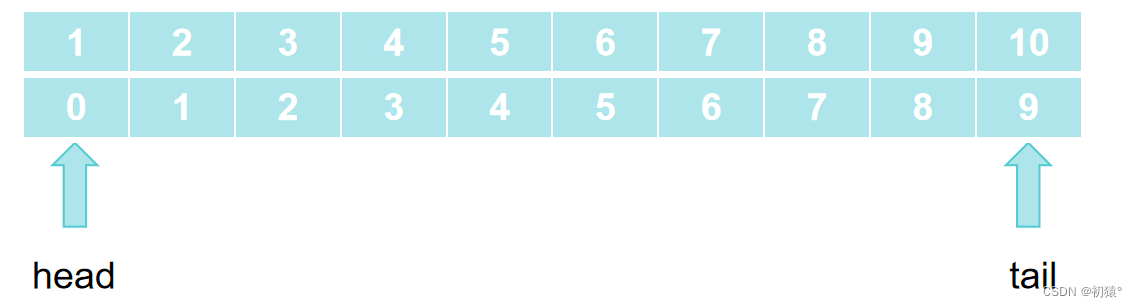
下图中分别是数组中元素和索引,对于下面的数组查找元素7
第一步初始化确定查找区间的起始和终点
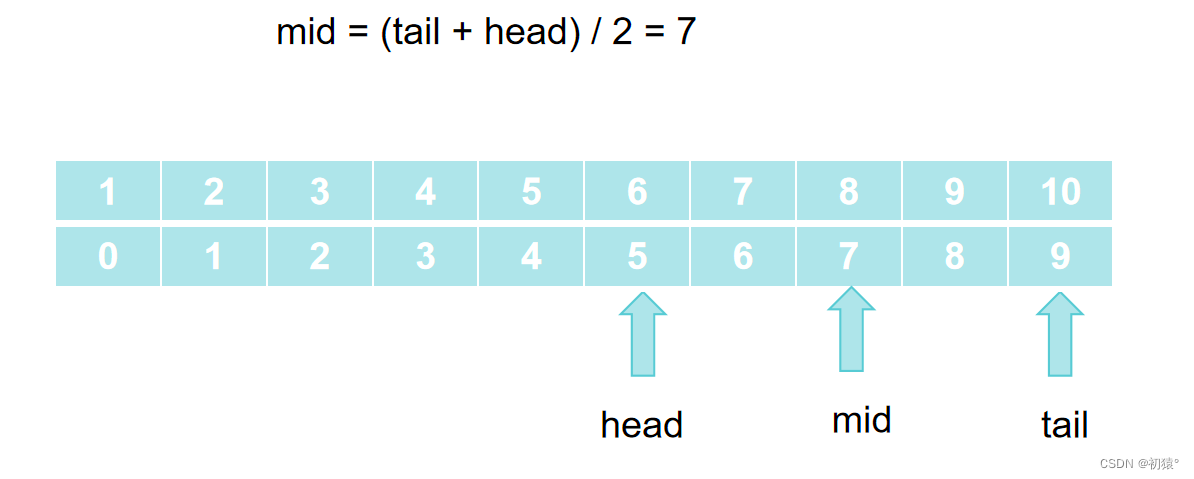
然后计算中点:
然后对于该位置和查找元素比较:
然后继续重复上面的操作:
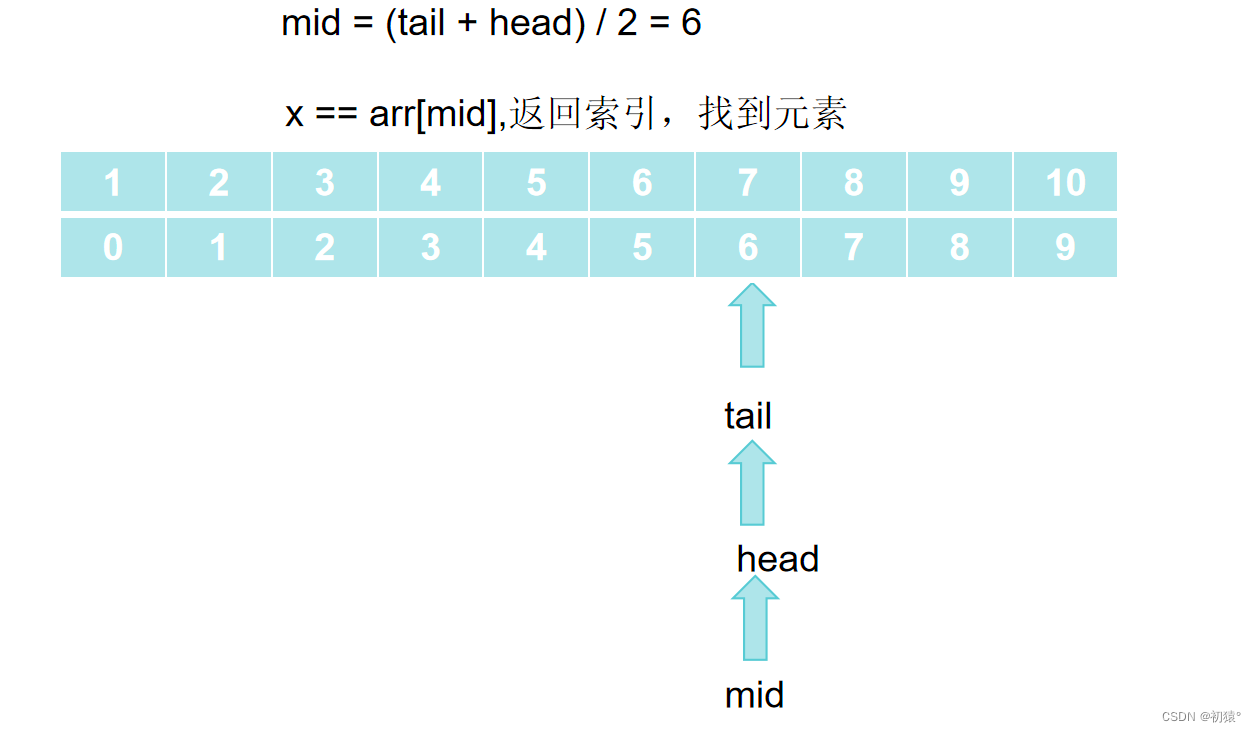
现在对比,然后通过判断可以确定查找元素在中点的左半区域,那么tail = mid - 1,同理上面的:
然后继续重复操作:
最后:
对于大概过程了解了,下面就是对于这个过程的代码实现:
#include <stdio.h> #include <stdlib.h> #include <time.h> using namespace std; #define swap(a, b) {\ __typeof(a) _a = a;\ a = b;\ b = _a;\ } int binary_search(int *arr, int n, int x) { //找到起点和终点 int head = 0, tail = n - 1, mid; //重复操作 while (tail >= head) { //确定中点位置 mid = (head + tail) / 2; //数组为单调递增 //如果查找元素大于中点,说明元素在中点右半区域,所以舍弃左半区域和中点 if (arr[mid] < x) head = mid + 1; //如果查找元素小于中点,说明元素在中点左半区域,所以舍弃左半区域和中点 else if (arr[mid] > x) tail = mid - 1; //找到元素,返回元素索引 else return mid; } //说明没有找到返回-1 return -1; } void output(int *arr, int n) { for (int i = 0; i < n; i++) { i && printf(" "); printf("%d", arr[i]); } putchar(10); return ; } int mid_num(int a, int b, int c) { if (a > b) swap(a, b); if (a > c) swap(a, c); if (b > c) swap(b, c); return b; } //将数组使用快速排序,使数组成为递增序列 void my_sort(int *arr, int l, int r) { while (r > l) { if (r - l <= 2) { if (r - l <= 1) return ; if (arr[l] > arr[l + 1]) swap(arr[l], arr[l + 1]); } int x = l, y = r - 1; int z = mid_num(arr[x], arr[y], arr[(x + y)>>1]); do { while (arr[x] < z) ++x; while (arr[y] > z) --y; if (x <= y) { swap(arr[x], arr[y]); ++x, --y; } } while(x <= y); my_sort(arr, l, x); l = x; } } int main() { srand(time(0)); #define MAX_N 10 int arr[MAX_N + 5]; for (int i = 0; i < MAX_N; i++) arr[i] = rand() % 100; my_sort(arr, 0, MAX_N); output(arr, MAX_N); int x; while (~scanf("%d", &x)) { if (x == -1) break; printf("%d is at arr %d\n", x, binary_search(arr, MAX_N, x)); } return 0; }





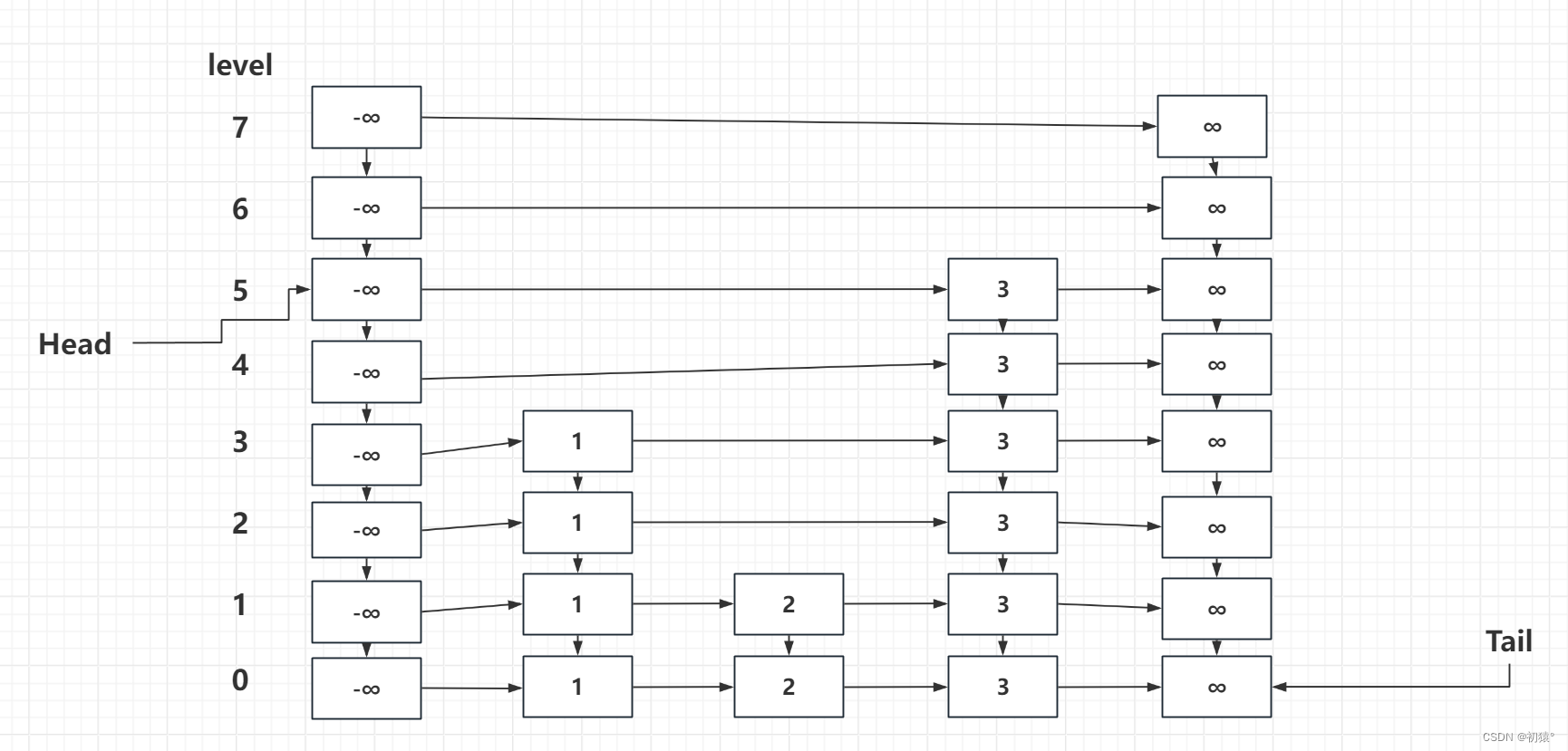
跳跃表
链表的查找、插入和删除的时间复杂度是O(n)的,为了降低这个时间复杂度那么就有了跳跃表的出现,跳跃表是基于链表的升级。
下图是一个跳跃表的图展示结构:
通过图中跳跃表是由链表组成的,设计跳跃表我们会用到节点,那么我们就先创建节点。
数据分析:
注意:在设计跳跃表时,头指针的位置永远在,左上角,而头指针的高度就是跳跃表中元素最高的高度而不是跳跃表限制的高度。
分析节点需要什么变量:
- key值表示节点存储的值
- 存储指向的下一个节点的地址的指针
- 存储指向上下节点的地址指针
- 每个节点当前的level值
typedef struct Node { int key, level; struct Node *next, *down, *up; } Node;对于节点初始化操作,他处的节点可能不止一个所以在初始化时,就初始化拥有level层的节点。
Node *getNewNode(int key, int n) { Node *nodes = (Node *)malloc(sizeof(Node) * n); //这里是初始化的一列的节点 //然后这一列节点是从上到下相互指向的,也就是双向链表 for (int i = 0; i < n; i++) { nodes[i].key = key; nodes[i].level = i; nodes[i].next = NULL; nodes[i].down = (i ? nodes + (i - 1) : NULL); nodes[i].up = (i + 1 < n ? nodes + (i + 1) : NULL); } return nodes + n - 1; }通过初始化的新节点是当前节点最顶上的节点的地址。
创建完成节点后,那么就开始创建跳跃表的数据结构:
- 头节点和尾节点指针
- 跳跃表最高限制level层数
typedef struct Skiplist { Node *head, *tail; int max_level; } Skiplist;跳跃表初始化操作:
Skiplist *getNewSkiplist(int n) { Skiplist *s = (Skiplist *)malloc(sizeof(Skiplist)); s->head = getNewNode(INT32_MIN, n); s->tail = getNewNode(INT32_MAX, n); s->max_level = n; Node *p = s->head, *q = s->tail; //使头节点去指向尾节点 while (p) { p->next = q; p = p->down, q = q->down; } //使头节点指向当前跳跃表最左上方的节点 //那么现在就应该是level 0层第一个的节点 while (s->head->level != 0) s->head = s->head->down; return s; }有了在堆区的开辟空间,那么就需要释放空间,对于跳跃表的释放操作:
void clearNode(Node *p) { if (p == NULL) return ; free(p); return ; } void clearSkiplist(Skiplist *s) { Node *p = s->head, *q; while (p->level != 0) p = p->down; while (p) { q = p->next; clearNode(p); p = q; } free(s); return ; }操作:
查找:
需要知道的是头指针指向的是,跳跃表的最坐上角的节点,不是跳跃表限制高度位置,而是跳跃表中的节点最高的位置,然后所在的列就是负无穷的那一列。
现在明确了头指针的位置,如何去查找,可以知道跳跃表里的元素是有序的,这里是一个递增的序列,那么先从头指针的那行去找,从左向右。当查找时,如果下个元素大于查找的值就跳到下层去找说明层没有查找的元素,如果小于等于就往右去找。
具体过程就不去模拟了,下面是代码实现:
Node *find(Skiplist *s, int x) { Node *p = s->head; //先从左往右找,知道碰到后边界往下 //往下后,又循环上面的语句 //直到没有下层或者找到节点 while (p && p->key != x) { //说明该层后面还有节点,就往后找 if (p->next->key <= x) p = p->next; //说明当层没有找到对应的节点 else p = p->down; } return p; }插入:
插入的时候需要处理:
- 随机高度:通过随机值来处理
- 和节点插入:先找到插入前一个节点的位置,而且可能每层的节点前一个节点不一样这是需要考虑的,如果插入节点的值比当前节点下一个节点大,那就继续往后,直到当前节点的下一个节点值比插入节点的值大,开始插入操作;
- 跳跃表头指针的高度:如果新插入节点的高度比之前跳跃表中的头指针的高度高,需要重置头指针的位置,并且不能超过跳跃表限制高度
下面是代码实现:
double randDouble() { #define MAX_RAND_N 1000000 return (rand() % MAX_RAND_N) * 1.0 / MAX_RAND_N; #undef MAX_RAND_N } int randLevel(Skiplist *s) { int level = 1; double p = 1.0 / 2.0; while (randDouble() < p) level += 1; #define min(a, b) ((a) < (b) ? (a) : (b)) return min(s->max_level, level); #undef min } void insert(Skiplist *s, int x) { //获取随机高度 int level = randLevel(s); //使头指针的高度要高于添加节点的高度 while (s->head->level + 1 < level) s->head = s->head->up; //当前node的位置是指向最顶点的节点的 Node *node = getNewNode(x, level); Node *p = s->head; //是当头指针的高度和添加节点的高度相同 while (p->level != node->level) p = p->down; while (p) { //因为是要插入节点操作 //插入时是需要前一个节点的,所以需要判断后一个节点 //因为边界是无穷大的,所以不用判短指针为空的操作 while (p->next->key < node->key) p = p->next; //插入操作 node->next = p->next; p->next = node; //插入完成向下层继续插入操作 p = p->down; node = node->down; } return ; }删除:
删除操作需要的处理:
- 判断值是否在跳跃表中:通过查找操作
- 如何找到删除节点的前一个节点:和插入操作一样的去处理;
int erase(Skiplist *s, int key) { Node *p = find(s, key); //p为空说明没有这个值 if (!p) return 0; //说明找到了 Node *q = s->head; //使指针指向,需要删除节点的最高层 //find返回值就是最高层节点的指针 while (q->level != p->level) q = q->down; //开始找对应值的前一个节点 //并开始删除操作 while (q) { //找到一个节点的下一个节点的值大于等于当前值 while (q->next->key < key) q = q->next; //目前节点是满足上面的条件的 //如果等于key值说明需要删除 if (key == q->next->key) { q->next = q->next->next; } //不等于就往下层走 q = q->down; } return 1; }整段代码:
#include<iostream> using namespace std; #include <stdio.h> #include <stdlib.h> #include <string.h> #include <inttypes.h> #include <time.h> typedef struct Node { int key, level; struct Node *next, *down, *up; } Node; typedef struct Skiplist { Node *head, *tail; int max_level; } Skiplist; Node *getNewNode(int key, int n) { Node *nodes = (Node *)malloc(sizeof(Node) * n); //这里是初始化的一列的节点 //然后这一列节点是从上到下相互指向的,也就是双向链表 for (int i = 0; i < n; i++) { nodes[i].key = key; nodes[i].level = i; nodes[i].next = NULL; nodes[i].down = (i ? nodes + (i - 1) : NULL); nodes[i].up = (i + 1 < n ? nodes + (i + 1) : NULL); } return nodes + n - 1; } Skiplist *getNewSkiplist(int n) { Skiplist *s = (Skiplist *)malloc(sizeof(Skiplist)); s->head = getNewNode(INT32_MIN, n); s->tail = getNewNode(INT32_MAX, n); s->max_level = n; Node *p = s->head, *q = s->tail; //使头节点去指向尾节点 while (p) { p->next = q; p = p->down, q = q->down; } //使头节点指向当前跳跃表最左上方的节点 //那么现在就应该是level 0层第一个的节点 while (s->head->level != 0) s->head = s->head->down; return s; } Node *find(Skiplist *s, int x) { Node *p = s->head; //先从左往右找,知道碰到后边界往下 //往下后,又循环上面的语句 //直到没有下层或者找到节点 while (p && p->key != x) { //说明该层后面还有节点,就往后找 if (p->next->key <= x) p = p->next; //说明当层没有找到对应的节点 else p = p->down; } return p; } double randDouble() { #define MAX_RAND_N 1000000 return (rand() % MAX_RAND_N) * 1.0 / MAX_RAND_N; #undef MAX_RAND_N } int randLevel(Skiplist *s) { int level = 1; double p = 1.0 / 2.0; while (randDouble() < p) level += 1; #define min(a, b) ((a) < (b) ? (a) : (b)) return min(s->max_level, level); #undef min } void insert(Skiplist *s, int x) { //获取随机高度 int level = randLevel(s); //使头指针的高度要高于添加节点的高度 while (s->head->level + 1 < level) s->head = s->head->up; //当前node的位置是指向最顶点的节点的 Node *node = getNewNode(x, level); Node *p = s->head; //是当头指针的高度和添加节点的高度相同 while (p->level != node->level) p = p->down; while (p) { //因为是要插入节点操作 //插入时是需要前一个节点的,所以需要判断后一个节点 //因为边界是无穷大的,所以不用判短指针为空的操作 while (p->next->key < node->key) p = p->next; //插入操作 node->next = p->next; p->next = node; //插入完成向下层继续插入操作 p = p->down; node = node->down; } return ; } void clearNode(Node *); int erase(Skiplist *s, int key) { Node *p = find(s, key); //p为空说明没有这个值 if (!p) return 0; //说明找到了 Node *q = s->head; //使指针指向,需要删除节点的最高层 //find返回值就是最高层节点的指针 while (q->level != p->level) q = q->down; //开始找对应值的前一个节点 //并开始删除操作 while (q) { //找到一个节点的下一个节点的值大于等于当前值 while (q->next->key < key) q = q->next; //目前节点是满足上面的条件的 //如果等于key值说明需要删除 if (key == q->next->key) { q->next = q->next->next; } //不等于就往下层走 q = q->down; } return 1; } void clearNode(Node *p) { if (p == NULL) return ; free(p); return ; } void clearSkiplist(Skiplist *s) { Node *p = s->head, *q; while (p->level != 0) p = p->down; while (p) { q = p->next; clearNode(p); p = q; } free(s); return ; } void output(Skiplist *s) { Node *p = s->head; int len = 0; for (int i = 0; i <= s->head->level; i++) { len += printf("%4d", i); } printf("\n"); for (int i = 0; i < len; i++) printf("-"); printf("\n"); while (p->level > 0) p = p->down; while (p) { bool flag = (p->key != INT32_MIN && p->key != INT32_MAX); for (Node *q = p; flag && q; q = q->up) { printf("%4d", q->key); } if (flag) printf("\n"); p = p->next; } return ; } int main() { srand(time(0)); int x; #define MAX_LEVEL 32 Skiplist *s = getNewSkiplist(MAX_LEVEL); #undef MAX_LEVEL // insert while (~scanf("%d", &x)) { if (x == -1) break; insert(s, x); output(s); } output(s); // erase while (~scanf("%d", &x)) { if (x == -1) break; if (erase(s, x)) { output(s); } else { printf("No Find\n") ; } } clearSkiplist(s); return 0; }

















 1915
1915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











