







一、训练误差与泛华误差
1、在训练时,我们关心的是泛化误差,也就是对新数据的预测
2、训练误差:模型在训练数据上的误差;泛化误差:模型在新数据上的误差
二、验证数据集与测试数据集
1、验证数据集:用于评估模型好坏的数据集,就像模拟考试
2、测试数据集:只用一次,就像正式考试
3、训练数据集:训练模型参数;对于训练数据集,我们会拿出一部分作为验证数据集,训练数据就像平时进行刷题
4、在实际中使用的测试数据集,其实来源于我们的验证数据集,所以验证数据集上得出来的超参数可能会在泛化误差之中虚高
三、K折交叉验证

1、没有足够多的数据时指无论什么情况下,训练数据都是越多越好。
2、对于k折,数据量大时可以将k取更小的值,数据量小时则反之
3、K折交叉验证误差做平均是为了超参数的选择
四、总结

五、过拟合与欠拟合
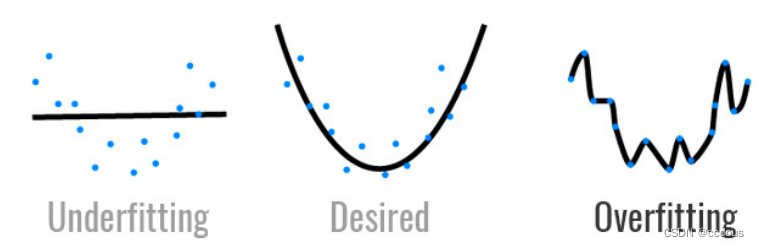
1、模型容量:拟合各种函数的能力,可以理解为模型的复杂程度,低就是简单模型,高就是复杂模型。复杂模型可以使用复杂函数,简单模型就不太行;比如线性模型就简单,多层感知机就比较复杂。
2、简单数据与复杂数据,简单数据比如人工数据集

3、简单数据高模型容量可能过拟合,就相当于模型将数据全部记下来了,包括很多噪音,对新数据没有泛化性;复杂数据使用简单模型应该会欠拟合,就是字面意思。
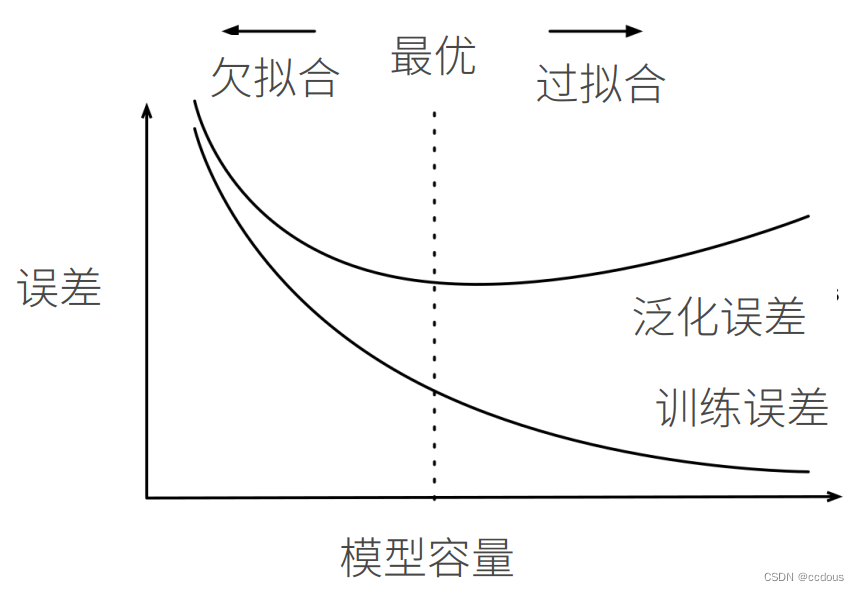
4、估计模型容量
(1)模型容量在不同种类的算法之间难以比较,比如树模型与神经网络之间的差别非常大
(2)给定模型种类,有两个因素估计模型容量:参数个数与参数选择范围
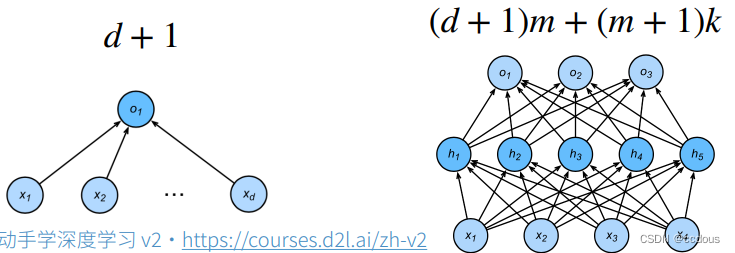
对于上图线性回归,输入为d维向量,自然就有d个权重w,参数就是d个w和一个偏差d;
对于有一层隐藏层的感知机,其中这一层输出位m维向量,最终输出层向量为k,按照线性模型反推,输入->隐藏层(d+1)*m,隐藏层->输出层(m+1)*k
(3)VC维:VC维度定义了在假设空间中能够被模型拟合的样本点的最大数量,例如二维空间的vc维是3,在多1个点,比如四个点就陷入了XOR问题,这里知道大概概念就好了。

支持N维输入的感知机的VC维是N+1;
一些多层感知机的VC维O(Nlog2N)

5、数据复杂度
(1)数据复杂度是一个相对概念,多样性指分为几类,比如softmax输出分成了许多类
(2)多个重要因素

6、总结

六、多项式生成数据集
、
max_degree = 20 # 多项式的最大阶数,除了前面四个其他都是属于噪音
n_train, n_test = 100, 100 # 训练和测试数据集大小
true_w = np.zeros(max_degree) # 分配大量的空间
true_w[0:4] = np.array([5, 1.2, -3.4, 5.6])
#总计为200的训练和测试集
features = np.random.normal(size=(n_train + n_test, 1))
np.random.shuffle(features)
#生成了200个,多项式的样本相当于200*20
poly_features = np.power(features, np.arange(max_degree).reshape(1, -1))
#相当于除以阶乘
for i in range(max_degree):
poly_features[:, i] /= math.gamma(i + 1) # gamma(n)=(n-1)!
# labels的维度:(n_train+n_test,)
labels = np.dot(poly_features, true_w)
#添加噪声
labels += np.random.normal(scale=0.1, size=labels.shape)
七、模型进行训练和测试
1、评估模型在给定数据集上的损失的函数
def evaluate_loss(net, data_iter, loss): ...#跟之前的一样 return metric[0]/metric[1]
2、定义训练函数
train(train_features, test_features, train_labels, test_labels,num_epochs=400): 略,跟之前的一样
3、三阶多项式函数拟合(正常)
# 从多项式特征中选择前4个维度,即1,x,x^2/2!,x^3/3!
train(poly_features[:n_train, :4], poly_features[n_train:, :4],
labels[:n_train], labels[n_train:])
4、线性函数拟合(欠拟合)
# 从多项式特征中选择前2个维度,即1和x
train(poly_features[:n_train, :2], poly_features[n_train:, :2],
labels[:n_train], labels[n_train:])
5、高阶多项式函数拟合(过拟合)
# 从多项式特征中选取所有维度
train(poly_features[:n_train, :], poly_features[n_train:, :],
labels[:n_train], labels[n_train:], num_epochs=1500)
6、总结
-
欠拟合是指模型无法继续减少训练误差。过拟合是指训练误差远小于验证误差。
-
由于不能基于训练误差来估计泛化误差,因此简单地最小化训练误差并不一定意味着泛化误差的减小。机器学习模型需要注意防止过拟合,即防止泛化误差过大。
-
验证集可以用于模型选择,但不能过于随意地使用它。
-
我们应该选择一个复杂度适当的模型,避免使用数量不足的训练样本。















 851
851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









