







一、硬性限制

1、通常不限制偏移b,因为限制不会有区别;seta越小,意味着正则项强
2、优化的是最小化的损失函数
3、后部的限制条件,每个项的平方和小于一个值;极端情况下,当seta等于0,意味着所有的w为0,即只有一个偏移,比如seta为1 ,每个w都不会大于1,并且当w越多,每个w就相当于越小。
二、柔性限制

1、损失函数后面的那一块又叫做罚函数,可以当成惩罚因子
2、正则项也称为岭回归中的正则化项,向损失函数中添加L2范数(参数向量的平方和),有助于防止模型过度拟合训练数据,通过惩罚较大的参数值来促使模型更加简单(限制w的取值)且泛化能力更强。

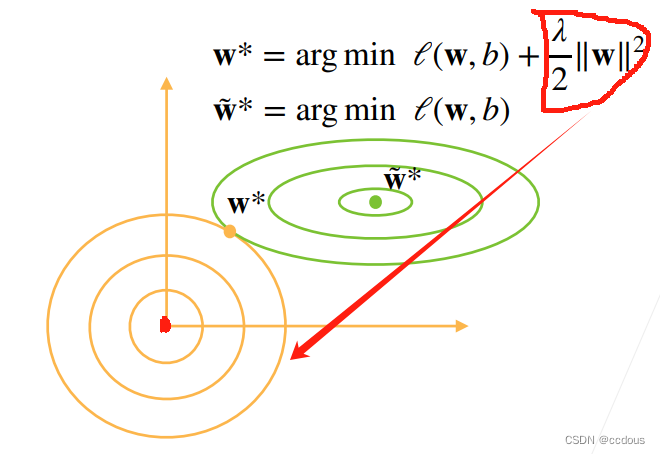
三、中心点是最优解但是容易过拟合 ,所以要拉动它,就是用这个平方项它往左下角拉
四、参数更新

权重衰退的称呼是因为,先在权重减小的基础上,再做梯度下降。
五、总结

六、代码
1、生成数据:略,但生成数据可以考虑生成过拟合的数据,比如我们训练数据很小
2、初始化模型参数:略
3、定义𝐿2范数惩罚
def l2_penalty(w):
return torch.sum(w.pow(2)) / 2
4、定义训练代码实现
def train(lambd):
#初始化模型参数
w, b = init_params()
net, loss = lambda X: d2l.linreg(X, w, b), d2l.squared_loss
num_epochs, lr = 100, 0.003
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
# 增加了L2范数惩罚项,
# 广播机制使l2_penalty(w)成为一个长度为batch_size的向量
l = loss(net(X), y) + lambd * l2_penalty(w)
l.sum().backward()
d2l.sgd([w, b], lr, batch_size)
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数是:', torch.norm(w).item())
5、lambd往大了调,是为了降低w的l2 norm,达到避免过拟合的效果;随着 𝜆λ 增大,模型在优化过程中会更加倾向于减小参数 wi 的值,以减少正则项的值。因此,为了最小化整体损失函数,参数的平方和(即L2范数)会变小。
6、总结
-
正则化是处理过拟合的常用方法:在训练集的损失函数中加入惩罚项,以降低学习到的模型的复杂度。
-
保持模型简单的一个特别的选择是使用𝐿2惩罚的权重衰减。这会导致学习算法更新步骤中的权重衰减。
-
权重衰减功能在深度学习框架的优化器中提供。
-
在同一训练代码实现中,不同的参数集可以有不同的更新行为。















 2275
2275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









