 Go语言sync.Pool深度解析
Go语言sync.Pool深度解析




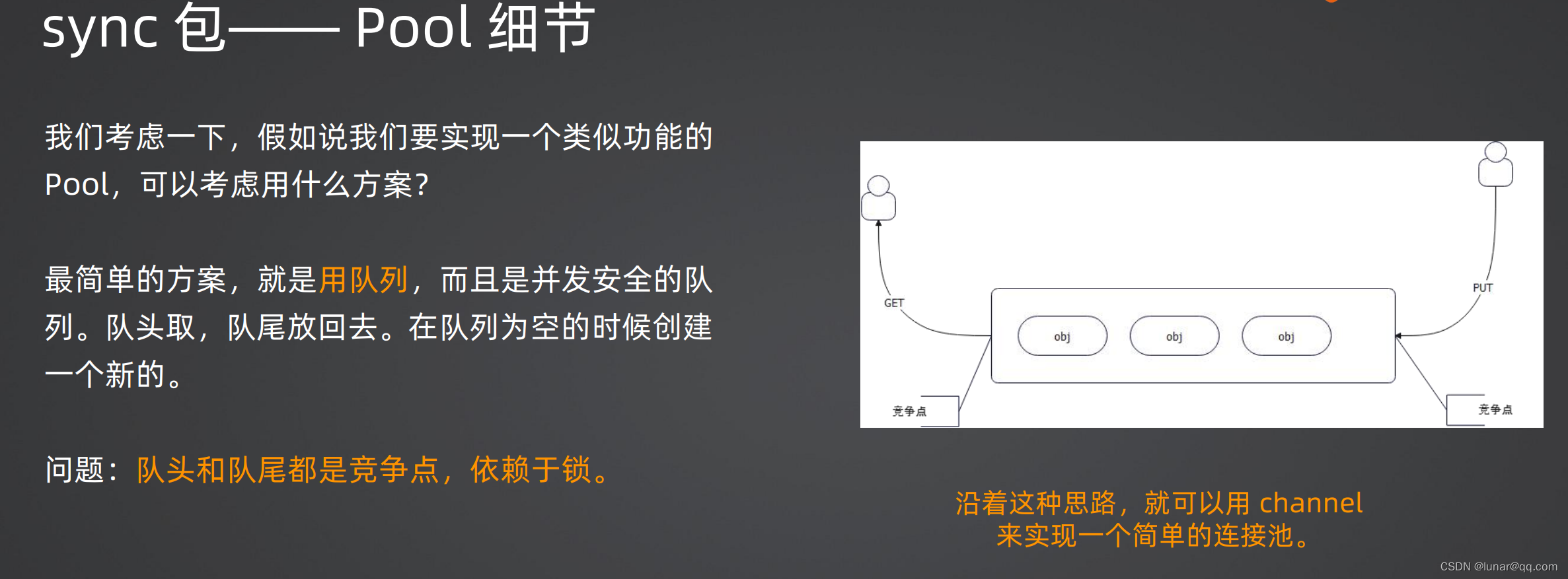
 sync.Pool是Go语言中用于管理可重用对象的并发安全容器,减少对象创建和销毁的开销及对GC的影响。它由私有和共享池组成,采用ringbuffer和链表结构,支持并发访问。对象获取时先尝试私有池,然后共享池,接着从其他处理器的池中“偷”对象,最后才考虑回收的victim池。放回对象时,优先放入私有池,满时创建新的ringbuffer。sync.Pool依赖GC进行内存管理,旨在防止因GC引起的性能波动。
sync.Pool是Go语言中用于管理可重用对象的并发安全容器,减少对象创建和销毁的开销及对GC的影响。它由私有和共享池组成,采用ringbuffer和链表结构,支持并发访问。对象获取时先尝试私有池,然后共享池,接着从其他处理器的池中“偷”对象,最后才考虑回收的victim池。放回对象时,优先放入私有池,满时创建新的ringbuffer。sync.Pool依赖GC进行内存管理,旨在防止因GC引起的性能波动。
一.什么是sync.pool
sync.Pool是用来保存可以被重复使用的临时对象,一边在以后的同类操作中可以重复使用,从而避免了反复创建和销毁临时对象带来的消耗以及对GC造成的压力。常用池化技术来提高程序的性能,例如连接池,线程池等。sync.Pool是并发安全的,可以在多个goroutine中并发调用sync.Pool存取对象.但是需要注意的是,sync.Pool保存的对象随时可能在不发出通知的情况下被清除,因此不能使用sync.Pool存储需要持久化的对象。

sync包-----Pool细节
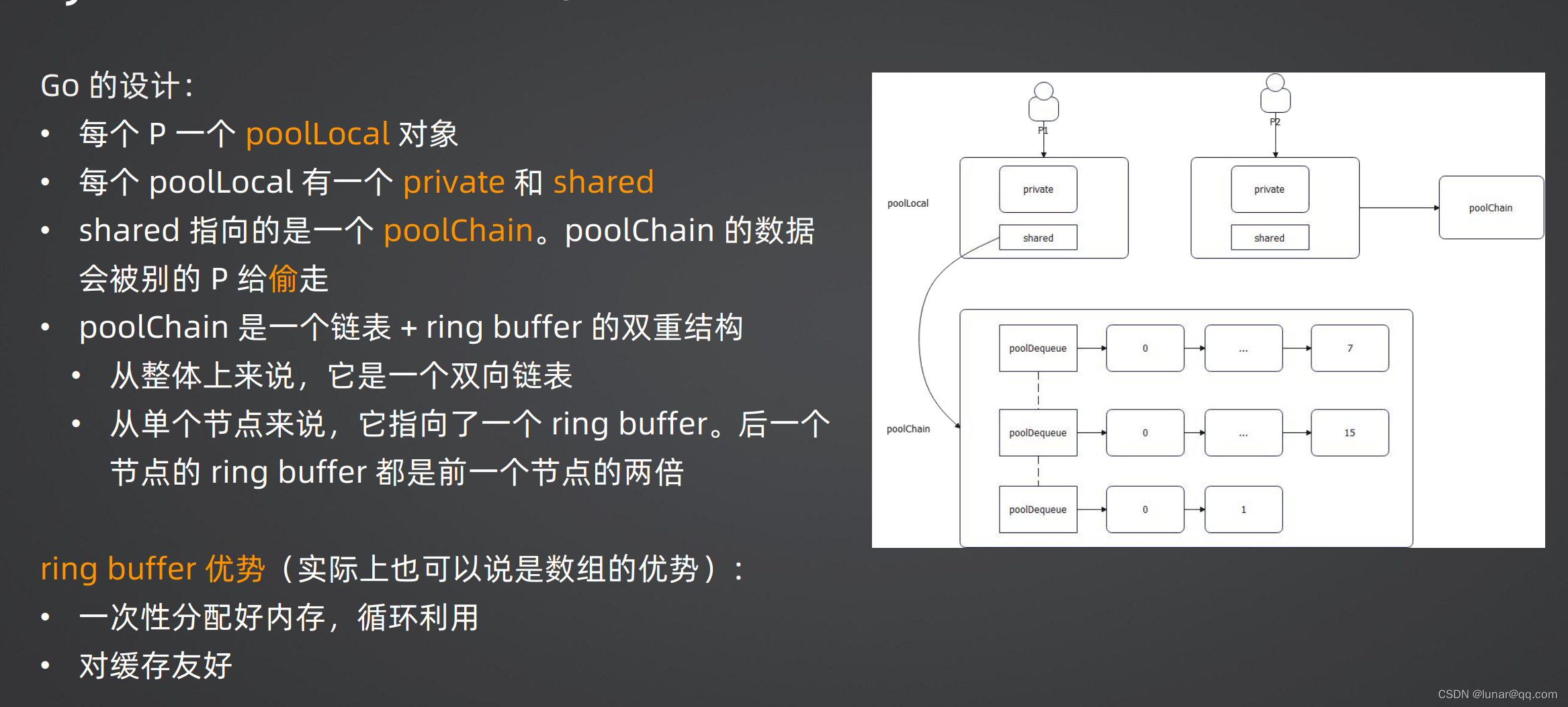
Go的设计:
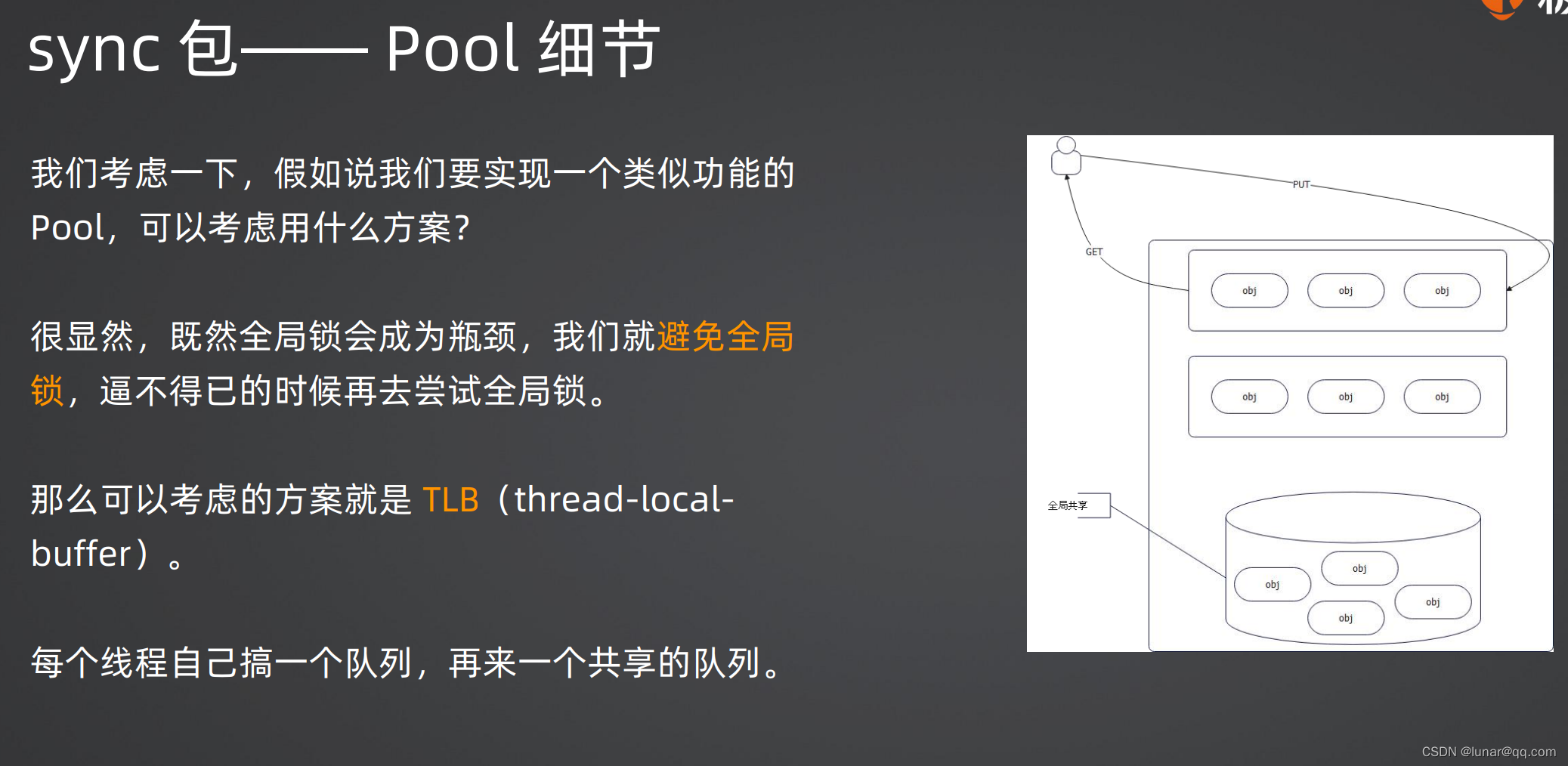
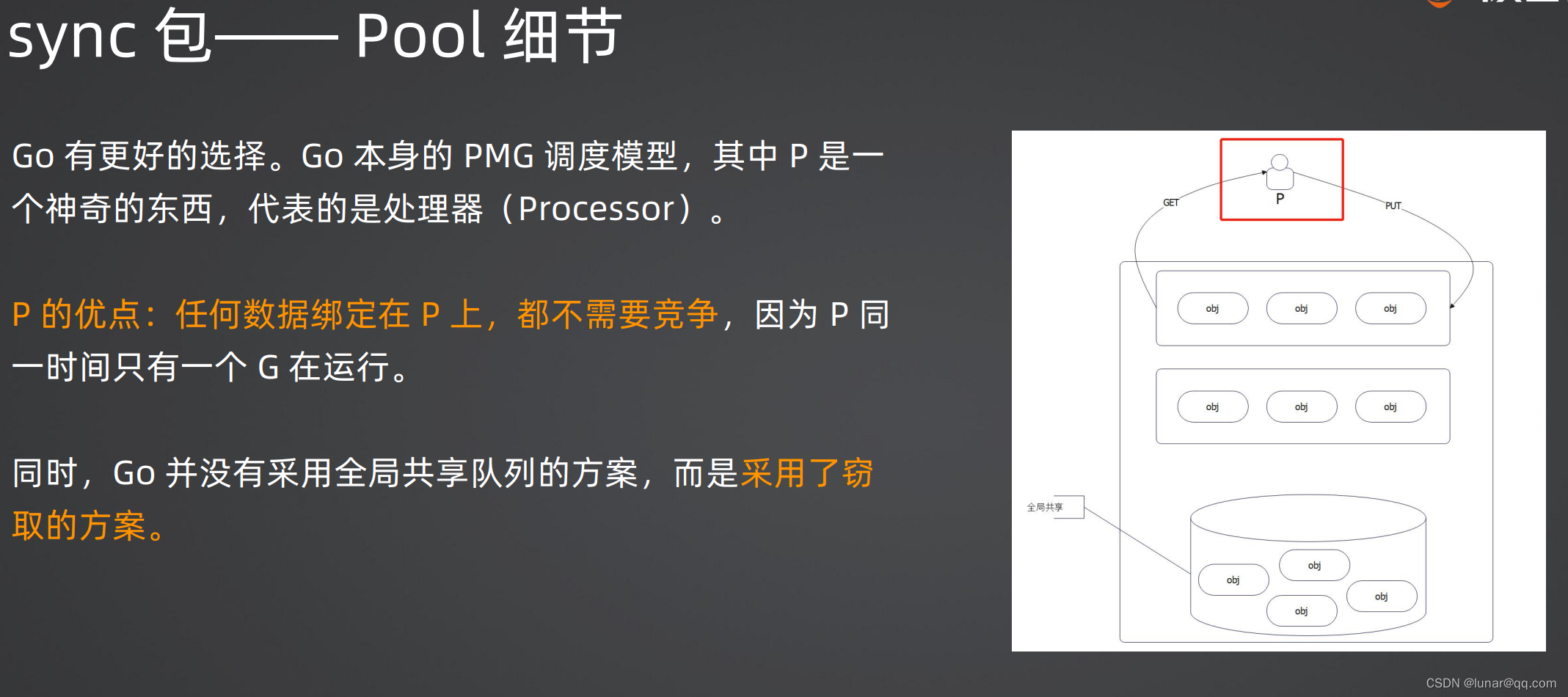
1.每个P(Processor) 一个poolLocal对象
2.每个poolLocal有一个private和shared
3.shared指向的是一个poolChain。poolChain的数据会被别的P偷走
4.poolChain是一个链表 + ring buffer 的双重结构
从整体上来说,他是一个双向链表
从单个节点来说,它指向了一个 ring buffer。后一个节点的ring buffer 都是前一个结点的两倍
ring buffer优势(实际上也可以说是数组的优势):
一次性分配好内存,循环利用
对缓存友好
sync包----pool get 步骤
1.首先看private可不可用,可用就直接返回
2.不可用则从自己的poolChain里面尝试获取一个
(1)从头开始找。注意,头指向的其实是最近创建的ring buffer
(2)从队头往队尾找
3.找不到则尝试从别的P里面偷一个出来 。偷的过程就是全局并发,因为理论上来说,其他P都可能恰好一起来偷了
(1)偷是从队尾偷
4.如果偷也偷不到,那么就会去找缓刑(victim)的
5.连缓刑的也没有,那就去创建一个新的
实际例子:
就好比你准备买东西
1.先看自己有没有(private)
2.没有找爸妈借(shared poolChain)
3.还没有找亲戚借(从别人的poolChain里面偷一个)
4.在没有就薅网贷(victim,你已经在深渊边缘)
5.在没有就。。。(创建一个新的)
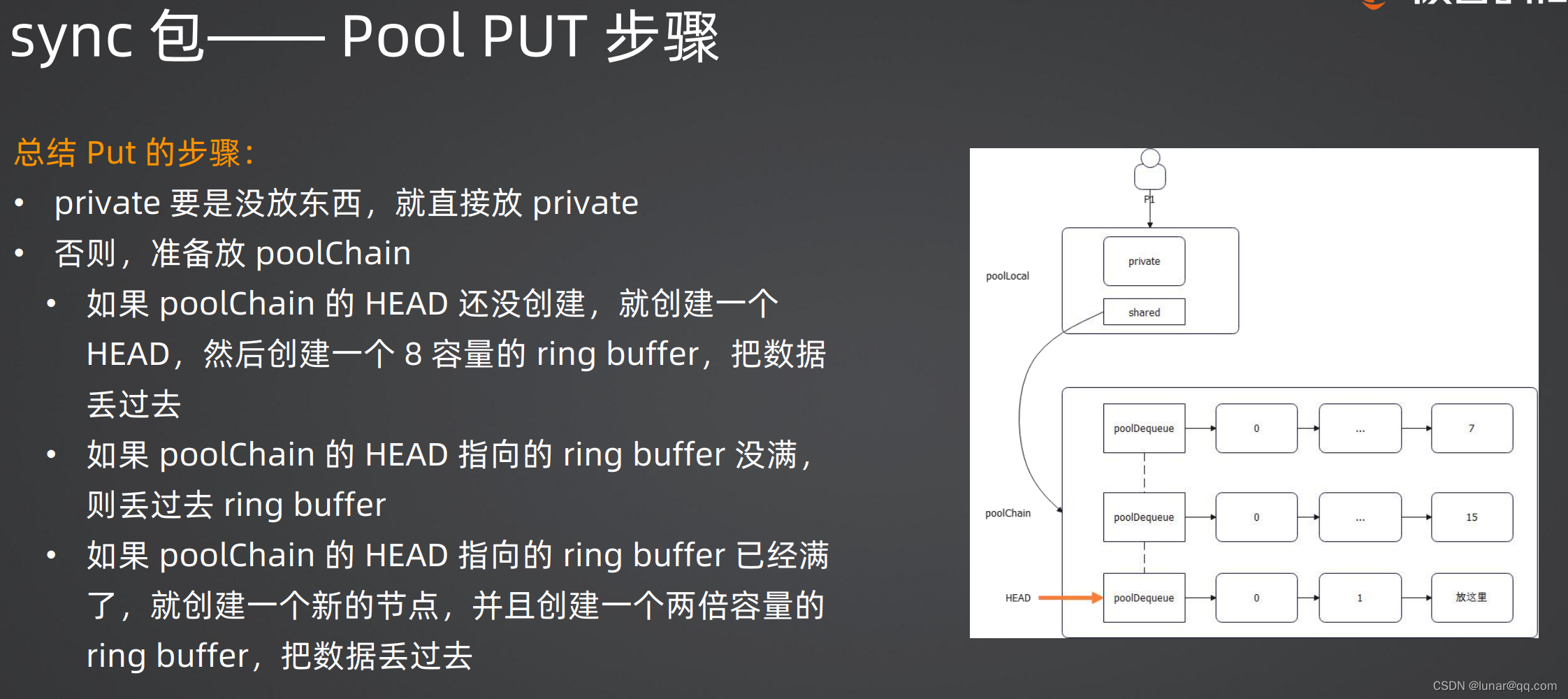
sync包----pool put步骤
1.private要是没放东西,就直接放private
2.否则,准备放poolChain
(1)如果poolChain的Head还没创建,就创建一个Head,然后创建一个8容量的ring buffer,把数据丢过去
(2)如果poolChain的Head指向的ring buffer没满,则丢过去ring buffer
(3)如果poolChain的Head指向的ring buffer 已经满了,就创建一个新的节点,并且创建一个两倍容量的ring buffer,把数据丢过去
sync包----Pool与GC
正常情况下,我们设计一个Pool都要考虑容量和淘汰问题(基本类似于缓存):
1.我们希望能够控制住Pool的内存消耗量
2.在这个前提下,我们要考虑淘汰的问题
Go的sync.Pool就不太一样。它纯粹依赖于GC,用户完全没办法手工控制。
sync.Pool的核心机制是依赖于两个:
local
victim
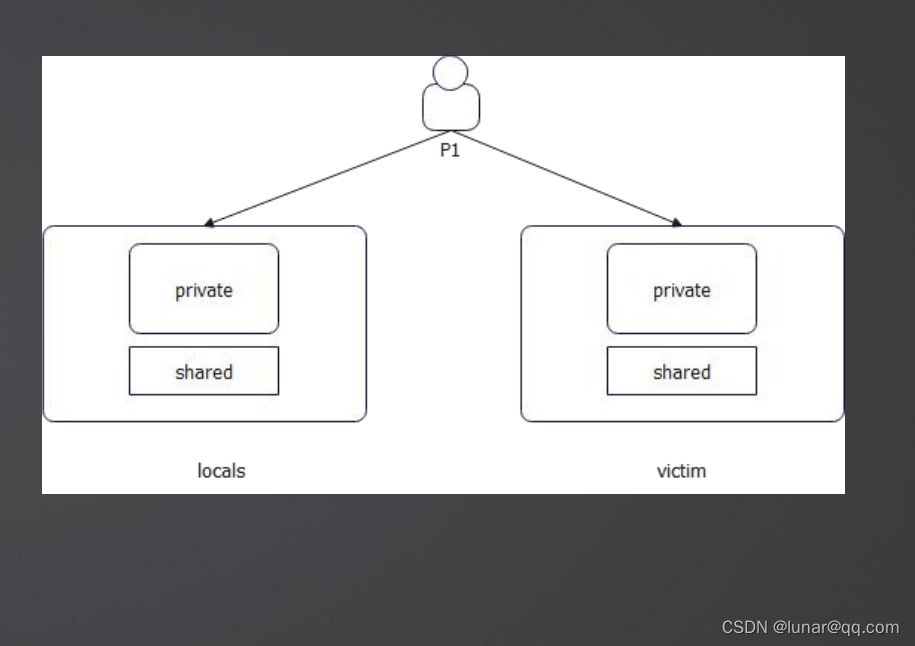
GC过程
过程:
1.local会被挪过去变成victim
2.victim会被直接回收掉
复活:如果victim的对象再次被使用,那么它就会被丢回去local,逃过了下一轮被GC回收掉的命运
优点:防止GC引起性能抖动


sync包----Pool为什么最后才去找victim的
前面的步骤,有一个令人困惑的点是:偷不到别的P的,再去找缓刑(victim)的。
那么问题来了:偷是一个全局竞争的过程,但是找civtim不是,找victim和找正常的是一样的过程。显然先找victim会有更好的性能,那么为什么要先去偷呢?
因为sync.Pool希望victim里面的对象尽可能被回收掉。


















 898
898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









