







数据集:训练数据集--验证数据集--测试数据集
在深度学习中,我们通常将数据分成三个集合:训练集、验证集和测试集。这三个集合在训练深度学习模型时起到不同的作用。
训练集(用来训练模型参数)是用来训练模型的数据集,即我们用来调整模型参数的数据集。我们通常使用训练集中的数据来帮助模型学习如何将输入映射到输出的过程。
验证集(用来评估模型好坏的数据集,选择模型的超参数)是用来评估模型的数据集,即我们用来选择最优模型的数据集。我们通常使用验证集来测试模型在未见过的数据上的表现,以便选择最优的模型。
测试集(只使用一次的数据集)是用来最终评估模型的数据集,即我们用来测试模型的最终性能的数据集。我们通常使用测试集来评估模型在完全未见过的数据上的表现,以便了解模型在真实情况下的性能。
通常,我们会将原始数据集按照一定的比例划分为训练集、验证集和测试集。例如,可以将数据集划分为 70% 训练集、15% 验证集和 15% 测试集。这样可以保证我们有足够的数据来训练和评估模型。
过拟合与欠拟合

简单的数据适合简单的模型(模型容量低);复杂的数据适合复杂的模型。
当简单的数据使用复杂的模型时就会出现过拟合;复杂的数据使用简单的模型就会出现欠拟合。
模型容量
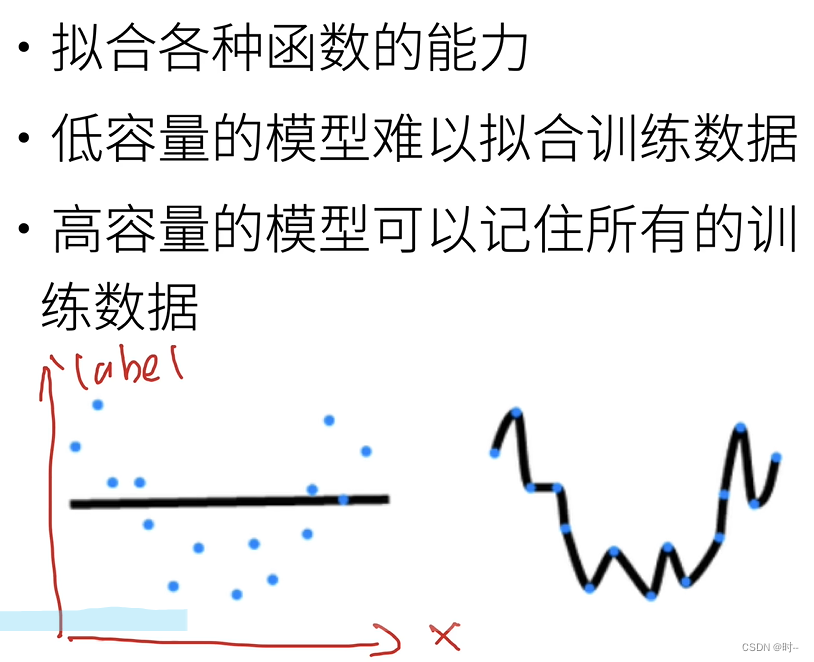 左边就是欠拟合;右边就是过拟合(将噪音也进行了拟合)
左边就是欠拟合;右边就是过拟合(将噪音也进行了拟合)
注意:记住的是训练模型,模型容量高是可以在训练数据集上表现良好,甚至是100%的正确率,但是过度的拟合训练数据会记住一些噪声,反而降低在 验证数据集/测试数据集 上的表现。
模型容量的影响——模型首先要足够大,然后通过各种手段来控制模型容量的大小

在这里,训练误差与泛化误差:
在机器学习中,训练误差指的是在训练数据上表现出的误差,而泛化误差指的是在新数据上表现出的误差。
训练误差反映了模型在训练数据上的表现,这通常是模型调参和优化的重点。如果训练误差过大,则表明模型无法很好地拟合训练数据,可能需要调整模型的复杂度或使用其他优化方法。
泛化误差则反映了模型在新数据上的表现,这是衡量模型泛化能力的关键指标。如果泛化误差过大,则表明模型过于依赖训练数据中的特征,无法很好地适应新数据。这种情况通常是由于模型过于复杂或训练数据不足所导致的。
通常希望训练误差尽可能小,泛化误差尽可能接近训练误差。这意味着模型能够很好地拟合训练数据,同时又不会过度拟合训练数据中的噪声或特征,从而在新数据上表现良好。
估计模型容量

不同模型之间不好比较模型容量;相同模型通过比较模型参数的个数和参数值的选择范围
d+1 : 线性模型 d为输入个数,输入个数等于权重个数。参数的个数为权重个数+1(偏移量b)
(d+1)m + (m+1)k : 单隐藏层感知机
 此为单隐藏层感知机模型参数
此为单隐藏层感知机模型参数
W1 : k * m b1 : m W2 : m * k b2 : k
















 1701
1701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











