






布隆过滤器(Bloom-Filter)
介绍
布隆过滤器能够实现使用较少的空间来判断一个指定的元素是否包含在一个集合中。布隆过滤器并不保存这些数据,所以只能判断是否存在,而并不能取出该元素。
优点:空间效率和查询效率⾼
缺点:
有⼀定误判率即可(可以控制在可接受范围内)。
删除元素困难(不能将该元素hash算法结果位置修改为0,因为可能会影响其他元素)。
极端情况下,如果布隆过滤器所有位置都是1,那么任何元素都会被判断为存在于集合中。
核心思想:
利用多个不同的Hash函数来解决“冲突”。
Hash存在一个冲突(碰撞)的问题,用同一个Hash得到的两个URL的值有可能相同。为了减少冲突,我们可以多引入几个Hash,如果通过其中的一个Hash值我们得出某元素不在集合中,那么该元素肯定不在集合中。
只有在所有的Hash函数告诉我们该元素在集合中时,才能确定该元素存在于集合中。
使用情景:
凡是判断一个元素是否在一个集合中的操作,都可以使用它
常见使用场景:
- idea中编写代码,一个单词是否包含在正确拼写的词库中(拼写不正确划绿线的提示);
- 公安系统,根据身份证号\人脸信息,判断该人是否在追逃名单中;
- 爬虫检查一个网址是否被爬取过。
缓存穿透
所谓缓存穿透,就是一个业务请求先查询redis,redis没有这个数据,那么就去查询数据库,但是数据库也没有的情况
正常业务下,一个请求查询到数据后,我们可以将这个数据保存在Redis
之后的请求都可以直接从Redis查询,就不需要再连接数据库了
但是一旦发生上面的穿透现象,仍然需要连接数据库,一旦连接数据库,项目的整体效率就会被影响
如果有恶意的请求,高并发的访问数据库中不存在的数据,严重的,当前服务器可能出现宕机的情况
业界主流解决方案:布隆过滤器
布隆过滤器的使用步骤
- 针对现有所有数据,生成布隆过滤器,保存在Redis中
- 在业务逻辑层,判断Redis之前先检查这个id是否在布隆过滤器中
- 如果布隆过滤器判断这个id不存在,直接返回
- 如果布隆过滤器判断id存在,在进行后面业务执行
为什么使用布隆过滤器
常规的检查一个元素是否在一个集合中的思路是遍历集合,判断元素是否相等,这样的查询效率非常低下。
要保证快速确定一个元素是否在一个集合中,我们可以使用HashMap。因为HashMap内部的散列机制,保证更快更高效的找到元素。所以当数据量较小时,用HashMap或HashSet保存对象然后使用它来判定元素是否存在是不错的选择。
但是如果数据量太大,每个元素都要生成哈希值来保存,我们也要依靠哈希值来判定是否存在,一般情况下,我们为了保证尽量少的哈希值冲突需要8字节哈希值做保存。8字节也就是long类型,其取值范围:-9223372036854775808-----9223372036854775807。
5亿条数据 每条8字节计算后结果为需要3.72G内存,随着数据数量增长,占用内存数字可能更大。
所以Hash散列或类似算法可以保证高效判断元素是否存在,但是消耗内存较多。所以我们使用布隆过滤器实现,高效判断是否存在的同时,还能节省内存的效果。但是布隆过滤器的算法天生会有误判情况,需要能够容忍,才能使用
布隆过滤器原理
⼀个很长的⼆进制向量(位数组),⼀系列随机函数 (哈希),空间效率和查询效率⾼(又小又快),有⼀定的误判率(哈希表是精确匹配)
布隆过滤器误判的效果:
布隆过滤器判断不存在的,一定不在集合中
布隆过滤器判断存在的,有可能不在集合中
过短的布隆过滤器如果保存了很多的数据,可能造成二进制位置值都是1的情况,一旦发送这种情况,布隆过滤器就会判断任何元素都在当前集合中,布隆过滤器也就失效了。所以我们要给布隆过滤器一个合适的大小才能让它更好的为程序服务
设计布隆过滤器
我们在启动布隆过滤器时,需要给它分配一个合理大小的内存,这个大小应该满足
1.内存占用在一个可接受范围
2.不能有太高的误判率(<1%)
内存越节省,误判率越高;内存越大,误判率越低。数学家已经给我们了公式计算误判率
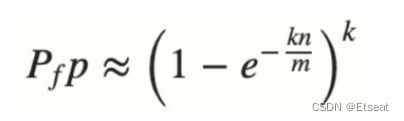
上面是根据误判率计算布隆过滤器长度的公式
n 是已经添加元素的数量;
k 哈希的次数;
m 布隆过滤器的长度(位数的大小)
Pfp计算结果就是误判率
如果我们已经确定可接受的误判率,想计算需要多少位数布隆过滤器的长度
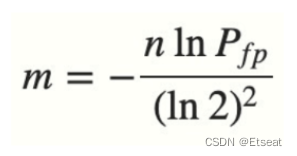
布隆过滤器计算器:https://hur.st/bloomfilter
应用
布隆过滤器工具类代码(开源)
/*
* 启动布隆过滤器
*/
@Component
public class RedisBloomUtils {
@Autowired
private StringRedisTemplate redisTemplate;
private static RedisScript<Boolean> bfreserveScript = new DefaultRedisScript<>("return redis.call('bf.reserve', KEYS[1], ARGV[1], ARGV[2])", Boolean.class);
private static RedisScript<Boolean> bfaddScript = new DefaultRedisScript<>("return redis.call('bf.add', KEYS[1], ARGV[1])", Boolean.class);
private static RedisScript<Boolean> bfexistsScript = new DefaultRedisScript<>("return redis.call('bf.exists', KEYS[1], ARGV[1])", Boolean.class);
private static String bfmaddScript = "return redis.call('bf.madd', KEYS[1], %s)";
private static String bfmexistsScript = "return redis.call('bf.mexists', KEYS[1], %s)";
public Boolean hasBloomFilter(String key) {
return redisTemplate.hasKey(key);
}
/**
* 设置错误率和大小(需要在添加元素前调用,若已存在元素,则会报错)
* 错误率越低,需要的空间越大
*
* @param key
* @param errorRate 错误率,默认0.01
* @param initialSize 默认100,预计放入的元素数量,当实际数量超出这个数值时,误判率会上升,尽量估计一个准确数值再加上一定的冗余空间
* @return
*/
public Boolean bfreserve(String key, double errorRate, int initialSize) {
return redisTemplate.execute(bfreserveScript, Arrays.asList(key), String.valueOf(errorRate), String.valueOf(initialSize));
}
/**
* 添加元素
*
* @param key
* @param value
* @return true表示添加成功,false表示添加失败(存在时会返回false)
*/
public Boolean bfadd(String key, String value) {
return redisTemplate.execute(bfaddScript, Arrays.asList(key), value);
}
/**
* 查看元素是否存在(判断为存在时有可能是误判,不存在是一定不存在)
*
* @param key
* @param value
* @return true表示存在,false表示不存在
*/
public Boolean bfexists(String key, String value) {
return redisTemplate.execute(bfexistsScript, Arrays.asList(key), value);
}
/**
* 批量添加元素
*
* @param key
* @param values
* @return 按序 1表示添加成功,0表示添加失败
*/
public List<Integer> bfmadd(String key, String... values) {
return (List<Integer>) redisTemplate.execute(this.generateScript(bfmaddScript, values), Arrays.asList(key), values);
}
/**
* 批量检查元素是否存在(判断为存在时有可能是误判,不存在是一定不存在)
*
* @param key
* @param values
* @return 按序 1表示存在,0表示不存在
*/
public List<Integer> bfmexists(String key, String... values) {
return (List<Integer>) redisTemplate.execute(this.generateScript(bfmexistsScript, values), Arrays.asList(key), values);
}
private RedisScript<List> generateScript(String script, String[] values) {
StringBuilder sb = new StringBuilder();
for (int i = 1; i <= values.length; i++) {
if (i != 1) {
sb.append(",");
}
sb.append("ARGV[").append(i).append("]");
}
return new DefaultRedisScript<>(String.format(script, sb.toString()), List.class);
}
}
项目应用
缓存预热思路
在即将发生高并发业务之前,我们将一些高并发业务中需要的数据保存到Redis中,这种操作,就是"缓存预热",这样发生高并发时,这些数据就可以直接从Redis中获得,无需查询数据库了。
我们要利用Quartz周期性的将每个批次的秒杀商品,预热到Redis。例如每天的12:00 14:00 16:00 18:00进行秒杀,那么就在 11:55 13:55 15:55 17:55 进行预热
我们预热的内容有
- 我们预热的内容是将参与秒杀商品的sku查询出来,根据skuid将该商品的库存保存在Redis中。还要注意为了预防雪崩,在向Redis保存数据时,都应该添加随机数
- (待完善).在秒杀开始前,生成布隆过滤器,访问时先判断布隆过滤器,如果判断商品存在,再继续访问
- 在秒杀开始之前,生成每个商品对应的随机码,保存在Redis中,随机码可以绑定给有Spu,防止有用户知道SpuId暴力访问















 460
460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









