







一、设计目标
实现任意Q符号N重信源的R进制哈夫曼编码,其中参数满足:8≤Q≤15,2≤R≤5,1≤N≤3,且由用户自行输入,信源的概率分布也由用户输入。展示编码结果、平均码长、信源熵、编码效率。
二、设计步骤
(1)输入模块:实现对Q、N、R和信源概率数组(odds)的输入,并对其作出判断:Q、N、R是否满足要求、概率数组长度是否为Q、概率和是否为1;
(2)编码模块:
①计算N重信源概率,得到N重信源概率数组odds_N,并表示出各个N重符号的概率对应的符号组成的数组sym_N(例如:当N取3时,odds_N第三个元素为p1,p1,p3的乘积,sym_N的第三个元素为'1-1-3',代表的就是符号1-符号1-符号3这样三个一重符号构成的一个三重符号);
②对odds_N进行排序,并根据公式 "Qs=(R-1)*θ+R" 进行0元素补充,其中Qs为补充后的符号个数,θ为哈夫曼编码时概率求和次数(每次R个元素进行概率求和并重排序)。注:补充0元素是为了使最后一次概率求和时正好剩下R个概率;
③创建3行Qs列的元组(内容都以字符串类型存储),第一行储存各符号的概率,第二行储存各符号储存各符号的码字,第三行储存每个符号的表示,并根据数组odds_N和sym_N修改第一行和第三行内容;
(以上为编码准备工作,以下为huffman函数的编码内容)
④将补充后的序列长度、排序后的概率数组、待修改第二行的元组、编码进制数传入huffman函数进行编码;
⑤计算概率求和次数θ,设置五个变量来标志每次求和的元素下标和五个变量来表示当前数组最小的五个值(若R<5则不使用某些变量),并设置两个数组来表示当前待求和的概率(即原概率数组去掉已经被求和的概率,加上求和之后的概率)与本轮求和中最小的R个概率;
⑥在θ次循环中,重复执行:找最小值、求概率和、分配码元0~R-1、求和前后概率替换(即删除旧概率添加新概率)的操作,最后将分配完码元的元组赋给输出;
注:
①分配码元的过程分为两次,第一次针对原有的概率,第二次针对求和后的概率;
②flags数组用以标记某概率在一轮循环中是否已经分配码元,以免重复分配;
③belongs数组用以表示各个初始概率属于哪个求和后的概率;
(3)输出模块:打印编码结果和编码效率等参数。
三、代码实现
%%huffman code
%%输入Q值并判断
clear;clc;
while(1)
Q = input("请输入Q的值(8≤Q≤15): ");
if(Q < 8)||(Q > 15)
disp('不满足8≤Q≤15的条件,请重新输入Q值!');
else
break;
end
end
%%输入R值并判断
while(1)
R = input("请输入R的值(2≤R≤5): ");
if(R < 2)||(R > 5)
disp('不满足2≤R≤5的条件,请重新输入R值!');
else
break;
end
end
%%输入N值并判断
while(1)
N = input("请输入N的值(1≤N≤3): ");
if(N < 1)||(N > 3)
disp('不满足1≤N≤3的条件,请重新输入N值!');
else
break;
end
end
%%输入Q个元素的概率并判断
%%提供待测数组Q=11:[0.1274 0.1416 0.0199 0.1428 0.0989 0.0152 0.0435 0.0855 0.1497 0.1509 0.0246]
while(1)
odds = input("请以数组形式[]输入Q个元素各自的概率:");
length_odds = length(odds);
if(length_odds ~= Q)
disp('输入概率个数错误(不为Q),请重新输入!');
elseif(sum(odds) ~= 1)
disp(['概率之和为:',num2str(sum(odds))]);%%帮助概率纠错
disp('输入概率数值有误,请重新输入!');
else
break;
end
end
%%对概率进行排序与分组
[sort_odds , sort_index] = sort(odds , 'descend');%%分别为排序后的概率与最初的索引
%%计算N重概率
odds_N = [];%N重信源的概率
sym_N = [];%N重信源概率对应的符号序列(如11-2-6对应U11U2U6)
Qs = Q^N;
if(N == 1)
odds_N = sort_odds;
for x = 1:Q
sym_N = [sym_N , num2str(sort_index(x)),','];
end
sym_N = sym_N(1 : end-1);
end
if(N == 2)
odds_N = (sort_odds') * sort_odds;
odds_N = reshape(odds_N , [1,Q^2]);%重构成一行121列的矩阵
for x = 1:Q
stringsx = num2str(sort_index(x));%带“-”的符号
for y = 1:Q
stringsxy = [stringsx,'-',num2str(sort_index(y))];
sym_N = [sym_N , stringsxy,','];
end
end
sym_N = sym_N(1 : end-1);
end
if(N == 3)
odds1 = (sort_odds') * sort_odds;
odds2 = reshape(odds1 , [1,Q^2]);%重构成一行121列的矩阵
for k = 1:Q
odds_N = [odds_N , sort_odds(k)*odds2];
end
for x = 1:Q
stringsx = num2str(sort_index(x));%带“-”的符号
for y = 1:Q
stringsxy = [stringsx,'-',num2str(sort_index(y))];
for z = 1:Q
stringsxyz = [stringsxy,'-',num2str(sort_index(z))];
sym_N = [sym_N , stringsxyz,','];
end
end
end
sym_N = sym_N(1 : end-1);
end
%%对N重概率进行排序与分组
[huffodds , sort_index_N] = sort(odds_N , 'descend');
%%根据公式n'=(R-1)*合并次数+R进行元素补充(如果需要)
mod1 = mod(Q^N-R , R-1);
supply = mod((R-1-mod1),R-1);%%需要补充0概率的个数,mod为了避免sply=0的情况
if(supply ~= 0)
for i = 1:supply
huffodds = [huffodds , 0];
end
end
Qs= length(huffodds);
%%创建元组
pri_cell = creat_charcell(3,Qs);%%第一行储存分组后的概率,第二行码字,第三行符号
%%根据求得的概率和符号修改元组第一和第三行
for xx = 1:Q^N
odds_N_str = num2str(odds_N(xx));
sym_N_cell = split(sym_N,',');%注意分裂开得到的是元组类型
pri_cell(1,xx) = {odds_N_str};
pri_cell(3,xx) = {char(sym_N_cell(xx))};
end
%%编码
aft_cell = huffman(Qs,huffodds,pri_cell,R);
aft_cell = aft_cell(:,1:Q^N);%去除补充的0概率列
%%编码结果打印
disp('--------------------------------------');
disp('哈夫曼编码结果:');
sum_huffcode = 0;
for k = 1 : Q^N
symm = char(aft_cell(3,k));
od = num2str(odds_N(k));%%字符串形式的概率
co = char(aft_cell(2,k));%%字符串形式的编码
sum_huffcode = sum_huffcode + length(co)*odds_N(k);
disp(['符号',symm,'的概率为:',od,',哈夫曼编码为:',co]);
end
%%编码参数计算与展示
l = sum_huffcode;
odds_N(find(odds_N==0))=[];
H = sum(odds_N.*log2(1./odds_N));%%熵
eff = H / (l*log2(R));%%编码效率
disp('--------------------------------------');
disp(['平均码长:',num2str(l)]);
disp(['信源熵:',num2str(H)]);
disp(['编码效率:',num2str(eff)]);
%--------------------------------------函数分割线--------------------------------------%
%%输入参数分别为:Qs,N重概率序列(已排序),元组,进制数
%%输出参数分别为:输出元组
%%编码规则:概率从大到小分配0,1,2……R-1码元
function output = huffman(n,huffodds,cel,r)
Qs = n;
nand = (Qs - r)/(r - 1)+1;%合并次数
sumodds = zeros(1,nand);%存储各次合并求取的概率和
pri_odds = huffodds;
belongs = zeros(1,Qs);%元素代表各概率所属的概率和
%%初始化
min1=0;min2=0;min3=0;min4=0;min5=0;%本次合并的五个最小值
start1=0;start2=0;start3=0;start4=0;start5=0;%五个start分别对应五个合并位置
for ii = 1 : nand
%%初始化
jj = 0;%重置以便调试
pri_belongs = belongs;
flags = zeros(1,Qs);%判断某一个概率在一轮合并中是否分配码元,以免重复分配
%%求取合并概率下标(注意,此处取降序以免相同概率影响排序,从而影响码元分配,不信可以试试)
[useless , index] = sort(huffodds,'descend');
len = length(index);
start1 = index(len);min1 = huffodds(start1);
start2 = index(len-1);min2 = huffodds(start2);
if(r>2) start3 = index(len-2);min3 = huffodds(start3);end
if(r>3) start4 = index(len-3);min4 = huffodds(start4);end
if(r>4) start5 = index(len-4);min5 = huffodds(start5);end
%%修改sumodds数组
sumodds(ii) = huffodds(start2) + huffodds(start1);
if(r>3) sumodds(ii) = sumodds(ii) + huffodds(start3);end
if(r>4) sumodds(ii) = sumodds(ii) + huffodds(start4);end
if(r>5) sumodds(ii) = sumodds(ii) + huffodds(start5);end
%%第一轮分配码元,并修改belongs数组
if(r>4)
if(pri_odds(start5) == huffodds(start5))
cel(2,start5) = {['4',char(cel(2,start5))]};
belongs(start5) = sumodds(ii);
end
end
if(r>3)
if(pri_odds(start4) == huffodds(start4))
cel(2,start4) = {['3',char(cel(2,start4))]};
belongs(start4) = sumodds(ii);
end
end
if(r>2)
if(pri_odds(start3) == huffodds(start3))
cel(2,start3) = {['2',char(cel(2,start3))]};
belongs(start3) = sumodds(ii);
end
end
if(pri_odds(start2) == huffodds(start2))
cel(2,start2) = {['1',char(cel(2,start2))]};
belongs(start2) = sumodds(ii);
end
if(pri_odds(start1) == huffodds(start1))
cel(2,start1) = {['0',char(cel(2,start1))]};
belongs(start1) = sumodds(ii);
end
%%第二轮分配码元并修改数组(判断是否需要)
if(ii ~= 1)&&((length(find(pri_belongs == min2))~=0)||(length(find(pri_belongs == min1))~=0)||(length(find(pri_belongs == min3))~=0)||(length(find(pri_belongs == min4))~=0)||(length(find(pri_belongs == min5))~=0))
if(length(find(pri_belongs == min1))~=0)
loc_sum = find(pri_belongs == min1);%属于min1概率的组分的位置
belongs(loc_sum) = sumodds(ii);%修改所属概率和
for jj = 1:length(loc_sum)
%%此处判断,实质是为了判断第一轮是否赋予了码元,避免重复或遗漏
if(loc_sum(jj) ~= start1)||(pri_odds(start1) ~= huffodds(start1))
loc_bel = loc_sum(jj);%单个元素位置
cel(2,loc_bel) = {['0',char(cel(2,loc_bel))]};
flags(loc_bel) = 1;
end
end
end
if(length(find(pri_belongs == min2))~=0)
loc_sum = find(pri_belongs == min2);%属于min2概率的组分的位置
belongs(loc_sum) = sumodds(ii);%修改所属概率和
for jj = 1:length(loc_sum)
if(loc_sum(jj) ~= start2)||(pri_odds(start2) ~= huffodds(start2))
loc_bel = loc_sum(jj);%单个元素位置
if(flags(loc_bel) == 0)%对标志位的判断
cel(2,loc_bel) = {['1',char(cel(2,loc_bel))]};
flags(loc_bel) = 1;
end
end
end
end
if(length(find(pri_belongs == min3))~=0)&&(r>2)
loc_sum = find(pri_belongs == min3);%属于min3概率的组分的位置
belongs(loc_sum) = sumodds(ii);%修改所属概率和
for jj = 1:length(loc_sum)
%%此处判断,实质是为了判断第一轮是否赋予了码元,避免重复或遗漏
if(loc_sum(jj) ~= start3)||(pri_odds(start3) ~= huffodds(start3))
loc_bel = loc_sum(jj);%单个元素位置
if(flags(loc_bel) == 0)%对标志位的判断
cel(2,loc_bel) = {['2',char(cel(2,loc_bel))]};
flags(loc_bel) = 1;
end
end
end
end
if(length(find(pri_belongs == min4))~=0)&&(r>3)
loc_sum = find(pri_belongs == min4);%属于min4概率的组分的位置
belongs(loc_sum) = sumodds(ii);%修改所属概率和
for jj = 1:length(loc_sum)
%%此处判断,实质是为了判断第一轮是否赋予了码元,避免重复或遗漏
if(loc_sum(jj) ~= start4)||(pri_odds(start4) ~= huffodds(start4))
loc_bel = loc_sum(jj);%单个元素位置
if(flags(loc_bel) == 0)%对标志位的判断
cel(2,loc_bel) = {['3',char(cel(2,loc_bel))]};
flags(loc_bel) = 1;
end
end
end
end
if(length(find(pri_belongs == min5))~=0)&&(r>4)
loc_sum = find(pri_belongs == min5);%属于min5概率的组分的位置
belongs(loc_sum) = sumodds(ii);%修改所属概率和
for jj = 1:length(loc_sum)
%%此处判断,实质是为了判断第一轮是否赋予了码元,避免重复或遗漏
if(loc_sum(jj) ~= start5)||(pri_odds(start5) ~= huffodds(start5))
loc_bel = loc_sum(jj);%单个元素位置
if(flags(loc_bel) == 0)%对标志位的判断
cel(2,loc_bel) = {['4',char(cel(2,loc_bel))]};
flags(loc_bel) = 1;
end
end
end
end
end
%%合并与删除概率(因start1,2,3,4,5可能乱序,故需要先排序再处理)
start = sort([start1,start2],'descend');
if(r>2) start = sort([start1,start2,start3],'descend');end
if(r>3) start = sort([start1,start2,start3,start4],'descend');end
if(r>4) start = sort([start1,start2,start3,start4,start5],'descend');end
huffodds(start(1)) = sumodds(ii);
huffodds(start(2)) = [];
if(r>2) huffodds(start(3)) = [];end
if(r>3) huffodds(start(4)) = [];end
if(r>4) huffodds(start(5)) = [];end
end
output = cel;
end
%--------------------------------------函数分割线--------------------------------------%
%%creat_charcell函数:创建a*b维的cell类型的空char数组
function charcell = creat_charcell(a,b)
charcell=cell(a,b);
for i=1:a
for j=1:b
charcell(i,j)=cellstr(num2str(charcell{i,j}));
%%charcell中的元组由double→char→{char}
end
end
end四、运行结果
此处以提供的待测数组为测试对象:Q=11,R=3,N=2
部分编码结果如下:
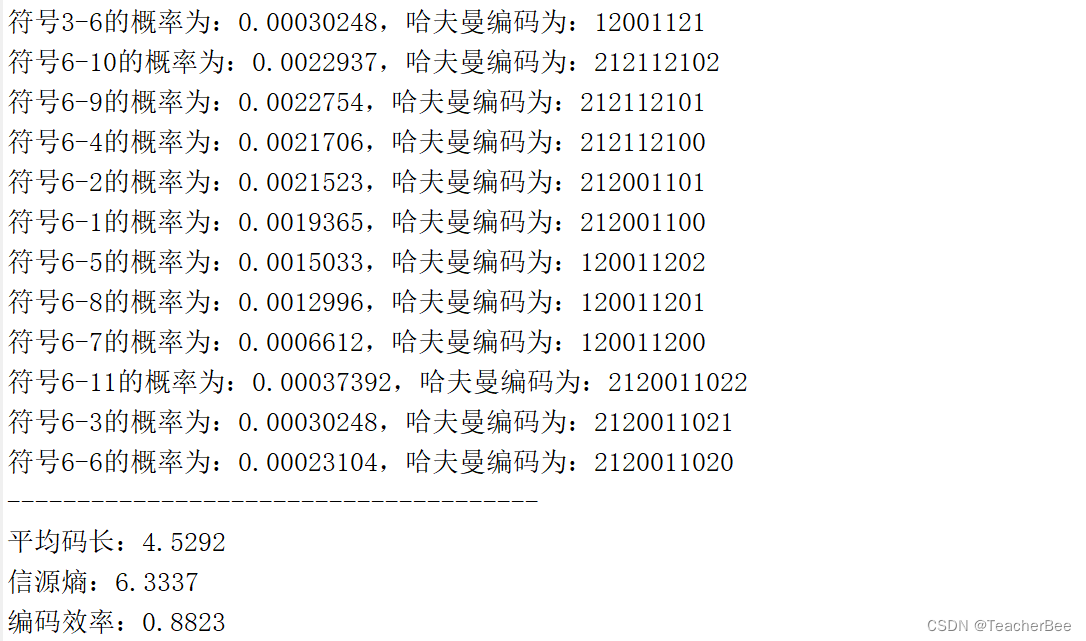
五、总结
(1)Q、N、R的取值范围可根据代码最前段自行更改;
(2)若不要求3~5进制编码或2~3重信源,可删去huffman函数中关于R的判断语句或N重概率相关语句,代码冗余度会大幅降低;
(3)概率和是否为1的判断可以删去,因为有时候会无故报错(我也不知道为啥...);
(4)作者编程水平有限,希望为读者能提供一定帮助。















 1464
1464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









