







一、贝叶斯公式
1、条件概率

2、全概率公式

图解:

在了解贝叶斯概率前,先了解以下定义:
三个小偷都有可能去该村子偷东西,那么这个村子失窃的可能性就要考虑这三个小偷去偷东西的总概率,也就是全概率公式:

解释一下上述推导过程,P(B|A) 表示在 A 的情况下 B 发生的概率。结合题意理解为,任意一个小偷去偷,偷窃成功的情况;P(A) 表示其中一个小偷准备去这个村子行窃的概率。下面总结出一个通用的公式:
![]()
贝叶斯公式是在 B 已经发生的情况下,执果索因。也就是本例中,已经得知该村子失窃,现在要判断是谁行窃的可能性最大。可以表示为:
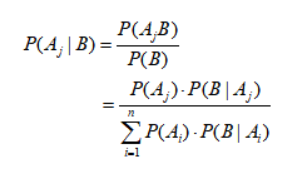
这样,我们就把已知每个人作案成功的概率转化为已知失窃,判别是谁作案的问题。这样的问题是很常见的,先验概率一般是已知的,通过它来求得后验概率。上面的公式也许有人看不太明白,这里写一个简单的贝叶斯公式:
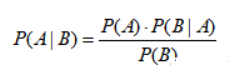
我们把P(A)称为"先验概率"(Prior probability),即在B事件发生之前,我们对A事件概率的一个判断。P(A|B)称为"后验概率"(Posterior probability),即在B事件发生之后,我们对A事件概率的重新评估。P(B|A)/P(B)称为"可能性函数"(Likelyhood),这是一个调整因子,使得预估概率更接近真实概率。
后验概率 = 先验概率 x 调整因子
3、贝叶斯公式
如果 UAi = Ω,AiAj ≠ Φ(对一切i ≠ j) ,P(Ai )>0,则对任一事件B,只要P(Bi)>0,有:

但是如果将贝叶斯的公式应用到机器学习中,效果并不是很好,原因在于一般数据特征值较多,计算复杂度太高,还有可能找不到对应的特征。引用一个例子来解释一下。现在有一个女生,她的择偶标准做了以下说明:
| 帅? | 性格好? | 身高? | 上进? | 嫁与否? |
| 帅 | 不好 | 矮 | 不上进 | 不嫁 |
| 不帅 | 好 | 矮 | 上进 | 不嫁 |
| 帅 | 好 | 矮 | 上进 | 嫁 |
| 不帅 | 好 | 高 | 上进 | 嫁 |
| 帅 | 不好 | 矮 | 上进 | 不嫁 |
| 不帅 | 不好 | 矮 | 不上进 | 不嫁 |
| 帅 | 好 | 高 | 不上进 | 嫁 |
| 不帅 | 好 | 高 | 上进 | 嫁 |
| 帅 | 好 | 高 | 上进 | 嫁 |
| 不帅 | 不好 | 高 | 上进 | 嫁 |
| 帅 | 好 | 矮 | 不上进 | 不嫁 |
| 帅 | 好 | 矮 | 不上进 | 不嫁 |
现在有一对情侣,男生想女生求婚,男生的四个特点分别是不帅,性格不好,身高矮,不上进,请你判断一下女生是嫁还是不嫁?
首先,既然有了标准,那么对照着表格找一下好了,然而不巧的是,表中没有该男生的形象,四个特征的各种组合有很多种,目前只得到12组数据,那其他情况的概率即为0,根据贝叶斯公式可以计算得,该女生不可能嫁给他。

显然这样无法计算了,而且,当特征较多时,其组合形式会特别多。因此,出现了朴素贝叶斯,对特征值进行独立性假设(会影响模型预测准确率,但在大部分场景下一样实用)。这样每个特征值对结果的影响互不相关,则有下面两个等价公式:
-
P(不帅、性格不好、矮、不上进)=P(不帅)P(性格不好)P(矮)P(不上进)
-
P(不帅、性格不好、矮、不上进|嫁)=P(不帅|嫁)P(性格不好|嫁)P(矮|嫁)P(不上进|嫁)

接下来我们对应表格可以查找到公式中对应的概率值,计算得:
(1/2*1/6*1/6*1/6*1/2)/(1/3*1/3*7/12*1/3) = 3/56
同理计算不嫁的概率:

显然27/28 > 3/56,所以选择不嫁。
参考:
















 870
870











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











