






这篇文章是2024年TOIS的A Diffusion model for POI recommendation。
首先可以说一下为什么看这篇文章的一个想法。因为扩散模型这几年的火热,从原先的CV领域已经慢慢的拓展到了其他的领域中。之前读过的另一篇扩散模型用在轨迹这种时序序列的文章,可以在CSDN中看到。
两者都在轨迹这种序列数据中使用了扩撒模型,这篇与上一篇的对比给我感觉还是有所差别的。
先从头开始说吧。
作者提出了一种基于注意力机制的图编码器,通过整合观察到的访问序列中的额外时空信息来扩展传统的顺序 GNN。这种新颖的序列图编码器可以为用户生成细粒度的嵌入。同时在此基础上提出了 Diff-POI,这是一种基于扩散的模型,从反映用户地理偏好的后验分布中进行采样。借助扩散过程,Diff-POI 能够充分利用所获得的位置和用户嵌入的潜力。
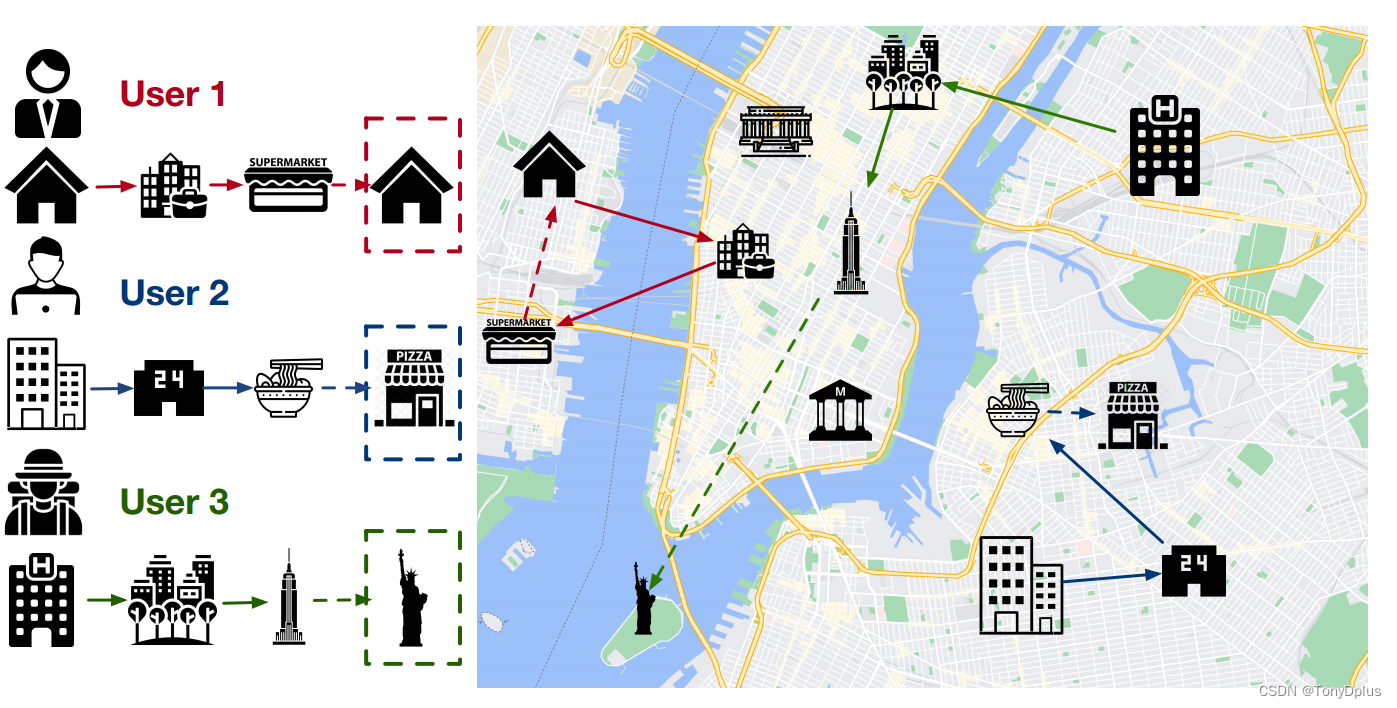
先从这种图来分析作者的动机吧。以往的一些POI推荐方法往往只能在已有框架下进行预测推荐,这种情况对于图中的user1和2来说是适配的,但是如果用户是一个旅行者,他的POI推荐可能就会难易准确描述。
更进一步的说,如果模型的测试集中出现了从未在训练集中出现的POI,模型会无法进行较好的推荐,从而影响模型的精准度,这也是许多已有的基于图卷积进行POI预测的模型所无法克服的固有弊端。
但是图神经网络确实在POI推荐中出现了不错的效果。扩散模型的加噪去噪则能带来更多位置的变化,可以克服这一弊端。当然这个是我自己的理解,作者给的理由也相似。
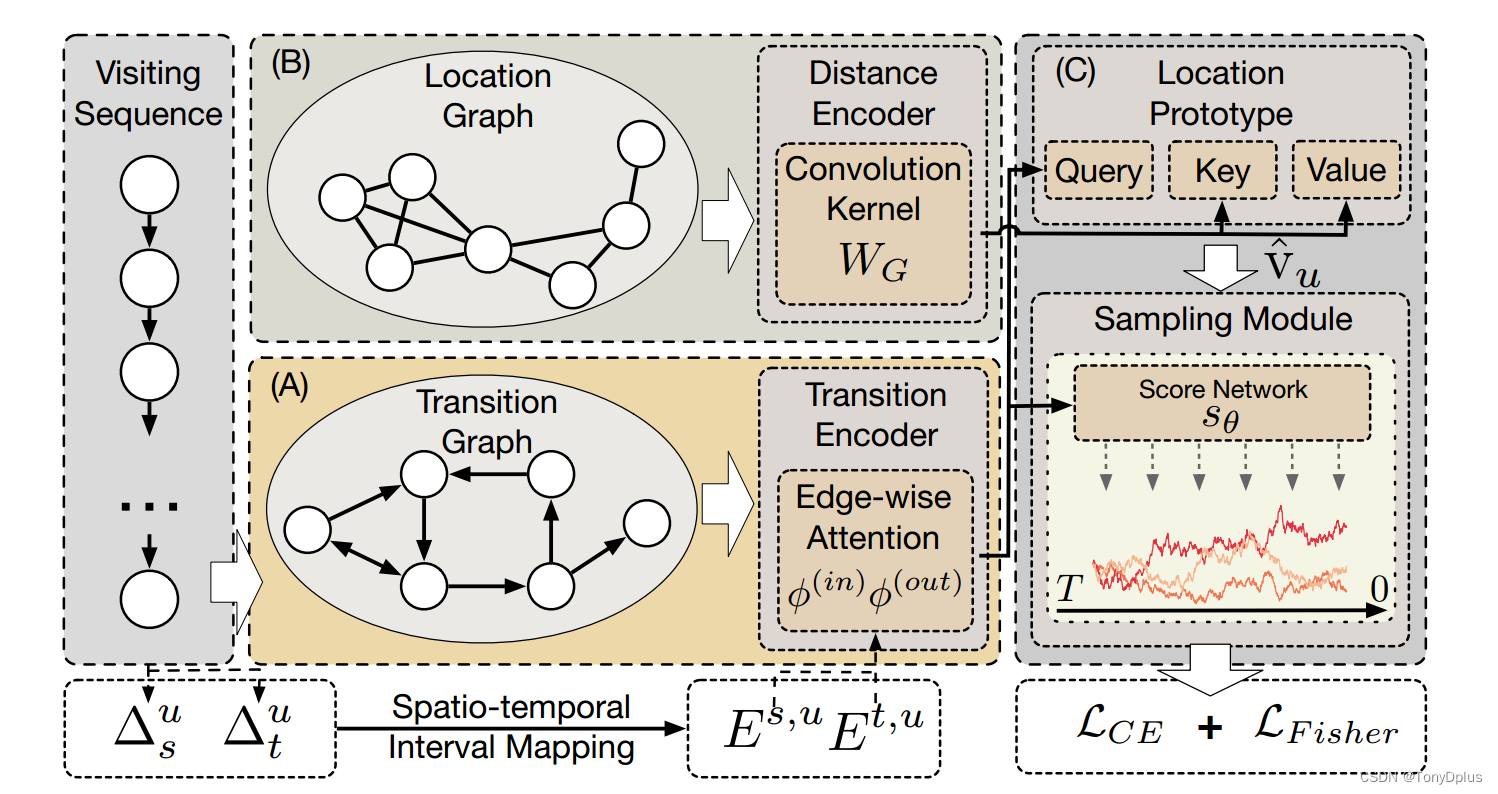
接着我们再来分析一下模型吧。
其实主要可以分为两个部分。在Diff-POI模型中,确实首先使用图神经网络(GNN)来捕捉用户的空间偏好特征,然后利用扩散模型对得到的分布进行加噪和去噪。
前面的A,B部分其实都是对用户的序列信息构造图模型,在此他也做了一个创新,使用一个基于注意力的图编码器,将时空信息与传统的序列图结合起来,生成精细的用户体验嵌入。
因为我对图方法的研究不是很深入,因此也不是很理解。
但是我对这个模型最感兴趣的是他的扩散模型部分。
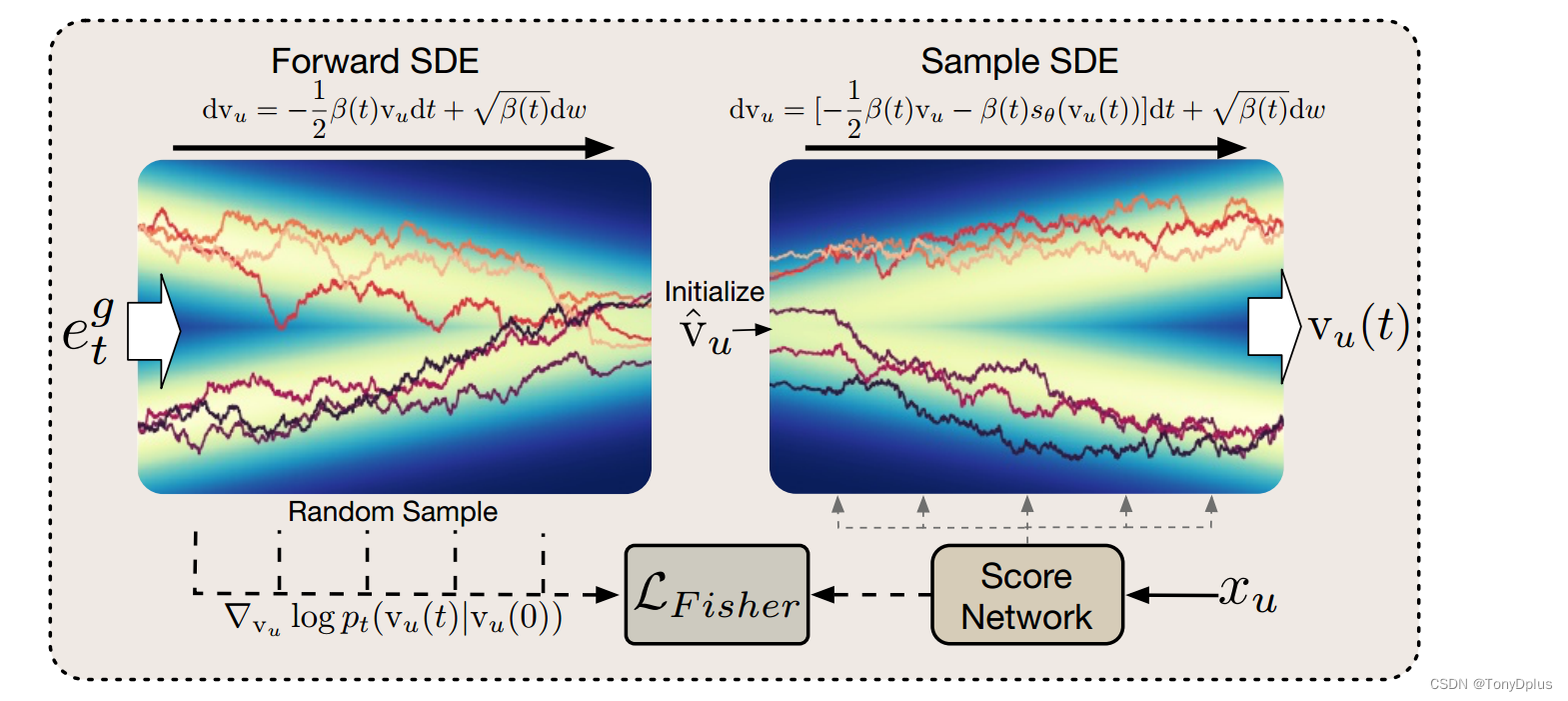
模型的加噪使用的是SDE(随机微分方程),因为考虑轨迹有这种顺序特征,这样的加噪能更好的符合时间步的变化。
接下来的去噪过程中,模型需要学习如何从加噪的数据中恢复出原始数据。这通常涉及到估计数据分布的梯度,即得分函数(Score Function),它指示了数据点在后验分布中的梯度方向。为了估计得分函数,模型使用一个得分网络(通常是一个多层感知器MLP),它参数化了得分函数并尝试学习如何从加噪数据中恢复原始数据。得分网络通过Fisher散度进行优化。
逆向扩散过程允许模型超越用户历史访问的聚合表示,探索并推荐新区域的POI。
总的来说模型分为两步
第一步:图神经网络的预训练
在这一步中,模型通过图神经网络(GNN)对用户的行为数据进行编码,提取特征表示。具体包括:
- 使用图结构来表示用户和POI之间的关系。
- 利用图神经网络对用户的访问序列和POI的地理关系进行编码。
- 通过注意力机制和图卷积网络提取用户和POI的特征嵌入。
第二步:扩散模型的训练
在图神经网络预训练完成后,接下来进行扩散模型的训练,这包括加噪和去噪过程:
- 正向扩散(加噪):在这一步中,模型向用户的空间偏好向量添加噪声,模拟数据从原始分布向先验分布的扩散。
- 逆向扩散(去噪):这是训练过程的关键部分,模型需要学习如何从加噪后的分布中恢复出原始的用户偏好。这涉及到:
- 训练一个得分网络来估计后验分布的梯度。
- 使用逆向SDE进行采样,逐步去除噪声,恢复用户的空间偏好。
- 优化得分网络,使其能够准确反映后验分布的梯度,通常使用Fisher散度作为辅助损失函数。
当然文中也对比了许多基线方法:
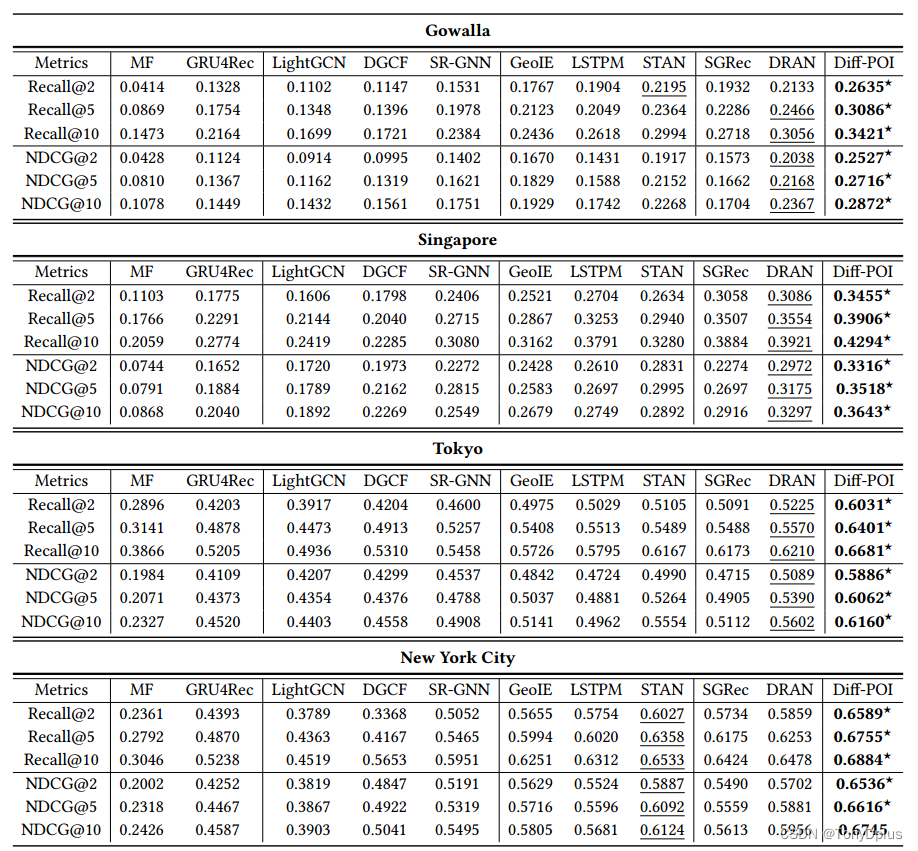
Diff-POI确实都取得了不错的效果。
总的来说,作者使用了图神经网络在POI推荐中已有的优越效果,加入了注意力图编码器来更好的捕获特征,同时为了解决图神经网络对于无法预测未知节点的情况,通过加入扩散模型,运用扩散模型带来的自由探索由此来克服这一难点。两者的结合也体现了较好的效果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









