






这次阅读的是2023年FCS的DPPS: a novel dual privacy-preserving scheme for enhancing query privacy in continuous location-based services。
当然,首先我是如何搜索到这一篇的呢?我是以2021年TMC的A novel metric and attack model. IEEE Transactions on Mobile Computing为background进行论文检索时发现了这一篇论文。
这篇论文确实以TMC中提出的方法有极大的相似性,其也是注重考虑了通过网格化的地理划分后的网格位置之间的转移概率。转移熵仍然是其主要的参考标准之一。
因此相同的部分就不做过多的赘述,我们来讲讲不一一样的。
首先就是他这边的一张图给出的case

在ti时,生成了三个接近真实位置的虚拟位置,这使得攻击者很容易识别真实位置。此外,在ti+1选择的虚拟位置之一不在查询范围内并且超出了最大距离Dis,因此对手可以基于两个位置集之间的相关性直接将其识别为虚假位置。
这是论文的描述,对于第一点我是保留一个疑问的,同时也没有论文证明,但是也是能够接受,第二个的话则是考虑了一个速度因素
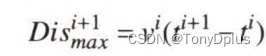
通过考虑用户的移动速度,过滤出一个范围,这样就为地理坐标设置了一个上限,也能够抵抗来自速度信息的推理攻击。
此外改论文引用了HMM的概念,但是其主要的目的不是像我们想象的那样,更多的是考虑连续两次查询带来的隐藏状态,即转移概率。

这里他也用数学的方式推导出了为何攻击者在得到转移概率信息后能够造成威胁。
-
互信息的定义: 互信息 𝐼(𝑋;𝑌)I(X;Y) 表示随机变量 𝑋X 和 𝑌Y 之间的信息量。它可以通过两个变量的联合分布 𝑝(𝑥,𝑦)p(x,y)、边缘分布 𝑝(𝑥)p(x) 和 𝑝(𝑦)p(y) 来计算。公式的第一行就是互信息的定义式。
-
分解互信息: 第二行将互信息的定义式进行了分解,分成了两项。第一项是 𝑝(𝑥,𝑦)p(x,y) 与 𝑝(𝑥)p(x) 的比值的期望值的对数,第二项是 𝑝(𝑦)p(y) 的期望值的对数。
-
条件概率的应用: 接下来,将条件概率 𝑝(𝑦∣𝑥)p(y∣x) 代入第一项中,将其表示为 𝑝(𝑥)p(x) 与 𝑝(𝑦∣𝑥)p(y∣x) 的乘积的期望值的对数。而第二项则保持不变。
-
化简求和: 在第三行中,将求和符号移至了概率的内部,并利用了 𝑝(𝑥,𝑦)=𝑝(𝑥)𝑝(𝑦∣𝑥)p(x,y)=p(x)p(y∣x) 的条件概率定义,对第一项进行了化简。第二项保持不变。
-
信息熵的应用: 在第四行,将对数中的 𝑝(𝑦)p(y) 提出来,并使用了 ∑𝑥𝑝(𝑥,𝑦)=𝑝(𝑦)∑xp(x,y)=p(y) 的性质,化简了第二项。
-
最终结果: 最后,将第三行和第四行代入第一行的定义中,我们得到了互信息 𝐼(𝑋;𝑌)I(X;Y) 的一个表达式。最后一行说明了互信息 𝐼(𝑋;𝑌)I(X;Y) 是 𝑌Y 的熵减去给定 𝑋X 条件下 𝑌Y 的熵。而根据信息论的性质,给定更多的信息可以减少不确定性,所以 𝐻(𝑌∣𝑋)H(Y∣X) 通常会小于 𝐻(𝑌)H(Y)。
更细的解释可以为:
-
第一行: 这一部分利用了对数的性质,将互信息的定义式中的 𝑝(𝑥,𝑦)𝑝(𝑥)p(x)p(x,y) 拆分为两个对数相减的形式:log(𝑝(𝑥,𝑦))−log(𝑝(𝑥))log(p(x,y))−log(p(x))。然后通过对 𝑋X 和 𝑌Y 的所有可能取值求和,得到了两个双重求和。
-
第二行: 接下来,将分子 𝑝(𝑥,𝑦)p(x,y) 替换为 𝑝(𝑥)𝑝(𝑦∣𝑥)p(x)p(y∣x),这是基于条件概率的定义 𝑝(𝑥,𝑦)=𝑝(𝑥)𝑝(𝑦∣𝑥)p(x,y)=p(x)p(y∣x)。这样做的目的是为了引入条件概率 𝑝(𝑦∣𝑥)p(y∣x)。
-
第三行: 由于我们已经引入了条件概率 𝑝(𝑦∣𝑥)p(y∣x),我们可以将求和符号移到 𝑝(𝑥)p(x) 的外面,得到了 𝑝(𝑥)p(x) 与 𝑝(𝑦∣𝑥)p(y∣x) 的乘积的期望值的对数。
这个推导我认为是这篇论文的一个核心。当然他的HMM与IOT的HMM还是不一样的。
最后论文的dummy算法为
weight[d]=a⋅∣1−pitl∣+b⋅dis(ti+1,i+1)
这个对我来说算是比较有意思的设置,同时考虑了转移概率与距离因素,通过调控a,b的参数可以得到不一样的限制范围,生成不同要求的匿名集合。















 74
74











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









